Hybridizing Deep Learning and Neuroevolution: Application to the Spanish Short-Term Electric Energy Consumption Forecasting

 , , , and
, , , and
Abstract
:1. Introduction
- We propose a new general-purpose approach based on deep learning for big data time-series forecasting. Due to the high computational cost of the deep learning, we adopted a distributed computing solution in order to be able to process large time series.
- The hyper-parameter tuning and optimization of the deep neural networks is a key factor for obtaining competitive results. Usually, the hyper-parameters of a deep neural network are pre-fixed previously or computed by a grid search, which performs an exhaustive search through the whole set of established hyper-parameters. However, the grid search presents an important limitation: it works with discrete values, which greatly limits the fine-tuning of the vast majority of hyper-parameters. Thus, an evolutionary search is proposed to find the hyper-parameters.
- We conduct a wide experimentation using Spanish electricity consumption registered over 10 years, with measurements recorded every 10 min. Results show a mean relative error of 1.44%, demonstrating the high potential of the proposed approach, also compared to other forecasting strategies.
- We evaluate our proposal predictive accuracy and compare it with a strategy based on deep learning using a grid search for setting the hyper parameters. The evolutionary search showed to be effective in order to achieve higher accuracy.
- In addition, we compare the approach with seven state-of-the-art forecasting algorithms such as ARIMA, decision tree, an algorithm based on gradient boosting, random forest, evolutionary decision trees, a standard neural network and an ensemble proposed in [14], outperforming all of them.
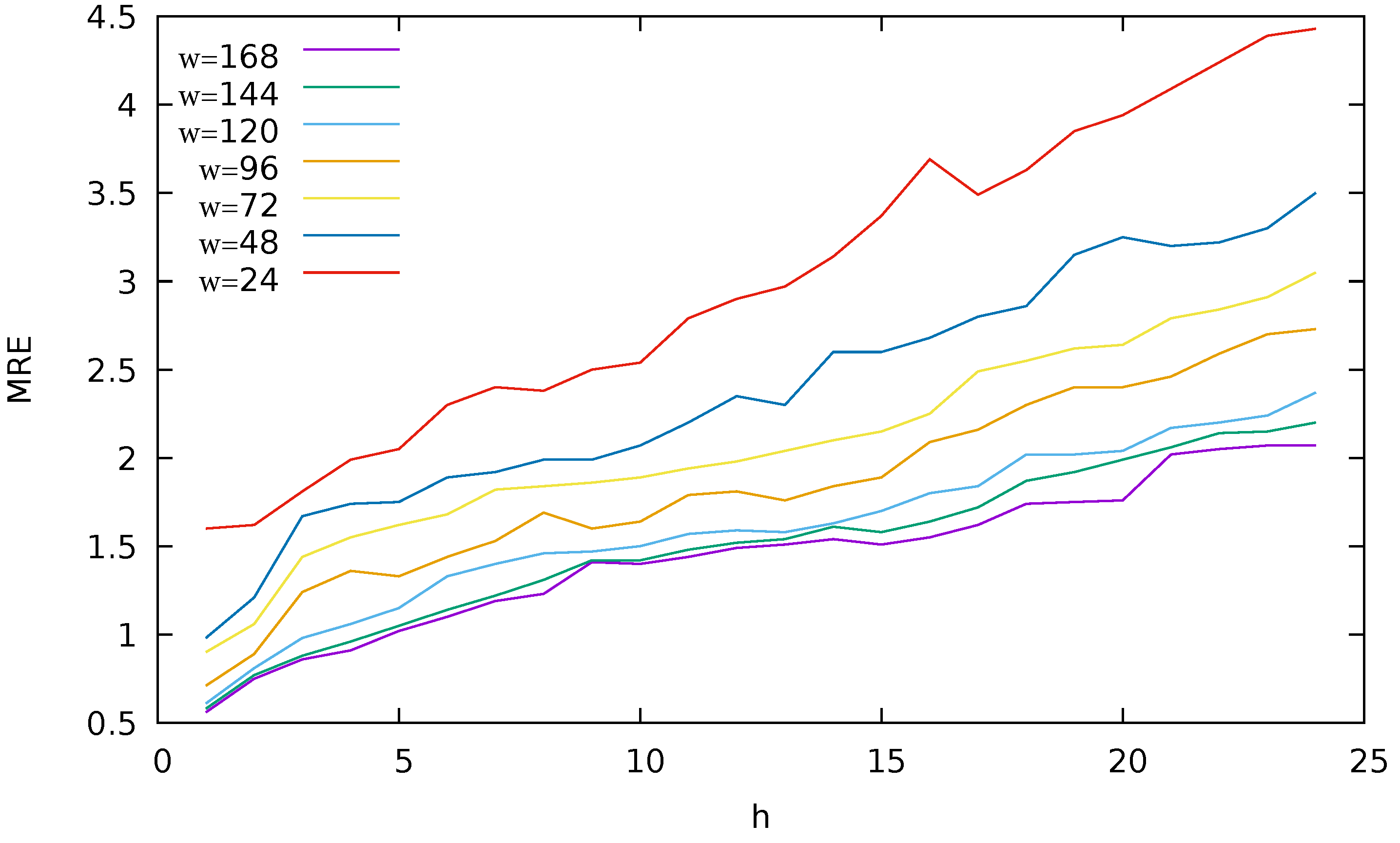
- We analyze how the size of the historical window affects the accuracy of the model. We found that when using the past 168 values as input features to predict the next 24 values the best results were obtained.
