
Abstract
Apple (Malus × domestica Borkh.) is the most widely grown permanent fruit crop of temperate climates. Although commercial apple growing is based on a small number of globally spread cultivars, its diversity is much larger and there are estimates about the existence of more than 10,000 documented varieties. The varietal diversity can be described and determined based on phenotypic characters of the external and internal traits of fruit, which, however, can be modulated by environmental factors. Consequently, molecular methods have become an important alternative means for the characterisation of apple cultivar diversity. In order to use multilocus microsatellite data for determination of unidentified or misidentified apple varieties, a database with molecular genetic fingerprints of well-determined reference cultivars needs to be available. The objective of the present work was to establish such a database that could be applied for the molecular genetic determination of a large number of historic and modern, diploid and triploid apple cultivars. Based on the analysis of more than 1600 accessions of apple trees sampled in 37 public and private cultivar collections in different European countries at 14 variable microsatellite loci, a database with 600 molecular genetic profiles was finally obtained. The key criterion for considering a molecular genetic profile as confirmed and for including it into the reference database was that at least two accessions of the same cultivar of different provenances generated an identical result, which was achieved for 98% of the apple cultivars present in the database. For the remaining genotypes, the cultivar assignment was supported by a parentage analysis or by comparison to molecular genetic profiles available in published works. The database is composed of 574 scion cultivars, 24 rootstock genotypes and two species of crab apples. Of the 574 scion cultivars, 61% were derived from historic or old cultivars, many of which were grown in Central Europe in the past. The remaining scion cultivars are currently grown or available in testing programmes and may gain importance in the future. In order to validate the genotyping data, parentage analysis was performed involving cultivars and rootstocks that arose after 1900, for which information about at least one parent cultivar was available from pomological and scientific literature and the molecular genetic profiles of the assumed parent(s) were also present in our database. This analysis revealed the presence of null alleles at locus COL, however, when excluding this locus, a mean genotyping error rate of only 0.28% per locus was revealed, which points to a high reliability of the dataset. The datasets with 14 and 13 loci (excluding locus COL) showed a high degree of discrimination power, with a combined non-exclusion probability of identity of 2.6 × 10−20 and 3.4 × 10−19. Five of the microsatellite loci analysed in the present study overlapped with another published dataset and after the application of conversion values, it was possible to align the allele lengths and compare the molecular genetic profiles of 20 randomly derived cultivars, which were analysed in both studies. This comparison evidenced an exact correspondence of the microsatellite profiles contained in the two datasets, further pointing to the accuracy of our database. Apart from its application to characterise genetic resources or to manage germplasm collections, the here presented database could serve as an important tool for quality control or as a useful instrument in breeding programmes.
Similar content being viewed by others
Introduction
Apple (Malus × domestica Borkh.) is the most widely grown permanent fruit crop of temperate climates. In Europe, apple was cultivated on an area of 473,500 ha in 2017 and it represented the most common fruit tree species (Eurostat 2019). The domestic apple is an interspecific hybrid originating from Central Asia that had been cultivated since antiquity (Janick 2005; Cornille et al. 2014). In the course of centuries, a multitude of apple varieties had arisen by spontaneous crossing and the trees with the most desirable properties have been selected by humans and further clonally propagated by grafting. Some of the cultivars were grown locally, while others were distributed over larger geographic areas in Europe (Hartmann 2015). Furthermore, trees, scionwood or apple seeds from European countries were disseminated to other continents during the colonisation of the New World, where the selection of new cultivars had been continued (Janick 2005; Volk and Henk 2016).
There are estimates that more than 10,000 apple cultivars had been documented (Janick et al. 1996; Rieger 2006). Europe saw the highest cultivar diversity of apple in the late 19th century, when many different local cultivars were grown in numerous little orchards (Luby 2003). The number of known cultivars in England most probably exceeded 2500, while more than 6000 cultivars were assumed on the territory of the former Soviet Union (Juniper et al. 1998). In the United States, representing a secondary centre of apple cultivar diversification (Janick 2005), more than 7000 apple cultivars were listed between 1804 and 1904 (cited by Volk and Henk 2016). This number, however, may also include synonymous names.
Even though scientific breeding programmes initiated at the beginning of the 20th century, some of the globally most widely grown apple cultivars, such as ‘Golden Delicious’, ‘Red Delicious’ or ‘Granny Smith’ arose as chance seedlings (Brown and Maloney 2003). Only in the recent decades, cultivars obtained by systematic breeding have been gaining more importance on the market. However, many of the breeding programmes relied on a small number of progenitors, posing a risk of reduced genetic diversity of new apple cultivars (Noiton and Alspach 1996; Bannier 2011). Therefore, conservation of the remaining cultivar diversity in germplasm repositories is of utmost importance in order to prevent a future narrowing of the genetic base of apple (Way et al. 1990).
A prerequisite for efficient germplasm management is an exact determination of the cultivars maintained in a collection. Apple cultivars can be described and determined based on phenotypic characters, which mainly focus on the external and internal traits of fruit (Morgan and Richards 2002). Although in the past, there were strong attempts to implement a systematics and a key for determination of apple cultivars, this initiative had failed because cultivars of the domestic apple do represent the same botanical species. Furthermore, phenotypic traits can be modulated by environmental factors and thus render pomological determination more difficult. In addition, a sufficient number of typical fruit has to be available. Finally, the pomological determination requires experienced specialists, which are becoming scarce, as pomology has been widely excluded from the curricula of horticultural science education (Hartmann 2015).
In the last two decades, molecular tools have been implemented as an alternative or additional means to the characterisation of apple cultivar diversity (Guilford et al. 1997; Hokanson et al. 1998). Such methods rely on the direct analysis of DNA, which can be isolated from plant tissue independent of the phenological stage of the tree and which is not affected by environmental influences. The most commonly applied technique is the analysis of simple sequence repeats (SSRs) or microsatellite markers, which, due to their robustness, reproducibility and high-throughput potential, have been employed to describe the genetic resources of apple in many countries (e.g. Guarino et al. 2006; Pereira-Lorenzo et al. 2007; Routson et al. 2009; van Treuren et al. 2010; Garkava-Gustavsson et al. 2013; Ferreira et al. 2016; Gasi et al. 2016; Urrestarazu et al. 2016; Larsen et al. 2017; Testolin et al. 2019).
The main objective of the present study was to establish a database with molecular genetic fingerprints of reference cultivars that could be used for determination of a large number of unidentified or misidentified apple cultivars. A thorough validation of the dataset comprising historic, old and recent apple cultivars was considered crucial in order to assure a high degree of reliability of the database, making it a suitable tool for characterisation of genetic resources but also for other applications.
Materials and Methods
Samples
The present study comprises genotyping data of 1621 accessions of apple trees that were sampled in 37 public and private cultivar collections in different European countries and that can be attributed to 600 different genotypes (see summary in Tables 1 and 2, and extensive information in Supplementary Table S1). The key criterion for including a molecular genetic profile into the reference database was that at least two accessions of the same cultivar of different provenances generated an identical result. Accessions belonging to 570 cultivars were indeed derived from two or more distinct cultivar collections, whereas 19 cultivars were obtained from a single collection, but comprised at least two accessions of different origin. Eleven cultivars were sampled from a single accession, however, in ten instances their cultivar assignment was supported by a parentage analysis or by molecular genetic data derived from other studies (Table 2). The crab apple species M. floribunda 821, which is the progenitor of scab resistance (Rvi6) and was therefore included in the database, was only available from one cultivar collection.
German and English language pomological literature was searched for information about the country and year of origin of each cultivar as well as their parent cultivars (if known). The principal sources of information on old apple cultivars were the books of Morgan and Richards (2002), Silbereisen et al. (2015), Mühl (2001), Votteler (2014), Hartmann (2003, 2015), Bartha-Pichler et al. (2005), Smith (1971), Rolff (2001), Bernkopf et al. (2003) and Bernkopf (2011), cited in the order of consultation significance. For the more recent cultivars, the publications of Sansavini et al. (2012), Brown and Maloney (2003) and Evans et al. (2011) were consulted as were the Community Plant Variety Office (CPVO) Database (https://cpvo.europa.eu/en/applications-and-examinations/cpvo-varieties-database), the United States Patent and Trademark Office (USPTO) online database (http://appft.uspto.gov/netahtml/PTO/index.html) and the UPOV PLUTO: Plant Variety Database (http://www.upov.int/pluto/en/). The information about the origin of the rootstocks investigated in the present study was taken from Webster and Wertheim (2003), NIAB-EMR (2016) and Petzold (1984). In case that the references/databases mentioned above did not provide information about a given cultivar, literature searches specifically targeting that particular cultivar were conducted and cited in Table 2. Based on information about the year of origin, cultivars were classified as (i) historic, if they arose before 1900, as (ii) old, if they originated between 1900 and 1950 and as (iii) recent, if they were bred after 1950.
