
Abstract
Sensitive parameters of a numerical weather prediction model substantially influence the model prediction. Weather research and forecasting (WRF) model parameters are assigned default values based on theoretical and experimental analysis by the scheme developers. Calibrating the sensitive parameters of the model has the potential to improve model prediction. The objective of this study is to improve the prediction of the Indian summer monsoon by calibrating the WRF model parameters. A multiobjective adaptive surrogate model-based optimization (MO-ASMO) method is used to calibrate nine sensitive parameters from five physics parameterization schemes. Normalized root-mean-square error values corresponding to four meteorological variables precipitation, surface air temperature, surface air pressure, and wind speed are minimized by calibrating the WRF model sensitive parameters for high-intensity precipitation events of the Indian summer monsoon (ISM). Twelve high-intensity four-day precipitation events of ISM during the years 2015–2017 over the monsoon core region in India are considered to calibrate the model parameters. MO-ASMO method outputs a set of nondominated solutions for the model parameters that reduce the model prediction error. A decision analysis method is used to identify the best solution among the nondominated solutions, which contains the calibrated values of the parameters. A comparison of the default and calibrated parameter values across various precipitation events, driving data, and physical processes in the monsoon core region are carried out. Eighteen high-intensity four-day precipitation events of ISM during the years 2014–2018 are chosen to validate the robustness of the calibrated parameters. The WRF model is run with two different boundary data to verify the effectiveness of the calibrated parameters against the default parameters. The model calibrated parameters obtained using the MO-ASMO method are superior to the default parameters across various precipitation events and boundary data over the monsoon core region during the Indian summer monsoon.
Similar content being viewed by others


1 Introduction
The Indian Summer Monsoon (ISM) is an essential global phenomenon that occurs due to the atmospheric response to the differential heating of land and sea (Webster et al. 1998). The erratic and irregular nature of ISM significantly affects a country based on the agrarian economy such as India (Gadgil 1996; Krishna Kumar et al. 2004). ISM Rainfall (ISMR) sets in at the beginning of June and retracts by the end of September. The months of June to September account for 80% of the annual rainfall received by India (Rajeevan et al. 2013; Turner and Annamalai 2012). The monsoon core region (MCR), which spans from 69\(^{\circ }\) E to 88\(^{\circ }\) E and 18\(^{\circ }\) N to 28\(^{\circ }\) N is a critical zone where ISMR plays a crucial role (Rajeevan et al. 2010) corresponding to the mean Indian summer monsoon and its intraseasonal variability. Apart from being a prominent contributor to the South Asian region’s water resources and food security, the ISM has a profound impact on the general circulation and global climate, as it represents a copious heat source (Rao 1976; Chen et al. 2018). Therefore, an accurate prediction of the ISMR over the monsoon core region is crucial for the management of water resources in India.
Numerical weather prediction (NWP) models are essential to provide an accurate forecast of the Indian summer monsoon. There has been a significant improvement of NWP models over the years concerning the capability to replicate large-scale systems, finer spatial and temporal resolution, more explicit dynamical methods to represent climate models, and longer forecast lead times (Dudhia 1993; Janjić 1994; Lau and Ploshay 2009; Chen et al. 2011). This improvement has been mainly due to the advances in supercomputing ability, better observation systems, advanced assimilation techniques, and better post-processing methods. Better observation systems lead to a better understanding of the underlying physical processes resulting in the development of a more accurate dynamical representation of these processes (Chen and Dudhia 2001; Gilliam and Pleim 2010; Stensrud 2009). Advanced assimilation techniques have resulted in improving the accuracy of the initial values for the NWP models, which leads to a better forecast (Kalnay 2003; Houtekamer and Zhang 2016; Bannister 2017). In recent years, parameter sensitivity and optimization of NWP model parameters are performed using potent computational techniques resulting in further enhancement in the accuracy of predictions (Di et al. 2015, 2018; Quan et al. 2016; Duan et al. 2017; Ji et al. 2018; Yang et al. 2012, 2015; Ollinaho et al. 2014).
Model calibration is a procedure in which the parameters of a model are adjusted to match the model predictions with respective observations. Optimization techniques are used to adjust the model parameters to minimize the error between the predictions and observations (Duan et al. 2006). Model calibration involves a few challenges, such as a high number of parameters, simulation of fundamental meteorological variables with adequate accuracy and computational complexity. An NWP model typically has about tens to hundreds of parameters that are present in the model equations in the form of constants or exponents. The values of the parameters vary depending on the local conditions and on the climate regimes, which makes it difficult to measure at the simulation scales. These parameters influence the meteorological variables such as atmospheric pressure, temperature, wind speed, and precipitation. In view of this, the determination of accurate values of the parameters known as model calibration is critical to improving the accuracy of the prediction. Model calibration is a complex multiobjective optimization problem that involves minimizing the error corresponding to multiple variables. An extensive amount of model runs involving a massive number of parameters, high spatial and temporal resolution, and multi-day forecast requires a tremendous computational power, which further complicates the model calibration (Duan et al. 2017).
There have been different attempts aiming to calibrate NWP models using various optimization techniques such as downhill simplex method (Avriel 2003), quasi-Newton method (Nocedal and Wright 2006), simulated annealing (Kirkpatrick et al. 1983), and genetic algorithm (Koza and Koza 1992), to name a few. NWP model parameters are generally formulated as the constant properties of the system and are huge in number. Optimizing all the model parameters to calibrate the NWP model is a cumbersome procedure, as it requires advanced optimization algorithms and substantial computational power. Several studies (Di et al. 2015; Quan et al. 2016; Ji et al. 2018) attempted to bring down this number of parameters from a high number to a feasible number by identifying the parameters that greatly influence the forecast using sensitivity analysis methods. Duan et al. (2017) and Di et al. (2018) implemented the adaptive surrogate model-based optimization (ASMO) method (Wang et al. 2014) to adjust the WRF model parameters for reducing the precipitation error in the Greater Beijing area by minimizing a single objective function. Gong et al. (2016) used a multiobjective adaptive surrogate model-based optimization (MO-ASMO) method to estimate the parameters of a land surface model.
The objective of this study is to perform WRF model calibration to improve the simulation of high-intensity precipitation events during the Indian summer monsoon using the MO-ASMO method. The model parameters used in this study are obtained from a previous study where the Morris one-at-a-time method, a global sensitivity analysis method, is used first to identify the parameters that profoundly influence the meteorological variables (Chinta et al. 2020). The values of these parameters are tuned to minimize the model error using the MO-ASMO method. The meteorological variables precipitation, surface air temperature, surface air pressure, and wind speed in the monsoon core region (MCR) are used to estimate the model error in this study. Twelve high-intensity precipitation events over MCR during the ISM are used to calibrate the WRF model in this study. In the MO-ASMO method, a surrogate model is constructed to substitute the actual NWP model for improving the speed of convergence. In this study, four surrogate models are constructed to minimize the error concerning precipitation, surface air temperature, surface air pressure, and wind speed. Therefore, four sets of parameters are obtained for minimizing the above meteorological variables individually using their respective surrogate models. A multiobjective approach is then followed to obtain the optimal model parameters which minimize the model forecast error in terms of all the above variables combined with the help of the four surrogate models from the previous step. The multiobjective approach gives a group of solutions, out of which the best solution is chosen using a decision analysis method.
Therefore, a total of five sets of optimal parameters are obtained, out of which four sets of optimal parameters minimize the errors from individual variables, and the fifth set of optimal parameters minimizes the model error in terms of all the above variables combined. This fifth set of parameters is referred to as the calibration set. There exists a need to verify the robustness of all the five sets of optimal parameters obtained from model calibration by verifying with other high-intensity precipitation events during ISM. Eighteen high-intensity precipitation events during ISM, which do not coincide with the calibration events, are selected to validate the robustness of the optimal parameters obtained from the model calibration.
This structure of this paper is as follows. Section 2 gives a brief description of the methodology implemented in this study. Section 3 gives details regarding the WRF model configuration, parameters, physics schemes, events simulated, and experimental design. Section 4 lists out the crucial results and inferences obtained from model calibration and validation. Section 5 presents the conclusions from this study.
2 Methodology
Multiobjective adaptive surrogate model-based optimization (MO-ASMO) method is useful to calibrate the parameters of a large complex dynamical model such as the WRF model by utilizing lesser computational cost, but still maintaining the effectiveness of the optimization. This method requires the usage of surrogate models, which act as a proxy to the actual physical model during the optimization procedure resulting in a substantial reduction of the time needed for optimization. Nondominated solutions are the solutions for which the improvement of one objective function value leads to a deterioration of some of the other objective function values. Multiobjective optimization provides a surface containing a set of nondominated solutions, which is called the Pareto front. A multiple-criteria decision analysis method is used in this study, which determines the best solution among all the nondominated solutions in the Pareto front obtained from the MO-ASMO method. Figure 1 presents a flowchart depicting the methodology implemented in this study.

