Monthly Rainfall Anomalies Forecasting for Southwestern Colombia Using Artificial Neural Networks Approaches

 ,
,  ,
,  , and
, and
Abstract
:1. Introduction
2. Study Area and Data
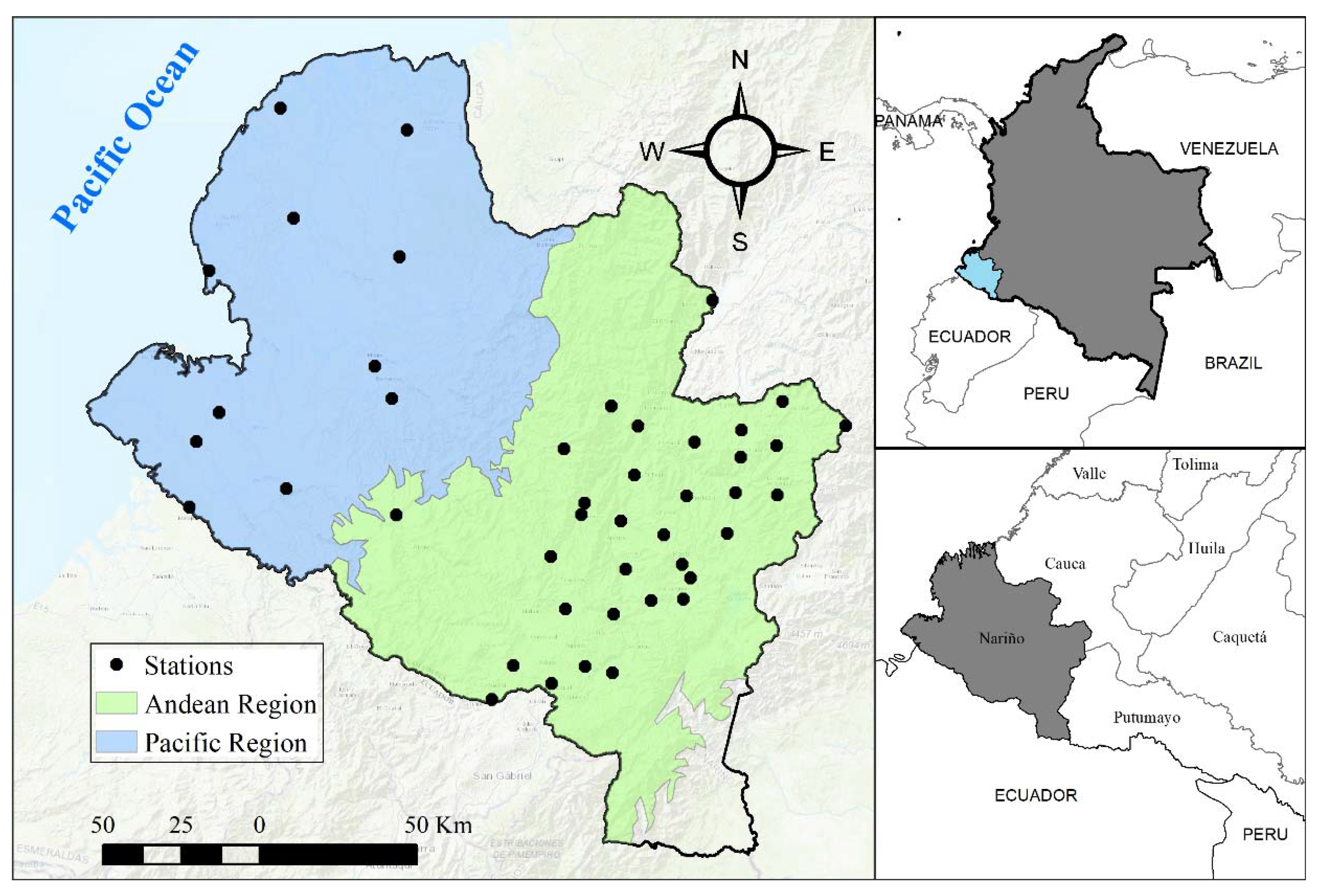
2.1. Study Area
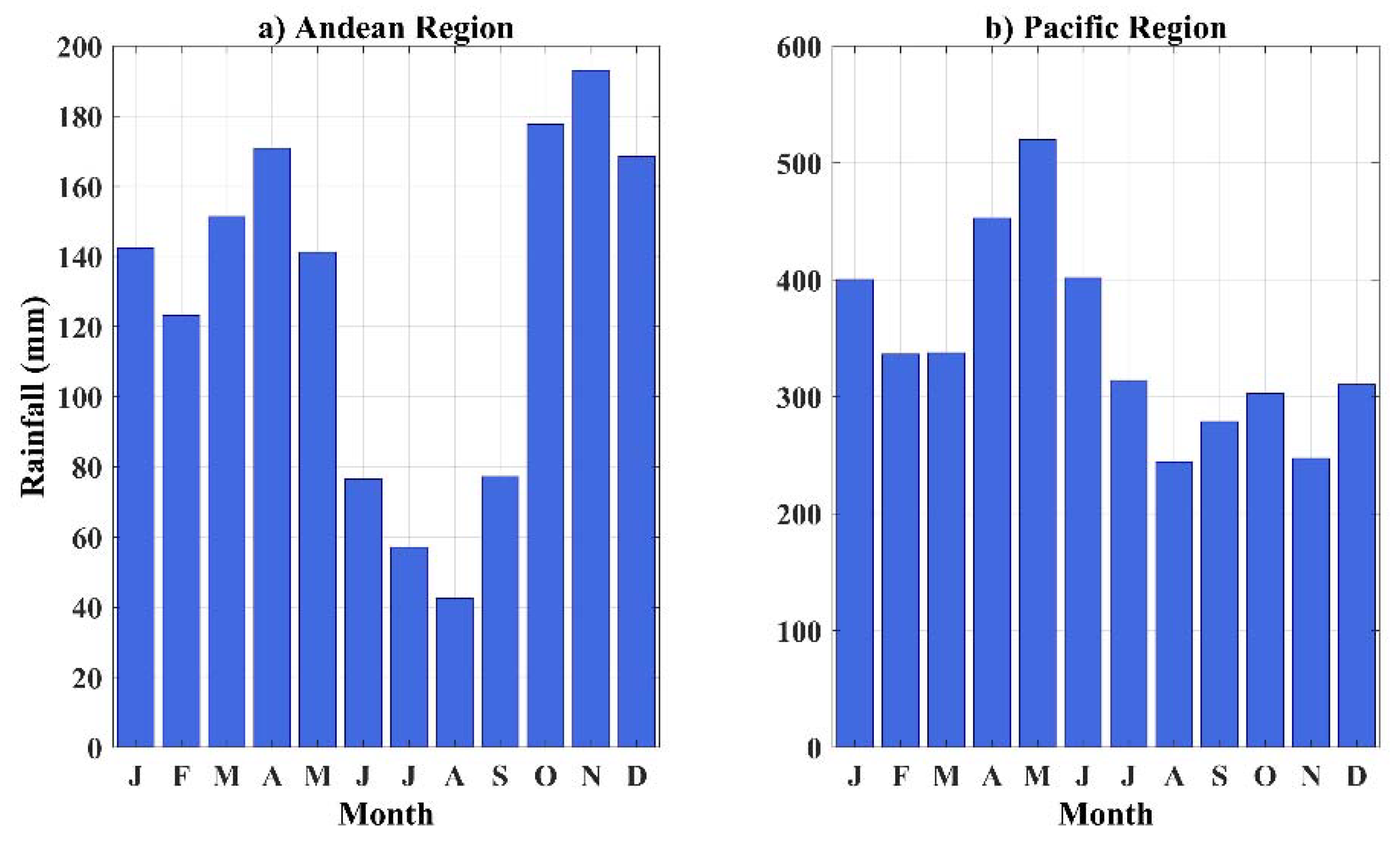
2.2. Rainfall Data
2.3. Large-Scale Climate Indices
3. Methodology
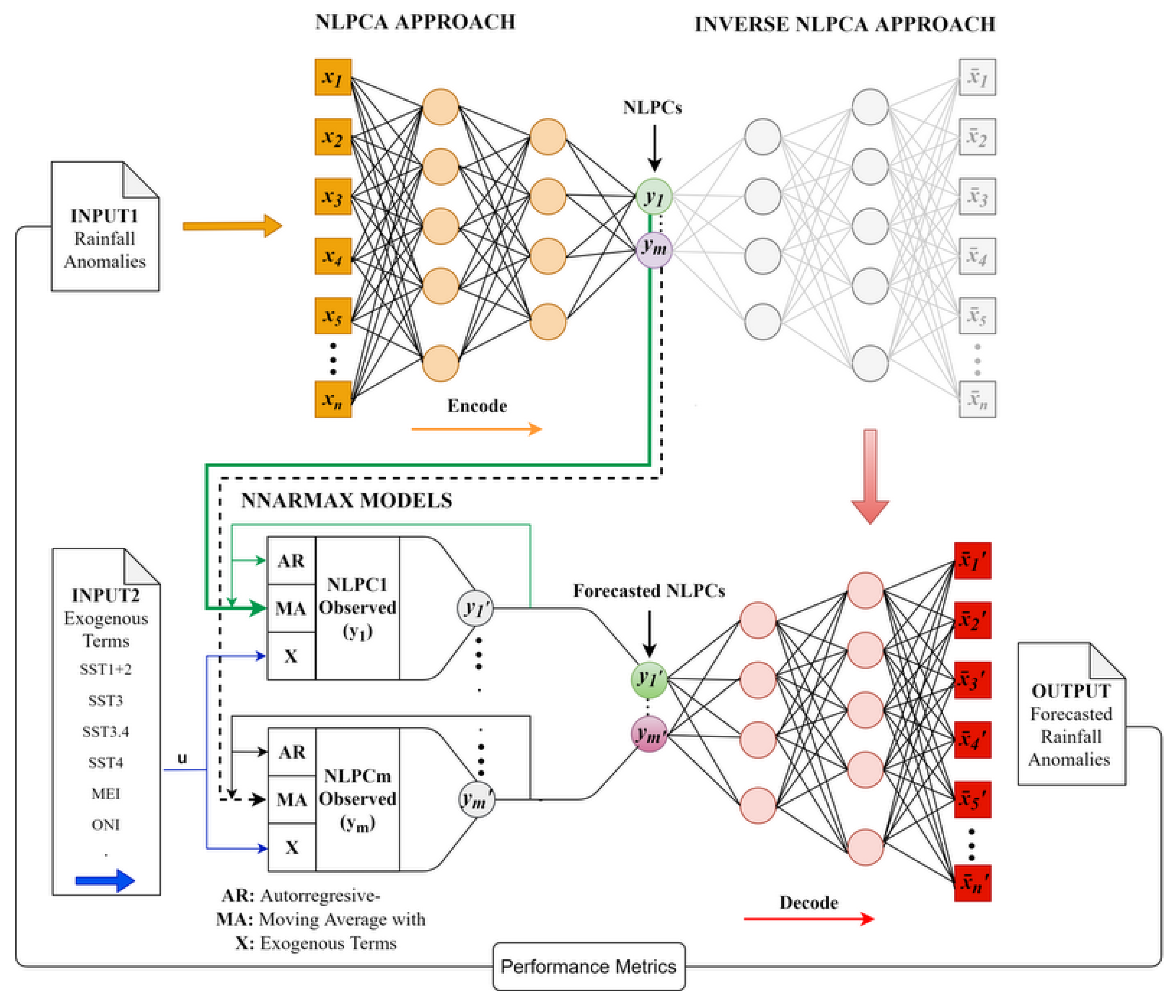
3.1. Non-Linear Principal Component Analysis
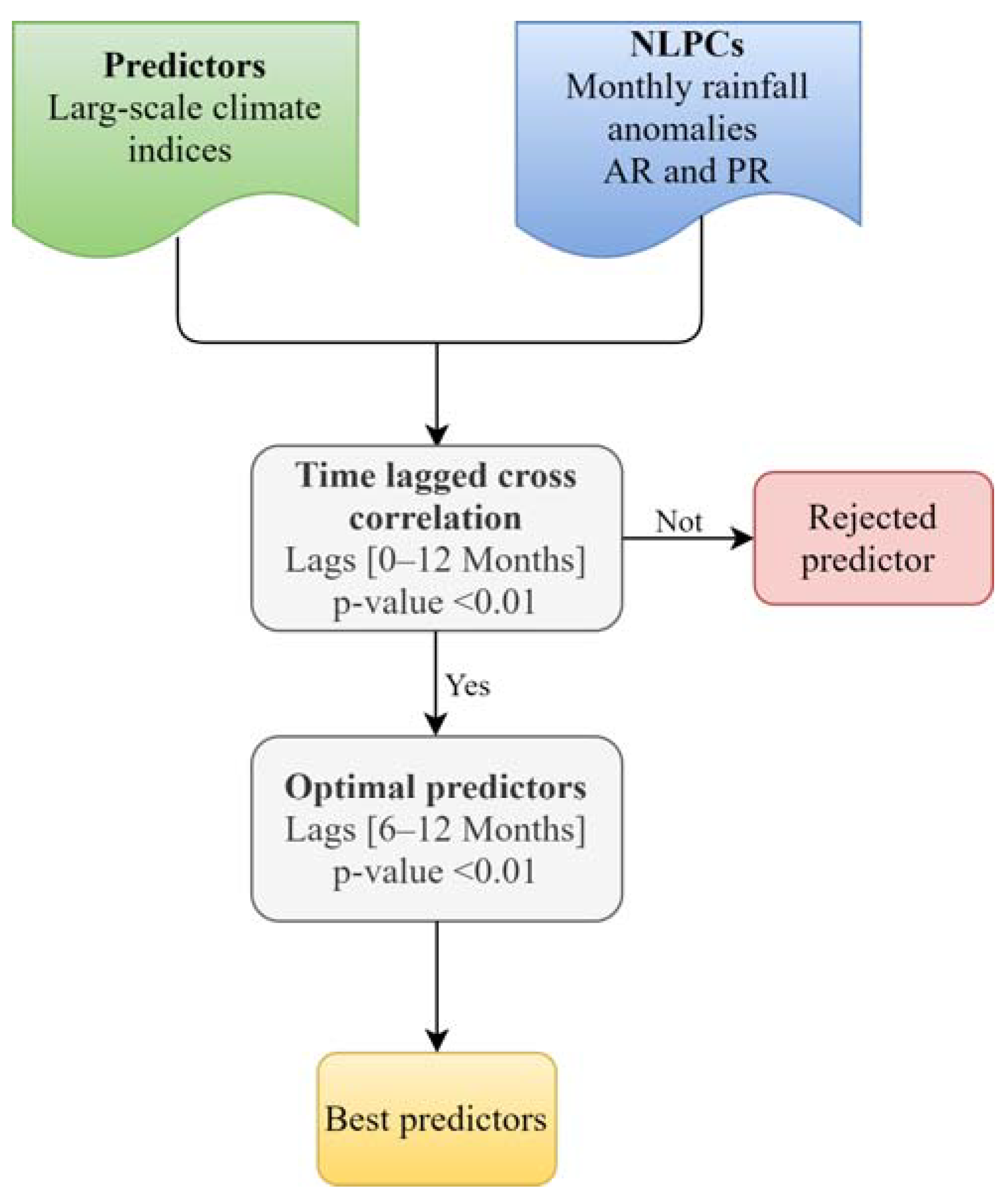
3.2. Selecting of Significant Predictors
3.3. Building a Model Using Artificial Neural Network
3.3.1. NNARMAX Model
3.3.2. Backward Elimination Method