Nucleic Acid Isolation and Microsatellite DNA Analysis
Nucleic acid was isolated from leaf discs (approximately 100 mg) by direct homogenisation of fresh plant tissue in lysis buffer PL1 of the NucleoSpin Plant II Kit (Macherey-Nagel, Düren, Germany), using a 3-mm tungsten carbide bead (Qiagen, Hilden, Germany) and a Mixer Mill MM300 (Retsch GmbH, Haan, Germany). The remaining steps of the DNA isolation process were performed exactly according to the kit’s manual. Quality and quantity of DNA isolates were controlled by electrophoresis on 1% agarose gels stained with ethidium bromide. DNA isolates were maintained at −20 °C until analysis. Aliquots of DNA isolates were obtained of rootstock samples from East Malling Research (UK) and part of the samples from Haidegg Research Station (Austria).
Each DNA sample was analysed at 14 microsatellite DNA loci described by Liebhard et al. (2002) in four multiplex reactions (Table 3). For each reaction pool, a 10 µl reaction mix was prepared, which contained 200 µM dNTPs, the appropriate concentration of each primer (see Table 3), 1 × GeneAmp PCR Buffer II (Life Technologies, Carlsbad, CA, USA), 1.5 mM MgCl2 (Life Technologies) and 0.5 Units of AmpliTaq Gold Polymerase (Life Technologies). To each 10 µl aliquot of the master mix, 2 µl DNA isolate were added (approximately 10 ng) and amplified on a GeneAmp PCR System 2700 (Life Technologies) under the following conditions: 10 min initial denaturation at 94 °C, 35 cycles with 20 s at 94 °C, 20 s at 57.5 °C and 45 s at 72 °C, followed by 10 min of final extension at 72 °C.
Amplified microsatellite DNA products were separated and visualised on a CEQ 8000 Genetic Analysis System (Beckman Coulter, Fullerton, CA, USA) for 35 min at 7.5 kV. Sizing of fragments relative to the internal CEQ DNA Size Standard 400 (Beckman Coulter) and assignment to specific allele classes were performed by applying the Fragment Analysis Software version 9.0 of the same manufacturer. Each electropherogram was carefully visually inspected for binning accuracy before data were exported. A cross-tabulation matrix in Microsoft Access was employed in order to compare all the molecular genetic profiles at 14 microsatellite loci to each other and to identify exact matches (Baric et al. 2009). All synonymous profiles were represented by a unique genotype (each assigned a distinctive profile number) and included into the final dataset (Supplementary Table S2).
Data Analysis
As the complete dataset comprised diploid and triploid genotypes, the number of alleles per locus and their size ranges were determined by applying the software SPAGeDi version 1.4 (Hardy and Vekemans 2002). In addition, the software CERVUS 3.0.7 (Kalinowski et al. 2007) was employed on a dataset including only diploid genotypes of apple. More precisely, allele frequency and identity analyses were performed on (i) a dataset including all diploid genotypes and the 14 microsatellite loci analysed in this study, (ii) a dataset excluding locus COL, and thus containing data at 13 microsatellite loci, (iii) a dataset containing data at six microsatellite loci (CH01f02, CH02b10, CH02c09, CH02c11, CH02d08, CH01h01) and (iv) a dataset containing data at five microsatellite loci (CH01f02, CH02c09, CH02c11, CH02d08, CH01h01). The latter two reduced sets of microsatellites overlapped with part of the loci employed in the studies of Bus et al. (2012) and Urrestarazu et al. (2016) (see Table 3). The aim of the latter analyses was to calculate the average exclusion probabilities of identical genotypes by using different numbers of loci and to test whether the reduced number of microsatellites would provide sufficient resolution to distinguish genotypes of different apple cultivars, when used as a tool for determination of unknown apple genotypes.
In order to get an impression about the accuracy of genotyping data, parentage analyses were carried out. In a first step, the analysis involved the dataset at 14 microsatellite loci and focused on 85 diploid genotypes of old and recent cultivars, and rootstocks that arose after 1900, for which information about at least one parent cultivar was available and the molecular genetic profile of the assumed parent was also present in the database. This dataset also included the cultivars ‘Golden Delicious’ and ‘James Grieve’ that arose before 1900, but their parentage was confirmed by genotypic data in the studies of Evans et al. (2011) and Salvi et al. (2014). This analysis, however, excluded other historic cultivars, for which information about parentages provided in the literature may be less reliable as they were not derived from systematic breeding activities. The analysis was performed with the software ML-Relate (Kalinowski et al. 2006), which can calculate the maximum likelihood estimates for each of the four relationships: unrelated, half siblings, full siblings and parent/offspring. In the course of these analyses, it was noticed that seven assumed parent-offspring combinations showed mismatches at locus COL, likely due to the presence of null alleles. Consequently, this locus was excluded from the dataset and the analyses were repeated with the remaining 13 loci. Furthermore, locus COL was omitted from all further parentage analyses.
In a second step, the analysis targeted 116 diploid genotypes, again comprising old and recent cultivars, and rootstocks, for which information about both parents was available from the literature and which genotypes were also present in the dataset. The software CERVUS 3.0.7 was employed in order to identify the statistically most likely candidate parent pairs. A simulation of parentage analysis was performed in order to determine the critical LOD values for parent pairs without known sexes at a strict confidence of 95% and a relaxed confidence of 80%. The simulation was based on the following parameters: N offspring: 20,000; N candidate parents: 1000; proportion of candidate parents sampled: 0.30; proportion of loci typed: 0.99; proportion of loci mistyped: 0.01; and error rate in likelihood calculations: 0.01. The confidence was determined using the log-likelihood ratio or LOD score. The parent pair analysis without known sexes was run based on the output of the parentage simulation and by allowing for typing errors.
In order to use the here described microsatellite dataset as a reference database for determination of unknown apple cultivars and to handle the presence of diploid and triploid genotypes, a new “Apple Fingerprint Identifier” script was generated in Microsoft Access (Baric and Radmüller, unpublished). This programme allows comparing the genotype of an unknown variety to all the 600 entries present in the reference database including the full set of 14 microsatellite loci. The programme permits manually inserting the genotypic data of the target cultivar or to import a list of cultivars from an Excel file comprising three columns per locus. For each target genotype, the alleles at each locus are compared to each entry of the database. Finally, a ranked list of the genotypes from the database with the highest similarity to the target is generated, which is based on the number of matches. In order to visually facilitate identification, all matching alleles between the target genotype and the genotypes from the database are highlighted in green, whereas mismatching alleles are highlighted in red. In this way, the genotype of an unknown apple variety can be assigned to the reference cultivar, if it shares all alleles with the reference genotype or displays a tolerated number of mismatches. The Access programme can also be used with a lower number of microsatellite loci, if the set of microsatellite loci analysed in different projects or laboratories is only partially overlapping.
Finally, a preliminary trial was performed to assess the potential of combining genotyping data obtained in the present study with published microsatellite data (Urrestarazu et al. 2016). First, the allele lengths of five common cultivars (‘Fuji’, ‘Gala’, ‘Golden Delicious’, ‘Granny Smith’ and ‘Red Delicious’) were compared at a set of five microsatellite loci that were analysed in both studies in order to determine conversion values necessary to align the allele lengths (Table 4). After conversion of the allele lengths in the dataset of Urrestarazu et al. (2016), a set of 20 cultivars that were present in both datasets were randomly selected and their allele lengths were compared.
Results
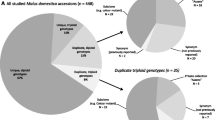
The dataset includes a total of 600 genotypes at 14 microsatellite loci, of which 533 are diploid and 67 are triploid. The ploidy was determined exclusively based on molecular genetic data and the genotypes identified as triploids displayed three different alleles at three or more microsatellite loci. Of the 600 genotypes included in the database, two belonged to the crab apples Malus baccata and M. floribunda, while the remaining were 24 rootstocks and 574 scion cultivars of M. domestica. Of the latter, 264 were classified as historic, 87 as old and 223 as recent cultivars. Of the historic cultivars, 51 (19.3%), of the old cultivars, 9 (10.3%) and of the recent cultivars only 7 (3.1%) were triploid (Fig. 1).

Composition of the database as regards the proportion of molecular genetic profiles belonging to scion cultivars, rootstocks and crab apples (a). The proportion of historic (derived before 1900), old (originated between 1900 and 1950) and recent (bred after 1950) apple cultivars is shown exclusively for scion cultivars (b). The small black-and-white pie charts indicate the proportion of diploid and triploid genotypes within the entire dataset (a) or within each category of scion cultivars (b). The percentages provided as numbers in the small pie charts specify the share of diploid cultivars
The complete dataset of 600 genotypes comprised a mean number of 19.4 alleles per locus, ranging from 12 to 32 (see Table 3). The average number of alleles per locus was slightly smaller in the dataset with 533 diploid genotypes and amounted to 19.0. Six alleles at five different loci were exclusively present in triploid genotypes. The number of missing genotypic information in the dataset was observed at a very low frequency; for cultivar ‘Vista Bella’ genotypic information was missing at locus Ch02c02a, while for the rootstocks ‘M.4’ and ‘M.6’ genotypic information was partially missing at locus Ch02d08 and for the rootstock ‘M.11’ at locus CH02h11a.