Flowchart of the methodology adopted in this study. The algorithm used in each step is provided in the brackets below that step
To construct a robust surrogate model, ample input and output data from an actual physical model is necessary. Therefore, the actual model is run for a sufficient number of times, involving different sets of parameter values from the specified ranges. The sets of parameter values to run the actual model are determined using a proper sampling method, which uniformly distributes the samples over the specified ranges. Sampling methods such as Latin hypercube (McKay et al. 1979) and Quasi-Monte Carlo (Sobol’ 1967; Halton 1964) are most appropriate for ASMO because of their ability to span the whole sample space with relatively few sampling points, and flexible sample sizes (Wang et al. 2014). Latin hypercube sampling (LHS) used in this study is a statistical method for generating a near-random distribution of sample sets of parameter values from a multidimensional distribution. The parameter sample sets generated from LHS are used to run the actual physical model, and the output data obtained thereof is used to train the surrogate model along with the initial data that is used to run the model.
A surrogate model is constructed using statistical regression to represent the response surface of the actual physical model. Several algorithms, such as Gaussian process regression (Williams and Rasmussen 1996), artificial neural networks (Svozil et al. 1997), support vector machines (Scholkopf and Smola 2001), random forest (Breiman 2001), and multivariate adaptive regression splines (Friedman et al. 1991) can be used to construct a surrogate model. Gaussian process regression (GPR) and artificial neural networks (ANN) have performed better than the other algorithms as a surrogate model in the ASMO method (Gong et al. 2015). The surrogate models used in this study are constructed using GPR. GPR is an interpolating regression method that uses basis functions with tuned parameters to represent the original model that returns the output values for a given set of inputs within a fraction of the time needed for the actual physical model. The hyperparameters from GPR are optimized using an adaptive sampling method. It reduces the number of simulations of the actual model by searching the region containing the optimal solution by using information from previous iterations to drive the next sample datasets. Algorithms like genetic algorithm (Schmitt 2001) and shuffled complex evolution (Duan et al. 1993) can be used for adaptive sampling in the ASMO method. The genetic algorithm (GA) used in this study is an adaptive heuristic search algorithm, which intelligently exploits random search by utilizing the information from previous iteration data to direct the search towards the optimum in the solution space. The new sampling points obtained from GA are used to run the actual model, and the existing surrogate model is updated.
Nondominated sorting genetic algorithm II (NSGA-II) formulated by Deb et al. (2002) is used in this study as the multiobjective optimization algorithm on the surrogate models from the preceding step. NSGA-II outputs a Pareto front containing nondominated optimal solutions. Some of the solutions (25%) from the Pareto front with high crowding distance values are selected to run the actual physical model, and the data obtained is used to update the surrogate model. This step is repeated until convergence, i.e., when it reaches the iteration limit or the number of actual model run limit. The final Pareto front obtained from NSGA-II usually contains hundreds of solutions. It is a daunting task and often impractical to run the actual physical model for that many times in an ensemble mode (Gong et al. 2015). So, there exists a need to rank the solutions from the Pareto front to identify the best solution. Therefore, a multiple-criteria decision analysis method called the Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS) is used in this study. All the objectives are given weights accordingly, and the objective function values are multiplied with these weights. The positive and negative ideal solutions are identified from these values. In the TOPSIS method (Hwang et al. 1993), the final solution should have the shortest Euclidean distance from the positive ideal solution and the longest Euclidean distance from the negative ideal solution. The final solution obtained from the TOPSIS method contains the calibrated parameter values for the actual physical model.
3 Design of experiments
3.1 Model configuration and parameters used for calibration
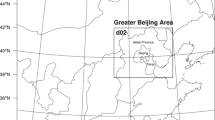
The model calibrated in this study is the Advanced Research WRF (WRF-ARW) model version 3.7.1 developed by the National Centre for Atmospheric Research (NCAR) and is a non-hydrostatic compressible mesoscale numerical weather prediction system. Figure S1 shows the domains of the two-grid nested model used in this study. The outer domain d01 encloses the Indian Subcontinent and the regions surrounding it, and the inner nested domain d02 encloses the Indian monsoon core region. The outer domain (d01) is composed of 188 points in the zonal direction and 213 points in the meridional direction with a spatial resolution of 36 km. The inner domain (d02) is composed of 262 points in the zonal direction and 181 points in the meridional direction with a spatial resolution of 12 km. The time-step for integration is 120 s and 40 s for the domains d01 and d02, respectively. With a higher resolution in the boundary layer, the vertical profile is partitioned into 40 sigma (\(\sigma\)) layers from the land surface up to 50 hPa level in the atmosphere. The six-hourly NCEP FNL (National Center for Environmental Prediction Final) Operational Global Analysis data at \(1^{\circ }\times 1^{\circ }\) resolution provided the initial and boundary conditions for the WRF model.
The physical processes represented in WRF are near-surface physics, cumulus convection, microphysics, short-wave and long-wave radiative transfer, land-surface physics, and planetary boundary layer physics. A great variety of parameterization schemes are available for each physical process. Many adjustable parameters are present in each parameterization scheme. Ratnam et al. (2017) performed a sensitivity study of physical parameterization schemes concerning the Indian summer monsoon and proposed the best set of schemes. The microphysics scheme alone was chosen differently from that set, as the WSM6 scheme represents more categories of hydrometeors compared to the WSM3 scheme. Table 1 presents an overview of the schemes used in this study.
A sensitivity study of chosen 23 tunable parameters from the physics parameterization schemes in Table 1 for the high-intensity precipitation events of ISM was performed in a previous study (Chinta et al. 2020). For calibrating the WRF model, nine parameters are selected that profoundly influence model output variables. Table 2 presents the list of parameters, their allowable ranges, and a brief description.
3.2 Observation datasets and events simulated
The output variables from WRF model simulations are validated with the observed data to verify the accuracy of the simulations. The precipitation (RAIN) data given by the Global Precipitation Measurement (GPM) Integrated Multi-satellitE Retrievals for GPM (IMERG) is used in this study. IMERG daily accumulated precipitation data at \(0.1^{\circ }\times 0.1^{\circ }\) resolution is used to validate the rainfall data and ERA-Interim reanalysis data at \(0.125^{\circ }\times 0.125^{\circ }\) resolution is used to validate surface air pressure (SAP), surface air temperature (SAT), and wind speed at 10 m (WS10).

