1. Introduction
Social cueing is an essential element in human communication, and human gaze plays a crucial role in non-verbal social cueing. Human gaze is a complex behavior integrating physical, psychological, and social functions, resulting in several combinations of primitive behaviors such as saccades, vestibulo-ocular reflexes, smooth pursuits, or vergences. The functionality of human gaze can include information gathering, signaling of intention/attention, expressing emotional states, or even providing information; and typically the gazing activities are fused into multi-modal communication with speech, facial expressions, or bodily gestures [
1,
2].
This complex nature of human gaze has fascinated the minds of roboticists in developing more advanced robotic systems with naturalistic and effective human–robot interaction modalities [
1,
3,
4,
5,
6]. It has been widely studied that gaze functions in human–robot interaction can play a similar role in human–human interaction [
7]. Previous research efforts on robotic gaze, to list a few, have studied the role of gaze as a strategy in social human–robot interaction [
8], applied in robotic gaze control of a humanoid system and evaluated the performance [
9], implemented more natural human-like gaze behavior and evaluated its impact in storytelling scenarios [
10], and applied to industrial assembly tasks in human–robot collaboration [
11]. Robot’s gaze can also affect robot’s interpersonal relationship, life-likeness, cognitive competence, social attentiveness, and information disambiguation [
11]. However, did we fully achieve the full bandwidth of gaze-based social cueing with robotic systems?
The limitations of robotic gaze have reported that the effectiveness of the robotic gaze is not as effective as human gaze [
12,
13]. The robotic gaze is also known to be not capable enough to achieve social communications (e.g., joint visual attention measured through reflexive attention) when tested with simplistic robotic platforms such as Zeno or Keepon [
12]. While more recent studies are presenting positive results by adopting advanced human-like eye gaze controllers [
14,
15], and utilizing eye-tracker technology to provide more adaptive and responsive joint attention [
16,
17,
18], there still lies in real human interaction scenarios in which the robotic gaze control is not capturing the full aspects of human–human interaction.
One of the most frequent cases in human–robot interaction where the robotic gaze is not performing at full capacity is the in-attentional blindness (IB) case, arising in many task-oriented social communications. The IB in human–robot communication arises when the human’s attention is not aligned with robotic gaze due to its focus on other objects or tasks [
19,
20], thus causing blindness toward the robotic gaze. Thus, in this work, we present a method for a social robot to adequately deliver gaze-based social signals competing for the participant’s attention with varied visual stimuli. This is particularly crucial in educational environments, where multimedia contents are utilized frequently alongside the tutor (robot) for enhanced learning.
With this objective in mind,
Section 2 discusses the prior work in robotic gaze control as well as the definitions of IB, and
Section 3 presents the hypotheses of this study in robotic gaze for social cueing in an IB scenario.
Section 4 discusses our experimental design and the methodologies we created to implement an effective gaze-based social cueing framework.
Section 5 presents the results of our experiments conducted with 93 participants, and
Section 6 discusses our findings and outlines future steps.
2. Social-Cueing in Human–Robot Interaction
2.1. The Role of Gaze in Human–Robot Interaction
Since the gaze plays an important role in sending attention signals [
21], gaze-based social cueing has been actively studied in the HRI domain. Yoshikawa et al. showed that the effect of eye-gazing in face-to-face human–robot interaction and found the importance of responsive gaze control [
22]. Palinko et al. executed a comparison study on eye-gaze and head-gaze, and although their results showed higher performance in eye-gaze, they did not imply either one alone can transfer enough information in social communication [
23]. Atienze and Zelinsky developed an active vision system for effective human intention recognition in collaborative tasks and showed the efficiency of combining natural gaze and gestures [
24]. Miyauchi et al. showed the effectiveness of active eye contact as a means of meta-communication [
25], and Boucher et al. also justified the importance of gaze in human–human and human–robot interaction [
26]. Some other studies systematized the gaze functions in human–robot interaction according to five social contexts: establishing liveliness, signaling social attention, regulating interaction processes, supporting interaction content, and projecting mental states [
7,
21].
2.2. In-attentional Blindness during Task-Related Interaction
While most of the prior work has focused on gaze control as a single action, recent studies imply that “in-attentional blindness” in visual-cueing and social communications has been often disregarded in robot-based studies. In-attentional blindness (IB), also known as perceptual blindness, is a phenomenon in which an individual is not aware of unexpected stimuli in plain sight when focusing on a task [
19,
20]. This phenomenon can result in failure in perceiving social cue or visual gaze from robotic systems during human–robot interaction and communication when a person’s attention is occupied by a certain task. Furthermore, the visual cue (e.g., gaze) is a visual attention factor, so the visual cue may not be effectively perceived when the user is not looking at the robot’s eyes due to the IB. As a result that people might not see the robot’s face, some studies do not even take into account the gaze by robots during interaction [
27,
28,
29].
This well-known psychological factor provides a consideration in experimental design: robotic systems need the capacity to avoid or overcome any interaction that may involve IB. A few potential solutions could include (1) passively waiting for the right time for a user not to focus on other tasks before delivering a visual cue, (2) proactively attracting the user’s attention by using modalities other than visual stimuli, then delivering the visual cue only after the person’s attention has been drawn to the robot, or (3) reinforcing the visual cue in terms of frequency, duration, and amplitude.
In this work, we would like to employ the second approach by first establishing joint attention through the use of non-visual cues and then delivering the intended visual cue. Our hypotheses, therefore, are composed as follows.
3. Hypotheses
To monitor the presence of in-attentional blindness (IB) in human–robot interactions and to provide a social communication strategy to overcome the challenges of IB, we set the following hypotheses for this study.
Hypothesis 1 (H1). A robot’s gaze-based social cue, designed to aid in improving the user’s performance in a task-oriented communication, may suffer from IB during a human–robot interaction.
To evaluate H1, we designed a robotic system (both a robotic body and its software simulator [
30]) to conduct human–robot collaborative quiz solving in which the robot guides conversational quiz experiment. We aimed to measure the impact of the robot’s gaze-based cue and evaluated H1 while monitoring the presence of IB. The details of the experimental design can be found in
Section 4.2.
Hypothesis 2 (H2). Our proposed approach based on a foundation of joint-attention will effectively improve the performance in a human–robot collaborative task.
To evaluate H2, we designed a two-stage gaze control framework which initially worked to re-attain the user’s attention through the use of non-visual cues, before proceeding with a more basic form of gaze-based social cueing. The details of the experimental design are also described in
Section 4.2.
