A Comparative Study of PLSR and SVM-R with Various Preprocessing Techniques for the Quantitative Determination of Soluble Solids Content of Hardy Kiwi Fruit by a Portable Vis/NIR Spectrometer




Abstract
:1. Introduction
2. Materials and Methods
2.1. Sample Preparation
2.2. Spectra Acquisition
2.3. Reference Measurement
2.4. Chemometrics
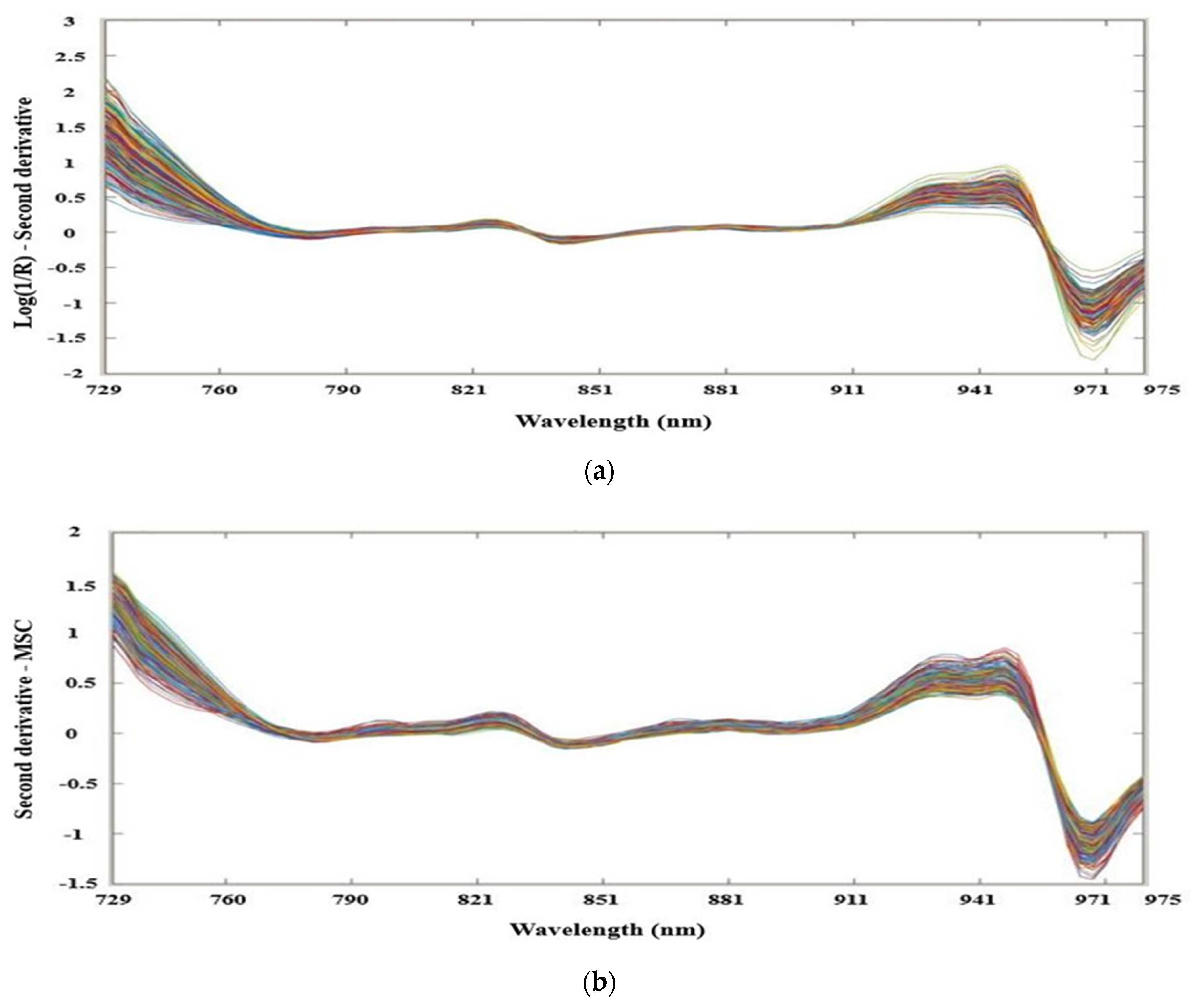
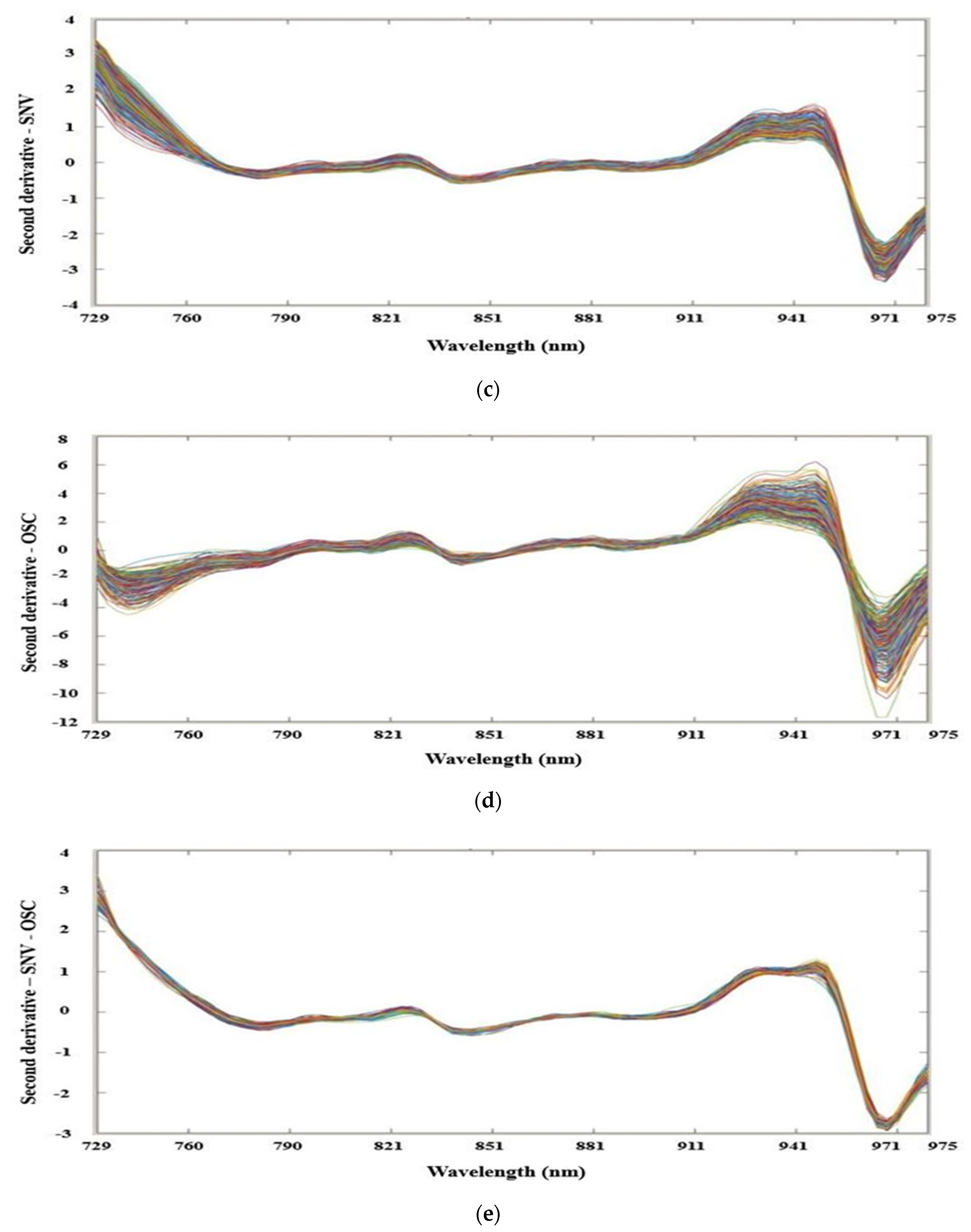
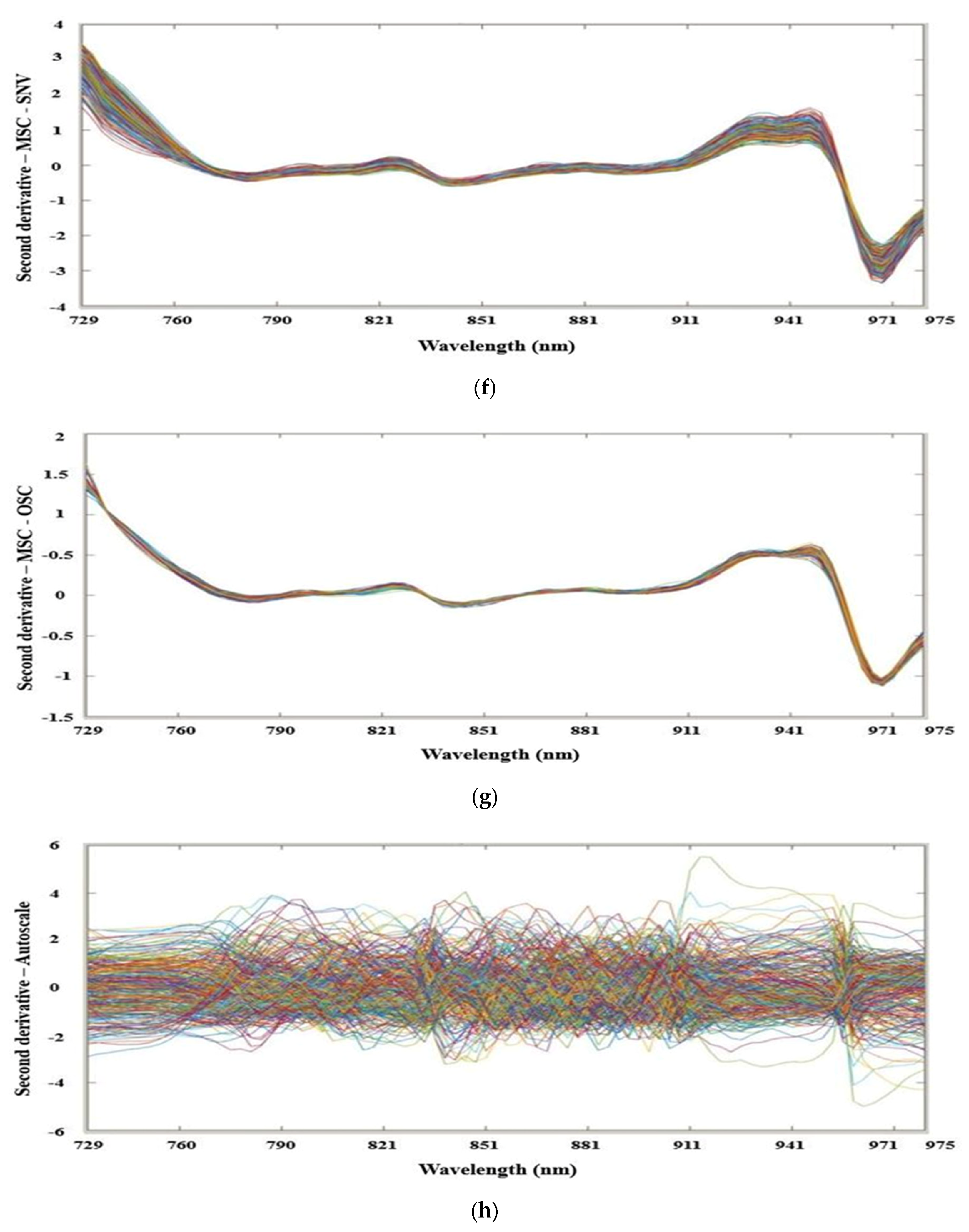
2.5. Spectral Data Preprocessing
2.6. Principle Component Analysis (PCA) and Partial Least Squares (PLS) Analysis
2.7. Support Vector Machine (SVM) Analysis
3. Results
3.1. Characteristics of Spectral Profiles
3.2. Statistical Properties
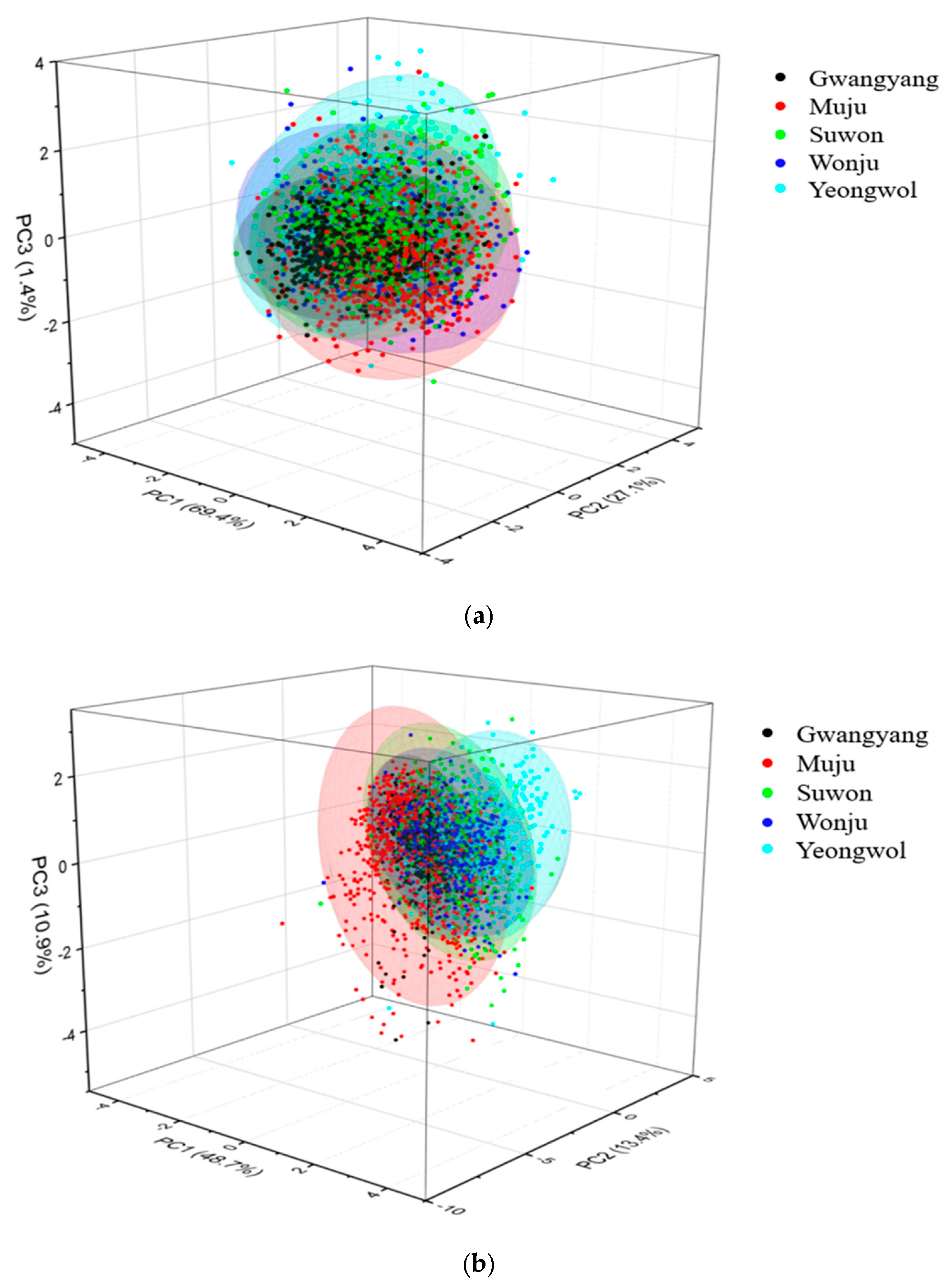
3.3. Principal Component Analysis (PCA)
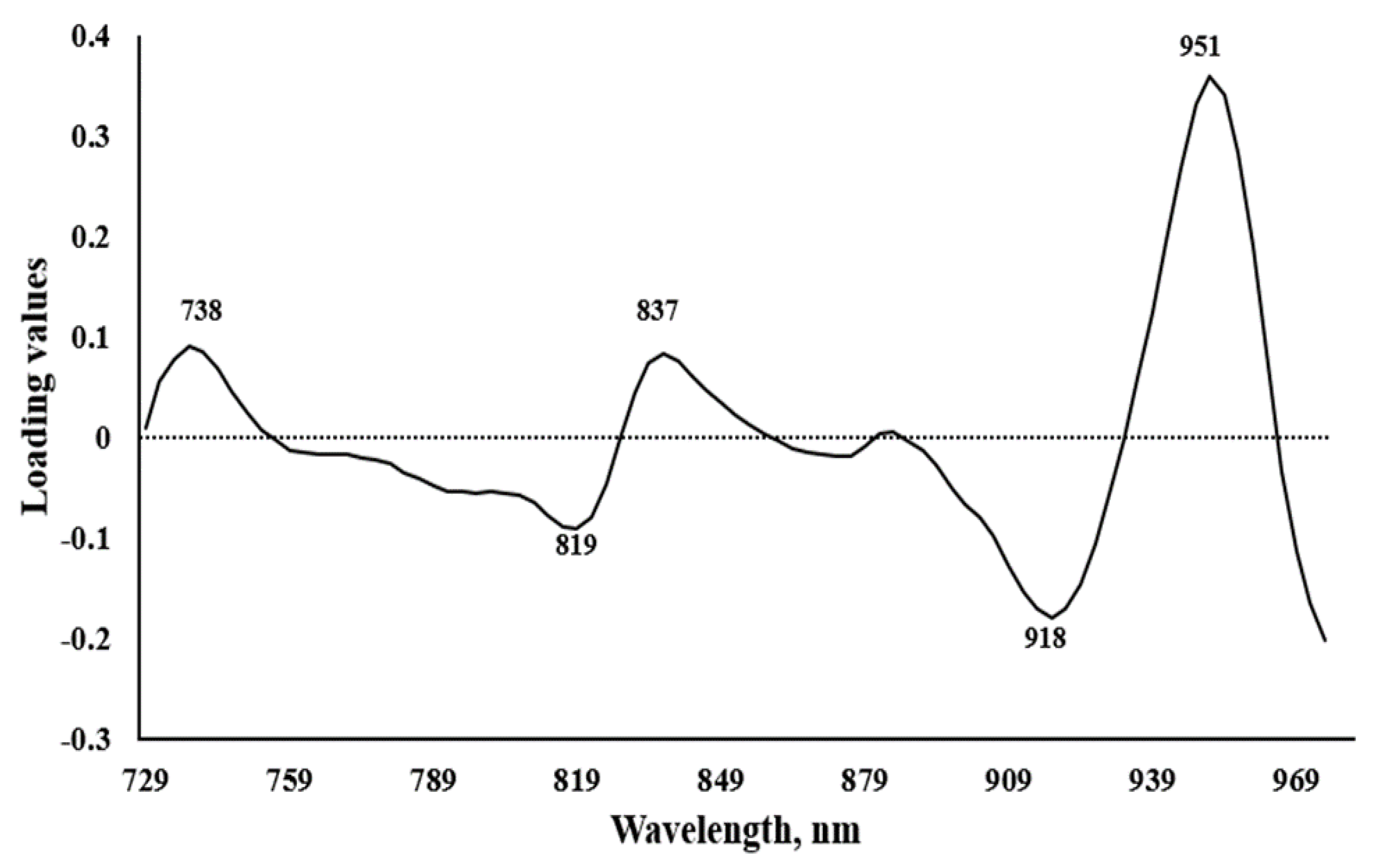
3.4. PCA Loadings
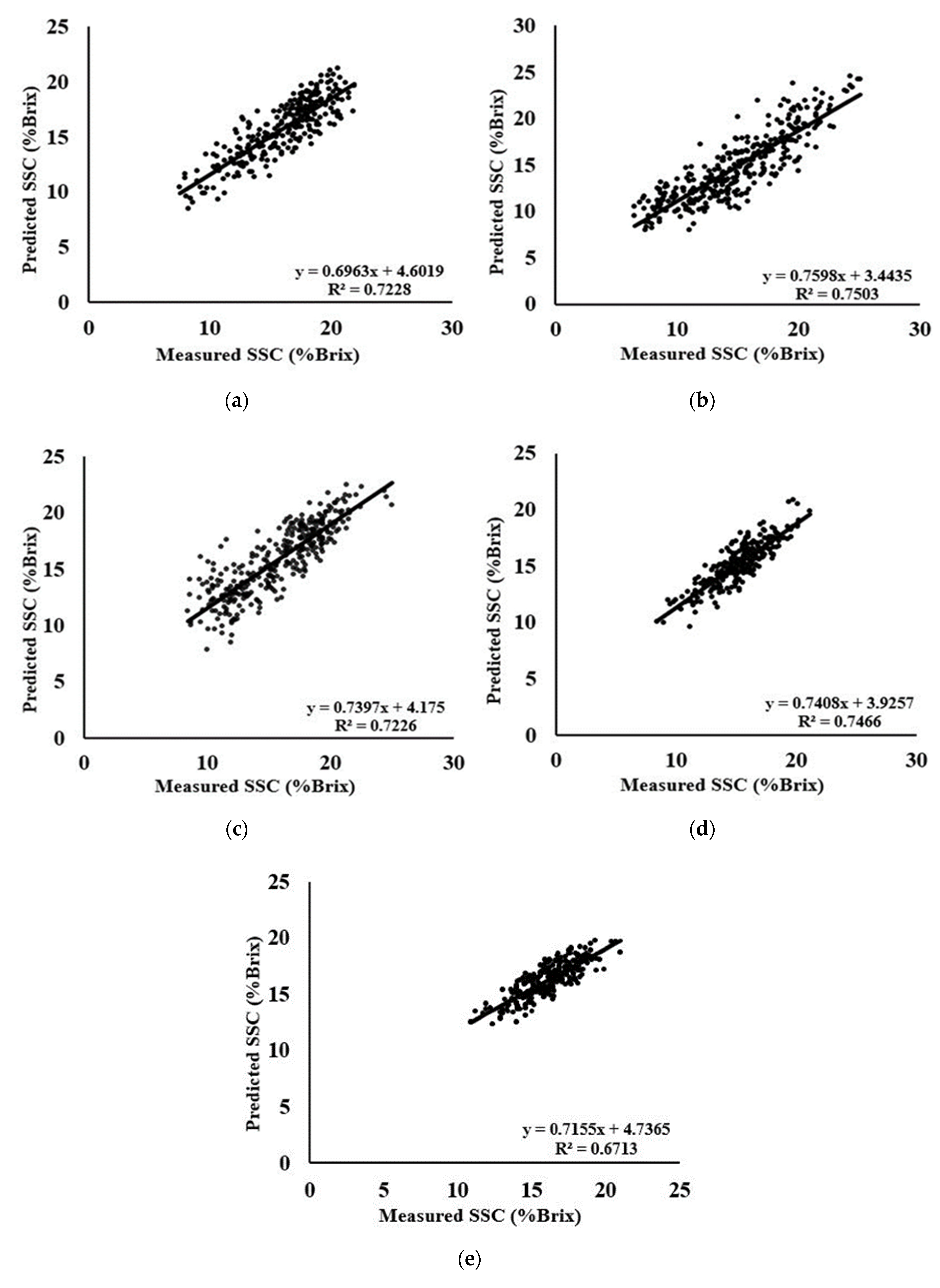
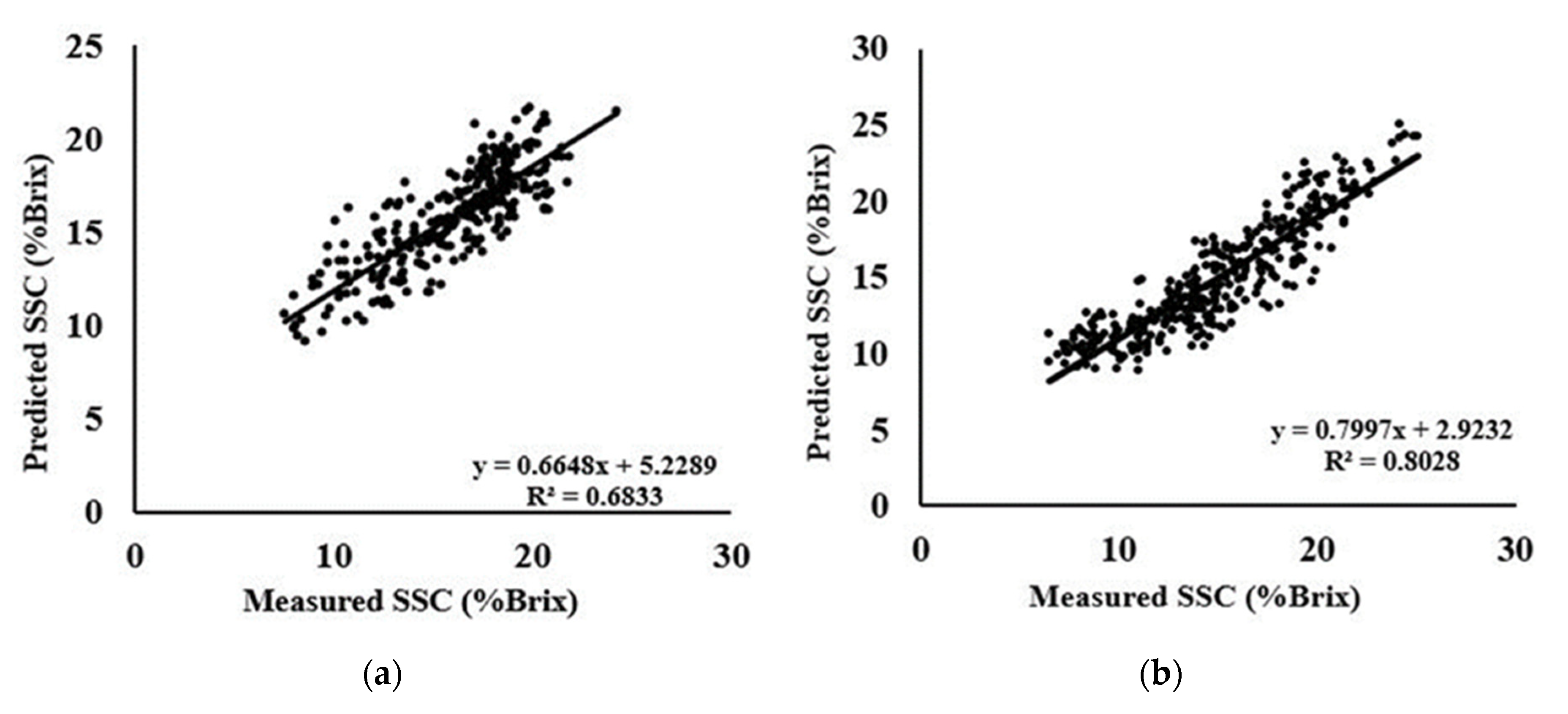
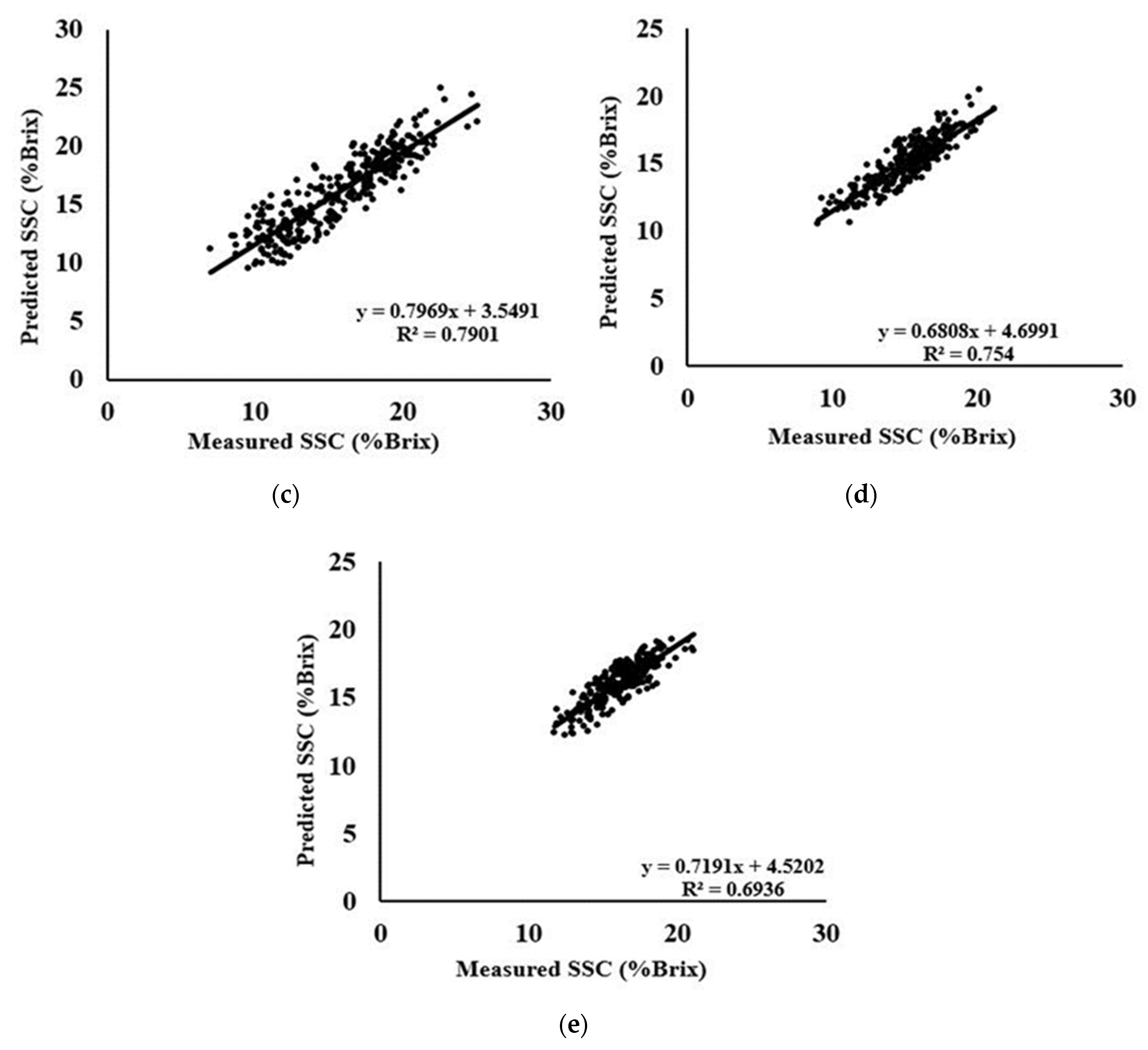
3.5. PLS Models for the Prediction of SSC-Area Dataset
3.6. PLS Models for the Prediction of SSC-Species and Combine Dataset
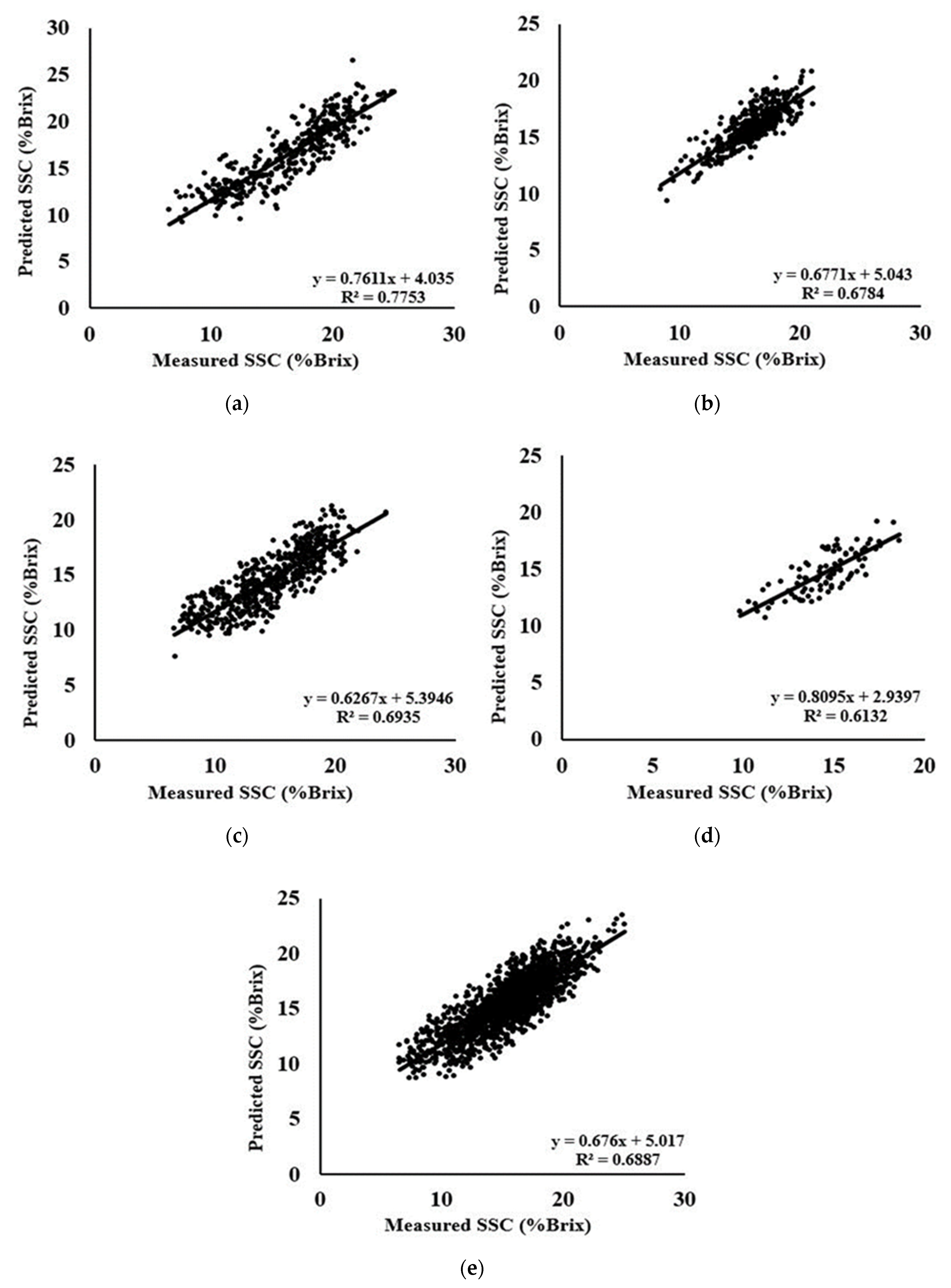
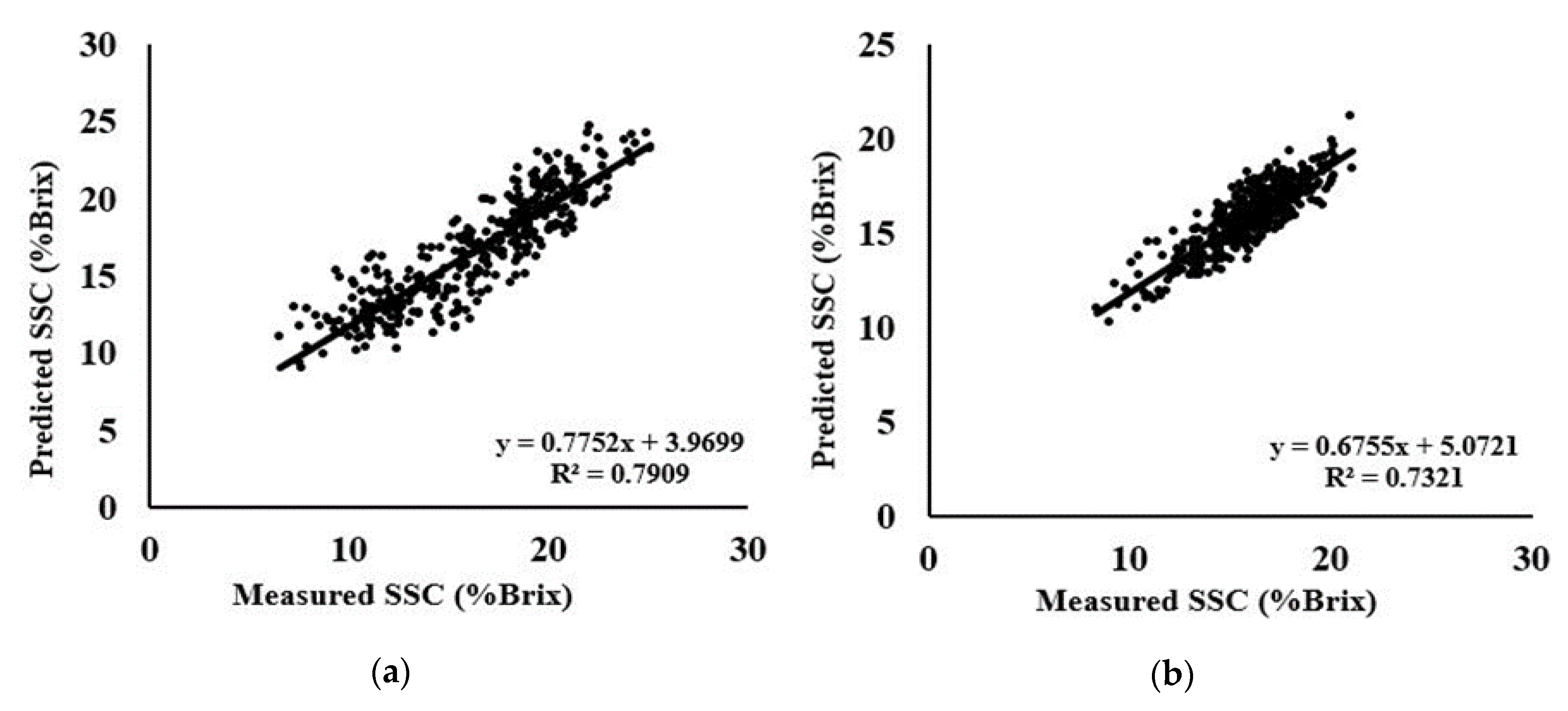
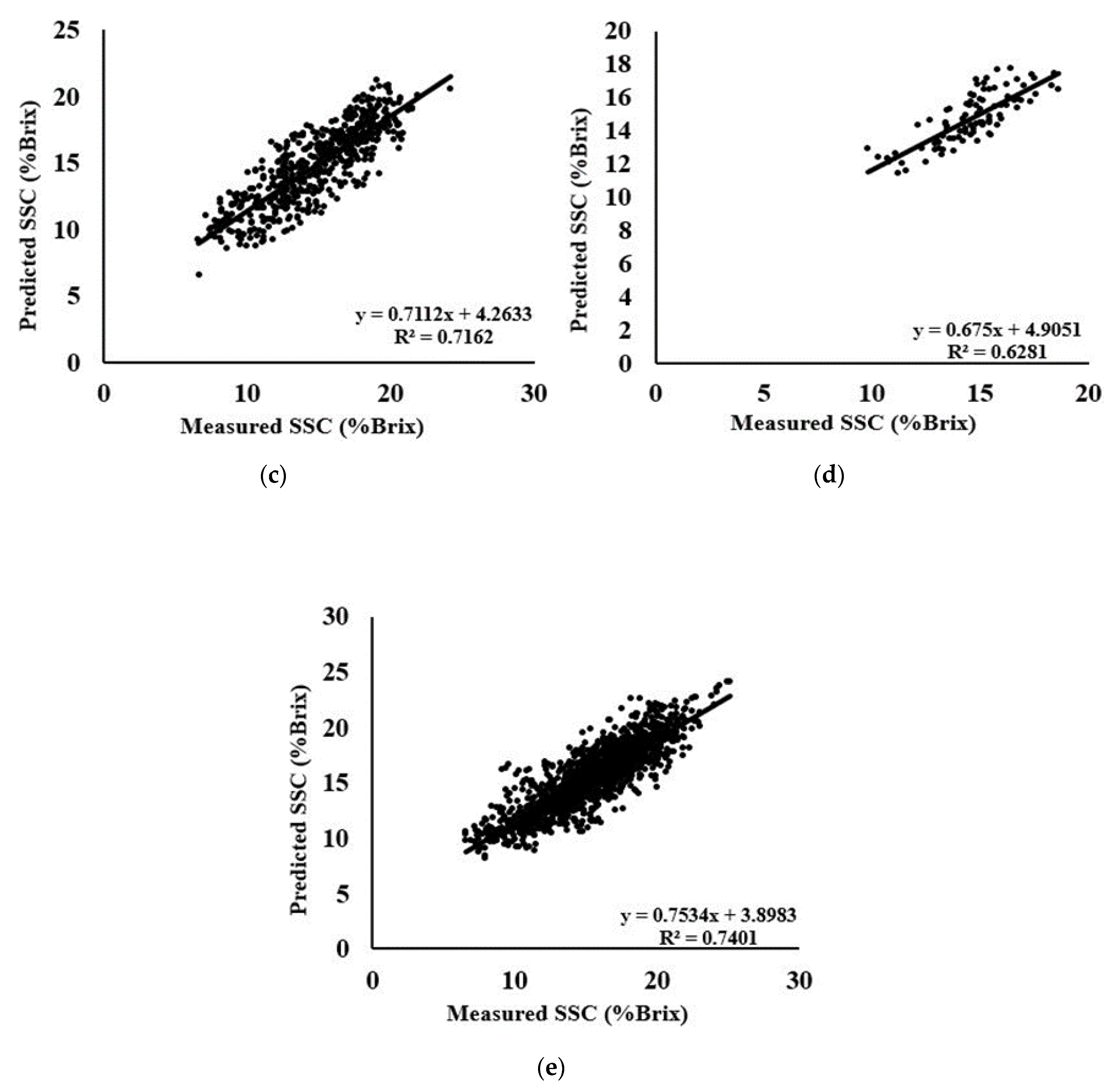
3.7. SVM-R Models for the Prediction of SSC-Area Dataset
3.8. SVM Models for the Prediction of SSC- Species and Combine Dataset
4. Discussion
Comparison of PLSR and SVM-R Analysis
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Li, J.; Huang, W.; Zhao, C.; Zhang, B. A comparative study for the quantitative determination of soluble solids content, pH and firmness of pears by Vis/NIR spectroscopy. J. Food Eng. 2012, 116, 324–332. [Google Scholar] [CrossRef]
- Chen, P.; Sun, Z. A review of non-destructive methods for quality evaluation and sorting of agricultural products. J. Agric. Eng. Res. 1991, 49, 85–98. [Google Scholar] [CrossRef]
- Angra, S.K.; Dimri, A.K.; Kapur, P. Nondestructive brix evaluation of apples of different origin using near infrared (nir) filter-based reflectance spectroscopy. Instrum. Sci. Technol. 2009, 37, 241–253. [Google Scholar] [CrossRef]
- Mehinagic, E.; Royer, G.; Bertrand, D.; Symoneaux, R.; Laurens, F.; Jourjon, F. Relationship between sensory analysis, penetrometry and visible-NIR spectroscopy of apples belonging to different cultivars. Food Qual. Prefer. 2003, 14, 473–484. [Google Scholar] [CrossRef]
- Camps, C.; Guillermin, P.; Mauget, J.C.; Bertrand, D. Measurement of textural properties of apple and their prediction by near infrared reflectance spectroscopy. In Proceedings of the 7th Fruit, Nut and Vegetable Production Engineering Symposium: Information and Technology for Sustainable Fruit and Vegetable Production, Montpellier, France, 12–16 September 2005. FRUTIC 05. [Google Scholar]
