1. Introduction
Along with the rapid development of the society, the problem of water pollution in China has become increasingly serious. Influenced by this phenomenon, the safety of drinking water is of great concern. Water source selection is one of the preventive measures to ensure the safety and hygiene of drinking water for residents [
1]. Meanwhile, as China has become the largest consumer of bottled water, selecting an appropriate drinking water source region (DWSR) is also a challenge to companies when supporting the supply of drinks. Therefore, it is essential and practical to study how to select suitable DWSRs, which raises a complex decision-making problem that would always encounter uncertainty in an realistic decision environment. To address this issue, we concentrate on developing an evaluation approach for selecting available DWSRs from the angle of companies by answering several research questions:
- (1)
Is it possible to accurately represent the contradictory evaluation results for DWSRs given by different decision makers?
- (2)
As distinctive criteria are not equal and asymmetrically prioritized in terms of different decision makers’ preferences, how to generate weights of criteria?
- (3)
How to distinguish different decision makers with respect to different alternatives?
- (4)
How to fuse distinctive assessments of DWSRs without complaints, which may lead to the decline of decision efficiency?
Responding to these points, our research deals with multi-criteria group decision-making (MCGDM) problems defined in weak probabilistic hesitant fuzzy contexts and unknown weight information on the premise of an asymmetrical prioritization of criteria. The contributions of this study are:
(1) Information presentation. Differing from most MCGDM problems [
2], the individual decision maker considered in this paper is not referred to an individual person, but an individual group. Actually, there are some available extensions of fuzzy sets that are capable of describing the decision information supplied by individual groups, such as probabilistic linguistic term sets [
3] and picture fuzzy sets [
4]. However, these sets are always defined to present complete information or are not able to show probabilistic information. Hence, considering the ability of weak probabilistic hesitant fuzzy elements (P-HFEs) for expressing distinctive opinions in a set and allowing incomplete probabilistic information, it is quite appropriate to use weak P-HFEs to express the opinions of each individual group.
(2) Weight generation function. In light of the asymmetrically prioritized relationship between criteria, we are going to extend the classical prioritized aggregation operators [
5] to fuse criteria values regarding each alternative given by each group. Meanwhile, the prioritization given by each group will be utilized in a newly introduced priority-based basic unit interval and monotonic (P-BUM) function, to yield the importance weights of different criteria with respect to different alternatives.
(3) Information measurements. Commonly, large distance is in correspondence to little consensus [
6,
7]. Given that the numbers of the elements in different weak P-HFEs are not equal, this paper will introduce a series of Hausdorff distance measures to measure the distinction among different groups. Based on this, the weights of different groups under different alternatives will be generated.
(4) Information fusion. Generally speaking, aggregation operators are powerful tools to integrate the information derived from individuals in one group [
8]. To synthesize distinctive opinions, a series of aggregation operators, which can be divided into two branches, will be developed. One branch contains two prioritized aggregation operators, aiming to fuse criteria values for alternatives. The other branch is to integrate group assessments by inserting the relationship between different groups into the extension of the classical induced ordered weighted averaging (IOWA) operator, which considers the special ability of an inducing variable.
(5) Approach development. A hybrid evaluation approach will be developed to handle an existing problem for evaluating DWSRs, which contains positive and negative decision information and incomplete weight information.
The rest of this paper is arranged as follows. In
Section 2, a review of extant studies is presented. In
Section 3, the weak P-HFEs with its operations and comparisons, as well as some aggregation operators are reviewed. Moreover, the innovative operators, which cover the previously defined two aggregation phases, are introduced. Moreover, a supported P-BUM function and a family of generalized Hausdorff distance measures are put forward. In
Section 4, the background of the MCGDM problem being tackled in this paper and the corresponding solving approach are presented. In
Section 5, an example of application regarding the evaluation for DWSRs is furnished. In
Section 6, discussions including the findings of the experiment and comparisons are illustrated. In
Section 7, conclusions are drawn.