The dataset comprising 533 diploid genotypes was used to determine the combined non-exclusion probability of identity, which amounted to 2.6 × 10−20, to 3.4 × 10−19, to 8.8 × 10−10, and to 5.0 × 10−8 in the dataset with 14, 13, six and five microsatellite loci, respectively, showing that the probability of finding identities by chance increases with the decrease of the number of loci employed. In fact, the identity analysis, which compared 533 individuals in 141,778 pairwise comparisons, did not result in any matching genotype in the datasets containing 14 and 13 loci, whereas in the datasets reduced to six and five microsatellite loci one matching genotype combination was found. The dataset containing six or five microsatellite loci did not allow distinguishing the genotypes of the cultivars ‘Jeanne Hardy’ and ‘Adersleber Kalvill’ as they showed an exact match at all these loci. The probability of identity and the probability of sib identity for the exact match of these two genotypes were 5.8 × 10−11 and 9.3 × 10−4, respectively, when using the dataset with six loci.
The initial analysis aiming to validate the dataset indicated the presence of null alleles at locus COL. In 7 out of 85 presumed parent-offspring combinations tested, a mismatch was found at this locus (see Supplementary Table S3). A closer look at the genotyping data revealed that six of these parent-offspring combinations were homozygous for different alleles at locus COL, which strongly suggests the presence of null alleles. This assumption is further supported by the low observed heterozygosity found at this locus, which amounted to 0.72 (data not shown). In comparison, the average observed heterozygosity for the remaining loci was 0.84 (±0.03 S.D.). When omitting locus COL from the dataset and repeating the parentage analysis with software ML-Relate, no further indication for a genotyping error was noticed. Of the 85 diploid cultivars tested, for which one documented parent was included in the dataset, the highest likelihood for a parent-offspring relationship was found in 77 instances. In three cases, the highest likelihood supported a full sibling relationship, however, the log likelihoods for the parent-offspring relationship were only 0, 0.56, 0.85 lower, respectively (Supplementary Table S3). For the cultivars ‘Collina’, ‘Pimona’, ‘Prime Gold’ and ‘Reglindis’, the parent cultivar suggested from the literature could be excluded (see Table 2), while another cultivar with the highest likelihood for a parent-offspring relationship was identified (Supplementary Table S3). Moreover, while for ‘Prime Gold’ the parentage of ‘Golden Delicious’ was excluded, a parent-offspring relationship was identified for ‘Morgenduft’ and ‘Red Delicious’. In the case of ‘Lombarts Kalvill’, ‘Weißer Winterkalvill’ present in our dataset could be excluded as a parent.
The next analysis focused on a dataset with 116 diploid genotypes, for which information about both parents was available from the literature or other sources, and the molecular genetic profiles of the suggested parent cultivars were also present in the dataset. This analysis confirmed the parentage for 108 genotypes. While 104 offspring genotypes showed an exact match with both parent genotypes at all 13 loci, a single mismatch was observed for the offspring genotype and one of its parents in four cases (Supplementary Table S4). In each mismatch, a different locus was involved, which results in a mean genotyping error rate of 0.28% per locus. For five apple cultivars, ‘Millicent Barnes’, ‘Nevson’, ‘Plumac’, ‘Strauwaldts Goldparmäne’ and ‘Tunda’, one of the assumed parents could be excluded, while another parent was found as the most probable parent (see Supplementary Tables S4 and S5). All confirmed or identified parent-offspring combinations showed positive LOD scores that ranged from 17.01 to 45.31, with an average value of 27.97 (±4.79 S.D.). All LOD scores but one exceeded the critical LOD value of 17.56 (Supplementary Table S4). For all but three cultivars, the parentage assignment was made at the strict confidence level of 95%. For the cultivar ‘Melrose’, which is an offspring of ‘Jonathan’ × ‘Red Delicious’ (Silbereisen et al. 2015), a higher likelihood was found for the combination ‘Akane’ × ‘Red Delicious’, ‘Akane’ being an offspring of ‘Jonathan’. Similarly, for the cultivar ‘Rubinola’, an offspring of ‘Prima’ × ‘Rubin’ (Salvi et al. 2014), a higher likelihood was found for the combination ‘Prima’ × ‘Topaz’, ‘Topaz’ being an offspring of ‘Rubin’. In case of the cultivar ‘Dalilight’, one mismatch was found for the parent combination ‘Elstar’ × ‘Cripps Pink’ and the LOD score was below the critical threshold of 17.56. For this cultivar a higher LOD score, also below the threshold, was found for the combination ‘Elstar’ × ‘Golden Delicious’, ‘Golden Delicious’ being a parent of ‘Cripps Pink’.
For two cultivars, ‘Blushing Golden’ and ‘Sinta’, the presumed parent pairs (see Table 2) could not be confirmed by the analysis. While in both cases ‘Golden Delicious’ was confirmed as one of the parents, the second parent suggested by the literature was rejected. For these cultivars, it was not possible to identify a genotype in our dataset that may represent the second most likely parent (Supplementary Table S5). In addition, the two possible parents of ‘Prime Gold’, identified in the ML-Relate analysis, ‘Morgenduft’ and ‘Red Delicious’ (Supplementary Table S3), were further confirmed as the probable parent pair with a LOD score of 28.89.
The comparison of molecular genetic profiles obtained in the present study with a set of data of common cultivars that were randomly derived from the dataset of Urrestarazu et al. (2016) showed a very good comparability at the five microsatellite loci that were in common. For four microsatellite loci, it was necessary to apply a conversion value in order to align the allele lengths (Baric et al. 2008). For three of these loci, it was even necessary to apply a second conversion value for longer alleles as a shift from odd to even allele lengths (or from even to odd numbers) occurred in the longer allele range of the dataset of Urrestarazu et al. (2016). Nevertheless, after applying the conversion values shown in Table 4 and comparing the molecular genetic profiles of the five cultivars used to determine the conversion values and the 20 randomly derived cultivars, an exact match between the data of the two studies could be found (see Supplementary Table S6).
Discussion
In the last years, there has been an increasing interest in the characterisation and maintenance of heirloom cultivars of apple at the regional and national level of many countries. Multilocus microsatellite analysis has become a standard tool for the assessment of genetic variability and the identification of duplicate accessions in order to contribute to a more efficient management of germplasm collections (e.g. Guarino et al. 2006; Pereira-Lorenzo et al. 2007; Routson et al. 2009; van Treuren et al. 2010; Garkava-Gustavsson et al. 2013; Ferreira et al. 2016; Gasi et al. 2016; Urrestarazu et al. 2016; Larsen et al. 2017; Testolin et al. 2019). Furthermore, molecular data can provide a complementary or alternative means for the determination of apple cultivars based on phenotypic traits. However, while the comparison of molecular genetic profiles of accessions present in a collection or geographic area can help to disclose identical genotypes, such an approach does not automatically lead to a correct cultivar determination. Frequently, trees are maintained in germplasm collections under their local names and without the possibility to compare their molecular genetic profiles to standard cultivars, they could be regarded as local even if they in fact represented widely grown international cultivars (Urrestarazu et al. 2016; Testolin et al. 2019). In addition, several studies have pointed to the problem of misclassified accessions preserved in germplasm collections, which can occur due to phenotypic determination errors, due to mix-up of grafting and/or planting material or due to documentation mistakes (Hokanson et al. 1998; Baric et al. 2009; van Treuren et al. 2010; Urrestarazu et al. 2016).
With regard to using multilocus microsatellite data for determination of unidentified or misidentified apple varieties, a database with molecular genetic fingerprints of well-determined reference cultivars needs to be available (Thomas et al. 1994). Based on the results of a genotyping study of Dutch genetic resources of apple, van Treuren et al. (2010) presented a database with 121 confirmed or verified multilocus microsatellite profiles to identify apple cultivars. The aim of the present study was to set up a more comprehensive reference database comprising 600 unique multilocus microsatellite profiles that could be applied for the identification of historic, old and recent apple cultivars, with focus on the Central European cultivation area. In order to generate a representative dataset, a targeted sampling procedure involving 37 European cultivar collections and more than 1600 accessions of apple trees was implemented. One of the intended applications of the database was to characterise and determine the local genetic resources of apple from the regions of Tyrol in Austria and South Tyrol in Italy that were collected in a common research project (Baric et al., in preparation). Therefore, the apple cultivars to be sampled and genotyped for the establishment of the database were selected based on the study of pomological references. A large part of the database covers apple cultivars that were grown in the Central European area in the past. The database includes 72 out of 74 common German apple cultivars described by Silbereisen et al. (2015), 24 out of 27 cultivars considered as widespread in South Tyrol (Northern Italy) in the first half of the 20th century (Amonn and Meier 1934), and approximately 50% of the cultivars listed in the Austrian-Hungarian Pomology published in 1888 (Stoll 1888), to name but a few. Another utilisation potential of our database was seen as a tool for the support of breeding programmes or the production of propagation material, as the database also comprises a considerable proportion of recent cultivars, many of which are still in the process of technical examination and variety testing.
