
Abstract
Knowledge, in practice, is time-variant and many relations are only valid for a certain period of time. This phenomenon highlights the importance of harvesting temporal-aware knowledge, i.e., the relational facts coupled with their valid temporal interval. Inspired by pattern-based information extraction systems, we resort to temporal patterns to extract time-aware knowledge from free text. However, pattern design is extremely laborious and time consuming even for a single relation, and free text is usually ambiguous which makes temporal instance extraction extremely difficult. Therefore, in this work, we study the problem of temporal knowledge extraction with two steps: (1) temporal pattern extraction by automatically analysing a large-scale text corpus with a small number of seed temporal facts, (2) temporal instance extraction by applying the identified temporal patterns. For pattern extraction, we introduce various techniques, including corpus annotation, pattern generation, scoring and clustering, to improve both accuracy and coverage of the extracted patterns. For instance extraction, we propose a double-check strategy to improve the accuracy and a set of node-extension rules to improve the coverage. We conduct extensive experiments on real world datasets and compared with state-of-the-art systems. Experimental results verify the effectiveness of our proposed methods for temporal knowledge harvesting.



Similar content being viewed by others


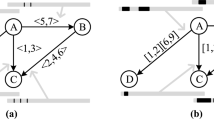
Notes
We clean the whole dataset since only the raw data is available. For Wikipedia articels, we remove all infobox, links and lists, and only keep the plain texts. For news articles, we apply keyword-based and rule-based methods to filter out noisy sentences such as URLs, emails, etc.
References
Agichtein, E., Gravano, L.: Snowball: Extracting relations from large plain-text collections. In: Proceedings of the fifth ACM conference on Digital libraries, pp. 85–94. ACM (2000)
Auer, S., Bizer, C., Kobilarov, G., Lehmann, J., Cyganiak, R., Ives, Z.: Dbpedia: A nucleus for a web of open data. In: The semantic web, pp 722–735. Springer (2007)
Brin, S.: Extracting patterns and relations from the world wide web. In: InternationalWorkshop on TheWorldWideWeb and Databases, pp. 172–183. Springer (1998)
Campos, R., Dias, G., Jorge, A.M., Jatowt, A.: Survey of temporal information retrieval and related applications. ACM Computing Surveys (CSUR) 47(2), 15 (2015)
Chang, C.H., Kayed, M., Girgis, M.R., Shaalan, K.F.: A survey of web information extraction systems. IEEE transactions on knowledge and data engineering 18(10), 1411–1428 (2006)
Chiticariu, L., Li, Y., Reiss, F.R.: Rule-based information extraction is dead! long live rule-based information extraction systems!. In: EMNLP, October, pp. 827–832 (2013)
Clark, K., Manning, C.D.: Deep reinforcement learning for mention-ranking coreference models. arXiv:1609.08667 (2016)
Cucerzan, S., Sil, A.: The msr systems for entity linking and temporal slot filling at tac 2013. In: Text Analysis Conference (2013)
Diefenbach, D., Lopez, V., Singh, K., Maret, P.: Core techniques of question answering systems over knowledge bases: a survey. Knowledge and Information systems 55(3), 529–569 (2018)
Ester, M., Kriegel, H.P., Sander, J., Xu, X., et al.: A density-based algorithm for discovering clusters in large spatial databases with noise. In: KDD, vol. 96, pp. 226–231 (1996)
Fader, A., Soderland, S., Etzioni, O.: Identifying relations for open information extraction. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing, pp 1535–1545, Association for Computational Linguistics (2011)
Ferragina, P., Scaiella, U.: Tagme: on-the-fly annotation of short text fragments (by wikipedia entities). In: Proceedings of the 19th ACM international conference on Information and knowledge management, pp 1625–1628, ACM (2010)
Garrido, G., Penas, A., Cabaleiro, B.: Uned slot filling and temporal slot filling systems at tac kbp 2013: System description. In: TAC (2013)
Herzig, J., Berant, J.: Neural semantic parsing over multiple knowledge-bases. arXiv:1702.01569 (2017)
Hoffart, J., Suchanek, F.M., Berberich, K., Weikum, G.: Yago2: A spatially and temporally enhanced knowledge base from wikipedia. Artif. Intell. 194, 28–61 (2013)
Kuzey, E., Weikum, G.: Extraction of temporal facts and events from wikipedia. In: Proceedings of the 2nd TemporalWeb AnalyticsWorkshop, pp. 25–32. ACM (2012)
Ling, X., Weld, D.S.: Temporal information extraction.. In: AAAI, vol. 10, pp 1385–1390 (2010)
Liu, Y., Hua, W., Xin, K., Zhou, X.: Context-aware temporal knowledge graph embedding. In: International Conference onWeb Information Systems Engineering, pp. 583–598 (2019)
Liu, Y., Hua, W., Zhou, X.: Extracting temporal patterns from large-scale text corpus. In: Australasian Database Conference, pp 17–30, Springer (2019)
Madotto, A., Wu, C-S, Fung, P.: Mem2seq: Effectively incorporating knowledge bases into end-to-end task-oriented dialog systems. arXiv:1804.08217 (2018)
