
Abstract
Negative observations pose a problem in econometric models that apply log-transformation to the data. We propose a simple yet effective solution to this problem by extending the domain of numbers to the set of complex numbers. In particular, this approach suggests that we can replace the negative values with their absolute values and estimate this transformed model with conventional estimation methods. Moreover, we extended this approach to logs of independent variables with negative observations as well. Using our method, we estimated the profit efficiencies of the US banks and illustrated that different treatments for observations with negative profits (loss) may lead to substantially different efficiency estimates. We also showed the importance of controlling bank heterogeneity when estimating efficiency.

Similar content being viewed by others
Notes
Our approach is general and can be applied in many other contexts that involve logarithm of negative numbers.
See Bos and Koetter (2011) for similar arguments.
The efficiency estimates are sensible after some adjustment for negative profit observations as we will describe later in the text.
Koetter et al. (2012) do not control for heterogeneity. Hence, although their method for handling negative profit values is reasonable, their efficiency estimates may be contaminated by the presence of heterogeneity.
In what follows, when we say profit function we mean alternative profit function.
In the stochastic frontier context where we estimate efficiency, Greene (2005a), Greene (2005b) and Wang and Ho (2010) handle heterogeneity as well. However, their models only capture heterogeneity that is based on individual effects, i.e., dummy variables. In the banking context, this may not be sufficient to capture all the heterogeneity. For example, bank size would likely be an important determinant of bank heterogeneity, which may not be fully captured by bank-specific dummies. See Kutlu and Tran (2019) for a literature review on heterogeneity in panel stochastic frontier models.
We use bold font for vectors and matrices.
There are alternative functional forms such as level-log and level-level that allow negative profits. However, these functional forms may not be the most preferable ones in the profit function estimation context. In general, when level-log or level-level may be considered as reasonable alternatives, one may utilize the Bayesian Information Criterion as a model selection criteron.
In practice, zero profit is rare. So, we can ignore this case. Moreover, this result is due to the fact that \(\exp \left(i\pi \right)=-1\).
When the residuals are real numbers, we have \({\overline{{\bf{v}}}}^{\prime}{\bf{v}}={{\bf{v}}}^{\prime}{\bf{v}}\).
Note that MD is symmetric and idempotent, which is essential for establishing formula for the parameter estimates. Note also that \({\widetilde{{\bf{y}}}}^{* }={{\bf{M}}}_{{\bf{D}}}{\mathrm{ln}}\,{\bf{y}}={{\bf{M}}}_{{\bf{D}}}{\mathrm{ln}}\,\left|{\bf{y}}\right|\).
This is obtained through partitioned-regression results of Frisch-Waugh-Lovell Theorem.
Although level-log or level-level production models are not commonly used, in the maximum likelihood setting, it is possible to compare level-level, level-log and log-log models on the statistical grounds based on Bayesian Information Criterion. One advantage of level-log and level-level models is that the negative profit values are allowed. Similar to log-log model, level-log or level-level models may include negative profit dummies as additional explanatory variables, which may capture the structural differences between firms with profits and losses.
This follows from the fact that \(\exp ({{\bf{x}}}^{\prime}\hat{{\boldsymbol{\beta }}}+\pi i)=-\exp ({{\bf{x}}}^{\prime}\hat{{\boldsymbol{\beta }}})\).
We assume that \({{\bf{D}}}_{{{\bf{X}}}_{{\bf{1}}}}\) has the same column rank as X1, which is k1. When at least two variables from X1 has the same sign for all observations, \({{\bf{D}}}_{{{\bf{X}}}_{{\bf{1}}}}\) will have a smaller number of columns as we need to drop repeating dummies. This, however, is not an issue for the general arguments that we present.
Separate minimization of comlex and real parts of parameters is not a standard feature of complex OLS. Our rearrangement of the model enables us to utilize this property, which substantially simplifies the analysis.
