Parameter Estimation and Hypothesis Testing of Multivariate Poisson Inverse Gaussian Regression


Department of Statistics, Faculty of Science and Data Analytics, Institut Teknologi Sepuluh Nopember (ITS), Jawa Timu 60111, Indonesia
*
Author to whom correspondence should be addressed.
Symmetry 2020, 12(10), 1738; https://doi.org/10.3390/sym12101738
Submission received: 3 September 2020
/
Revised: 14 October 2020
/
Accepted: 16 October 2020
/
Published: 20 October 2020
(This article belongs to the Section Mathematics)
Abstract
:Multivariate Poisson regression is used in order to model two or more count response variables. The Poisson regression has a strict assumption, that is the mean and the variance of response variables are equal (equidispersion). Practically, the variance can be larger than the mean (overdispersion). Thus, a suitable method for modelling these kind of data needs to be developed. One alternative model to overcome the overdispersion issue in the multi-count response variables is the Multivariate Poisson Inverse Gaussian Regression (MPIGR) model, which is extended with an exposure variable. Additionally, a modification of Bessel function that contain factorial functions is proposed in this work to make it computable. The objective of this study is to develop the parameter estimation and hypothesis testing of the MPIGR model. The parameter estimation uses the Maximum Likelihood Estimation (MLE) method, followed by the Newton–Raphson iteration. The hypothesis testing is constructed using the Maximum Likelihood Ratio Test (MLRT) method. The MPIGR model that has been developed is then applied to regress three response variables, i.e., the number of infant mortality, the number of under-five children mortality, and the number of maternal mortality on eight predictors. The unit observation is the cities and municipalities in Java Island, Indonesia. The empirical results show that three response variables that are previously mentioned are significantly affected by all predictors.
1. Introduction
The relationship between predictor variables and Poisson distributed response variables can be analyzed while using Poisson regression. However, some cases cannot deal with the assumption in Poisson regression, namely equidispersion, which indicates that the mean is equal to the variance of the response variable. In real data, the variance can be larger than the mean (overdispersion). Thus, a proper model for analyzing such a kind of data needs to be developed. Multivariate data consists of two or more correlated response variables. The researchers have conducted several studies in the univariate Poisson regression, but the development of multivariate Poisson regression is still lacking [1].
The Poisson Inverse Gaussian Regression (PIGR) model is one of the alternative models to overcome the overdispersion issue. This model is built from mixed Poisson distribution, which is a combination of the Poisson distribution and the inverse Gaussian distribution. The PIG distribution was firstly introduced by Holla in 1996, with the characteristics of count data having a high initial value and considerably skewed to the right curve [2]. The univariate IGPR models have been widely utilized in previous studies [3,4,5,6,7,8]. Otherwise, there are few studies of the Multivariate Poisson Inverse Gaussian Regression (MPIGR) model. Ghitany et al. (2012) previously discussed research on the MPIGR model. That study examined several multivariate mixed Poisson regression models and their application. Parameter estimation was done using the MLE method by the Expectation and Maximization (EM) algorithm [9].
This study extends the MPIGR model by adding an exposure variable. Furthermore, the third modification of Bessel function contain factorial functions which results very large numbers that is incomputable by a computer. The results that cause the programming cannot be completed and the parameter estimator is not obtained. Therefore, the factorial function must be modified into a simpler form so that it does not produce incomputable numbers. Once the model specification has been determined, this research discusses the parameter estimation and hypothesis testing. The MLE method, followed by the Newton–Raphson iteration, is employed for the parameter estimation in this work. The next aim is to develop the hypothesis testing using the MLRT approach that has been done in this study. The proposed MPIGR model, along with its parameter estimation and hypothesis testing, is applied in order to model the relationship of three correlated response variables and eight predictors. The three response variables are the number of infant mortality, the number of under-five children mortality, and the number of maternal mortality. The observation unit is the cities and municipalities in Java Island, Indonesia. Furthermore, the exposure variable is used as a weight for each unit of observation. The exposure variable in this research is the number of live births.
As the third objective of the Sustainable Development Goals (SDGs), infant, under-five children, and maternal mortality are estimated to decrease every year. However, in 2017 alone, the under-five children accounted for 5.4 million death, with 2.5 million death occurring in the first month of life (neonatal), 1.6 million occurring at age 1–11 months (infant), and 1.3 million at age 1–4 years. There are 118 countries that already had an under-five mortality rate below the SDG target of a mortality rate at least as low as 25 deaths per 1000 births. At the same time, approximately 50 countries need to be accelerated to achieve the SDG target by 2030. As one of low-middle income country, the under-five mortality rate in Indonesia in 2017 is 28 deaths per 1000 births for male and 22 deaths per 1000 births for female. Nevertheless, efforts to reduce mortality inequity within country should be intensified [10].