Daily regional average precipitation in the monsoon core region during ISM for the years 2015–2017. Solid line boxes show the events that are used for model calibration
The focus of this study is on the high-intensity rainfall instances during the Indian summer monsoon (ISM). Accordingly, 12 four-day precipitation events over June, July, August, and September are chosen for the calibration study as shown in Fig. 2. Each event contains the day with the highest rainfall in the monsoon core region in their respective month according to the IMERG data. For events (A), (B), (C), and (D) the simulation dates are from 21st June to 24th June, 25th July to 28th July, 2nd August to 5th August, and 18th September to 21st September in the year 2015 respectively. For events (E), (F), (G), and (H) the simulation dates are from 23rd June to 26th June, 1st July to 4th July, 30th July to 2nd August, and 15th September to th September in the year 2016 respectively. For events (I), (J), (K), and (L) the simulation dates are from 26th June to 29th June, 19th July to 22nd July, 27th August to 30th August, and 16th September to 19th September in the year 2017 respectively. Apart from the 12 events used for calibration, another 18 high-intensity precipitation events spread over the years 2014–2018 are chosen to validate the parameter values obtained from the calibration study.
3.3 Experimental setup
The MO-ASMO method, along with TOPSIS, is used to calibrate the nine sensitive parameters in this study. Many algorithms used in this study, such as the Latin hypercube sampling (sampling method), the Gaussian process regression (surrogate model), genetic algorithm (adaptive sampling method), and NSGA-II (multiobjective optimization method) are available as functions in MATLAB (2018). First, an initial sample set of the parameters is generated based on their allowable ranges using the LHS method. The parameters are assumed to follow a uniform distribution during sampling as their distribution is unknown. Wang et al. (2014) proposed that 15–20 times the number of parameters would be a proper initial sample set. Considering that nine parameters are calibrated in this study, the initial sample size is chosen to be 180. The initial sample set consists of 180 samples, and each sample has nine parameter values. The initial sample set is used to run the WRF model 180 times for all the calibration events shown in Fig. 2 and the model output is compared against the observation data to evaluate the root-mean-square error (RMSE) from the simulation. Meteorological variables precipitation, surface air temperature, wind speed at 10 m, and surface air pressure are compared against the observation data to evaluate the RMSE.
where \(sim_i^t\) and \(obs_i^t\) are the simulated and observed values of a variable at grid point i and time t, respectively. N is the total number of grid points of domain d02 in the MCR, and T is the number of days of the simulation. Apart from this 180 sample set, the WRF model is also run for the default values of the 9 parameters, as shown in Table 2, and the RMSE is evaluated. A normalized RMSE (NRMSE) value is for all the 180 samples in the initial sample set is calculated using the RMSE value from the default run.
where \(RMSE_{i}\) is the RMSE of the particular sample and \(RMSE_{def}\) is the RMSE obtained from the default parameter run.
A dataset with 180 samples containing nine parameter values as input and 4 NRMSE values as output is obtained to construct the surrogate model. Four surrogate models using GPR are constructed to output the values of NRMSE corresponding to the four meteorological variables RAIN, SAT, WS10, and SAP when the surrogate model is input with the values of 9 parameters. Therefore, each surrogate model has nine inputs corresponding to the nine parameters and one output corresponding to the NRMSE of the meteorological variable. An adaptive sampling algorithm (GA) is employed to make the surrogate models more robust. GA finds the set of parameters that minimizes the value of NRMSE of that particular surrogate model. The set of parameters obtained from GA is used to run the WRF model, and the output is used to train the existing surrogate model further. This loop is carried out till convergence. The loop is terminated when the NRMSE value does not decrease for ten iterations.
The simulation error corresponding to the four meteorological variables precipitation, surface air temperature, surface air pressure, and wind speed at 10 m has to be minimized to calibrate the WRF model. NSGA-II is used to solve this multiobjective optimization problem with the help of surrogate models constructed with the procedure mentioned above. The population size of NSGA-II used in this study is 200. The convergence of the NSGA-II algorithm outputs a matrix containing 80 solutions. 20 (25% of 80) solutions with the largest crowding distances are chosen to run the actual model. The WRF model output is used to update the surrogate models further. A total of 5 iterations (20 \(\times\) 5 = 100 actual model runs) of NSGA-II is performed in this study. The final output matrix of NSGA-II contains the nondominated solutions on the Pareto front. TOPSIS is a decision analysis method that can handle multiple criteria to come up with the best solution. This method evaluates a group of alternate solutions by assigning weights for each criterion and calculating the Euclidean distances from the positive ideal solution and the negative ideal solution. In this study, all four criteria, i.e., minimizing the NRMSE values for the four meteorological variables RAIN, SAT, WS10, and SAP, are assigned equal weights. The best solution is selected such that it has the longest distance from the negative ideal solution and the shortest distance from the positive ideal solution. The best solution contains the final model calibrated parameter values that minimize the model simulation error.
Threat score (TS) is a probabilistic forecast skill score the is used to evaluate the precipitation forecast accuracy. Table 3 presents the thresholds of daily accumulated precipitation to evaluate the threat score values for different categories of precipitation.
where FO is the number of grid cells in which the observed and simulated precipitation are in the prescribed range. XO is the number of grid cells in which the observed precipitation is in the prescribed range, whereas the simulated precipitation is not. FX is the number of grid cells in which the simulated precipitation is in the prescribed range, whereas the observed precipitation is not. Daily accumulated precipitation data is compared against the observed data to evaluate the TS, which ranges between 0 and 1. A TS value of 1 indicates a perfect forecast.
Another quantity to verify the quantitative precipitation forecast concerning different aspects is the structure (S), amplitude (A), and location (L) score—SAL score formulated by Wernli et al. (2008). Amplitude value indicates the domain averaged relative departure from the observed data. The structure (S) value indicates the difference between simulated and observed values using the ratio of total precipitation to the maximum precipitation. It gives information regarding the shape and size of the precipitation field. If the amplitude (A) value is positive, it implies an overestimation, whereas if the amplitude value is negative, it implies an underestimation of the total precipitation. Location (L) value gives the normalized distance from the center of mass of the simulated field corresponding to the observed precipitation field. It also gives the error in the normalized distance of the precipitation fields from the center of mass of the whole field. The results from the simulation are better if the values of S, A, and L are closer to zero.
4 Results and discussion
4.1 Results from model calibration
4.1.1 Convergence trend and final NRMSE values
After running the WRF model with the values of parameters obtained from the LHS method, NRMSE values of the four meteorological variables RAIN, SAP, WS10, and SAP are calculated using the default values. The initial values of NRMSE after training the model with 180 samples are 0.8884 (RAIN), 0.9642 (SAT), 0.8215 (WS10), and 0.9968 (SAP). Adaptive sampling is used to generate new samples to run the WRF model for further training of the surrogate models constructed using GPR. The convergence trend for each variable is presented in Figure S2.
The loop converges when the NRMSE value does not decrease further for ten iterations, as defined in Sect. 3.3. The number of iterations required for convergence of each variable loop is 26 (RAIN), 23 (SAT), 18 (WS10), and 32 (SAP) for the surrogate models constructed using GPR. The final minimum value of NRMSE for each variable is shown in Table 4. A substantial drop in the RMSE values is observed compared to the default parameters for all the variables, where RAIN (16.90%) and WS10 (21.37%) have shown the highest reduction in the RMSE values. Four individual sets of parameters are obtained for four meteorological variables precipitation (RAIN_min), surface air temperature (SAT_min), surface air pressure (SAP_min), and wind speed at 10 m (WS10_min) that minimize the NRMSE value for that particular variable. Surrogate models are also constructed using ANN, and the number of iterations required for convergence of each variable loop is 35 (RAIN), 48 (SAT), 25 (WS10), and 38 (SAP). The convergence trend of the surrogate models constructed using ANN is presented in Figure S3. As the surrogate models constructed using GPR required a lesser number of iterations for the convergence, those models are used for the multiobjective optimization.
Multiobjective optimization is used to minimize the NRMSE values corresponding to the four variables. A set of nondominated solutions is obtained after five iterations of NSGA-II, out of which the best solution is chosen using the TOPSIS method. As the initial sample set contained 180 samples, a total of 379 (180 + 26 + 23 + 18 + 32 + 100) actual model runs are performed to obtain the final solution. The NRMSE values obtained from the calibrated parameters are shown in Table 4. A slight deviation from the minimum NRMSE values is noticed compared to the calibration NRMSE values. The RMSE value of SAP from the calibration parameters is observed to be slightly (\(\sim\) 0.44%) higher than the RMSE value with default parameters. However, all the other variables show a substantial drop in RMSE compared to the RMSE values with default parameters. Instead of choosing equal weights for all the objectives in the TOPSIS method, choosing a higher weight for minimizing the NRMSE value of SAP would lead to a solution with better NRMSE value for SAP during calibration. However, that still means a compromise on other objectives, as the weights for those objectives would reduce.
There are a few nondominated solutions from the multiobjective optimization that have all the values of RMSE less than the RMSE values with default parameters. However, the improvement of RMSE value in variables other than SAP is minimal for those solutions. This aspect could be attributed to the structural inadequacy of the model, in which an improvement obtained for one objective by parameter calibration results in the reduction of model performance for other objectives. A model bias that exists even after the calibration of parameter values confirms the presence of structural errors in the model (Williamson et al. 2015). A structural error of this kind can occur when different model components are unrealistically linked, and their relationships are structurally fixed, hardcoded, or only weakly sensitive to parameter perturbations. Nevertheless, each of these components individually could have a strong sensitivity and has the potential to be optimized (Yang et al. 2019).
4.1.2 Comparison of RMSE values with default parameters
RMSE values of the WRF model variables using default parameters and the parameters that give minimum NRMSE value are compared for different calibration events (A–L) over the MCR and presented in Fig. 3. These results show a general trend that there is a substantial improvement in the RMSE values compared to the values with default parameters. There are a few events where the RMSE values for some variables have slightly increased compared to the default case. However, an overall trend suggests that the sets of parameters for different variables performed well for all the events combined. The reduction in RMSE values is higher for RAIN (16.90%), and WS10 (21.37%), whereas the reduction in RMSE values is slightly lower for SAT (6.08%) and SAP (0.50%). These results show that these parameter values that give minimum NRMSE value for a particular variable are consistent over several rainfall events over the monsoon core region during the ISM.

