Principle of Duality in Cubic Smoothing Spline


1
Graduate School of Social Sciences, Hiroshima University, 1-2-1 Kagamiyama, Higashi-Hiroshima 739-8525, Japan
2
School of Informatics and Data Science, Hiroshima University, 1-2-1 Kagamiyama, Higashi-Hiroshima 739-8525, Japan
*
Author to whom correspondence should be addressed.
Mathematics 2020, 8(10), 1839; https://doi.org/10.3390/math8101839
Submission received: 20 September 2020
/
Revised: 12 October 2020
/
Accepted: 15 October 2020
/
Published: 19 October 2020
(This article belongs to the Section Probability and Statistics)
Abstract
:Fitting a cubic smoothing spline is a typical smoothing method. This paper reveals a principle of duality in the penalized least squares regressions relating to the method. We also provide a number of results derived from them, some of which are illustrated by a real data example.
Keywords:
cubic smoothing spline; principle of duality; penalized regression; right-inverse matrix; ridge regressionMSC:
62G051. Introduction
Fitting a cubic smoothing spline, which was developed by [1,2] and others, is a typical smoothing method. The cubic smoothing spline fitted to a scatter plot of ordered pairs for is a function such that
where are points satisfying , denotes a function space that contains all functions of which the second derivative is square integrable over , and is a positive smoothing/tuning parameter, which controls the trade-off between goodness of fit and smoothness.
Let . Then, given is a natural cubic spline of which the knots are (see, e.g., [3,4]), it follows that
where , denotes the identity matrix, and and are explicitly presented later. Then, as shown in [3], in (1) is uniquely determined by in (3). Thus, estimating is equivalent to estimating .
Let , where and . Note that since , and are linearly independent and thus is of full column rank. Let
Denote the difference between and (resp. and ) by (resp. ):
Accordingly, we have
In this paper, we present a comprehensive list of penalized least squares regressions relating to (6). One such example is the ridge regression [5] that leads to . Then, we reveal a principle of duality in them. In addition, based on them, we provide a number of theoretical results, for example, .
This paper is organized as follows. Section 2 fixes some notations and gives key preliminary results used to derive the main results in the paper. Section 3 provides a comprehensive list of penalized least squares regressions relating to (6), and reveals a principle of duality in them. Section 4 shows some results that are obtainable from the regressions shown in Section 3. Section 5 illustrates some results provided in Section 3 and Section 4 by a real data example. Section 6 deals with the cases such that the other right-inverse matrices are used. Section 7 concludes the paper.
2. Preliminaries
In this section, we give key preliminary results used to derive the main results of this paper. Before stating them, we fix some notations.
2.1. Notations
Let (resp. ) denote the ith entry of (resp. ) for , , which is positive by definition, for , , and for a full-row-rank matrix , , which is a right-inverse matrix of , be denoted by . For a full-column-rank matrix , let (resp. ) denote the column space of (resp. the orthogonal complement of ) and (resp. ) denote the orthogonal projection matrix to the space (resp. ). Explicitly, they are and . is a Toeplitz matrix of which the first (resp. last) row is (resp. ) and we define matrices and as follows:
and
Finally, we denote the eigenvalues of by in descending order.
2.2. Key Preliminary Results
Lemma 1.
- (i)
- can be factorized as .
- (ii)
- We have the following inequalities:
Proof of Lemma 1.
- (i)
- Let be an n-dimensional column vector. Then, by definition of , it follows thatwhich leads to .
- (ii)
- The first inequality follows by applying the Gershgorin circle theorem and the second inequality holds from for .
□
Remark 1.
In Appendix A, we give some remarks on a special case such that .
Lemma 2.
- (i)
- equals and
- (ii)
- equals .
Proof of Lemma 2.
- (i)
- Given that for , both and are of full column rank. In addition, is a square matrix. Thus, if , then it follows that . From , we have . Likewise, from and , we obtain . Accordingly, we have , which completes the proof.
- (ii)
- Recall that . It is clear that is a full-column-rank matrix such that is a square matrix. In addition, . Thus, it follows that .