2. Literature Review
Initiated by Zadeh [
9], the fuzzy set is a powerful tool to represent uncertain information. During the last decades, it has been extended to various forms to accommodate complex and vague decision environments. These extended forms can be roughly captured by two branches: numeric and linguistic. Despite the success of a series improvement of the linguistic decision making [
10,
11,
12,
13], this has ignored the distortion of the original information because it usually requires some tools (the cloud model [
14], linguistic scale function [
15], the transformation function [
16,
17], etc.) to make the linguistic values calculable. Bearing this in mind, we intend to manage MCGDM problems with numeric values when there are uncertainties expressed by the weak P-HFEs, which can be deemed as an important extension of numeric fuzzy settings. Weak P-HFEs [
18], including a hesitant fuzzy set [
19] and corresponding probabilities, is a direct extension of the probabilistic hesitant fuzzy elements (P-HFEs) [
20]. Despite the common advantage of these two sets for simultaneously representing positive and negative information, the weak P-HFEs further considered the incompleteness of probabilistic information. It is this idea that allows us to measure the degree of membership degree with its probabilities in realistic situations. Although there is some similar characteristics between weak P-HFSs and PHFSs, they differ from each other in the development of solving realistic problems. As to the PHFS, it has awakened high interest among the researchers [
21,
22,
23], due to its ability to enrich the flexibility of expressing real-world decision information. Compared with the development of PHFSs and to the best of our knowledge, there is not a huge amount of literature reporting studies about the weak P-HFEs. This is possibly because the weak P-HFEs were newly introduced as a notable concept. To enhance and spread the applicability of weak P-HFEs, this paper will investigate MCGDM problems with weak probabilistic hesitant fuzzy information.
In general, the majority of selection issues contain fuzzy information and groups of decision makers, which are always addressed as MCGDM problems. Water source selection is an environmental process that is always concerned with the application of multi-criteria decision problems [
24]. As a rule of thumb, when the decision makers involved in a decision process are no less than one, the multi-criteria decision converts to an MCGDM process. Furthermore, an MCGDM problem usually includes the fusion of decision information. For this, aggregation operators turn out to be an effective and powerful tool since they are so intuitive to fuse individual information by consideration of importance weights. Until now, a majority of distinctive aggregation operators are developed. Aiming to suit the MCGDM problem in this paper, the comprehensive assessments of each alternative as well as the overall opinions of all decision makers ought to be derived. As such, we define the fusion process into two phases, which are respectively in need of two types of aggregation operators:
(1) In terms of the synthesis of criteria values, we define the first fusion phase to be in accordance with the phenomenon of the prioritization between criteria, which appears frequently in real-life decision environments. To support this process, there are two fundamental issues to be solved: determining the weights and developing the operator. Nevertheless, early efforts in figuring out the incomplete weight information of criteria did not consider the prioritization relationship of criteria [
25,
26,
27,
28,
29]. Oppositely, the prioritized average operators have absorbed not a few academic concentrations, including the prioritized aggregation operator [
5], the prioritized ordered weighted averaging operator (POWA) [
30], and their extensions [
31,
32,
33,
34]. Thus, the combination of the generation technique of objective weights for criteria and prioritized aggregation operators has some benefits in finding solutions to realistic decision-making problems.
(2) From the perspective of integrating individual opinions, we define the second fusion phase, which could reflect the relationship between individuals with respect to different alternatives. To accomplish this phase, a family of the IOWA operators [
35] proves to be a suitable tool. This is because the necessary inducing variables could represent the relationship between argument variables. Following this idea, the extension of the IOWA operator to the weak probabilistic hesitant fuzzy environment poses a challenge as to how to determine the inducing variable. Undoubtedly, distance is a good choice. Measuring the distance between different objects is a useful way to manifest the relationship between them. To support this, the last decades have witnessed a lot of studies on different distance measures, such as the Hamming distance, the Euclidean distance, the Hausdorff distance, the Hybrid distance, the entropy-based distance, and the ordered weighted distance measure [
28,
36,
37,
38]. Except for the Hausdorff distance, the others all demand that the length of the compared objects should be the same. To some extent, this requirement may not be possible under a weak probabilistic hesitant fuzzy environment, due to the uncertainty expressed through the weak P-HFEs.
