
Abstract
Mathematical models for transmission dynamics of the novel COVID-2019 coronavirus, an outbreak of which began in December, 2019, in Wuhan are considered. To control the epidemiological situation, it is necessary to develop corresponding mathematical models. Mathematical models of COVID-2019 spread described by systems of nonlinear ordinary differential equations (ODEs) are overviewed. Some of the coefficients and initial data for the ODE systems are unknown or their averaged values are specified. The problem of identifying model parameters is reduced to the minimization of a quadratic objective functional. Since the ODEs are nonlinear, the solution of the inverse epidemiology problems can be nonunique, so approaches for analyzing the identifiability of inverse problems are described. These approaches make it possible to establish which of the unknown parameters (or their combinations) can be uniquely and stably recovered from available additional information. For the minimization problem, methods are presented based on a combination of global techniques (covering methods, nature-like algorithms, multilevel gradient methods) and local techniques (gradient methods and the Nelder–Mead method).
Similar content being viewed by others


1 INTRODUCTION
In December, 2019, a pneumonia outbreak was reported in Wuhan, China, during which COVID-2019 virus was identified for the first time by analyzing nucleic acid in a patient with pneumonia. According to data from the Chinese Center for Disease Control and Prevention, the reproduction number is estimated as lying between 2 and 3, which corresponds to the number of new infections from a single infection; so long as it is greater than 1, the epidemic will grow (see Figs. 1, 2).

Number of COVID-2019 infected (blue), recovered (orange), and died (green) individuals from January 22, 2020 to February 11, 2020 over the territory of China.

A possible source of COVID-2019 virus is bats, since RNA from COVID-2019 samples was found to coincide up to 96% with virus RNA, which was earlier found in Rhinolophus affinis [1]. Virus replication occurs mainly in the lower respiratory tract, causing cytokine overproduction and an immune response in the organism that reduces the number of Т-lymphocytes in the blood, which are responsible for the protective functions of the organism [2]. As of February 11, 2020, the number of confirmed infected cases was 43 143 people, of which 1018 were deaths and 4347 were recovered people [3]. Genetically, COVID-2019 is 80% identical to severe acute respiratory syndrome (SARS), an outbreak of which was observed in China in 2003 and resulted in more than 5000 infected individuals [4] (see Table 1). However, the rate of spread of COVID-2019 is much higher than that of SARS, since, starting at January 24, the number of recorded cases in Wuhan grew from 549 to 31 728 people over 17 days (see Fig. 2).
An additional key epidemiological parameter is the incubation period, which is estimated to be 3–7 days according to WHO data. An optimal incubation period of 5.2 days was obtained in [5, 6].
On January 30, the World Health Organization declared the COVID-2019 disease outbreak a public health emergency of international concern [7].
In the context of the current situation, it is necessary to predict the epidemic evolution in China and the world. An approach to the prediction of COVID-2019 spread is the mathematical modeling of infection transmission in a population with a given infection source, transition rates between groups of people with similar characteristics (symptoms, quarantine, antibodies, strains), death rate, latent period, degree of isolation (population migration between provinces, ban on product import), and statistical data on infected and recovered individuals at fixed times. A mathematical model based on the mass balance law and described by a system of nonlinear ordinary differential equations (ODEs) most accurately describes the spread of infectious diseases in populations divided into groups of individuals with similar characteristics (for example, susceptible, infected, treated, recovered, etc.). Most of the coefficients and initial conditions for the ODEs are not known or can be estimated with a large error. For example, the number of recorder COVID-2019 cases was predicted in [8] based on data for the period of up to January 23, 2020. The predicted number on February 10, 2020, was 75 000 people, although the actual number was 40 645 individuals. Such errors in the predicted evolution of an infectious disease leads to huge costs associated with control measures and result in incorrect conclusions. To identify unknown parameters of mathematical models described by ODE systems, it is necessary to use additional information on the number of infected and recovered individuals on every day. The approach used in this work is classical for inverse problems [9]. In the next sections, we describe existing mathematical models of COVID-2019 spread, present methods for solving the arising inverse problems, and give examples of their solutions.
This paper is organized as follows. In Section 2, we present mathematical models of COVID-2019 spread and formulate inverse problems. The identifiability of a mathematical model is described in Section 3. A classification of optimization methods for solving inverse problems and the domain of their application are addressed in Section 4.