□
Denote the spectral decomposition of by and let , where . Then, is a positive definite matrix such that . Define
Then, given that is of full column rank and is nonsingular, is also of full row rank. In addition, we have
(We provide Matlab/GNU Octave and R functions for calculating , , and in Appendix A).
Lemma 3.
- (i)
- equals and
- (ii)
- equals .
Proof of Lemma 3.
Both (i) and (ii) may be proved similarly to Lemma 2 (ii). For example, given , we have . □
Denote the eigenvalues of by in ascending order and the spectral decomposition of by , where and . Let , , and .
Lemma 4.
- (i)
- equals ,
- (ii)
- equals , and
- (iii)
- equals .
Proof of Lemma 4.
(i) Since is a nonnegative definite matrix of which the rank is , we have . In addition, given , it follows that , which completes the proof. (ii) and (iii) may be proved similarly to Lemma 2 (ii). □
Given , we have
Define
where . Then, we have
Lemma 5.
- (i)
- equals and
- (ii)
- equals .
Proof of Lemma 5.
Both (i) and (ii) may be proved similarly to Lemma 2 (ii). For example, given , we have . □
Lemma 6.
There exists an orthogonal matrix such that .
Proof of Lemma 6.
Recall that both and are of full column rank and . Accordingly, there exists a nonsingular matrix such that . Given that , we have . Then, from , we have . □
Let (i) , (ii) , (iii) , and (iv) . From the results above, we immediately obtain the following results:
Proposition 1.
- (i)
- ,
- (ii)
- ,
- (iii)
- both and are nonsingular, and
- (iv)
- .
3. Several Regressions Relating to (6) and Principle of Duality in Them
In this section, we provide a comprehensive list of penalized least squares regressions relating to (6), and reveal a principle of duality in them. The penalized regressions are, more precisely, those to compute , , , , , and .
3.1. Penalized Regressions to Compute
Concerning , we have the following results:
Lemma 7.
It follows that
3.2. Penalized Regressions to Compute
Concerning , we have the following results:
Lemma 8.
Consider the following penalized regressions:
Then, we have
Proof of Lemma 8.
Let . From Proposition 1, it follows that , , and is nonsingular. Accordingly, given that and , it follows that
from which we have . Given , we thus obtain . Similarly, we can obtain . □
Lemma 9.
can be calculated by the following penalized regressions:
Remark 2.
We add some more exposition about (16). Let as before. In addition, let be a vector such that . Then, it follows that . Given that and , the minimization problem in (14) can be represented as follows:
It is noteworthy that is not penalized in (21) and . Thus, the minimization problem (21) can be decomposed into (16) and (40). Moreover, (21) gives the best linear unbiased predictors of and of the following linear mixed model:
where .
3.3. Penalized Regressions to Compute
Concerning , we have the following results:
Lemma 10.
Consider the following penalized regressions:
Then, it follows that
Proof of Lemma 10.
Applying the matrix inversion lemma to , we have
Postmultiplying (28) by yields . Given , we thus have . Similarly, we can obtain . □
Lemma 11.
can be calculated by the following penalized regressions:
and
Proof of Lemma 11.
3.4. Penalized Regression to Compute
Concerning , we have the following results:
Lemma 12.
Let . Then, it follows that
Proof of Lemma 12.
Remark 5.
Similarly to Remark 2, we add some more exposition about (25). Let be such that . As stated, . Then, it follows that
3.5. Ordinary Regressions to Compute and
Concerning and , we have the following results:
Lemma 13.
- (i)
- Let , whereThen, it follows that
- (ii)
- It follows that , where
Proof of Lemma 13.
Given Proposition 1, both results are easily obtainable. For example, the former result can be proved as follows:
□
Remark 6.
