
Abstract
Purpose
Within the field of life cycle assessment (LCA), simplifications are a response to the practical restrictions in the context of a study. In the 1990s, simplifications were part of a debate on streamlining within LCA. Since then, many studies have been published on simplifying LCA but with little attention to systematise the approaches available. Also, despite being pervasive during the making of LCA studies, simplifications remain often invisible in the final results. This paper therefore reviews the literature on simplification in LCA in order to systematise the approaches found today.
Methods
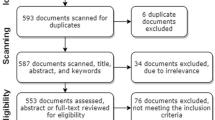
A review of the LCA simplification literature was conducted. The systematic search and selection process led to a sample of 166 publications. During the review phase, the conceptual contributions to the simplification discourse were evaluated. A dataset of 163 entries was created, listing the conceptual contributions to the simplification debate. An empirically grounded analysis led to the generative development of a systematisation of simplifications according to their underlying simplifying logic.
Results and discussion
Five simplifying logics were identified: exclusion, inventory data substitution, qualitative expert judgment, standardisation and automation. Together, these simplifying logics inform 13 simplification strategies. The identified logics represent approaches to handle the complexities of product systems and expectations of the users of LCA results with the resources available to the analyst. Each simplification strategy is discussed with regard to its main applications and challenges.
Conclusions
This paper provides a first systematisation of the different simplification logics frequently applied in LCA since the original streamlining discussion. The presented terminology can help making communication about simplification more explicit and transparent, thus important for the credibility of LCA. Despite the pervasiveness of simplification in LCA, there is a relative lack of research on simplification per se, making further research describing simplification as a practice and analysing simplifications methodologically desirable.
Similar content being viewed by others

1 Introduction
Simplifications are part of daily practice for LCA practitioners. Resource or data limitations, the complexity of the product and the goal or timing of a study may drive an analyst to simplify some aspects of LCA work. It is difficult to imagine an LCA study which does not contain any simplification in at least part of the assessment. Simplifications are a way of getting work done and reducing the complexity of the task (Star 1983). In the LCA community, the notion of simplification has traditionally been connected to a desire for easier and quicker assessment (Curran and Young 1996) and framed by concerns that LCA is too complex to be used routinely (Graedel and Lifset 2016).
Simplifying LCA became a subject of debate in the LCA community when the US environmental protection agency (EPA) hosted a conference on LCA streamlining in 1995 (Curran and Young 1996). Several prominent publications introduced ideas on how to simplify LCA (e.g. Christiansen 1997; Graedel 1998; Todd and Curran 1999; Weitz et al. 1996). A guiding theme in these contributions was the desire to reduce the data work involved in LCA. This goal was pursued primarily through the exclusion of inventory data and impact categories, the use of surrogate data (Christiansen 1997; Todd and Curran 1999; Weitz et al. 1996) and matrix approaches to LCA (Graedel 1998). Next to an instrumental purpose, the streamlining debate also served to highlight the importance of simplifications in LCA work.
In the decades that followed the EPA conference, LCA has matured into a dominant environmental assessment methodology with applications in many sectors and domains. Commercial and non-commercial software and database packages, sector-specific standards and ready-made impact assessment methodologies have greatly aided the diffusion of LCA methodology. The ever-growing pool of LCA studies suggests that LCA is more accessible today than ever. At the same time, the original reasons for simplifying LCA—resource limitations, the product’s complexity, the goal or timing of a study—are still the chief concerns of most analysts. Given the impressive developments within the LCA community, it seems timely to examine whether simplification strategies have evolved as well.
Since the initial streamlining discussion in the 1990s, a great number of studies have been produced on simplifying LCA. Many studies propose a particular simplification technique (e.g. Huebschmann et al. 2011; Olivetti et al. 2013; Pelton and Smith 2015) or apply multiple techniques to a product system (e.g. Arzoumanidis et al. 2017; Hochschorner and Finnveden 2003; Hur et al. 2005; Moberg et al. 2014; Soust-Verdaguer et al. 2016).
While the literature allows insight into some common simplification practices, it is unlikely to capture the richness and variety of simplification practices that exist throughout the LCA community. Nevertheless, little attention has been paid to systematise those practices that are documented in the simplification literature. It is striking that while simplifications are one of the key subjective choices that affect the outcome of an LCA study, their practical application is rarely transparently communicated (Tasala Gradin 2020). Despite being pervasive during the making of LCA studies, simplifications have become a less visible part of LCA work than they were during the streamlining debate.
This article aims to bring more attention to simplifications in LCA by showing what two decades of simplification practices have contributed to the LCA literature. Compared with previous studies on LCA simplification (Arzoumanidis et al. 2014; Moberg et al. 2014), this article adopts a wider scope and a more generative approach. Rather than focus on a specific product system, this article presents a review of simplification practices prevalent in the LCA literature. Simplifications cover methodological simplifications, such as exclusions in the inventory model, but also practices that simplify LCA work, such as automated data integration. The findings from the review are systematised into a framework distinguishing between different simplifying logics. Based on the findings, this article discusses how a systematisation of simplification strategies can inform LCA practice.
The purpose with the presented systematisation is to improve understanding about simplification practices within LCA, thus helping to promote transparency on simplification in LCA. The insights from this review may encourage LCA practitioners to make better informed decisions as to which simplification technique to apply to effectively conduct LCA work. They can also be used to more effectively communicate about simplifications in an LCA study, thus help making simplifications again a more visible part of LCA work.
2 Method
The research method combines a systematic search and review of simplification literature with a grounded-theory informed generative development of simplifying logics. A systematic search and review method starts from a comprehensive review to systematise existing evidence. However, rather than systematically counting and reporting the frequency of each answer type, the method proposes to focus on the evaluation of new conceptual insights (Grant and Booth 2009). Grounded theory is used in this literature review to prioritise a methodological reading of the empirical literature in order to let the data speak for itself. From this empirical grounding, a concept-centric analysis proceeds to categorise sets of ideas across articles (Wolfswinkel et al. 2013). The focus is thus on theory generation from empirical data and not theory verification (Alvesson and Sköldberg 2009). In practice, the research follows a five-step method proposed by Wolfswinkel et al. (2013): define, search, select, analyse and present. The application of these five steps in this study is outlined below.
Define
The definition of the search terms emerged from four works about simplification in environmental LCA that were known to be early publications on the topic (Christiansen 1997; Curran and Young 1996; Graedel 1998; Todd and Curran 1999). An initial reading of these publications revealed that simplification, streamlining, scoping and screening were terms that were closely related to each other and would produce useful terms to define the search query.
Search
Searches on the research databases ‘Web of Science’ and ‘Scopus’ were conducted, combining different ways of spelling ‘LCA’ with ‘simplification’, ‘streamlining’,Footnote 1 ‘scoping’ and ‘screening’ (c.f. Table 1). A search on Scopus for ‘title, abstract and keywords’ provided too many hits to review them qualitatively (2653). It was therefore decided to restrict the sample to articles that have these keywords in the title. This produced an initial list of 147 (Scopus) and 132 (Web of Science) references (c.f. Table 1). A limitation of the title-based search is that it only includes papers that explicitly self-identify simplification as the main research topic or contribution. This restriction was perceived useful as it steers sampling towards articles that make a conceptual contribution to the simplification discourse. During the research process, the sample was complemented with 33 articles identified using a snowball sampling method and suggestions from co-authors and reviewers. The aim was to increase the quality of the sample (Wolfswinkel et al. 2013).
Select
After removing duplicates, an initial screening of the titles and abstracts of the sample references was conducted (Wolfswinkel et al. 2013). Based on this screening, 26 references were excluded from the sample because they did not focus on environmental life cycle assessment (LCA) or on a simplification technique.Footnote 2
Analyse and present
The selected articles were subjected to a more detailed screening and analysis of the content. After a systematic search, the character of review changed to an empirically grounded conceptual analysis. The analysis focussed on the qualitative differences and similarities between different simplification practices.
To make the analysis efficient, the authors attributed a level of importance of a simplification technique to the publication studied. Simplifications could be either central to the publication, applied in the publication or mentioned in the publication. Simplifications central to a publication were treated as primary sources and were always recorded and analysed. Simplifications that were applied or mentioned in a publication were only included if they contributed to a new conceptual insight to the respective simplification practice. Based on this analytical heuristic, a dataset of 163 entries of conceptual contributions to the simplification debate was created.
Using an open coding process (Wolfswinkel et al. 2013), a list of simplification techniques was compiled. Similar techniques were grouped in simplification strategies, and similar strategies in overarching simplifying logics. In line with an open coding process, existing terminologies in the publications studied were used to name the categories. This results in a systematisation where the simplification technique groups simplifications on an operational level and the simplifying logic expresses the central overarching principle to which a group of simplifications connects. Simplification strategies lie in between and connect the operational techniques with the theoretical logics. Table 2 presents an example of this systematisation for the simplifying logic ‘exclusion’. The exclusion of upstream energy sources is an example of a technique that excludes part of in the inventory model. In its own turn, exclusion in the inventory model is an example of a strategy following an exclusion simplifying logic.