In order to diminish the inclusion of molecular genetic profiles belonging to erroneously assigned cultivars into the reference database, an important goal of the present study was to sample at least two independent accessions of distinct provenances of each cultivar (Baric et al. 2009; Evans et al. 2011). If two or more (up to eight) accessions carrying the same cultivar name displayed identical molecular genetic fingerprints, they were considered as confirmed and the multilocus microsatellite genotypes were included in the reference database. This objective was reached for 98% of the apple cultivars present in the database. Three or even more independent accessions were analysed of one third of the cultivars present in the database. Among the historic cultivars raised before 1900, the percentage of molecular genetic profiles that were verified by three or more accessions was considerably higher and amounted to 56%. Nevertheless, as discussed by Urrestarazu et al. (2016), an identical molecular genetic profile of two accessions with different origins does not always prove the trueness-to-type, as graft cuttings have been exchanged for centuries on a large geographical scale and erroneously determined accessions could have been maintained and transmitted from one germplasm collection to another. This may indeed be the case for some historic cultivars, as was shown for ‘Edelborsdorfer’, one of the oldest German apple cultivars documented in the 16th century. In a study employing the same set of microsatellite markers as used in the present work, several distinct genotypes denominated ‘Edelborsdorfer’ were found in different cultivar collections (Storti et al. 2013). Among these were accessions with an identical triploid genotype that by the integration of genotyping data and pomological characterisation could successively be identified as the cultivar ‘Seebaer Borsdorfer’, which is a synonym of ‘Fromms Renette’, and also an offspring of the true-to-type ‘Edelborsdorfer’ (Storti et al. 2013). Therefore, the presence of a small number of misidentified cultivars in the here described reference database cannot be completely ruled out and may be rectified in the course of future pomological evaluations of the germplasm collections sampled. For this reason, whenever using the database to determine an unknown apple variety, it is recommended to provide the cultivar name followed by an indication about the germplasm collection where accessions with a matching multilocus genotype can be found. In this way, a subsequent comparative pomological assessment based on reference material from defined cultivar collections could be performed.
In order to acquire high quality multilocus microsatellite fingerprints of each apple cultivar, every sample obtained from a different accession was analysed independently by using an anonymous sampling code. Before data was exported, each electropherogram was visually assessed for binning accuracy. The comparison of the multilocus microsatellite genotypes in a cross-tabulation matrix finally allowed identifying identical or highly similar molecular genetic profiles. In case of incongruences between samples supposed to represent the same apple cultivar, the data were reviewed and, if necessary, the DNA analyses were repeated. Each cultivar was finally represented by a unique genotype that was included into the reference database.
Due to the rigorous quality control performed during laboratory and data analyses, we feel confident that the here presented dataset is reliable and robust. Nevertheless, a parentage analysis performed on a set of multilocus microsatellite genotypes of apple cultivars with previously known parent-offspring relationships permitted to get an impression about the rate of genotyping errors present in our dataset. Genotyping errors affect all kinds of datasets, but the rate of their occurrence is generally addressed by few studies (Hoffman and Amos 2005; Pompanon et al. 2005). Hoffman and Amos (2005) found that one of the most common errors affecting microsatellite data is the misinterpretation of allele banding patterns due to confusion between homozygote and heterozygote genotypes with adjacent alleles. In particular, dinucleotide microsatellite repeats that are prone to “stutter” peaks are affected by this type of genotyping error (Litt et al. 1993). However, a study comparing microsatellite profiles of apple cultivars at a set of five microsatellite loci obtained independently by two laboratories showed that the most common type of discordance among laboratories was ‘dropout of longer alleles’ due to preferential amplification of shorter alleles during PCR, followed by mis-scoring of “stutter” patterns as homozygous or heterozygous, and complete allele mismatch (Baric et al. 2008). Another issue, that can in particularly affect the success of parentage analyses, is the occurrence of ‘null alleles’ that are caused by a non-amplification of alleles due to a mutation at the primer binding site (Hoffman and Amos 2005). In the present study, one of the loci analysed (COL) was found to be considerably affected by null alleles and consequently, this locus had to be excluded from parentage analysis. Other genotyping incongruences between parent-offspring trios with known parentages were observed at very low rates, resulting in a mean genotyping error rate of 0.28% per locus, which points to a high reliability of the dataset. Nevertheless, as the presence of genotyping errors cannot be completely excluded, it is recommended to allow for at least one mismatch when using the database for cultivar identification or for parentage analysis. The parentage analysis used to verify the dataset included apple cultivars that were derived after 1900 and for which information about parent-offspring relationships were provided by different references. Multilocus microsatellite genotypes of more than 100 scion cultivars and rootstocks could be compared to the genotypes of both documented parents, while more than 80 could be compared to one of their parents. This means that approximately one third of the cultivars included in the reference database are supported by the matching of their multilocus microsatellite profiles with one or even two parental genotypes suggested by the pomological literature. Among these is a small number of cultivars for which only one accession could be analysed, but that were still included in the reference database because their multilocus microsatellite profiles matched with the documented parents. The remaining cultivars, which multilocus microsatellite profiles are based on the analysis of a single accession, were not supported as offspring but as a parent, such as ‘Otava’ and ‘Minnewashta’ in the group of recent cultivars. ‘Wyken Pippin’, a British cultivar from the early 1700s could only be obtained from the National Fruit Collection in Brogdale (UK), but was inserted in the database as it is listed as a parent of some historic and old apple cultivars (Smith 1971).
Parentage analyses revealed a smaller percentage of cultivars, which documented pedigrees were not supported by multilocus microsatellite data, as was observed in previous studies (e.g. Evans et al. 2011; Moriya et al. 2011; Salvi et al. 2014). The cultivar ‘Nevson’ was patented as a controlled cross between ‘Gala’ and ‘Red Delicious’ (United States Patent PP12,415; USPTO Database of the United States Patent and Trademark Office), while for ‘Plumac’ the cultivars ‘Fuji’ and ‘Braeburn’ were assumed as the “… probable parents based on their characteristics and their proximity to the new cultivar in the area of discovery.” (United States Patent PP23,418; USPTO Database of the United States Patent and Trademark Office). For each of the two cultivars, multilocus microsatellite data refuted one of the proposed parents and indicated that both are likely to be the offspring of the same cultivar pair, ‘Gala’ × ‘Braeburn’, and can thus be considered sister cultivars. Similar, one of the parents proposed for the cultivar ‘Tunda’, which was described as an offspring of ‘Delcorf’ × ‘Liberty’ (Sansavini et al. 2012) could not be supported by molecular data and instead the parentage of ‘Delcorf’ × ‘Alkmene’ was proposed. The American cultivar ‘Prime Gold’, introduced in 1965, was assumed to be a seedling of ‘Golden Delicious’, also because of their resemblance (Morgan and Richards 2002). However, the most likely parent pair found in our database and supported by matching of multilocus microsatellite data was ‘Red Delicious’ × ‘Morgenduft’, while ‘Golden Delicious’ was excluded as a possible parent. Based on parent-offspring analysis involving only one of the potential parents, new inferences were possible for the cultivars ‘Pimona’ and ‘Reglindis’. Both cultivars were derived from the Dresden-Pillnitz breeding programme (Germany) in the 1960s. ‘Pimona’ was documented as a cross of ‘Clivia’ × ‘Undine’ (Mühl 2001) and microsatellite analysis performed by Reim et al. (2009) confirmed the maternal parent, while ‘Undine’ was excluded as the possible pollen donor. The parent-offspring analyses based on our database identified ‘Tumanga’ as an alternative cultivar that could represent the second parent of ‘Pimona’. The reported parentage of ‘Reglindis’ as ‘James Grieve’ × ‘Antonowka’ F2 was put in doubt in previous studies (Reim et al. 2009; Bus et al. 2012). It was suggested that two different genotypes of ‘Reglindis’ existed and that the commercially grown cultivar did not represent the original selection. The commercialised genotype in fact carried a rare allele at the CH-Vf1 locus, which is analysed as a marker for scab resistance. As the rare allele was known to occur in ‘Geheimrat Dr. Oldenburg’ and its progeny, it was speculated that ‘Apollo’, ‘Helios’ or ‘Alkmene’ may be a parent of the commercialised ‘Reglindis’ (Bus et al. 2012). Indeed, the parent-offspring analysis using our database identified ‘Apollo’ as a parent of ‘Reglindis’, while the parentage of the latter two cultivars was not supported. The parent-offspring relationships of ‘Pimona’ and ‘Reglindis’ proposed by our analyses appear sound as both ‘Apollo’ and ‘Tumanga’ (Syn. ‘Auralia’) were used as ancestors and are confirmed parents of a number of cultivars derived from the Dresden-Pillnitz breeding programme (Reim et al. 2009).