The maternal mortality ratio (MMR) is one of statistical measures of maternal mortality. MMR is the number of maternal deaths during a given time period per 100,000 live births during the same time period. MMR is considered to be low if it is less than 100, moderate if it is 100–299, high if it is 300–499, very high if it is 500–999, and extremely high if it is greater than or equal to 1000 maternal deaths per 100,000 live births. SDGs target for maternal mortality by 2030 is reducing the global MMR to less than 70 per 100,000 births, with no country having a maternal mortality rate of more than twice the global average. The MMR of Indonesia in 2017 is 177, which is categorized as moderate and must be reduced in order to achieve the SDGs target [11]. There is a relationship among maternal mortality, infant mortality, and under-five mortality. In previous study, it stated that the maternal mortality cause the infant to be more likely to die than to survive and the survival trajectory of these children is far worse than those of mothers who not die [12].
Based on the issue above, analysis of the MPIGR model is performed in order to determine the factors that influence the mortality number of infants, under-five children, and maternal in Java, Indonesia. The remaining part of this paper is constructed, as follows. Section 2 provides the material and method in more detail. Results and conclusion are addressed in the last section.
2. Materials and Methods
2.1. Multivariate Poisson Inverse Gaussian Distribution (MPIGD)
The MPIGD is a mixed Poisson distribution that consists of two or more correlated response variables. Let Y1, Y2, …, Ym as the response variables with the assumption Yj ~ Poisson (μj), j = 1, 2, …, m, with its mean and variance are the same or they can be written in the following regression equation:
which is called as equidispersion. For some cases, equidispersion is too restrictive and rarely satisfied. Oftentimes, the conditional variance will exceed the conditional mean (overdispersion), which is likely to result from positive contagion and unobserved heterogeneity. An error term is introduced to μj,
Thus, are the mean for each response variable now, Yj ~ Mixed Poisson (μjvj) [8,13]. The mixed Poisson distribution depends on the specific distribution of random variable V. In this study, variable V is an inverse Gaussian distributed. Hence, Y1, Y2, …, Ym are Poisson inverse Gaussian distribution (PIGD), with the probability mass function (pmf) being given by [3],
the implies the probability density function of Inverse Gaussian of random variable V [9].
where and .
2.2. Multivariate Poisson Inverse Gaussian Regression (MPIGR)
The MPIGR model is a development model from the univariate Inverse Gaussian Poisson Regression (PIGR) with two or more correlated response variables. Let (Yi1, Yi2, …, Yim) ~ MPIG (vμij), where then the MPIGR model can be stated as follows:
with , the qi is an exposure variable which is defined as the weight of the i-th unit observation, is the vector of predictor variables with (p + 1) dimension on the i-th observation (i = 1, 2, …, n), is a (p + 1) × 1 vector of regression coefficient associated with the j-th response variable (j = 1, 2, …, m).
3. Results
3.1. Parameter Estimation of MPIGR Model
Estimation of the MPIGR model parameters is obtained using the Maximum Likelihood Estimation (MLE) method by maximizing the likelihood function. Two parameters will be estimated, namely βj and τ. The first step of the MLE method is by taking n random sample, with j = 1, 2, …, m, k = 1, 2, …, p and i = 1, 2, …, n. The joint probability density function of is:
where . The likelihood function of Equation (8) is as below:
The log-likelihood function from Equation (9) is:
Then, Equation (10) derive to the parameter and we get:
where , then
with the same procedure, generally we get:
Furthermore, the first derivative of the MPIGR log-likelihood function to parameter τ is formulated as below:
where and we got:
where
According to [14], the third modification of Bessel function in Equation (12) can be written, as follows:
Equations (9)–(11) equate to zero and produce non-explicit form. Hence, an iterative method needs to be applied for estimating parameters. The iterative method used is the Newton–Raphson iteration method while using the following algorithm:
- ▪
- Step 1. Determine the initial value for parameter . The initial value of parameter is obtained while using the separate univariate Poisson regression. The initial value for overdispersion parameter τ used the average of the observed overdispersion based on the variance of PIGD [9].
- ▪
- Step 2. Determine the gradient vector , which is the elements consist of the first derivative of the log-likelihood function, .
- ▪
- Step 3. Determine the Hessian matrix where the elements consist of the second derivative of the log-likelihood function, as follows
- ▪
- Step 4. Start the Newton–Raphson iteration using the following formula,with and r = 0, 1, 2, …, r*.
- ▪
- Step 5. The iteration will stop if , with ε is a very small value and it will produce the estimator value for each parameter.
3.2. Factorial Simplification in the Third Modification of BESSEL Function
The factorial function in the third modification of Bessel function, as performed in Equations (15) and (16) results in the large value by the calculation in programming. These results cause the program unable to complete, so that parameter estimates cannot be obtained. Therefore, the factorial simplification in Bessel function is needed. Based on Equations (15) and (16), let . Because the factorial function only works for these conditions, N > 0, m > 0, and n > m, accordingly (N + m)! contains the whole of (N−m)! and the factorial function can be simplified, as below:
According to Equation (18), the factorial function in Equation (15) can be written, as follows:
with the same procedure, the factorial function in Equation (16) can be simplified, as below:
Substitute Equations (19) and (20) to Equations (15) and (16) in order to calculate in Equation (14). The result of will be used in the first and second derivative of MPIGR log-likelihood function in order to obtain the parameter estimation.