4. Study Design
4.1. Robotic Platform and Gaze Control
We created a custom-designed robotic platform with dynamic eye-gaze and a multi-modal robotic communication simulator, which we named “My Own Cognitive Communication Agent” (hereafter referred to as “MOCCA”) [
30]. The MOCCA system is composed of robotic hardware working in conjunction with a computer-based simulated environment created in Unity
TM. The robotic body and its virtual twin are designed to provide synchronized responses in real time to user inputs. Our experiments use the virtual MOCCA, in conjunction with an eye-tracker that tracks the human participants’ gaze targets to obtain quantifiable data required for evaluating the efficacy of robotic gaze in real-time human–robot gaze interactions. More broadly, we have used the MOCCA system to study the interactive and responsive characteristics of robotic gaze control and mutual gaze in human–robot interaction scenarios [
31,
32].
4.2. Experimental Design
To analyze the effectiveness of different gaze-based social cueing methods in IB situations, we designed a social and collaborative communication scenario, which features a robotic tutor and a human learner. In this scenario, the MOCCA software provides multiple-choice questions to participants in 1-on-1 quiz sessions. While the participant considers possible answers to the questions, the MOCCA character uses gazed-based expression to give a cue revealing the answer at each question. We hypothesized that the total scores from the quiz would increase when participants successfully recognize these cues, as they would consequently choose the answer with the help of the robotic gaze-based cueing.
As such, we utilized quiz scores as a metric for evaluating the efficacy of social cues. To ensure that the evaluation was objective, quiz questions primarily asked participants to name the capitals of various countries (The quiz questions are shown in
Appendix A). This scenario differs significantly from the guessing game question [
33,
34], in which participants’ baseline performances can be assumed to be the same owing to the random nature of the problem. Instead, the performance of participants in response to our questions would be highly dependent on the participants’ prior knowledge. As a result, we first needed to ensure that we conducted the comparative analysis from the same baseline.
The experiments were conducted in a controlled environment to minimize distractions where participants were sitting towards a wall and wearing an earphone to focus on the robot’s sound.
4.3. Participants
We recruited 93 participants (with the gender distribution of 45 males and 48 females; and ages spanning 20 to 29) and they are randomly assigned to three groups: “no cue” (NC) control group (30 participants: 15 males and 15 females), “oblique cue” (OC) group (30 participants: 14 males and 16 females), and “leading cue” (LC) group (33 participants: 16 males and 17 females). All participants were asked to take multiple-choice quizzes with the virtual MOCCA robot, and each participant answered 12 questions in total: the first set of 6 questions (Pre-test set) ensured group equivalence, and the second set of 6 questions (Test set) was used for comparative analysis. In order to assess participants’ baseline scores, the MOCCA robot did not give any hints during the Pre-test set to all the participants, regardless of groups they were part of. During the following Test set, the MOCCA robot applied different interventions to each group, respectively. For the NC control group, the robot continued providing no hints. For the other two groups (OC and LC), the robot provided hints to the correct answer by two different types of rapid gaze-based cues. For the OC group, the robot used an indirect and passive cueing method to bring about a possible IB situation. Conversely, for the LC group, the robot tried to guide participants’ attention on itself through a directed and contextual cueing method before giving hints.
4.4. Procedures
Detailed ways in which MOCCA hosted participants of each group are as follows. During each question, the MOCCA robot presented four choices displayed around her head on the screen as shown in
Figure 1. Each choice was intentionally placed at each corner side so that the participant would be able to notice the eye movements of MOCCA while reading through the four choices. In order to provide a cue revealing the answer to participants, the MOCCA robot made a quick, head-eye combined movement toward the right choice as shown in
Figure 1.
Participants in the OC group were asked to read through the four choices independently and select an answer at their leisure. We intended MOCCA to provide participants with a hint after they had read through all the choices, which we estimated would take two seconds after all choices first appeared on the screen. For the LC group, the MOCCA robot loosely controlled the participants’ pace and attention by reading out the four choices.
Once MOCCA completed this action, she instructed participants to answer on the count of three, and then provided a hint on the count of two. We expected the participants’ visual attention to be directed to the MOCCA robot on the countdown by audibly counting to three.
After the sessions ended, a researcher asked each participant to answer a brief post-survey on the likeability of MOCCA, the trust level of the social engagement, and the participant’s awareness of each of the robotic cues. The survey questions are as follows:
Q1: Do you like this robot? (Please answer using the 5-level Likert scale: 1: I hate it, 2: Dislike a little bit, 3: Neither dislike or like, 4: I like it a bit, or 5: I love it).
Q2: Do you trust MOCCA? (1: I do not trust it at all, 2: I have a bit of distrust, 3: I neither distrust or trust it, 4: I trust it a bit, 5: I have total trust in it).
Q3: Were you aware that MOCCA gave you hints during the quiz sessions? (1: I was not at all aware, 2: I was slightly aware, 3: I was somewhat aware, 4: I was moderately aware, 5: I was clearly aware).
