
Abstract
Early forecasting of COVID-19 virus spread is crucial to decision making on lockdown or closure of cities, states or countries. In this paper we design a recursive bifurcation model for analyzing COVID-19 virus spread in different countries. The bifurcation facilitates recursive processing of infected population through linear least-squares fitting. In addition, a nonlinear least-squares fitting procedure is utilized to predict the future values of infected populations. Numerical results on the data from two countries (South Korea and Germany) indicate the effectiveness of our approach, compared to a logistic growth model and a Richards model in the context of early forecast. The limitation of our approach and future research are also mentioned at the end of this paper.
Similar content being viewed by others

Introduction
Coronavirus disease (COVID-19) is a novel respiratory illness that originated in 2019 and can spread from person to person, as defined by Centers for Disease Control and Prevention (CDC)1. The first incidence of such disease was publicly reported to World Health Organization (WHO) as an outbreak in Wuhan, China, on 31 December 20192,3. It was assumed on an association with the consumption of wild animals sold at Huanan Seafood Wholesale Market4,5. So far, the original source of this disease has not been clearly identified and the disease is continuously spread in over 70 countries. Reverse polymerase chain reactions and genome sequencing were used for diagnostics and therapeutics measures6. COVID-19 is a member of coronavirus family, and it is contagious among humans and animals7. Coronaviruses are a group of RNA viruses; the earliest study on animal coronavirus was reported in the late 1920s8, and human coronavirus was first studied by Kendall, Bynoe and Tyrell in 1960s through extracting the viruses from patients who suffered from common colds9,10. The genome size of coronaviruses ranges between 26 and 32 kilobases11. The viruses have characteristic club-shaped spikes projected from their surface, and the surface morphology of the viruses resembles a solar corona12. The viruses can be further categorized into gamma, beta, delta and alpha coronaviruses13. Beta and alpha coronaviruses originate from bats, while gamma and delta coronaviruses spread among birds and pigs14. COVID-19 is a member of beta category, which is associated with severe diseases. The genome structure of COVID-19 is 96% similar to that of bat coronaviruses15,16. It is still not clear about the exact route of the virus jump from bats to humans.
COVID-19 had a profound impact on global social and economic development17. It caused severe demographic changes and extremely high unemployment rates with many economic activities being halted. This extraordinary event brought about some unintended consequences such as the violation of international law on the settlement of refugees due to border closure18.
Different governments and health officials have introduced various preventive measures to curb the COVID-19 virus spread, including hand sanitizers, gloves, masks, social distance, and geographical closure17. Although the geographical closure led to temporary urban air quality improvement, lockdown of towns, cities, states, and countries causes severe damage to the well-being and economic growth of society in a broad sense, and the virus poses a major threat to the international healthcare system19. The unknown nature about the peak of virus spread makes the decision of lockdown or closure a difficult task to plan in advance. This calls for an accurate early forecasting model for the ongoing spread of COVID-19 virus.
Literature review
Many studies have been carried out on the epidemic investigation of COVID-19 spread. The first category of studies is a pure statistical analysis. Important epidemic parameters were estimated20,21, including basic reproduction number22, doubling time23 and serial interval24. In addition, some advanced models were developed in handling untraced contacts25, undetected international cases26, and actual infected cases27. Statistical reasoning28,29 and stochastic simulation30,31 were also explored by a few researchers.
The second group of investigations was based on dynamic modelling. Susceptible exposed infectious recovered model (SEIR) was used in assessing various measures in the COVID-19 outbreak32,33,34,35. Furthermore, it was utilized in investigating the effect of lockdown36, transmission process37, transmission risk32, and the effect of quarantine32. The SEIR model with time delays was also developed for studying the period of incubation and recovery38,39.
Richards40 developed a flexible growth function for empirical use in the context of plant data based on von Bertalanffy’s growth function41, which was originally designed for animals. This model was later used for fitting the single-phase outbreaks of severe acute respiratory syndrome (SARS) in Hong Kong42 and Taiwan43 as well as a multi-phase outbreak of SARS in Toronto44. The Georgia State group45 recently studied short-term forecasts of the COVID-19 epidemic in Guangdong and Zhejiang, China between February 13 and 23, 2020 via a generalized logistic growth model46, the Richards model, and a sub-epidemic model47. As an extension to a logistic growth model, the Richards mode can be described by a single differential equation:
where P(t) represents the cumulative number of infected cases at time point t, r denotes a growth rate, K refers to the maximum asymptote, and a is a scaling parameter. One solution of Eq. (1) is
where \(t_{0}\) is the time value of the sigmoid’s midpoint. When a = 1, this model is degenerated into a simple logistic growth mode with three parameters [K, r, \(t_{0}\)]. Equation (2) represents a four-parameter model [a, K, r, \(t_{0}\)] and other variations of the Richards model could consist of up to 6 parameters. In this paper, our comparison and discussion are limited to Eq. (2).
