Automatic Changes Detection between Outdated Building Maps and New VHR Images Based on Pre-Trained Fully Convolutional Feature Maps


Abstract
:1. Introduction
2. Methods
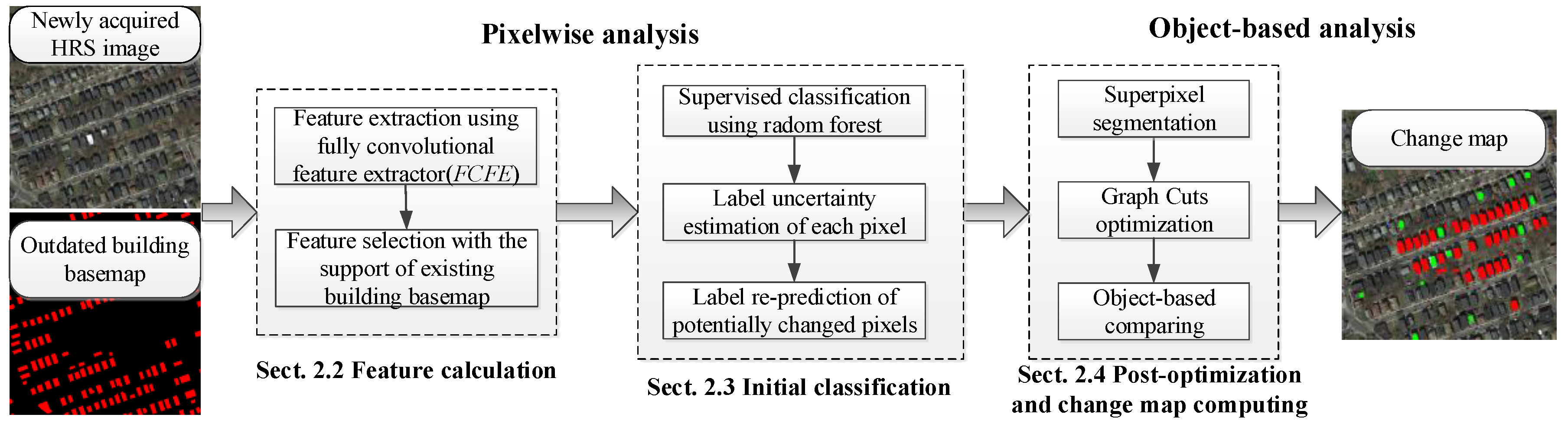
2.1. Overview of the Method
- (1)
- Feature calculation, which is a fully convolutional feature extractor reconstructed from FCN-8s [17] and pre-trained on the PASCAL VOC dataset. Feature calculation extracts multi-scale pixel-wise features from newly acquired HRS images. An RF classifier is then trained to rank the importance of the extracted features based on the outdated basemap. After that, representative features are selected as feature descriptors for each pixel.
- (2)
- Initial classification, where the label uncertainty for each pixel is estimated through cross-validation based on selected features. The reliable (unchanged) pixels are then separated as training samples to train the new RF classifier, and potentially changed pixels are re-predicted.
- (3)
- Post optimization and change map computing, where the SLIC (Simple Linear Iterative Cluster) algorithm [35] is used to segment HRS images into superpixels, and the probability of superpixels for each label is estimated. The negative logarithm of probability is then used to construct the data term. A Gaussian kernel of normalized RGB feature is then used to construct a smooth term of the energy function. After that, the graph cuts algorithm is used to minimize the energy function and obtain the optimized, updated label. The updated labels are finally compared with the outdated basemap to compute the change map.