5. Results
Our results from the study design described in
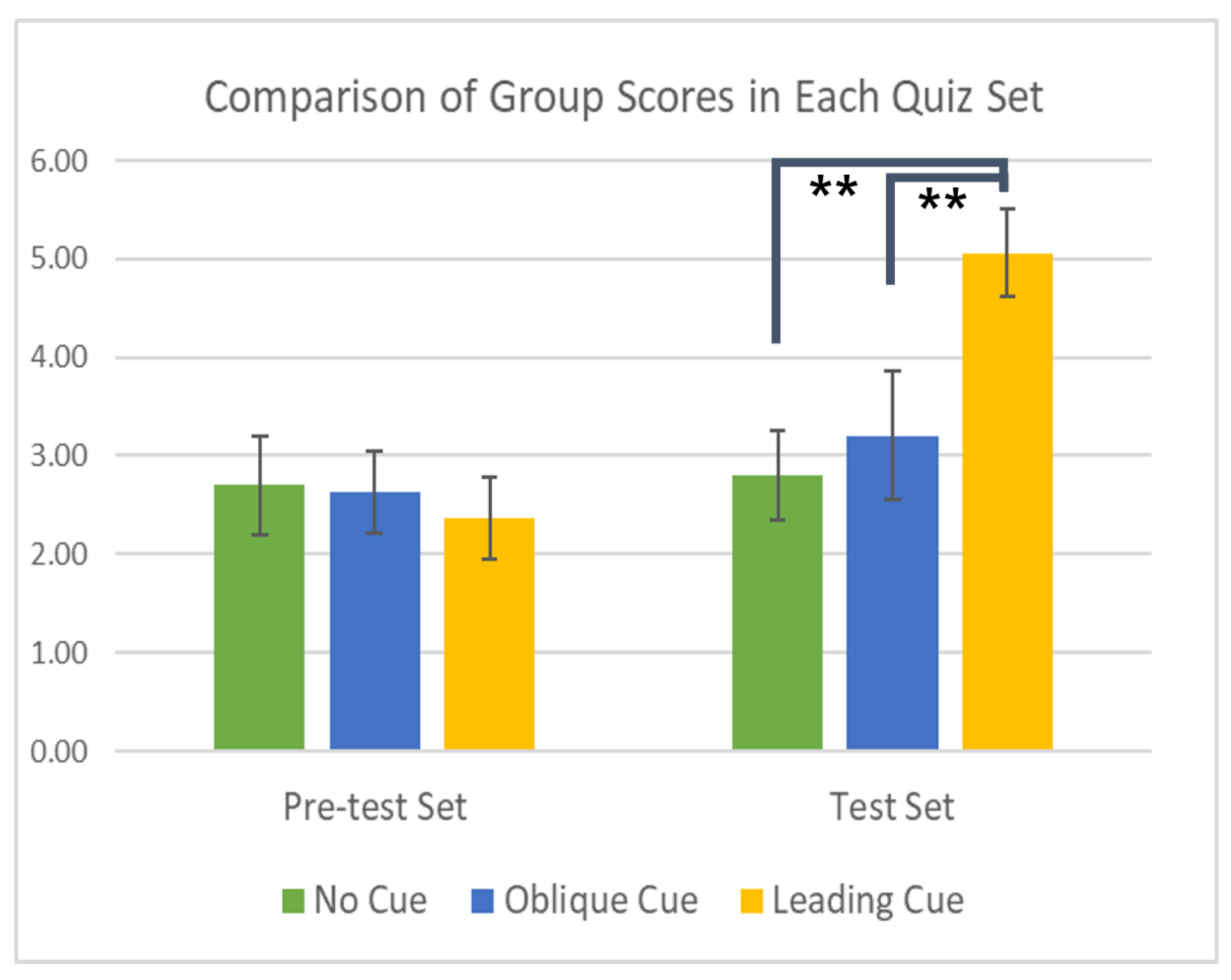
Section 4 showed clear presence of IB and the efficacy of our approach. The quiz scores from each group, designed to show the evidence of the effectiveness of the corresponding social cue, are compared in
Table 1 with the mean and standard deviation of each set score.
The one-way ANOVA analysis on this data indicated that there were no significant differences in the scores achieved by all three groups in the Pre-test set of questions in which no social cues are provided. This, thereby, demonstrates the group equivalence and well-balanced group design on the participants.
As for the Test set scores, the Test set score of the group OC was higher than that of the group NC, although this distinction was not statistically significant, despite the presentation of hints to the OC group by MOCCA. The effect of social cueing shown in the group LC, however, was more apparent and noticeable. The scores of the group LC were significantly higher compared to those of both groups OC and NC. This results are displayed in
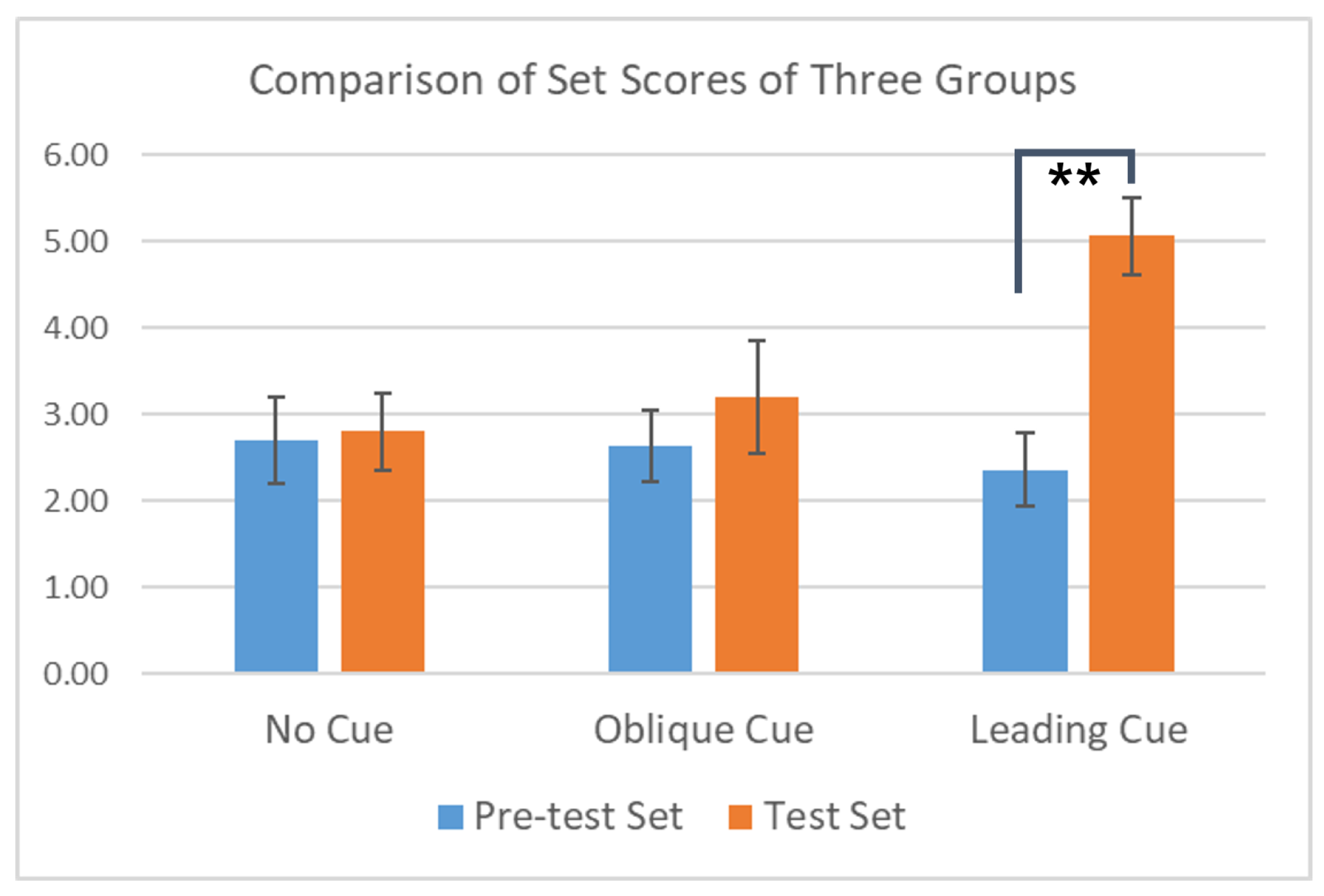
Figure 2. We also examined the increase in the scores between quiz sets (Pre-test set vs. Test set) within each group. The increase in the Test set score was significant only in the group LC as displayed in
Figure 3.