3. Related Works
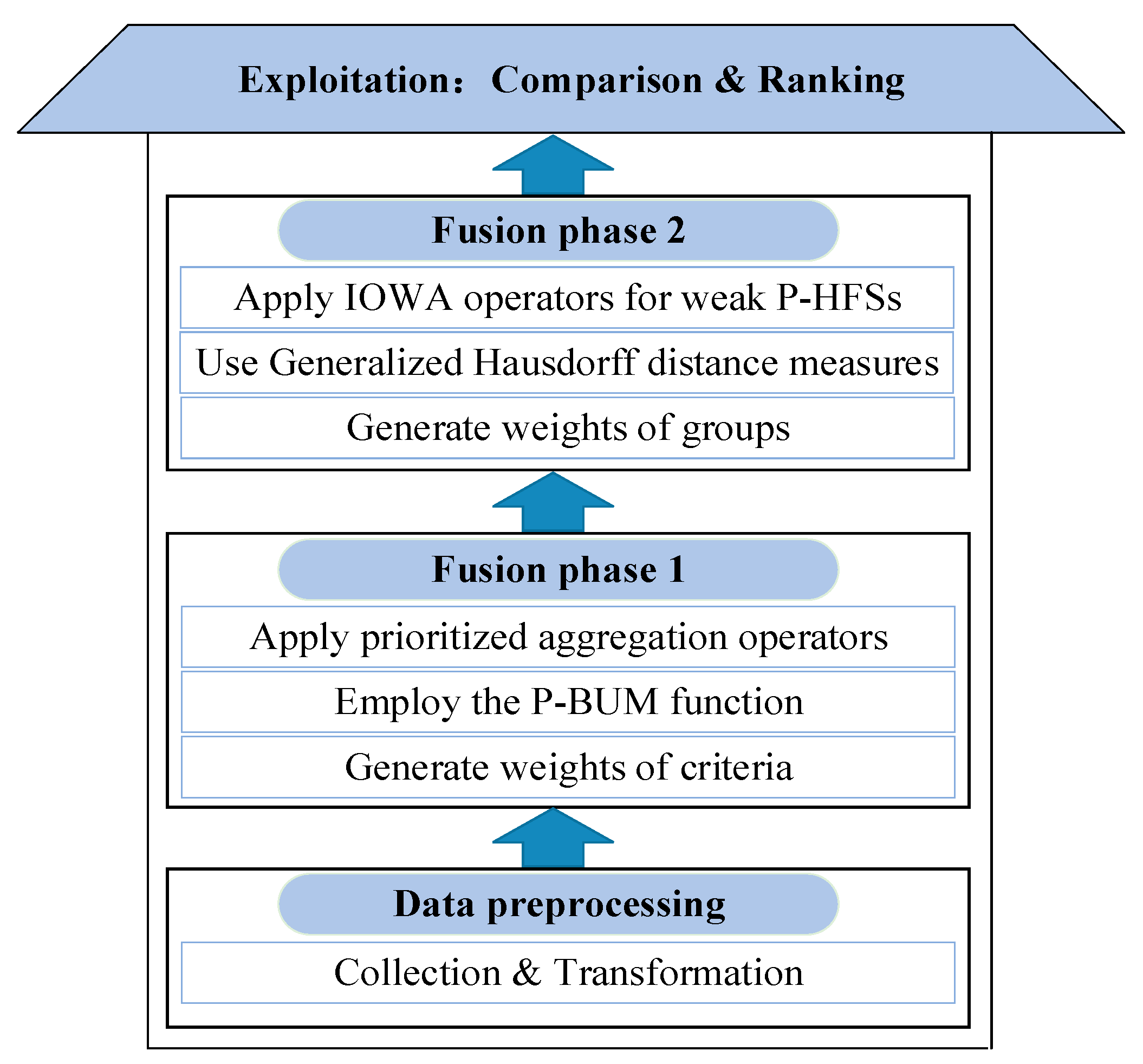
This section firstly reviews some basic concepts related to the decision data in this paper. Furthermore, we discuss the extension of prioritized aggregation operators to weak probabilistic hesitant fuzzy environments. To complete the aggregation, a P-BUM function is established. Then, by considering the relationship between weak P-HFEs, we put forward a generalized aggregation operator, which is quantified by the introduction of a family of generalized Hausdorff distances.
3.1. Weak Probabilistic Hesitant Fuzzy Elements
Definition 1. [
18].
Let be a fixed set. A weak P-HFE is defined in terms of a function that, when applied to , returns to a subset of and is mathematically expressed as: where the values in both of the two sets and are lying in the range of .
To be specific, the symbol refers to some possible membership degrees of to the set . Accordingly, stands for the associated possibilities with .
For convenience, is called a weak P-HFE, in which is defined as one of the terms in the weak P-HFE and .
Definition 2. [
18].
Let be two arbitrary weak P-HFEs and ,
then - (1)
;
- (2)
;
- (3)
; and
- (4)
.
As to any fuzzy setting, comparison is imperative. In this paper, we adopt the following definition to compare any two weak P-HFEs.
Definition 3. [
18]
For a weak P-HFE , its score and deviation degree are defined as:
Then, based on Equations (2) and (3), the comparison rules of two weak P-HFEscan be summarized below.
- (1)
If, then;
- (2)
If, then;
- (3)
If, then three situations exist:
- 1)
If, then;
- 2)
If, then;
- 3)
If, then.
3.2. Prioritized Aggregation Operators
This subsection reviews some prioritized aggregation operators to facilitate further studies.
Definition 4. [
5]
Let be a finite set of criteria. The prioritization of these criteria is mathematically predefined with a linear ordering
, which implies that the priority of criterion becomes lower with the increase in the subscript of . Assume is the assessment value of an arbitrary alternative over ,
then the prioritized average (PA) operator is defined with the following form:where with and .