3.3. Hypothesis Testing of MPIGR Model
The hypothesis testing of the MPIG regression model was undertaken by the Maximum Likelihood Ratio Test (MLRT) method both simultaneously and partially. Simultaneous hypothesis testing is performed in order to determine the significance of the regression parameters in the model simultaneously with the following hypothesis: the null hypothesis is βj1 = βj2 = … = βjk = … = βjp = 0 and τ = 0 and the alternative hypothesis is at least one βjk ≠ 0 and τ ≠ 0, where j = 1, 2, …, m; and k = 1, 2,…, p.
Let Ω as a set of parameters under population with and is a set of parameters under null hypothesis with The is the likelihood of the full model, which includes all of the predictor variables, and is the likelihood of a saturated model without predictor variables. The likelihood function for each model, as follows:
and
The test statistics for the hypothesis in the simultaneous test of MPIGR model is formulated, as below.
The log-likelihood function in Equation (22) is maximized by determining the first-order partial derivative of the log-likelihood function with respect to the parameters of and and the results are as follows.
Generally, we get:
Hence, the statistics G2 for the MPIGR model determined by substituting Equations (9) and (22) to Equation (23) and the result is as follows:
The details of the statistics G2 based on the likelihood ratio test method is described in Appendix A. The statistics G2 follows the asymptotic of the Chi-square distribution, such that the significant level α reject the null hypothesis when G2 value falls into the rejection region, i.e., when .
3.4. Application
The MPIGR model in this study is applied in order to model the number of infants, child, and maternal death. The data are collected from the Health Profile of Java, Indonesia, in 2017. There are six provinces with 119 cities or municipalities in Java Island. Because of the data limitation, Banten Province was not included in this study. Thus, this study only used 111 cities or municipalities.
The variables used in this study is consist of three correlated response variables, namely the number of infant mortality (Y1), under-five children mortality(Y2), and maternal mortality (Y3). There are eight predictor variables, such as the percentage of antenatal care visit by pregnant women (X1), the percentage of pregnant women who received Fe3 tablet (X2), the percentage of complete neonatal visits (X3), the percentage of Low Birth Weight (LBW) (X4), the percentage of healthy house (X5), the percentage of active integrated service post (X6), the percentage of infants received vitamin A (X7), and the percentage of births that are assisted by health workers (X8). Banten Province does not have several predictor variables selected, which is quite important for modelling the response variable. Thus, Banten Province was excluded from the study on the consideration of the selected predictor variables.
Every region in Java Island has different characteristics. Therefore, the exposure variable is needed, because the city or municipality is worth comparing. The exposure variable used in this study is the number of live births of each city or municipality in Java.
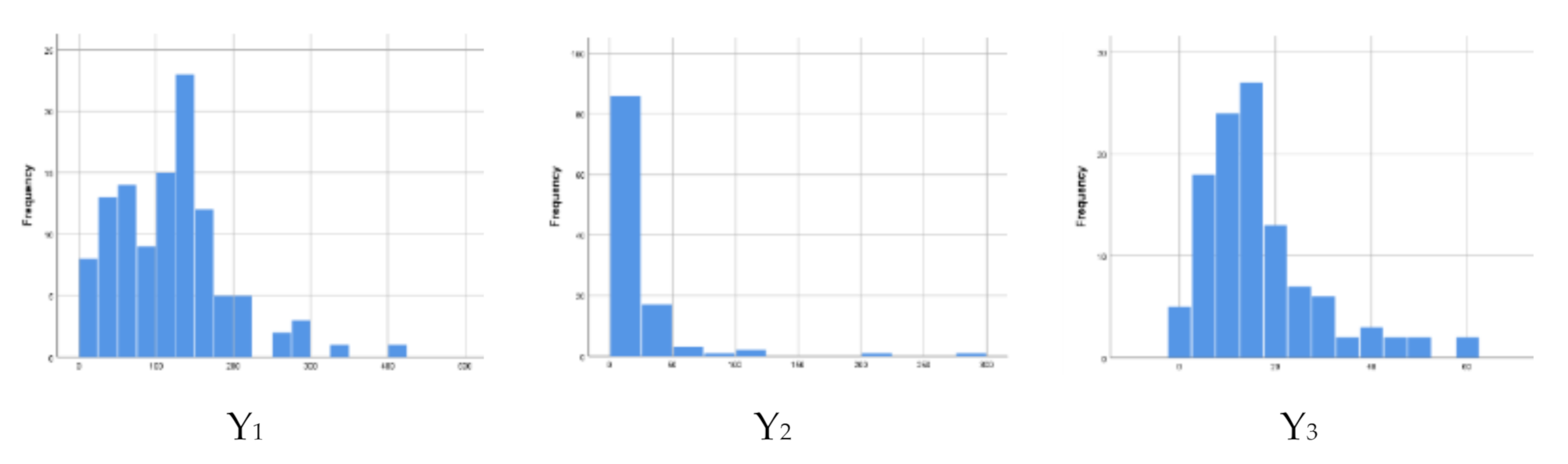
Based on Table 1, the means of three response variables are 118.08, 20.41, and 16.4. Because the mean of Y1, Y2, and Y3 differ greatly, we need to measure the spread of the data. The coefficient of variation (CoV) can be used to measure data distribution. The CoV of Y1, Y2, and Y3 are 63.4, 425.6, and 89.1. The number of child mortality (Y2) has the highest CoV, which means that variable Y2 is more heterogenous than the other two variables. This evidence is also supported by histogram for Y1, Y2, and Y3 in Figure 1. It shows that the Y2 curve is quite skewed to the right than Y1 and Y3.
