
Abstract
Water injection is one of the robust techniques to maintain the reservoir pressure and produce trapped oil from oil reservoirs and improve an oil recovery factor. However, incompatibility between injected water and reservoir water causes an unflavored issue named “scale deposition.” Owing to the deposited scales, effective permeability of a reservoir reduced, and pore throats might be plugged. To determine formation damage owing to scale deposition during a water injection process, two well-known machine learning methods, least squares support vector machine (LSSVM) and artificial neural network (ANN), are employed in the present paper. To improve the performance of the LSSVM method, a metaheuristic optimization algorithm, genetic algorithm (GA), is used. The constructed LSSVM model is examined using real formation damage data samples experimentally measured, which was reported in the literature. According to the obtained outputs of the above models, LSSVM has a high performance based on the correlation coefficient, and infinitesimal uncertainty based on a relative error between the model predictions and the corresponding actual data samples was less than 15%. Outcomes from this study indicate the useful application of the LSSVM approach in the prediction of permeability reduction due to scale deposition, and it can lead to a better and more reliable understanding of formation damage effects through water flooding without expensive laboratory measurements.
Similar content being viewed by others


Introduction
Detrimental mineral deposition in formations that are operated to produce oil is known as one of the most problematic issues in the petroleum industry, especially when scales of barium and calcium sulfate cause a significant reduction in permeability due to pore throat plugs in reservoir rocks. Besides, these scales can adversely affect the productivity of wells through blocking tubing and casings (Boon et al. 1983; Cusack et al. 1987; Ahmed 2004). A mineral deposition is heavily and strongly influenced by a variety of parameters such as temperature fluctuation, pressure reduction, and getting mixed incompatible waters (Bertero et al. 1988; BinMerdhah et al. 2010; Moghadasi 2004).
Moreover, deposition of sulfate scales is mainly caused by the injection of seawater saturated with sulfate anion into a formation containing high calcium, strontium, and barium cations for water flooding (Crabtree et al. 1999; Moghadasi et al. 2004; Frenier and Ziauddin 2008; Khatami et al. 2010; McElhiney 2001; Collins 2005). As for water incompatibility, barium sulfate scales are also formed with changes in the pressure, temperature, and concentration of relevant ions (BinMerdhah et al. 2010; Crabtree et al. 1999; Frenier and Ziauddin 2008; Liu et al. 2009). Based on the experiments done by Mitchell et al. (1980), taking inhibitor selection as the main topic results in concluding barium sulfate scale precipitations as the particular major problem of North Sea fields (Mitchell et al. 1980). The acquired result was later shown by Read and Ringen, who injected a mixture of seawater and North Sea formation water to synthetic alumina cores under special conditions, and a considerable reduction in permeability was observed due to scaling (Read and Ringen 1982). The possibility of calcium sulfate and strontium sulfate scaling due to seawater injection was experimentally evaluated on samples gathered from an Arab-D reservoir in the northern area of the Ghawar field. Lindlof and Stoffer (1983) finalized that the amounts of strontium sulfate precipitation certified their already calculations, and a mixture of seawater and Arab-D formation water caused the existence of scale formation in the wellbore when the flow was turbulent.
Scale formation as a result of incompatibility between injected seawater and formation water once again turned into a topic that investigated the Namorado field in Brazil. Precipitation stopping procedures were accompanied by a high rate of water production to block formations of strontium and barium sulfate, studied by Bezerra et al. (1990). Aliaga et al. (1992) showed the wavy behavior of dissolution and precipitation in the reservoir. They conducted flooding experiments in sand packs to study and quantify a permeability reduction and inferred that geochemical flow models can be employed in a case of having solid migration. Considerable scale deposition can occur when two incompatible waters were injected concurrently into a rock core, a result that was deduced when a sensitivity analysis was run to observe the effect of temperature on barium and strontium sulfate scale formation. According to tests performed to investigate scale formation kinetics, Wat (1992) proposed that the kinetics of scale formation plays a significant role in modeling of formation