To enforce the necessity of the prioritization between criteria, Yager [
30] further put forward the POWA operator, which is originated from the idea of the normalized priority-based importance degrees and the BUM function [
39].
Definition 5. [
30]:
Let be a BUM function and be the weight vector of criteria, then the POWA operator is mathematically defined as:
where the BUM function should satisfy , and , and , in which the value of ranks as the th largest among .
3.3. Prioritized Weak Probabilistic Hesitant Fuzzy Weighted Averaging Operator
Motivated by the fundamental concepts of prioritized aggregation operators, this subsection introduces the prioritized weak probabilistic hesitant fuzzy weighted average (PWPHFWA) operator.
Definition 6.Letbe a finite set ofcriteria, which are partitioned by a prioritization, and assumeisweak P-HFEs representing the assessment value of an arbitrary alternativeover. The PWPHFWA operator is an aggregation function withwherebeing Obviously, during the calculation of the weights of criteria, the probabilities are normalized and newly distributed. To some extent, this process avoids the ignorance of probabilistic information. In other words, this conforms to the habit of human beings that the sum of importance weights should be equal to 1.
To better understand the PWPHFWA operator, a practical example is illustrated below.
Example 1.Let the prioritized relationship of four criteria be. Assume the criteria values for an alternative is,,, and.
As per Equation (8), we have
,
,
, and
. Afterwards, from these results and according to Equation (7), we have
,
,
, and
. Then, utilizing Equation (6), one can obtain:
From this numeric example, the resulted criteria weights show their accordance with the predefined prioritization of criteria, and illustrate that the frontal prioritized criteria cannot be compensated by the posteriori ones.
Theorem 1.The aggregated value by the PWPHFWA operator is still a weak P-HFE.
It is obvious that this theorem always holds, so the proof is omitted here.
Theorem 2.The probabilistic information in the aggregated value by the PWPHFWA operator is completed, i.e., the sum of the associated probabilistic values equals to 1.
Proof. As per Equations (7)–(8), the original probabilistic information existing in each criterion value, which may not be coincident with human habits that the sum of the probabilistic values should be 1, is normalized by a division operation. Undoubtedly, this design firmly supports the establishment of Theorem 2. □
Frankly speaking, the PWPHFWA operator does not possess the properties of idempotency, monotonicity and boundary. This conclusion can be drawn from an analysis that the addition between two identical weak P-HFEs would not result in the same value like other settings. Nevertheless, the commutative law of the PWPHFWA operator can be elucidated in the following theorem.
Theorem 3. Letbe an arbitrary permutation of. Denote the prioritization of the permutatedcriteria as, whereare, respectively, in the same position with. Supposeareweak P-HFEs representing the assessment value, then:
whererefer to the prioritized criteria of.
Remark. For the sake of the prioritized positions being predefined for every criterion, the new prioritizationtotally equates to the original prioritization. In other words, whatever the permutation of the finite criteria is, the prioritization of the distinctive criteria is fixed.
Proof. Obviously, since the permutation does not influence the prioritized ranking of the criteria, the weight information of the permutated criteria is entirely the same as that of the original ranked criteria. Therefore, the aggregation results of and those of would be the same. That is to say, Theorem 3 always holds. □
3.4. Prioritized Weak Probabilistic Hesitant Fuzzy Ordered Weighted Averaging Operator
To strengthen the power of the prioritization imperative, this subsection further proposes the prioritized weak probabilistic hesitant fuzzy ordered weighted averaging (PWPHFOWA) operator as follows.
Definition 7. Letbe a BUM function andbe a fixed set ofcriteria with an associated prioritization. Supposeisweak P-HFEs representing the assessment value of an arbitrary alternativeover,
then the PWPHFOWA operator is defined with the mathematical expression:
where the BUM function satisfies,and, andin which the value ofranks as theth largest among. In other words,is a permutation such that, for.
Theorem 4. The aggregated value by the PWPHFOWA operator is still a weak P-HFE.
It is obvious that this theorem always holds, so the proof is omitted here.
Theorem 5. The probabilistic information in the aggregated value by the PWPHFOWA operator is completed, i.e., the sum of the associated probabilistic values equals 1.
Similar to Theorem 2, this theorem can be easily proved.
Theorem 6. Letbe an arbitrary permutation of. Denote the prioritization of the permutatedcriteria as, whereare, respectively, in the same position with. Assumeisweak P-HFEs representing the assessment value, then:whererefer to the prioritized criteria of.