3.4. Inverse NLPCA
3.5. Forecast Verification
4. Results and Discussion
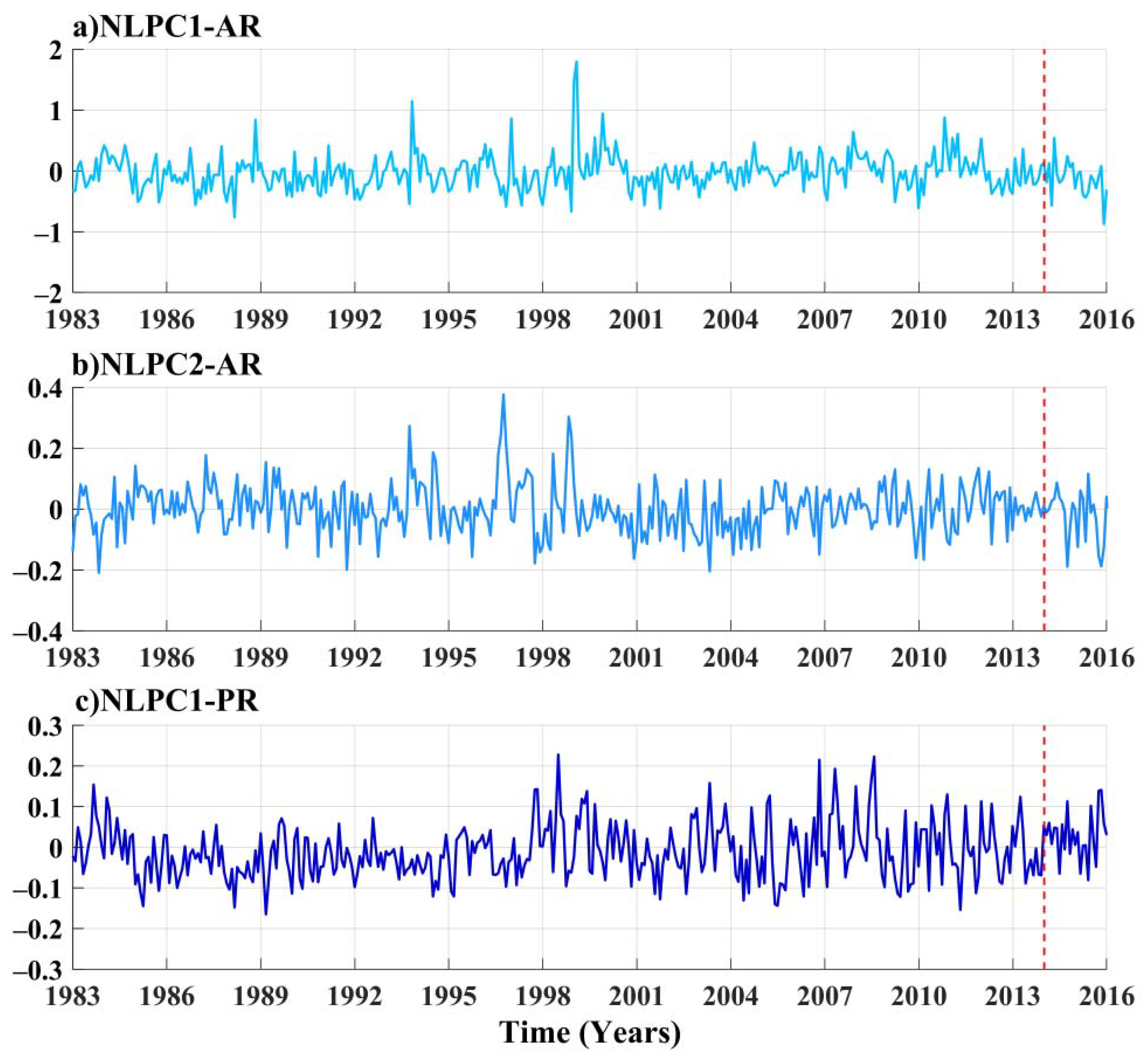
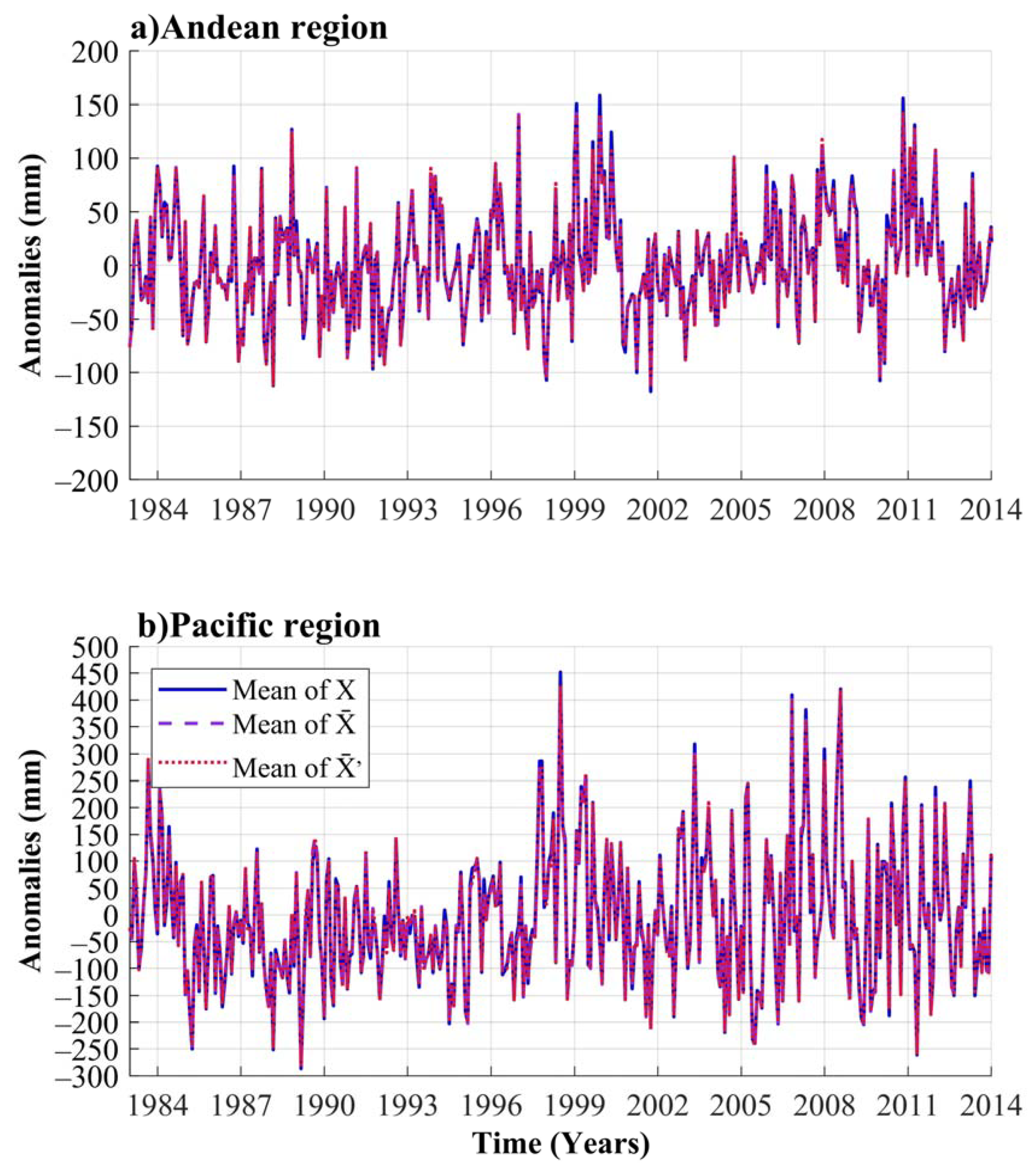
4.1. Modes of Monthly Rainfall Anomalies Variability
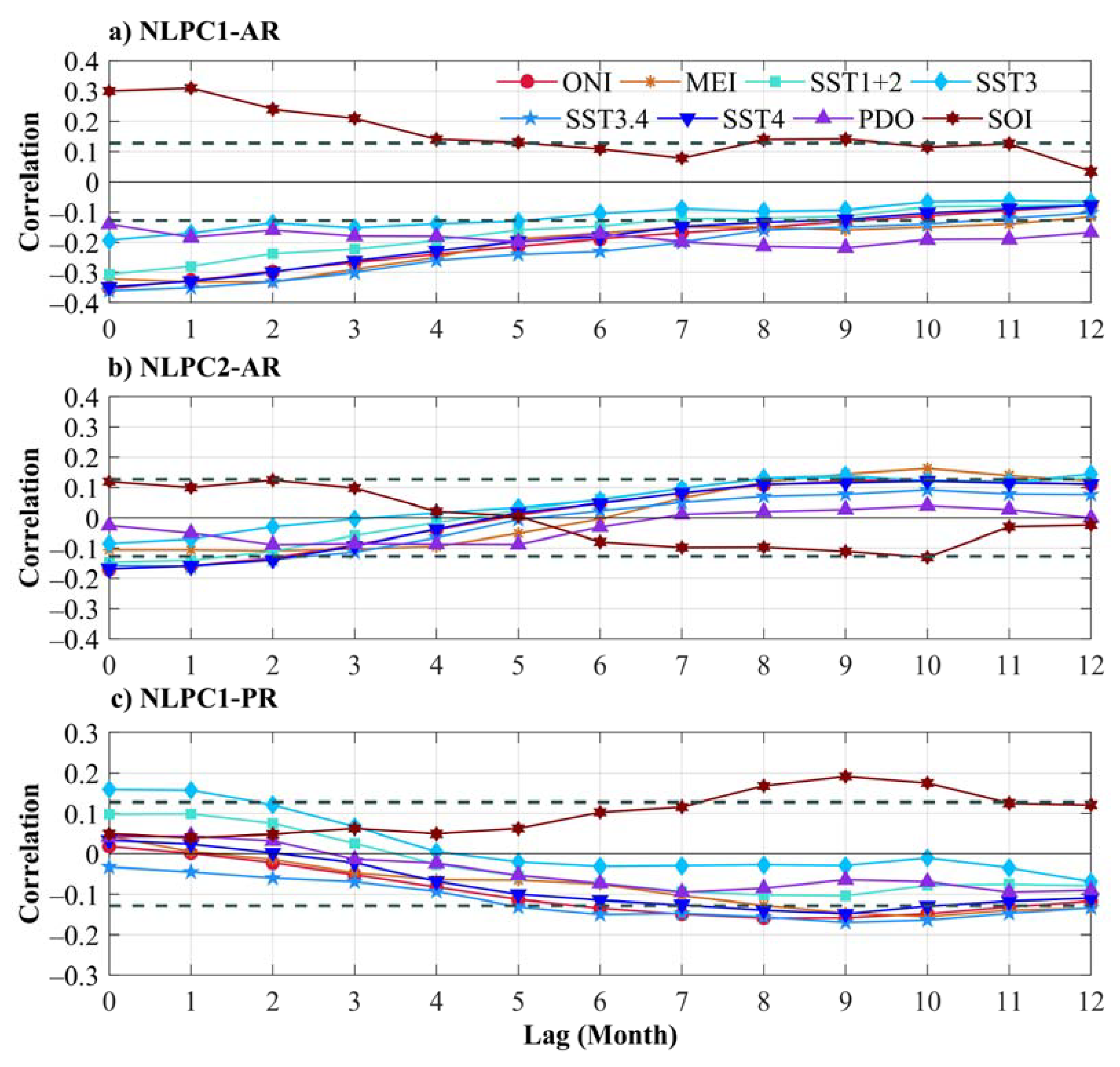
4.2. Identification of Significant Exogenous Variables
4.3. Preliminary NNARMAX Model for Rainfall Forecasting
4.4. Simplified NNARMAX Model
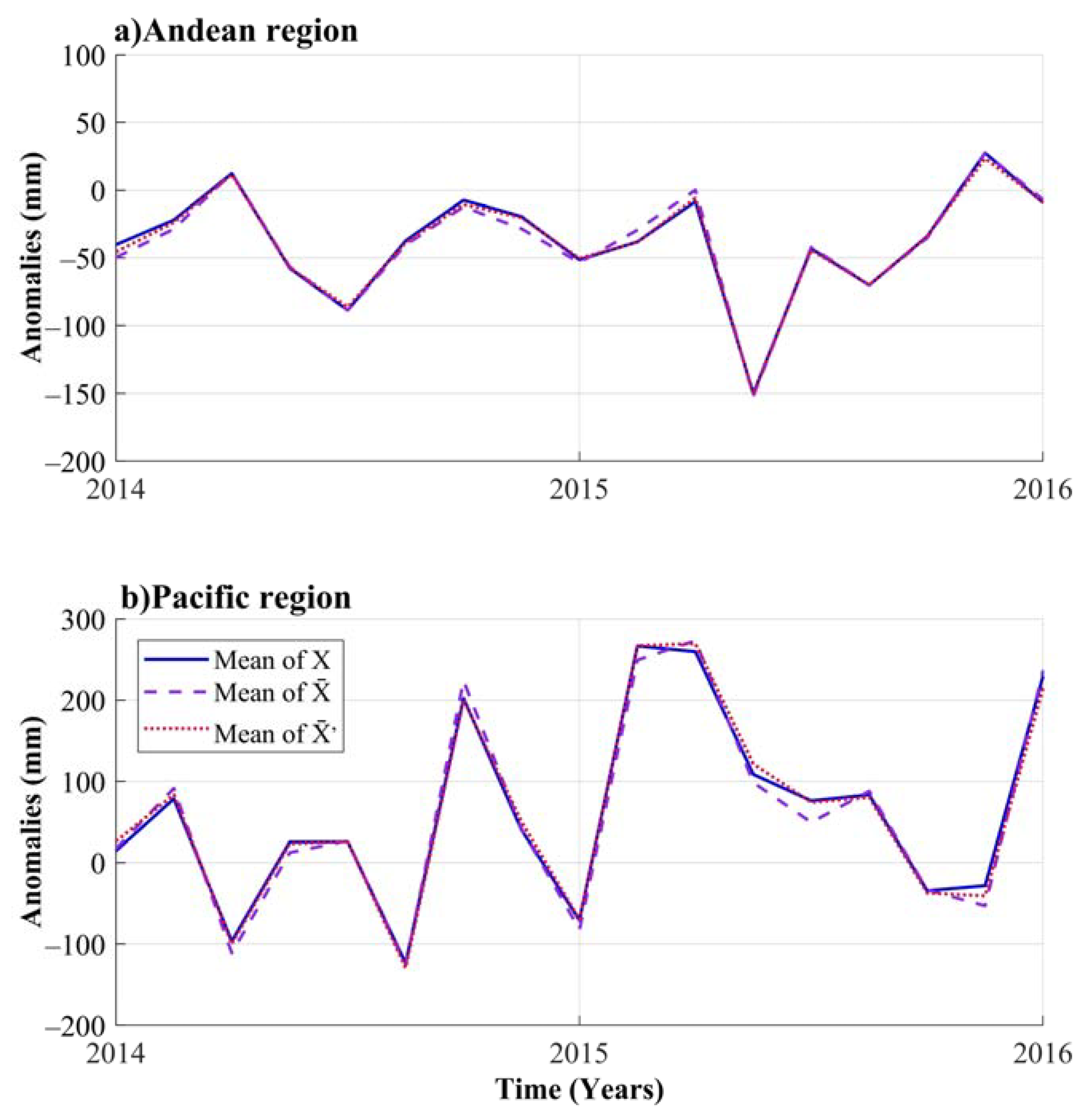
4.5. Inverse NLPCA Approach
5. Conclusions
- The Non-linear Principal Component Analysis (NLPCA) allowed the reduction of dimensions of the rainfall anomalies for AR and PR. We get two Non-linear Principal Components (NLPCs) for AR with an explained variance of the original dataset around 73% and one NLPC for PR with an explained variance of around 48%.
- The analysis of the partial cross-correlations between the main modes of the monthly rainfall variability for AR and PR obtained through NLPCA and the eight large-scale climate indices linked to the ENSO phenomenon helped identify the possible predictors (exogenous variables) for each preliminary NNARMAX model. In this study, the lagged climatic indices from 6 to 12 months with r > 0.128 were considered. The variables selected for the forecasting of NLPC1-AR (NLPC2-AR) were SST1+2, SST3.4, SST4, MEI, ONI, SOI, and PDO (SST1+2, SST3, and MEI), while for NLPC1-PR, they were SST3.4, SST4, MEI, ONI, and SOI.
- The correlation degree measure between NLPCs and climate indices, as well as the relationship persistence, were used for the selection of the best exogenous variables for each Simplified-NNARMAX model. The selected exogenous variables were refined through the backward elimination method. For NLPC1-AR (NLPC2-AR), the selected input variables were SST3.4, MEI, and PDO (SST1+2, SST3, and MEI). For NLPC1-PR, the best predictors were SST3.4 and MEI.