damage. Furthermore, mixing in situ-based synthetic seawater with formation water that has a significant amount of dissolved barium ions leads to making the precipitation of barium sulfate happen. It was observed by McElhiney (2001) when they studied the in situ precipitation of barium sulfate during core flooding experiments. Moghaddasi et al., who proposed a diversity of mechanisms for scale formation as a result of water injection, developed a model to predict correctly scaling deposition as a strong function of hydrodynamic and kinetic conditions in Iranian oil fields (Wat 1992; Moghadasi 2002, 2003a, b; Strachan 2004). CaSO4 precipitation was modeled to be slightly affected by pressure and notably impacted by temperature and a flood velocity, a result presented experimentally and theoretically through studying a permeability reduction as a consequence of mixing two incompatible solutions consisting of Ca2+ and SO42− ions. Strachan (2004) determined the effects of wettability alterations and permeability damages extracted from using aqueous-based polymeric and phosphonate precipitation inhibitors. Bedrikovetsky (2005) have observed that a flow velocity usually influences a reaction rate coefficient, and their studies led to the development of an analytical model to treat data generated with quasi-steady-state tests and later be extended by formulating a formation damage coefficient based on pressure drop measurements during core flooding. Merdhah and Yassin (2007, 2009) reported that increasing temperature, pressure head, and brine concentration had an unfavorable impact on the permeability reduction and reaction rate constant. Clarifying the constant for each model of scale deposition, more accurate for artificial cores than for natural reservoir cores based on a series of core flooding tests dependent on pressure measurements, was done by Carageorgos et al. (2010). Figuring the interaction between reservoir lithology and a scale inhibitor has recently turned into researchers’ interest like Todd (2012), who did some tests within modern phosphorus inhibitors that have some advantages in comparison with the conventional types. A comparison between these kinds of inhibitors alongside a number of other available P-containing polymers was also made. Ahmadi et al. (2017) used data analytics methods to develop a gray-box predictive tool for estimating the permeability reduction in the reservoir. They revealed that the hybrid of evolutionary optimizers could significantly improve the efficacy of the data-driven model.
This study aims to provide a simple machine learning model for estimating permeability reduction due to the scale deposition in a water injection process. Two different types of machine learning methods are employed to fulfill the aim of this paper; ANN and GA-LSSVM methods are those intelligent models used in the current paper. To develop and examine those machine learning models, high accuracy with infinitesimal uncertainty real data from the previous studies (BinMerdhah et al. 2010; Moghadasi et al. 2004; Merdhah and Yassin 2007, 2009; Merdhah et al. 2008; Zabihi et al. 2011) is used. Comparing those experimental results and those correlated with machine learning models in terms of statistical performance indexes provides appropriate information to make a decision on which methods work better.
Least squares support vector machine (LSSVM)
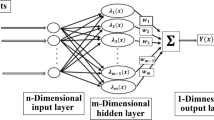
Suykens and Vandewalle (1999) proposed the original LSSVM model in 1999 for function estimation and regression. Overfitting problems may occur through classical SVM and feed-forward neural networks. The objective of the LSSVM is to overcome this hurdle. Consider given inputs Xi (flow rate, pressure difference, temperature, initial permeability, and ions concentration in formation water such as Sr2+, Ba2+, Ca2+, and SO42−) and output Yi (permeability reduction due to formation damage) time series. Table 1 reports the statistical properties of those input data samples employed for developing intelligent models in the current paper. A LSSVM nonlinear function can be represented as follows (Suykens and Vandewalle 1999; Suykens et al. 2002; Kisi 2012; Pelckmans et al. 2002; Ahmadi and Ebadi 2014; Ahmadi et al. 2014a, b):
where f expresses the connection between the target variable (permeability reduction ratio) and input variables (flow rate, pressure difference, temperature, initial permeability, and ions concentration in formation water such as Sr2+, Ba2+, Ca2+, and SO42−), w acts as an m-dimensional weight vector, φ plays a mapping function which maps x into the m-dimensional characteristic vector, and b represents the bias term (Kisi 2012; Ahmadi et al. 2014a).
To minimize the risk of LSSVM structure, we have to solve the following problem (Suykens and Vandewalle 1999; Suykens et al. 2002; Kisi 2012; Pelckmans et al. 2002; Ahmadi and Ebadi 2014; Ahmadi et al. 2014a, b):