Comparison of RMSE values of the WRF model variables using default parameters and parameters that give minimum NRMSE value for that variable, when compared with the observed data for different calibration events over the MCR: a precipitation, b surface air temperature, c wind speed at 10 m, d surface air pressure. The percentage value above the bars indicate the reduction in RMSE values compared to the default parameters

Comparison of RMSE values of the WRF model variables using default parameters and calibrated parameter values, when compared with the observed data for different calibration events over the MCR: a precipitation, b surface air temperature, c wind speed at 10 m, d surface air pressure
RMSE values of the WRF model variables using the default and calibrated parameters are compared for different calibration events (A–L) over the MCR and presented in Fig. 4. These results show a general trend that there is a substantial improvement in the RMSE values compared to the values with default parameters except for the case of SAP. The RMSE values for calibrated parameters have reduced for RAIN (15.69%), WS10 (17.24%), and SAT (3.35%), whereas the RMSE value has slightly increased in the case of SAP (− 0.44%), when compared to the default case. Except for SAP, where the RMSE values are slightly higher for most of the events compared to the default case, all the other variables have better RMSE values for all the events. These results show that the calibrated parameter values are consistent over multiple rainfall events over the monsoon core region during the ISM.
4.1.3 Impact of calibrated parameters on spatial patterns
The spatial patterns of the daily average of the variables RAIN, SAT, WS10, and SAP for different calibration events over the monsoon core region using the default and calibrated parameters are compared against the observed data and are shown in Figures S4–S7 respectively. Figure S4a represents the observed precipitation data averaged over 48 days (12 calibration events), and Figure S4b, c represent the spatial patterns obtained using the default and calibrated parameters, respectively. Figure S4d, e represent the spatial patterns of the bias obtained using the default and calibrated parameters, respectively. The observed data shows a heavy rainfall over the west coast of Maharashtra, whereas the default parameters failed to capture that. The calibrated parameters have predicted the heavy rainfall slightly better compared to the default parameters, as also seen in the spatial patterns of the bias. Overall, the calibrated parameters have predicted the spatial pattern of precipitation better than the default parameters.
Figure S5 presents the spatial patterns of the SAT. The calibrated parameters improved the spatial pattern of the SAT over the northern part of the domain and also over the coast of Odisha compared to the default parameters. Figure S6 presents the spatial patterns of WS10. The calibrated parameters substantially improved the spatial pattern of WS10 all over the domain compared to the default parameters. Figure S7 presents the spatial patterns of SAP. The spatial patterns of SAP of the default and calibrated parameters are very similar, and the improvement from the calibrated parameters for SAP is insignificant. The spatial patterns of different variables justify the percentage of improvement of RMSE values obtained for that particular variable.
4.1.4 Impact of calibrated parameters on other variables
To verify the effectiveness of the calibration parameters, variables other than those used for model calibration is needed. Therefore relative humidity at 2 m is evaluated using the default and calibrated parameters for different calibration events over the MCR in Fig. 5. RMSE values for the calibrated parameters have dropped significantly for all the events, when compared to the default parameters. The reduction in RMSE when all the calibration events are considered together is 24.65%, which indicates that the calibrated parameters are robust compared to the default parameters.