2. Related Works
3. Data and Methodology
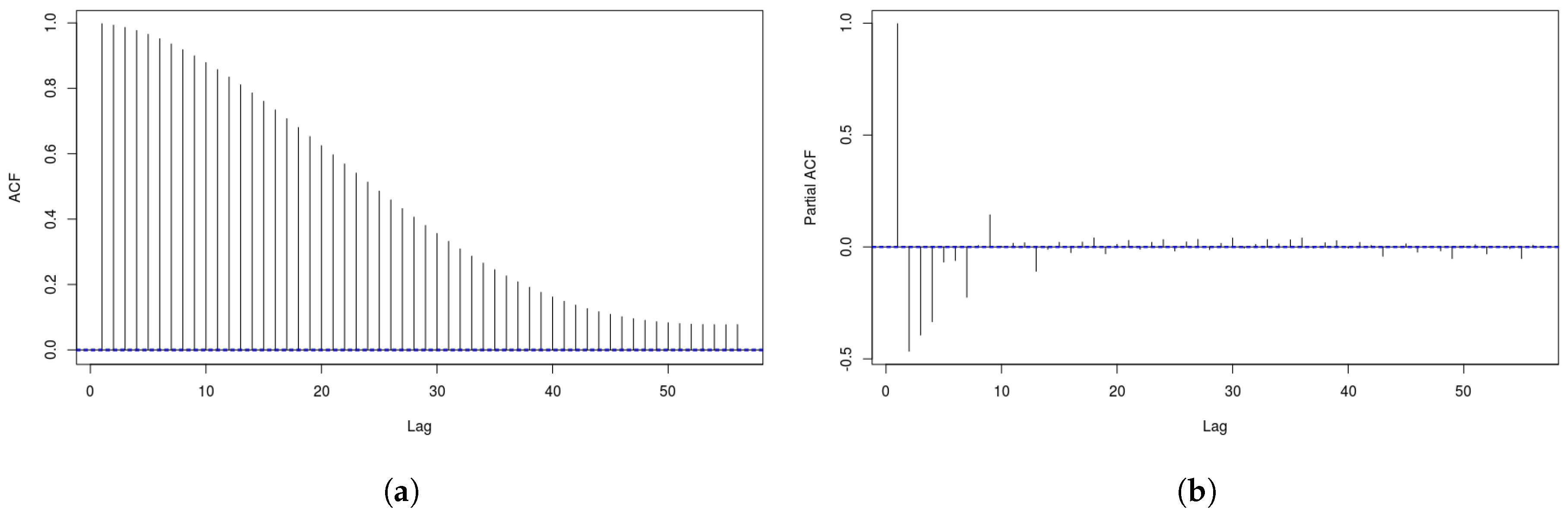
3.1. Data
3.2. Methodology
3.2.1. Parameters of the Neural Network
3.2.2. Genetic Algorithm Parameters
3.2.3. Description of the Methodology
4. Experimental Results
5. Conclusions and Future Works
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- U.S. Energy Information Administration. International Energy Outlook. Available online: https://www.eia.gov/outlooks/ieo/index.php (accessed on 5 August 2020).