It is likely that our database may have revealed a higher number of parent-offspring relationships among recent apple cultivars, for which no documented information was found. However, this group of cultivars was excluded from parentage analysis because many modern apple cultivars were derived from a limited number of founding clones and their pedigrees may be interconnected (Noiton and Alspach 1996). Consequently, genetically and genealogically closely related cultivars could be mistakenly assigned a parent-offspring relationship, especially if the number of analysed microsatellite loci is restricted (Salvi et al. 2014). This was also evident from the parentage analysis performed in the present study involving cultivars with known pedigrees. For the cultivars ‘Melrose’, ‘Rubinola’ or ‘Dalilight’ higher likelihoods of parentage were found for siblings or grandparents than for the established parents. Whether this is the case for the parent-offspring relationship of the cultivar ‘Collina’, could not be fully clarified in the present study. ‘Collina’ was described as a cross of ‘Priscilla-NL’ × ‘Elstar’, but its multilocus microsatellite profile in our database was not supported as a direct progeny of ‘Elstar’, but of ‘Santana’. The latter is an offspring of the same parent pair (‘Elstar’ × ‘Priscilla-NL’), but the maternal and paternal parent being inversed. These cultivars originated from the Dutch breeding programme and their pedigree was previously analysed by a set of 80 microsatellite markers (Evans et al. 2011). While the postulated pedigree of ‘Santana’ was fully supported by molecular genetic data, that of ‘Collina’ showed two mismatches, leading to the conclusion that “… this pedigree is not yet fully correct, but nevertheless close.” (Evans et al. 2011). Indeed, our dataset comprising a much smaller set of loci also revealed two mismatches between ‘Collina’ and ‘Elstar’ at loci CH02b10 and CH02h11a, while ‘Collina’ and ‘Santana’ showed an exact match at one of the two alleles of all analysed loci. Therefore, it could be speculated that ‘Collina’ (a cultivar from the 2000s) and ‘Santana’ (a cultivar from the 1990s) are not in a full-sibling but in a parent-offspring relationship. However, this speculation would need to be tested by analysing a larger set of microsatellite loci and including the second parent, ‘Priscilla-NL’, in the analysis, which was not available in the present study.
Hundreds of microsatellite markers have been described so far (Guilford et al. 1997; Liebhard et al. 2002; Silfverberg-Dilworth et al. 2006), leading to a high diversity of laboratory protocols and marker sets that have been employed by different laboratories (Sehic et al. 2011). Nevertheless, in the last years there has been a tendency towards harmonisation of microsatellite marker sets employed by different studies in order to allow exchange of data (Larsen et al. 2017; Lassois et al. 2016; Urrestarazu et al. 2016; Testolin et al. 2019). Five of the microsatellite loci analysed in the present study overlapped with the marker set analysed by Urrestarazu et al. (2016), who investigated a large number of accessions from different European germplasm collections. The comparison of microsatellite data obtained in different laboratories is, however, not straightforward, as allele lengths do not represent absolute measures, but can be affected by different capillary electrophoresis systems and chemistries (Haberl and Tautz 1999; Delmotte et al. 2001). Therefore, locus- and laboratory-specific conversion values need to be applied to make datasets directly comparable (Baric et al. 2008). Another issue to be considered in this regard is the occurrence of ‘allelic drift’, which can affect the accuracy of allele binning in automated electrophoresis systems (Idury and Cardon 1997). This is the reason, why we had to apply two conversion values for some of the loci in order to align our dataset with the one of Urrestarazu et al. (2016). In the latter, a shift deviating from the expected pattern for dinucleotide microsatellite repeats with even and odd fragment lengths was observed for three of the five loci compared. Nevertheless, the application of the conversion values and the comparison of 25 cultivars analysed in both studies finally resulted in an exact correspondence of the microsatellite profiles and demonstrated that our data are comparable with those obtained in a different study. This comparison also confirmed that the triploid accessions of ‘Winesap’ that were sampled from two cultivar collections in fact represented the cultivar ‘Stayman Winesap’. The triploid genotype, which is an offspring of ‘Winesap’, seems to be maintained under the name of its parent in several European germplasm collections (Ordidge et al. 2018). In addition, the molecular genetic profiles of the cultivar ‘Wyken Pippin’ at five loci that were in common to the present study and the microsatellite dataset of Ordidge et al. (2018) showed a perfect match. Similarly, by comparing genotyping data at six microsatellite loci that overlapped among our dataset and that of Bus et al. (2012), it was possible to confirm the identity of three ‘Antonowka’ cultivars (Storti et al. 2012). However, it needs to be considered that the probability of finding identities by chance increases with the decreasing number of microsatellite loci included in the analysis. While for the dataset with 14 microsatellite loci, the combined non-exclusion probability of identity and sib identity amounted to 2.6 × 10-20 and 2.7 × 10−7, respectively, these values were considerably higher, 5.0 × 10−8 and 3.9 × 10−3, for the dataset with five microsatellite loci. Indeed, all the 600 genotypes included in the database could be distinguished from each other with the set of 14 and 13 microsatellite loci. When reducing the number of microsatellites to five and six loci, it was still possible to distinguish 599 genotypes, but not the cultivars ‘Jeanne Hardy’ and ‘Adersleber Kalvill’ that showed identical profiles at these loci. Consequently, a reduced number of microsatellite loci needs to be employed with great attention, especially if the dataset comprises data of closely related genotypes. In such a situation, the resulting identities should be used as a first indication for follow-up confirmation studies of the correctness of the molecular genetic determination.
The full set of microsatellite markers analysed in the present study showed a high degree of variability and a good resolution allowing to distinguish all 600 apple genotypes present in the database. As demonstrated in previous studies, the application of microsatellite loci was not suitable to distinguish clones or spurs of the same cultivar (e.g. Patzak et al. 2012; Gasi et al. 2016; Larsen et al. 2017). Accordingly, the microsatellite data did not permit to differentiate the common and the red clones of the cultivars ‘Gravensteiner’ and ‘Jonathan’. In addition, the same genotype was identified for the accessions denominated ‘Tiroler Spitzlederer’ and ‘Plattlederer’ indicating that this local cultivar may display a considerable degree of phenotypic plasticity. It also appears probable that the accession ‘Plattlederer’ had a falsely assigned name and that the true genotype was in fact not analysed in the present study. It is intriguing that the book “Bozner und Meraner Obstsorten” (Amonn and Meier 1934), which describes the 27 most important apple cultivars grown in the area of South Tyrol in the first half of the 20th century, only lists ‘Spitzlederer-Apfel’ (Syn. ‘Tiroler Spitzlederer’), but does not mention the cultivar ‘Plattlederer’. If ‘Tiroler Spitzlederer’ and ‘Plattlederer’ indeed represented two distinct cultivars, the former was obviously more common in the last century and could thus be preserved, while the latter, less widespread cultivar, may have become lost over time. Our database furthermore allowed identifying several synonym names, such as the synonymy of ‘Köstlicher von Zallinger’, ‘Napoleone’ and ‘Carla’ or the synonymy of ‘Stina Lohmann’ and ‘Korbiniansapfel’. Finally, the here presented database proved useful at several occasions to identify unknown or misidentified apple cultivars (Baric 2012). Therefore, apart from its application to characterise genetic resources or to manage germplasm collections, the database could serve as an important tool for quality control. This instrument could prove useful for the selection of parents and the confirmation of crosses in breeding programmes, for the confirmation of true-to-typeness during the production of propagation and planting material in nurseries or to verify the cultivar declaration in the retail process of fresh and/or processed apple fruit.