3 Simplification in LCA
Following a bottom-up grouping of simplification practices in the LCA literature, five simplifying logics were identified: exclusion, inventory data substitution, qualitative expert judgment, standardisation and automation. In this section, the five identified simplifying logics are presented together with the simplification strategies and techniques that follow these logics.
3.1 Exclusion
If the LCA model is taken as a starting point, the analyst builds up an inventory model by including ever more parts of the product system and life cycle emissions. If the product system and interactions with the natural environment are the starting point, the analyst may exclude parts of that world to simplify an assessment. Inclusion and exclusion approach the issue from different angles but are essentially similar strategies for selecting what to assess.
Exclusion strategies may focus on the inventory model or on the impact categories accounted for. They allow to limit the study to those parts that are relevant to the purpose of the study. Exclusions can be reported in a goal and scope definition under system boundaries and choice of impact categories. The reported choices influence the work done during the life cycle inventory (LCI) and life cycle impact assessment (LCIA) phases, and in an iterative LCA procedure, the analyst re-addresses these choices repeatedly.
3.1.1 Exclusion in the inventory model
An analyst can simplify the inventory model by leaving out part of the product system’s life cycle from the assessment. Exclusions in the inventory model may focus on stages, (e.g. use-stage), modules (e.g. transport to end-user) or processes (e.g. softeners used in plastic packaging). Excluding a part of the product system from the inventory model reduces the amount of data the analyst needs to collect. Practically, exclusions in the inventory model can be divided into horizontal and vertical exclusion techniques. Horizontal exclusion techniques reduce the parts of the product life cycle under consideration by removing life cycle stages or modules from the inventory model. Vertical exclusion techniques reduce the detail of the inventory model in each stage by excluding processes that are deemed irrelevant (Huebschmann et al. 2011; Mueller and Besant 1999; Rebitzer et al. 2004). A well-known vertical exclusion technique is the 1% cut-off rule. Given the complexity of product systems, it is inevitable that inventory models are incomplete.
Excluding parts of the product system intends to save time and resources for data collection (Nicoletti and Notarnicola 1999). Some parts of the product system are irrelevant to the outcome of the study and can be excluded. Depending on the purpose of the study, it can be relevant to exclude parts of the product system with minor emission flows in a hotspot analysis, common parts in a comparative analysis (Huebschmann et al. 2009; Klöpffer and Grahl 2014) or up- and downstream processes outside of control of the actors involved in a design process (Lee et al. 2003; Lee and Xu 2004). It can be efficient to focus on the most significant environmental aspects (Hur et al. 2005) if these are known to the analyst.
However popular their application in LCA, exclusion strategies are not unproblematic. It can be difficult to know which parts of the system can be excluded safely without affecting the outcome of the study (Hunt et al. 1998). One way to select the most appropriate exclusion techniques is to screen the entire product life cycle at a superficial level and exclude the parts that matter least (Kressirer et al. 2013). Another way is to test multiple exclusion patterns and identify which one gives the most accurate results (Hunt et al. 1998; Kellenberger and Althaus 2009; Lasvaux et al. 2014; Nicoletti and Notarnicola 1999; Ryu et al. 2003; Valkama and Keskinen 2008).
3.1.2 Exclusion of impact categories
Life cycle impact assessment typically implies the use of a standardised impact assessment method such as ReCiPe2016. These methods provide an extensive list of impact indicators based on a state-of-the-art review of relevant environmental science (Huijbregts et al. 2017). Exclusion strategies have proven relevant to LCIA because analysts recognise that it is challenging for non-experts to understand results expressed using 17 or more impact indicators. Simplification strategies focus on reducing the number of impact categories to improve the communication of the results to a non-expert audience without affecting the outcomes of the study—i.e. the identification of hotspots, rankings and recommended decisions (Heidari et al. 2019; Soust-Verdaguer et al. 2016). The number of impact categories that can be safely excluded is dependent on the covariance between impact indicators (Huijbregts et al. 2006; Lasvaux et al. 2016; Moberg et al. 2014; Steinmann et al. 2016). The literature reports that five indicators may relatively well describe a homogenous product group such as oil (Pascual-Gonzalez et al. 2015), whereas it cautions against any exclusion of impact categories for more complex products such as mobile phones (Moberg et al. 2014).
A more radical version of this simplification strategy excludes almost all impact categories in favour of one or a few proxy indicators to communicate potential environmental impact. Popular proxy indicators are (non-renewable) cumulative energy demand (CED) and/or global warming potential (GWP) (De Benedetti et al. 2010; Duan et al. 2017; Frankl et al. 1998; Huijbregts et al. 2006; Klocke et al. 2014; Scipioni et al. 2013). These categories are understood better by a large audience, which can help to diffuse LCA results.
Criticism within the LCA community of this exclusion strategy has focussed on the extent to which impact categories can be safely excluded. Especially, the use of a single proxy indicator has been criticised for being a poor predictor of environmental impact (Moberg et al. 2014; Pascual-Gonzalez et al. 2015). To some professional decision makers, single score values may seem untrustworthy (Baitz et al. 2013). As a strategy to accomplish LCA work, the reduction of impact categories may reduce the efforts involved in generating primary emission data. Time savings have been judged to be minimal if LCI data is available (Baitz et al. 2013). The necessity to adjust the exclusion of impact categories to the specifics of the context studied makes the process more complex as well.
To sum up, an exclusion logic is prominent in inventory modelling and impact assessment strategies. While common practice in LCA, exclusion strategies may introduce inaccuracies into the results and promote burden-shifting within the product system or between impact categories. Typically, exclusion strategies aim to exclude parts that are of low relevance to the outcome of an LCA study.This makes detailed knowledge of the product system essential. Such knowledge may result from prior experience; others select appropriate techniques by reading more extensive LCA studies published elsewhere. For specific applications such as Environmental Product Declarations (EPDs) and Product Environmental Footprints (PEF), product-based rules have been developed to guide selection with regard to system boundaries and impact assessment (European Commission 2018; ISO 14027:2017).
3.2 Inventory data substitution
Data collection and generation are cornerstones of LCA work. The fit between data availability and system boundaries greatly influences the quality of LCA results. Where primary data are absent, LCA practitioners have demonstrated great inventiveness in finding alternative options. Since the emergence of standardised impact assessment methods, data work in LCA studies has been confined largely to collecting inventory data. Baumann and Tillman (2004) distinguish between three data types: product description, input flows (raw materials, energy, other physical inputs) and output flows (waste flows, emissions to air, water and land).
3.2.1 Model structure
A product description of the analysed processes provides the structure of the inventory model. To this structure, input and output flows are linked in the form of data on resources used, waste and emissions produced. An analyst may split the model structure between a foreground system and a background system and collect primary data only for the foreground system (Baumann and Tillman 2004; Klöpffer and Grahl 2014). Thereby, the analyst effectively substitutes the description of the background system for a more aggregate description of these processes. The background system is hence not excluded from the study but instead substituted by ‘black boxes’. This part of the model structure provides little detail and its inventory data can be substituted by secondary data sources.
The relation between model structure and flow data can be complicated. In ideal conditions, the purpose of the study steers foregrounding and backgrounding in the model structure and thus the detail in the input and output flow data that is collected. In practice, it can be observed that the development of the model structure is sometimes determined by the availability of flow data.
3.2.2 Input flows
Primary input data can be found in a bill of resources and is usually based on technical and economic knowledge of the product system. Data substitution of input flows is guided by a diverse set of problems that an LCA analyst encounters when modelling the inventory system. Firstly, input data is difficult to collect for complex product systems such as buildings (Bribian et al. 2009; Hester et al. 2018), cars (Danilecki et al. 2017), electronics and information and communication technology (ICT) (Moberg et al. 2014). Secondly, input data becomes quickly more difficult to collect when it resides outside the organisation that sponsors the study (Baumann and Tillman 2004; Klöpffer and Grahl 2014). Thirdly, input data is difficult to obtain for product systems that are under development. A particular product can still be under design (Chen and Chien 2004; Hur et al. 2005; Malmqvist et al. 2011; Moberg et al. 2014). Input data may simply be unavailable in research and development phase of a product system (Huebschmann et al. 2009). Continuous product development in the ICT sector reduces the amount of time available to conduct LCA (Moberg et al. 2014). Fourthly, product systems that are considered unique, such as construction projects, may complicate the collection of input data (Bribian et al. 2009). Due to these limitations, it is usually impossible to collect all input data from primary sources.