- Narayanaswamy, B.; Jayram, T.S.; Yoong, V.N. Hedging strategies for renewable resource integration and uncertainty management in the smart grid. In Proceedings of the 3rd IEEE PES Innovative Smart Grid Technologies Europe, ISGT, Berlin, Germany, 14–17 October 2012; pp. 1–8. [Google Scholar]
- Haque, R.; Jamal, T.; Maruf, M.N.I.; Ferdous, S.; Priya, S.F.H. Smart management of PHEV and renewable energy sources for grid peak demand energy supply. In Proceedings of the 2015 International Conference on Electrical Engineering and Information Communication Technology (ICEEICT), Dhaka, Bangladesh, 21–23 May 2015; pp. 1–6. [Google Scholar]
- Kim, Y.; Son, H.; Kim, S. Short term electricity load forecasting for institutional buildings. Energy Rep. 2019, 5, 1270–1280. [Google Scholar] [CrossRef]
- Nazeriye, M.; Haeri, A.; Martínez-Álvarez, F. Analysis of the Impact of Residential Property and Equipment on Building Energy Efficiency and Consumption-A Data Mining Approach. Appl. Sci. 2020, 10, 3589. [Google Scholar] [CrossRef]
- Zekic-Suzac, M.; Mitrovic, S.; Has, A. Machine learning based system for managing energy efficiency of public sector as an approach towards smart cities. Int. J. Inf. Manag. 2020, 54, 102074. [Google Scholar] [CrossRef]
- Energy 2020—A Strategy for Competitive, Sustainable and Secure Energy. Available online: http://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:52010DC0639&from=EN (accessed on 5 August 2020).
- Raza, M.Q.; Khosravi, A. A review on artificial intelligence based load demand forecasting techniques for smart grid and buildings. Renew. Sustain. Energy Rev. 2015, 50, 1352–1372. [Google Scholar] [CrossRef]
- Torres, J.F.; de Castro, A.G.; Troncoso, A.; Martínez-Álvarez, F. A scalable approach based on deep learning for big data time series forecasting. Integr. Comput.-Aided Eng. 2018, 25, 1–14. [Google Scholar] [CrossRef]
- Miikkulainen, R.; Liang, J.Z.; Meyerson, E.; Rawal, A.; Fink, D.; Francon, O.; Raju, B.; Shahrzad, H.; Navruzyan, A.; Duffy, N.; et al. Evolving Deep Neural Networks. CoRR 2017. abs/1703.00548. Available online: https://arxiv.org/abs/1703.00548 (accessed on 5 August 2020).
- Stanley, K.O.; Clune, J.; Lehman, J.; Miikkulainen, R. Designing neural networks through neuroevolution. Nat. Mach. Intell. 2019, 1, 24–35. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G.E. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Such, F.P.; Madhavan, V.; Conti, E.; Lehman, J.; Stanley, K.O.; Clune, J. Deep Neuroevolution: Genetic Algorithms Are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning. CoRR 2017. abs/1712.06567. Available online: https://arxiv.org/abs/1712.06567 (accessed on 5 August 2020).
- Divina, F.; Gilson, A.; Goméz-Vela, F.; Torres, M.G.; Torres, J.F. Stacking Ensemble Learning for Short-Term Electricity Consumption Forecasting. Energies 2018, 11, 949. [Google Scholar] [CrossRef] [Green Version]
- Nowicka-Zagrajek, J.; Weron, R. Modeling electricity loads in California: ARMA models with hyperbolic noise. Signal Process. 2002, 82, 1903–1915. [Google Scholar] [CrossRef] [Green Version]
- Huang, S.J.; Shih, K.R. Short-term load forecasting via ARMA model identification including non-Gaussian process considerations. IEEE Trans. Power Syst. 2003, 18, 673–679. [Google Scholar] [CrossRef] [Green Version]
- Martínez-Álvarez, F.; Troncoso, A.; Asencio-Cortés, G.; Riquelme, J.C. A survey on data mining techniques applied to energy time series forecasting. Energies 2015, 8, 1–32. [Google Scholar] [CrossRef] [Green Version]