From Proposition 1, we also have , where
3.6. Principle of Duality in the Penalized Regressions
See the second columns of Table 1 and Table 2. In the columns, the penalized regressions shown above are arranged in pairs that mirror one another. We reveal a principle of duality in the penalized regressions. As stated in Section 1, (D1) is obtainable by replacing in (P1) by , respectively. Likewise, for example, (D6) in Table 2 is obtainable by replacing in (P6) by , respectively. In Table 1 and Table 2, we may observe five other pairs of regressions that are duals of each other. From the seven dual pairs shown in Table 1 and Table 2, we observe that the following principle exists:
4. Results That Are Obtainable from the Regressions
In this section, we show how the regressions listed in the previous section are of use to obtain a deeper understanding of the fitting a cubic smoothing spline. Before proceeding, recall and so on.
First, given that (16) is a ridge regression, it immediately follows that , which leads to and at the same time we have
Third, from (19) and , we have
Thus, can be represented as
Here, we remark that, given that is a smoother matrix, the second term on the right-hand side of (50) represents a low-frequency part of . In addition, from (49), represents a high-frequency part of . Thus, is generally smoother than .
Fourth, given , , , and , we have
Sixth, given , we have
Note that , for example, indicates that the sum of the entries in each row of the hat matrix of equals unity.
5. Illustrations of Some Results
In this section, we illustrate some of the results in the previous sections by a real data example.
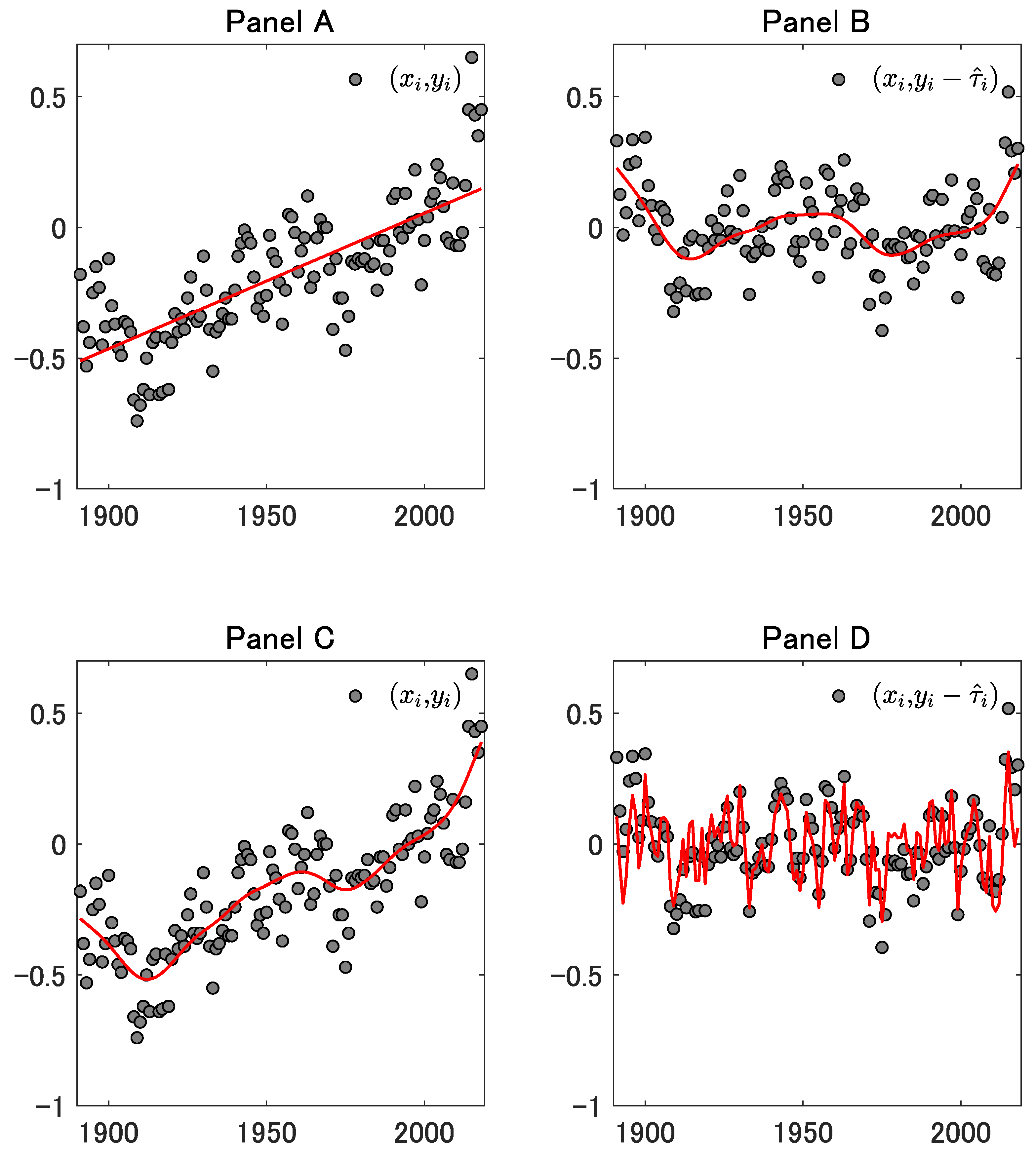
Panel A of Figure 1 shows a scatter plot of North Pacific sea surface temperature (SST) anomalies (1891–2018). SST is an essential climate variable and has been used for the detection of climate change. See, for example, Høyer and Karagali [7] and the references therein. We obtained the data from the website of the Japan Meteorological Agency. The solid line in the panel plots for , where in (4) and . Panel B of Figure 1 depicts a scatter plot of for . The solid line in the panel plots for , where is calculated by (18) with . The solid line in Panel C denotes , where is calculated by (14) with . Panel D illustrates a scatter plot of for . The solid line in the panel plots for , where is calculated by (27) with . Figure 2, Figure 3 and Figure 4 correspond to the cases such that , respectively.
6. The Cases Such That the Other Right-Inverse Matrices Are Used