Comparison of Relative humidity at 2 m values using default parameters and calibrated parameter values for different calibration events over the MCR

Comparison of Threat score values for different precipitation simulations using default parameters and calibrated parameter values for different calibration events over the MCR: a light rain, b moderate rain, c heavy rain. The percentage value above the bars indicate the improvement in TS values compared to the default parameters
Threat score (TS) values are evaluated to verify the robustness of calibrated parameters for the precipitation prediction. Figure 6 presents the comparison of TS values for different precipitation simulations using the default and calibrated parameters for various calibration events over the MCR. The calibration TS values for the light rain category have decreased slightly (− 1.94%) from the default values for most of the calibration events. In contrast, calibration TS values have improved for moderate rain (12.28%) and heavy rain (16.92%) categories significantly compared to the default case. Overall, the calibrated parameters have improved the threat score values compared to the default parameters.
Since there is a slight reduction in the calibration TS values for the light rain event, SAL scores for precipitation are also examined for the calibration and default cases to check the robustness of calibration parameters for all the calibration events combined and are shown in Fig. 7. The negative value of S indicates that the simulated precipitation objects are small compared to those of the observed precipitation. Structure (S) score for the calibration parameters (− 0.132) is closer to zero compared to the default parameters (− 0.612), which implies that the calibration parameters have captured the structure of precipitation better than the default parameters. The negative value of amplitude (A) score indicates the domain averaged simulated precipitation is less than that of the observed precipitation. Domain averaged precipitation for all the calibration events is seen to be of 12.97 mm/day from observations, whereas the values are 10.77 mm/day and 11.89 mm/day for the default and calibrated parameters respectively. Therefore the calibrated parameters (A = − 0.097) captured the amplitude of precipitation better than the default parameters (A = − 0.185). Location (L) scores for the calibrated (0.071) and default parameters (0.59) show that the calibrated parameters accurately captured the location of precipitation compared to the default parameters. All the scores concerning S, A, and L for calibration parameters are closer to zero compared to the default case, which indicates the superiority of the calibrated parameters over the default parameters for the calibration events.

Comparison of structure (S), amplitude (A), and location (L) of precipitation simulations using default parameters and calibrated parameter values for different calibration events over the MCR

Daily regional average precipitation in the monsoon core region during ISM for the years 2014–2018. Solid line boxes show the events that are used for model calibration whereas the dashed line boxes show the events that are used for validation
The model calibrated parameters have performed well for the twelve calibration events. There exists a need to verify the potency of the calibrated parameters for other precipitation events.
4.2 Impact of calibrated parameters on other precipitation events
4.2.1 Comparison of RMSE values with default parameters
Eighteen high-intensity precipitation events are selected during the ISM for the years 2014–2018 to validate the robustness of the calibrated parameters for events other than the calibration events. The events are shown in Fig. 8 and are referred to as validation events. RMSE values of the WRF model variables using default parameters and the parameters that give minimum NRMSE value are compared for different validation events (a–r) over the MCR and presented in Fig. 9. These results show a general trend that there is a substantial improvement in the RMSE values compared to the values with default parameters. There are a few events where the RMSE values for RAIN have slightly increased compared to the default case. However, an overall trend suggests that the sets of parameters for different variables performed well for all the events combined. The reduction in RMSE values is higher for WS10 (17.21%), RAIN (5.71%), and SAT (4.00%), whereas the reduction in RMSE values is slightly lower for SAP (0.49%). There is a small reduction in percentage improvement of RMSE values for validation events compared to the calibration events. Overall results suggest that these parameter values that give minimum NRMSE value for a particular variable are consistent over several rainfall events over the monsoon core region during the ISM.

Comparison of RMSE values of the WRF model variables using default parameters and parameters that give minimum NRMSE value for that variable, when compared with the observed data for different validation events over the MCR: a precipitation, b surface air temperature, c wind speed at 10 m, d surface air pressure

Comparison of RMSE values of the WRF model variables using default parameters and calibrated parameter values, when compared with the observed data for different validation events over the MCR: a precipitation, b surface air temperature, c wind speed at 10 m, d surface air pressure

Comparison of relative humidity at 2 m values using default parameters and calibrated parameter values for different validation events over the MCR

Comparison of threat score values for different precipitation simulations using default parameters and calibrated parameter values for different validation events over the MCR: a light rain, b moderate rain, c heavy rain
RMSE values of the WRF model variables using the default and calibrated parameters are compared for different validation events (a–r) over the MCR and presented in Fig. 10. These results show a general trend that there is a considerable improvement in the RMSE values compared to the values with default parameters except for the case of SAP, similar to the calibration events. The RMSE values for calibrated parameters have reduced for RAIN (7.16%), WS10 (18.93%), and SAT (3.67%), whereas the RMSE value in RMSE value has slightly increased in the case of SAP (− 0.47%), when compared to the default case. Except for SAP, where the RMSE values are slightly higher for most of the events compared to the default case, all the other variables have better RMSE values for all the events. These results show that the calibrated parameter values are consistent over several rainfall events over the monsoon core region during the ISM.
4.2.2 Impact of calibrated parameters on other variables
Relative humidity at 2 m is evaluated using the default and calibrated parameters for different validation events over the MCR in Fig. 11. RMSE values for the calibrated parameters have dropped significantly for all the events, when compared to the default parameters. The reduction in RMSE when all the calibration events are considered together is 18.47%, which indicates that the calibrated parameters are robust compared to the default parameters.