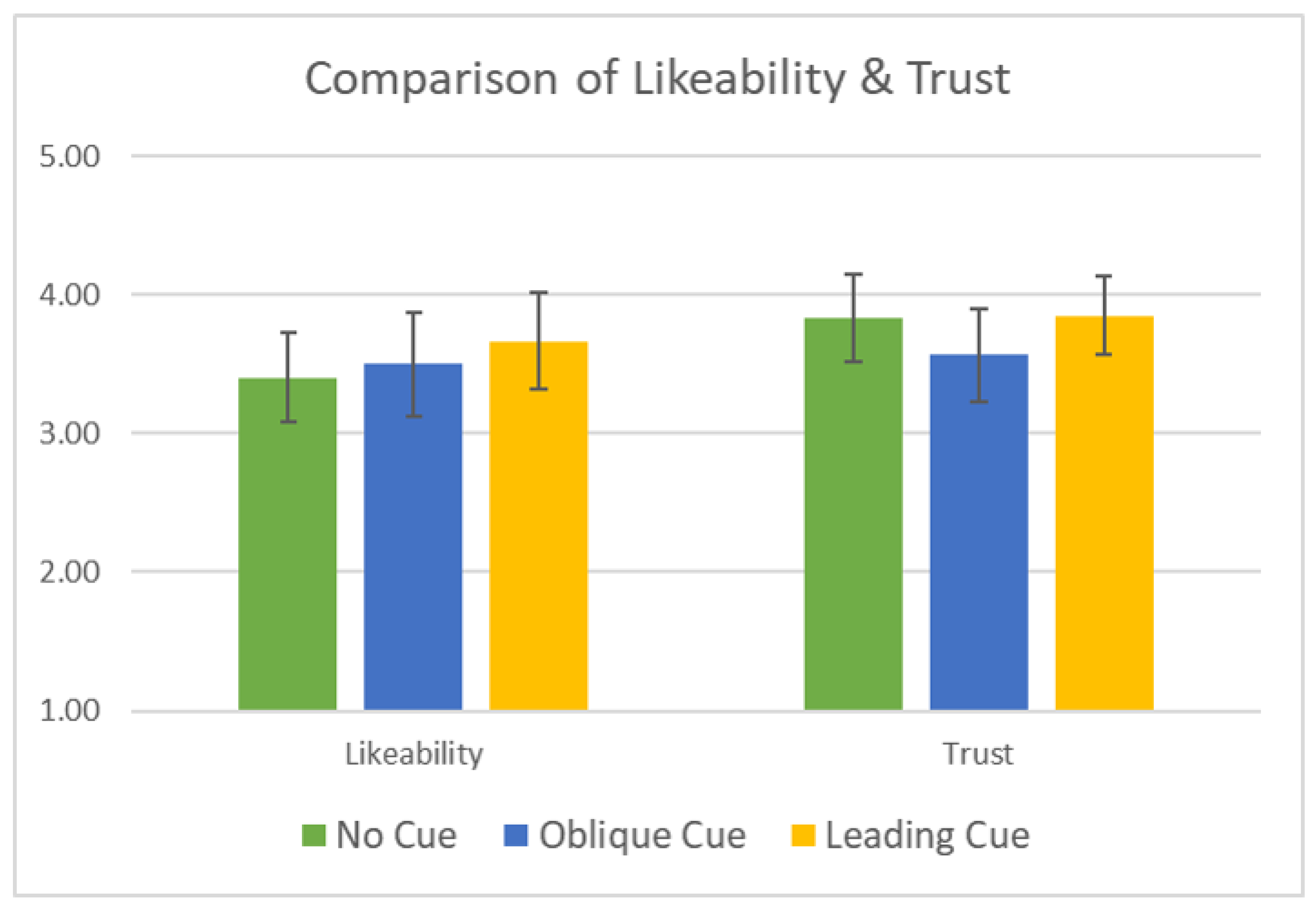
Additionally, the post-survey results showed that there was no statistically significant difference found on the likeability of MOCCA among the participants but showed general fondness (average of 3.5 in a 5-level Likert scale) as displayed in the left side of
Figure 4. However, the visible trend on the linear increase of likeability implies that the LC can be effective in developing a more interactive and effective social robotic cueing mechanism as the social cueing mechanism becomes more proactive (NC < OC < LC), with a big enough participants’ size of 93.
The participants’ response on the trust level, as shown in the right side of
Figure 4, shows no statistical difference nor any trend. On the contrary, the distinct decline of trust level on the oblique cue (OC) group shows that the random and unexpected social cue can play a negative role in gaining trust between social human–robot interaction.