Although there have been many recent studies with respect to the COVID-19 virus spread, an accurate forecasting model for the virus spread based on data at a very early time point is still elusive. Such a model is crucial to a decision-making process for strategic plans to achieve a balance between reduction in life loss and avoidance of economic crisis due to lockdown. In this paper, we develop a new recursive bifurcation model, apply it to the recent data in two countries (South Korea and Germany), and compare it with a simple logistic growth model and the Richards model in the context of COVID-19 virus spread.
The rest of this paper is organized as follows. In “Recursive bifurcation model”, a recurve bifurcation model is introduced to model the COVID-19 spread. A bifurcation analysis is given in “Bifurcation analysis of COVID-19 virus spread” on the data of infected population in South Korea. “Early forecasting of COVID-19 virus spread” describes the forecasting of COVID-19 virus spread based on our model and a comparative study with two existing models, followed by some concluding remarks in “Conclusions”.
Recursive bifurcation model
In this paper, we focus on the cumulative number of infected population, which is an important metric to measure the extent of the COVID-19 spread in different countries. Although the infected population in most countries follows a pattern of a logistic or sigmoid function, the logarithm of the infected population may provide more information, as shown in Fig. 1b.

The number of infected population in South Korea as of April 5, 2020.
The countries, in which a bifurcation pattern occurred, include South Korea, Germany, United States, France, Canada, Australia, Malaysia, and Ecuador. Figure 2 shows the pattern in the last 5 countries of the list. The detailed information of Germany and United States data are given in “Early forecasting of COVID-19 virus spread”. By utilizing the bifurcation, we can find out the intrinsic parameters (such as growth rate) in cycle 1 and apply those parameters in the prediction for cycle 2 or beyond. More importantly, the bifurcation model performs better than the Richards model in the early forecasting of COVID-19 virus spread. A more detailed discussion about this improvement is provided in “Early forecasting of COVID-19 virus spread”.

A bifurcation pattern of the infected population of COVID-19 virus spread in five countries.
Following the above idea, we introduce a recursive Tanh function to describe the cumulative number of infected population within each cycle of an entire virus spread process:
where i refers to the i-th cycle, P is the cumulative number of infected population at any time point in the i-th cycle, D represents the number of days since the initiation of virus spread, \(P_{i - 1}\) stands for the cumulative number of infected population at the end of the (i − 1)-th cycle, \(r_{i}\) is the spread rate in the i-th cycle, and \(D_{i - 1}\) refers to the number of days at the end of the (i − 1)-th cycle. The purpose of adding 1 in the logarithm calculation is to avoid an infinity caused by the case where P = 0.
Note that Eq. (3) is not strictly a recursive formula in a conventional sense. The reason for us to call it as a recursive one is that Eq. (3) should be recursively solved starting from cycle 1 toward cycle n, if n is the last cycle for the virus spread. When n = 1, this equation is degenerated to a regular Tanh function:
Bifurcation analysis of COVID-19 virus spread
In order to validate Eq. (3) for the analysis of COVID-19 virus spread, we have to select a complete virus spread process. Among all the countries, South Korea seems to be the best choice for this validation because the country provides reasonably reliable data and the virus spread in that country has been stabilized.
\(r_{i}\) in Eq. (3) represents an intrinsic attribute of the virus spread rate. It can be estimated by a linear least-squares fit of the following linear equation in a parameter space:
where \(X = D - D_{i}\) and \( W = - 0.5 ln \left[ {\frac{2}{{1 + \frac{{log\left( {P + 1} \right) - log\left( {P_{i - 1} + 1} \right)}}{{log\left( {P_{i} + 1} \right) - log\left( {P_{i - 1} + 1} \right)}}}} - 1} \right]\).