In this section, we illustrate what happens if the other right-inverse matrices are used.
Let be of full row rank. Recall that in this paper denotes , which is a right-inverse matrix of a full-row-rank matrix . Define a set of matrices
denotes the set of right-inverse matrices of and accordingly belongs to .
Lemma 14.
if and only if and .
Proof of Lemma 14.
It is clear that if , then and . Conversely, suppose that and . Then, and there exists a nonsingular matrix such that . By removing from these equations, we have , which leads to . □
From Lemma 14, if , then or . Accordingly, we have the following result:
Proposition 3.
If , then .
Based on the result, we illustrate what happens if the other right-inverse matrices are used. We give an example. Let . Then, from Proposition 3 and Lemma 3, it follows that . Accordingly, letting , it follows that and . In addition, given that , , and is of full column rank, is nonsingular. Thus, from [8], for example, we have
where
and
which shows that we may obtain (penalized) regressions relating to the cubic smoothing spline even if we use the other right-inverse matrices of such that . Nevertheless, as illustrated here, they are more complex than those shown in Table 1 and Table 2.
7. Concluding Remarks
In this paper, we provided a comprehensive list of penalized least squares regressions relating to the cubic smoothing spline, and then revealed a principle of duality in them. This is the main contribution of this study. Such penalized regressions are tabulated in Table 1 and Table 2 and the principle of duality revealed is stated in Proposition 2. In addition, we also provided a number of results derived from them, most of which are also tabulated in Table 1 and Table 2 and some of which are illustrated in Figure 1, Figure 2, Figure 3 and Figure 4.
Author Contributions
R.D. wrote an initial draft under the supervision of H.Y. and then H.Y. edited the manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
The Japan Society for the Promotion of Science supported this work through KAKENHI Grant Number 16H03606.
Acknowledgments
We thank Kazuhiko Hayakawa and three anonymous referees for their valuable comments on an earlier version of this paper. The usual caveat applies.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Appendix A.1. Some Remarks on a Special Case Such That x = [1,…,n]⊤
- (i)
- If , then , which is a Toeplitz matrix of which the first (resp. last) row is (resp. ).
- (ii)
- If , then is bisymmetric (i.e., symmetric centrosymmetric), which may be proved as in Yamada (2020a).