But, the following limits should be considered (Suykens and Vandewalle 1999; Suykens et al. 2002; Kisi 2012; Pelckmans et al. 2002; Ahmadi and Ebadi 2014; Ahmadi et al. 2014a, b):
where γ and ek represent the margin parameter and loose variable for xk, respectively (Ahmadi and Pournik 2016; Ahmadi et al. 2015a, b, 2016; Ahmadi and Bahadori 2015).
Developing the limited issue into an unlimited issue and suggesting the Lagrange multipliers αi to figure out the objective function is a robust and effective way that can be used to find the solution of the optimization problem given in Eq. (2) which presents the following expression (Suykens and Vandewalle 1999; Suykens et al. 2002; Kisi 2012; Pelckmans et al. 2002; Ahmadi and Ebadi 2014; Ahmadi et al. 2014a, b):
According to the Karush–Kuhn–Tucker (KKT) investigation, the optimal states can be obtained by conducting the partial derivatives of Eq. (4) with respect to the parameters such as w, b, e, and α, respectively, as follows (Ahmadi et al. 2015a, b, 2016; Ahmadi and Pournik 2016; Ahmadi and Bahadori 2015; Ayatollahi et al. 2016; Hajirezaie et al. 2015, 2017a, b):
Thus, the linear equations are determined as follows: (Suykens and Vandewalle 1999; Suykens et al. 2002; Kisi 2012; Pelckmans et al. 2002; Ahmadi and Ebadi 2014; Ahmadi et al. 2014a, b):
where Y = Y1,…, Yym; Z = φ(X1)TYi,…, φ(Xm)TYm, I = [1,….,1], and α = [α1,…,α1]. By involving the kernel function K(X,Xk) = φ(X)Tφ(Xk), i = 1,2,…,m, the least squares SVM regression is expressed as follows (Ahmadi and Pournik 2016; Ahmadi et al. 2015a, b, 2016; Ahmadi and Bahadori 2015; Ayatollahi et al. 2016; Hajirezaie et al. 2015, 2017a, b; Ahmadi 2015, 2016):
One of the well-known kernels is the radial basis function (RBF) kernel; in this paper, the RBF kernel is employed. It can be formulated as the following equation (Ahmadi and Pournik 2016; Ahmadi et al. 2015a, b, 2016; Ahmadi and Bahadori 2015; Ayatollahi et al. 2016; Hajirezaie et al. 2015, 2017a, b; Ahmadi 2015, 2016):
where \(\sigma^{2}\) represents the squared bandwidth that has to optimize using a robust optimization algorithm, genetic algorithm (GA), during calculations (Suykens and Vandewalle 1999; Suykens et al. 2002; Kisi 2012; Pelckmans et al. 2002; Ahmadi and Ebadi 2014; Ahmadi et al. 2014a, b). The objective function of the optimization approach is the mean squared error (MSE) between the results of the least squares SVM method and the corresponding experimental data samples which can be expressed as (Suykens and Vandewalle 1999; Suykens et al. 2002; Kisi 2012; Pelckmans et al. 2002; Ahmadi and Ebadi 2014; Ahmadi et al. 2014a, b):
where Scale, subscripts est, and act are the forecasted and measured formation damage values, respectively, and ns is the number of data banks from the initial population.
Genetic algorithm (GA)
A genetic algorithm (GA) is an evolutionary optimization algorithm which is developed on the basis of the Darvin hypothesis. According to this hypothesis, each generation of a possible solution is produced by different GA operators, including mutation and crossover of the previous set of solutions. After each generation, a predefined function, called fitness function, is evaluated, and according to this evaluation, possible solutions will be sorted (See Fig. 1) (Niazi et al. 2008). The main advantage of the GA algorithm is that the optimization process is free of derivatives. Hence, it can apply to a broad range of non-linear problems without trapping in local extremums (Reihanian et al. 2011).
Methodology
Data points employed in this paper were divided into two phases, including the testing and training phases. Those that belong to the training phase are employed for training a machine learning model; this phase contains 80% of the whole data bank. Those data points that belong to the testing phase are used to verify the performance and accuracy of the constructed machine learning model; this phase comprises 20% of the whole data bank.
RBF kernel as a simple to use and robust kernel function provides only two hyperparameters to be optimized by GA (Liu et al. 2005a, b). According to Eqs. (9)–(11), optimization of these two hyperparameters, including γ and σ2, plays a vital role in developing an efficient LSSVM model. γ stands for the regularization factor, and σ2 denotes the variance of the kernel (Vong et al. 2006).
As demonstrated in the previous section, to gain optimum values of the LSSVM parameters such as γ and σ2, GA was utilized to minimize the mean squares error (MSE) of the output results of the evolved least squares SVM. The procedure of the GA-LSSVM algorithm is illustrated in Fig. 1. Finally, the values of the global optima, which include σ2 and γ, have been determined as 1.24934 and 0.08245, correspondingly.