2 MATHEMATICAL MODELS OF COVID-2019 SPREAD
Mathematical epidemiology models based on a compartmental structure are described by systems of nonlinear ODEs
and characterize an isolated spread of infection within a region. An outbreak of a novel infection leads to the development of new mathematical epidemiology models, taking into account its features. One of the first models of a tuberculosis epidemic was constructed in [10] based on mathematical models in meteorology, demography, economy, and epidemiology of acute diseases. It captures the main difference of a tuberculosis epidemic from epidemic processes of acute diseases, namely, the presence of a long latent period. Later, Waaler’s model was developed by Soviet mathematicians Marchuk and his followers [11, 12]. Specifically, a mathematical model of pneumonia transmission was widely used [13].
A mathematical model of COVID-2019 transmission from a supposed source of infection (bats) to humans was developed in [1]. Since the infection source has not been traced thus far, the authors adapted a mathematical model of virus transmission from a seafood market to humans. The model is schematically shown in Fig. 3. It consists of 14 ODEs of type (1) and involves 25 coefficients φ characterizing the transition rates between 14 groups. The groups are identified according to the well-known SEIR model, which describes the dynamics of an infection between susceptible, exposed, infected, and recovered individuals. The problem of identifying unknown coefficients based on available statistical data concerning the number of infected and recovered individuals at fixed days is ill posed, i.e., its solution is neither unique nor stable [14, 15]. To use such a model for predictions, it is necessary to obtain more statistical data.

Block diagram of the mathematical source–market–people model [1].
A more detailed mathematical model of a metapopulation is based on a global network of local population groups connected by edges representing passenger traffic between cities [16]. At each node of the network, the outbreak dynamics is locally modeled using a discrete-time compartmental SEIR model similar in structure to the mathematical model of a tuberculosis epidemic of 1962 [10]. The SEIR parameters are estimated based on a five-day incubation period. It is assumed that initial COVID-2019 cases are present only in Wuhan, and border control is not taken into account.
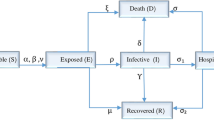
In [17] a deterministic SEIR compartmental model for the dynamics of the novel coronavirus was proposed to estimate the influence exerted by public health care control on the infection (see Fig. 4). According to the model, the outbreak had to reach its maximum on February 7, 2020, with a considerable low peak value. The proposed epidemiology SEIR model is based on eight ODEs with 12 coefficients φ, and parameter values are chosen using the method of interval generation [18]. Note that the prediction was obtained with an error, since the peak value within growth was not reached on February 12, 2020, which requires the development of more accurate methods for parameter identification for ODE systems.

Diagram of the mathematical model of COVID-2019 spread [17].
A new time-delay mathematical model for the COVID-2019 outbreak in China was proposed in [19]. The model consists of four integro-differential equations with three unknown coefficients determined by a local gradient method using additional information on the number of infected and recovered individuals over two weeks. Since the solution of the identification problem is not unique, the reliability of the numerical results is not guaranteed because of the use of local iterative methods [20, 21].
The same approach to the construction of compartmental mathematical models based on systems of nonlinear ODEs was used for other close acute infections, such the SARS outbreak of 2003 in China [22–24], Middle Eastern respiratory syndrome (MERS) in Saudi Arabia and South Korea [25], tuberculosis and HIV in Russia and Kazakhstan [26–28], etc. Despite the genome similarity of COVID-2019 to the SARS and MERS coronavirus, the course of the disease, including the incubation period, differs strongly, which prevents the application of previously developed models to the novel COVID-2019 coronavirus. The presence of a latent period in COVID-2019 is similar to mathematical models of tuberculosis dynamics, which we used to obtain a prediction verified by statistical data [26–28].
2.1 Formulation of the Inverse Problem
In view of the measures taken in China to control the epidemic, including quarantine and isolation, the population in a chosen province is divided into susceptible (S), exposed (E), asymptomatic infected (A), symptomatic infected (I), hospitalized (H), and recovered (R) individuals. Additionally, groups under quarantine are distinguished, namely, susceptible (Sq) and exposed (Eq) [17]. The diagram of the compartmental mathematical model is shown in Fig. 4. Taking into account the mass balance law, the mathematical model for ODE system (1) is written as
with initial data
The parameters of mathematical model (2) and initial data (3) in the case of Wuhan on January 10, 2020, are described in Table 2.