- (iii)
- (iv)
It is a type of the Whittaker–Henderson (WH) method of graduation, which was developed by Bohlmann [10], Whittaker [11] and others. See Weinert [12] for a historical review of the WH method of graduation. (A3) is also referred to as the Hodrick–Prescott (HP) [13] filtering in econometrics. For more details about the HP filtering, see, for example, Schlicht [14], Kim et al. [15], Paige and Trindade [16], and Yamada [17,18,19,20,21].
Appendix A.2. User-Defined Functions
Appendix A.2.1. A Matlab/GNU Octave Function to Make in (7)

Appendix A.2.2. A Matlab/GNU Octave Function to Make in (8)

Appendix A.2.3. A Matlab/GNU Octave Function to Make in (9)

Appendix A.2.4. A R Function to Make in (7)


Appendix A.2.5. A R Function to Make in (8)

Appendix A.2.6. A R Function to Make in (9)

References
- Schoenberg, I.J. Spline functions and the problem of graduation. Proc. Natl. Acad. Sci. USA 1964, 52, 947–950. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Reinsch, C. Smoothing by spline functions. Numer. Math. 1967, 10, 177–183. [Google Scholar] [CrossRef]
- Green, P.J.; Silverman, B.W. Nonparametric Regression and Generalized Linear Models: A roughness Penalty Approach; Chapman and Hall/CRC: Boca Raton, FL, USA, 1994. [Google Scholar]
- Wood, S.N. Generalized Additive Models: An Introduction with R, 2nd ed.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2017. [Google Scholar]
- Hoerl, A.E.; Kennard, R.W. Ridge regression: Biased estimation for nonorthogonal problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Verbyla, A.P.; Cullis, B.R.; Kenward, M.G.; Welham, S.J. The analysis of designed experiments and longitudinal data by using smoothing splines. J. R. Stat. Soc. 1999, 48, 269–311. [Google Scholar] [CrossRef]
- Høyer, J.L.; Karagali, I. Sea surface temperature climate data record for the North Sea and Baltic Sea. J. Clim. 2016, 29, 2529–2541. [Google Scholar] [CrossRef]
- Yamada, H. The Frisch–Waugh–Lovell theorem for the lasso and the ridge regression. Commun. Stat. Theory Methods 2017, 46, 10897–10902. [Google Scholar] [CrossRef]
- Pesaran, M.H. Exact maximum likelihood estimation of a regression equation with a first-order moving-average error. Rev. Econ. Stud. 1973, 40, 529–535. [Google Scholar] [CrossRef]
- Bohlmann, G. Ein ausgleichungsproblem. Nachrichten von der Gesellschaft der Wissenschaften zu Gottingen, Mathematisch-Physikalische Klasse 1899, 1899, 260–271. [Google Scholar]
- Whittaker, E.T. On a new method of graduation. Proc. Edinb. Math. Soc. 1923, 41, 63–75. [Google Scholar] [CrossRef] [Green Version]
- Weinert, H.L. Efficient computation for Whittaker–Henderson smoothing. Comput. Stat. Data Anal. 2007, 52, 959–974. [Google Scholar] [CrossRef]
- Hodrick, R.J.; Prescott, E.C. Postwar U.S. business cycles: An empirical investigation. J. Money Credit. Bank. 1997, 29, 1–16. [Google Scholar] [CrossRef]
- Schlicht, E. Estimating the smoothing parameter in the so-called Hodrick–Prescott filter. J. Jpn. Stat. Soc. 2005, 35, 99–119. [Google Scholar] [CrossRef] [Green Version]
- Kim, S.; Koh, K.; Boyd, S.; Gorinevsky, D. ℓ1 trend filtering. SIAM Rev. 2009, 51, 339–360. [Google Scholar] [CrossRef]
- Paige, R.L.; Trindade, A.A. The Hodrick–Prescott filter: A special case of penalized spline smoothing. Electron. J. Stat. 2010, 4, 856–874. [Google Scholar] [CrossRef]
- Yamada, H. Ridge regression representations of the generalized Hodrick–Prescott filter. J. Jpn. Stat. Soc. 2015, 45, 121–128. [Google Scholar] [CrossRef] [Green Version]
- Yamada, H. Why does the trend extracted by the Hodrick–Prescott filtering seem to be more plausible than the linear trend? Appl. Econ. Lett. 2018, 25, 102–105. [Google Scholar] [CrossRef]
- Yamada, H. Several least squares problems related to the Hodrick–Prescott filtering. Commun. Stat. Theory Methods 2018, 47, 1022–1027. [Google Scholar] [CrossRef]
- Yamada, H. A note on Whittaker–Henderson graduation: Bisymmetry of the smoother matrix. Commun. Stat. Theory Methods 2020, 49, 1629–1634. [Google Scholar] [CrossRef]
- Yamada, H. A smoothing method that looks like the Hodrick–Prescott filter. Econom. Theory 2020. [Google Scholar] [CrossRef]
Figure 1.