- McGlone, V.A.; Jordan, R.B.; Seelye, R.; Martinsen, P.J. Comparing density and NIR methods for measurement of kiwifruit dry matter and soluble solids content. Postharvest Biol. Technol. 2002, 26, 191–198. [Google Scholar] [CrossRef]
- Moons, E.; Sinnaeve, G. Non-destructive Visible and NIR spectroscopy measurement for the determination of apple internal quality. Acta Hortic. 2000, 517, 441–448. [Google Scholar] [CrossRef]
- Ventura, M.; De Jager, A.; De Putter, H.; Roelofs, P.M.M. Non-destructive determination of soluble solids in apple fruit by near infrared spectroscopy (NIRS). Postharvest Biol. Technol. 1998, 14, 21–27. [Google Scholar] [CrossRef]
- Zude, M.; Herold, B.; Roger, J.M.; Bellon-Maurel, V.; Landahl, S. Nondestructive tests on the prediction of apple fruit flesh firmness and soluble solids content on tree and in shelf life. J. Food Eng. 2006, 77, 254–260. [Google Scholar] [CrossRef]
- Peirs, A.; Lammertyn, J.; Ooms, K.; Nicolaı¨, B.M. Prediction of the optimal picking date of different apple cultivars by means of VIS/NIR-spectroscopy. Postharvest Biol. Technol. 2000, 21, 189–199. [Google Scholar] [CrossRef]
- Camps, C.; Guillermin, P.; Mauget, J.C.; Bertrand, D. Discrimination of storage duration of apples stored in a cooled room and shelf-life by visible-near infrared spectroscopy. J. Near Infrared Spec. 2007, 15, 169–177. [Google Scholar] [CrossRef]
- Schmilovitch, Z.; Mizrach, A.; Hoffman, A.; Egozi, H.; Fuchs, Y. Determination of mango physiological indices by near-infrared spectrometry. Postharvest Biol. Technol. 2000, 19, 245–252. [Google Scholar] [CrossRef]
- Lee, J.S.; Kim, S.C.; Seong, K.C.; Kim, C.H.; Um, Y.C.; Lee, S.K. Quality prediction of kiwifruit based on near infrared spectroscopy. Kor. J. Hort. Sci. Technol. 2012, 30, 709–717. [Google Scholar] [CrossRef]
- Lee, S.; Sarkar, S.; Park, Y.; Yang, J.; Kweon, G. Feasibility study for an optical sensing system for Hardy Kiwi (Actindia arguta) sugar content estimation. J. Agric. Life Sci. 2019, 53, 147–157. [Google Scholar] [CrossRef]
- McGlone, V.A.; Kawano, S. Firmness, dry-matter and soluble-solids assessment of postharvest kiwifruit by NIR spectroscopy. Postharvest Biol. Technol. 1998, 13, 131–141. [Google Scholar] [CrossRef]
- Gautier, H.; Verdin, D.V.; Bénard, C.; Reich, M.; Buret, M.; Bourgaud, F.; Génard, M. How does tomato quality (sugar, acid, and nutritional quality) vary with ripening stage, temperature, and irradiance? J. Agric. Food Chem. 2008, 56, 1241–1250. [Google Scholar] [CrossRef]