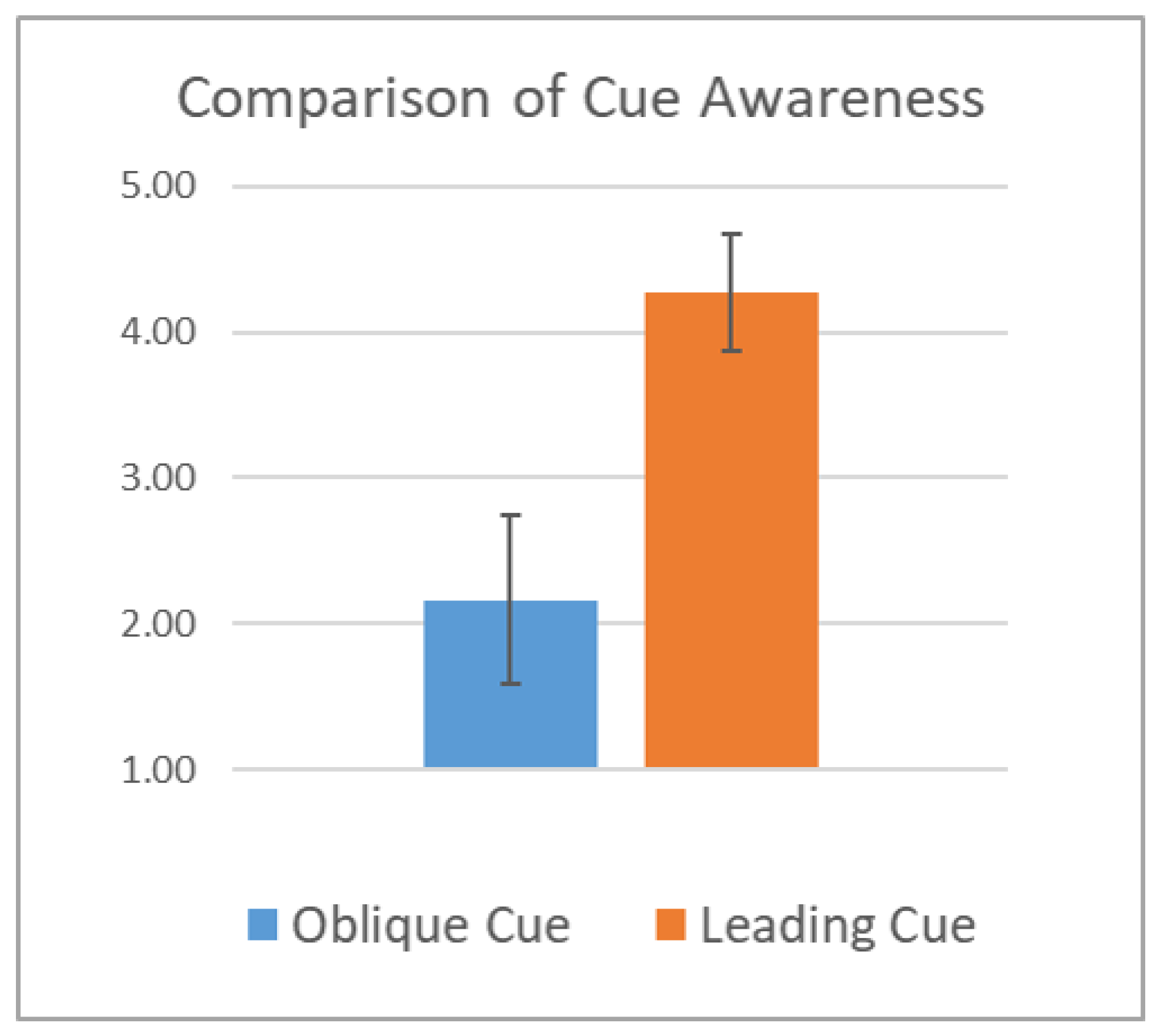
The third question from the post-survey as depicted in
Figure 5 aligns with our anticipations in the cue design as well as the level of trust above. The distribution shows clear difference in the success of cue awareness between OC and LC.
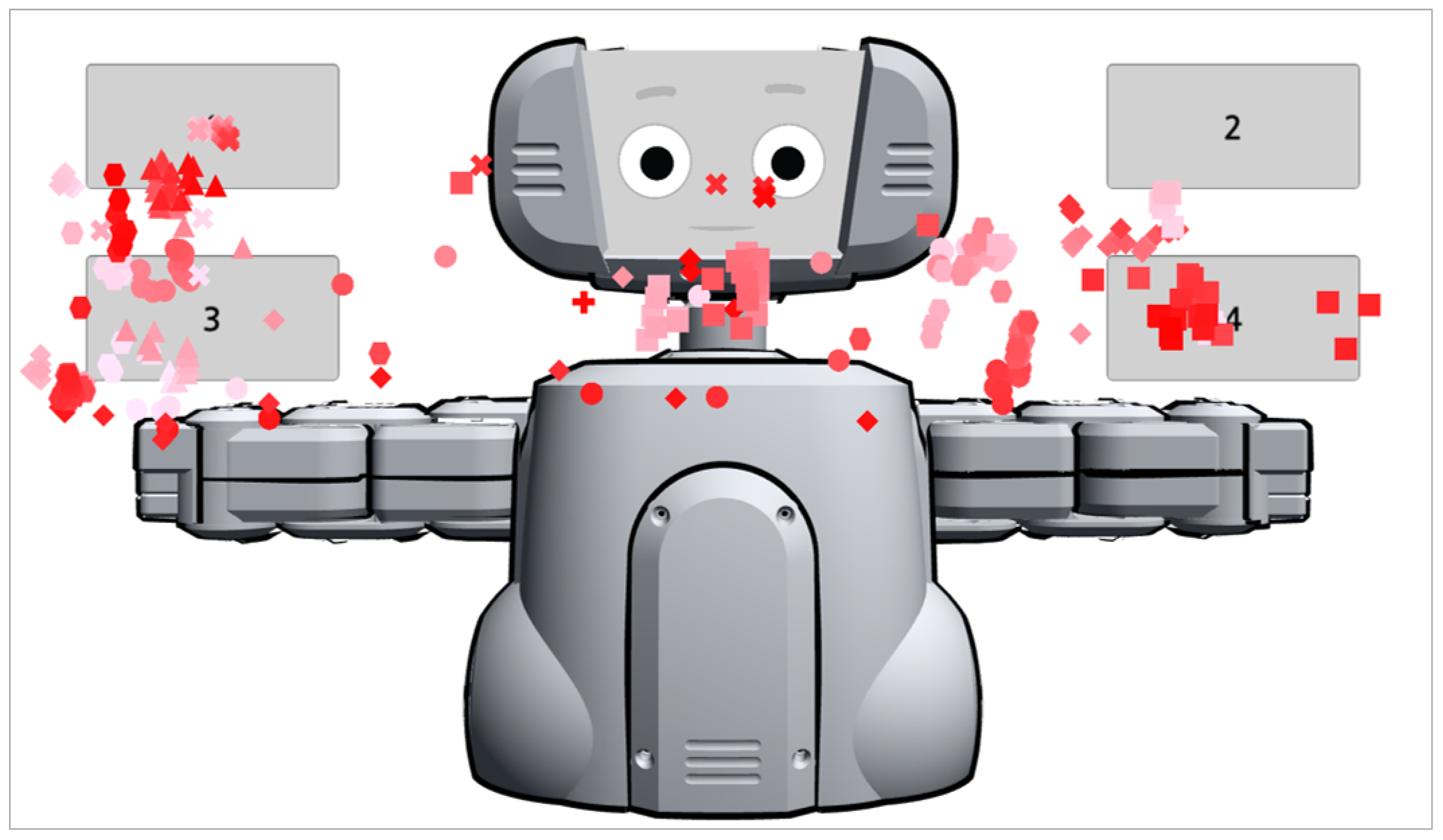
The system also tracked and recorded participants’ gaze trajectories in real time while they were responding to the questions.