Table 2 displays the characteristics of each predictor that is presumed to influence the number of infants, child, and maternal deaths. The characteristics of each predictor are explained based on the mean and standard deviation for each province in Java Island. As a health indicator, these predictors are expected to meet the targets in order to improve the quality of health in Indonesia.
Predictors other than LBW are expected to have a high percentage, because these predictors are thought to reduce the number of infants, child, and maternal death. In comparison, LBW is expected to have a low percentage, because LBW is believed to be able to increase the number of infant deaths.
Based on Table 2, almost all of the provinces in Java reach an average of 80–90% for some predictors, except LBW. Still, the province with a low percentage, such as Yogyakarta, has the average of the ratio of complete neonatal visits at 77.32% that should be increased. Furthermore, for the percentage of active integrated service posts, other provinces except Jakarta have a percentage of 60–78%, which is a quite low average. The active integrated service post is a form of Community-Based Health Efforts to facilitate the public for infants, children, and maternal to get health services. Aside from active integrated service posts, the percentage of healthy homes in all provinces in Java has not reached 80% other than Central Java Province. Additional suggestions to the government, the role of the community should be improved in order to encourage the people to get involved in the implementation of active integrated service posts, and the percentage of healthy homes.
The characteristics of each predictor provide a description and presumption about the predictors affect the number of infants, child, and maternal deaths in Java. Further analysis is required to obtain more accurate results. The MPIGR model is used to determine the predictors, since it significantly affects the number of infants, child, and maternal death in Java. Before applying the MPIGR, it is necessary to test the overdispersion assumption. Overdispersion occurs when the variance is higher than the mean. The overdispersion exists when the deviance value over the degree of freedom is higher than one, and the ratio of Pearson Chi-square value over the degree of freedom is higher than one.
Table 3 shows that all of the response variables suffer overdispersion, because the values of deviance/df are higher than one. Therefore, the MPIGR model should be used to model the data. The relationship between pair of response variables was measured by the Pearson’s product–moment correlation. The coefficient of Pearson’s correlation between variable Y1 and Y2 is 0.543 (p-value = 6.97 × 10−10). The coefficient of Pearson’s correlation between variable Y1 and Y3 is 0.587 (p-value = 1.29 × 10−11). Otherwise, the coefficient of Pearson’s correlation between variable Y2 and Y3 is 0.130 (p-value = 0.172). Even though there is one pair of the response variables that has significantly no correlation, we need to make sure whether there is dependency among the response variables in multivariate way. Therefore, we calculated the correlation using Bartlett’s test. The result shows that and p-value (7.20 × 10−20) < α (0.05). The decision is to reject the null hypothesis, stating that Pearson correlation matrix not equal to an identity matrix. Thus, the response variable can be used in multivariate analysis while using the MPIGR model.
The significance of the simultaneous test shows that the statistics G2 = 39.86 × 108 is higher than ; hence, the decision to reject the null hypothesis. It means that there is at least one predictor variable that significantly influences the number of infants, child, and maternal mortality.
The partial hypothesis testing is done in order to determine the significant predictor variables that are influencing the number of infants, child, and maternal mortality in Java. Table 4 shows the estimation results of MPIGR model parameters.
The estimate of the dispersion parameter (τ) is 0.493 with its p < 0.001. Based on the empirical results summarized in Table 3, all of the predictor variables have a significant effect on the three responses. The MPIGR model of these three responses and eight predictors can be written in the following equations:
We use the Mean Squared Error (MSE) to measure the difference in the average squared between the estimated and the actual value in order to determine whether the model fits the data well. The Root Mean Squared Error (RMSE) reveals the estimates of standard deviation of each response, where their standard deviation of response observations are reported in Table 1. The MSE and RMSE for the response variables are tabulated in Table 5. It is shown that the RMSE values are close the standard deviation of each response. This empirical results also prove that the predicted responses are relatively very close to the observations values.