The mathematical model (2), (3) involves 14 unknown parameters \(p = (c,\beta ,q,\rho ,{{\delta }_{I}},{{\delta }_{q}},{{\gamma }_{I}},{{\gamma }_{A}},{{\gamma }_{H}},\alpha ,~{{E}_{0}},{{I}_{0}},{{A}_{0}},{{E}_{{{{q}_{0}}}}}) \in {{\mathbb{R}}^{{14}}}.\) \(p = (c,\beta ,q,\rho ,{{\delta }_{I}},{{\delta }_{q}},{{\gamma }_{I}},{{\gamma }_{A}},{{\gamma }_{H}},\alpha ,~{{E}_{0}},{{I}_{0}},{{A}_{0}},{{E}_{{{{q}_{0}}}}}) \in {{\mathbb{R}}^{{14}}}.\) To identify them, we formulate the inverse problem of determining the parameter vector p from available additional measurements of the number of susceptible individuals at fixed days tk:
In the vector form of (1), \(X = (S,E,I,A,{{S}_{q}},{{E}_{q}},H,R)\) and \(p = (\varphi ,~{{E}_{0}},{{I}_{0}},{{A}_{0}},{{E}_{{{{q}_{0}}}}})\). Data (4) are written as
where \({{f}_{{ik}}} = ({{S}_{k}},{{S}_{{{{q}_{k}}}}},{{H}_{k}},{{R}_{k}})\) and \(N = 8\).
In operator form, the inverse problem (2)–(4) is written as
where \(A{\kern 1pt} :Q \to F\); \(Q = \{ p \geqslant 0\} \) and F are the Hilbert spaces of feasible parameters and measurements, respectively; \(f = ({{f}_{{i1}}},{{f}_{{i2}}}, \ldots ,{{f}_{{iK}}})\) is the vector of data; and \(i = 1,5,7,8\).
In the general case, inverse problem (2)–(4) is ill posed, i.e., its solution may be nonunique or unstable (the Fréchet derivative \(A{\kern 1pt} '\) of the operator of the inverse problem has no inverse). Based on available data (4), the identifiability analysis performed in Section 3 yields a set of identifiable parameters, which are subsequently determined [14, 15, 29].
Inverse problem (2)–(4) is reduced to the minimization of the objective functional \(J(p) = \left\langle {A(p) - f,A(p) - f} \right\rangle \), which, in our case, has the form
and characterizes the standard deviation of the model results from statistical data. Finally, the inverse problem (2)–(4) is written as
A classification of methods for solving of problem (5) is given in Section 4.
3 IDENTIFIABILITY OF THE MATHEMATICAL MODEL
In certain cases, the solution of the inverse problem (2)–(4) may be nonunique or unstable with respect to the errors in measurements (4). To determine a unique set of parameters (or their combinations) and the degree of sensitivity of the unknown parameters to errors in the data of the inverse problem, the identifiability of mathematical models for ODE systems was analyzed [14, 30, 31]. Formally, the following three types of identifiability can be distinguished (see the diagram in Fig. 5).

Classification of identifiability methods [14].
1. A priori (structural) identifiability is used to study the structure of a model in the case of continuous data. The methods of structural identifiability include ones of an additional function, differential algebra, series expansions, graph theory, and others [14, 30]. For example, the graph theory method not only determines the identifiability of a model, but also allows one to find a special change of variables that brings the original model to an identifiable form.
2. Practical (a posteriori) identifiability makes it possible to reveal identifiable parameters with respect to noisy data by applying Monte Carlo techniques, the correlation matrix method, and others [14, 29].
3. Sensitivity analysis yields a sequence of parameters sensitive to measurement errors and estimates the degree of this sensitivity [14, 29].
To study the identifiability of the inverse problem (2)–(4), we used the DAISY code [31]. An analysis showed that the problem of identifying 14 parameters \(p\) from measurements (4) has a nonunique solution, i.e., the model is locally unidentifiable. When the parameter vector is reduced to \((\beta ,q,\rho ,{{\delta }_{I}},{{\delta }_{q}},{{E}_{0}},{{I}_{0}},{{A}_{0}},{{E}_{{{{q}_{0}}}}}) \in {{\mathbb{R}}^{9}}\), the mathematical model (2)–(4) becomes locally identifiable.