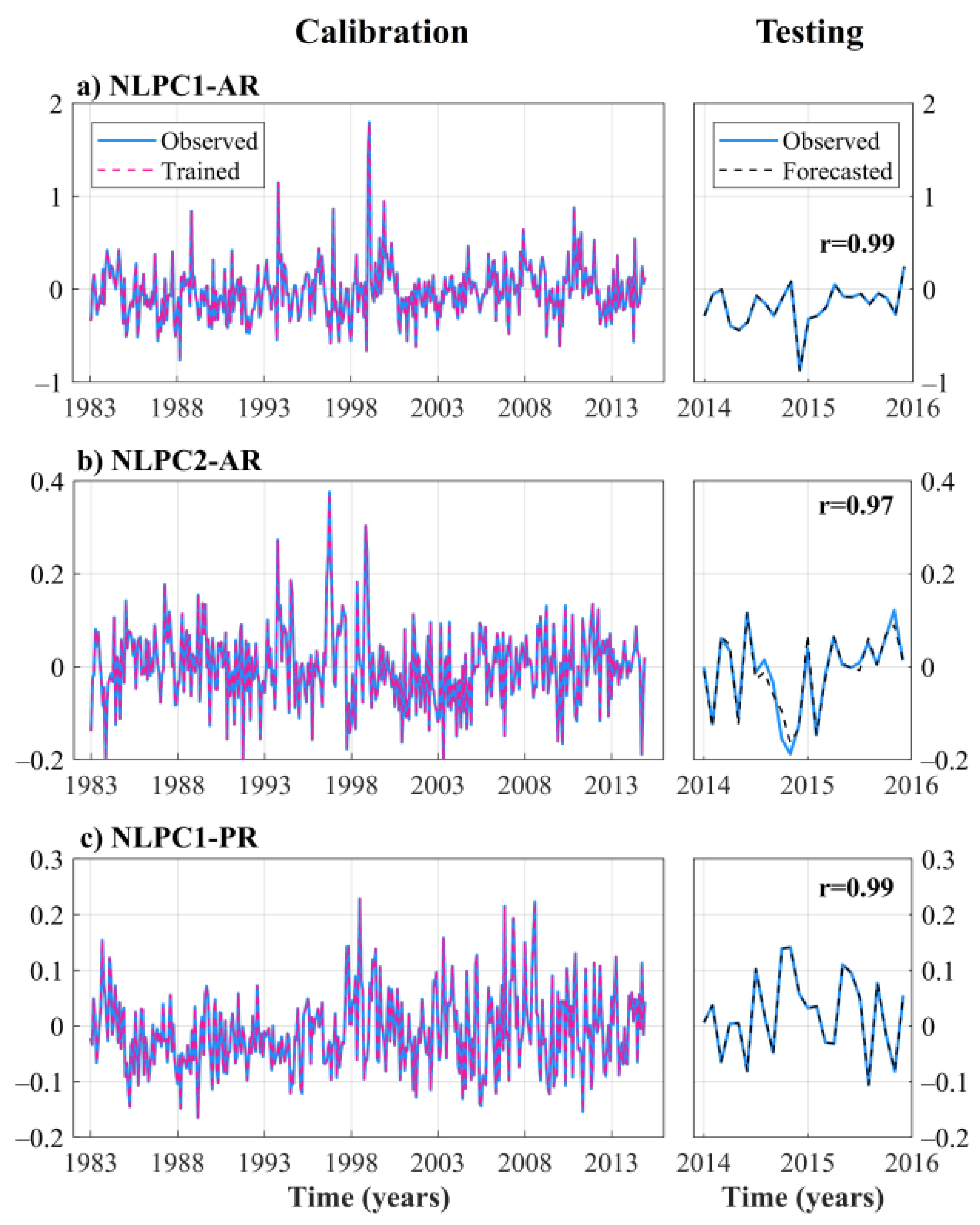
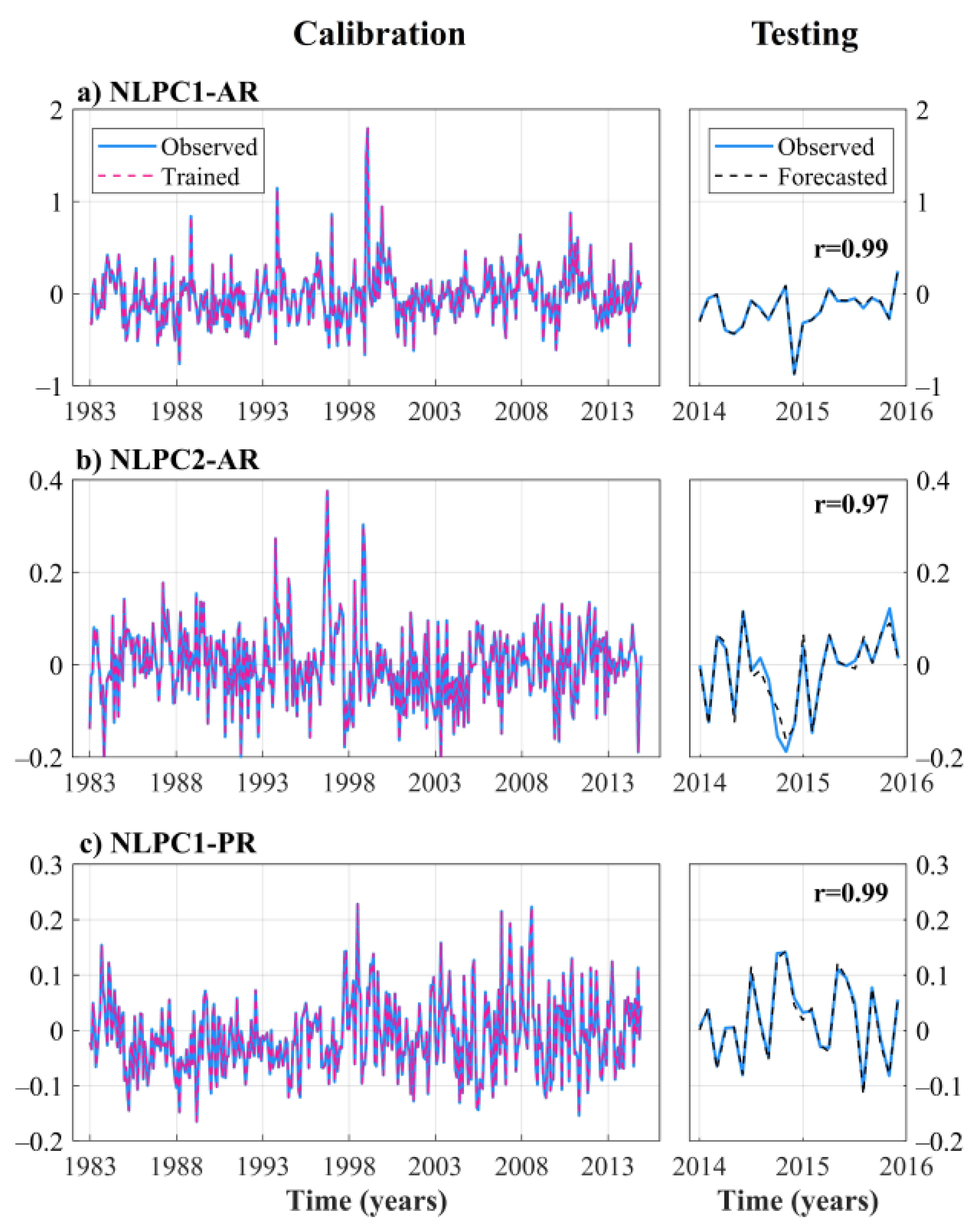
- The performance of the Simplified-NNARMAX model for NLPC1-AR, NLPC2-AR, and NLPC1-PR was measured using Pearson’s correlation between the observed series and the forecasted series. The results showed satisfactory forecasting performance with r values greater than 0.95 for the calibration and testing datasets. Although Simplified-NNARMAX uses less exogenous variables as input than the initial NNARMAX, the performance of each of the models remains preserved, confirming that the selection of exogenous variables was adequate.
- The forecasted NLPCs obtained using Simplified-NNARMAX were used as inputs of the Inverse NLPCA to get the forecasted rainfall anomalies for AR and PR. The results showed suitable forecasting performance both for the AR and for the PR. For AR, the RMSE values were 3.76 and 5.01 mm, while the MAE values were 2.64 and 3.8 mm for the calibration and testing datasets, respectively. While for PR, the RMSE values were 8.5 and 13.99 mm, and MAE values were 6.57 and 10.9 mm for the calibration and testing datasets, respectively. These results indicate that the forecast with ANN approaches is more accurate for AR than for PR. The performance measures of forecasting per each gauge station in both AR and PR support this conclusion. The RMSE values range between 17 and 165 mm, in which the RMSE values in PR are higher than those in AR.
- The ANN approach provided in this study allows the forecasting of the rainfall anomalies of each gauge station that makes up a particular region of interest using as exogenous variables the large-scale climate indices. Furthermore, this model demonstrated the possibility of rainfall forecasting five months in advance for the AR and PR in Southwestern Colombia, providing reasonable forecasting of the months that recorded rainfall above or below the average. This information is relevant for the decision-makers in the Department of Nariño, given that this model provides enough time for the proper planning and management of water resources as well as risk management.
Author Contributions
Funding
Conflicts of Interest
References
- Mehdizadeh, S. Using AR, MA, and ARMA Time Series Models to Improve the Performance of MARS and KNN Approaches in Monthly Precipitation Modeling under Limited Climatic Data. Water Resour. Manag. 2020, 34, 263–282. [Google Scholar] [CrossRef]
- Belayneh, A.; Adamowski, J.; Khalil, B.; Ozga-Zielinski, B. Long-Term SPI Drought Forecasting in the Awash River Basin in Ethiopia Using Wavelet Neural Network and Wavelet Support Vector Regression Models. J. Hydrol. 2014, 508, 418–429. [Google Scholar] [CrossRef]
- Hossain, I.; Rasel, H.; Imteaz, M.A.; Mekanik, F. Long-Term Seasonal Rainfall Forecasting Using Linear and Non-Linear Modelling Approaches: A Case Study for Western Australia. Meteorol. Atmos. Phys. 2020, 132, 131–141. [Google Scholar] [CrossRef]
- Montealegre, B.; Edgar, J.; Caicedo, J.D.P. La Variabilidad Climática Interanual Asociada al ciclo El Niño-La Niña-Oscilación del Sur y su efecto en el patrón pluviométrico de Colombia. Meteorol. Colomb. 2000, 2, 7–21. [Google Scholar]
- Solomon, S.; Qin, D.; Manning, M.; Chen, Z.; Marquis, M.; Averyt, K.B.; Tignor, M.; Miller, H.L. Climate Change 2007: The Physical Science Basis. Contribution of Working Group I to the Fourth Assessment Report of the Intergovernmental Panel on Climate Change; Cambridge University: Cambridge, UK; New York, NY, USA, 2007; Volume 996, pp. 434–497. Available online: https://www.ipcc.ch/site/assets/uploads/2018/05/ar4_wg1_full_report-1.pdf (accessed on 14 July 2020).