Comparison of structure (S), amplitude (A), and location (L) of precipitation simulations using default parameters and calibrated parameter values for different validation events over the MCR

Comparison of RMSE values of the WRF model variables using default parameters and parameters that give minimum NRMSE value for that variable, when compared with the observed data for different calibration events over the MCR with ERA-interim reanalysis data as the boundary conditions: a precipitation, b surface air temperature, c wind speed at 10 m, d surface air pressure
Threat score (TS) values are evaluated to verify the robustness of calibrated parameters for the precipitation prediction for different precipitation simulations using default parameters and calibrated parameter values for different validation events over the MCR in Fig. 12. The calibration TS values for the light rain category have reduced slightly (− 1.12%) from the default values for most of the calibration events, whereas calibration TS values have improved for moderate rain (10.83%) and heavy rain (3.45%) categories significantly compared to the default case.
Since there is a slight reduction in the calibration TS values for the light rain, similar to the calibration events, SAL scores for precipitation are also examined for the calibration and default cases to check the robustness of calibration parameters for all the validation events combines and are shown in Fig. 13. Structure (S) score for the calibration parameters (− 0.550) is closer to zero compared to the default parameters (− 0.634), which implies that the calibration parameters have captured the structure of precipitation better than the default parameters. Domain averaged precipitation for all the calibration events is seen to be of 12.69 mm/day from observations, whereas the values are 10.46 mm/day and 10.94 mm/day for the default and calibrated parameters respectively. Therefore the calibrated parameters (A = − 0.146) captured the amplitude of precipitation better than the default parameters (A = − 0.193). Location (L) scores for the calibrated (0.165) and default parameters (0.208) show that the calibrated parameters accurately captured the location of precipitation compared to the default parameters. All the scores concerning S, A, and L for calibration parameters are closer to zero compared to the default case, which indicates the superiority of the calibrated parameters over the default parameters for the validation events.

Comparison of RMSE values of the WRF model variables using default parameters and calibrated parameter values, when compared with the observed data for different calibration events over the MCR with ERA-interim reanalysis data as the boundary conditions: a precipitation, b surface air temperature, c wind speed at 10 m, d surface air pressure
The model calibrated parameters have performed well for both the calibration and validation events. There exists a need to verify the potency of the calibrated parameters for different driving data.
4.3 Results from different driving data
As the model parameters are calibrated using only NCEP-FNL data as the driving data for the WRF model, the parameters are verified with different driving data for the WRF model to verify the sensitivity concerning the driving data. ERA-Interim Reanalysis data is used to drive the WRF model for the calibrated parameter values for the calibration events. RMSE values of the WRF model variables using default parameters and the parameters using ERAI driving data that give minimum NRMSE value are compared for different calibration events (A–L) over the MCR and presented in Fig. 14. These results show a general trend that there is a substantial improvement in the RMSE values compared to the values with default parameters. There are a few events where the RMSE values for RAIN have slightly increased compared to the default case. However, an overall trend suggests that the sets of parameters for different variables performed well for all the events combined. The reduction in RMSE values is higher for RAIN (17.27%), WS10 (17.36%), and SAT (16.48%), whereas there is no significant reduction in RMSE value for SAP (0.59%).