4 OPTIMIZATION METHODS
Formally, optimization methods can be divided into global, local, and combined ones. The first group consists of nature-like algorithms, including genetic algorithms, simulated annealing, particle swarm optimization, differential evolution, etc., as well as covering methods, for example, Evtushenko’s method of nonuniform coverings [32–34] and tensor decomposition. Global optimization methods localize the domain of an extremum and they are effective in spaces of high dimension. Local optimization methods are subdivided into two groups: order-zero methods, which use only the value of the functional (the Nelder–Mead and Hooke–Jeeves methods) and gradient methods (Gauss–Newton, Levenberg–Marquardt, etc.). A feature of local methods is high efficiency and convergence to a local extremum for gradient methods. The main disadvantage of local methods is the convergence to a local minimum, especially, in spaces of high dimension. Combined methods are based on the following idea: global optimization methods determine the domain of a global extremum, in which local methods start to refine the extremum value [26]. The formal classification of optimization methods is shown as a diagram in Fig. 6. In what follows, we outline the basic methods of three groups: global stochastic methods (Subsection 4.1), covering methods (Subsection 4.2), and local gradient-type methods (Subsection 4.3).

Classification of optimization methods for solving problem (5).
4.1 Global Stochastic Methods
The global stochastic methods include nature-like algorithms modeling natural selection processes (genetic algorithm [28, 35], the method of differential evolution, genetic programming, etc.), as well as algorithms imitating instinctive behavior in nature (particle swarm optimization, the ant algorithm) and processes in physics (simulated annealing [26]). A feature of algorithms of this type is that they solve a simpler problem based on laws of nature and do not take into account the features of the functional to which they are applied. Such algorithms can be naturally extended to parallel architectures. Although these methods are global, i.e., they determine the domain of a global extremum, there are no theoretical estimates for their convergence (only stochastic ones are available). Moreover, the tuning of parameters of nature-like algorithms to ensure statistical convergence is a complicated problem, which is sometimes more complicated than the optimization problem.
4.2 Tensor Decomposition
Covering methods need a priori information about the functional whose extremum is to be found. For example, the basic idea of nonuniform covering method [32] is that the solution space Q is partitioned into subsets covering Q. On each subset, the objective function has certain properties (for example, Lipschitz continuity, convexity, existence of a second derivative, etc.) which are used in solving optimization problems, thus improving the convergence rate.
Tensor decomposition (TD) is a global optimization method that is directly applied to parameter maximization problems [37]. It is based on the properties of the TD [37, 38]
and on the method of TD-cross approximation of the tensor \(\mathcal{T}\) [39], which constructs an approximation based on the largest elements. Here, Gi are called the TD kernels of the tensor \(\mathcal{T}\) and are matrices of size \({{r}_{{i - 1}}} \times {{r}_{i}},\) \({{r}_{0}} = {{r}_{d}} = 1,\) \({{a}_{0}} = {{a}_{d}} = 1.\)
For a large space of admissible parameters, the TD-based optimization method yields optimal parameters. Additionally, some of the computations can be executed in parallel, which makes the method a direct alternative to nature-like algorithms.
4.2.1. TD algorithm for optimization problem. Minimization problem (5) can be reduced to the maximization of the function \(g(J(p)) = \operatorname{arccot} J(p)\). We specify the set of feasible values that can be taken by \({{p}_{k}} \in [{{a}_{k}},{{b}_{k}}]\), i.e., by the components of the vector \(p = ({{p}_{1}}, \ldots ,{{p}_{d}})\), and represent them on a grid, dividing each of the intervals \([{{a}_{k}},{{b}_{k}}]\) by \(n\) nodes.
Let \({{i}_{k}}\) be an arbitrary value taken by the parameter \({{p}_{k}}\). Considering \(g(J(p))\) for all feasible combinations \(p_{k}^{{{{i}_{k}}}}\), taking into account the discrete form of the obtained response, and the representability of the multivariable functional in the form of a tensor, we obtain
The original problem is reduced to finding the largest component of the tensor \(\mathcal{T}\). Eventually, we obtain the solution of the global minimization problem in the projection onto the grid, and the result can be improved by applying local minimization.