- Harel-Beja, R.; Tzuri, G.; Portnoy, V.; Lotan-Pompan, M.; Lev, S.; Cohen, S.; Avisar, E. A genetic map of melon highly enriched with fruit quality QTLs and EST markers, including sugar and carotenoid metabolism genes. Theor. Appl. Genet. 2010, 121, 511–533. [Google Scholar] [CrossRef]
- Chen, X.; Han, W. Spectroscopic determination of soluble solids content of ‘Qinmei’ kiwifruit using partial least squares. Afr. J. Biotechnol. 2012, 11, 2528–2536. [Google Scholar]
- Ying, Y.; Liu, Y.; Fu, X.; Lu, H. Application of principal component regression and artificial neural network in FT-NIR soluble solids content determination of intact pear fruit. In Proceedings of the Optical Sensors and Sensing Systems for Natural Resources and Food Safety and Quality, Boston, MA, USA, 8 November 2005; Chen, Y.-R., Meye, G.E., Tu, S.-I., Eds.; SPIE Digital Library: Bellingham, WA, USA. [Google Scholar] [CrossRef]
- Moghimi, A.; Aghkhani, M.H.; Sazgarnia, A.; Sarmad, M. Vis/NIR spectroscopy and chemometrics for the prediction of soluble solids content and acidity (pH) of kiwifruit. Biosyst. Eng. 2010, 106, 295–302. [Google Scholar] [CrossRef]
- McGlone, V.A.; Clark, C.J.; Jordan, R.B. Comparing density and VNIR methods for predicting quality parameters of yellow-fleshed kiwifruit (Actinidia chinensis). Postharvest Biol. Technol. 2007, 46, 1–9. [Google Scholar] [CrossRef]
- Fu, X.; Ying, Y.; Xu, H.; Yu, H. Support vector machines and near infrared spectroscopy for quantification of vitamin C content in kiwifruit. In Proceedings of the an ASABE Meeting Presentation, Providence, RI, USA, 29 June–2 July 2008; p. 085204. [Google Scholar] [CrossRef]
- Chen, Q.; Zhao, J.; Fang, C.H.; Wang, D. Feasibility study on identification of green, black, and oolong teas using near-infrared reflectance spectroscopy based on support vector machine (SVM). Spectrochim. Acta A 2007, 66, 568–574. [Google Scholar] [CrossRef]
- Du, D.; Wang, J.; Wang, B.; Zhu, L.; Hong, X. Ripeness prediction of postharvest kiwifruit using a MOS E-Nose combined with chemometrics. Sensors 2019, 19, 419. [Google Scholar] [CrossRef] [Green Version]
- Cogdill, R.P.; Dardenne, P. Least square support vector machines for chemometrics: An introduction and evaluation. J. Near Infrared Spec. 2004, 12, 93–100. [Google Scholar] [CrossRef]
- Blanco, M.; Villarroya, I. NIR spectroscopy: A rapid response analytical tool. Trac Trend Anal. Chem. 2002, 21, 240–250. [Google Scholar] [CrossRef]
- Fan, G.; Zha, J.; Du, R.; Gao, L. Determination of soluble solids and firmness of apples by Vis/NIR transmittance. J. Food Eng. 2009, 93, 416–420. [Google Scholar] [CrossRef]