Note that D is an n × k1 matrix and X is an n × k matrix.
In their appendix, Kutlu and Wang (2018) consider a stochastic frontier model where the dependent variable is in a level form. Hence, their model allows negative values in the dependent variable. However, unlike conventional stochastic frontier models, they model a supply relation in their paper, which is obtained from a game theoretical model.
Note that when y < 0, we have \(y=\exp \left({{\bf{x}}}^{\prime}{\boldsymbol{\beta }}+i\pi +v-u\right)=-\exp \left({{\bf{x}}}^{\prime}{\boldsymbol{\beta }}+v-u\right)\). Or in general, \(y=s\exp \left({{\bf{x}}}^{\prime}{\boldsymbol{\beta }}+v-u\right)\). Since ym > 0, \({y}^{m}=\exp \left({{\bf{x}}}^{\prime}{\boldsymbol{\beta }}+v\right)\). This illustrates the connection of our complex valued model and our efficiency estimates.
An alternative estimator for efficiency is \(\widehat{eff}=sE\left[\exp \left(-u\right)| \varepsilon \right]\).
Also, we can replace \({\widehat{eff}}_{\max }\) by 1 in this formula.
Bos and Koetter (2011) efficiency estimates are positive. Hence, in their paper they did not apply this correction.
For detailed explanation of variables see Koetter et al. (2012). Note that while we use the same variables, we extended their dataset, which covered years between 1976 and 2007.
Kutlu et al. (2019) controls for heterogeneity as well but they only use firm-effects, time, and time square variables when controlling for heterogeneity. We, on the other hand, control heterogeneity more extensively by including firm-specific total assets and total equity variables. Kutlu et al. (2019) solve endogeneity problem in this context but also consider exogeneity case too. Other examples that solve endogeneity are Kutlu (2010), Kutlu (2018),Amsler et al. (2016),Amsler et al. (2017), Karakaplan and Kutlu (2017a),Karakaplan and Kutlu (2017b), and Kutlu et al. (2020). In our case, we assume that the explanatory variables are exogenous.
\({N}^{+}\left(.,.\right)\) denotes the half-normal distribution.
Details of the estimation procedure can be found in Kutlu et al. (2019).
Note that we did not impose homogeneity of degree one to the input prices as alternative profit function does not require such a restriction (see Restrepo-Tobón and Kumbhakar, 2014).
We used Matlab to estimate the stochastic frontier models. For optimizations, we used 20 initial points and switching optimization methods including BFGS, DFP, Nelder-Mead simplex method, and a patternsearch algorithm.
We also calculated the Feng and Horrace (2012) variation of efficiency for the Complex model via \({\widehat{eff}}^{T}=\frac{\widehat{eff}-{\widehat{eff}}_{\min }}{{\widehat{eff}}_{\max }-{\widehat{eff}}_{\min }}\) formula. The mean efficiency is 82.53. The correlation between the negative efficiency and transformed efficiency scores (Feng and Horrace (2012)) is very high: 0.9815.
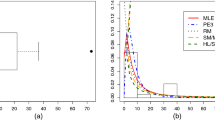
Note that as the percentage of the negative profit observations is small, the median of efficiency is mostly determined by the efficiency scores for observations with positive valued profits. Hence, although Bos-Koetter method assigns positive values to negative profit firms, the medians of efficiency estimates are still close. Indeed, the efficiency scores of negative profit observations for Complex and Bos-Koetter methods are highly correlated (in absolute value) as it can be seen in Table 3. Moreover, the median efficiency estimates (in absolute value) for Complex and Bos-Koetter methods are 75.55 and 76.62, respectively.
Since other methods give substantially different results, we only compare Complex and Bos-Koetter methods in Figure 1.
We would like to thank to the anonymous referee for suggesting this model as an alternative to our model.