The flowchart of hyperparameters selection based on GA
Results and discussion
The gained outcomes from the LSSVM method are demonstrated in Figs. 2, 3, 4, and 5. Figure 2 depicts the comparison between the least squares SVM outputs and the corresponding measured permeability reduction ratio versus the relevant data index. As illustrated in Fig. 2, the obtained results of the least squares SVM covered the relevant experimental permeability reduction ratio. In other words, the outputs of the LSSVM approach have the same behavior as the actual measured data. Figure 3 depicts the scatter or regression plot of the LSSVM output results versus the corresponding experimental formation damage data. As depicted in Fig. 3, the LSSVM outputs follow the red dash line Y = X; this means that the outputs gained from the least squares SVM are the same as the measured permeability reduction data samples. The extracted correlation coefficient from Fig. 3 again shows the high degree of efficiency and accuracy of the LSSVM in monitoring a permeability reduction due to scale deposition during water flooding. Also, to depict the robustness of the LSSVM, the relative deviations of the LSSVM model outcomes from the corresponding actual formation damage are demonstrated in Figs. 4 and 5. Figure 4 exhibits the relative deviation of the least squares SVM outputs versus the relevant experimental data. As can be seen from Fig. 4, the maximum deviation of the LSSVM results is observed in the early boundary. In other words, the maximum deviation of the LSSVM outputs is observed for a permeability reduction between 0.3 and 0.8. One of the possible reasons is the number of training data points for those boundaries were limited, and consequently, the machine learning model is not trained very well for those. Also, as shown in Fig. 4, the maximum relative deviation of the LSSVM outcomes is about 18%. Figure 5 depicts the relative deviation of the LSSVM output results versus the corresponding measured permeability reduction data.