Comparison of normalized values of parameters for different sets
RMSE values of the WRF model variables using the default and calibrated parameters using ERAI driving data are compared for different calibration events (A–L) over the MCR and presented in Fig. 15. These results show a general trend that there is a considerable improvement in the RMSE values compared to the values with default parameters except for the case of SAP, similar to the NCEP-FNL driving data. The RMSE values for calibrated parameters have reduced for RAIN (15.36%), WS10 (16.56%), and SAT (4.41%), whereas the RMSE value in RMSE value has increased slightly in the case of SAP (− 0.38%), when compared to the default case. Except for SAP, where the RMSE values are slightly higher for most of the events compared to the default case, all the other variables have better RMSE values for all the events. These results show that the calibrated parameter values are consistent over several rainfall events over the monsoon core region during the ISM and are insensitive to the dataset driving the WRF model.
4.4 Evaluation of calibrated parameters with IMD gridded data
There exists a need to evaluate the calibrated parameters using the gridded data provided by the India Meteorological Department (IMD). The calibrated parameters obtained in this study are evaluated using the precipitation (Pai et al. 2014) and 2 m air temperature (Srivastava et al. 2009) datasets of the IMD. These gridded datasets are developed using the observation data obtained from various weather stations across India. The IMD precipitation data is at a resolution of \(0.25^{\circ } \times 0.25^{\circ }\) and the 2 m air temperature data is at \(1^{\circ } \times 1^{\circ }\) resolution. The evaluation results are presented in Fig. S8 in the supplementary information file.
The results show a general trend that there is a substantial improvement in the RMSE values compared to the values with default parameters when validated against the IMD gridded daily observed data for different calibration events over the MCR. The RMSE values for calibrated parameters have substantially reduced for precipitation (13.21%) and slightly reduced for temperature (1.56%). Therefore, the robustness of the calibrated parameters is verified, when compared against the actual observation data.
4.5 Final values of the parameters
The normalized parameter values of different sets and the default values are presented in Fig. 16. It is tough to establish a straightforward relationship connecting the calibrated parameter values and the simulated model variables because of the extremely non-linear interactions involved between numerous physical processes such as transport of water vapor, turbulent interactions of water and heat fluxes between the atmosphere and land surface, and horizontal advection of mass, momentum, and energy. Therefore, the difference in the default and the calibrated parameter values is difficult to explain. The parameters P3, P4, P5, and P6 strongly influence the convection intensity. P3 is the multiplier for the downdraft mass flux rate. A higher value of P3 results in more downdraft leading to an increase in the evaporation from condensed water and, eventually, less precipitation. P4 is the multiplier for the entrainment mass flux rate. A higher value of P4 leads to an increase in the entrainment rate, resulting in a dilution of the moist convective core and suppressing the updraft mass flux, thereby, less convective precipitation. P5 is the starting height of the downdraft over the updraft source layer (USL). A higher value of P5 results in the initiation of downdraft at a higher level leading to a narrow and tall downdraft, thereby limiting the growth of convective precipitation. P6 is the mean consumption time of convective available potential energy (CAPE). This value indicates the convective time after which the CAPE is removed from the system, thereby influencing the amount of precipitation.
P8 is the scaling factor applied to the fall velocity of ice. This value controls the terminal velocity of the descending ice crystals, which impacts cloud formation. A higher value of P8 leads to an increase in the conversion of cloud ice to rainwater resulting in high precipitation. P12 is the scattering tuning parameter that influences scattering in the clear sky. A higher value of P12 leads to an increase in the scattering of solar radiation, resulting in a lesser amount of radiation reaching the ground. This results in less heating, lower temperatures, and less precipitation. P16 is the multiplier for the saturated soil water content. A higher value of P16 results in higher evaporation of water vapor from the soil leading to an increase in precipitation. P18 is the multiplier for Clapp and Hornberger ‘b’ parameter. A higher value of P18 increases the surface evapotranspiration by improving the transport of water and heat in the soil, resulting in higher precipitation. P20 is the critical Richardson number for the boundary layer of land. A higher value of P20 results in an increase in the heat and momentum diffusivity leading to a higher temperature. Since all the parameters have a highly non-linear correlation with the model output variables, it becomes incredibly strenuous to explain the calibrated parameter values. Nevertheless, the calibration parameters obtained in this study have performed quite well for all the output variables over 30 rainfall events over the monsoon core region during the Indian summer monsoon.
5 Conclusions
Calibration of the WRF model parameters was performed using a multiobjective adaptive surrogate model-based optimization (MO-ASMO) method for high-intensity rainfall events during the Indian summer monsoon. Nine sensitive model parameters were calibrated to reduce the model prediction error concerning four meteorological variables precipitation, surface air temperature, wind speed at 10 m, and surface air pressure. The WRF model was run using the initial data provided by the Latin hypercube sampling for the calibration events, and the root-mean-square errors for the four variables were evaluated using the observation data. Four surrogate models were constructed using the Gaussian process regression (GPR), and the surrogate models were trained with the input data from LHS and normalized root-mean-square error values from the WRF model for the individual variables. NSGA-II algorithm was used as a multiobjective optimization algorithm to minimize the model prediction error by using the surrogate model parameters, and a Pareto front containing nondominated solutions was obtained. TOPSIS method was used to obtain the best solution among the nondominated solutions. Five sets of parameters were obtained from this study, out of which four parameter sets minimize the NRMSE values for the individual variables. However, the calibration set of parameters optimizes all the variables together.
A remarkable reduction concerning the RMSE values was observed with the calibrated parameters compared to the default parameters for the calibration events. Other variables and quantities such as relative humidity at 2 m, threat score, and SAL score that were not used in the model calibration procedure were observed to have improved with the calibration parameters. All the parameter sets were validated for a different set of events by evaluating the RMSE and TS values to corroborate the robustness of the calibrated parameters. A sensitivity study concerning the driving data was carried out to check the robustness of the model calibrated parameters. The calibrated parameters obtained in this study were potent and were found to be robust across various precipitation events, driving data, and physical processes. Only four meteorological variables were used to reduce the model prediction error in this study. Other variables, such as relative humidity at 2 m, surface shortwave radiation, etc. can also be used following a similar approach used in this study to reduce the model prediction error. The calibrated values of the parameters change with region and type of climatic conditions existing in that region. A sensitivity study is required initially to identify the sensitive parameters that greatly influence the model output, and the sensitive parameters thus obtained can be used for calibration. Multiobjective adaptive surrogate model-based optimization method, coupled with the TOPSIS method used in this study, is an efficient way to calibrate the parameters of the WRF model.
References
Avriel M (2003) Nonlinear programming: analysis and methods. Courier Corporation, North Chelmsford
Bannister R (2017) A review of operational methods of variational and ensemble-variational data assimilation. Q J R Meteorol Soc 143(703):607–633
Breiman L (2001) Random forests. Mach Learn 45(1):5–32
Chen F, Dudhia J (2001) Coupling an advanced land surface-hydrology model with the Penn State-NCAR MM5 modeling system. Part I: Model implementation and sensitivity. Mon Weather Rev 129(4):569–585
Chen G-S, Liu Z, Clemens SC, Prell WL, Liu X (2011) Modeling the time-dependent response of the Asian summer monsoon to obliquity forcing in a coupled GCM: a PHASEMAP sensitivity experiment. Clim Dyn 36(3–4):695–710
Chen X, Pauluis OM, Leung LR, Zhang F (2018) Multiscale atmospheric overturning of the Indian summer monsoon as seen through isentropic analysis. J Atmos Sci 75(9):3011–3030
Chinta S, Jetti YS, Balaji C (2020) Assessment of WRF model parameter sensitivity for high-intensity precipitation events during the Indian summer monsoon. arXiv:2003.01353
Deb K, Pratap A, Agarwal S, Meyarivan T (2002) A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans Evol Comput 6(2):182–197