References
Almanidis P, Karakaplan MU, Kutlu L (2019) A dynamic stochastic frontier model with threshold effects: U.S. bank size and efficiency. J Product Anal 52:69–84
Amsler C, Prokhorov A, Schmidt P (2016) Endogenous stochastic frontier models. J Econom 190:280–288
Amsler C, Prokhorov A, Schmidt P (2017) Endogenous environmental variables in stochastic frontier models. J Econom 199:131–140
Bagwell CB (2005) HyperLog — A flexible log-like transform for negative, zero, and positive valued data. Cytometry Part A 64A:34–42
Berger AN, Mester LJ (1997) Inside the black box: what explains differences in the efficiencies of financial institutions. J Bank Finance 21:895–947
Bos JWB, Koetter M (2011) Handling losses in translog profit models. Appl Econ 43:307–312
Cornwell C, Schmidt P, Sickles RC (1990) Production frontiers with time-series variation in efficiency levels. J Econom 46:185–200
Feng Q, Horrace WC (2012) Alternative technical efficiency measures: skew, bias and scale. J Appl Econom 27:253–268
Fernandez de Guevara J, Maudos J (2002) Inequalities in the efficiency of the banking sectors of the European Union. Appl Econ Lett 9:541–544
Greene WH (2005a) Fixed and random effects in stochastic frontier models. J Product Anal 23:7–32
Greene WH (2005b) Reconsidering heterogeneity in panel data estimators of the stochastic frontier model. J Econom 126:269–303
Karakaplan MU, Kutlu L (2017a) Endogeneity in panel stochastic frontier models: an application to the Japanese cotton spinning industry. Appl Econ 49:5935–5939
Karakaplan MU, Kutlu L (2017b) Handling endogeneity in stochastic frontier analysis. Econ Bull 37:889–901
Koetter M, Kolari JW, Spierdijk L (2012) Enjoying the quiet life under deregulation? Evidence from adjusted Lerner indices for U.S. banks. Rev Econ Stat 94:462–480
Kutlu L (2010) Battese-Coelli estimator with endogenous regressors. Econ Lett 109:79–81
Kutlu L (2018) A distribution-free stochastic frontier model with endogenous regressors. Econ Lett 163:152–154
Kutlu L, Tran KC (2019) Heterogeneity and Endogeneity in Panel Stochastic Frontier Models, Panel Data Econometrics: Theory, Edited by Mike G. Tsionas (Elsevier).
Kutlu L, Tran KC, Tsionas MG (2019) A time-varying true individual effects model with endogenous regressors. J Econom 211:539–559
Kutlu L, Tran KC, Tsionas MG (2020) A spatial stochastic frontier model with endogenous frontier and environmental variables. Eur J Oper Res 286:389–399
Kutlu L, Wang R (2018) Estimation of cost efficiency without cost data. J Product Anal 49:137–151
Maudos J, Pastor JM (2001) Cost and profit efficiency in banking: an international comparison of Europe, Japan and the USA. Appl Econ Lett 8:383–387
Miller KS (1973) Complex linear least squares. SIAM Rev 15:706–726
Schmidt P, Sickles RC (1984) Production frontiers and panel data. J Bus Econ Stat 2:367–374
Svetunkov S (2012) Complex-valued modeling in economics and finance. Springer, New York
Ravallion M (2017) A concave log-like transformation allowing non-positive values. Econ Lett 161:130–132
Vander Vennet R (2002) Cost and profit efficiency of financial conglomerates and universal banks in Europe. J Money Credit Bank 34:254–282
Wang HJ, Ho CW (2010) Estimating fixed-effect panel stochastic frontier models by model transformation. J Econom 157:286–296
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Simulations
In the simulations, we assume the following data generating process (DGP):
where β0 = β1 = 1; \(x \sim U\left(0,1\right)\) for positive valued y and \(x \sim \gamma U\left(0,1\right)\) for negative valued y observations; \(v \sim U\left(0,{\sigma }_{v}^{2}\right)\); and PI is either iπ or 0. Here, iπ represents negative profits and 0 represents positive profits. We picked different distributions for x depending on the sign of y because losses may have different magnitudes compared to profits. In our benchmark setting, we set γ = 0.2. We also repeated the experiment for γ = 0.5. We considered σv = 0.1 and σv = 0.2 cases. The sample size is n = 1000 and 500 observations have negative profit and 