Where primary data for the bill of resources is unavailable for one reason or another, missing data can be substituted by data from other sources. Substitute data in the bill of resources may come from similar processes known internally or from other studies (Kressirer et al. 2013). Industry and patent literature have long been suggested as a source for substitute data (Bretz and Frankhauser 1996). Alternatively, an analyst may calculate mass and energy balances to fill in missing data (Huebschmann et al. 2009; Huebschmann et al. 2011; Mueller and Besant 1999). Relatively accurate data on the operational energy use of buildings can be derived from dynamic thermal simulation tools (Bribian et al. 2009; Soust-Verdaguer et al. 2016). Duan et al. (2015, 2017) have reported the use of statistical reports to estimate transport volumes and modes. Lastly, LCA databases like EcoInvent make transparent how its process data is built-up and may thus be used as a data-substitute for input flows.
3.2.3 Output flows
Output flows include waste flows as well as the emissions to air, water and land. In early LCA studies, much time was typically spent on collecting primary emission data to build up an environmental profile of each process and conduct the LCA (Baumann and Tillman 2004; Klöpffer and Grahl 2014). During the last two decades, it has become possible to substitute primary output data for the data available in LCA inventory databases. The use of databases is normally recommended for the analysis of the background processes of a product system only. In the simplification literature, different studies report the use databases to substitute primary data in foreground processes as well (Hur et al. 2005; Lee et al. 2012b; Moberg et al. 2014; Niero et al. 2014). While databases are convenient data sources, the available data may not always match the product system modelled (Moberg et al. 2014). System boundaries may differ between datasets, and the reliability and underlying assumptions of secondary data are not always clear (Niero et al. 2014). Also, only a few countries have their own comprehensive LCA database. Consequently, a significant amount of work can be required to find a data match that fits well with the description of respective processes in the analysed product system. It is common for the analyst to select a well-fitting data match based on their expertise (Lee and Xu 2004; Nicoletti and Notarnicola 1999). The closeness-of-fit between a secondary data source and the product system studied determines how appropriate the use of secondary data is to model the foreground model.
Despite the common practice of relying on LCA databases, other techniques allow for the substitution of primary emission data. Surrogate data may be collected from existing LCA studies found elsewhere (Lee et al. 2012b), or it may be estimated from a stoichiometric calculation (Arzoumanidis et al. 2013; Bretz and Frankhauser 1996; Huebschmann et al. 2011). Data from environmentally extended input-out tables allows the analyst to generate a comprehensive study outside the traditional process LCA environment (Suh 2009). Emission data collection may in some instances be skipped altogether if a relationship between mass and embodied emissions can be established. In a trial study, Moberg et al. used a regression model developed by Teehan and Kandlikar of 11 different ICT products to suggest that their greenhouse gas emissions are 27 kg/kg (Moberg et al. 2014; Teehan and Kandlikar 2013).
As a simplifying logic, data substitution is popular in LCA. Secondary data are typically easier to acquire (Lee et al. 2012b; Niero et al. 2014) and yet, they allow analysts to quantify the entire product life cycle (Bretz and Frankhauser 1996; Hur et al. 2005). Therefore, data substitution prioritises the completeness of a study over accuracy. A traditional downside of using secondary inventory data stems from the inaccuracies that it may introduce to the LCI results. While it has often been assumed that data inaccuracies even out in the end (Bretz and Frankhauser 1996), some express concerns about the ability of analysts to select appropriate data substitutes (Hester et al. 2018; Olivetti et al. 2013). Structured guidance in the selection of inventory data may be a way around this problem. It is also possible to calculate and use a probability distribution of the environmental profile of material options that are available in the same category. For example, if a particular type of steel is unknown or lacks emission data, then a distribution of the environmental profile of chromium and sheet steel materials that are available can be used as substitute (Hester et al. 2018; Olivetti et al. 2013).
3.3 Qualitative expert judgment—matrix approaches
Within the LCA process, there are many points where qualitative judgments are introduced in the quantification of impacts. ISO 14044:2006 refers to the representativeness of data, consistency and the reproducibility of the study as qualitative aspects of LCA (ISO 2006b). In order to quantify, LCA studies are based on many qualitative assumptions. Sometimes, qualitative judgment allows for avoiding a full quantification. For example, the red flag method provides the opportunity to assess impacts without calculating these impacts with characterisation values (Baumann & Tillman, 2004). In the reviewed simplification literature, the central simplification strategy that emerged on the qualitative end of the LCA spectrum is matrix approaches to LCA. The most prominent matrix approach in the simplification literature is the environmentally responsible product assessment (ERPA) matrix developed at AT&T by Graedel and Allenby (c.f. Graedel 1998). The ERPA matrix builds on a 5 × 5 grid, combining different life cycle stages and environmental stressors.Footnote 3 Using the resulting 25-cell matrix, the assessor judges for each cell the importance of a stressor in a life cycle stage (e.g. the importance of solid residues during manufacturing). Supported by a checklist with questions, the assessor assigns each cell a value between 0 and 4 based on its perceived importance. Finally, a double weighting approach allows for a final value used to assess the relative difference between solutions (Graedel 1998). The ERPA matrix has been especially popular in studies focussing on electronics and car design (Chen and Chow 2003; Hochschorner and Finnveden 2003; Hur et al. 2005; Yang and Chen 2012).
Other matrix approaches work in a similar way. They abstain from a formal quantification in favour of an expert judgment on impacts, which are then given a numerical value and aggregated (Fleischer et al. 2001; Weinberg 1998). Matrix approaches differ primarily in their assessment of environmental stressors and product system stages. They are sometimes combined with expert-based methods such as the analytical hierarchy process (AHP) and Delphi panels (Eagan and Weinberg 1999; Hur et al. 2005).
Matrix approaches are a simplification strategy that challenges the predominant idea that LCA should be a quantification of a product system and its effects. In situations where little data is available, the logic of a qualitative expert judgment may provide a suitable and quick way to assess potential hotspots. A shortage of emission data was especially common during the early days of LCA, but it may also occur during design processes where time restraints limit the possibilities to quantify the environmental effects of decisions (Lee et al. 2003; Yang and Chen 2012). Matrix approaches, therefore, aim to produce useful results within the time frame relevant to the design process (Fleischer et al. 2001; Hochschorner and Finnveden 2003; Hur et al. 2005; Weinberg 1998).
After a brief surge in popularity, applications of matrix approaches have become scarce in the simplification literature. A problem with matrix approaches is that the qualitative expert judgment does not require the collection of new data, incentivising conservative statements (Fleischer et al. 2001). The approach requires a high level of expertise (Hur et al. 2005), which indirectly requires a quantitative understanding of amounts, emissions and impacts (Fleischer et al. 2001). The arguments against matrix approaches seem to have grown in importance with the development of commercial LCA databases as well as advanced software packages. The easier quantification of product life cycles seems to have coincided with a reduced interest in matrix approaches. Nonetheless, it is worth reminding that qualitative methods remain especially useful in areas where ready-made quantitative impacts assessment methods do not do justice to all relevant environmental impacts. For example, the assessment of agricultural products suffers from an inadequate coverage of land degradation, biodiversity loss and pesticide effects in conventional impact assessment methods (van der Werf et al. 2020).
3.4 Standardisation
In science and technology studies, a standard is a set of rules that promote similarity across time and space to enable people to coordinate their actions (Bowker and Star 2000; Busch 2011; Timmermans and Epstein 2010). Within the LCA community, standards are normally not explicitly recognised as a simplifying logic. Instead, standards are typically framed within a discourse of objectivity. The effectiveness of standards has been discussed concerning their ability to reduce the differences between LCA outcomes due to subjective choices of the analyst (Säynäjoki et al. 2017; Weidema 2014). From a simplification perspective, standards follow a de facto simplification logic because they intend to offer structure and guidance for methodological choices in LCA. Methodological standards and standardised LCA tools are two simplification strategies discussed under this heading.
3.4.1 Methodological standards and guidance
As simplifications, standards and guidelines reduce the efforts involved in making methodological choices by providing access to codified expertise. The most important standards are without a doubt the ISO 14040:2006 and 14044:2006 standards which harmonise the LCA terminology as well as many important procedural requirements in LCA (ISO 2006a; ISO 2006b). The ISO standards are complemented by several sector specific standards, such as the EN15804:2012 for construction works (CEN 2019).
Next to these generic standards, a large number of very detailed standards and guidelines have been produced. Within Europe, a harmonised LCA guideline has been published by the European Commission’s Joint Research Centre (JRC) on LCA (JRC 2010). Product Category Rules (PCRs) guide the production of EPDs for market communication of specific product-systems. Under auspices of the European Commission’s Environmental Footprint initiative (EF) a harmonisation of product-based rulesFootnote 4 is envisioned within Europe (European Commission 2018). The introduction of LCA in different legal contexts will likely drive a development towards more detailed rules for how to conduct LCA. An example of which is the upcoming introduction of an LCA-based climate declaration in the permit process of residential buildings in Sweden (Boverket 2018).