Mahdisoltani, F., Biega, J., Suchanek, F.: Yago3: A knowledge base from multilingual wikipedias. In: 7th Biennial Conference on Innovative Data Systems Research, CIDR Conference (2014)
Mikolov, T., Yih, W.T., Zweig, G.: Linguistic regularities in continuous space word representations. In: Proceedings of NAACL-HLT, pp. 746–751 (2013)
Min, B., Grishman, R., Wan, L., Wang, C., Gondek, D.: Distant supervision for relation extraction with an incomplete knowledge base. In: Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp 777–782 (2013)
Mintz, M., Bills, S., Snow, R., Jurafsky, D.: Distant supervision for relation extraction without labeled data. In: Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 2-Volume 2, pp. 1003–1011. Association for Computational Linguistics (2009)
Mitchell, T., Cohen, W., Hruschka, E., Talukdar, P., Betteridge, J., Carlson, A., Dalvi, B., Gardner, M., Kisiel, B., Krishnamurthy, J., et al.: Never-ending learning (2015)
Nakashole, N., Theobald, M., Weikum, G.: Scalable knowledge harvesting with high precision and high recall. In: Proceedings of the fourth ACM international conference on Web search and data mining, pp. 227–236 (2011)
Nakashole, N., Weikum, G., Suchanek, F.: Patty: a taxonomy of relational patterns with semantic types. In: Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, pp. 1135–1145. Association for Computational Linguistics (2012)
Qu, J., Hua, W., Ouyang, D., Zhou, X., Li, X.: A fine-grained and noise-aware method for neural relation extraction. In: Proceedings of the 28th ACM International Conference on Information and Knowledge Management, pp. 659–668 (2019)
Qu, J., Ouyang, D., Hua, W., Ye, Y., Li, X.: Distant supervision for neural relation extraction integrated with word attention and property features. Neural Netw. 100, 59–69 (2018)
Qu, J., Ouyang, D., Hua, W., Ye, Y., Zhou, X.: Discovering correlations between sparse features in distant supervision for relation extraction. In: Proceedings of the twelfth ACM international conference on web search and data mining, pp. 726–734 (2019)
Schmitz, M., Bart, R., Soderland, S., Etzioni, O., et al.: Open language learning for information extraction. In: Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, pp. 523–534. Association for Computational Linguistics (2012)
Shen, W., Wang, J., Han, J.: Entity linking with a knowledge base: Issues, techniques, and solutions. IEEE Trans. Knowl. Data Eng. 27(2), 443–460 (2014)
Strötgen, J., Gertz, M.: Heideltime: High quality rule-based extraction and normalization of temporal expressions. In: Proceedings of the 5th International Workshop on Semantic Evaluation, pp 321–324, Association for Computational Linguistics (2010)
Suchanek, F., Weikum, G.: Knowledge harvesting in the big-data era. In: Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, pp. 933–938. ACM (2013)
Talukdar, P.P., Wijaya, D., Mitchell, T.: Coupled temporal scoping of relational facts. In: Proceedings of the fifth ACM international conference on Web search and data mining, pp 73–82, ACM (2012)
Vrandečić, D., Krötzsch, M: Wikidata: a free collaborative knowledge base (2014)
Wang, Y., Dylla, M., Spaniol, M., Weikum, G.: Coupling label propagation and constraints for temporal fact extraction. In: Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Short Papers-Volume 2, pp. 233–237. Association for Computational Linguistics (2012)
Wang, Y., Yang, B., Qu, L., Spaniol, M., Weikum, G.: Harvesting facts from textual web sources by constrained label propagation. In: Proceedings of the 20th ACM international conference on Information and knowledge management, pp 837–846, ACM (2011)
Wang, X., Zhang, H., Li, Q., Shi, Y., Jiang, M.: A novel unsupervised approach for precise temporal slot filling from incomplete and noisy temporal contexts. In: The World Wide Web Conference, pp. 3328–3334. ACM (2019)
Wang, Y., Zhu, M., Qu, L., Spaniol, M., Weikum, G.: Timely yago: harvesting, querying, and visualizing temporal knowledge from wikipedia. In: Proceedings of the 13th International Conference on Extending Database Technology, pp 697–700, ACM (2010)
Wu, W., Li, H., Wang, H., Zhu, K.Q.: Probase: a probabilistic taxonomy for text understanding. In: Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data, pp 481–492, ACM (2012)
Wu, F., Weld, D.S.: Open information extraction using wikipedia. In: Proceedings of the 48th annual meeting of the association for computational linguistics, pp. 118–127. Association for Computational Linguistics (2010)
Yang, B., Mitchell, T.: Leveraging knowledge bases in lstms for improving machine reading. arXiv:1902.09091 (2019)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Liu, Y., Hua, W. & Zhou, X. Temporal knowledge extraction from large-scale text corpus. World Wide Web 24, 135–156 (2021). https://doi.org/10.1007/s11280-020-00836-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11280-020-00836-5