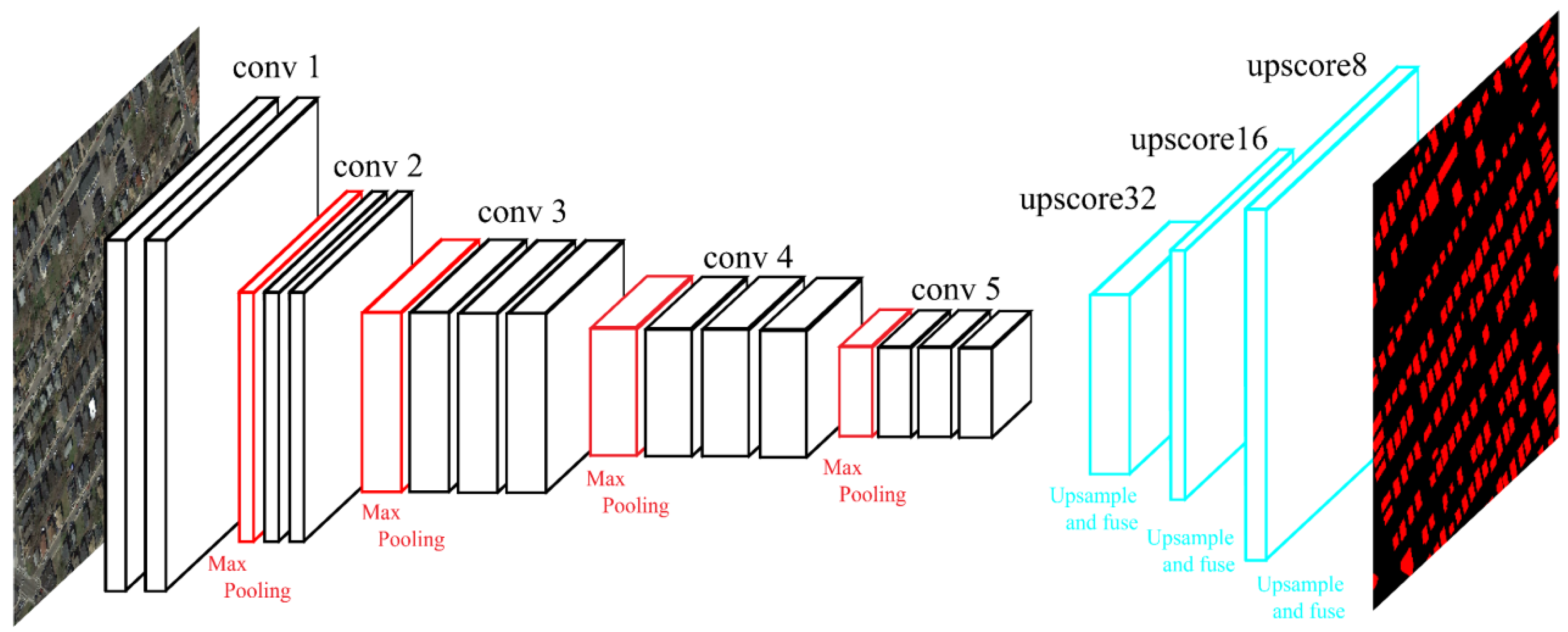
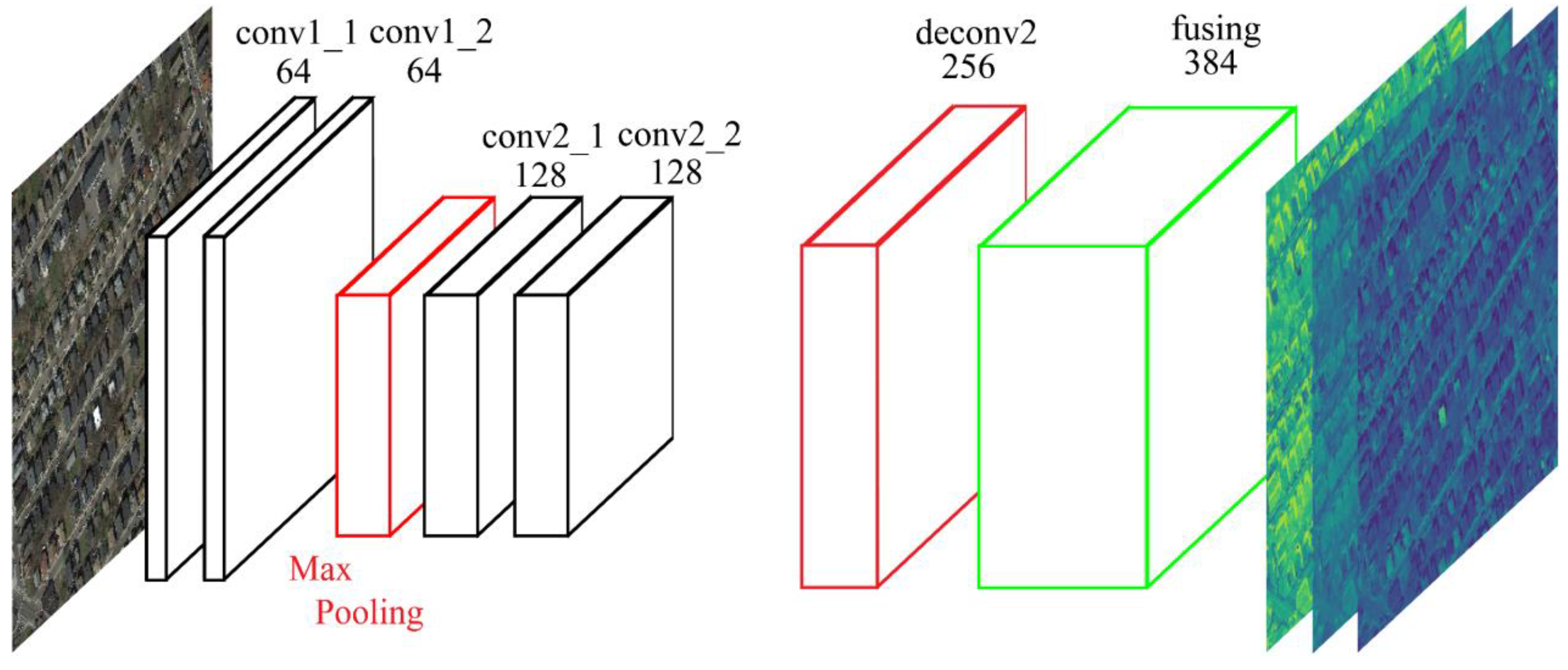
2.2. Feature Extraction through Fully Convolutional Feature Extractor
2.2.1. Structure of the Proposed Fully Convolutional Feature Extractor
2.2.2. Feature Selection Guided by the Existing Basemaps Using Random Forest
2.3. Initial Classification by Automatic Sample Selection Using RF
| Algorithm 1. Label uncertainty estimation |
| Input: S (sample set, i.e., pixel index from HRS image) with F (features from Section 2.2), L (noisy label acquired from the existing basemaps); kmax (pre-defined times of dataset partition); Nest (number of RF meta-estimators); Dmax (max depth of the decision trees in RF) Procedure:
Output: Accumulator Mu indicating the label uncertainty of S. |
2.4. Post-Optimization Using Graph Cuts and Change Map Computing
3. Experimental Results and Discussion
3.1. Experiment Setup
3.1.1. Datasets Description
3.1.2. Assessment Criteria
3.1.3. Parameters Setting
3.2. Results of ISPRS Simulated Data
3.2.1. Change Detection Results
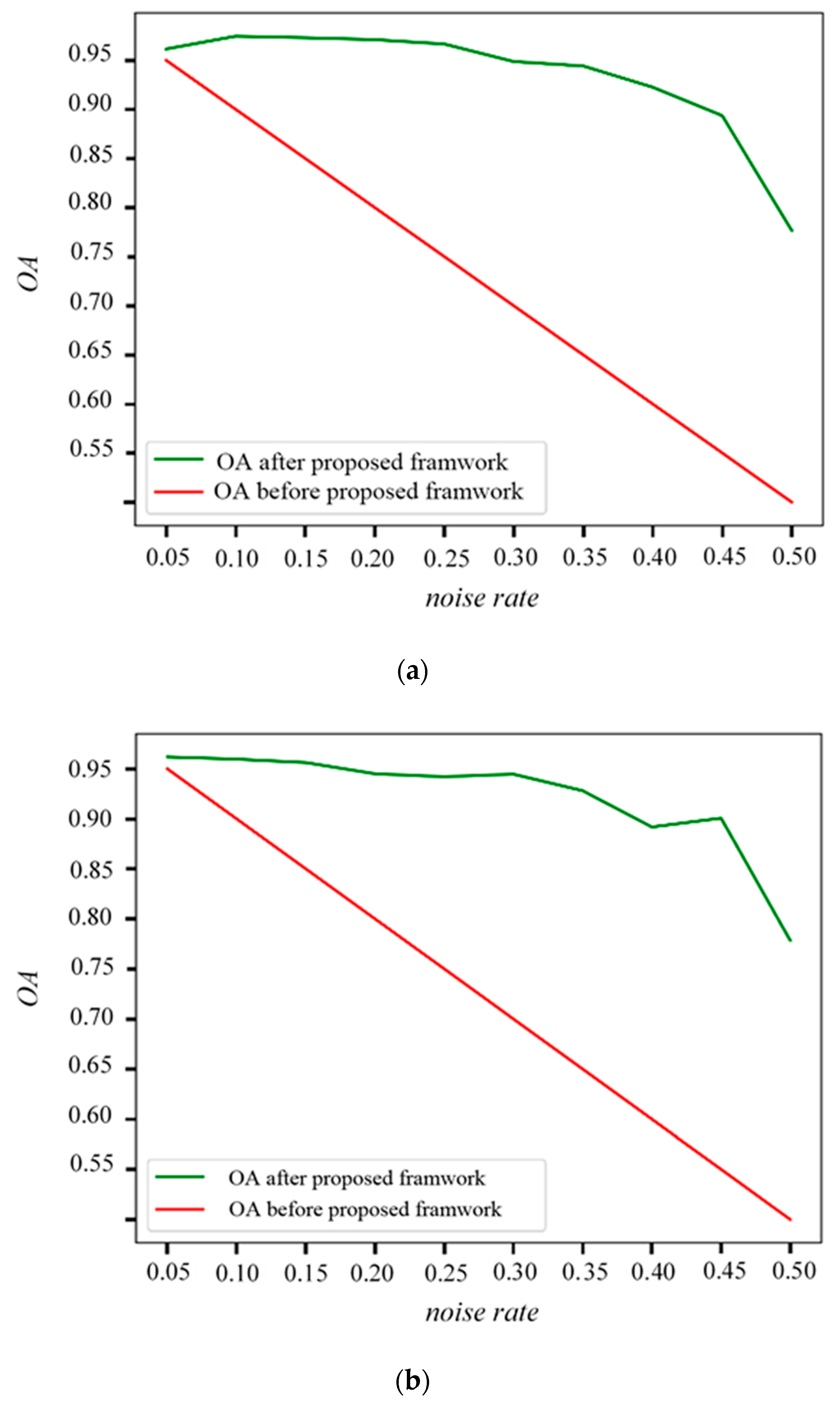
3.2.2. Results with Different Label Noise Levels
3.3. Results of Boston Real Dataset
3.3.1. Detection Results
3.3.2. Performance Comparison
4. Conclusions and Future Works
Author Contributions
Funding
Conflicts of Interest
References
- Chen, J.; Lu, M.; Chen, X.; Chen, J.; Chen, L. A spectral gradient difference based approach for land cover change detection. ISPRS J. Photogram. Remote Sens. 2013, 85, 1–12. [Google Scholar] [CrossRef]
- Kalnay, E.; Cai, M. Impact of urbanization and land-use change on climate. Nature 2003, 423, 528–531. [Google Scholar] [CrossRef] [PubMed]
- Dong, L.; Shan, J. A comprehensive review of earthquake-induced building damage detection with remote sensing techniques. ISPRS J. Photogram. Remote Sens. 2013, 84, 85–99. [Google Scholar] [CrossRef]
- Han, D. Construction monitoring of civil structures using high resolution remote sensing images. In Proceedings of the 13th SGEM GeoConference on Informatics, Geoinformatics and Remote Sensing, Albena, Bulgaria, 16–22 June 2013; pp. 595–600. [Google Scholar]
- Bouziani, M.; Goïta, K.; He, D.C. Automatic change detection of buildings in urban environment from very high spatial resolution images using existing geodatabase and prior knowledge. ISPRS J. Photogram. Remote Sens. 2010, 65, 143–153. [Google Scholar] [CrossRef]