- Muik, B.; Lendl, B.; Molina-Díaz, A.; Perez-Villarejo, L.; Ayora-Canada, M.J. Determination of oil and water content in olive pomace using near infrared and Raman spectrometry. A comparative study. Anal. Bioanal. Chem. 2004, 379, 35–41. [Google Scholar] [CrossRef]
- Huang, H.B.; Yu, H.; Xu, H.; Ying, Y. Near infrared spectroscopy for on/in-line monitoring of quality in foods and beverages: A review. J. Food Eng. 2008, 87, 303–313. [Google Scholar] [CrossRef]
- Andersson, M. A comparison of nine PLS1 algorithms. J. Chemom. 2009, 23, 518–529. [Google Scholar] [CrossRef]
- Wold, S.; Sjöström, M.; Eriksson, L. PLS-regression: A basic tool of chemometrics. Chemometr. Intell. Lab. Syst. 2001, 58, 109–130. [Google Scholar] [CrossRef]
- Gholizadeh, A.; Boruvka, L.; Saberioon, M.M.; Vasat, R. Visible, near infrared, and mid-infrared spectroscopy applications for soil assessment with emphasis on soil organic matter content and quality: State-of-the-art and key issues. Appl. Spectrosc. 2013, 67, 1349–1362. [Google Scholar] [CrossRef]
- Kim, J.G.; Park, Y.; Shin, M.H.; Muneer, S.; Lerud, R.; Michelson, C.; Il Kang, D.; Min, J.H.; Chamidha Kumarihami, H.M.P. Application of NIR-Spectroscopy to predict the harvesting maturity, fruit ripening and storage ability of Ca-chitosan treated baby kiwifruit. J. Stored Prod. Postharvest Res. 2018, 9, 44–53. [Google Scholar] [CrossRef]
- Peirs, A.; Tirry, J.; Verlinden, B.; Darius, P.; Nicolai, B.M. Effect of biological variability on the robustness of NIR models for soluble solids content. Postharvest Biol. Technol. 2003, 28, 269–280. [Google Scholar] [CrossRef]
- Li, X.; Huang, J.; Xiong, Y.; Zhou, J.; Tan, X.; Zhang, B. Determination of soluble solid content in multi-origin ‘Fuji’ apples by using FT-NIR spectroscopy and an origin discriminant strategy. Comput. Electron. Agric. 2018, 155, 23–31. [Google Scholar] [CrossRef]
- Zhang, B.B.; Cai, Z.X.; Xu, J.L.; Li, F.; Qian, W.; Guo, L. Prediction of soluble solid content of Hujingmilu peach based on regression analysis. Food Sci. 2014, 35, 68–71. [Google Scholar]
- Tiwari, G.; Slaughter, D.C.; Cantwell, M. Nondestructive maturity determination in green tomatoes using a handheld visible and near instrument. Postharvest Biol. Technol. 2013, 86, 221–229. [Google Scholar] [CrossRef]
- Nicolaï, B.M.; Beullens, K.; Bobelyn, E.; Peirs, A.; Saeys, W.; Theron, K.I.; Lammertyn, J. Nondestructive measurement of fruit and vegetable quality by means of NIR spectroscopy: A review. Postharvest Biol. Technol. 2007, 46, 99–118. [Google Scholar] [CrossRef]
- Cen, H.; He, Y. Theory and application of near infrared reflectance spectroscopy in determination of food quality. Trends Food Sci. Technol. 2007, 18, 72–83. [Google Scholar] [CrossRef]