4.3 Gradient-Type Methods
Gradient-type methods as applied to minimization problem (5) consist in successive approximation of the solution p according to the iterative process
Here, \({{\alpha }_{n}}\) is the descent parameter, the choice of which is determined by the type of the gradient method (steepest descent method, Landweber iteration, minimum errors, conjugate gradients, etc.) and \(J{\kern 1pt} '({{p}_{n}}) = 2[A{\kern 1pt} '({{p}_{n}})]{\kern 1pt} {\text{*}}(A({{p}_{n}}) - f)\) is the gradient of the objective functional \(J(p)\). The convergence of gradient methods to a normal pseudosolution and convergence acceleration techniques were addressed in [20, 40–43] (see also references therein). The following expression for the objective functional gradient \(J{\kern 1pt} '\) was obtained in [44]:
where \({\Psi }(t) = \left( {{{{\Psi }}_{1}}(t), \ldots ,{{{\Psi }}_{8}}(t)} \right)\) is the solution of the adjoint problem
Here, \({{F}_{\varphi }},~\;{{F}_{X}}\) are the corresponding Jacobian matrices and \({{[{{{\Psi }}_{i}}]}_{{t = {{t}_{k}}}}}\) is the jump in the function \({{{\Psi }}_{i}}\) at the point tk.
5 CONCLUSIONS
Mathematical models for transmission dynamics of COVID-2019, an epidemic of which broke out in Wuhan in December 2019 were presented. The models are described by systems of nonlinear ordinary differential equations, whose coefficients and initial data are unknown or their averaged values are specified. A mathematical model of COVID-2019 spread under quarantine consisting of eight nonlinear ODEs with 10 unknown coefficients and four initial conditions was considered. The identifiability of the model was analyzed using additional measurements of susceptible individuals infected under quarantine and recovered at fixed times. This inverse problem is a priori not identifiable, i.e., its solution is nonunique, but becomes identifiable when some varying parameters of the model are fixed. The problem of identifying model parameters is reduced to the minimization of a quadratic objective functional of the residual. Methods for solving the minimization problem are given based on a combination of global techniques (covering methods, nature-like algorithms, multilevel gradient methods) and local techniques (order-zero methods, gradient methods).
The model under study is similar to the mathematical model for tuberculosis transmission with control programs [26] and for coinfections of tuberculosis and HIV [29]. The combined approaches for functional optimization were found effective as applied to problems of this type. Namely, global optimization methods determine the domain of the global extremum, while local optimization methods refine solutions of the inverse problem, “starting” in the global extremum domain. Specification of parameters in models of tuberculosis transmission in Russian Federation regions allowed us to simulate the situation for several years ahead and to compare the prediction with statistical data (see Fig. 7).

Number of susceptibles SB (turquoise) under treatment without T (yellow) and with Tm (red) drug-resistant strains in the Sverdlovsk region of the Russian Federation for data over 2010–2013 with a prediction for 2014–2019 as obtained after parameter identification by simulated annealing combined with gradient descent (thin) and by tensor decomposition combined with gradient descent (thick) in thousand people. Circles denote the statistical data used to solve the parameter identification problem (red) and to verify the algorithms (color of the modelled quantity).
REFERENCES
T. Chen, J. Rui, Q. Wang, Z. Zhao, J. Cui, and L. Yin, “A mathematical model for simulating the transmission of Wuhan novel Coronavirus,” bioRxiv, https://doi.org/10.1101/2020.01.19.911669
C. Huang, Y. Wang, X. Li, L. Ren, J. Zhao, “Clinical features of patients infected with 2019 novel coronavirus in Wuhan, China,” Lancet (2020). https://doi.org/10.1016/S0140-6736(20)30183-5
Wuhan Coronavirus (2019-nCoV) Global Cases (Johns Hopkins University, 2020). https://gisanddata.maps.arcgis.com/apps/opsdashboard/index.html#/bda7594740fd40299423467b48e9ecf6
World Health Organization: SARS (2019). Accessed January 12, 2020. www.who.int/ith/diseases/sars/en/
S. Zhao, Q. Lin, J. Ran, S. S. Musa, G. Yang, W. Wang, et al., “Preliminary estimation of the basic reproduction number of novel coronavirus (2019-nCoV) in China, from 2019 to 2020: A data-driven analysis in the early phase of the outbreak,” Int. J. Infect. Dis. 92, 214–217 (2020).
J. A. Backer, D. Klinkenberg, and J. Wallinga, “Incubation period of 2019 novel coronavirus (2019-nCoV) infections among travelers from Wuhan, China, January 20–28, 2020,” Euro Surveill. 25 (5) 2000062 (2020).