Comparison between the proposed LSSVM model outputs and measured permeability reduction versus data index

Scatter plot of the proposed LSSVM model results against relevant experimental permeability reduction data

Relative deviation of the LSSVM outcomes versus relevant measured permeability reduction data

Relative deviation of the LSSVM outcomes versus relevant data index
To certify the ability of the developed least squares SVM method in monitoring a permeability reduction due to scale deposition, a conventional back-propagation (BP) neural network is also implemented to tackle this obstacle. The interested readers can find more information about ANN in the Refs. (Ahmadi and Chen 2019a, b; Ahmadi and Shadizadeh 2012; Ahmadi 2011). Due to the limitation on the available experimental data in the open literature and the possibility of overfitting in architectures with more than one hidden layer, we decided to use only one hidden layer in our study. In this case, artificial neural network (ANN) performance is highly dependent on various parameters like a number of neurons in the hidden layer. To overcome this hurdle, a sensitivity analysis of ANN model performance versus a number of neurons in the hidden layer was investigated systematically. Owing to this fact, the dependence of the correlation coefficient (R2) and the mean squares error (MSE) of the output results of ANN versus a relevant number of neurons in the hidden layer is demonstrated in Figs. 6 and 7, respectively. Figure 6 depicts the sensitivity of the ANN correlation coefficient versus the corresponding hidden neurons. According to this figure, the best correlation coefficient is achieved for seven hidden neurons. Also, the dependency of the mean squares error (MSE) on a number of neurons in the hidden layer is demonstrated in Fig. 7. Figure 7 certifies that the optimum number of neurons in the hidden layer is equal to 7. The obtained results of the optimized neural network are illustrated in Figs. 8, 9, 10, and 11. Figure 8 exhibits the comparison between ANN results and actual formation damage against the relevant data index. As shown in Fig. 8, the ANN results did not follow the trend of the measured permeability reduction data. Figure 9 demonstrates the correlation between ANN outcomes and the corresponding measured formation damage data. As can be seen from Fig. 9, the outcomes of the network approach deviated from a diagonal line; this means that the ANN model predicts permeability reduction ratio with higher error compared to those predicted by the LSSVM approach. Finally, the relative deviation of the network outputs from the actual permeability reduction data versus the corresponding experimental data and the data index is illustrated in Figs. 10 and 11, respectively. As shown in Fig. 10, the maximum deviation occurred in the early boundary of the permeability reduction ratio. Also, the maximum error of the network approach is about 100 percent, which is not acceptable in any scientific area. Figure 11 demonstrates the relative error of the network model versus the relevant data index for both the training and testing phases. Finally, to wrap up the previous results, Table 2 reports the determined statistical criteria of the least squares SVM and ANN models. According to Table 2, the least squares SVM has a high efficiency compared to the ANN model.