- Hastenrath, S.; Greischar, L. Further Work on the Prediction of Northeast Brazil Rainfall Anomalies. J. Clim. 1993, 6, 743–758. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Z.; Li, T. The Statistical Extended-Range (10–30-day) Forecast of Summer Rainfall Anomalies over the Entire China. Clim. Dyn. 2017, 48, 209–224. [Google Scholar] [CrossRef]
- Krishnamurti, T.; Stefanova, L.; Chakraborty, A.; TSV, V.; Cocke, S.; Bachiochi, D.; Mackey, B. Seasonal Forecasts of Precipitation Anomalies for North American and Asian monsoons. J. Meteorol. Soc. Jpn. Ser. II 2002, 80, 1415–1426. [Google Scholar] [CrossRef] [Green Version]
- Kang, J.; Wang, H.; Yuan, F.; Wang, Z.; Huang, J.; Qiu, T. Prediction of Precipitation Based on Recurrent Neural Networks in Jingdezhen, Jiangxi Province, China. Atmosphere 2020, 11, 246. [Google Scholar] [CrossRef] [Green Version]
- Ihara, C.; Kushnir, Y.; Cane, M.A.; De la Pena, V.H. Indian Summer Monsoon Rainfall and Its Link with ENSO and Indian Ocean Climate Indices. Int. J. Clim. J. R. Meteorol. Soc. 2007, 27, 179–187. [Google Scholar] [CrossRef]
- Hossain, I.; Rasel, H.; Imteaz, M.A.; Mekanik, F. Long-Term Seasonal Rainfall Forecasting: Efficiency of Linear Modelling Technique. Environ. Earth Sci. 2018, 77, 280. [Google Scholar] [CrossRef]
- Rahman, M.A.; Yunsheng, L.; Sultana, N. Analysis and Prediction of Rainfall Trends over Bangladesh using Mann–Kendall, Spearman’s rho Tests and ARIMA Model. Meteorol. Atmos. Phys. 2017, 129, 409–424. [Google Scholar] [CrossRef]
- Bang, S.; Bishnoi, R.; Chauhan, A.S.; Dixit, A.K.; Chawla, I. Fuzzy Logic based Crop Yield Prediction using Temperature and Rainfall parameters predicted through ARMA, SARIMA, and ARMAX models. In Proceedings of the 2019 Twelfth International Conference on Contemporary Computing (IC3), Noida, India, 8–10 August 2019; pp. 1–6. [Google Scholar]
- Ebtehaj, I.; Bonakdari, H.; Zeynoddin, M.; Gharabaghi, B.; Azari, A. Evaluation of Preprocessing Techniques for Improving the Accuracy of Stochastic Rainfall Forecast Models. Int. J. Environ. Sci. Technol. 2020, 17, 505–524. [Google Scholar] [CrossRef]
- Khalili, N.; Khodashenas, S.R.; Davary, K.; Baygi, M.M.; Karimaldini, F. Prediction of Rainfall Using Artificial Neural Networks for Synoptic Station of Mashhad: A Case Study. Arab. J. Geosci. 2016, 9, 624. [Google Scholar] [CrossRef]
- Alhamshry, A.; Fenta, A.A.; Yasuda, H.; Shimizu, K.; Kawai, T. Prediction of Summer Rainfall over the Source Region of the Blue Nile by Using Teleconnections Based on Sea Surface Temperatures. Theor. Appl. Clim. 2019, 137, 3077–3087. [Google Scholar] [CrossRef]
- Dikshit, A.; Pradhan, B.; Alamri, A.M. Temporal Hydrological Drought Index Forecasting for New South Wales, Australia Using Machine Learning Approaches. Atmosphere 2020, 11, 585. [Google Scholar] [CrossRef]
- Mishra, A.; Desai, V. Drought Forecasting Using Feed-Forward Recursive Neural Network. Ecol. Model. 2006, 198, 127–138. [Google Scholar] [CrossRef]
- Somvanshi, V.; Pandey, O.; Agrawal, P.; Kalanker, N.; Prakash, M.R.; Chand, R. Modeling and Prediction of Rainfall Using Artificial Neural Network and ARIMA Techniques. J. Ind. Geophys. Union 2006, 10, 141–151. [Google Scholar]
- Chattopadhyay, S.; Chattopadhyay, G. Univariate Modelling of Summer-Monsoon Rainfall Time Series: Comparison between ARIMA and ARNN. Comptes Rendus Geosci. 2010, 342, 100–107. [Google Scholar] [CrossRef]
- Tasadduq, I.; Rehman, S.; Bubshait, K. Application of Neural Networks for the Prediction of Hourly Mean Surface Temperatures in Saudi Arabia. Renew. Energy 2002, 25, 545–554. [Google Scholar] [CrossRef]
- Montazerolghaem, M.; Vervoort, W.; Minasny, B.; McBratney, A. Spatiotemporal Monthly Rainfall Forecasts for South-Eastern and Eastern Australia Using Climatic Indices. Theor. Appl. Climatol. 2016, 124, 1045–1063. [Google Scholar] [CrossRef]
- Poveda, G.; Waylen, P.R.; Pulwarty, R.S. Annual and Inter-Annual Variability of the Present Climate in Northern South America and Southern Mesoamerica. Palaeogeogr. Palaeoclimatol. Palaeoecol. 2006, 234, 3–27. [Google Scholar] [CrossRef]
- Carvajal, Y.; Grisales, C.; Mateus, J. Correlación de variables macroclimáticas del Océano Pacífico con los caudales en los ríos interandinos del Valle del Cauca (Colombia). Rev. Peru. Biol. 1999, 6, 9–17. [Google Scholar] [CrossRef] [Green Version]
- Poveda, G.; Vélez, J.; Mesa, O.; Hoyos, C.; Mejía, J.F.; Barco, O.J.; Correa, P.L. Influencia de fenómenos macroclimáticos sobre el ciclo anual de la hidrología colombiana: Cuantificación lineal, no lineal y Percentiles Probabilísticos. Meteorol. Colomb. 2002, 6, 121–130. [Google Scholar]
- Poveda, G. La hidroclimatología de Colombia: Una síntesis desde la escala inter-decadal hasta la escala diurna. Rev. Acad. Colomb. Cienc. 2004, 28, 201–222. [Google Scholar]
- Puertas Orozco, O.L.; Carvajal Escobar, Y. Incidence of El Niño Southern Oscillation in the Precipitation and the Temperature of the Air in Colombia, Using Climate Explorer. Ing. Desarro. 2008, 23, 104–118. [Google Scholar]
- Tootle, G.A.; Piechota, T.C.; Gutiérrez, F. The Relationships between Pacific and Atlantic Ocean Sea Surface Temperatures and Colombian Streamflow Variability. J. Hydrol. 2008, 349, 268–276. [Google Scholar] [CrossRef]
- Rojo, J.D.; Carvajal, L.F. Predicción no Lineal de caudales Utilizando Variables Macroclimáticas y análisis Espectral Singular. Tecnol. Cienc. Agua 2010, 1, 59–73. [Google Scholar]
- Ávila Díaz, Á.J.; Carvajal Escobar, Y.; Gutiérrez Serna, S.E. Análisis de la influencia de El Niño y La Niña en la oferta hídrica mensual de la cuenca del río Cali. Tecnura 2013, 18, 120–133. [Google Scholar]
- Rodríguez-Rubio, E. A Multivariate Climate Index for the Western Coast of Colombia. Adv. Geosci. 2013, 33, 21–26. [Google Scholar] [CrossRef] [Green Version]
- Restrepo, J.C.; Higgins, A.; Escobar, J.; Ospino, S.; Hoyos, N. Contribution of Low-Frequency Climatic–Oceanic Oscillations to Streamflow Variability in Small, Coastal Rivers of the Sierra Nevada de Santa Marta (Colombia). Hydrol. Earth Syst. Sci. 2019, 23, 2379–2400. [Google Scholar] [CrossRef] [Green Version]
- Cerón, W.; Carvajal-Escobar, Y.; Andreoli, R.V.; Kayano, M.T.; Gonzáles, N. Spatio-Temporal Variability of the Droughts in Cali, Colombia and Their Relationships with the El Niño-Southern Oscillation (ENSO) between 1971 and 2011. Atmósfera 2020, 33, 51–69. [Google Scholar] [CrossRef]
- Canchala, T.; Loaiza Cerón, W.; Francés, F.; Carvajal-Escobar, Y.; Andreoli, R.V.; Kayano, M.T.; Alfonso-Morales, W.; Caicedo-Bravo, E.; Ferreira de Souza, R.A. Streamflow Variability in Colombian Pacific Basins and Their Teleconnections with Climate Indices. Water 2020, 12, 526. [Google Scholar] [CrossRef] [Green Version]
- Canchala, T.; Alfonso-Morales, W.; Loaiza Cerón, W.; Carvajal-Escobar, Y.; Caicedo-Bravo, E. Teleconnections between Monthly Rainfall Variability and Large-Scale Climate Indices in Southwestern Colombia. Water 2020, 12, 1863. [Google Scholar] [CrossRef]
- Enfield, D.B.; Mestas-Nuñez, A.M. Global Modes of ENSO and non-ENSO Sea Surface Temperature Variability and Their Associations with Climate. El Niño South. Oscil. Multiscale Var. Global Reg. Impacts 2000, 89–112. Available online: https://www.aoml.noaa.gov/phod/docs/enfield/final_proofs.pdf (accessed on 30 July 2019).