- Muralitharan, K.; Sakthivel, R.; Vishnuvarthan, R. Neural network based optimization approach for energy demand prediction in smart grid. Neurocomputing 2018, 273, 199–208. [Google Scholar] [CrossRef]
- Mordjaoui, M.; Haddad, S.; Medoued, A.; Laouafi, A. Electric load forecasting by using dynamic neural network. Int. J. Hydrogen Energy 2017, 42, 17655–17663. [Google Scholar] [CrossRef]
- Wei, S.; Mohan, L. Application of improved artificial neural networks in short-term power load forecasting. J. Renew. Sustain. Energy 2015, 7, id043106. [Google Scholar] [CrossRef]
- Gajowniczek, K.; Ząbkowski, T. Short Term Electricity Forecasting Using Individual Smart Meter Data. Procedia Comput. Sci. 2014, 35, 589–597. [Google Scholar] [CrossRef] [Green Version]
- Min, Z.; Qingle, P. Very Short-Term Load Forecasting Based on Neural Network and Rough Set. In Proceedings of the Intelligent Computation Technology and Automation, International Conference on(ICICTA), Changsha, China, 11–12 May 2010; Volume 3, pp. 1132–1135. [Google Scholar]
- Troncoso, A.; Riquelme, J.C.; Riquelme, J.M.; Martínez, J.L.; Gómez, A. Electricity Market Price Forecasting Based on Weighted Nearest Neighbours Techniques. IEEE Trans. Power Syst. 2007, 22, 1294–1301. [Google Scholar]
- Martínez-Álvarez, F.; Troncoso, A.; Riquelme, J.C.; Aguilar-Ruiz, J.S. Energy time series forecasting based on pattern sequence similarity. IEEE Trans. Knowl. Data Eng. 2011, 23, 1230–1243. [Google Scholar] [CrossRef]
- Shen, W.; Babushkin, V.; Aung, Z.; Woon, W.L. An ensemble model for day-ahead electricity demand time series forecasting. In Proceedings of the International Conference on Future Energy Systems, Berkeley, CA, USA, 22–24 May 2013; pp. 51–62. [Google Scholar]
- Koprinska, I.; Rana, M.; Troncoso, A.; Martínez-Álvarez, F. Combining pattern sequence similarity with neural networks for forecasting electricity demand time series. In Proceedings of the IEEE International Joint Conference on Neural Networks, Dallas, TX, USA, 4–9 August 2013; pp. 940–947. [Google Scholar]
- Jin, C.H.; Pok, G.; Park, H.W.; Ryu, K.H. Improved pattern sequence-based forecasting method for electricity load. IEEJ Trans. Electr. Electron. Eng. 2014, 9, 670–674. [Google Scholar] [CrossRef]
- Wang, Z.; Koprinska, I.; Rana, M. Pattern sequence-based energy demand forecast using photovoltaic energy records. In Proceedings of the International Conference on Artificial Neural Networks, Nagasaki, Japan, 11–14 November 2017; pp. 486–494. [Google Scholar]
- Bokde, N.; Asencio-Cortés, G.; Martínez-Álvarez, F.; Kulat, K. PSF: Introduction to R Package for Pattern Sequence Based Forecasting Algorithm. R J. 2017, 1, 324–333. [Google Scholar] [CrossRef] [Green Version]
- Pérez-Chacón, R.; Asencio-Cortés, G.; Martínez-Álvarez, F.; Troncoso, A. Big data time series forecasting based on pattern sequence similarity and its application to the electricity demand. Inf. Sci. 2020, 540, 160–174. [Google Scholar] [CrossRef]
- Zeng, B.; Li, C. Forecasting the natural gas demand in China using a self-adapting intelligent grey model. Energy 2016, 112, 810–825. [Google Scholar] [CrossRef]
- Fan, G.F.; Wang, A.; Hong, W.C. Combining Grey Model and Self-Adapting Intelligent Grey Model with Genetic Algorithm and Annual Share Changes in Natural Gas Demand Forecasting. Energies 2018, 11, 1625. [Google Scholar] [CrossRef] [Green Version]
- Ma, X.; Liu, Z. Application of a novel time-delayed polynomial grey model to predict the natural gas consumption in China. J. Comput. Appl. Math. 2017, 324, 17–24. [Google Scholar] [CrossRef]