Panel A shows a scatter plot of North Pacific sea surface temperature anomalies (1891–2018). The solid line in the panel plots for , where in (4) and . Panel B depicts a scatter plot of for . The solid line in the panel plots for , where is calculated by (18) with . The solid line in Panel C denotes , where is calculated by (14) with . Panel D illustrates a scatter plot of for . The solid line in the panel plots for , where is calculated by (27) with .
Figure 1.
Panel A shows a scatter plot of North Pacific sea surface temperature anomalies (1891–2018). The solid line in the panel plots for , where in (4) and . Panel B depicts a scatter plot of for . The solid line in the panel plots for , where is calculated by (18) with . The solid line in Panel C denotes , where is calculated by (14) with . Panel D illustrates a scatter plot of for . The solid line in the panel plots for , where is calculated by (27) with .

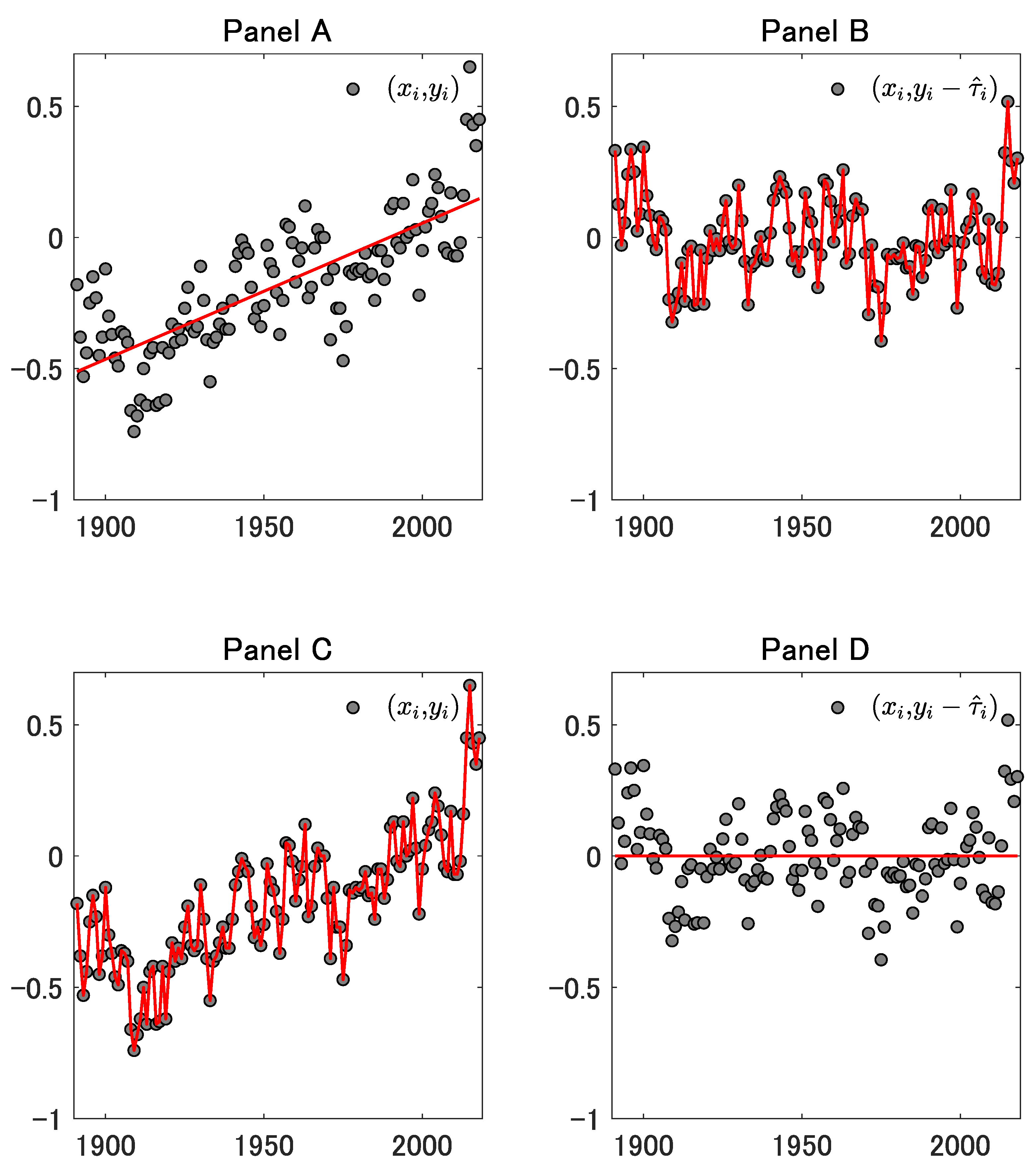
Figure 2.
This figure corresponds to the case where . For the other explanations, see Figure 1.
Figure 2.
This figure corresponds to the case where . For the other explanations, see Figure 1.

Figure 3.
This figure corresponds to the case where . For the other explanations, see Figure 1.
Figure 3.
This figure corresponds to the case where . For the other explanations, see Figure 1.

Figure 4.
This figure corresponds to the case where . For the other explanations, see Figure 1.
Figure 4.
This figure corresponds to the case where . For the other explanations, see Figure 1.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Most of the main results (I).