- Dianat, R.; Kasaei, S. Change detection in optical remote sensing images using difference-based methods and spatial information. IEEE Geosci. Remote Sens. Lett. 2009, 7, 215–219. [Google Scholar] [CrossRef]
- Tewkesbury, A.P.; Comber, A.J.; Tate, N.J.; Lamb, A.; Fisher, P.F. A critical synthesis of remotely sensed optical image change detection techniques. Remote Sens. Environ. 2015, 160, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Guo, Z.; Du, S. Mining parameter information for building extraction and change detection with very high-resolution imagery and GIS data. GISci. Remote Sens. 2017, 54, 3–63. [Google Scholar] [CrossRef]
- Kaiser, P.; Wegner, J.D.; Lucchi, A.; Jaggi, M.; Hofmann, T.; Schindler, K. Learning aerial image segmentation from online maps. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6054–6068. [Google Scholar] [CrossRef]
- Taili, W.; Hongyang, L.; Qikai, L.; Nianxue, L. Classification of high-resolution remote-sensing image using openstreetmap information. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2305–2309. [Google Scholar]
- Gevaert, C.M.; Persello, C.; Elberink, S.O.; Vosselman, G.; Sliuzas, R. Context-based filtering of noisy labels for automatic basemap updating from UAV data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 11, 2731–2741. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, Y.; Nie, K.; Li, X.; Wang, W. Extracting building areas from photogrammetric DSM and DOM by automatically selecting training samples from historical DLG data. ISPRS Int. J. Geo-Inf. 2020, 9, 18. [Google Scholar] [CrossRef] [Green Version]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Mirzapour, F.; Ghassemian, H. Using GLCM and Gabor filters for classification of PAN images. In Proceedings of the 2013 21st Iranian Conference on Electrical Engineering (ICEE), Mashhad, Iran, 14–16 May 2013; pp. 1–6. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015; pp. 3431–3440. [Google Scholar]
- Yao, C.; Luo, X.; Zhao, Y.; Zeng, W.; Chen, X. A review on image classification of remote sensing using deep learning. In Proceedings of the 2017 3rd IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 13–16 December 2017; pp. 1947–1955. [Google Scholar]
- Cheriyadat, A.M. Unsupervised feature learning for aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 439–451. [Google Scholar] [CrossRef]