500 observations have positive profit. We ran the Monte Carlo experiment for 500, 000 repetitions. We announce the means of parameter estimates; means of confidence intervals; empirical sizes for 5% significance level; and correlations of predicted y with true values of y. In the first column (Complex), we announce the results for our estimator; in the second column (Drop), we present results obtained when we drop observations with y < 0; in the third column (Bos-Koetter), we present results for Bos-Koetter method; and in the fourth column (Constant) we present results for the model which adds constant to y to assure that transformed y has positive values. Since the Constant method transforms y variable in a different way (i.e., \({\mathrm{ln}}\,\left(y+C\right)={\beta }_{0}+{\beta }_{1}{\mathrm{ln}}\,x+v\)), in that scenario we only examine the correlation of y by its prediction, which is given as follows:
where \(C=\min (\left|y\right|)+c\) is the adjusting constant and c = 0.01 is a small number to assure that the logarithm is evaluated at positive values. We present the simulation results in Table 6.
Based on our Monte Carlo experiment results, we see that the Complex and Drop approaches outperform the Bos-Koetter approach in terms of parameter bias and validity of empirical sizes (which must be 0.05). Similarly, these two approaches outperform the Constant approach in terms of predicting y. When γ is large so that there are observations with relatively small negative values (i.e., large C), the Constant approach seems to be much less reliable in terms of predicting y. Since the Complex approach uses all data, this approach has an advantage in terms of getting smaller confidence intervals. This is useful especially when the percentage of negative observations is large. Overall, the Complex approach may not only gives good Monte Carlo experiment results but also it has the ability to make predictions related to negative profits, which makes it a reasonable choice for empirical applications.
Appendix B: Alternative negative profit modeling
An alternative way to model negative profit is given as follows:Footnote 36
where \(y\in {\mathbb{R}}\) is the profit; \(x\in {{\mathbb{R}}}^{k}\) is a vector of explanatory variables that may or may not include interaction terms and the constant term; \(\beta \in {{\mathbb{R}}}^{k}\) is a vector parameters excluding the constant term and β0 is the constant term; and \(v\in {\mathbb{R}}\) is an i.i.d. error term with \(E\left[v\right]=0\). To differentiate the models, we call this model Alternative Complex model. Hence, depending on the sign of v, the profit can be negative or positive. When we take the logarithm of this equation, we have:
where \(\omega =\mathrm{ln}\,\left(\left|v\right|\right)-E\left[\mathrm{ln}\,\left|v\right|\right]\) is an error term with mean zero and \({\beta }_{00}={\beta }_{0}+E\left[\mathrm{ln}\,\left|v\right|\right]\) is a constant term.
One important difference between Complex model and Alternative Complex model is that the constant term in the Alternative Complex model includes β0 and \(E\left[\mathrm{ln}\,\left|v\right|\right]\). Thus, interpretation of the constant term depends on which one of these models we have in our mind. Another difference is that the Alternative Complex model does not have a dummy variable for negative profits. In practice, we may be agnostic about whether the Complex model or Alternative Complex model is the true model and include the negative profit dummy variable in the model. In this case, the constant term’s interpretation depends on which one of these models is the true model. If the value of the constant term is not important, this approach would be more robust than any one of these two models.
Rights and permissions
About this article

Cite this article
Karakaplan, M.U., Kutlu, L. & Tsionas, M.G. A solution to log of dependent variables with negative observations. J Prod Anal 54, 107–119 (2020). https://doi.org/10.1007/s11123-020-00587-5
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11123-020-00587-5