References
Aigner K, Schalansky J (2013) Äpfel und Birnen: das Gesamtwerk. Matthes & Seitz, Berlin. ISBN 978-3-88221-051‑4
Aliotta G, Grassi G (2008) La storia naturale del melo in Europa e le radici culturali dell’Annurca. In: Aliotta G, Ciarallo A, Salerno CR (eds) Le piante e l’uomo in Campania. Le radici culturali e scientifiche. Istituto per la Diffusione delle Scienze Naturali, Torre Annunziata, pp 139–163
Amonn W, Meier L (1934) Bozner und Meraner Obstsorten. J. F. Amonn, Bozen
Baab G (2011) Die neuen resistenten Apfelsorten aus den Niederlanden. Öko-Obstbau 2011/1:4
Bannier HJ (2011) Moderne Apfelzüchtung: Genetische Verarmung und Tendenzen zur Inzucht. Erwerbs-Obstbau 52:85–110
Baric S (2012) Molecular tools applied to the advancement of fruit growing in South Tyrol – a review. Erwerbs-Obstbau 54:125–135
Baric S, Monschein S, Hofer M, Grill D, Dalla Via J (2008) Comparability of genotyping data obtained by different procedures – an interlaboratory survey. J Hortic Sci Biotechnol 83:183–190
Baric S, Storti A, Hofer M, Dalla Via J (2009) Molecular genetic characterisation of apple cultivars from different germplasm collections. Acta Hortic 817:347–353
Baric S, Storti A, Hofer M, Dalla Via J (2012) Resolving the parentage of the apple cultivar ‘Meran’. Erwerbs-Obstbau 54:143–146
Bartha-Pichler B, Brunner F, Gersbach K, Zuber M (2005) Rosenapfel und Goldparmäne. 365 Apfelsorten – Botanik, Geschichte und Verwendung. AT Verlag, Baden, München. ISBN 3‑03800-209‑7
Bernkopf S (2011) Von Rosenäpfeln und Landlbirnen. Ein Streifzug durch Oberösterreichs Apfel- und Birnensorten. Trauner, Linz
Bernkopf S, Keppel H, Novak R (2003) Neue alte Obstsorten. Äpfel, Birnen und Steinobst, 5th edn. Club Niederösterreich, Wien. ISBN 3‑7040-1350‑1
Bosch HT (2017) Pfaffenhofer Schmelzling. Sortenportraits Apfel, Erhalternetzwerk Obstsortenvielfalt, Pomologen-Verein Deutschland. https://obstsortenerhalt.de/obstart/details/21140. Accessed 21 Jan 2020
Bosch HT (2006) Rambur, Renette, Rotbirn...: lebendige Vielfalt der Äpfel und Birnen. Eine Bestandaufnahme der Apfel- und Birnensorten im Saarland und der Westpfalz.Verband der Gartenbauvereine Saarland-Pfalz, Schmelz
Bounous G (2006) Antiche cultivar di melo in Piemonte. Supplemento al n. 52 dei “Quaderni della Regione Piemonte – Agricoltura”. Regione Piemonte, Assessorato Agricoltura, Torino
Brown SK, Maloney KE (2003) Genetic improvement of apple: breeding, markers, mapping and biotechnology. In: Ferree DC, Warrington IJ (eds) Apples: botany, production and uses. CABI, Oxon, Cambridge, pp 31–59
Bus VG, van de Weg WE, Peil A, Dunemann F, Zini E, Laurens FN, Blažek J, Hanke V, Forsline PL (2012) The role of Schmidt ‘Antonovka’ in apple scab resistance breeding. Tree Genet Genomes 8:627–642
Cornille A, Giraud T, Smulders MJM, Roldán-Ruiz I, Gladieux P (2014) The domestication and evolutionary ecology of apples. Trends Genet 30:57–65
Delmotte F, Leterme N, Simon JC (2001) Microsatellite allele sizing: difference between automated capillary electrophoresis and manual technique. Biotechniques 31:810–814
Eurostat (2019) Agricultural production – orchards. Source: Statistics Explained. https://ec.europa.eu/eurostat/statistics-explained/index.php/Agricultural_production_-_orchards#Apple_trees. Accessed 21 Jan 2020
Evans KM, Patocchi A, Rezzonico F, Mathis F, Durel CE, Fernández-Fernández F, Boudichevskaia A, Dunemann F, Stankiewicz-Kosyl M, Gianfranceschi L, Komjanc M, Lateur M, Madduri M, Noordijk Y, van de Weg WE (2011) Genotyping of pedigreed apple breeding material with a genome-covering set of SSRs: trueness-to-type of cultivars and their parentages. Mol Breed 28:535–547
Ferreira V, Ramos-Cabrer AM, Carnide V, Pinto-Carnide O, Assunção A, Marreiros A, Rodrigues R, Pereira-Lorenzo S, Castro I (2016) Genetic pool structure of local apple cultivars from Portugal assessed by microsatellites. Tree Genet Genomes 12:36
Gaber R (2020) Siebenkant. Obstsortenblätter, Arche Noah. https://www.arche-noah.at/files/siebenkant_beschreibung_und_foto.pdf. Accessed 21 Jan 2020
Garkava-Gustavsson L, Mujaju C, Sehic J, Zborowska A, Backes GM, Hietaranta T, Antonius K (2013) Genetic diversity in Swedish and Finnish heirloom apple cultivars revealed with SSR markers. Sci Hortic 162:43–48
Gasi F, Kanlić K, Stroil BK, Pojskić N, Asdal Å, Rasmussen M, Kaiser C, Meland M (2016) Redundancies and genetic structure among ex situ apple collections in Norway examined with microsatellite markers. HortScience 51:1458–1462
Guarino C, Santoro S, De Simone S, Lain O, Cipriani G, Testolin R (2006) Genetic diversity in a collection of ancient cultivars of apple (Malus × domestica Borkh.) as revealed by SSR-based fingerprinting. J Hortic Sci Biotechnol 81:39–44
Guilford P, Prakash S, Zhu JM, Rikkerink E, Gardiner S, Bassett H, Forster R (1997) Microsatellites in Malus × domestica (apple): abundance, polymorphism and cultivar identification. Theor Appl Genet 94:249–254
Haberl M, Tautz D (1999) Comparative allele sizing can produce inaccurate allele size differences for microsatellites. Mol Ecol 8:1347–1349
Hampson CR, Kemp K (2003) Characteristics of important commercial apple cultivars. In: Ferree DC, Warrington IJ (eds) Apples: Botany, Production and Uses. CABI, Oxon, Cambridge, pp 61–89
Hardy OJ, Vekemans X (2002) SPAGeDi: a versatile computer program to analyse spatial genetic structure at the individual or population levels. Mol Ecol Notes 2:618–620
Hartmann W (2003) Farbatlas Alte Obstsorten, 2nd edn. Ulmer, Stuttgart. ISBN 3‑8001-4394‑1
Hartmann W (2015) Farbatlas Alte Obstsorten, 5th edn. Ulmer Verlag, Stuttgart. ISBN 978-3-8001-0316‑4
Hoffman JI, Amos W (2005) Microsatellite genotyping errors: detection approaches, common sources and consequences for paternal exclusion. Mol Ecol 14:599–612
Hokanson SC, Szewc-McFadden AK, Lamboy WF, McFerson JR (1998) Microsatellite (SSR) markers reveal genetic identities, genetic diversity and relationships in a Malus × domestica Borkh. core subset collection. Theor Appl Genet 97:671–683
Idury RM, Cardon LR (1997) A simple method for automated allele binning in microsatellite markers. Genome Res 7:1104–1109
Jacobsen R (2014) Apples of Uncommon Character. Bloomsbury, New York. ISBN 978-1-62040-227‑6
Janick J (2005) The origins of fruits, fruit growing and fruit breeding. Plant Breed Rev 25:255–321
Janick J, Cummins JN, Brown SK, Hemmat M (1996) Apples. In: Janick J, Moore JN (eds) Trees and tropical fruits. Fruit Breeding, vol 1. John Wiley & Sons, New York, pp 1–77
Juniper BE, Watkins R, Harris SA (1998) The origin of the apple. Acta Hortic 484:27–33
Kalinowski ST, Taper ML, Marshall TC (2007) Revising how the computer program CERVUS accommodates genotyping error increases success in paternity assignment. Mol Ecol 16:1099–1006
Kalinowski ST, Wagner AP, Taper ML (2006) ML-Relate: a computer program for maximumlikelihood estimation of relatedness and relationship. Mol Ecol Notes 6:576–579
Larsen B, Toldam-Andersen TB, Pedersen C, Ørgaard M (2017) Unravelling genetic diversity and cultivar parentage in the Danish apple gene bank collection. Tree Genet Genomes 13:14
Lassois L, Denancé C, Ravon E, Guyader A, Guisnel R, Hibrand-Saint-Oyant L, Poncet C, Lasserre-Zuber P, Feugey L, Durel CE (2016) Genetic diversity, population structure, parentage analysis, and construction of core collections in the French apple germplasm based on SSR markers. Plant Mol Biol Rep 34:827–844
Leroy A (1873) Dictionnaire de Pomologie: contenant l’histoire, la description, la figure des fruits anciens et des fruits modernes les plus généralement connus et cultivés. Tome IV – Pommes, M–Z, Variétés N°° 259 a 527. Dans Les Principales Librairies Agricoles et Horticoles, Angers, Paris
Liebhard R, Gianfranceschi L, Koller B, Ryder CD, Tarchini R, Van de Weg E, Gessler C (2002) Development and characterisation of 140 new microsatellites in apple (Malus × domestica Borkh.). Mol Breed 10:217–241
Link H (2002) Lucas’ Anleitung zum Obstbau, 32nd edn. Ulmer, Stuttgart. ISBN 3‑8001-5545‑1