Figure 3a shows the result of determining the virus spread rate, \(r_{1}\). By using this r value, we predict the infected population, \(y_{p}\), which is very close to the true data, y, as shown in Fig. 3b.

Determination of virus spread rate with South Korea data in cycle 1.
Furthermore, by using \(r_{1}\) in cycle 2 of South Korea data, we want to validate whether Eq. (3) is still valid by introducing Eq. (6), and \(\alpha\) should be unity (Fig. 4):
where \(y = log\left( {P + 1} \right) - log\left( {P_{i - 1} + 1} \right)\) and \(Z = \left( {log\left( {P_{i} + 1} \right) - log\left( {P_{i - 1} + 1} \right)} \right)\left[ {\frac{2}{{1 + e^{{ - 2r_{i} \left( {D - D_{i - 1} } \right)}} }} - 1} \right]\).

Analysis of virus spread with South Korea data in cycle 2.
Based on Fig. 4, \(\alpha = 0.968\), which is very close to unity. This indirectly indicates the correctness of Eq. (3) for cycle 2 with growth rate, \(r_{1}\), from cycle 1. The bifurcation in Fig. 1a is easy to identify visually. An automatic algorithm can be created on the basis of discontinuity of tangential direction with a traverse on the curve. Since it is not the main focus of this paper, we do not explore this aspect any further herein.
Early forecasting of COVID-19 virus spread
Based on the model in “Bifurcation analysis of COVID-19 virus spread”, we design an algorithm for early forecasting of COVID-19 virus in South Korea and Germany, as given in Table 1. Since the infected population has recently been stabilized in these two countries, it is then possible to validate the accuracy of this early forecasting model.
We first use the following formula to estimate \(\hat{\beta }_{n}\) through a linear least-squares fit:
where \(y = log\left( {P + 1} \right) - log\left( {P_{n - 1} + 1} \right)\) and \(Z = \left[ {\frac{2}{{1 + e^{{ - 2r_{n} \left( {D - D_{n - 1} } \right)}} }} - 1} \right]\).
Nonlinear Levenberg-Marquart least-squares fitting48 is computed to determine three unknown parameters (\(\beta_{n}\), \(\theta_{n}\,and\,D_{n}\)) simultaneously in the following equation for future forecasting:
where \(\theta_{n} \) is an extra parameter, which plays a role of slope control. Once \(\beta_{n}\), \(\theta_{n}\) and \(D_{n}\) are determined, Eq. (8) can be used to predict the values of infected population at future time points.
Figure 5a defines several different time points to investigate the performance of early forecast on the “future” infected population. Here, the “future” is termed only in a sense with respect to a selected time point (i.e., a reference point after which the “future” is factitiously defined) even though we already have the true infected population data for a period after that time point. \(t_{i}\) refers to the time value of the inflection point. \(0.9t_{i}\), \(0.8t_{i}\), \(...,\) and 0 equally divide the range [0, \(t_{i}\)] into ten intervals. We use a similar interval for time values that are greater than \(t_{i}\): \(1.1t_{i}\), \(1.2t_{i}\), \(...,\) and \(mt_{i}\), where \(m\) could be any real number and should be greater than unity.

Notations for early forecast on future infected population.
It is shown in Fig. 5b that the infection point, \(t_{i}\), appeared 12 days later than the cycle transition point, \(t_{c}\), between cycles 1 and 2 on South Korea data; a similar pattern was also observed in U.S., Germany and the countries listed in Fig. 2. This provides a better opportunity for our bifurcation method to produce an early forecast, compared to existing methods such as the Richards method, which generates a reasonably good prediction only at a time point after the inflection point because the right part of a curve after the inflection point can’t normally be mirrored from the left part of the curve before the inflection point. In the case of Germany data (Fig. 5c), \(t_{c}\) appeared 38 days earlier than \(t_{i}\). This provides an opportunity for our bifurcation method to utilize the cycle information for early forecast on the COVID virus spread.
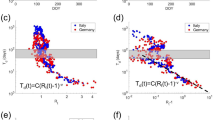
Tables 2 and 3 are a comparison in the 95 percent confidence interval of prediction errors of three models at a reference time point defined in Fig. 5a. The second column of these tables contains a mean value and 95 percent confidence bounds in a pair of parentheses. In general, our bifurcation model performs relatively better for an early forecast at 0.8 \(T_{i}\) or 0.9 \(T_{i}\). The forecast time point was selected to a date of writing this paper. Between the Richards model and a simple logistic growth model, the former is better in terms of relative error in one out of two cases. Since there are at least 4 parameters [a, K, r, \(t_{0}\)] in the Richards model, closely-estimated start values are needed in nonlinear least-squares fitting. Figure 6 shows the curve fitting of two-country data based on the three models used in this paper. The parameters associated with each model are given in Table 4.