3.4.2 Standardised LCA tools
Standardised LCA tools simplify modelling and data work by offering largely pre-structured inventory and impact assessment modelsFootnote 5 (e.g. Arzoumanidis et al. 2017; Beccali et al. 2016; Heidari et al. 2019; Malmqvist et al. 2011; Verghese et al. 2010). The inclusion of secondary data is beneficial as LCI usually requires many resources (Zah et al. 2009). There are many different types of tools available, as different contexts ask for different modelling structures and data use. Standardised LCA tools range from simple spreadsheet-based tools to more specialised LCA tools that resemble software packages (Horne and Verghese 2009; Kellenberger and Althaus 2009; Malmqvist et al. 2011).
The simplification literature emphasises the accuracy of LCA tools and their ease of use as key quality indicators (Arzoumanidis et al. 2017; Heidari et al. 2019; Malmqvist et al. 2011; Verghese et al. 2010). LCA tools are a good way to introduce LCA when detailed knowledge of the methodology is lacking (Malmqvist et al. 2011; Verghese et al. 2010; Zah et al. 2009). In these situations, LCA tools benefit from aligning with a user-interface that is familiar to the inexperienced user (Bribian et al. 2009), such as an Excel spreadsheet or a plug-in to already used design software (Malmqvist et al. 2011). In addition, the promise of instant feedback may be attractive to its users (Hollberg et al. 2020). While it may be apparent, users are warned that estimates from simple LCA tools do not replace more detailed LCA studies (Verghese et al. 2010; Zah et al. 2009).
The accuracy of LCA tools varies and depends mainly on the fit between the tool and the product system (Arzoumanidis et al. 2017; Heidari et al. 2019). This explains why many tools are developed with specific product systems in mind (Arzoumanidis et al. 2017; Zah et al. 2009), such as PIQET for packaging. Another development of fit-for-purpose tools is to link tools to particular uses. For example, in the north European residential building sector, one can choose between ‘all purpose’ LCA tools like OneClick LCA and BM1.0 and use specific tools like CAALA and BidCon that align, respectively, with architectural drawing and economic cost estimation.
From a simplification perspective, the proliferation of LCA standards and tools within different domains reflects the different contexts in which LCAs are conducted. Also, the proliferation reflects a desire of stakeholders to exert influence over the content of legitimate LCA practices. Because standards also serve to legitimise appropriate LCA practices, they may be difficult to grasp and do not necessarily make LCA easier to apply. To inexperienced users, it may be difficult to identify the correct set of standards that are relevant to the study.
3.5 Automation
The positioning of automation as a simplifying logic in LCA is a relatively recent development. While automating parts of LCA was advocated for early on (Bretz and Frankhauser 1996), it took a bit of time before it received attention in the simplification literature. Automation strategies can be implemented using LCA tools and software packages. The most basic automation strategy in LCA is probably the calculation and tabulation of LCI and LCIA results using spreadsheets and dedicated computational software (Baumann and Tillman 2004; Chen and Liau 2001). More advanced automation strategies have since emerged in the simplification literature. Contributions to automation in the simplification literature can be divided into computational and data integration strategies.
3.5.1 Computational LCA
A variety of methods have been suggested to simplify the computation of LCA. Modular LCA calculates the results of individual stages first before adding up the sums for each individual alternative value chain (Recchioni et al. 2007; Steubing et al. 2016). Parametric models have been used to calculate large numbers of possible configurations and find preferable alternatives (Hollberg and Ruth 2016; Pelton and Smith 2015). A top-down parametrisation of many configurations may be contrasted with a bottom-up cluster approach, which reduces the number of configurations (John 2012). The resulting cluster approach could generate rules of thumb to predict potential impacts when little information is available.
Within the reviewed simplification literature, computational LCA has been discussed in a few other publications (Chen and Chien 2004; Chen and Liau 2001; Zah et al. 2009). The Sustainability Quick Check for Biofuels (SQCB) uses questionnaire answers to model and compute a life cycle inventory based on prior knowledge of a collection of analysed product systems (Zah et al. 2009). At a more advanced level, neural network or response surface methods enable learning from existing LCA for similar products to predict impacts (Chen and Chien 2004; Chen and Liau 2001). One aspect that unites these computational simplifications is that they depend greatly on the availability of flow models and inventory data to compute. Where good quality inventory data is available, automated computational approaches may make instantly visible how potential environmental impacts change with each design decision (Hollberg et al. 2020).
3.5.2 Automated data integration
Data integration and automation strategies aim to make data easily available to the LCA analyst. Strategies may be separated into ones drawing on product system data, an automated integration of emission data and those identifying a match between the two.
Already in the 1990s work on the automated transfer of inventory data took place within the LCA community (Bretz and Frankhauser 1996). To stimulate communication between different datasets and software packages, the SPINE and SPOLD data formats were developed (Baumann and Tillman 2004), and later the ILCD and EcoSpold formats (European Commission 2010; Meinshausen et al. 2016). Today, data accessibility and interoperability are still important topics within LCA, and a reason for the development of the Global LCA Data network (GLAD). Other developments reflected in the simplification literature include the import of product system data from different computer-aided design (CAD) programmes (Koffler et al. 2008; Malmqvist et al. 2011; Soust-Verdaguer et al. 2016) and the connection between material databases and emission databases (De Benedetti et al. 2010). Today, these ideas find practical application in LCA plug-in tools for design software (Bueno and Fabricio 2018; Hollberg et al., 2020).
Automation-based strategies aim for a fast quantification of impacts (De Benedetti et al. 2010) introducing the ambition of real-time optimisation (Hollberg and Ruth 2016). The expected time and cost reductions are an important argument for automation strategies (De Benedetti et al. 2010; Hester et al. 2018; Kellenberger and Althaus 2009; Malmqvist et al. 2011; Zah et al. 2009). It enables to reduce the workload for the analyst (Kellenberger and Althaus 2009) or increase the amount of LCA work done. Automation makes it possible to assess entire product portfolios (Bretz and Frankhauser 1996; Pascual-Gonzalez et al. 2015). It also enables to increase the number of design alternatives or scenarios analysed (Hollberg and Ruth 2016; Pelton and Smith 2015; Steubing et al. 2016), so as to exploit a larger design space (Hester et al. 2018).
Automation strategies come with a cost to construct models and collect data (Hester et al. 2018; Pelton and Smith 2015). A way to reduce the data work is to use commercial databases with emission data (Chen and Liau 2001; Hester et al. 2018; Zah et al. 2009). To judge the efficiency of automation strategies, it is useful to compare the time investments in the creation of the inventory model structure and collection of flow data for the processes to the time gained from the automated use of the model on multiple cases. Time gain can be considerable when large product portfolios are assessed. The opportunity to reuse the model makes automation strategies more appropriate for relatively similar product systems (Steubing et al. 2016; Zah et al. 2009) and less suitable to accommodate radical design changes (Pelton and Smith 2015).
3.6 Additional terminology relevant for simplification
Heretofore, we have addressed five main simplifying logics in combination with different simplification strategies and techniques that follow these logics. Before discussing this classification further, we would like to pay attention to some key current terminology relevant to simplification practices.
3.6.1 Simplifying assumptions
Assumptions are not typically considered a simplification strategy on its own. At the same time, it is evident that assumptions feed-into each of the different simplification strategies discussed so far. The ISO 14040:2006 and 14044:2006 standards are rife with references to assumptions. Assumptions on system boundaries, cut-off rules, and so on should be transparently discussed during the respective phase of the LCA. Assumptions are made when simplification strategies are applied, whether one excludes part of a product system from an LCA or substitutes inventory data. The consistency of assumptions should be analysed using a consistency check. The extent to which assumptions influence the results should be part of a sensitivity analysis (ISO 2006a; ISO 2006b).
From a simplification perspective, assumptions are probably most visible in scenarios of the future state of a product system. For example, how to upscale a technology from laboratory scale to commercial production that is representative of actual future production (Dowson et al. 2012). Other situations exist where knowledge about the actual state of affairs is lacking. For example, it is assumed that the outcome of a non-representative survey on ketchup use represents actual ketchup use (Andersson et al. 1998).
Assumptions may simplify assessment by providing acceptable alternatives for the unknown and the uncertain. For example, it is assumed that all renewable energy resources are zero emission technologies (Bribian et al. 2009) or that a type of gas heater in a building is less than 100 kW (Kellenberger and Althaus 2009). Sometimes, it may serve the purpose of an analysis to make simplifying assumptions. In a paper comparing six generations of a car brand, Danilecki et al. used time-static calculations of emissions related to material use (Danilecki et al. 2017).