World Health Organization. Novel Coronavirus (2019-nCoV). Situation Report 10. January 30, 2020.
W. Ming, J. Huang, and C. J. P. Zhang, Breaking down of healthcare system: Mathematical modelling for controlling the novel coronavirus (2019-nCoV) outbreak in Wuhan, China. bioRxiv, https://doi.org/10.1101/2020.01.27.922443
S. I. Kabanikhin, “Definitions and examples of inverse and ill-posed problems,” J. Inverse Ill-Posed Probl. 16, 317–357 (2008).
H. T. Waaler, A. Geser, and S. Andersen, “The use of mathematical models in the study of the epidemiology of tuberculosis,” Am. J. Publ. Health 52, 1002–1013 (1962).
G. I. Marchuk, Mathematical Models in Immunology: Computational Methods and Experiments (Nauka, Moscow, 1991) [in Russian].
M. I. Perelman, G. I. Marchuk, S. E. Borisov, B. Ya. Kazennukh, K. K. Avilov, A. S. Karkach, and A. A. Romanyukha, “Tuberculosis epidemiology in Russia: The mathematical model and data analysis,” Russ. J. Numer. Anal. Math. Model. 19 (4), 305–314 (2004).
G. I. Marchuk, et al., “Application of mathematical analysis methods for evaluating the severity of clinical conditions, efficacy of treatment, and prediction and detection of complications in acute pneumonia,” Terapevt. Arkh. 53 (3), 3–9 (1981).
H. Miao, X. Xia, A. S. Perelson, and H. Wu, “On identifiability of nonlinear ODE models and applications in viral dynamics,” SIAM Rev. Soc. Ind. Appl. Math. 53 (1), 3–39 (2011).
S. I. Kabanikhin, D. A. Voronov, A. A. Grodz, and O. I. Krivorotko, “Identifiability of mathematical models in medical biology,” Russ. J. Genet. Appl. Res. 6 (8), 838–844 (2016).
A. Zlojutro, D. Rey, and L. Gardner, “Optimizing border control policies for global out-break mitigation,” Sci. Rep. 9, 2216 (2019).
B. Tang, X. Wang, Q. Li, N. L. Bragazzi, S. Tang, Y. Xiao, and J. Wu, “Estimation of the transmission risk of 2019-nCoV and its implication for public health interventions,” SSRN. https://ssrn.com/abstract=3525558
L. F. White and M. Pagano, “A likelihood-based method for real-time estimation of the serial interval and reproductive number of an epidemic,” Stat. Med. 27, 2999–3016 (2008).
Y. Chen, J. Cheng, Y. Jiang, and K. Liu, “A time delay dynamical model for outbreak of 2019-nCoV and the parameter identification,” J. Inverse Ill-Posed Probl. 28 (2), 243–250 (2020).
B. Kaltenbacher, A. Neubauer, and O. Scherzer, Iterative Regularization Methods for Non-linear Ill-Posed Problems (De Gruyter, Berlin, 2008).
H. T. Banks, Sh. Hu, and W. C. Thompson, Modeling and Inverse Problems in the Presence of Uncertainty (CRC, Boca Raton, 2014).
X. Han, S. J. de Vlas, L. Fang, D. Feng, W. Cao, and J. D. F. Habbema, “Mathematical modelling of SARS and other infectious diseases in China: A review,” Tropical Medicine Int. Health 14 (1), 91–100 (2009).
J. Zhang, J. Lou, Z. Ma, and J. Wu, “A compartmental model for the analysis of SARS transmission patterns and outbreak control measures in China,” Appl. Math. Comput. 162, 909–924 (2005).
R. G. McLeod, J. F. Brewster, A. B. Gumel, and D. A. Slonowsky, “Sensitivity and uncertainty analyses for a SARS model with time-varying inputs and outputs,” Math. Bio-sci. Eng. 3 (3), 527–544 (2006).
M. Tahir, S. I. A. Shah, G. Zaman, and T. Khan, “Stability behavior of mathematical model MERS corona virus spread in population,” Filomat 33 (12), 3947–3960 (2019).
S. Kabanikhin, O. Krivorotko, and V. Kashtanova, A combined numerical algorithm for reconstructing the mathematical model for tuberculosis transmission with control programs. J. Inverse Ill-Posed Probl. 26 (1), 121–131 (2018).