Proof. On one hand, from the definition of the PWPHFOWA operator, the reordered sequence of the criteria is determined by the original criteria values, so this variable would not be affected by the permutation of the criteria. On the other hand, the importance weights of the criteria are dependent on the BUM function and the normalized priority-based importance degrees derived from the priorities of the criteria. Clearly, this does not have any connection with the permutation of the criteria yet. Thereby, the proof of Theorem 6 is completed. □
In this PWPHFOWA operator, the sequence of the criteria weights is dominated by the weak P-HFEs expressing the criteria values for the alternative. Meanwhile, the normalized priority-based importance degrees generated from the prioritized information indirectly determines the weights of criteria by using a BUM function. Thereafter, there is a significant push towards the development of the BUM function, which should accommodate to the environment of prioritized weak probabilistic hesitant fuzzy information. Followed by the properties of the PWPHFOWA operator, we present a BUM function for weak P-HFEs as below.
Definition 8. Letbe a collection of weak P-HFEs, andbe a subset of,
then a P-BUM function is defined as:
whereis the corresponding importance degree of the criterion value, which is ranked as theth
position with a decreasing sequence.
Theorem 7. For the P-BUM function, it has the following properties:
- (1)
Boundary: For,, especially for an empty set, i.e., no element is included in,. On the contrary, for a universal set,.
- (2)
Monotonicity: If, then.
It is obvious that these two properties naturally hold. Thereby, we omit the proof here.
Example 2. Assume the criterion values for an alternative is,,, and. The prioritized relationship between these four criteria is.
First of all, rank the criteria values by employing Definition 3. The scores and the ranking are listed as follows:
From the scores, one can easily discriminate the orders of the four criteria as
. Following this, the criteria are reordered as:
Correspondingly, by taking advantage of the results in Example 1, we have the criteria satisfactions numerically expressed by the normalized priority-based importance degrees are newly endowed with
Then, utilizing the P-BUM function, one can obtain the weight information related to the criteria as:
Finally, By employing Equation (10), we have the comprehensive value of alternative
as:
3.5. Weak Probabilistic Hesitant Fuzzy Induced Ordered Weighted Averaging Operators
The above presented PWPHFOWA operator is an extension of the POWA operator under a weak probabilistic hesitant fuzzy environment. If we take the prioritized information as an inducing variable, this POWA operator may be deemed as a special case of the IOWA operator [
35]. Bearing this in mind, this subsection aims to present a more general type of the PWPHFOWA operator. In detail, the weak probabilistic hesitant fuzzy IOWA (WPHFIOWA) operator, together with its properties, is going to be studied.
Definition 9.
Letbe a collection of weak P-HFEs. A WPHFIOWA operator of dimensionis an aggregation function with the following expression:
whereplays the part of the inducing variable andis called the argument variable. Moreover, according to the ranking of the inducing variables,is reordered and denoted by.
In Equation (13), based on the value of
and a quantifier guided function [
39], the weight information
could be indirectly decided. In what follows, some properties of this WPHFIOWA operator are studied.
Theorem 8. The aggregated value by the WPHFIOWA operator is still a weak P-HFE.
It is obvious that this theorem always holds, so the proof is omitted here.
Theorem 9. The probabilistic information in the aggregated value by the WPHFIOWA operator is completed, i.e., the sum of the associated probabilistic values equals to 1.
Similar to Theorem 2, this theorem can be easily proved.
Theorem 10. Letbe any permutation of, then:
whereare the associating inducing variables of.
This theorem can be analogously verified by reference to the proof of Theorem 6.
As is well known, central to the IOWA operator is the implementation of the inducing variable, which is a deterministic factor in the aggregation process. Generally, many indices can be applied to undertake this role for formulating the relationship between the argument variables. For the sake that the distance between two objects could intuitively reflect their distinction, we consider the distances between weak P-HFEs to be inducing variables.
Definition 10. Letbe two arbitrary weak P-HFEs, the generalized Hausdorff distance measure betweenandcan be mathematically defined with the following form:where.
This distance measure satisfies some properties summarized below.
Theorem 11. Letbe any three weak P-HFEs, then
- (1)
;
- (2)
, iff;
- (3)
; and
- (4)
If, thenand.
It is obvious that properties (1–3) naturally hold. Herein, we just provide the proof process of the last property in Theorem 11 in the
Appendix.
In the following, we take an analysis of the WPHFIOWA operator by configuring the value of the parameter .
If
, then the above generalized Hausdorff distance measure degenerates to the following Hamming–Hausdorff distance measure between
and
:
If
, then the above generalized Hausdorff distance measure degenerates to the following Euclidean–Hausdorff distance measure:
By taking the distance between two weak P-HFEs as the inducing variable, we can characterize an extension of the IOWA operator defined below.