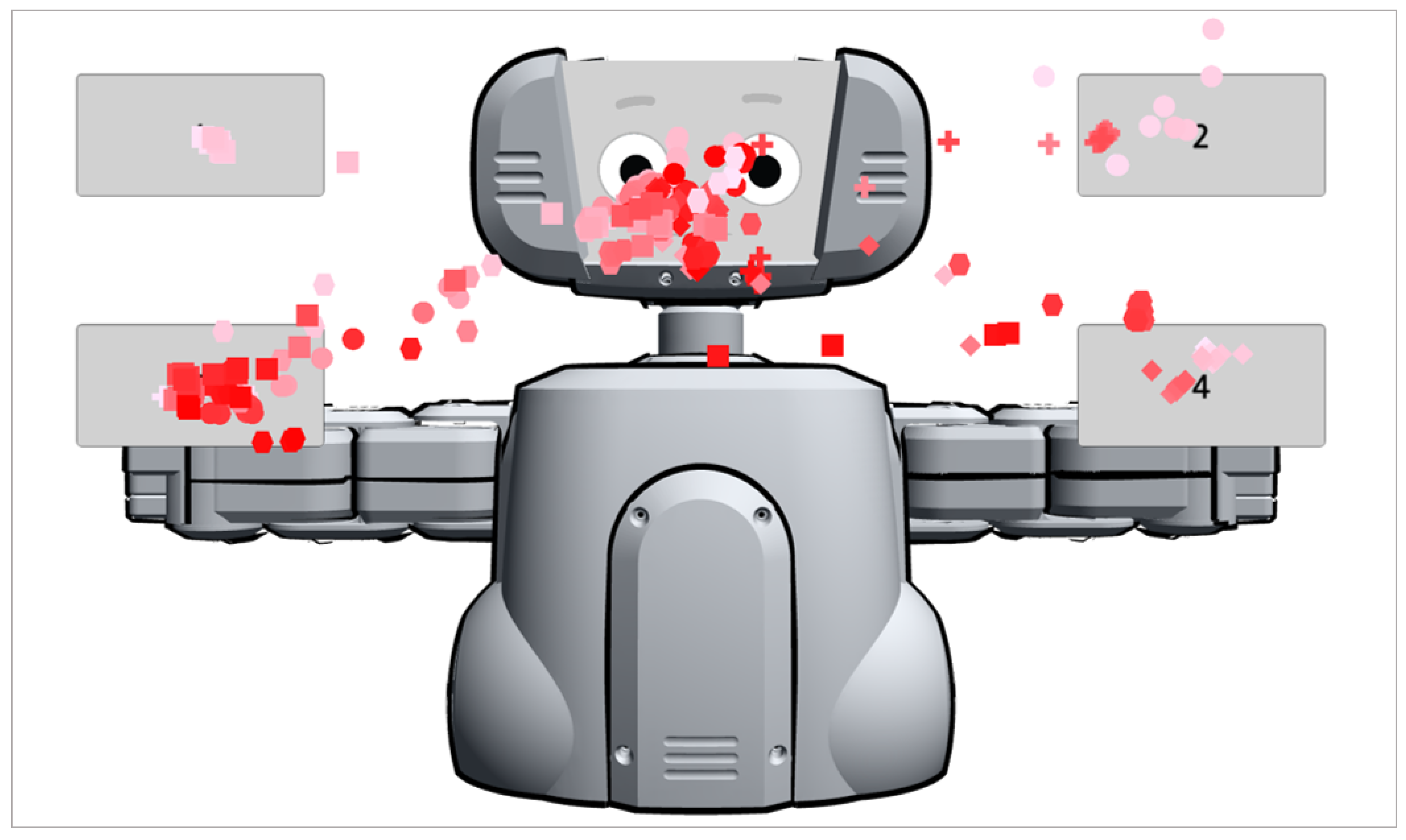
Figure 6 and
Figure 7 demonstrate that the gaze distributions in the OC and LC groups. In oblique cuing (OC) case (
Figure 6), the gaze trajectories are distributed over most of the choice buttons but not much on the robotic face, which means the robot’s social cueing did not have any implications on the human’s attention. However, in the leading cueing (LC) case (
Figure 7), it is obvious that the user’s attentions were focused mainly on the robot’s face and the button toward which the robot focused its leading cue.
6. Discussions
The findings from the experiment supported the formulated hypotheses. Our first hypothesis H1 anticipated that the impact of the robot’s gaze-based social cues might be limited due to the presence of the in-attentional blindness. By comparing the test scores of the NC group (to which no cues were provided) with those of the experimental OC group (to which cues were provided when participants might be reading the choices), we found that there was no significant increase in the OC group’s test scores despite being tipped for the answer.
To figure out a solution to overcome the drop in social communication during IB cases, we designed a “leading cueing”, where the robot deliberately guided the participant’s attention by achieving eye contact before signaling the correct answer. We hypothesized in the H2 that this LC method would improve participants’ performance by making it more likely that participants chose the right answers. By comparing the LC group’s test scores with those of the NC and OC groups, respectively, we found that the robot’s leading cues led to a significant increase in the test scores of the LC group when compared to those of the other two groups.
As Fisher et al. [
11] explained, the social and communicative function of the robotic gaze can only be fulfilled when the robot successfully secures the user’s attention and willingness to take the message. This experiment also demonstrated the importance of proactively guiding and leading a user’s attention through sophisticated interaction design to successfully capture the user’s attention in potential IB situations. Moreover, Morgan et al. [
35] showed that the cue-agent’s mental state directly impacts participants’ performance on a perceptual task. Thus, it seems to be a meaningful study to use robot’s modalities to control its mental state and examine the improved effects on dealing with IB.
Furthermore, as a result of the participants’ increased awareness of the robot’s hints, a significantly higher number of participants reported being aware of the help cues (4.3/5.0) in the LC group while most participants were not at all cognizant of the cues (2.2/5.0) in the OC group.
The quiz task used in our experiment can be generalized to situations in which the user needs to focus on a certain task. That is, in order for the robot to effectively communicate to the user, the communication method and timing of the robot must be designed in consideration of the occurrence of the IB situation in a general situation in which the user and the robot collaborate. In addition, we used the quiz questions of asking the capitals of certain countries, but this was only to create a set of common-sense questions. If expertise needs to be required, the IB situation could arise more evidently. Thus, if the robot is able to achieve delivering the collaborative social cue more effectively, it is expected that the user’s task performance and the likeability and reliability of the robot can be increased.