Simplifying assumptions may introduce inaccuracies into the LCA results (Danilecki et al. 2017; Dowson et al. 2012; Soust-Verdaguer et al. 2016). To minimise and justify such inaccuracies, it can be worthwhile to think about the kind of evidence used to make simplifying assumptions. Many LCA studies assume material use based on an educated guess by the analyst, sometimes with reference to other literature (Frankl et al. 1998; Soust-Verdaguer et al. 2016). Other studies may rely on calculations (Dowson et al. 2012; Huebschmann et al. 2010), empirical evidence (Andersson et al. 1998) as well as stakeholder opinions.
3.6.2 Screening
Screening studies are not simplifications in their own right, but they apply other approaches to determine whether more detailed studies are needed. A screening approach aims to be comprehensive but use a low level of detail (Kressirer et al. 2013). It is thought that large errors become less significant in the final aggregate results and that errors in opposite directions even each other out, which is preferred over a systematic bias generated by excluding parts of a process (Bretz and Frankhauser 1996).
Some screening approaches propose to use results from other studies (Weitz and Sharma 1998). Others use screening indicators, secondary data or standard product modules (De Benedetti et al. 2010; Huebschmann et al. 2009). A more detailed example of a screening study, however, also included many primary data points and even survey-based scenarios (Andersson et al. 1998). Screening may be attractive when many product alternatives have to be considered (Fleischer and Schmidt 1997). While screening is a simple way to start an LCA, it may lead to a more extensive LCA study in which simplification strategies are applied.
4 A systematisation of identified simplifications
The simplification practices identified in the reviewed literature led to an empirically grounded systematisation of different ways to simplify LCA. Table 3 presents five conceptual simplifying logics connected to 13 simplification strategies. Each simplification strategy is subsequently connected to its operational simplification techniques and to the main areas of concern that relate to its use.
Exclusion and inventory data substitution logics are probably the most recognised simplifying logics of those presented. They were already part of the initial debate on streamlining LCA (e.g. Christiansen 1997; Todd and Curran 1999; Weitz et al. 1996). Both aim to reduce data collection efforts, but they differ in the way to achieve this. Exclusion-based simplification strategies reduce parts of the inventory model and impacts included. Inventory data substitution-based strategies instead prioritise completeness and aim to reduce data work using already available data. The success of either approach depends largely on the degree to which these simplifications lead to inaccuracies in the final results and whether it introduces a loss of information relevant to the study. The simplification literature does not present conclusive evidence as to which simplifying logic leads to better results.
Qualitative expert judgment is a simplifying logic expressed mainly through matrix approaches to LCA. Matrix approaches mark a departure from the idea that LCA revolves around quantification of inventory flows and impacts. In doing so, matrix approaches replace a formal quantification in LCA with an evaluative judgment based on expert knowledge. Reliability issues can be addressed to some degree by implementing a consensual approach such as the Delphi method. A decline in publications focussing on matrix approaches to LCA is clear in the reviewed literature. Alternative qualitative simplifications such as the red flag method received little notice in the reviewed simplification literature and are therefore not specifically discussed.
Standardisation is a simplifying logic that aims to provide a common structure to LCA work. While usually discussed separately, methodological standards and fit-for-purpose LCA tools share ambitions to frame LCA applications. The ISO14040:2006 structures terminology and procedure but leaves considerable space for deciding how to fit methodological choices to the goal of a study. Specialised product-based standards prescribe detailed rules for specific applications. LCA tools provide pre-structured packages of methodological choices, data, and computational rules. Many LCA tools are fit-for-purpose tools that can be readily applied to specific product systems and uses of application. The proliferation of rules and tools is an area of concern from a simplification perspective. With so much choice, it may be difficult to identify what fits the context of the study. These difficulties are exacerbated when multiple standards exist that legitimate contrasting LCA practices.
Automation-based simplifications focus on computational LCA and automated data integration. Computational approaches reduce computing times and increase the number of product variations that can be considered. Automated data integration reduces data handling by importing data from inventory databases, CAD software and other data sources. In recent years, these strategies have become increasingly prevalent in the reviewed simplification literature. Automation strategies are attractive because they speed-up LCA work without necessarily reducing its scope or accuracy. It is relevant to balance modelling time with expected gains from computational LCA approaches. Furthermore, with the increase in LCA results that automation strategies facilitate, it remains important to keep traditional LCA concerns about transparency and quality of results in mind.
The five simplifying logics reflect different ways to handle complexity in an LCA model while smoothing the procedure of conducting assessments. Exclusion and inventory data substitution simplify modelling and data collection efforts. Qualitative expert judgments may allow the analyst to abstain from a formal quantification. Standardisation gives a common structure to those who seek it. Automation can greatly speed up computation and data handling. Together, they form the main categories for the systematisation of simplifications developed in this paper. Each simplifying logic binds several simplification strategies and operational techniques. The resulting framework gives an overview of the types of simplifications present in the LCA simplification literature.
5 Discussion
The streamlining debate in the 1990s introduced the idea that simplifications are a natural part of conducting LCA. Simplification was justified as a way to manage resources and time effectively to model complexity in accordance with the goal of a study (Christiansen 1997; Todd & Curran 1999). Today, simplifications are still a common practice in LCA studies. The reviewed simplification literature gives evidence of an abundance of available simplification techniques. Several publications report the use of multiple simplifications on a product system (e.g. Arzoumanidis et al. 2017; Hochschorner and Finnveden 2003; Hur et al. 2005; Hunt et al. 1998; Moberg et al. 2014; Soust-Verdaguer et al. 2016; Tasala Gradin 2020). Heretofore, little effort has been made to systematise simplification approaches in a more general way.
Organising simplifications according to five simplifying logics, as done in this paper, provides a structured and transparent way to discuss simplifications in LCA. It enables the analyst to identify similarities and differences between simplifications. For example, it helps to understand what a PCR and an LCA tool may have in common. It allows distinguishing inventory data substitutions that aim for completeness from exclusion strategies that reduce completeness of a study. The three-level structure (simplifying logic, simplification strategy and simplification technique) enables analysts to increase the granularity at which simplifications are discussed. For example, it allows distinguishing between different techniques used to exclude part of the inventory model. Most simplifications are applicable to multiple phases in the LCA method. Understanding the similarities and differences between simplifications is therefore better facilitated in a framework organised according to simplifying logics. The resulting systematisation can be used to transparently communicate about simplifications used in LCA studies. It can also serve as a heuristic to learn about available simplification opportunities.
To learn and communicate about simplifications is important for the credibility of LCA. Currently, many studies lack a transparent reporting of simplification practices. This is unfortunate, as the application of simplifications has been shown repeatedly to influence the outcome of LCA studies (Hunt et al. 1998; Tasala Gradin 2020). More transparent communication of LCA studies may thus help build confidence in the quality of LCA studies. Furthermore, the wide-ranging possibilities for simplification have made LCA accessible to those with less expertise. This type of capacity building is crucial for LCA to become globally mainstream (Rebitzer & Schäfer 2009; Wangel 2018).
To use simplification techniques appropriately requires knowledge of LCA and the simplifications at play. This point was recently illustrated in a review of LCA studies using the EcoInvent database, where the authors found widespread evidence of inconsistent use and non-transparent communication of data modelling choices (Saade et al. 2019). Despite their apparent usefulness, it is important to not use simplification techniques uncritically or as a substitute for LCA know-how. Also, LCA analysts may have to balance the desire for simple and clear outcomes with the ambition for accurate and thus more complicated representations of the product value chain (Freidberg 2015).
Previous publications have established repeatedly that there is no essential distinction between full and simplified LCA (Arzoumanidis et al. 2017; Curran and Young 1996). In practice, such distinctions are relative to the skill of the analysts themselves and to quality standards appropriate in the context of a study. Some LCA studies are so detailed that they hardly qualify as simplified LCA, even though the authors label them so (e.g. Andersson et al. 1998; Moberg et al. 2014). The systematisation presented in Table 3 enables the analyst to distinguish between simplifying practices without a need to position them against extensive LCA. In this way, simplifications can be treated as part of common practices to accomplish LCA work, instead of as an essential quality that distinguishes simplified LCA from extensive LCA.
The systematisation of simplifications in LCA can be further developed to include simplification practices that are absent from this review. This is relevant as any pragmatic classification system has imperfections (Bowker and Star 2000). Likely, the reviewed simplification literature does not reflect the full richness of simplification practices used in the LCA community. Additionally, some simplifications may connect to multiple simplifying logics. For example, while LCA tools follow a standardisation logic, they may follow automation and exclusion logics as well. While some of the simplification approaches in the literature focus on ways for the analyst to handle product systems complexities in LCA modelling, others focus on adaptations to use-contexts (decision support, ecodesign, policy making, ecolabelling, etc.). There can be considerable complexity to the use-context with regard to needs and expectations on LCA in management (Nilsson-Lindén et al. 2020) or policy-making, which deserves more attention in the simplification literature. Furthermore, more widespread adoption of life cycle thinking (LCT) may reframe current LCA practices and open up to new forms of LCA work (Heiskanen 2002). Finally, the article does not provide conclusive evidence on which simplification technique should be applied to a specific product system. No evidence has been presented about the superiority of any simplification strategy. This is consistent with the understanding that there is no one-size-fits-all approach to simplification (Todd & Curran 1999).