- Gerretzen, J.; Szymańska, E.; Jansen, J.J.; Bart, J.; Jan van Manen, H.R.; van den Heuvel, E.; Buydens, L.M.C. Simple and effective way for data preprocessing selection based on design of experiments. Anal. Chem. 2015, 87, 12096–12103. [Google Scholar] [CrossRef] [Green Version]
- Chang, C.W.; Laird, D.A.; Mausbach, M.J.; Hurburgh, C.R., Jr. Near-infrared reflectance spectroscopy-principal components regression analysis of soil properties. Soil Sci. Soc. Am. J. 2001, 65, 480–490. [Google Scholar] [CrossRef] [Green Version]
- Kweon, G. Toward the ultimate soil survey: Sensing multiple soil and landscape properties in one pass. Agron. J. 2012, 104, 1547–1557. [Google Scholar] [CrossRef]
- Thissen, U.; Pepers, M.; Ustun, B.; Melssen, W.J.; Buydens, L.M.C. Comparing support vector machines to PLS for spectral regression applications. Chemometr. Intell. Lab. Syst. 2004, 73, 169–179. [Google Scholar] [CrossRef]
- Berrueta, L.A.; Alonso-Salces, R.M.; Héberger, K. Supervised pattern recognition in food analysis. J. Chromatogr. 2007, 1158, 196–214. [Google Scholar] [CrossRef] [PubMed]
- Lin, H.T.; Lin, C.J. A Study on Sigmoid Kernels for SVM and the Training of non-PSD Kernels by SMO-Type Methods. Neural Comput. 2003, 1–32. Available online: https://www.csie.ntu.edu.tw/~cjlin/papers/tanh.pdf (accessed on 16 July 2020).
- Keerthi, S.S.; Lin, C.J. Asymptotic behaviors of support vector machines with Gaussian kernel. Neural Comput. 2003, 15, 1667–1689. [Google Scholar] [CrossRef] [PubMed]
- Malegori, C.; Marques, E.J.N.; de Freitas, S.T.; Pimentel, M.F.; Pasquini, C.; Casiraghi, E. Comparing the analytical performance of Micro-NIR and FT-NIR spectrometers in the evaluation of acerola fruit quality, using PLS and SVM regression algorithms. Talanta 2017, 165, 112–116. [Google Scholar] [CrossRef]
- Escribano, S.; Biasi, W.V.; Lerud, R.; Slaughter, D.C.; Mitcham, E.J. Non-destructive prediction of soluble solids and dry matter content using NIR spectroscopy and its relationship with sensory quality in sweet cherries. Postharvest Biol. Technol. 2017, 128, 112–120. [Google Scholar] [CrossRef]
- Goke, A.; Serra, S.; Musacchi, S. Postharvest dry matter and soluble solids content prediction in d’Anjou and Bartlett pear using near-infrared spectroscopy. HortScience 2018, 53, 669–680. [Google Scholar] [CrossRef]
- Miller, C.E. Chemical principles of near-infrared technology. In Near-Infrared Technology: In the Agricultural and Food Industries, 2nd ed.; Williams, P.C., Norris, K.H., Eds.; American Association of Cereal Chemists: Saint Paul, MN, USA, 1987; pp. 193–199. [Google Scholar]