Sensitivity of correlation coefficient versus the number of neurons for permeability reduction monitoring

Sensitivity of mean square error (MSE) versus number neurons for permeability reduction monitoring

Comparison between proposed ANN model outputs and measured formation damage versus data index

Scatter plot of the proposed ANN model results against relevant experimental formation damage data

Relative deviation of the ANN outcomes versus relevant measure permeability reduction data

Relative deviation of the network outcomes versus relevant data index
Figure 12 shows the relative importance of those input parameters employed in the current paper for developing the machine learning models predicts permeability impairment due to scale deposition. As illustrated in Fig. 12, the initial permeability has the highest impact on the permeability reduction ratio.

Relative importance of the input variables on the permeability impairment using Pearson’s correlation
Conclusions
The following main conclusions can be drawn from this study:
-
1.
The traditional feed-forward ANN with a back-propagation training algorithm fails to represent formation damage owning to scale deposition through water flooding in oil reservoirs, but the obtained data from the LSSVM approach are closest to the real formation damage data samples.
-
2.
LSSVM model has only two hyperparameters to be optimized rather than the weight and bias of each input variable in the ANN. This feature of the LSSVM data-driven model makes it easy to use. However, the performance of such a model cannot always be above the ANN model; it depends on the quality, quantity, and the behavior of the system in terms of linearity.
-
3.
The quality and quantity of the data samples play a vital role in the efficacy of the data-driven model. Tuning the proposed machine learning model, including LSSVM and BP-ANN, with new high-quality data samples, can make these predictive tools more reliable, and provide an opportunity for broader applications, especially in industrial scale.
References
Ahmadi MA (2011) Prediction of asphaltene precipitation using artificial neural network optimized by imperialist competitive algorithm. J Petrol Explor Prod Technol 1(2–4):99–106
Ahmadi MA (2015) Connectionist approach estimates gas–oil relative permeability in petroleum reservoirs: application to reservoir simulation. Fuel 140:429–439
Ahmadi MA (2016) Toward reliable model for prediction Drilling Fluid Density at wellbore conditions: a LSSVM model. Neurocomputing 211:143–149
Ahmadi M-A, Bahadori A (2015) A LSSVM approach for determining well placement and conning phenomena in horizontal wells. Fuel 153:276–283
Ahmadi MA, Chen Z (2019a) Comparison of machine learning methods for estimating permeability and porosity of oil reservoirs via petro-physical logs. Petroleum 5(3):271–284
Ahmadi MA, Chen Z (2019b) Machine learning models to predict bottom hole pressure in multi-phase flow in vertical oil production wells. The Canadian Journal of Chemical Engineering 97(11):2928–2940
Ahmadi MA, Ebadi M (2014) Evolving smart approach for determination dew point pressure through condensate gas reservoirs. Fuel 117:1074–1084
Ahmadi MA, Pournik M (2016) A predictive model of chemical flooding for enhanced oil recovery purposes: application of least square support vector machine. Petroleum 2(2):177–182
Ahmadi MA, Shadizadeh SR (2012) New approach for prediction of asphaltene precipitation due to natural depletion by using evolutionary algorithm concept. Fuel 102:716–723
Ahmadi MA, Ebadi M, Hosseini SM (2014a) Prediction breakthrough time of water coning in the fractured reservoirs by implementing low parameter support vector machine approach. Fuel 117:579–589
Ahmadi MA et al (2014b) Evolving predictive model to determine condensate-to-gas ratio in retrograded condensate gas reservoirs. Fuel 124:241–257
Ahmadi MA et al (2015a) Connectionist model for predicting minimum gas miscibility pressure: application to gas injection process. Fuel 148:202–211
Ahmadi M-A, Bahadori A, Shadizadeh SR (2015b) A rigorous model to predict the amount of dissolved calcium carbonate concentration throughout oil field brines: side effect of pressure and temperature. Fuel 139:154–159
Ahmadi MA, Galedarzadeh M, Shadizadeh SR (2016) Low parameter model to monitor bottom hole pressure in vertical multiphase flow in oil production wells. Petroleum 2(3):258–266
Ahmadi MA, Mohammadzadeh O, Zendehboudi S (2017) A cutting edge solution to monitor formation damage due to scale deposition: application to oil recovery. Can J Chem Eng 95(5):991–1003
Ahmed SJ (2004) Laboratory study on precipitation of calcium sulphate in berea sandstone cores. King Fahd University of Petroleum and Minerals, Dhahran
Aliaga D et al (1992) Barium and calcium sulfate precipitation and migration inside sandpacks. SPE formation evaluation 7(01):79–86
Ayatollahi S et al (2016) A rigorous approach for determining interfacial tension and minimum miscibility pressure in paraffin-CO2 systems: application to gas injection processes. J Taiwan Inst Eng 63:107–115
Bedrikovetsky P et al (2005) Characterization of sulphate scaling formation damage from laboratory measurements (to predict well-productivity decline). In: SPE international symposium on oilfield chemistry. Society of Petroleum Engineers
Bertero L et al (1988) Chemical equilibrium models: their use in simulating the injection of incompatible waters. SPE Reserv Eng 3(01):288–294
Bezerra MCM, Khalil CN, Rosario FF (1990) Barium and strontium sulfate scale formation due to incompatible water in the Namorado Fields Campos Basin, Brazil. In: SPE Latin America petroleum engineering conference. Society of Petroleum Engineers
BinMerdhah AB, Yassin AAM, Muherei MA (2010) Laboratory and prediction of barium sulfate scaling at high-barium formation water. J Petrol Sci Eng 70(1–2):79–88
Boon J et al (1983) Reaction between rock matrix and injected fluids in Cold Lake oil sand—spotential for formation damage. J Can Pet Technol 22(04):55–66