- Wu, Y.H.; Shen, H. Grey-related least squares support vector machine optimization model and its application in predicting natural gas consumption demand. J. Comput. Appl. Math. 2018, 338, 212–220. [Google Scholar] [CrossRef]
- Martínez-Álvarez, F.; Asencio-Cortés, G.; Torres, J.F.; Gutiérrez-Avilés, D.; Melgar-García, L.; Pérez-Chacón, R.; Rubio-Escudero, C.; Troncoso, A.; Riquelme, J.C. Coronavirus Optimization Algorithm: A Bioinspired Metaheuristic Based on the COVID-19 Propagation Model. Big Data 2020, 8, 232–246. [Google Scholar] [CrossRef]
- Torres, J.F.; Fernández, A.M.; Troncoso, A.; Martínez-Álvarez, F. Deep Learning-Based Approach for Time Series Forecasting with Application to Electricity Load. In Biomedical Applications Based on Natural and Artificial Computing; Springer International Publishing: Berlin, Germany, 2017; pp. 203–212. [Google Scholar]
- Berriel, R.F.; Lopes, A.T.; Rodrigues, A.; Varejão, F.M.; Oliveira-Santos, T. Monthly energy consumption forecast: A deep learning approach. In Proceedings of the 2017 International Joint Conference on Neural Networks, IJCNN 2017, Anchorage, AK, USA, 14–19 May 2017; pp. 4283–4290. [Google Scholar]
- Shi, H.; Xu, M.; Li, R. Deep Learning for Household Load Forecasting: A Novel Pooling Deep RNN. IEEE Trans. Smart Grid 2018, 9, 5271–5280. [Google Scholar] [CrossRef]
- Guo, Z.; Zhou, K.; Zhang, X.; Yang, S. A deep learning model for short-term power load and probability density forecasting. Energy 2018, 160, 1186–1200. [Google Scholar] [CrossRef]
- Talavera-Llames, R.L.; Pérez-Chacón, R.; Lora, A.T.; Martínez-Álvarez, F. Big data time series forecasting based on nearest neighbours distributed computing with Spark. Knowl.-Based Syst. 2018, 161, 12–25. [Google Scholar] [CrossRef]
- Floreano, D.; Dürr, P.; Mattiussi, C. Neuroevolution: From architectures to learning. Evol. Intell. 2008, 1, 47–62. [Google Scholar] [CrossRef]
- Kandasamy, K.; Neiswanger, W.; Schneider, J.; Póczos, B.; Xing, E. Neural Architecture Search with Bayesian Optimisation and Optimal Transport. CoRR 2018. abs/1802.07191. Available online: https://arxiv.org/abs/1802.07191 (accessed on 5 August 2020).
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical Bayesian Optimization of Machine Learning Algorithms. In NIPS’12, Proceedings of the 25th International Conference on Neural Information Processing Systems—Volume 2; Curran Associates Inc.: New York, NY, USA, 2012; pp. 2951–2959. [Google Scholar]
- Assunção, F.; Lourenço, N.; Ribeiro, B.; Machado, P. Incremental Evolution and Development of Deep Artificial Neural Networks. In Genetic Programming; Hu, T., Lourenço, N., Medvet, E., Divina, F., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 35–51. [Google Scholar]
- Assunção, F.; Lourenço, N.; Machado, P.; Ribeiro, B. Fast DENSER: Efficient Deep NeuroEvolution. In Genetic Programming; Sekanina, L., Hu, T., Lourenço, N., Richter, H., García-Sánchez, P., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 197–212. [Google Scholar]
- Real, E.; Aggarwal, A.; Huang, Y.; Le, Q.V. Regularized Evolution for Image Classifier Architecture Search. CoRR 2018. abs/1802.01548. Available online: https://arxiv.org/abs/1802.01548 (accessed on 5 August 2020). [CrossRef] [Green Version]
- Real, E.; Moore, S.; Selle, A.; Saxena, S.; Suematsu, Y.L.; Tan, J.; Le, Q.V.; Kurakin, A. Large-Scale Evolution of Image Classifiers. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Precup, D., Teh, Y.W., Eds.; PMLR: International Convention Centre: Sydney, Australia, 2017; Volume 70, pp. 2902–2911. [Google Scholar]
- Spanish Electricity Price Market Operator. Available online: http://www.omie.es/files/flash/ResultadosMercado.html (accessed on 5 August 2020).