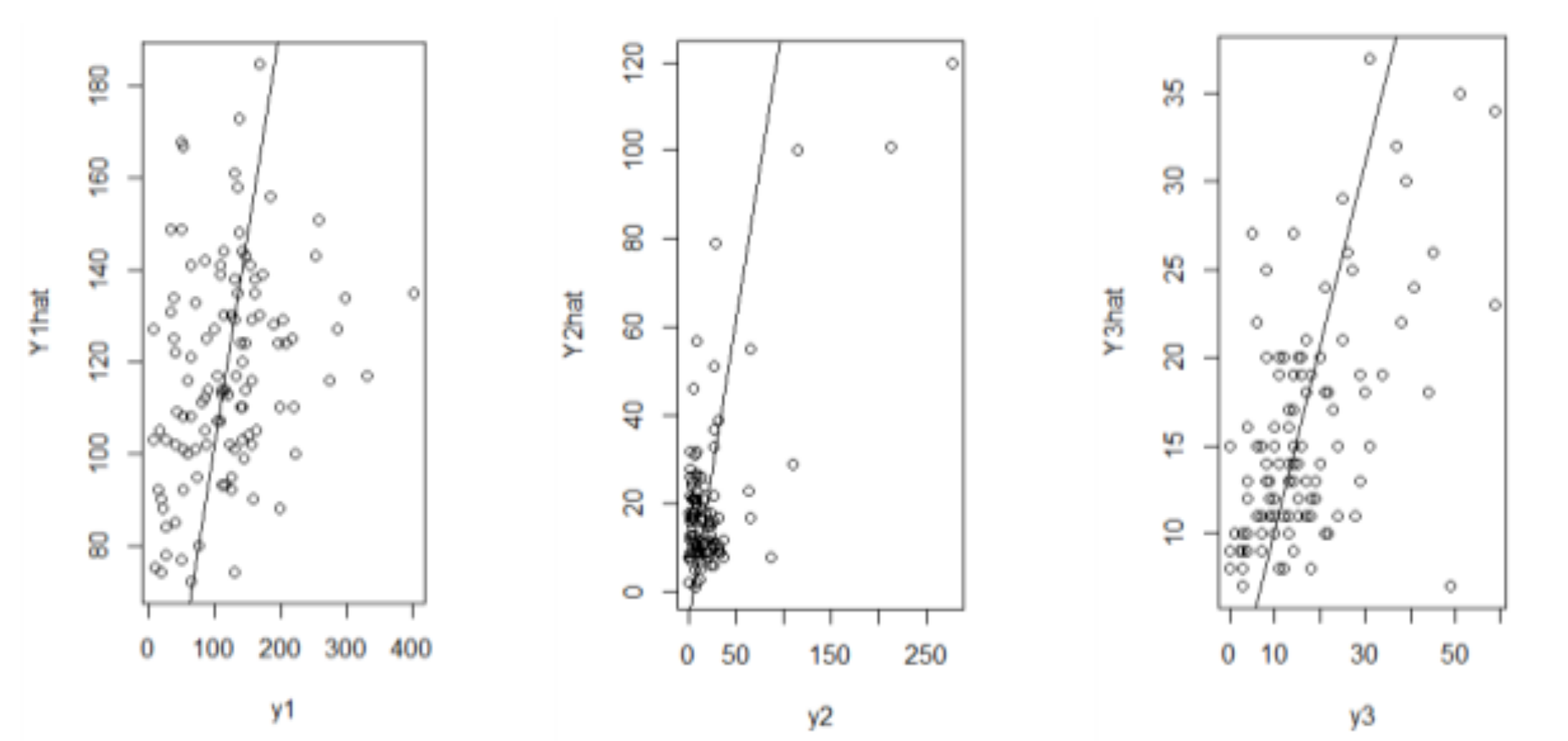
In addition to RMSE written in Table 5, the scatter plots of true and prediction values of each response are exhibited in order to show that the MPIGR model is good at predicting the observed data. To support this result, Figure 2 is displayed to see how spread out the residuals are. Based on Figure 2, the fitting values for Y1 and Y3 are better than those of Y2. This empirical results, of course, can be improved. These findings become the big concerns for the next research that are possibly related to the spatial dependencies among the responses that are discussed in the coming section.
4. Discussion
The result of the significant partial test shows that at a significance level α = 0.05, the predictor variables that significantly influence the number of infants, child, and maternal deaths are the percentage of antenatal care visit by pregnant women (X1), the percentage of pregnant women who received Fe3 tablet (X2), the percentage of complete neonatal visits (X3), the percentage of Low Birth Weight (LBW) (X4), the percentage of healthy house (X5), the percentage of active integrated service post (X6), the percentage of infants received vitamin A (X7), and the percentage of births that are assisted by health workers (X8).
According to regression coefficient of the MPIGR model, the percentage of Low Birth Weight (LBW) (X4) gave the greatest effect to the number of infant mortality (Y1), the number of under-five children mortality (Y2), and the number of maternal mortality (Y3). However, it has inappropriate dependencies with Y1, Y2, and Y3. Based on these results, we need to look at the pattern of the relationship between the predictor and the response variables below.
The pattern of the relationship between the predictor and response variables leads to the conclusion that several predictors have an inappropriate relationship structure. The percentage of antenatal care visit by pregnant women (X1) has a negative relationship with Y1 and Y2, while it has positive or inappropriate relationship with Y3. The percentage of pregnant women who received Fe3 tablet (X2) has negative dependencies with Y2, while it has a positive or inappropriate relationship with Y1 and Y3. On the other side, the percentage of complete neonatal visits (X3) has negative or appropriate dependencies with Y1 and Y3. Meanwhile, the percentage of Low Birth Weight (LBW) (X4) has positive dependencies with all of the response variables. However, conflicting results were obtained for all of the response variables.