Curve fitting of two-country data at their respective reference time points with three different models.
Note that for the data from South Korea and Germany, there is no multi-stage pattern if the simple logistic growth model or the Richards model is used. Only through the special treatment in our bifurcation model, did a two-stage pattern appear, allowing a more accurate forecast at an early time point (such as 0.8 \(T_{i} \) or 0.9 \(T_{i}\)) on the infected population growth at a later time point (for example, 2.0 \(T_{i}\)).
The importance of our model is supported by the results in Tables 2 and 3, where our model performs significantly better than the existing models in terms of early forecast on the growth of COVID-19 virus spread. Consequently, our model has a potential to be used in decision making for the events of virus spread in the future.
The data from United States presents a challenge to our approach and also reflects a limitation of the method. As shown in Fig. 7a, for the period from January 22, 2020 to April 17, 2020, there was no inflection point and our cycle transition point appeared very early (Day 33). This case indicates that the cycle transition point appeared at least 52 days earlier than the inflection point. However, since the inflection point did not appear even on August 3, 2020 (Fig. 7b), it is difficult to validate the accuracy of any early forecasting models on U.S. data at the time of writing this paper. It is still elusive how to design and evaluate an early forecasting model when the entire virus spread history is at its early stage without the occurrence of its inflection point. This will be a future research topic.

Infected population data of COVID-19 in United States.
Conclusions
In this paper, we propose a recursive bifurcation approach for early forecasting of COVID-19 virus spread. An algorithm is developed to predict the future infected population based on ongoing existing data as of June 14, 2020. Numerical analyses were conducted in comparison with two existing models (a logistic growth model and a Richards model). The results indicate that our bifurcation model performs relatively better than the two existing models at 0.8 \(T_{i} \) or 0.9 \(T_{i}\) time point, where \(T_{i} \) refers to the inflection point of an infected population-time curve. We presented an important observation in which the cycle transition time point, \(T_{c}\), appeared much earlier than \(T_{i}\). This allows our bifurcation model to perform well in the early forecasting of COVID-19 virus spread in South Korea and Germany. However, the ongoing infection spread in United States presents a challenge to our model. It will be a future research topic on how to evaluate the forecasting of COVID-19 infection spread when its inflection point has not occurred as of August 3, 2020.
Data availability
The dataset of this article has been published at Harvard Dataverse with the following link: Shen, Julia, 2020, “Recursive Bifurcation Model for COVID-19 Virus Spread”, https://doi.org/10.7910/DVN/PVCPWM, Harvard Dataverse, V1.
References
CDC. What you need to know about coronavirus disease 2019 (COVID-19). (Centers for Disease Control and Prevention (cdc.gov/COVID19), Atlanta, 2020).
CGTN. 27 cases of viral pneumonia reported in central China's Wuhan City. (2020). https://news.cgtn.com/news/2019-12-31/Authorities-begin-testing-after-pneumonia-cases-in-central-China-MRPvtFbCve/index.html.
World Health Organization. Novel coronavirus. (2020). https://web.archive.org/web/20200122103944/https://www.who.int/westernpacific/emergencies/novel-coronavirus.
Xu, Z. et al. Pathological findings of COVID-19 associated with acute respiratory distress syndrome. Lancet Respir. Med. 8(4), 420–422 (2020).
Sun, J. et al. COVID-19: Epidemiology, evolution, and cross-disciplinary perspectives. Trends Mol. Med. 26(5), 483–495 (2020).
Wang, D. et al. Clinical characteristics of 138 hospitalized patients with 2019 novel coronavirus–infected pneumonia in Wuhan, China. JAMA 323(11), 1061–1069 (2020).
Kooraki, S., Hosseiny, M., Myers, L. & Gholamrezanezhad, A. Coronavirus (COVID-19) outbreak: What the department of radiology should know. J. Am. Coll. Radiol. 17(4), 447–451 (2020).