- Team, T.H. H2O: R Interface for H2O. In R Package Version 3.1.0.99999; H2O.ai, Inc.: New York, NY, USA, 2015. [Google Scholar]
- Scrucca, L. On some extensions to GA package: Hybrid optimisation, parallelisation and islands evolution. R J. 2017, 9, 187–206. [Google Scholar] [CrossRef] [Green Version]
- Herrera, F.; Lozano, M.; Sánchez, A.M. A taxonomy for the crossover operator for real-coded genetic algorithms: An experimental study. Int. J. Intell. Syst. 2003, 18, 309–338. [Google Scholar] [CrossRef] [Green Version]
- Salles, R.; Assis, L.; Guedes, G.; Bezerra, E.; Porto, F.; Ogasawara, E. A Framework for Benchmarking Machine Learning Methods Using Linear Models for Univariate Time Series Prediction. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017. [Google Scholar]
- Rokach, L.; Maimon, O. Top-down Induction of Decision Trees Classifiers-a Survey. Trans. Sys. Man Cyber Part C 2005, 35, 476–487. [Google Scholar] [CrossRef] [Green Version]
- Therneau, T.M.; Atkinson, B.; Ripley, B. rpart: Recursive Partitioning. Available online: https://rdrr.io/cran/rpart/ (accessed on 5 August 2020).
- Ridgeway, G. Generalized Boosted Models: A Guide to the Gbm Package. Available online: https://rdrr.io/cran/gbm/man/gbm.html (accessed on 5 August 2020).
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S, 4th ed.; Springer: New York, NY, USA, 2002. [Google Scholar]
- Grubinger, T.; Zeileis, A.; Pfeiffer, K. evtree: Evolutionary Learning of Globally Optimal Classification and Regression Trees in R. J. Stat. Softw. 2014, 61, 1–29. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
| w | #Rows | #Columns | File Size (In MB) |
|---|---|---|---|
| 24 | 20,742 | 48 | 6 |
| 48 | 20,741 | 72 | 9 |
| 72 | 20,740 | 96 | 11.9 |
| 96 | 20,739 | 120 | 14.9 |
| 120 | 20,738 | 144 | 17.9 |
| 144 | 20,737 | 168 | 20.9 |
| 168 | 20,736 | 192 | 23.9 |
| Parameter | Values |
|---|---|
| Layers | From 2 to 100 |
| Neurons | From 10 to 1000 |
| Lambda () | From 0 to 1 × 10 |
| Rho () | From 0.99 to 1 |
| Epsilon () | From 0 to 1 × 10 |
| Activation function | From 0 to 3 |
| Distribution function | From 0 to 7 |
| End metric | From 0 to 7 |
| Operator | Value |
|---|---|
| Population size | 50 |
| Generations | 100 |
| Limit of generations | 50 |
| Crossover probability | 0.8 |
| Mutation probability | 0.1 |
| Elitisms probability | 0.05 |
| h | Layers | Neurons | Activation | Distribution | End Metric | |||
|---|---|---|---|---|---|---|---|---|
| 1 | 52 | 942 | 4.09× 10 | 1.00 | 6.43 × 10 | Tanh | Gaussian | Deviance |
| 2 | 68 | 921 | 0 | 1.00 | 0 | Maxout | Huber | MSE |
| 3 | 75 | 880 | 0 | 1.00 | 0 | Maxout | Huber | Deviance |
| 4 | 68 | 921 | 0 | 1.00 | 0 | Maxout | Huber | MSE |
| 5 | 88 | 504 | 0 | 1.00 | 0 | Maxout | Huber | Deviance |
| 6 | 80 | 789 | 0 | 1.00 | 0 | Maxout | Huber | MSE |
| 7 | 74 | 892 | 0 | 1.00 | 0 | Maxout | Huber | RMSLE |
| 8 | 46 | 300 | 0 | 1.00 | 0 | Maxout | Huber | MAE |
| 9 | 75 | 889 | 5.57 × 10 | 0.99 | 6.74 × 10 | Tanh | Gaussian | Mean per class error |
| 10 | 25 | 852 | 0 | 1.00 | 0 | Maxout | Huber | RMSLE |