S. I. Kabanikhin, O. I. Krivorotko, D. V. Ermolenko, V. N. Kashtanova, and V. A. Latyshenko, “Inverse problems of immunology and epidemiology,” Eurasian J. Math. Comput. Appl. 5 (2), 14–35 (2017).
S. Kabanikhin, O. Krivorotko, A. Takuadina, D. Andornaya, and S. Zhang, “Geo-information system of spread of tuberculosis based on inversion and prediction,” (2002). arXiv:2002.02367 [q-bio.PE]
V. Latyshenko, O. Krivorotko, S. Kabanikhin, Sh. Zhang, V. Kashtanova, and D. Yermolenko, “Identifiability analysis of inverse problems in biology,” Proceedings of the 2nd International Conference on Computational Modeling, Simulation, and Applied Mathematics (2017), pp. 567–571.
R. Bellman and K. Åström, “On structural identifiability,” Math. Biosci. 30 (4), 65–74 (1970).
G. Bellu, M. P. Saccomani, S. Audoly, and L. D’Angiò, “DAISY: A new software tool to test global identifiability of biological and physiological systems,” Comput. Methods Programs Biomed. 88 (1), 52–61 (2007).
Yu. G. Evtushenko, “Numerical methods for finding global extrema (case of a nonuniform mesh),” Comput. Math. Math. Phys. 11 (6), 38–54 (1971).
Yu. G. Evtushenko and M. A. Posypkin, “Nonuniform covering method as applied to multicriteria optimization problems with guaranteed accuracy,” Comput. Math. Math. Phys. 53 (2), 144–157 (2013).
Yu. G. Evtushenko, M. A. Posypkin, L. A. Rybak, and A. V. Turkin, “Finding sets of solutions to systems of nonlinear inequalities,” Comput. Math. Math. Phys. 57 (8), 1241–1247 (2017).
H. T. Banks, S. I. Kabanikhin, O. I. Krivorotko, and D. V. Yermolenko, “A numerical algorithm for constructing an individual mathematical model of HIV dynamics at cellular level,” J. Inverse Ill-Posed Probl. 26 (6), 859–873 (2018).
V. Zheltkova, D. Zheltkov, Z. Grossman, G. A. Bocharov, and E. E. Tyrtyshnikov, “Tensor based approach to the numerical treatment of the parameter estimation problems in mathematical immunology,” J. Inverse Ill-Posed Probl. 26 (1), 51–66 (2017).
I. V. Oseledets and E. E. Tyrtyshnikov, “Breaking the curse of dimensionality, or how to use SVD in many dimensions,” SIAM J. Sci. Comput. 31, 3744–3759 (2009).
I. V. Oseledets, “Tensor-train decomposition,” SIAM J. Sci. Comput. 33, 2295–2317 (2011).
E. E. Tyrtyshnikov, “Incomplete cross approximation in the mosaic-skeleton method,” Computing 64, 367–380 (2000).
O. M. Alifanov, E. A. Artuhin, and S. V. Rumyantsev, Extreme Methods for the Solution of Ill-Posed Problems (Nauka, Moscow, 1988) [in Russian].
V. V. Vasin, “On the convergence of gradient-type methods for nonlinear equations,” Dokl. Math. 57 (2), 173–175 (1998).
A. S. Nemirovskii, “The regularizing properties of the adjoint gradient method in ill-posed problems,” USSR Comput. Math. Math. Phys. 26 (2), 7–16 (1986).
A. V. Gasnikov, Modern Numerical Optimization Methods: Universal Gradient Descent Method (Mosk. Fiz.-Tekh. Inst., Moscow, 2018) [in Russian].
S. I. Kabanikhin and O. I. Krivorotko, “Identification of biological models described by systems of nonlinear differential equations,” J. Inverse Ill-Posed Probl. 23 (5), 519–527 (2015).
Funding
This work was supported by the Mathematical Center in Akademgorodok and the Ministry of Science and Higher Education of the Russian Federation, contract no. 075-15-2019-1675.
Author information
Authors and Affiliations
Corresponding author
Additional information
Translated by I. Ruzanova
Rights and permissions
About this article

Cite this article
Kabanikhin, S.I., Krivorotko, O.I. Mathematical Modeling of the Wuhan COVID-2019 Epidemic and Inverse Problems. Comput. Math. and Math. Phys. 60, 1889–1899 (2020). https://doi.org/10.1134/S0965542520110068
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1134/S0965542520110068