Di Z, Duan Q, Gong W, Wang C, Gan Y, Quan J, Li J, Miao C, Ye A, Tong C (2015) Assessing WRF model parameter sensitivity: a case study with 5 day summer precipitation forecasting in the Greater Beijing Area. Geophys Res Lett 42(2):579–587
Di Z, Duan Q, Wang C, Ye A, Miao C, Gong W (2018) Assessing the applicability of WRF optimal parameters under the different precipitation simulations in the Greater Beijing Area. Clim Dyn 50(5–6):1927–1948
Duan Q, Gupta VK, Sorooshian S (1993) Shuffled complex evolution approach for effective and efficient global minimization. J Optim Theory Appl 76(3):501–521
Duan Q, Schaake J, Andreassian V, Franks S, Goteti G, Gupta HV, Gusev Y, Habets F, Hall A, Hay L et al (2006) Model Parameter Estimation Experiment (MOPEX): an overview of science strategy and major results from the second and third workshops. J Hydrol 320(1–2):3–17
Duan Q, Di Z, Quan J, Wang C, Gong W, Gan Y, Ye A, Miao C, Miao S, Liang X et al (2017) Automatic model calibration: a new way to improve numerical weather forecasting. Bull Am Meteorol Soc 98(5):959–970
Dudhia J (2005) PSU/NCAR mesoscale modeling system, tutorial class notes and users’ guide, MM5 Modeling System Version 3. http://www.mmm.ucar.edu/mm5/overview.html
Dudhia J (1989) Numerical study of convection observed during the winter monsoon experiment using a mesoscale two-dimensional model. J Atmos Sci 46(20):3077–3107
Dudhia J (1993) A nonhydrostatic version of the Penn State-NCAR mesoscale model: validation tests and simulation of an Atlantic cyclone and cold front. Mon Weather Rev 121(5):1493–1513
Friedman JH et al (1991) Multivariate adaptive regression splines. Ann Stat 19(1):1–67
Gadgil S (1996) Climate change and agriculture—an Indian perspective. In: Abool YR, Gadgil S, Pant GB (eds) Climate variability and agriculture, pp 1–18
Gilliam RC, Pleim JE (2010) Performance assessment of new land surface and planetary boundary layer physics in the WRF-ARW. J Appl Meteorol Climatol 49(4):760–774
Gong W, Duan Q, Li J, Wang C, Di Z, Dai Y, Ye A, Miao C (2015) Multi-objective parameter optimization of common land model using adaptive surrogate modeling. Hydrol Earth Syst Sci 19(5):2409–2425
Gong W, Duan Q, Li J, Wang C, Di Z, Ye A, Miao C, Dai Y (2016) Multiobjective adaptive surrogate modeling-based optimization for parameter estimation of large, complex geophysical models. Water Resour Res 52(3):1984–2008
Halton JH (1964) Algorithm 247: radical-inverse quasi-random point sequence. Commun ACM 7(12):701–702
Hong S-Y, Lim J-OJ (2006) The WRF single-moment 6-class microphysics scheme (WSM6). Asia-Pac J Atmos Sci 42(2):129–151
Hong S-Y, Noh Y, Dudhia J (2006) A new vertical diffusion package with an explicit treatment of entrainment processes. Mon Weather Rev 134(9):2318–2341
Houtekamer P, Zhang F (2016) Review of the ensemble kalman filter for atmospheric data assimilation. Mon Weather Rev 144(12):4489–4532
Hwang C-L, Lai Y-J, Liu T-Y (1993) A new approach for multiple objective decision making. Comput Oper Res 20(8):889–899
Janjić ZI (1994) The step-mountain eta coordinate model: further developments of the convection, viscous sublayer, and turbulence closure schemes. Mon Weather Rev 122(5):927–945
Ji D, Dong W, Hong T, Dai T, Zheng Z, Yang S, Zhu X (2018) Assessing parameter importance of the weather research and forecasting model based on global sensitivity analysis methods. J Geophys Res Atmos 123(9):4443–4460
Kain JS (2004) The Kain–Fritsch convective parameterization: an update. J Appl Meteorol 43(1):170–181
Kalnay E (2003) Atmospheric modeling, data assimilation and predictability. Cambridge University Press, Cambridge
Kirkpatrick S, Gelatt CD, Vecchi MP (1983) Optimization by simulated annealing. Science 220(4598):671–680
Koza JR, Koza JR (1992) Genetic programming: On the programming of computers by means of natural selection, vol 1. MIT press, New York
Krishna Kumar K, Rupa Kumar K, Ashrit R, Deshpande N, Hansen JW (2004) Climate impacts on Indian agriculture. Int J Climatol J R Meteorol Soc 24(11):1375–1393
Lau N-C, Ploshay JJ (2009) Simulation of synoptic-and subsynoptic-scale phenomena associated with the East Asian summer monsoon using a high-resolution GCM. Mon Weather Rev 137(1):137–160
MATLAB (2018) Version 9.5.0.944444 (R2018b). The MathWorks Inc., Natick
McKay MD, Beckman RJ, Conover WJ (1979) Comparison of three methods for selecting values of input variables in the analysis of output from a computer code. Technometrics 21(2):239–245
Mlawer EJ, Taubman SJ, Brown PD, Iacono MJ, Clough SA (1997) Radiative transfer for inhomogeneous atmospheres: RRTM, a validated correlated-k model for the longwave. J Geophys Res Atmos 102(D14):16663–16682
Nocedal J, Wright S (2006) Numerical optimization. Springer, Berlin
Ollinaho P, Järvinen H, Bauer P, Laine M, Bechtold P, Susiluoto J, Haario H (2014) Optimization of NWP model closure parameters using total energy norm of forecast error as a target. Geosci Model Dev 7(5):1889–1900
Pai D, Sridhar L, Rajeevan M, Sreejith O, Satbhai N, Mukhopadhyay B (2014) Development of a new high spatial resolution (0.25\(\times\) 0.25) long period (1901–2010) daily gridded rainfall data set over India and its comparison with existing data sets over the region. Mausam 65(1):1–18
Quan J, Di Z, Duan Q, Gong W, Wang C, Gan Y, Ye A, Miao C (2016) An evaluation of parametric sensitivities of different meteorological variables simulated by the WRF model. Q J R Meteorol Soc 142(700):2925–2934
Rajeevan M, Gadgil S, Bhate J (2010) Active and break spells of the Indian summer monsoon. J Earth Syst Sci 119(3):229–247
Rajeevan M, Rohini P, Kumar KN, Srinivasan J, Unnikrishnan C (2013) A study of vertical cloud structure of the Indian summer monsoon using CloudSat data. Clim Dyn 40(3–4):637–650
Rao Y (1976) Southwest Monsoon (Meteorological Monograph, Synoptic Meteorology No. 1). Indian Meteorological Department, New Delhi, p 367
Ratnam J, Behera SK, Krishnan R, Doi T, Ratna SB (2017) Sensitivity of Indian summer monsoon simulation to physical parameterization schemes in the WRF model. Clim Res 74(1):43–66
Schmitt LM (2001) Theory of genetic algorithms. Theoret Comput Sci 259(1–2):1–61
Scholkopf B, Smola AJ (2001) Learning with kernels: support vector machines, regularization, optimization, and beyond. MIT press, New York
Sobol’ IM (1967) On the distribution of points in a cube and the approximate evaluation of integrals. Zhurnal Vychislitel’noi Matematiki i Matematicheskoi Fiziki 7(4):784–802
Srivastava A, Rajeevan M, Kshirsagar S (2009) Development of a high resolution daily gridded temperature data set (1969–2005) for the Indian region. Atmos Sci Lett 10(4):249–254
Stensrud DJ (2009) Parameterization schemes: keys to understanding numerical weather prediction models. Cambridge University Press, Cambridge
Svozil D, Kvasnicka V, Pospichal J (1997) Introduction to multi-layer feed-forward neural networks. Chemometr Intell Lab Syst 39(1):43–62
Turner AG, Annamalai H (2012) Climate change and the South Asian summer monsoon. Nat Clim Change 2(8):587
Wang C, Duan Q, Gong W, Ye A, Di Z, Miao C (2014) An evaluation of adaptive surrogate modeling based optimization with two benchmark problems. Environ Modell Softw 60:167–179
Webster PJ, Magana VO, Palmer T, Shukla J, Tomas R, Yanai M, Yasunari T (1998) Monsoons: processes, predictability, and the prospects for prediction. J Geophys Res Oceans 103(C7):14451–14510
Wernli H, Paulat M, Hagen M, Frei C (2008) SAL-A novel quality measure for the verification of quantitative precipitation forecasts. Mon Weather Rev 136(11):4470–4487
Williams CK, Rasmussen CE (1996) Gaussian processes for regression. Adv Neural Inf Process Syst 20:514–520
Williamson D, Blaker AT, Hampton C, Salter J (2015) Identifying and removing structural biases in climate models with history matching. Clim Dyn 45(5–6):1299–1324
Yang B, Qian Y, Lin G, Leung R, Zhang Y, Fu Q (2012) Some issues in uncertainty quantification and parameter tuning: a case study of convective parameterization scheme in the WRF regional climate model. Atmos Chem Phys 12:5
Yang B, Zhang Y, Qian Y, Huang A, Yan H (2015) Calibration of a convective parameterization scheme in the WRF model and its impact on the simulation of East Asian summer monsoon precipitation. Clim Dyn 44(5–6):1661–1684
Yang B, Berg LK, Qian Y, Wang C, Hou Z, Liu Y, Shin HH, Hong S, Pekour M (2019) Parametric and structural sensitivities of turbine-height wind speeds in the boundary layer parameterizations in the weather research and forecasting model. J Geophys Res Atmos 124(12):5951–5969
Acknowledgements
This research is supported by the National Monsoon Mission, Ministry of Earth Sciences, Government of India (Project No. IITM/MM-II/IITM/2018/IND-8). The authors are grateful to the international WRF community for the development and support of the WRF model. All models runs are carried out on Aditya High-Performance Computing (HPC) system at the Indian Institute of Tropical Meteorology (IITM), Pune, India. The authors thank NCEP for providing the FNL data. The authors also thank ECMWF for making available ERA-Interim reanalysis data sets. The IMERG data are provided by the NASA/Goddard Space Flight Center’s PMM and PSS teams. The figures are plotted using NCAR Command Language (NCL).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Chinta, S., Balaji, C. Calibration of WRF model parameters using multiobjective adaptive surrogate model-based optimization to improve the prediction of the Indian summer monsoon. Clim Dyn 55, 631–650 (2020). https://doi.org/10.1007/s00382-020-05288-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00382-020-05288-1