The percentage of healthy house (X5) has negative relationship with Y1 and Y3, while it has positive or inappropriate sign with Y2. The percentage of active integrated service post (X6) has negative dependencies with Y1 and Y3, while it has a positive effect on Y2. The percentage of infants received vitamin A (X7) has a positive relationship with Y1 and Y3, while it has negative or appropriate dependencies with Y2. The latter one, the percentage of births assisted by health workers (X8), has negative dependencies with Y3, while it has an inappropriate relationship with Y1 and Y3. This finding means that, even though all predictor variables are statistically significant, not all of them have an appropriate relationship with all of the response variables.
The results of this study lead us to more deeply investigate the appropriate method for modeling the data. We assume that the spatial aspect needs to be added to the modeling. Thus, to support our assumptions, a spatial heterogeneity test was carried out in order to test the differences in the characteristics between one point of observation and another. The test statistics used the Glejser test with the null hypothesis (H0) is no spatial heterogeneity and the alternative hypothesis (H1) is that there is spatial heterogeneity. The results of the test is G2 =1309.84, which is higher than . Therefore, the decision is to reject H0, which means that the response variables have a spatial heterogeneity and can be modelled using a spatial model in future work. The local model, for example, geographically weighted regression, for MPIGR will be the big concern for our future research.
5. Conclusions
The Multivariate Poisson Inverse Gaussian Regression (MPIGR) is the development of the Poisson Inverse Gaussian univariate regression (PIGR) model. The MPIGR model that is proposed in this research accommodates the exposure variable within the model, as the quality of each observation unit level, to overcome the overdispersion problem. The parameter estimation is performed using the Maximum Likelihood Estimation (MLE), followed by the Newton–Raphson iteration. Meanwhile, to simultaneously and partially examine the MPIGR model, the Maximum Likelihood Ratio Test (MLRT) method is used.
The empirical results of the application, where the unit of observation is city or municipality, showed that all eight predictors affect the three response variables, i.e., number of infants, under-five children, and maternal mortality in Java, Indonesia. The predictors are the percentage of antenatal care visits of pregnant women, the percentage of pregnant women receiving Fe3 tablets, the percentage of neonatal visits complete, the percentage of low birth weight babies (LBW), the percentage of healthy homes, the percentage of active integrated service post, the percentage of babies receiving vitamin A, and the percentage of deliveries assisted by health workers.
According to computational problems that were suffered by factorial calculation in Bessel function, the factorial simplification in the third modification of Bessel function was done to avoid the large numbers incomputable by a computer. The proposed simplification procedure is very crucial to make the fitting of the MPIGR models computable. The application of the MPIGR model to real data in this study is limited to three-count response variables. Based on the result of the spatial heterogeneity test, the spatial aspects are needed to model the data with the spatial model in future research.
Author Contributions
Conceptualization, S.M., P.P., J.D.T.P., and D.D.P.; methodology, P.P. and J.D.T.P.; software S.M. and D.D.P.; validation, P.P. and D.D.P.; formal analysis, S.M. and D.D.P.; investigation, S.M.; data curation, S.M.; writing original draft preparation, S.M.; writing—review and editing, P.P., J.D.T.P., and D.D.P.; supervision, P.P., J.D.T.P., and D.D.P.; project administration, P.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research and the APC were funded by the Ministry of Education and Culture (Kemendikbud) of the Republic of Indonesia with grant number 1279/PKS/ITS/2020.
Acknowledgments
All authors thank the editor and reviewers for the improvement of this paper through criticism and suggestions provided.
Conflicts of Interest
The authors declare no conflict of interest.