Litt M, Hauge X, Sharma V (1993) Shadow bands seen when typing polymorphic dinucleotide repeats: some causes and cures. Biotechniques 15:280–284
Luby JJ (2003) Taxonomic classification and brief history. In: Ferree DC, Warrington IJ (eds) Apples: botany, production and uses. CABI, Oxon, Cambridge, pp 1–14
Maurizzi S (2001) Il melo. Il Sole 24 Ore Edagricole, Bologna
Melville F, Cripps JEL (1970) Better rootstocks for apple trees. J Agric 11:267–269
Morgan J, Richards A (2002) The new book of apples. Ebury, London. ISBN 978-0-09-188398‑0
Moriya S, Iwanami H, Okada K, Yamamoto T, Abe K (2011) A practical method for apple cultivar identification and parent-offspring analysis using simple sequence repeat markers. Euphytica 177:135–150
Mühl F (2001) Alte und neue Apfelsorten, 4th edn. Obst- und Gartenbauverlag, München. ISBN 978-3-87596-093‑8
Müller J, Bissmann O, Poenicke W, Rosenthal H, Schindler O (1930) Deutschlands Obstsorten. Eckstein & Stähle, Stuttgart
Neri D (2004) Low-input apple production in central Italy: tree and soil management. J Fruit Orn Plant Res 12:69–76
NIAB-EMR (2016) Rootstock research at East Malling: a history. http://www.emr.ac.uk/projects/rootstock-research-east-malling-history/. Accessed 21 Jan 2020
Noiton DAM, Alspach PA (1996) Founding clones, inbreeding, coancestry, and status number of modern apple cultivars. J Am Soc Hortic Sci 121:773–782
Oberhofer H (2007) Obst- und Weinbau im Wandel der Zeit. Südtiroler Beratungsring für Obst- und Weinbau, Lana
Orange Pippin (2019) Geneva crab crab-apple. Fruit varieties descriptions. https://www.orangepippin.com/varieties/crab-apples/geneva. Accessed 21 Jan 2020
Ordidge M, Kirdwichai P, Baksh MF, Venison EP, Gibbings JG, Dunwell JM (2018) Genetic analysis of a major international collection of cultivated apple varieties reveals previously unknown historic heteroploid and inbred relationships. PLoS ONE 13:e202405
Patzak J, Paprštein F, Henychová A, Sedlák J (2012) Comparison of genetic diversity structure analyses of SSR molecular marker data within apple (Malus × domestica) genetic resources. Genome 55:647–665
Perazzolli M, Malacarne G, Baldo A, Righetti L, Bailey A, Fontana P, Velasco R, Malnoy M (2014) Characterization of resistance gene analogues (RGAs) in apple (Malus × domestica Borkh.) and their evolutionary history of the Rosaceae family. Plos One 9(2):e83844. https://doi.org/10.1371/journal.pone.0083844
Pereira-Lorenzo S, Ramos-Cabrer AM, Diaz-Hernandez MB (2007) Evaluation of genetic identity and variation of local apple cultivars (Malus × domestica Borkh.) from Spain using microsatellite markers. Genet Resour Crop Evol 54:405–420
Petzold H (1984) Apfelsorten, 3rd edn. Neumann-Verlag, Leipzig, Radebeul. ISBN 3‑7888-0363‑0
Pompanon F, Bonin A, Bellemain E, Taberlet P (2005) Genotyping errors: causes, consequences and solutions. Nat Rev Genet 6:847–859
Provincia di Vicenza (2005a) Scheda descrittiva: Rusenente – *ITAVAGM087. Istituto di Genetica e Sperimentazione Agraria “N. Strampelli”. Banca Dati, Biodiversità del Veneto. http://biodiversita.provincia.vicenza.it/schdett.php?c=*ITAVAGM087. Accessed 21 Jan 2020
Provincia di Vicenza (2005b) Scheda descrittiva: Talimi – *ITAVAGM073. Istituto di Genetica e Sperimentazione Agraria “N. Strampelli”. Banca Dati, Biodiversità del Veneto. http://biodiversita.provincia.vicenza.it/schdett.php?c=*ITAVAGM073. Accessed 21 Jan 2020
Ramos-Cabrer A, Diaz-Hernandez M, Pereira-Lorenzo S (2007) Use of microsatellites in the management of genetic resources of Spanish apple cultivars. J Hortic Sci Biotechnol 82:257–265
Reim S, Flachowsky H, Hanke MV, Peil A (2009) Verifying the parents of the Pillnitzer apple cultivars. Acta Hortic 814:319–323
Rieger M (2006) Introduction to fruit crops. Chapter 3: Apple (Malus domestica). The Haworth Press, Binghampton, pp 47–64
Rolff JH (2001) Der Apfel. Sortennamen und Synonyme. Selbstverlag Johann-Heinrich Rolff, Kiefersfelden
Routson KJ, Reilley AA, Henk AD, Volk GM (2009) Identification of historic apple trees in the Southwestern United States and implications for conservation. HortScience 44:589–594
Salvi S, Micheletti D, Magnago P, Fontanari M, Viola R, Pindo M, Velasco R (2014) One-step reconstruction of multi-generation pedigree networks in apple (Malus × domestica Borkh.) and the parentage of Golden Delicious. Mol Breed 34:511–524
Sanders R (2012) Das Apfel-Buch. Delius Klasing, Bielefeld. ISBN 978-3-7688-3467‑4
Sansavini S, Guerra W, Pellegrino S (2012) Gli obiettivi del miglioramento genetico e le nuove varietà per l’Europa. Riv Fruttic 2012/11:10–25
Schiavon M (2010) Antiche varietà di mele e pere del Veneto. Veneto Agricoltura: Azienda Regionale per i Settori Agricolo Forestale e Agroalimentare, Legnaro
Sehic J, Garkava-Gustavsson L, Nybom H (2011) More harmonization needed for DNA-based identification of apple germplasm. Acta Hortic 976:277–283
Silbereisen R, Götz G, Hartmann W (2015) Obstsorten Atlas. Nikol, Hamburg. ISBN 978-3-86820-219‑9
Silfverberg-Dilworth E, Matasci CL, Van de Weg WE, Van Kaauwen MP, Walser M, Kodde LP, Soglio V, Gianfranceschi L, Durel CE, Costa F, Yamamoto T (2006) Microsatellite markers spanning the apple (Malus × domestica Borkh.) genome. Tree Genet Genomes 2:202–224
Smith MWG (1971) National apple register of the United Kingdom. Ministry of Agriculture, Fisheries and Food, London. ISBN 1‑897604-28‑9
Stoll R (1888) Österreichisch-Ungarische Pomologie, 2nd edn. Selbstverlag, Klosterneuburg bei Wien
Storti A, Bannier HJ, Holler C, Kajtna B, Rühmer T, Wilfling A, Soldavini C, Dalla Via J, Baric S (2013) Molekulargenetische Analyse des ‘Maschanzker’/‘Borsdorfer’-Sortenkomplexes. Erwerbs-Obstbau 55:99–107
Storti A, Dalla Via J, Baric S (2012) Comparative molecular genetic analysis of apple genotypes maintained in germplasm collections. Erwerbs-Obstbau 54:137–141
Szalatnay D, Frei A (2009) Wie aus einem deutschen Prinzen ein schöner Engländer wurde. Schweiz Z Obst Weinbau 145:11–13
Testolin R, Foria S, Baccichet I, Messina R, Danuso F, Losa A, Scarbolo E, Stocco M, Cipriani G (2019) Genotyping apple (Malus × domestica Borkh.) heirloom germplasm collected and maintained by the Regional Administration of Friuli Venezia Giulia (Italy). Sci Hortic 252:229–237
Thomas MR, Cain P, Scott NS (1994) DNA typing of grapevines: a universal methodology and database for describing cultivars and evaluating genetic relatedness. Plant Mol Biol 25:939–949
van Treuren R, Kemp H, Ernsting G, Jongejans B, Houtman H, Visser L (2010) Microsatellite genotyping of apple (Malus × domestica Borkh.) genetic resources in the Netherlands: application in collection management and variety identification. Genet Resour Crop Evol 57:853–865
Urrestarazu J, Denancé C, Ravon E, Guyader A, Guisnel R, Feugey L, Poncet C, Lateur M, Houben P, Ordidge M, Fernandez-Fernandez F, Evans KM, Paprstein F, Sedlak J, Nybom H, Garkava-Gustavsson L, Miranda C, Gassmann J, Kellerhals M, Suprun I, Pikunova AV, Krasova NG, Torutaeva E, Dondini L, Tartarini S, Laurens F, Durel CE (2016) Analysis of the genetic diversity and structure across a wide range of germplasm reveals prominent gene flow in apple at the European level. BMC Plant Biol 16:130
Volk GM, Henk AD (2016) Historic American apple cultivars: identification and availability. J Am Soc Hortic Sci 141:292–301
Votteler W (2014) Verzeichnis der Apfel- und Birnensorten. Bayerischer Landesverband für Gartenbau und Landespflege e. V., München. ISBN 978-3-87596-086‑0
Way RD, Aldwinckle HS, Lamb RC, Rejman A, Sansavini S, Shen T, Watkins R, Westwood MN, Yoshida Y (1990) Apples (Malus). Acta Hortic 290:1–62
Webster AD, Wertheim SJ (2003) Apple rootstocks. In: Ferree DC, Warrington IJ (eds) Apples: botany, production and uses. CABI, Oxon, Cambridge, pp 91–124
Whealy K, Thuente J (2001) Fruit, berry and nut inventory: an inventory of nursery catalogs listing all fruit, berry and nut varieties available by mail order in the United States. Seed Savers Exchange, Decorah, Iowa. ISBN 1‑882424-57‑3