Definition 11. Letbe a collection of weak P-HFEs, a weak probabilistic hesitant fuzzy distance-based IOWA (WPHFD-IOWA) operator of dimensionis an aggregation function mathematically defined as:whereandwithand. Definitely,stands for the distance ofto others anddenotes theth smallest one among.
Similarly, this WPHFD-IOWA operator possesses the same properties with the WPHFIOWA operator. Such properties are introduced by Theorems 8–10.
4. Methodology
This section firstly formulates a group decision environment on the basis of weak P-HFEs. Within this fuzzy environment, an evaluation method for handling MCGDM problems, where the criteria are given a prioritization relationship and the weight information is unknown, is proposed.
4.1. Problem Statement
Consider the kind of MCGDM problems within an uncertain decision environment involving the weak probabilistic hesitant fuzzy information. Suppose is the alternative set, in which indicates the number of alternatives. Define as a finite set of criteria, for which the importance information is unknown. Besides, these criteria are not given symmetrical priority, due to the subjective distinction of decision makers. Let denote groups of decision makers who are invited to furnish their opinions of alternatives with respect to different criteria. The opinion of group for alternative with respect to criteria is performed by a weak P-HFE denoted as . Overall, the evaluation ratings of alternatives are characterized by , and weak probabilistic hesitant fuzzy decision matrices are represented by . Except for providing judgments on alternatives, each group is required to provide a prioritization of the criteria with a linear ordering , in which implies the priority of criterion given by group .
4.2. Approach to MCGDM under Weak Probabilistic Hesitant Fuzzy Environment
Based on the previously proposed operators and distances, this subsection develops an evaluation approach to address MCGDM problems, where the criteria values are represented by weak probabilistic hesitant fuzzy decision matrices. Besides, the related weight information is missing.
Step 1. Collect the decision information given by different groups of decision makers and construct the corresponding weak probabilistic hesitant fuzzy decision matrices as .
Step 2. Apply the following functions, which are related to the PWPHFWA operator, to generate the normalized priority-based importance degrees related to different groups from the prioritized information.
Step 3. By referring to Definition 3, rank the criteria values related to different alternatives and distinctive groups, and then match the weights with the reordered criteria.
Step 4. Determine the importance weights of criteria regarding different alternatives and distinctive groups by operating the P-BUM function. That is,
where
is defined as the corresponding importance degree of the criterion, which is ranked as the
th position under a decreasing sequence.
Step 5. Employ the PWPHFOWA operator to obtain the comprehensive criteria values for different groups
with
. That is,
where
is a permutation such that
, for
.
After this manipulation, the results related to each group contain values, which represent the group assessment over alternatives.
Step 6. Taking the ease of employment and computational efficiency into consideration, we utilized the Hamming–Hausdorff distance measure to calculate the distances between one group and another one with respect to different alternatives. That is,
where
with
.
Step 7. Distinguish the distinction of one group with others with respect to different alternatives by calculating the average distance of one group to all the others with
Step 8. Compute the weights of different groups relating to different alternatives by
where
is a permutation such that
.
In some cases, there may exist the situation where a group rather prefers one alternative that their judgments may be far away from those of other groups, such that these judgments cannot be importantly weighted. Occasionally, this is common in real-life decision-making processes. In this situation, regarding one alternative, the distance value of this group to others may be very small such that the opinions of this group should not be greatly taken into consideration. Nevertheless, this disparity can be offset by the distances of this group to others in view of the other alternatives. Bearing this in mind, we consider the weights of different groups with respect to different alternatives, respectively. Therefore, the operation in this step does not allow for compensation between distances, i.e., the phenomenon that the far distance representing the poor relationship of the group to others would not reduce the ability of better relationship for compensation by poorer ones. Based on this, the weight generation process of different groups remains impartial.
Step 9. Fuse the opinions of different groups by utilizing the WPHFD-IOWA operator, i.e.,
By this step, the overall assessment for each alternative can be obtained.
Step 10. According to Definition 3, assess the alternatives by listing rankings of them.
The innovations contained in this approach are graphically described in
Figure 1.
5. Application and Results
This section concentrates on applying the evaluation approach to a practical problem concerning the assessment of sustainable drinking water source regions for a company in Singapore.
5.1. Problem Statement
Being a young company located in Singapore, Bello Group Pte. Ltd. commits to the research and development, production and sales of high-end differentiated beverages. Until now, its business has spread in various countries, such as China, Singapore, Indonesia, Malaysia, Cambodia, Vietnam, Maldives, and the United States. However, faced with the increasingly serious water pollution, how to evaluate and select sustainable drinking water source region(s) poses a challenge to the leaders in Bello. Hoping to acquire the largest benefit from this decision, the management team sincerely invites the participation and favor of the staff from the sales team and the investing party. Thus, the above analytical description forms an MCGDM problem that some drinking water source regions are required to be evaluated and a sustainable drinking water source region is further in need of determination.