- Kumar, S.; McGlone, A.; Whitworth, C.; Volz, R. Postharvest performance of apple phenotypes predicted by near-infrared (NIR) spectral analysis. Postharvest Biol. Technol. 2015, 100, 16–22. [Google Scholar] [CrossRef]
- Williams, P.C.; Norris, K.H. Near-Infrared Technology: In the Agricultural and Food Industries, 1st ed.; American Association of Cereal Chemists, Inc.: St. Paul, MN, USA, 1987. [Google Scholar]
- Toledo-Martín, E.M.; García-García, M.C.; Font, R.; Moreno-Rojas, J.M.; Gómez, P.; Salinas-Navarro, M.; Del Río-Celestino, M. Application of visible/near-infrared reflectance spectroscopy for predicting internal and external quality in pepper. J. Sci. Food Agric. 2016, 96. [Google Scholar] [CrossRef]
- Feng, J.; McGlone, A.V.; Currie, M.; Clark, C.J.; Jordan, B.R. Assessment of yellow-fleshed kiwifruit (Actinidia chinensis ‘Hort16A’) quality in pre- and post- harvest conditions using a portable near-infrared Spectrometer. Hort. Sci. 2011, 46, 57–63. [Google Scholar] [CrossRef] [Green Version]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Area | Farms | Latitude, Longitude |
|---|---|---|
| Gwangyang | G | 35° 1.972′ N, 127° 35.505′ E |
| Muju | M1 | 36° 0.230′ N, 127° 40.295′ E |
| M2 | 35° 55.788′ N, 127° 42.389′ E | |
| M3 | 36° 0.374′ N, 127° 44.935′ E | |
| Suwon | S1 | 37° 15.038′ N, 126° 57.483′ E |
| S2 | 37° 15.876′ N, 126° 55.477′ E | |
| Wonju | W1 | 37° 27.046′ N, 127° 53.167′ E |
| W2 | 37° 22.42′ N, 128° 0.502′ E | |
| W3 | 35° 55.784′ N, 127° 42.699′ E | |
| Yeongwol | Y1 | 37° 12.23′ N, 128° 36.622′ E |
| Name | Data Set | Data Set Composition |
|---|---|---|
| Area | Gwangyang (G) | G |
| Muju (M) | M1, M2, M3 | |
| Suwon (S) | S1, S2 | |
| Wonju (W) | W1, W2, W3 | |
| Yeongwol (Y) | Y | |
| Species | Autumn sense (A) | M1, S1, S2 |
| Chungsan (C) | W2, W3, Y | |
| Daesung (D) | G, M2, M3 | |
| Green ball (Gb) | W3 | |
| Combined data | G, M1, M2, M3, S1, S2 W1, W2, W3, Y |
| Characteristic | Area | Sample Set | Mean | SD | Median | Max. | Min. | No. of Samples |
|---|---|---|---|---|---|---|---|---|
| SSC | Gwangyang (G) | Calibration | 16.17 | 3.33 | 16.8 | 23.7 | 7.7 | 300 |
| Validation | 16.04 | 3.26 | 16.85 | 24.2 | 7.5 | 300 | ||
| Muju (M) | Calibration | 14.57 | 4.10 | 14.3 | 27.2 | 6.6 | 353 | |
| Validation | 14.82 | 4.18 | 14.75 | 25.1 | 5.0 | 352 | ||
| Suwon (S) | Calibration | 15.67 | 3.83 | 16.1 | 23.0 | 6.5 | 343 | |
| Validation | 15.81 | 3.60 | 16.4 | 25.0 | 7.0 | 343 | ||
| Wonju (W) | Calibration | 15.10 | 2.27 | 15.1 | 21.9 | 8.5 | 280 | |
| Validation | 15.3 | 2.32 | 15.5 | 21.1 | 8.4 | 279 | ||
| Yeongwol (Y) | Calibration | 16.08 | 1.83 | 16.2 | 20.3 | 10.1 | 289 | |
| Validation | 16.14 | 2.00 | 16.2 | 21.3 | 7.3 | 289 |