7. Conclusions
In this study, we have examined the ability of a social robot to adequately deliver collaborative gaze-based social signals to draw the participant’s attention which is easily disturbed by the presence of various visual stimuli. We primarily considered the existence and importance of in-attentional blindness in human–robot interaction with a focus on task-oriented communication by designing and conducting 1-on-1 collaborative quiz experiments. In accordance with the results, we can conclude that a robot’s gaze-based social cue may suffer from IB during a human–robot interaction (Hypothesis 1 (H1)); and the proposed proactive attention attraction based on a foundation of joint-attention will effectively improve the performance in a human–robot collaborative task (Hypothesis 2 (H2)).
In future studies, we aim to evaluate different methods by which a social robot can intentionally affect or control a human’s attention, such as by incorporating the stimuli of various modalities (e.g., eye tracking, vocal interaction, or body gestures). Through these multi-modal approaches, we will expand our study on how to effectively increase joint attention, successfully avoid in-attentional blindness even in multi-user interaction scenarios, and how to effectively utilize the users’ eye gaze data in real time.
Author Contributions
Conceptualization, W.L., C.H.P., and H.-K.C.; methodology, C.H.P. and W.L.; software, S.J.; validation, H.-K.C.; formal analysis, W.L.; investigation, C.H.P.; resources, S.J.; data curation, S.J.; writing—original draft preparation, W.L.; writing—review and editing, C.H.P., S.J., and H.-K.C.; visualization, S.J.; supervision, H.-K.C.; project administration, H.-K.C.; funding acquisition, H.-K.C. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Technology Innovation Program (10080615) funded by the Ministry of Trade, Industry and Energy (MOTIE, South Korea).
Acknowledgments
The authors would like to thank all the participants for taking their time to join our study and the undergraduate research assistants Jeongho Kim and Jungmin Lee with their rigorous efforts in data collection and experiments with participants.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Set of Questions
The following questions are used to conduct our experiments.
Q1: Which of the following cities is the national capital of Canada?
1. Toronto 2. Montreal 3. Vancouver 4. Ottawa
Q2: Which of the following cities is the national capital of Syria?
1. Aleppo 2. Damascus 3. Qinnasrin 4. Homs
Q3: Which of the following cities is the national capital of Malaysia?
1. George Town 2. Johor Bahru 3. Penang 4. Kuala Lumpur
Q4: Which of the following cities is the national capital of Morocco?
1. Tangier 2. Casablanca 3. Rabat 4. Fez
Q5: Which of the following cities is the national capital of Australia?
1. Canberra 2. Melbourne 3. Broome 4. Sydney
Q6: Which of the following cities is the national capital of Kenya?
1. Marsabit 2. Mombasa 3. Eldoret 4. Nairobi
Q7: Which of the following cities is the national capital of Turkey?
1. Ankara 2. Gaziantep 3. Istanbul 4. Rize
Q8: Which of the following cities is the national capital of Papua New Guinea?
1. Rabaul 2. Port Moresby 3. Lae 4. Madang
Q9: Which of the following cities is the national capital of the United Arab Emirates?
1. Dubai 2. Abu Dhabi 3. Sharjah 4. Fujairah
Q10: Which of the following cities is the national capital of Ireland?
1. Stockholm 2. Copenhagen 3. Dublin 4. Oxford
Q11: Which of the following cities is the national capital of Cuba?
1. Santiago de Cuba 2. Varadero 3. Havana 4. San Juan
Q12: Which of the following cities is the national capital of Venezuela?
1. Caracas 2. Santiago 3. Maracay 4. Coro
References
- Ruhland, K.; Peters, C.E.; Andrist, S.; Badler, J.B.; Badler, N.I.; Gleicher, M.; Mutlu, B.; McDonnell, R. A review of eye gaze in virtual agents, social robotics and hci: Behaviour generation, user interaction and perception. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2015; Volume 34, pp. 299–326. [Google Scholar]
- Ruusuvuori, J.; Peräkylä, A. Facial and verbal expressions in assessing stories and topics. Res. Lang. Soc. Interact. 2009, 42, 377–394. [Google Scholar] [CrossRef]
- Admoni, H.; Scassellati, B. Social eye gaze in human-robot interaction: A review. J. Hum.-Robot Interact. 2017, 6, 25–63. [Google Scholar] [CrossRef] [Green Version]
- Zheng, M.; Moon, A.; Croft, E.A.; Meng, M.Q.H. Impacts of robot head gaze on robot-to-human handovers. Int. J. Soc. Robot. 2015, 7, 783–798. [Google Scholar] [CrossRef]
- Sidner, C.L.; Kidd, C.D.; Lee, C.; Lesh, N. Where to look: A study of human-robot engagement. In Proceedings of the 9th International Conference on Intelligent User Interfaces, Funchal, Madeira, Portugal, January 2004; pp. 78–84. [Google Scholar]
- Mutlu, B.; Shiwa, T.; Kanda, T.; Ishiguro, H.; Hagita, N. Footing in human-robot conversations: How robots might shape participant roles using gaze cues. In Proceedings of the 4th ACM/IEEE International Conference on Human Robot Interaction, La Jolla, CA, USA, 9–13 March 2009; pp. 61–68. [Google Scholar]
- Srinivasan, V.; Murphy, R.R. A survey of social gaze. In Proceedings of the 2011 6th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Lausanne, Switzerland, 6–9 March 2011; pp. 253–254. [Google Scholar]
- Satake, S.; Kanda, T.; Glas, D.F.; Imai, M.; Ishiguro, H.; Hagita, N. How to approach humans? Strategies for social robots to initiate interaction. In Proceedings of the 4th ACM/IEEE International Conference on Human Robot Interaction, La Jolla, CA, USA, 9–13 March 2009; pp. 109–116. [Google Scholar]
- Zaraki, A.; Mazzei, D.; Giuliani, M.; De Rossi, D. Designing and evaluating a social gaze-control system for a humanoid robot. IEEE Trans. Hum.-Mach. Syst. 2014, 44, 157–168. [Google Scholar] [CrossRef]
- Mutlu, B.; Forlizzi, J.; Hodgins, J. A storytelling robot: Modeling and evaluation of human-like gaze behavior. In Proceedings of the 2006 6th IEEE-RAS International Conference on Humanoid Robots, Genova, Italy, 4–6 December 2006; pp. 518–523. [Google Scholar]