- Zhang, P.; Gong, M.; Su, L.; Liu, J.; Li, Z. Change detection based on deep feature representation and mapping transformation for multi-spatial-resolution remote sensing images. ISPRS J. Photogram. Remote Sens. 2016, 116, 24–41. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Marmanis, D.; Datcu, M.; Esch, T.; Stilla, U. Deep Learning Earth Observation Classification Using ImageNet Pretrained Networks. IEEE Geosci. Remote Sens. Lett. 2015, 13, 105–109. [Google Scholar] [CrossRef] [Green Version]
- Bei, Z.; Bo, H.; Zhong, Y. Transfer learning with fully pretrained deep convolution networks for land-use classification. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1436–1440. [Google Scholar]
- Penatti, O.A.B.; Nogueira, K.; Dos Santos, J.A. Do deep features generalize from everyday objects to remote sensing and aerial scenes domains? In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Boston, MA, USA, 7–12 June 2015; pp. 44–51. [Google Scholar]
- Fan, H.; Xia, G.S.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar]
- Paoletti, M.E.; Haut, J.M.; Plaza, J.; Plaza, A. A new deep convolutional neural network for fast hyperspectral image classification. ISPRS J. Photogram. Remote Sens. 2018, 145, 120–147. [Google Scholar] [CrossRef]
- Gong, J.; Hu, X.; Pang, S.; Li, K. Patch matching and dense CRF-based co-refinement for building change detection from Bi-temporal aerial images. Sensors 2019, 19, 1557. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, X.; Zhang, L. An SVM ensemble approach combining spectral, structural, and semantic features for the classification of high-resolution remotely sensed imagery. IEEE Trans. Geosci. Remote Sens. 2013, 51, 257–272. [Google Scholar] [CrossRef]
- Chen, G.; Hay, G.J.; Carvalho, L.M.T.; Wulder, M.A. Object-based change detection. Int. J. Remote Sens. 2012, 33, 4434–4457. [Google Scholar] [CrossRef]
- Griffiths, P.; Hostert, P.; Gruebner, O.; Linden, S.V.D. Mapping megacity growth with multi-sensor data. Remote Sens. Environ. 2010, 114, 426–439. [Google Scholar] [CrossRef]
- Du, P.; Liu, S.; Gamba, P.; Tan, K.; Xia, J. Fusion of difference images for change detection over urban areas. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 1076–1086. [Google Scholar] [CrossRef]
- Hussain, M.; Chen, D.; Cheng, A.; Wei, H.; Stanley, D. Change detection from remotely sensed images: From pixel-based to object-based approaches. ISPRS J. Photogram. Remote Sens. 2013, 80, 91–106. [Google Scholar] [CrossRef]