Carageorgos T, Marotti M, Bedrikovetsky P (2010) A new laboratory method for evaluation of sulphate scaling parameters from pressure measurements. SPE Reserv Eval Eng 13(03):438–448
Collins IR (2005) Predicting the location of barium sulfate scale formation in production systems. In: SPE international symposium on oilfield scale. Society of Petroleum Engineers
Crabtree M et al (1999) Fighting scale—removal and prevention. Oilfield Rev 11(3):30–45
Cusack F et al (1987) Field and laboratory studies of microbial/fines plugging of water injection wells: mechanism, diagnosis and removal. J Petrol Sci Eng 1(1):39–50
Frenier WW, Ziauddin M (2008) Formation, removal, and inhibition of inorganic scale in the oilfield environment. Society of Petroleum Engineers Richardson, TX
Hajirezaie S et al (2015) A smooth model for the estimation of gas/vapor viscosity of hydrocarbon fluids. J Nat Gas Sci Eng 26:1452–1459
Hajirezaie S, Wu X, Peters CA (2017a) Scale formation in porous media and its impact on reservoir performance during water flooding. J Nat Gas Sci Eng 39:188–202
Hajirezaie S et al (2017b) Development of a robust model for prediction of under-saturated reservoir oil viscosity. J Mol Liq 229:89–97
Khatami H et al (2010) Development of a fuzzy saturation index for sulfate scale prediction. J Petrol Sci Eng 71(1–2):13–18
Kisi O (2012) Modeling discharge-suspended sediment relationship using least square support vector machine. J Hydrol 456:110–120
Lindlof JC, Stoffer KG (1983) A case study of seawater injection incompatibility. J Petrol Technol 35(07):1256–1262
Liu H et al (2005a) Accurate quantitative structure − property relationship model to predict the solubility of C60 in various solvents based on a novel approach using a least-squares support vector machine. J Phys Chem B 109(43):20565–20571
Liu H et al (2005b) Prediction of the tissue/blood partition coefficients of organic compounds based on the molecular structure using least-squares support vector machines. J Comput Aided Mol Des 19(7):499–508
Liu X et al (2009) The analysis and prediction of scale accumulation for water-injection pipelines in the Daqing Oilfield. J Petrol Sci Eng 66(3–4):161–164
McElhiney JE et al (2001) Determination of in situ precipitation of barium sulphate during coreflooding. In: International symposium on oilfield scale. Society of Petroleum Engineers
Merdhah ABB, Yassin AAM (2007) Scale formation in oil reservoir during water injection at high-salinity formation water. J Appl Sci 7(21):3198–3207
Merdhah AB, Yassin AZ (2009) Scale formation due to water injection in Malaysian sandstone cores. Am J Appl Sci 6(8):1531
Merdhah AB, Yassin A, Azam A (2008) Study of scale formation due to incompatible water. Jurnal Teknologi 49:9–26
Mitchell R, Grist D, Boyle M (1980) Chemical treatments associated with North Sea projects. J Petrol Technol 32(05):904–912
Moghadasi J et al (2002) Formation damage in Iranian oil fields. In: International symposium and exhibition on formation damage control. Society of Petroleum Engineers
Moghadasi J et al (2003a) Scale formation in oil reservoir and production equipment during water injection (Kinetics of CaSO4 and CaCO3 crystal growth and effect on formation damage). In: SPE European formation damage conference. Society of Petroleum Engineers
Moghadasi J et al (2003b) Scale formation in Iranian oil reservoir and production equipment during water injection. In: International symposium on oilfield scale. Society of Petroleum Engineers
Moghadasi J et al (2004) Formation damage due to scale formation in porous media resulting from water injection. In: SPE international symposium and exhibition on formation damage control. Society of Petroleum Engineers
Moghadasi J et al (2004) Model study on the kinetics of oil field formation damage due to salt precipitation from injection. J Petrol Sci Eng 43(3–4):201–217
Niazi A, Jameh-Bozorghi S, Nori-Shargh D (2008) Prediction of toxicity of nitrobenzenes using ab initio and least squares support vector machines. J Hazard Mater 151(2–3):603–609
Pelckmans K et al (2002) LS-SVMlab: a matlab/c toolbox for least squares support vector machines. Tutorial 142:1–2
Read PA, Ringen JK (1982) The use of laboratory tests to evaluate scaling problems during water injection. In: SPE oilfield and geothermal chemistry symposium. Society of Petroleum Engineers
Reihanian M et al (2011) Application of neural network and genetic algorithm to powder metallurgy of pure iron. Mater Des 32(6):3183–3188
Strachan C et al (2004) Experience with pre-emptive squeeze treatments on BP magnus with aqueous based scale inhibitors. In: SPE international symposium on oilfield scale. Society of Petroleum Engineers
Suykens JA, Vandewalle J (1999) Least squares support vector machine classifiers. Neural Process Lett 9(3):293–300
Suykens JA, Van Gestel T, De Brabanter J (2002) Least squares support vector machines. World Scientific, Singapore
Todd MJ et al (2012) Phosphorus functionalised polymeric scale inhibitors, further developments and field deployment. In: SPE international conference on oilfield scale. Society of Petroleum Engineers
Vong C-M, Wong P-K, Li Y-P (2006) Prediction of automotive engine power and torque using least squares support vector machines and Bayesian inference. Eng Appl Artif Intell 19(3):277–287
Wat R et al (1992) Kinetics of BaSO4 crystal growth and effect in formation damage. In: SPE formation damage control symposium. Society of Petroleum Engineers
Zabihi R et al (2011) Artificial neural network for permeability damage prediction due to sulfate scaling. J Petrol Sci Eng 78(3–4):575–581
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ahmadi, M., Chen, Z. Machine learning-based models for predicting permeability impairment due to scale deposition. J Petrol Explor Prod Technol 10, 2873–2884 (2020). https://doi.org/10.1007/s13202-020-00941-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13202-020-00941-1