| Characteristic | Species | Sample Set | Mean | SD | Median | Max. | Min. | No. of Samples |
|---|---|---|---|---|---|---|---|---|
| SSC | Autumn sense (A) | Calibration | 16.50 | 3.84 | 17.0 | 27.2 | 7.0 | 405 |
| Validation | 16.39 | 4.02 | 17.0 | 25.1 | 6.5 | 404 | ||
| Chungsan (C) | Calibration | 15.86 | 2.21 | 16.1 | 21.9 | 7.3 | 467 | |
| Validation | 15.92 | 2.12 | 16.0 | 21.1 | 8.4 | 466 | ||
| Daesung (D) | Calibration | 14.93 | 3.63 | 15.2 | 23.7 | 5 | 591 | |
| Validation | 14.71 | 3.50 | 15.0 | 24.2 | 6.6 | 591 | ||
| Green ball (Gb) | Calibration | 14.67 | 1.83 | 14.95 | 19.0 | 10.0 | 102 | |
| Validation | 14.56 | 1.82 | 14.7 | 18.6 | 9.8 | 102 |
| Characteristic | All Together | Sample Set | Mean | SD | Median | Max. | Min. | No. of Samples |
|---|---|---|---|---|---|---|---|---|
| SSC | Combine | Calibration | 15.56 | 3.27 | 15.8 | 27.2 | 6.6 | 1564 |
| Validation | 15.54 | 3.33 | 15.8 | 25.1 | 5.0 | 1564 |
| Area | Pre-Processing | LV | Calibration | Prediction (Validation) | RPD | |||
|---|---|---|---|---|---|---|---|---|
| R2 | RMSEC | R2 | RMSEP | Bias | ||||
| G | Second derivative | 6 | 0.71 | 1.7832 | 0.72 | 1.7136 | −0.28473 | 1.9024 |
| M | MSC + SNV | 8 | 0.759 | 2.016 | 0.750 | 2.0846 | −0.12002 | 2.0051 |
| S | SNV | 9 | 0.718 | 2.0371 | 0.723 | 1.8521 | 0.068707 | 1.9437 |
| W | MSC + OSC | 4 | 0.835 | 0.92495 | 0.747 | 1.1514 | −0.041329 | 2.0149 |
| Y | MSC + SNV | 11 | 0.662 | 1.0695 | 0.671 | 1.0343 | 0.16688 | 1.9336 |
| Species | Pre-Processing | LV | Calibration | Prediction (Validation) | RPD | |||
|---|---|---|---|---|---|---|---|---|
| R2 | RMSEC | R2 | RMSEP | Bias | ||||
| A | Autoscale | 11 | 0.775 | 1.8256 | 0.775 | 1.8775 | 0.090077 | 2.1411 |
| C | MSC + SNV | 10 | 0.662 | 1.2857 | 0.678 | 1.1832 | −0.11288 | 1.7917 |
| D | Autoscale | 7 | 0.659 | 2.1201 | 0.694 | 1.9648 | −0.085569 | 1.7813 |
| Gb | Second derivative | 8 | 0.769 | 0.88278 | 0.613 | 1.2167 | 0.16661 | 1.4958 |
| All Together | Pre-Processing | LV | Calibration | Prediction (Validation) | RPD | |||
|---|---|---|---|---|---|---|---|---|
| R2 | RMSEC | R2 | RMSEP | Bias | ||||
| Combine | Second derivative | 11 | 0.652 | 1.9338 | 0.651 | 1.9512 | 0.018924 | 1.7066 |
| MSC | 10 | 0.656 | 1.9233 | 0.667 | 1.9049 | −0.027812 | 1.7481 | |
| SNV | 10 | 0.657 | 1.9201 | 0.665 | 1.9107 | −0.021354 | 1.7428 | |
| OSC | 4 | 0.654 | 1.9305 | 0.651 | 1.9364 | 0.02903 | 1.7196 | |
| SNV + OSC | 7 | 0.663 | 1.9033 | 0.674 | 1.8786 | −0.015084 | 1.7725 | |
| MSC + SNV | 7 | 0.632 | 1.9884 | 0.633 | 2.0067 | −0.020487 | 1.6594 | |
| MSC + OSC | 7 | 0.662 | 1.9056 | 0.689 | 1.8286 | −0.019629 | 1.8210 | |
| Autoscale | 10 | 0.652 | 1.934 | 0.669 | 1.887 | 0.025924 | 1.7647 | |