- Ma, L.; Li, M.; Thomas, B.; Ma, X.; Dirk, T.; Liang, C.; Chen, Z.; Chen, D. Object-Based Change Detection in Urban Areas: The effects of segmentation strategy, scale, and feature space on unsupervised methods. Remote Sens. 2016, 8, 761. [Google Scholar] [CrossRef] [Green Version]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogram. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef] [Green Version]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC Superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Li, Z.; Han, J.; Yao, X.; Guo, L. Exploring hierarchical convolutional features for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 1–11. [Google Scholar] [CrossRef]
- Matthew, D.; Fergus, R. Visualizing and understanding convolutional neural networks. In Proceedings of the 13th European Conference Computer Vision and Pattern Recognition (ECCV), Zurich, Switzerland, 5–12 September 2014; pp. 6–12. [Google Scholar]
- Kemker, R.; Salvaggio, C.; Kanan, C. Algorithms for semantic segmentation of multispectral remote sensing imagery using deep learning. ISPRS J. Photogram. Remote Sens. 2018, 145, 60–77. [Google Scholar] [CrossRef] [Green Version]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. RefineNet: Multi-path Refinement Networks for High-Resolution Semantic Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5168–5177. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Chen, J.J.; Yuan, C.; Deng, M.; Tao, C.; Peng, J.; Li, H. On the Selective and Invariant Representation of DCNN for High-Resolution Remote Sensing Image Recognition. arXiv 2017, arXiv:1708.01420. [Google Scholar]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Belgiu, M.; Dragut, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogram. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Breiman, L. Random Forest. In Machine Learning; Springer: Berlin, Germany, 2001; Volume 45, pp. 5–32. [Google Scholar]
- Zhu, X.; Wu, X. Class Noise vs. Attribute Noise: A Quantitative Study. Artif. Intell. Rev. 2004, 22, 177–210. [Google Scholar] [CrossRef]
- Zhuqiang, L.; Liqiang, Z.; Ruofei, Z.; Tian, F.; Liang, Z.; Zhenxin, Z. Classification of urban point clouds: A robust supervised approach with automatically generating training data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 1–14. [Google Scholar]