- Guenni, L.B.; García, M.; Munoz, A.G.; Santos, J.L.; Cedeño, A.; Perugachi, C.; Castillo, J. Predicting Monthly Precipitation along Coastal Ecuador: ENSO and Transfer Function Models. Theor. Appl. Clim. 2017, 129, 1059–1073. [Google Scholar] [CrossRef]
- Jiang, R.; Wang, Y.; Xie, J.; Zhao, Y.; Li, F.; Wang, X. Assessment of Extreme Precipitation Events and Their Teleconnections to El Niño Southern Oscillation, A Case Study in the Wei River Basin of China. Atmos. Res. 2019, 218, 372–384. [Google Scholar] [CrossRef]
- Canchala, T.; Carvajal-Escobar, Y.; Alfonso-Morales, W.; Loaiza, W.; Caicedo, E. Estimation of Missing Data of Monthly Rainfall in Southwestern Colombia using Artificial Neural Networks. Data Brief 2019. [Google Scholar] [CrossRef]
- Scholz, M.; Kaplan, F.; Guy, C.L.; Kopka, J.; Selbig, J. Non-linear PCA: A Missing Data Approach. Bioinformatics 2005, 21, 3887–3895. [Google Scholar] [CrossRef] [Green Version]
- Poveda, G.; Álvarez, D.M.; Rueda, Ó.A. Hydro-Climatic Variability over the Andes of Colombia Associated with ENSO: A Review of Climatic Processes and Their Impact on One of the Earth’s Most Important Biodiversity Hotspots. Clim. Dyn. 2011, 36, 2233–2249. [Google Scholar] [CrossRef]
- Enciso, A.M.; Carvajal-Escobar, Y.; Sandoval, M.C. Hydrological Analysis of Historical Floods in the Upper Valley of Cauca River: Análisis hidrológico de las crecientes históricas del río Cauca en su valle alto. Ing. Y Compet. 2016, 18, 47–58. [Google Scholar]
- Trenberth, K. The Climate Data Guide: Nino SST Indices (Nino 1+ 2, 3, 3.4, 4; ONI and TNI). Available online: https://climatedataguide.ucar.edu/climate-data/nino-sst-indices-nino-12-3-34-4-oni-and-tni (accessed on 18 January 2019).
- L’Heureux, M.L.; Collins, D.C.; Hu, Z.-Z. Linear Trends in Sea Surface Temperature of the Tropical Pacific Ocean and Implications for the El Niño-Southern Oscillation. Clim. Dyn. 2013, 40, 1223–1236. [Google Scholar] [CrossRef] [Green Version]
- Wolter, K.; Timlin, M.S. El Niño/Southern Oscillation Behaviour Since 1871 as Diagnosed in An Extended Multivariate ENSO Index (MEI. ext). Int. J. Clim. 2011, 31, 1074–1087. [Google Scholar] [CrossRef]
- Hsieh, W.W. Nonlinear Principal Component Analysis by Neural Networks. Tellus A: Dyn. Meteorol. Oceanogr. 2001, 53, 599–615. [Google Scholar] [CrossRef] [Green Version]
- Scholz, M. Validation of Nonlinear PCA. Neural Process. Lett. 2012, 36, 21–30. [Google Scholar] [CrossRef]
- Hsieh, W.W.; Tang, B. Applying Neural Network Models to Prediction and Data Analysis in Meteorology and Oceanography. Bull. Am. Meteorol. Soc. 1998, 79, 1855–1870. [Google Scholar] [CrossRef]
- Monahan, A.H. Nonlinear Principal Component Analysis by Neural Networks: Theory and Application to the Lorenz System. J. Clim. 1999, 13, 821–835. [Google Scholar] [CrossRef]
- Monahan, A.H. Nonlinear Principal Component Analysis: Tropical Indo–Pacific Sea Surface Temperature and Sea Level Pressure. J. Clim. 2001, 14, 219–233. [Google Scholar] [CrossRef]
- Miró, J.J.; Caselles, V.; Estrela, M.J. Multiple Imputation of Rainfall Missing Data in the Iberian Mediterranean Context. Atmos. Res. 2017, 197, 313–330. [Google Scholar] [CrossRef]
- Kenfack, C.S.; Mkankam, F.K.; Alory, G.; Du Penhoat, Y.; Hounkonnou, M.N.; Vondou, D.A.; Nfor, G.B. Sea Surface Temperature Patterns in the Tropical Atlantic: Principal Component Analysis and Nonlinear Principal Component Analysis. Terr. Atmos. Ocean. Sci. 2017, 28, 395–410. [Google Scholar] [CrossRef] [Green Version]
- Djibo, A.G.; Karambiri, H.; Seidou, O.; Sittichok, K.; Philippon, N.; Paturel, J.E.; Saley, H.M. Linear and Non-Linear Approaches for Statistical Seasonal Rainfall Forecast in the Sirba Watershed Region (Sahel). Climate 2015, 3, 727–752. [Google Scholar] [CrossRef]
- Lee, J.; Kim, C.-G.; Lee, J.E.; Kim, N.W.; Kim, H. Application of Artificial Neural Networks to Rainfall Forecasting in the Geum River Basin, Korea. Water 2018, 10, 1448. [Google Scholar] [CrossRef] [Green Version]
- Sumi, S.M.; Zaman, M.F.; Hirose, H. A Rainfall Forecasting Method Using Machine Learning Models and Its Application to the Fukuoka City Case. Int. J. Appl. Math. Comput. Sci. 2012, 22, 841–854. [Google Scholar] [CrossRef]
- De Vos, N.; Rientjes, T. Constraints of Artificial Neural Networks for Rainfall-Runoff Modelling: Trade-Offs in Hydrological State Representation and Model Evaluation. Hydrol. Earth Syst. Sci. 2005, 9, 111–126. [Google Scholar] [CrossRef] [Green Version]
- Franch, G.; Nerini, D.; Pendesini, M.; Coviello, L.; Jurman, G.; Furlanello, C. Precipitation Nowcasting with Orographic Enhanced Stacked Generalization: Improving Deep Learning Predictions on Extreme Events. Atmosphere 2020, 11, 267. [Google Scholar] [CrossRef] [Green Version]
- Hall, R.J.; Wei, H.L.; Hanna, E. Complex Systems Modelling for Statistical Forecasting of Winter North Atlantic Atmospheric Variability: A New Approach to North Atlantic Seasonal Forecasting. Q. J. R. Meteorol. Soc. 2019, 145, 2568–2585. [Google Scholar] [CrossRef]
- Kim, T.; Shin, J.-Y.; Kim, H.; Kim, S.; Heo, J.-H. The Use of Large-Scale Climate Indices in Monthly Reservoir Inflow Forecasting and Its Application on Time Series and Artificial Intelligence Models. Water 2019, 11, 374. [Google Scholar] [CrossRef] [Green Version]
- May, R.; Dandy, G.; Maier, H. Review of Input Variable Selection Methods for Artificial Neural Networks. Artif. Neural Netw.-Methodol. Adv. Biomed. Appl. 2011, 10, 16004. [Google Scholar]
- Scholz, M.; Vigário, R. Nonlinear PCA: A new hierarchical approach. In Proceedings of the ESANN, Bruges, Belgium, 24–26 April 2002; pp. 439–444. [Google Scholar]
- Stanski, H.R.; Wilson, L.J.; Burrows, W.R. Survey of Common Verification Methods in Meteorology. WMO. World Weather Watch Technical Report (8). 1989. Available online: https://www.cawcr.gov.au/projects/verification/Stanski_et_al/Stanski_et_al.html (accessed on 27 February 2020).