Estola, T. Coronaviruses, a new group of animal RNA viruses. Avian Dis. 14(2), 330–336 (1970).
Tyrrell, D. A. J. & Bynoe, M. L. Cultivation of viruses from a high proportion of patients with colds. Lancet 1, 76–77 (1966).
Kendall, E. J., Bynoe, M. L. & Tyrrell, D. A. Virus isolations from common colds occurring in a residential school. BMJ 2(5297), 82–86 (1962).
Woo, P. C., Huang, Y., Lau, S. K. & Yuen, K. Y. Coronavirus genomics and bioinformatics analysis. Viruses. 2(8), 1804–1820 (2010).
Almeida, J. D. et al. Virology: Coronaviruses. Nature 220(5168), 650 (1968).
Carstens, E. B. Ratification vote on taxonomic proposals to the International Committee on Taxonomy of Viruses. Adv. Virol. 155(1), 133–146 (2009).
Ather, A., Patel, B., Ruparel, N. B., Diogenes, A. & Hargreaves, K. M. Coronavirus disease 19 (COVID-19): Implications for clinical dental care. J. Endod. 46(5), 584–595 (2020).
Kucharski, A. J. et al. Early dynamics of transmission and control of COVID-19: A mathematical modelling study. Lancet. Infect. Dis 20(5), 553–558 (2020).
Cao, Y. C., Deng, Q. X. & Dai, S. X. Remdesivir for severe acute respiratory syndrome coronavirus 2 causing COVID-19: An evaluation of the evidence. Travel Med. Infect. Dis. 35, 101647-1-101647–6 (2020).
Bashir, M. F., Benjiang, M. A., & Shahzad, L. A brief review of socio-economic and environmental impact of Covid-19. Air Qual. Atmos. Health. 1–7. https://doi.org/10.1007/s11869-020-00894-8 (2020).
Ni Ghrainne, B. Covid-19, border closure, and international law. SSRN. https://doi.org/10.2139/ssrn.3662218 (2020).
Meo, S. A. et al. Biological and epidemiological trends in the prevalence and mortality due to outbreaks of novel coronavirus COVID-19. J. King Saud Univ. Sci. 32(4), 2495–2499 (2020).
Sanche, S. et al. The novel coronavirus 2019-ncov is highly contagious and more infectious than initially estimated. medRxiv. (2002.03268) (2020).
Lai, S. et al. Assessing spread risk of Wuhan novel coronavirus within and beyond China, January-April 2020: A travel network-based modelling study. medRxiv https://doi.org/10.1101/2020.02.04.20020479 (2020).
Zhao, S. et al. Preliminary estimation of the basic reproduction number of novel coronavirus (2019-ncov) in China, from 2019 to 2020: A data-driven analysis in the early phase of the outbreak. Int. J. Infect. Dis. 92, 214–217 (2020).
Muniz-Rodriguez, K. et al. Epidemic doubling time of the 2019 novel coronavirus outbreak by province in mainland China. medRxiv https://doi.org/10.1101/2020.02.05.20020750 (2020).
Nishiura, H., Linton, N. M. & Akhmetzhanov, A. R. Serial interval of novel coronavirus (2019-ncov) infections. Int. J. Infect. Dis. 93(2020), 284–286 (2020).
Nishiura, H. et al. The extent of transmission of novel coronavirus in Wuhan, China, 2020. J. Clin. Med. 9(2), 330-1-330–5 (2020).
De Salazar, P. M., Niehus, R., Taylor, A., Buckee, C. O. & Lipsitch, M. Using predicted imports of 2019-ncov cases to determine locations that may not be identifying all imported cases. medRxiv. https://doi.org/10.1101/2020.02.04.20020495 (2020).
Zhao, H., Man, S., Wang, B. & Ning, Y. Epidemic size of novel coronavirus-infected pneumonia in the epicenter Wuhan: Using data of five-countries’ evacuation action. medRxiv. https://doi.org/10.1101/2020.02.12.20022285 (2020).
Chinazzi, M. et al. The effect of travel restrictions on the spread of the 2019 novel coronavirus (2019-ncov) outbreak. medRxiv https://doi.org/10.1101/2020.02.09.20021261 (2020).
Jin, C., Yu, J., Han, L. & Duan, S. The impact of traffic isolation in Wuhan on the spread of 2019-nov. medRxiv. https://doi.org/10.1101/2020.02.04.20020438 (2020).