To mathematically model this problem, we firstly give some mathematic notations, which are in one-to-one correspondence with the objectives as follows. Let denote three groups of selected decision makers, who are representatives of the management team , the sales team , and the investing party . After a preparatory investigation of 20 drinking water source regions, three potential regions are preliminarily selected as candidate drinking water source regions for supporting the business of Bello. The regions are Mount Meng in Linyi city (), Liangshuihe Town in Danjiangkou city () and Southern Taihang Mountains in Xinxiang city (). To ensure the sustainable development of the company, the manager team has taken into account three criteria for evaluating the regions: the effect of political factors (), the taste of water () and the effect of market factors ().
Actually, owing to respective perspectives of the three decision groups, they hold different views on the relative importance degrees of the three criteria. This subjective distinction leads to the asymmetrical priority of different criteria indirectly. Thus, the three groups respectively provide rankings of the three criteria as , and . The strength of the prioritized information lies in the fact that it reflects the status of the criterion, which is acquiesced by individual groups.
To address this MCGDM problem, the fifteen decision makers are required to furnish their subjective evaluation results of the regions with respect to different criteria by giving scores according to an evaluation standard shown in
Table 1.
By reference to
Table 1, the three groups of decision makers provide their assessments, which are collected in
Table 2.
Caused by the limited expertise of different groups, they could not offer all assessment values. This realistic phenomenon is reflected by the blanks in
Table 2.
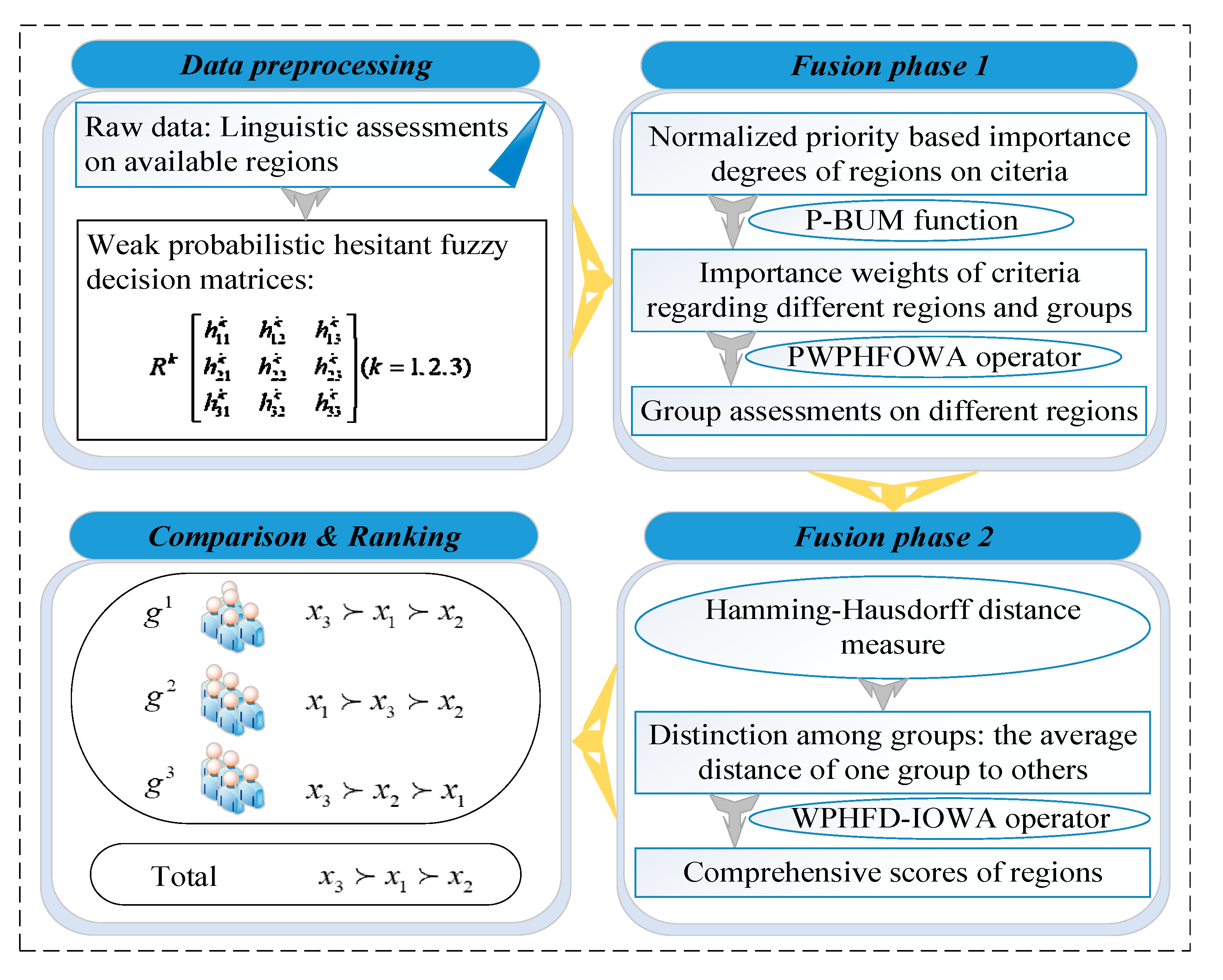
5.2. Solving Process
To deal with the realistic problem depicted in
Section 5.1, we statistically coll
ect the original decision data and express the opinions of each group with a weak probabilistic hesitant fuzzy decision matrix.