6 Conclusions
This paper provides a first systematisation of the different types of simplifications found in the LCA literature since the early streamlining discussion in the 1990s. Five simplifying logics were identified from the simplification literature: exclusion, inventory data substitution, qualitative expert judgment, standardisation and automation. The simplifying logics provide a terminology that distinguishes key conceptual contributions to the simplification discourse.
Simplifications are very commonplace in LCA practice yet rarely reported transparently. Aspiring to holistically assess all relevant emissions and resources across the whole life cycle of a product system, LCA users continuously face a need to cope with complexity. Facing such a colossal task in a more modest practical context, the LCA analyst will almost invariably need to simplify some aspects in an LCA study to get the work done. Given the importance of simplifications in LCA, practitioners should be equally transparent about the reasoning on simplifications as they would be on other methodological choices. The presented systematisation of simplifications provides a framework and a terminology to help practitioners to communicate more transparently about simplification in LCA.
Given the wide-spread use of simplifications in LCA, there is a relative lack of literature discussing simplification on its own merits. To begin, the simplification literature does not fully document the rich variety of simplification practices out there today. There is room for further research that describes simplification as a practice and simplifications methodologically. Furthermore, the literature is full of examples of singular simplification techniques or applications in a specific product-system but no review articles about simplification as such. There is thus also room for research analysing and systematising the consequences of different simplification strategies across product systems and types of applications. More systematic attention towards simplification would be helpful in addressing complexities in both real-world product chains and use-contexts for life cycle modelling relative to the available resources to the analyst. With this paper, we hope to open up a renewed debate on simplification practices in LCA.
Notes
A wild card (*) was used to include different suffixes for streamlining and simplification. It was judged less relevant for scoping and screening LCA.
The ERPA Matrix includes as life cycle stages premanufacture, product manufacture, product delivery, product use, refurbishment and recycling and disposal. It includes as environmental stressors the choice of material, energy use, solid residues, liquid residues and gaseous residues (Graedel 1998).
These product-based rules are referred to as Product Environmental Footprint Category Rules (PEFCR)
As opposed to all-purpose LCA software packages like GaBi, OpenLCA, SimaPro and Umberto that provide a more open modelling environment.
References
Alvesson M, Sköldberg K (2009) Reflexive methodology: new vistas for qualitative research, 2nd edn. Sage, London
Andersson K, Ohlsson T, Olsson P (1998) Screening life cycle assessment (LCA) of tomato ketchup: a case study. J Clean Prod 6:277–288. https://doi.org/10.1016/S0959-6526(98)00027-4
Arzoumanidis I, Petti L, Raggi A, Zamagni A (2013) The implementation of simplified LCA in agri-food SMEs. In: Product-Oriented Environmental Management Systems (POEMS): Improving Sustainability and Competitiveness in the Agri-Food Chain with Innovative Environmental Management Tools. pp 151-173. https://doi.org/10.1007/978-94-007-6116-2_7
Arzoumanidis I, Raggi A, Petti L (2014) Considerations when applying simplified LCA approaches in the wine sector. Sustainability 6:5018–5028. https://doi.org/10.3390/su6085018
Arzoumanidis I, Salomone R, Petti L, Mondello G, Raggi A (2017) Is there a simplified LCA tool suitable for the agri-food industry? An assessment of selected tools. J Clean Prod 149:406–425. https://doi.org/10.1016/j.jclepro.2017.02.059
Baitz M, Albrecht S, Brauner E, Broadbent C, Castellan G, Conrath P, Fava J, Finkbeiner M, Fischer M, Fullana i Palmer P, Krinke S, Leroy C, Loebel O, McKeown P, Mersiowsky I, Möginger B, Pfaadt M, Rebitzer G, Rother E, Ruhland K, Schanssema A, Tikana L (2013) LCA’s theory and practice: like ebony and ivory living in perfect harmony? Int J Life Cycle Assess 18:5–13. https://doi.org/10.1007/s11367-012-0476-x
Baumann H, Tillman AM (2004) The hitch Hiker's guide to LCA. An orientation in life cycle assessment methodology and application. Studentliteratur, Lund
Beccali M, Cellura M, Longo S, Guarino F (2016) Solar heating and cooling systems versus conventional systems assisted by photovoltaic: application of a simplified LCA tool. Sol Energy Mater Sol Cells 156:92–100. https://doi.org/10.1016/j.solmat.2016.03.025
Boverket (2018) Klimatdeklaration av byggnader. Föreslag på metod och regler. Boverket, Karlskrona
Bowker GC, Star SL (2000) Sorting things out: classification and its consequences. MIT press, Cambridge
Bretz R, Frankhauser P (1996) Screening LCA for large numbers of products: estimation tools to fill data gaps. Int J Life Cycle Assess 1:139–146. https://doi.org/10.1007/BF02978941
Bribian IZ, Uson AA, Scarpellini S (2009) Life cycle assessment in buildings: state-of-the-art and simplified LCA methodology as a complement for building certification. Build Environ 44:2510–2520. https://doi.org/10.1016/j.buildenv.2009.05.001
Bueno C, Fabricio MM (2018) Comparative analysis between a complete LCA study and results from a BIM-LCA plug-in. Automat Constr 90:188–200. https://doi.org/10.1016/j.autcon.2018.02.028
Busch L (2011) Standards: recipes for reality. MIT Press, Cambridge
CEN (2019) 15804:2012+A2:2019 European Committee for Standardization (CEN), Brussels
Chen JL, Chien HW (2004) Simple LCA by response surface method for multidisciplinary design of eco-product. Electronics Goes Green 2004. Fraunhofer, Stuttgart
Chen JL, Chow WK (2003) Matrix-type and pattern-based simple LCA for eco-innovative design of products. 3rd International Symposium on Environmentally Conscious Design and Inverse Manufacturing - Ecodesign '03. IEEE, New York. https://doi.org/10.1109/vetecf.2003.239967
Chen JL, Liau CW (2001) A simple life cycle assessment method for green product conceptual design. Second International Symposium on Environmentally Conscious Design and Inverse Manufacturing. IEEE Computer Soc, Los Alamitos
Christiansen K (1997) Simplifying LCA: just a cut?: final report from the SETAC-Europe LCA screening and streamlining working group. SETAC-Europe, Brussels
Curran MA, Young S (1996) Report from the EPA conference on streamlining LCA. Int J Life Cycle Assess 1:57–60. https://doi.org/10.1007/BF02978640
Danilecki K, Mrozik M, Smurawski P (2017) Changes in the environmental profile of a popular passenger car over the last 30 years - results of a simplified LCA study. J Clean Prod 141:208–218. https://doi.org/10.1016/j.jclepro.2016.09.050
De Benedetti B, Toso D, Baldo GL, Rollino S (2010) EcoAudit: a renewed simplified procedure to facilitate the environmentally informed material choice orienting the further life cycle analysis for Ecodesigners. Mater Trans 51:832–837. https://doi.org/10.2320/matertrans.MH200918
Dowson M, Grogan M, Birks T, Harrison D, Craig S (2012) Streamlined life cycle assessment of transparent silica aerogel made by supercritical drying. Appl Energy 97:396–404. https://doi.org/10.1016/j.apenergy.2011.11.047
Duan H, Hu M, Zhang Y, Wang J, Jiang W, Huang Q, Li J (2015) Quantification of carbon emissions of the transport service sector in China by using streamlined life cycle assessment. J Clean Prod 95:109–116. https://doi.org/10.1016/j.jclepro.2015.02.029
Duan H, Hu M, Zuo J, Zhu J, Mao R, Huang Q (2017) Assessing the carbon footprint of the transport sector in mega cities via streamlined life cycle assessment: a case study of Shenzhen, South China. Int J Life Cycle Assess 22:683–693. https://doi.org/10.1007/s11367-016-1187-5
Eagan P, Weinberg L (1999) Application of analytic hierarchy process techniques to streamlined life-cycle analysis of two anodizing processes. Environ Sci Technol 33:1495–1500. https://doi.org/10.1021/es9807338