Widmer C, Schütz S, Inderbitzin J, Kellerhals M, Stadler P (2017) Die neue Apfelsorte Mariella. Schweiz Z Obst Weinbau 153:12–15
Yoshida Y (1977) Progress of apple breeding in Japan. Japan Agric Res Q 11:56–59
Acknowledgements
The following people and institutions are greatly acknowledged for providing samples of apple cultivar accessions: M. Kellerhals (Agroscope Research Station), S. Bernkopf (Austrian Agency for Health and Food Safety, AGES Linz), M. Adam (Private Collection Adam, Hünfelden-Heringen), B. Kajtna (Arche Noah—the Austrian Seed Savers Association, Schiltern), H.-J. Bannier (Private Collection Bannier, Bielefeld), P. Modl (Institute of Horticulture and Viticulture, University of Natural Resources and Applied Life Sciences, Vienna), E. Schulte (Bundessortenamt Prüfstelle Wurzen), G. Bassi (Bassi Vivai Cuneo), A. Martinelli (Consorzio Italiano Vivaisti, S. Giuseppe di Comacchio), L. Berra (Agrion, Cuneo), Corvinus University of Budapest, F. Fernandez (East Malling Research), P. Magnago (Fondazione Edmund Mach di San Michele all’Adige), S. Monschein, T. Rühmer (Versuchsstation Obst- und Weinbau Haidegg), G. Bachelier (Jardin du Luxembourg, Paris), K. Vogl, L. Wurm (Höhere Bundeslehranstalt und Bundesamt für Wein- und Obstbau Klosterneuburg), U. Mayr (Kompetenzzentrum Obstbau Bavendorf), M. Kobelt (Lubera AG, Buchs), R. Stainer (Laimburg Research Centre for Agriculture and Forestry), C. Soldavini (Monastero SS. Pietro e Paolo, Germagno), H. Koike (Nagano Fruit Tree Experiment Station), M. Ordidge (National Fruit Collection in Brogdale), A. Wilfling (OIKOS – Institut für angewandte Ökologie & Grundlagenforschung, Gleisdorf), R. Stehr (Obstbauzentrum Jork Esteburg), J. Stein (Obst- und Kulturweg Ratzinger Höhe, Rosenheim), K. Dianat (Obst- und Weinbauzentrum der Landwirtschaftskammer Kärnten, St. Andrä), B. Escande (Pépinières Escande “Millet”, Saint Vite), H. W. Schreiweis, H.-T. Bosch (Pomologen-Verein e. V. Baden-Württemberg), H. Daepp (Verein Obstsortensammlung Roggwil), M. Matter† (Conservation Orchard Alsace, Alteckendorf), C. Holler (Sortengarten Burgenland, Neuhaus am Klausenbach), K. Werth, M. Bradlwarter (Sortenerneuerungskonsortium Südtirol, Terlan), H. Nybom (Swedish University of Agricultural Sciences, Uppsala), S. Schnell, M. Heinz (Landwirtschaftliche Lehranstalten Triesdorf), S. Tartarini, R. Gregori (Department of Agricultural Sciences, University of Bologna), G. Mezzalira, M. Giannini, L. Schiavon, F. Salmaso (Veneto Agricoltura – Agenzia Veneta per il Settore Primario, Legnaro) and Br. Franz (Zisterzienserabtei Stift Stams). The authors thank C. Kerschbamer and I. Wild for exceptional technical assistance, W. Radmüller for programming the “Apple Fingerprint Identifier” Access database for identification of unknown genotypes and H.-J. Bannier for critical comments on the manuscript. The study was conducted in the course of the projects “GENE-SAVE” and “APPLE-FINGERPRINT” funded by the European Union under the INTERREG IIIA programme between Italy and Austria, and by the Governments of South Tyrol (Italy) and Tyrol (Austria), as well as the project “Health and Nutrition – Old and New Apple Varieties at the Service of Health” (“Apfel-Fit”, 1‑1a-56) that was funded within the ERDF 2007–2013 Programme of the European Union.
The authors thank the Department of Innovation, Research and University of the Autonomous Province of Bozen-Bolzano for covering the Open Access publication costs.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
S. Baric, A. Storti, M. Hofer, W. Guerra and J. Dalla Via declare that they have no competing interests.
Additional information
The authors S. Baric and A. Storti contributed equally to the manuscript.
Caption Electronic Supplementary Material
10341_2020_483_MOESM1_ESM.xlsx
Supplementary Table S1: List of all accessions of apple trees from different germplasm or cultivar collections analysed in the present study. The abbreviations of the collection names are explained in Table 1.
10341_2020_483_MOESM2_ESM.xlsx
Supplementary Table S2: Dataset with microsatellite allele scores at 14 loci of each unique genotype representing a distinct apple cultivar, variety or rootstock. Allele lengths in base pairs (bp) are listed only once if a genotype was found to be homozygous at a particular locus. In case of triploid genotypes, having two identical alleles at a particular locus, two alleles are provided. In the latter case, it is not known which of the two alleles occurs twice. Missing data are indicated with a question mark (?).
Supplementary Table S3:
Parent-offspring relationships between diploid cultivars, for which information about at least one parent was available from the literature and this parent genotype was also present in the dataset. The table summarises the results of the relationship estimate performed with the computer programme ML-Relate (Kalinowski et al. 2006) based on 13 microsatellite loci (locus COL excluded). The Ln-likelihood for one of the four following relationships: unrelated (U), half siblings (HS), full siblings (FS), parent-offspring (PO) is shown. Column ‘R’ gives the relationship with the highest likelihood, while column ‘LnL(R)’ shows the log likelihood of R. Delta Ln(L) indicates how much lower the log likelihoods are for the other relationships. A Delta Ln(L) of ‘9999’ means that this relationship is not possible.
Supplementary Table S4:
Parent-offspring relationships between diploid cultivars, for which information about both parents was available from the literature and both presumed parent genotypes were present in the dataset. The table summarises the results of the parentage analysis for parent pairs with unknown sexes performed with the computer programme CERVUS 3.0.7 (Kalinowski et al. 2007) based on 13 microsatellite loci (locus COL excluded). The number of loci with mismatches and the LOD scores are related to the parent-offspring trio. Parent cultivar names written in regular font indicate that the parentage provided by the references was confirmed, while bold letters indicate a different parent cultivar than assumed by the references.
Supplementary Table S5:
Parent-offspring relationships between diploid cultivars, of which one of the presumed parents was excluded. The likelihood results were obtained with the computer programme ML-Relate (Kalinowski et al. 2006) based on 13 microsatellite loci (locus COL excluded). The Ln-likelihood for one of the four following relationships: unrelated (U), half siblings (HS), full siblings (FS), parent-offspring (PO) is shown. Column ‘R’ gives the relationship with the highest likelihood, while column ‘LnL(R)’ shows the log likelihood of R. Delta Ln(L) indicates how much lower the log likelihoods are for the other relationships. A Delta Ln(L) of ‘9999’ means that this relationship is not possible. The most likely parent pairs for the cultivars ‘Millicent Barnes’, ‘Nevson’, ‘Plumac’, ‘Strauwaldts Goldparmäne’ and ‘Tunda’ are provided in Supplementary Table S4.
Supplementary Table S6:
The comparison of molecular genetic profiles at five loci analysed in the present study (A) and in the study of Urrestarazu et al. (2016) (B). The original allele lengths are shown that can be aligned by the application of conversion values as shown in Table 4. The first five cultivars were selected in order to determine the conversion values, while the cultivars 6 to 25 were randomly selected from a pool of cultivars analysed in both studies in order to assess whether the allele lengths would match after the application of the determined conversion values. An exact correspondence was obtained in all the instances.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Baric, S., Storti, A., Hofer, M. et al. Molecular Genetic Identification of Apple Cultivars Based on Microsatellite DNA Analysis. I. The Database of 600 Validated Profiles. Erwerbs-Obstbau 62, 117–154 (2020). https://doi.org/10.1007/s10341-020-00483-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10341-020-00483-0