To illustrate the derivation of the three weak probabilistic hesitant fuzzy decision matrices, we take the first element in
as an example. From
Table 2, one can obtain the assessments of group
for the system on wind turbines (
) over criterion
as: 2, 2, 3, 4, 3. Through a simple normalization process, one can obtain a weak P-HFE as:
Clearly, the probabilistic information is complete. This represents the case that all the managers have provided their opinions of region
on criterion
. As to the evaluation values of group
for region
over criterion
, the cross values of the second column and the frontal five rows in
Table 2 show the results: 4, 3, 4, -, 4. This incomplete evaluation result can be expressed with:
where the sum of the probabilities is smaller than 1, indicating that not all the members in
could afford to score the performance of
over
on a scale of 1 to 5.
Aiming to fuse the distinctive opinions on different criteria, we apply Equations (18) and (19) to generate the normalized priority-based importance degrees related to different groups, as listed in
Table 3.
Clearly, the last column of
Table 3 performs the normalized priority-based importance degrees of each criterion with respect to different regions and groups.
Subsequently, by referring to Definition 3, rank the criteria values and match the weights with the reordered criteria. The results are listed below.
Based on the above presented results, employ the proposed P-BUM function to determine the importance weights of criteria regarding different alternatives and distinctive groups as:
Next, employ the PWPHFOWA operator to obtain the overall assessments from different groups as:
In the following, utilize the Hamming–Hausdorff distance measure to calculate the distances between one group and another one with respect to different alternatives by drawing support from Lingo 11.0. The distances are presented in
Table 4.
Now that the distinction of one group with another with respect to different alternatives are distinguished, the distances of one group to all the others can be generated through Equation (24):
Based on these distances, compute the weights of different groups related to different regions as:
Then, utilize the WPHFD-IOWA operator to derive the comprehensive opinions with respect to different regions as:
Herein, to be in line with the form of the original information, the values of comprehensive opinions are accurate to one decimal point.
Finally, according to Definition 3, scores and rankings of the regions are listed in
Table 5.
In conclusion, Southern Taihang Mountains in Xinxiang city should be preferentially considered as the first drinking water source region for Bello.
Clearly, the whole calculation process can be graphically described in
Figure 2.
7. Conclusions
This paper conducts a research on investigating a hybrid evaluation approach with weak P-HFEs and performs a practical example of application. The strengths of the approach lie in the following points.
(1) The processing of the original decision data brings a broader understanding of how to address realistic evaluation problems with positive and negative information, which are asymmetrically distributed.
(2) Weights of criteria are decided based on the prioritization relationship of criteria given by different decision groups. In the meanwhile, we have considered the situation that the weights of the groups related to different alternatives should be distinctive, in case of cheating during the decision process. The objective determination of weights has brought a new way of identifying the importance degree without complaints.
(3) The fusion of decision information fully considers the phenomenon of asymmetric prioritization among different criteria, as well as the distinction between individuals that existed in reality.
(4) The proposed evaluation approach can serve as an emerging method for handling MCGDM problems with prioritized criteria and incomplete weight information within weak probabilistic hesitant fuzzy circumstance. It is totally possible to employ the proposed approach to solve other similar evaluation problems.
However, there still remains some work to be done. First, the alternative sustainable DWSRs in the example are all located in China, the applicability of the proposed method to managing other similar problems [
42] remains to be further studied. Second, since the computational process of the weak P-HFEs is complicated, we need to further study the operations of weak P-HFEs. Except the above two points, the consensus between different groups should be taken into consideration. In future, we are going to conduct studies on these two aspects and devote our attention to applying the proposed approach to other fields, such as industrial engineering, E-commerce, and so on.





{kind=link}
{kind=link}