European Commission (2010) International reference life cycle data system (ILCD) handbook - general guide for life cycle assessment - detailed guidance. Joint Research Centre. Institute for Environment and Sustainability. Publications Office of the European Union, Luxembourg
European Commission (2018) Product Environmental Footprint Category Rules Guidance, version 6.3, May 2018. Brussels
Fleischer G, Schmidt WP (1997) Iterative screening LCA in an eco-design tool. Int J Life Cycle Assess 2:20–24. https://doi.org/10.1007/BF02978711
Fleischer G, Gerner K, Kunst H, Lichtenvort K, Rebitzer G (2001) A semi-quantitative method for the impact assessment of emissions within a simplified life cycle assessment. Int J Life Cycle Assess 6:149–156. https://doi.org/10.1007/bf02978733
Frankl P, Masini A, Gamberale M, Toccaceli D (1998) Simplified life-cycle analysis of PV systems in buildings: present situation and future trends. Prog Photovoltaics 6:137–146. https://doi.org/10.1002/(sici)1099-159x(199803/04)6:2<137::Aid-pip208>3.0.Co;2-n
Freidberg S (2015) It's complicated: corporate sustainability and the uneasiness of life cycle assessment. Sci Cult 24:157–182. https://doi.org/10.1080/09505431.2014.942622
Graedel TE (1998) Streamlined life-cycle assessment. Prentice Hall, Upper Saddle River
Graedel TE, Lifset R (2016) Industrial Ecology’s first decade. In: Clift R, Druckman A (eds) Taking stock of industrial ecology. Springer, Heidelberg, pp 3–20
Grant MJ, Booth A (2009) A typology of reviews: an analysis of 14 review types and associated methodologies. Health Inf Libr J 26:91–108. https://doi.org/10.1111/j.1471-1842.2009.00848.x
Heidari MD, Mathis D, Blanchet P, Amor B (2019) Streamlined life cycle assessment of an innovative bio-based material in construction: a case study of a phase change material panel. Forests 10:16. https://doi.org/10.3390/f10020160
Heiskanen E (2002) The institutional logic of life cycle thinking. J Clean Prod 10:427–437. https://doi.org/10.1016/S0959-6526(02)00014-8
Hester J, Miller TR, Gregory J, Kirchain R (2018) Actionable insights with less data: guiding early building design decisions with streamlined probabilistic life cycle assessment. Int J Life Cycle Assess 23:1903–1915. https://doi.org/10.1007/s11367-017-1431-7
Hochschorner E, Finnveden G (2003) Evaluation of two simplified life cycle assessment methods. Int J Life Cycle Assess 8:119–128. https://doi.org/10.1065/lca2003.04.114
Hollberg A, Ruth J (2016) LCA in architectural design—a parametric approach. Int J Life Cycle Assess 21:943–960. https://doi.org/10.1007/s11367-016-1065-1
Hollberg A, Genova G, Habert G (2020) Evaluation of BIM-based LCA results for building design. Automat Constr 109:102972. https://doi.org/10.1016/j.autcon.2019.102972
Horne R, Verghese K (2009) Accelerating life cycle assessment uptake: life cycle management and 'quick' LCA tools. In: Horne R, Grant T, Verghese K (eds) Life cycle assessment: principles, practice and prospects. CSIRO, Collingwood, pp 141–160
Huebschmann S, Kralisch D, Hessel V, Krtschil U, Kompter C (2009) Environmentally benign microreaction process design by accompanying (simplified) life cycle assessment. Chem Eng Technol 32:1757–1765. https://doi.org/10.1002/ceat.200900337
Huebschmann S, Kralisch D, Breuch D, Loewe H, Scholz R, Dietrich T (2010) A deliberate green process design in microstructured reactors by accompanying (simplified) life cycle assessment. In: Klemes JJ, Lam HL, Varbanov PS (eds) Pres 2010: 13th International Conference on Process Integration, Modelling and Optimisation for Energy Saving and Pollution Reduction, vol 21. Chem Eng Trans, pp 655-660. https://doi.org/10.3303/cet1021110
Huebschmann S, Kralisch D, Loewe H, Breuch D, Petersen JH, Dietrich T, Scholz R (2011) Decision support towards agile eco-design of microreaction processes by accompanying (simplified) life cycle assessment. Green Chem 13:1694–1707. https://doi.org/10.1039/c1gc15054e
Huijbregts MAJ, Rombouts LJA, Hellweg S, Frischknecht R, Hendriks AJ, van de Meent D, Ragas AMJ, Reijnders L, Struijs J (2006) Is cumulative fossil energy demand a useful Indicator for the environmental performance of products? Environ Sci Technol 40:641–648. https://doi.org/10.1021/es051689g
Huijbregts MAJ, Steinmann ZJN, Elshout PMF, Stam G, Verones F, Vieira M, Zijp M, Hollander A, van Zelm R (2017) ReCiPe2016: a harmonised life cycle impact assessment method at midpoint and endpoint level. Int J Life Cycle Assess 22:138–147. https://doi.org/10.1007/s11367-016-1246-y
Hunt RG, Boguski TK, Weitz K, Sharma A (1998) Case studies examining LCA streamlining techniques. Int J Life Cycle Assess 3:36–42. https://doi.org/10.1007/BF02978450
Hur T, Lee J, Ryu H, Kwon E (2005) Simplified LCA and matrix methods in identifying the environmental aspects of a product system. J Environ Manag 75:229–237. https://doi.org/10.1016/j.jenvman.2004.11.014
ISO (2006a) ISO 14040:2006 Environmental management - life cycle assessment - principles and framework. International Organization for Standardization (ISO)
ISO (2006b) ISO 14044:2006 Environmental management - life cycle assessment - requirements and guidelines. International Organization for Standardization (ISO)
ISO (2017) ISO/TS 14027:2017 Environmental labels and declarations - development of product category rules. International Organization for Standarization (ISO)
John V (2012) Derivation of reliable simplification strategies for the comparative LCA of individual and "typical" newly built Swiss apartment buildings. PhD dissertation, ETH, Zurich
JRC (2010) International reference life cycle data system (ILCD) handbook - general guide for life cycle assessment - detailed guidance. Publication Office of the European Union, Luxembourg
Kellenberger D, Althaus HJ (2009) Relevance of simplifications in LCA of building components. Build Environ 44:818–825. https://doi.org/10.1016/j.buildenv.2008.06.002
Klocke F, Kampker A, Dobbeler B, Maue A, Schmieder M (2014) Simplified life cycle assessment of a hybrid Car body part. In: Lien TK (ed) 21st CIRP conference on life cycle engineering, Procedia CIRP, vol 15. Elsevier Science Bv, Amsterdam, pp 484–489. https://doi.org/10.1016/j.procir.2014.06.056
Klöpffer W, Grahl B (2014) Life cycle assessment (LCA): a guide to best practice. Wiley, Weinheim
Koffler C, Krinke S, Schebek L, Buchgeister J (2008) Volkswagen slimLCl: a procedure for streamlined inventory modelling within life cycle assessment of vehicles. Int J Veh Des 46:172–188. https://doi.org/10.1504/ijvd.2008.017181
Kressirer S, Kralisch D, Stark A, Krtschil U, Hessel V (2013) Agile green process design for the intensified Kolbe-Schmitt synthesis by accompanying (simplified) life cycle assessment. Environ Sci Technol 47:5362–5371. https://doi.org/10.1021/es400085y
Lasvaux S, Schiopu N, Habert G, Chevalier J, Peuportier B (2014) Influence of simplification of life cycle inventories on the accuracy of impact assessment: application to construction products. J Clean Prod 79:142–151. https://doi.org/10.1016/j.jclepro.2014.06.003
Lasvaux S, Achim F, Garat P, Peuportier B, Chevalier J, Habert G (2016) Correlations in life cycle impact assessment methods (LCIA) and indicators for construction materials: what matters? Ecol Indic 67:174–182. https://doi.org/10.1016/j.ecolind.2016.01.056
Lee SG, Xu X (2004) A simplified life cycle assessment of re-usable and single-use bulk transit packaging. Packag Technol Sci 17:67–83. https://doi.org/10.1002/pts.643
Lee J, Kim I, Kwon E, Hur T (2003) Comparison of simplified LCA and matrix methods in identifying the environmental aspects of products. 3rd International Symposium on Environmentally Conscious Design and Inverse Manufacturing - Ecodesign '03. IEEE, New York. https://doi.org/10.1109/vetecf.2003.240344
Lee NR, Lee SS, Kim KI, Hong SJ, Hong TW (2012a) Materials life cycle assessment of chemical strengthening glass used for touch screen panel. Mat Sci Forum 724:7–11. https://doi.org/10.4028/www.scientific.net/MSF.724.7
Lee YJ, Yang X, Blanco E (2012b) Streamlined life cycle assessment of carbon footprint of a tourist food menu using probabilistic underspecification methodology. In: 2012 IEEE International Symposium on Sustainable Systems and Technology ISSST. IEEE, New York