Hellewell, J. et al. Feasibility of controlling 2019-ncov outbreaks by isolation of cases and contacts. Lancet Glob. Health. 8(4), e488–e496 (2020).
Quilty, B., Clifford, S., Flasche, S. & Eggo, R. M. Effectiveness of airport screening at detecting travellers infected with 2019-ncov. Eurosurveillance. 25(5), 1–6 (2020).
Tang, B. et al. An updated estimation of the risk of transmission of the novel coronavirus (2019-ncov). Infect. Dis. Model. 5(2020), 248–255 (2020).
Shen, M., Peng, Z., Guo, Y., Xiao, Y. & Zhang, L. L. Lockdown may partially halt the spread of 2019 novel coronavirus in Hubei province, China. medRxiv. https://doi.org/10.1101/2020.02.11.20022236 (2019).
Clifford, S. J. et al. Interventions targeting air travellers early in the pandemic may delay local outbreaks of sars-cov-2. medRxiv. https://doi.org/10.1101/2020.02.12.20022426 (2020).
Xiong, H. & Yan, H. Simulating the infected population and spread trend of 2019-ncov under different policy by EIR model. medRxiv. https://doi.org/10.1101/2020.02.10.20021519 (2020).
Li, X., Zhao, X. & Sun, Y. The lockdown of Hubei province causing different transmission dynamics of the novel coronavirus (2019-ncov) in Wuhan and Beijing. medRxiv. https://doi.org/10.1101/2020.02.09.20021477 (2020).
Chen, T. et al. A mathematical model for simulating the transmission of Wuhan novel coronavirus. bioRxiv. https://doi.org/10.1101/2020.01.19.911669 (2020).
Yue, Y. et al. Modeling and prediction for the trend of outbreak of NCP based on a time-delay dynamic system. Sci. Sin. Math. 50(3), 1–8 (2020).
Chen,Y., Cheng,J., Jiang,Y., & Liu,K. A time delay dynamical model for outbreak of 2019-ncov and the parameter identification. medRxiv. arXiv:2002.00418 (2020).
Richards, F. J. A flexible growth function for empirical use. J. Exp. Bot. 10(2), 290–301 (1959).
von Bertalanffy, L. Quantitative laws in metabolism and growth. Q. Rev. Biol. 32(3), 217–231 (1957).
Zhou, G. & Yan, G. Severe acute respiratory syndrome epidemic in Asia. Emerg. Infect. Dis. 9(12), 1608–1610 (2003).
Hsieh, Y. H., Lee, J. Y. & Chang, H. L. SARS epidemiology modeling. Emerg. Infect. Dis. 10(6), 1165–1167 (2004).
Hsieh, Y. H. & Cheng, Y. S. Real-time forecast of multiphase outbreak. Emerg. Infect. Dis. 12(1), 122–127 (2006).
Roosa, K. et al. Short-term forecasts of the COVID-19 epidemic in Guangdong and Zhejiang, China: February 13–23, 2020. J. Clin. Med. 9(2), 596–604 (2020).
Viboud, C., Simonsen, L. & Chowell, G. A generalized-growth model to characterize the early ascending phase of infectious disease outbreaks. Epidemics. 15(2016), 27–37 (2016).
Chowell, G., Tariq, A. & Hyman, J. M. A novel sub-epidemic modeling framework for short-term forecasting epidemic waves. BMC Med. 17(164), 1–18 (2019).
Press, W. H., Teukolsky, S. A., Vetterling, W. T. & Flannery, B. P. Numerical Recipes in C: The Art of Scientific Computing (Cambridge University Press, Cambridge, 1992).
Acknowledgements
All the ground truth data of infected populations were obtained from the Coronavirus Resource Center of Johns Hopkins University. The valuable comments from three anonymous reviewers are sincerely appreciated for helping us in improving the quality of this article. The author would also like to express her gratitude to the research office at Dartmouth College for covering the publication fee of this article.
Author information
Authors and Affiliations
Contributions
The first author is responsible for the design of the method and numerical analysis of test data.
Corresponding author
Ethics declarations
Competing interests
The author declares no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Shen, J. A recursive bifurcation model for early forecasting of COVID-19 virus spread in South Korea and Germany. Sci Rep 10, 20776 (2020). https://doi.org/10.1038/s41598-020-77457-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-020-77457-5
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