Nomenclature
| PIG | Poisson Inverse Gaussian |
| PIGD | Poisson Inverse Gaussian Distribution |
| PIGR | Poisson Inverse Gaussian Regression |
| MPIGD | Multivariate Poisson Inverse Gaussian Distribution |
| MPIGR | Multivariate Poisson Inverse Gaussian Regression |
| MLE | Maximum Likelihood Function |
| MLRT | Maximum Likelihood Ratio Test |
| CoV | Coefficient of Variation |
| LBW | Low Birth Weight |
Appendix A
The statistical test of the hypothesis for MPIGR model based on the likelihood ratio test method is formulated as follows:
References
- Consul, P.; Famoye, F. Generalized poisson regression model. Commun. Stat. Theory Methods 1992, 21, 89–109. [Google Scholar] [CrossRef]
- Holla, M.S. On a poisson-inverse gaussian distribution. Metr. Int. J. Theor. Appl. Stat. 1967, 11, 115–121. [Google Scholar] [CrossRef]
- Dean, C.; Lawless, J.F.; Willmot, G.E. A mixed poisson-inverse-gaussian regression model. Can. J. Stat. 1989, 17, 171–181. [Google Scholar] [CrossRef]
- Hilbe, J.M. Poisson Inverse Gaussian Regression. In Modeling Count Data; Cambridge University Press (CUP): Cambridge, UK, 2014; pp. 162–171. [Google Scholar]
- Karlis, D.; Xekalaki, E. A Simulation Comparison of Several Procedures for Testing the Poisson Assumption. J. R. Stat. Soc. Ser. D Stat. 2000, 49, 355–382. [Google Scholar] [CrossRef] [Green Version]
- Ouma, V.M. Poisson Inverse Gaussian (PIG) Model for Infectious Disease Count Data. Am. J. Theor. Appl. Stat. 2016, 5, 326. [Google Scholar] [CrossRef] [Green Version]
- Xie, F.-C.; Wei, B.-C. Influence analysis for Poisson inverse Gaussian regression models based on the EM algorithm. Metrika 2007, 67, 49–62. [Google Scholar] [CrossRef]
- Zha, L.; Lord, D.; Zou, Y. The Poisson inverse Gaussian (PIG) generalized linear regression model for analyzing motor vehicle crash data. J. Transp. Saf. Secur. 2014, 8, 18–35. [Google Scholar] [CrossRef] [Green Version]
- Ghitany, M.E.; Karlis, D. An EM Algorithm for Multivariate Mixed Poisson. Appl. Math. Sci. 2012, 6, 6843–6856. [Google Scholar]
- United Nations Inter-agency Group for Child Mortality Estimation (UN IGME). Levels & Trends in Child Mortality: Report 2018, Estimates Developed by the United Nations Inter-Agency Group for Child Mortality Estimation; United Nations Children’s Fund: New York, NY, USA, 2018. [Google Scholar]
- WHO; UNICEF; UNFPA; The World Bank. Maternal Mortality: Level and Trends 2000 to 2017; World Health Organization: Geneva, Switzerland, 2019; ISBN 978-92-4-151648-8. [Google Scholar]
- Moucheraud, C.; Worku, A.; Molla, M.; Finlay, J.E.; Leaning, J.; Yamin, A.E. Consequences of maternal mortality on infant and child survival: A 25-year longitudinal analysis in Butajira Ethiopia (1987–2011). Reprod. Health 2015, 12, S4. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Miaou, S.P.; Lord, D. Modeling Traffic Crash–Flow Relationships for Intersections Dispersion Parameter, Functional Form, and Bayes Versus Empirical Bayes Methods. Transp. Res. Rec. J. Transp. Res. Board 2003, 1840, 31–40. [Google Scholar] [CrossRef]
- Willmot, G.E. The Poisson-Inverse Gaussian distribution as an alternative to the negative binomial. Scand. Actuar. J. 1987, 1987, 113–127. [Google Scholar] [CrossRef]
- Stein, G.Z.; Juritz, J.M. Bivariate compound poisson distributions. Commun. Stat. Theory Methods 1987, 16, 3591–3607. [Google Scholar] [CrossRef]
- Stein, G.Z.; Zucchini, W.; Juritz, J.M. Parameter estimation for the Sichel distribution and its multivariate extension. J. Am. Stat. Assoc. 1987, 82, 938–944. [Google Scholar] [CrossRef]
Figure 1.
Histogram of response variables.

Figure 2.
The plot of the actual and the estimate values.


{kind=link}
{kind=link}
Table 1.
Description of the response variables.
| Variable | Mean | SD | Coefficient of Variation | Min | Max |
|---|---|---|---|---|---|
| The number of infant mortality (Y1) | 118.08 | 72.885 | 63.4 | 7 | 403 |
| The number of child mortality (Y2) | 20.41 | 36.554 | 425.6 | 0 | 278 |
| The number of maternal mortality (Y3) | 16.4 | 12.233 | 89.1 | 0 | 59 |
Table 2.
Descriptive statistics of predictor variables that are based on city or municipality in Java.
Table 2.
Descriptive statistics of predictor variables that are based on city or municipality in Java.
| Variable | Province | ||||
|---|---|---|---|---|---|
| Jakarta | Yogyakarta | Central Java | West Java | East Java | |
| The percentage of antenatal care visit by pregnant women | 99.26 (6.10) a | 90.92 (3.61) | 92.86 (3.62) | 97.44 (8.20) | 89.34 (5.47) |
| The percentage of pregnant woman who received Fe3 tablet | 95.14 (4.35) | 88.05 (4.41) | 92.85 (4.01) | 95.88 (9.50) | 88.37 (5.67) |
| The percentage of complete neonatal visits | 95.44 (2.13) | 77.32 (28.53) | 92.97 (10.29) | 94.30 (16.78) | 96.34 (3.82) |
| The percentage of Low Birth Weight (LBW) | 1.07 (1.45) | 5.26 (1.14) | 4.54 (0.93) | 2.87 (1.66) | 4.20 (1.41) |
| The percentage of healthy house | 66.33 (18.85) | 70.59 (17.97) | 85.27 (14.17) | 71.25 (15.84) | 70.53 (16.40) |
| The percentage of active integrated service post | 100 (0.00) | 76.99 (9.36) | 66.98 (18.88) | 63.07 (20.58) | 78.14 (14.53) |
| The percentage of infants received vitamin A | 92.52 (8.13) | 90.92 (16.40) | 97.25 (8.43) | 91.76 (16.01) | 98.30 (7.97) |
| The percentage of births assisted by health workers | 98.00 (5.56) | 100.0 (0.00) | 99.14 (1.56) | 97.94 (8.39) | 94.04 (4.16) |
| The number of live births b | 34649 (23137) | 8470 (4548) | 15424 (7310) | 33903 (25870) | 15144 (10125) |
a: Mean (Standard deviation); b: Exposure variable.