Malmqvist T, Glaumann M, Scarpellini S, Zabalza I, Aranda A, Llera E, Diaz S (2011) Life cycle assessment in buildings: the ENSLIC simplified method and guidelines. Energy 36:1900–1907. https://doi.org/10.1016/j.energy.2010.03.026
Meinshausen I, Müller-Beilschmidt P, Viere T (2016) The EcoSpold 2 format—why a new format? Int J Life Cycle Assess 21:1231–1235. https://doi.org/10.1007/s11367-014-0789-z
Moberg Å, Borggren C, Ambell C, Finnveden G, Guldbrandsson F, Bondesson A, Malmodin J, Bergmark P (2014) Simplifying a life cycle assessment of a mobile phone. Int J Life Cycle Assess 19:979–993. https://doi.org/10.1007/s11367-014-0721-6
Mueller KG, Besant CB (1999) Streamlining life cycle analysis: a method. First international symposium on environmentally conscious design and inverse manufacturing, Proceedings. IEEE Computer Soc, Los Alamos. https://doi.org/10.1109/ecodim.1999.747593
Nicoletti GM, Notarnicola B (1999) Streamlining LCA as a tool to evaluate the sustainability of commodities production processes. Ann Chim 89:747–755
Niero M, Di Felice F, Ren JZ, Manzardo A, Scipioni A (2014) How can a life cycle inventory parametric model streamline life cycle assessment in the wooden pallet sector? Int J Life Cycle Assess 19:901–918. https://doi.org/10.1007/s11367-014-0705-6
Nilsson-Lindén H, Diedrich A, Baumann H (2020) Life cycle work: a process study of the emergence and performance of life cycle practice. Organ Environ. https://doi.org/10.1177/1086026619893971
Olivetti E, Patanavanich S, Kirßchain R (2013) Exploring the viability of probabilistic under-specification to streamline life cycle assessment. Environ Sci Technol 47:5208–5216. https://doi.org/10.1021/es3042934
Pascual-Gonzalez J, Pozo C, Guillen-Gosalbez G, Jimenez-Esteller L (2015) Combined use of MILP and multi-linear regression to simplify LCA studies. Comput Chem Eng 82:34–43. https://doi.org/10.1016/j.compchemeng.2015.06.002
Pelton REO, Smith TM (2015) Hotspot scenario analysis: comparative streamlined LCA approaches for green supply chain and procurement decision making. J Ind Ecol 19:427–440. https://doi.org/10.1111/jiec.12191
Rebitzer G, Schäfer JH (2009) The remaining challenge--mainstreaming the use of LCA. Int J Life Cycle Assess 14:101–102. https://doi.org/10.1007/s11367-009-0077-5
Rebitzer G, Ekvall T, Frischknecht R, Hunkeler D, Norris G, Rydberg T, Schmidt WP, Suh S, Weidema BP, Pennington DW (2004) Life cycle assessment part 1: framework, goal and scope definition, inventory analysis, and applications. Environ Int 30:701–720. https://doi.org/10.1016/j.envint.2003.11.005
Recchioni M, Mandorli F, Germani M, Faraldi P, Polverini D (2007) Life-cycle assessment simplification for modular products. Advances in Life Cycle Engineering for Sustainable Manufacturing Businesses. Springer, London. https://doi.org/10.1007/978-1-84628-935-4_10
Ryu J, Kim I, Kwon E, Hur T (2003) Simplified life cycle assessment for eco-design. 2003 3rd international symposium on environmentally conscious design and inverse manufacturing - Ecodesign '03. IEEE, New York https://doi.org/10.1109/vetecf.2003.239965
Saade MRM, Gomes V, da Silva MG, Ugaya CML, Lasvaux S, Passer A, Habert G (2019) Investigating transparency regarding ecoinvent users’ system model choices. Int J Life Cycle Assess 24:1–5. https://doi.org/10.1007/s11367-018-1509-x
Säynäjoki A, Heinonen J, Junnila S, Horvath A (2017) Can life-cycle assessment produce reliable policy guidelines in the building sector? Environ Res Lett 12:013001. https://doi.org/10.1088/1748-9326/aa54ee
Scipioni A, Niero M, Mazzi A, Manzardo A, Piubello S (2013) Significance of the use of non-renewable fossil CED as proxy indicator for screening LCA in the beverage packaging sector. Int J Life Cycle Assess 18:673–682. https://doi.org/10.1007/s11367-012-0484-x
Soust-Verdaguer B, Llatas C, Garcia-Martinez A (2016) Simplification in life cycle assessment of single-family houses: a review of recent developments. Build Environ 103:215–227. https://doi.org/10.1016/j.buildenv.2016.04.014
Star SL (1983) Simplification in scientific work: an example from neuroscience research. Soc Stud Sci 13:205–228. https://doi.org/10.1177/030631283013002002
Steinmann ZJN, Schipper AM, Hauck M, Huijbregts MAJ (2016) How many environmental impact indicators are needed in the evaluation of product life cycles? Environ Sci Technol 50:3913–3919. https://doi.org/10.1021/acs.est.5b05179
Steubing B, Mutel C, Suter F, Hellweg S (2016) Streamlining scenario analysis and optimization of key choices in value chains using a modular LCA approach. Int J Life Cycle Assess 21:510–522. https://doi.org/10.1007/s11367-015-1015-3
Suh S (2009) Handbook of input-output economics in industrial ecology. Springer, Dordrecht
Tasala Gradin K (2020) Simplified life cycle assessment approaches and potential impact shifts. PhD dissertation, KTH Royal Institute of Technology, Stockholm
Teehan P, Kandlikar M (2013) Comparing embodied greenhouse gas emissions of modern computing and electronics products. Environ Sci Technol 47: 3997–4003.https://doi.org/10.1021/es303012r
Timmermans S, Epstein S (2010) A world of standards but not a standard world: toward a sociology of standards and standardization. Annu Rev Sociol 36:69–89
Todd JA, Curran MA (1999) Streamlined life-cycle assessment: a final report from the SETAC North America streamlined LCA workgroup
Valkama J, Keskinen M (2008) Comparison of simplified LCA variations for three LCA cases of electronic products from the ecodesign point of view. In: 2008 IEEE International Symposium on Electronics and the Environment. New York, pp 83–88
van der Werf HM, Knudsen MT, Cederberg C (2020) Towards better representation of organic agriculture in life cycle assessment. Nat Sustain:1–7. https://doi.org/10.1038/s41893-020-0489-6
Verghese KL, Horne R, Carre A (2010) PIQET: the design and development of an online 'streamlined' LCA tool for sustainable packaging design decision support. Int J Life Cycle Assess 15:608–620. https://doi.org/10.1007/s11367-010-0193-2
Verma A, Perumalsamy V, Shetty S, Kulm M, Sundaresan P (2013) Mutational screening of LCA genes emphasizing RPE65 in south Indian cohort of patients. PLoS One 8:e73172. https://doi.org/10.1371/journal.pone.0073172
Wangel A (2018) Globalisation and mainstreaming of LCA. In: Life cycle assessment. Springer, Heidelberg, pp 465–480
Weidema B (2014) Has ISO 14040/44 failed its role as a standard for life cycle assessment? J Ind Ecol 18:324–326. https://doi.org/10.1111/jiec.12139
Weinberg L (1998) The development of a streamlined, environmental life-cycle analysis matrix for facilities. In: Proceedings of the 1998 IEEE International Symposium on Electronics and the Environment. New York, pp. 65–70. https://doi.org/10.1109/isee.1998.675032
Weitz KA, Sharma A (1998) Practical life cycle assessment through streamlining. Environ Qual Manag 7:81–87. https://doi.org/10.1002/tqem.3310070408
Weitz KA, Todd JA, Curran MA, Malkin MJ (1996) Streamlining life cycle assessment: considerations and a report on the state of practice. Int J Life Cycle Assess 1:79–85. https://doi.org/10.1007/BF02978650
Wolfswinkel JF, Furtmueller E, Wilderom CP (2013) Using grounded theory as a method for rigorously reviewing literature. Eur J Inf Syst 22:45–55. https://doi.org/10.1057/ejis.2011.51
Yang CJ, Chen JL (2012) Forecasting the design of eco-products by integrating TRIZ evolution patterns with CBR and simple LCA methods. Expert Syst Appl 39:2884–2892. https://doi.org/10.1016/j.eswa.2011.08.150
Zah R, Faist M, Reinhard J, Birchmeier D (2009) Standardized and simplified life-cycle assessment (LCA) as a driver for more sustainable biofuels. J Clean Prod 17:S102–S105. https://doi.org/10.1016/j.jclepro.2009.04.004
Acknowledgements
Open access funding provided by Chalmers University of Technology.
Author information
Authors and Affiliations
Corresponding author
Additional information
Responsible editor: Serenella Sala
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Beemsterboer, S., Baumann, H. & Wallbaum, H. Ways to get work done: a review and systematisation of simplification practices in the LCA literature. Int J Life Cycle Assess 25, 2154–2168 (2020). https://doi.org/10.1007/s11367-020-01821-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11367-020-01821-w