| 11 | 58 | 843 | 3.69 × 10 | 1.00 | 2.45 × 10 | Tanh | Gaussian | RMSE |
| 12 | 41 | 491 | 0 | 1.00 | 0 | Maxout | Huber | RMSLE |
| 13 | 17 | 552 | 0 | 0.99 | 0 | Maxout | Huber | MSE |
| 14 | 26 | 661 | 0 | 0.99 | 0 | Maxout | Huber | MAE |
| 15 | 89 | 811 | 5.61 × 10 | 0.99 | 4.23 × 10 | Tanh | Gaussian | RMSE |
| 16 | 98 | 697 | 0 | 1.00 | 0 | Maxout | Huber | MAE |
| 17 | 74 | 478 | 1.46 × 10 | 1.00 | 3.58 × 10 | Tanh | Gaussian | Deviance |
| 18 | 62 | 705 | 2.74 × 10 | 0.99 | 6.64 × 10 | Tanh | Gaussian | MAE |
| 19 | 65 | 879 | 0 | 0.99 | 0 | Maxout | Huber | MAE |
| 20 | 81 | 780 | 7.62 × 10 | 0.99 | 5.21 × 10 | Tanh | Gaussian | MSE |
| 21 | 27 | 931 | 0 | 1.00 | 0 | Maxout | Huber | MAE |
| 22 | 95 | 745 | 0 | 1.00 | 0 | Maxout | Huber | Deviance |
| 23 | 41 | 923 | 0 | 1.00 | 0 | Maxout | Huber | MSE |
| 24 | 80 | 754 | 0 | 1.00 | 0 | Maxout | Huber | MAE |
| w | |||||||
|---|---|---|---|---|---|---|---|
| 24 | 48 | 72 | 96 | 120 | 144 | 168 | |
| NDL | 3.01 (0.90) | 2.38 (0.69) | 2.08 (0.57) | 1.85 (0.55) | 1.60 (0.46) | 1.51 (0.46) | 1.44 (0.42) |
| CNN | 4.08 (0.04) | 3.16 (0.03) | 2.69 (0.02) | 2.51 (0.02) | 2.30 (0.02) | 1.71 (0.02) | 1.79 (0.02) |
| LSTM | 2.43 (0.03) | 2.05 (0.02) | 1.82 (0.02) | 2.08 (0.02) | 1.74 (0.02) | 1.78 (0.02) | 1.97 (0.02) |
| FFNN | 4.51 (0.52) | 3.46 (0.33) | 3.39 (0.30) | 3.12 (0.42) | 2.98 (0.28) | 2.32 (0.29) | 2.46 (0.29) |
| ARIMA | 8.82 (5.31) | 8.26 (4.73) | 11.37 (10.43) | 14.03 (13.00) | 6.79 (2.53) | 7.63 (2.54) | 6.92 (2.97) |
| DT | 9.52 (1.55) | 9.45 (1.48) | 9.33 (1.39) | 9.40 (1.45) | 9.08 (1.12) | 8.86 (1.01) | 8.79 (0.96) |
| GBM | 8.07 (3.82) | 6.59 (2.71) | 5.73 (2.23) | 5.33 (2.08) | 5.02 (1.81) | 4.49 (1.54) | 4.45 (1.56) |
| RF | 4.39 (2.13) | 3.69 (1.71) | 2.93 (1.16) | 2.78 (1.04) | 2.45 (0.79) | 2.22 (0.71) | 2.15 (0.69) |
| EV | 4.49 (1.91) | 3.98 (1.52) | 3.48 (1.18) | 3.42 (1.15) | 3.19 (0.95) | 3.15 (0.90) | 3.09 (0.84) |
| NN | 4.39 (2.23) | 4.27 (2.16) | 4.13 (2.05) | 3.55 (1.56) | 3.15 (1.41) | 2.16 (0.78) | 2.08 (0.74) |
| ENSEMBLE | 3.58 (1.65) | 2.95 (1.19) | 2.64 (0.99) | 2.57 (0.97) | 2.38 (0.81) | 1.94 (0.69) | 1.88 (0.67) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Divina, F.; Torres Maldonado, J.F.; García-Torres, M.; Martínez-Álvarez, F.; Troncoso, A. Hybridizing Deep Learning and Neuroevolution: Application to the Spanish Short-Term Electric Energy Consumption Forecasting. Appl. Sci. 2020, 10, 5487. https://doi.org/10.3390/app10165487
Divina F, Torres Maldonado JF, García-Torres M, Martínez-Álvarez F, Troncoso A. Hybridizing Deep Learning and Neuroevolution: Application to the Spanish Short-Term Electric Energy Consumption Forecasting. Applied Sciences. 2020; 10(16):5487. https://doi.org/10.3390/app10165487
Chicago/Turabian StyleDivina, Federico, José Francisco Torres Maldonado, Miguel García-Torres, Francisco Martínez-Álvarez, and Alicia Troncoso. 2020. "Hybridizing Deep Learning and Neuroevolution: Application to the Spanish Short-Term Electric Energy Consumption Forecasting" Applied Sciences 10, no. 16: 5487. https://doi.org/10.3390/app10165487