- Tedeschi, R.G.; Cavalcanti, I.F.; Grimm, A.M. Influences of Two Types of ENSO on South American Precipitation. Int. J. Climatol. 2012, 33, 1382–1400. [Google Scholar] [CrossRef]
- Córdoba-Machado, S.; Palomino-Lemus, R.; Gámiz-Fortis, S.R.; Castro-Díez, Y.; Esteban-Parra, M.J. Influence of Tropical Pacific SST on Seasonal Precipitation in Colombia: Prediction Using El Niño and El Niño Modoki. Clim. Dyn. 2015, 44, 1293–1310. [Google Scholar] [CrossRef]
- Navarro, E.; Vieira, C.; Arias, P. Spatiotemporal Variability of the Precipitation in Colombia during ENSO Events. In Proceedings of the XV Seminario Iberoamericano de Redes de Agua y Drenaje, SEREA2017, Bogotá, Colombia, 27–30 November 2017. [Google Scholar]
- Montealegre, J. Estudio de la Variabilidad Climática de la Precipitación en Colombia Asociada a Procesos Oceánicos y Atmosféricos de Meso y Gran Escala; IDEAM: Bogotá, Colombia, 2009. [Google Scholar]
- Campozano, L.; Célleri, R.; Trachte, K.; Bendix, J.; Samaniego, E. Rainfall and Cloud Dynamics in the Andes: A Southern Ecuador Case Study. Adv. Meteorol. 2016, 2016. [Google Scholar] [CrossRef] [Green Version]
- Morán-Tejeda, E.; Bazo, J.; López-Moreno, J.I.; Aguilar, E.; Azorín-Molina, C.; Sanchez-Lorenzo, A.; Martínez, R.; Nieto, J.J.; Mejía, R.; Martín-Hernández, N. Climate Trends and Variability in Ecuador (1966–2011). Int. J. Climatol. 2016, 36, 3839–3855. [Google Scholar] [CrossRef] [Green Version]
- Garreaud, R.D.; Vuille, M.; Compagnucci, R.; Marengo, J. Present-Day South American Climate. Palaeogeogr. Palaeoclimatol. Palaeoecol. 2009, 281, 180–195. [Google Scholar] [CrossRef]
- Wang, S.; Huang, J.; He, Y.; Guan, Y. Combined Effects of the Pacific Decadal Oscillation and El Nino-Southern Oscillation on Global Land Dry–Wet Changes. Sci. Rep. 2014, 4, srep06651. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Córdoba-Machado, S.; Palomino-Lemus, R.; Gámiz-Fortis, S.R.; Castro-Díez, Y.; Esteban-Parra, M.J. Assessing the Impact of El Niño Modoki on Seasonal Precipitation in Colombia. Glob. Planet. Chang. 2015, 124, 41–61. [Google Scholar] [CrossRef]
- Cai, W.; Cowan, T. La Niña Modoki impacts Australia Autumn Rainfall Variability. Geophys. Res. Lett. 2009, 36. [Google Scholar] [CrossRef]
- Ashok, K.; Behera, S.K.; Rao, S.A.; Weng, H.; Yamagata, T. El Niño Modoki and its Possible Teleconnection. J. Geophys. Res. Ocean. 2007, 112. [Google Scholar] [CrossRef]
- Gutiérrez, F.; Dracup, J. An Analysis of the Feasibility of Long-Range Streamflow Forecasting for Colombia Using El Nino–Southern Oscillation Indicators. J. Hydrol. 2001, 246, 181–196. [Google Scholar] [CrossRef]
- Vicente-Serrano, S.M.; Aguilar, E.; Martínez, R.; Martín-Hernández, N.; Azorin-Molina, C.; Sánchez-Lorenzo, A.; El Kenawy, A.; Tomás-Burguera, M.; Moran-Tejeda, E.; López-Moreno, J.I. The Complex Influence of ENSO on Droughts in Ecuador. Clim. Dyn. 2017, 48, 405–427. [Google Scholar] [CrossRef] [Green Version]
- Loaiza Cerón, W.; Andreoli, R.V.; Kayano, M.T.; Ferreira de Souza, R.A.; Canchala, T.; Carvajal, Y. Comparison of Spatial Interpolation Methods for Annual and Seasonal Rainfall in Two Hotspots of Biodiversity in South America. An. Acad. Bras. Cienc. 2020, in press. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Region | Topologies | Explained Variance (%) | ||
|---|---|---|---|---|
| NLPC1 | NLPC2 | Total | ||
| AR | 33-25-15-2-15-25-33 | 55.26 | 17.46 | 72.72 |
| PR | 11-8-5-1-5-8-11 | 47.51 | – | 47.51 |
| NLPCs | Climate Index | Preliminary NNARMAX Model | ||||||
|---|---|---|---|---|---|---|---|---|
| Lags | ||||||||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 | ||
| NLPC1-AR | SST1+2 | −0.147 | −0.121 | −0.121 | −0.113 | −0.083 | −0.081 | −0.075 |
| STT3.4 | −0.231 | −0.197 | −0.164 | −0.153 | −0.137 | −0.120 | −0.102 | |
| SST4 | −0.182 | −0.148 | −0.134 | −0.124 | −0.103 | −0.089 | −0.079 | |
| MEI | −0.166 | −0.148 | −0.149 | −0.163 | −0.155 | −0.136 | −0.115 | |
| ONI | −0.189 | −0.169 | −0.151 | −0.131 | −0.112 | −0.094 | −0.078 | |
| SOI | 0.109 | 0.078 | 0.139 | 0.141 | 0.115 | 0.126 | 0.034 | |
| PDO | −0.172 | −0.198 | −0.213 | −0.218 | −0.191 | −0.190 | −0.168 | |
| NLPC2-AR | SST1+2 | 0.061 | 0.097 | 0.129 | 0.133 | 0.126 | 0.118 | 0.132 |
| SST3 | 0.058 | 0.097 | 0.132 | 0.140 | 0.122 | 0.119 | 0.145 | |
| MEI | −0.004 | 0.064 | 0.118 | 0.145 | 0.162 | 0.140 | 0.122 | |
| NLPC1-PR | STT3.4 | −0.150 | −0.147 | −0.156 | −0.170 | −0.164 | −0.147 | −0.133 |
| SST4 | −0.115 | −0.126 | −0.139 | −0.148 | −0.129 | −0.117 | −0.110 | |
| MEI | −0.075 | −0.104 | −0.127 | −0.146 | −0.155 | −0.139 | −0.134 | |
| ONI | −0.134 | −0.149 | −0.159 | −0.158 | −0.148 | −0.131 | −0.117 | |
| SOI | 0.103 | 0.116 | 0.168 | 0.192 | 0.175 | 0.125 | 0.121 | |
| NLPCs | Climate Indices | Simplified-NNARMAX Model | ||||||
|---|---|---|---|---|---|---|---|---|
| Lags | ||||||||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 | ||
| NLPC1-AR | STT3.4 | −0.231 | −0.197 | −0.164 | −0.153 | −0.137 | −0.120 | −0.102 |
| MEI | −0.166 | −0.148 | −0.149 | −0.163 | −0.155 | −0.136 | −0.115 | |
| PDO | −0.172 | −0.198 | −0.213 | −0.218 | −0.191 | −0.190 | −0.168 | |
| NLPC2-AR | SST1+2 | 0.061 | 0.097 | 0.129 | 0.133 | 0.126 | 0.118 | 0.132 |
| SST3 | 0.058 | 0.097 | 0.132 | 0.140 | 0.122 | 0.119 | 0.145 | |
| MEI | −0.004 | 0.064 | 0.118 | 0.145 | 0.162 | 0.140 | 0.122 | |
| NLPC1-PR | STT3.4 | −0.150 | −0.147 | −0.156 | −0.170 | −0.164 | −0.147 | −0.133 |
| MEI | −0.075 | −0.104 | −0.127 | −0.146 | −0.155 | −0.139 | −0.134 | |
| Region | RMSE (mm) | MAE (mm) | r | |||
|---|---|---|---|---|---|---|
| Calibration | Testing | Calibration | Testing | Calibration | Testing | |
| AR | 3.76 | 5.01 | 2.64 | 3.80 | 0.99 | 0.99 |
| PR | 8.56 | 13.99 | 6.57 | 10.85 | 0.99 | 0.99 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Canchala, T.; Alfonso-Morales, W.; Carvajal-Escobar, Y.; Cerón, W.L.; Caicedo-Bravo, E. Monthly Rainfall Anomalies Forecasting for Southwestern Colombia Using Artificial Neural Networks Approaches. Water 2020, 12, 2628. https://doi.org/10.3390/w12092628
Canchala T, Alfonso-Morales W, Carvajal-Escobar Y, Cerón WL, Caicedo-Bravo E. Monthly Rainfall Anomalies Forecasting for Southwestern Colombia Using Artificial Neural Networks Approaches. Water. 2020; 12(9):2628. https://doi.org/10.3390/w12092628
Chicago/Turabian StyleCanchala, Teresita, Wilfredo Alfonso-Morales, Yesid Carvajal-Escobar, Wilmar L. Cerón, and Eduardo Caicedo-Bravo. 2020. "Monthly Rainfall Anomalies Forecasting for Southwestern Colombia Using Artificial Neural Networks Approaches" Water 12, no. 9: 2628. https://doi.org/10.3390/w12092628