| Regressions Relating to the Cubic Smoothing Spline | Average | Sum | ⊥ | ||||
|---|---|---|---|---|---|---|---|
| (P1) | 1 | ||||||
| (D1) | 1 | ||||||
| (P2) | , where | 0 | 0 | ∘ | |||
| (D2) | , where | 0 | 0 | ∘ | |||
| (P3) | 0 | 0 | ∘ | ||||
| (D3) | 0 | 0 | ∘ | ||||
| (P4) | , where | 0 | 0 | ∘ | |||
| (D4) | , where | 0 | 0 | ∘ | |||
| , where | 1 |
. . . for . . is a smoothing/tuning parameter. . denotes the column space of . ‘Sum’ denotes the sum of the entries in each row of the hat matrices. ∘ indicates that the corresponding component belongs to the orthogonal complement of .
Table 2.
Most of the main results (II).
| Regressions Relating to the Cubic Smoothing Spline | Average | Sum | ⊥ | ||||
|---|---|---|---|---|---|---|---|
| (P5) | 1 | ||||||
| (D5) | 1 | ||||||
| (P6) | , where | 0 | 0 | ∘ | |||
| (D6) | , where | 0 | 0 | ∘ | |||
| (P7) | 0 | 0 | ∘ | ||||
| (D7) | 0 | 0 | ∘ |
. . . is a smoothing/tuning parameter. . denotes the column space of , where . ‘Sum’ denotes the sum of the entries in each row of the hat matrices. ∘ indicates that the corresponding component belongs to the orthogonal complement of .
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Du, R.; Yamada, H. Principle of Duality in Cubic Smoothing Spline. Mathematics 2020, 8, 1839. https://doi.org/10.3390/math8101839
AMA Style
Du R, Yamada H. Principle of Duality in Cubic Smoothing Spline. Mathematics. 2020; 8(10):1839. https://doi.org/10.3390/math8101839
Chicago/Turabian StyleDu, Ruixue, and Hiroshi Yamada. 2020. "Principle of Duality in Cubic Smoothing Spline" Mathematics 8, no. 10: 1839. https://doi.org/10.3390/math8101839
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.