- Fischer, K.; Jensen, L.C.; Kirstein, F.; Stabinger, S.; Erkent, Ö.; Shukla, D.; Piater, J. The effects of social gaze in human-robot collaborative assembly. In International Conference on Social Robotics; Springer: Paris, France, 2015; pp. 204–213. [Google Scholar]
- Admoni, H.; Bank, C.; Tan, J.; Toneva, M.; Scassellati, B. Robot gaze does not reflexively cue human attention. In Proceedings of the Annual Meeting of the Cognitive Science Society, Boston, MA, USA, 20–23 July 2011; Volume 33. [Google Scholar]
- Meltzoff, A.N.; Brooks, R.; Shon, A.P.; Rao, R.P. “Social” robots are psychological agents for infants: A test of gaze following. Neural Netw. 2010, 23, 966–972. [Google Scholar] [CrossRef] [PubMed]
- Metta, G.; Natale, L.; Nori, F.; Sandini, G.; Vernon, D.; Fadiga, L.; Von Hofsten, C.; Rosander, K.; Lopes, M.; Santos-Victor, J.; et al. The iCub humanoid robot: An open-systems platform for research in cognitive development. Neural Netw. 2010, 23, 1125–1134. [Google Scholar] [CrossRef] [PubMed]
- Shaw, P.; Law, J.; Lee, M. A comparison of learning strategies for biologically constrained development of gaze control on an icub robot. Auton. Robot. 2014, 37, 97–110. [Google Scholar] [CrossRef] [Green Version]
- Warren, Z.E.; Zheng, Z.; Swanson, A.R.; Bekele, E.; Zhang, L.; Crittendon, J.A.; Weitlauf, A.F.; Sarkar, N. Can robotic interaction improve joint attention skills? J. Autism Dev. Disord. 2015, 45, 3726–3734. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Navab, A.; Gillespie-Lynch, K.; Johnson, S.P.; Sigman, M.; Hutman, T. Eye-tracking as a measure of responsiveness to joint attention in infants at risk for autism. Infancy 2012, 17, 416–431. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Swanson, M.R.; Siller, M. Patterns of gaze behavior during an eye-tracking measure of joint attention in typically developing children and children with autism spectrum disorder. Res. Autism Spectr. Disord. 2013, 7, 1087–1096. [Google Scholar] [CrossRef]
- Simons, D.J.; Chabris, C.F. Gorillas in our midst: Sustained inattentional blindness for dynamic events. Perception 1999, 28, 1059–1074. [Google Scholar] [CrossRef] [PubMed]
- Drew, T.; Võ, M.L.H.; Wolfe, J.M. The invisible gorilla strikes again: Sustained inattentional blindness in expert observers. Psychol. Sci. 2013, 24, 1848–1853. [Google Scholar] [CrossRef] [PubMed]
- Mehlmann, G.; Häring, M.; Janowski, K.; Baur, T.; Gebhard, P.; André, E. Exploring a model of gaze for grounding in multimodal HRI. In Proceedings of the 16th International Conference on Multimodal Interaction, Istanbul, Turkey, 12–16 November 2014; pp. 247–254. [Google Scholar]
- Yoshikawa, Y.; Shinozawa, K.; Ishiguro, H.; Hagita, N.; Miyamoto, T. Responsive Robot Gaze to Interaction Partner. In Robotics: Science and Systems; University of Pennsylvania: Philadelphia, PA, USA, 2006; pp. 37–43. [Google Scholar]
- Palinko, O.; Rea, F.; Sandini, G.; Sciutti, A. Robot reading human gaze: Why eye tracking is better than head tracking for human-robot collaboration. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 5048–5054. [Google Scholar]
- Atienza, R.; Zelinsky, A. Intuitive human-robot interaction through active 3d gaze tracking. In Robotics Research. The Eleventh International Symposium; Springer: Berlin/Heidelberg, Germany, 2005; pp. 172–181. [Google Scholar]
- Miyauchi, D.; Sakurai, A.; Nakamura, A.; Kuno, Y. Active eye contact for human-robot communication. In CHI’04 Extended Abstracts on Human Factors in Computing Systems; ACM: Vienna, Austria, 2004; pp. 1099–1102. [Google Scholar]
- Boucher, J.D.; Pattacini, U.; Lelong, A.; Bailly, G.; Elisei, F.; Fagel, S.; Dominey, P.F.; Ventre-Dominey, J. I reach faster when I see you look: Gaze effects in human–human and human–robot face-to-face cooperation. Front. Neurorobot. 2012, 6, 3. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fischer, K.; Lohan, K.S.; Nehaniv, C.; Lehmann, H. Effects of different kinds of robot feedback. In International Conference on Social Robotics; Springer: Bristol, UK, 2013; pp. 260–269. [Google Scholar]
- Fischer, K.; Soto, B.; Pantofaru, C.; Takayama, L. The effects of social framing on people’s responses to robots’ requests for help. In Proceedings of the IEEE Conference on Robot-Human Interactive Communication–Ro-Man’14, Edinburgh, Scotland, UK, 25–29 August 2014. [Google Scholar]
- Admoni, H.; Dragan, A.; Srinivasa, S.S.; Scassellati, B. Deliberate delays during robot-to-human handovers improve compliance with gaze communication. In Proceedings of the 2014 9th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Bielefeld, Germany, 3–6 March 2014; pp. 49–56. [Google Scholar]
- Lee, D.H.; Jang, S.; Cho, H.K. MOCCA Studio: A Graphical Tool for High-Level Programming of Human-Robot Social Interaction. In Proceedings of the 14th ACM/IEEE International Conference on Human-Robot Interaction, Daegu, Korea, 11–14 March 2019. [Google Scholar]
- Deaner, R.O.; Shepherd, S.V.; Platt, M.L. Familiarity accentuates gaze cuing in women but not men. Biol. Lett. 2006, 3, 65–68. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jang, S.; Cho, H.K. Analysis of User’s Eye Gaze Distribution while Interacting with a Robotic Character. J. Korea Robot. Soc. 2019, 14, 74–79. [Google Scholar] [CrossRef]
- Mutlu, B.; Yamaoka, F.; Kanda, T.; Ishiguro, H.; Hagita, N. Nonverbal leakage in robots: Communication of intentions through seemingly unintentional behavior. In Proceedings of the 4th ACM/IEEE International Conference on Human Robot Interaction, La Jolla, CA, USA, 9–13 March 2009; pp. 69–76. [Google Scholar]
- Mwangi, E.; Barakova, E.I.; Díaz-Boladeras, M.; Català Mallofré, A.; Rauterberg, M. Directing Attention Through Gaze Hints Improves Task Solving in Human—Humanoid Interaction. Int. J. Soc. Robot. 2018, 10, 343–355. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Morgan, E.J.; Freeth, M.; Smith, D.T. Mental state attributions mediate the gaze cueing effect. Vision 2018, 2, 11. [Google Scholar] [CrossRef] [PubMed] [Green Version]
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}