- Boykov, Y.Y.; Jolly, M. Interactive graph cuts for optimal boundary & region segmentation of objects in N-D images. In Proceedings of the Eighth IEEE International Conference on Computer Vision, ICCV 2001, Vancouver, BC, Canada, 7–14 July 2001; pp. 105–112. [Google Scholar]
- Boykov, Y.; Kolmogorov, V. An experimental comparison of min-cut/max- flow algorithms for energy minimization in vision. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 1124–1137. [Google Scholar] [CrossRef] [Green Version]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Zhang, L.; Zhang, L.; Bo, D. Deep Learning for Remote Sensing Data: A Technical Tutorial on the State of the Art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Source | Size (pixels) | Spatial Resolution (m) | |
|---|---|---|---|---|
| ISPRS simulated dataset | a | Aerial | 1996 × 1995 | 0.09 |
| b | Aerial | 2818 × 2558 | 0.09 | |
| Boston real dataset | c | Google Earth | 1031 × 1097 | 1 |
| d | Google Earth | 1132 × 1139 | 1 | |
| e | Google Earth | 1159 × 1179 | 1 | |
| Method | Dataset (c) | Dataset (d) | Dataset (e) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Comp | FDR | OA | Comp | FDR | OA | Comp | FDR | OA | |
| Proposed | 0.861 | 0.269 | 0.942 | 0.878 | 0.268 | 0.966 | 0.890 | 0.223 | 0.963 |
| A | 0.736 | 0.645 | 0.798 | 0.784 | 0.732 | 0.822 | 0.762 | 0.733 | 0.761 |
| B | 0.419 | 0.495 | 0.874 | 0.246 | 0.594 | 0.919 | 0.304 | 0.600 | 0.887 |
| C | 0.746 | 0.431 | 0.896 | 0.759 | 0.372 | 0.948 | 0.755 | 0.468 | 0.907 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Zhu, Y.; Li, H.; Chen, S.; Peng, J.; Zhao, L. Automatic Changes Detection between Outdated Building Maps and New VHR Images Based on Pre-Trained Fully Convolutional Feature Maps. Sensors 2020, 20, 5538. https://doi.org/10.3390/s20195538
Zhang Y, Zhu Y, Li H, Chen S, Peng J, Zhao L. Automatic Changes Detection between Outdated Building Maps and New VHR Images Based on Pre-Trained Fully Convolutional Feature Maps. Sensors. 2020; 20(19):5538. https://doi.org/10.3390/s20195538
Chicago/Turabian StyleZhang, Yunsheng, Yaochen Zhu, Haifeng Li, Siyang Chen, Jian Peng, and Ling Zhao. 2020. "Automatic Changes Detection between Outdated Building Maps and New VHR Images Based on Pre-Trained Fully Convolutional Feature Maps" Sensors 20, no. 19: 5538. https://doi.org/10.3390/s20195538