Table 3.
Overdispersion test.
| Variable | Deviance | df | Deviance/df |
|---|---|---|---|
| Number of infant mortality (Y1) | 4462.60 | 102 | 43.75 |
| Number of child mortality (Y2) | 2181.11 | 102 | 21.38 |
| Number of maternal mortality (Y3) | 670.05 | 102 | 6.57 |
Table 4.
Parameter estimation of each predictor at each response variables.
| Parameter | The Number of Infant Mortality | The Number of Under-Five Children Mortality | The Number of Maternal Mortality | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Est | Se | Z | P | Est | Se | Z | P | Est | Se | Z | P | |
| 4.101 | 5.27 × 10−4 | −7.78 × 103 | p < 0.001 | −2.549 | 5.17 × 10−3 | 4.92 × 102 | p < 0.001 | 3.613 | 3.59 × 10−2 | −1.00 × 102 | p < 0.001 | |
| −0.032 | 7.40 × 10−8 | 4.31 × 105 | p < 0.001 | −0.072 | 7.24 × 10−7 | 9.89 × 104 | p < 0.001 | 0.014 | 1.06 × 10−5 | −1.34 × 103 | p < 0.001 | |
| 0.004 | 6.23 × 10−8 | 6.16 × 104 | p < 0.001 | −0.018 | 6.15 × 10−7 | −2.87 × 104 | p < 0.001 | 0.007 | 3.05 × 10−6 | 2.31 × 103 | p < 0.001 | |
| −0.003 | 5.16 × 10−9 | −5.33 × 105 | p < 0.001 | 0.001 | 5.03 × 10−9 | −2.64 × 105 | p < 0.001 | −0.003 | 4.43 × 10−8 | −6.09 × 104 | p < 0.001 | |
| −0.076 | 6.83 × 10−7 | 1.11 × 105 | p < 0.001 | −0.449 | 1.41 × 10−5 | 3.18 × 104 | p < 0.001 | −0.119 | 3.54 × 10−5 | 3.36 × 103 | p < 0.001 | |
| −0.002 | 3.88 × 10−9 | 4.88 × 105 | p < 0.001 | 0.005 | 2.04 × 10−8 | 2.24 × 105 | p < 0.001 | −0.005 | 3.99 × 10−7 | 1.28 × 104 | p < 0.001 | |
| −0.005 | 3.67 × 10−9 | 1.37 × 106 | p < 0.001 | 0.019 | 2.53 × 10−8 | −7.59 × 105 | p < 0.001 | −0.013 | 2.60 × 10−7 | 5.34 × 104 | p < 0.001 | |
| 0.004 | 6.67 × 10−9 | −6.03 × 105 | p < 0.001 | −0.005 | 2.02 × 10−8 | −2.57 × 105 | p < 0.001 | 0.006 | 8.32 × 10−7 | −7.68 × 103 | p < 0.001 | |
| 0.041 | 3.26 × 10−8 | 1.24 × 106 | p < 0.001 | 0.144 | 1.94 × 10−6 | 7.42 × 104 | p < 0.001 | 3.613 | 3.59 × 10−2 | −1.00 × 102 | p < 0.001 | |
Table 5.
The Mean Squared Error (MSE) and Root Mean Squared Error (RMSE) for each response variable.
Table 5.
The Mean Squared Error (MSE) and Root Mean Squared Error (RMSE) for each response variable.
| Y1 | Y2 | Y3 | |
|---|---|---|---|
| MSE | 4821.05 | 707.31 | 104.17 |
| RMSE | 69.43 | 26.59 | 10.21 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Mardalena, S.; Purhadi, P.; Purnomo, J.D.T.; Prastyo, D.D. Parameter Estimation and Hypothesis Testing of Multivariate Poisson Inverse Gaussian Regression. Symmetry 2020, 12, 1738. https://doi.org/10.3390/sym12101738
AMA Style
Mardalena S, Purhadi P, Purnomo JDT, Prastyo DD. Parameter Estimation and Hypothesis Testing of Multivariate Poisson Inverse Gaussian Regression. Symmetry. 2020; 12(10):1738. https://doi.org/10.3390/sym12101738
Chicago/Turabian StyleMardalena, Selvi, Purhadi Purhadi, Jerry Dwi Trijoyo Purnomo, and Dedy Dwi Prastyo. 2020. "Parameter Estimation and Hypothesis Testing of Multivariate Poisson Inverse Gaussian Regression" Symmetry 12, no. 10: 1738. https://doi.org/10.3390/sym12101738
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.