| Area | Pre-Processing | Calibration | Prediction (Validation) | RPD | |||
|---|---|---|---|---|---|---|---|
| R2 | RMSEC | R2 | RMSEP | Bias | |||
| G | Autoscale | 0.706 | 1.8103 | 0.683 | 1.8424 | −0.146 | 1.7694 |
| M | Autoscale | 0.823 | 1.7344 | 0.803 | 1.8421 | −0.064418 | 2.2691 |
| S | Autoscale | 0.802 | 1.7238 | 0.790 | 1.6644 | 0.32509 | 2.1629 |
| W | Autoscale | 0.792 | 1.0415 | 0.754 | 1.1596 | −0.18288 | 2.0006 |
| Y | Autoscale | 0.755 | 0.91677 | 0.694 | 0.9714 | −0.008294 | 2.3883 |
| Species | Pre-Processing | Calibration | Prediction (Validation) | RPD | |||
|---|---|---|---|---|---|---|---|
| R2 | RMSEC | R2 | RMSEP | Bias | |||
| A | Autoscale | 0.776 | 1.834 | 0.791 | 1.8359 | 0.26706 | 2.1896 |
| C | Autoscale | 0.706 | 1.2039 | 0.732 | 1.102 | −0.09689 | 1.9237 |
| D | Autoscale | 0.783 | 1.6942 | 0.716 | 1.8368 | −0.009629 | 1.9054 |
| Gb | MSC + SNV | 0.652 | 1.0846 | 0.628 | 1.1143 | 0.15616 | 1.6333 |
| All Together | Pre-Processing | Calibration | Prediction (Validation) | RPD | |||
|---|---|---|---|---|---|---|---|
| R2 | RMSEC | R2 | RMSEP | Bias | |||
| Combine | Second derivative | 0.101 | 3.183 | 0.095 | 3.2118 | 0.19047 | 1.0368 |
| MSC | 0.183 | 3.2424 | 0.188 | 3.268 | 0.25516 | 1.0189 | |
| SNV | 0.728 | 1.7104 | 0.657 | 1.9596 | 0.063723 | 1.6993 | |
| OSC | 0.533 | 3.157 | 0.490 | 3.2216 | 0.24963 | 1.0336 | |
| SNV + OSC | 0.809 | 1.4343 | 0.664 | 1.9452 | −0.0092358 | 1.7119 | |
| MSC + SNV | 0.728 | 1.7104 | 0.657 | 1.9595 | 0.063723 | 1.6994 | |
| MSC + OSC | 0.397 | 3.2445 | 0.371 | 3.3063 | 0.27998 | 1.0071 | |
| Autoscale | 0.766 | 1.5864 | 0.740 | 1.6867 | 0.063042 | 1.9742 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sarkar, S.; Basak, J.K.; Moon, B.E.; Kim, H.T. A Comparative Study of PLSR and SVM-R with Various Preprocessing Techniques for the Quantitative Determination of Soluble Solids Content of Hardy Kiwi Fruit by a Portable Vis/NIR Spectrometer. Foods 2020, 9, 1078. https://doi.org/10.3390/foods9081078
Sarkar S, Basak JK, Moon BE, Kim HT. A Comparative Study of PLSR and SVM-R with Various Preprocessing Techniques for the Quantitative Determination of Soluble Solids Content of Hardy Kiwi Fruit by a Portable Vis/NIR Spectrometer. Foods. 2020; 9(8):1078. https://doi.org/10.3390/foods9081078
Chicago/Turabian StyleSarkar, Shagor, Jayanta Kumar Basak, Byeong Eun Moon, and Hyeon Tae Kim. 2020. "A Comparative Study of PLSR and SVM-R with Various Preprocessing Techniques for the Quantitative Determination of Soluble Solids Content of Hardy Kiwi Fruit by a Portable Vis/NIR Spectrometer" Foods 9, no. 8: 1078. https://doi.org/10.3390/foods9081078