Projection Methods for Uniformly Convex Expandable Sets


1
Laboratoire ERIC, Université Lyon 2, 69500 Bron, France
2
The Alan Turing Institute, London NW1 2DB, UK
3
Data Science Division, The National Physical Laboratory, Teddington TW11 0LW, UK
4
Laboratoire des Signaux et Systèmes, CentraleSupélec, CNRS, Université Paris-Saclay, 91190 Gif-sur-Yvette, France
*
Author to whom correspondence should be addressed.
Mathematics 2020, 8(7), 1108; https://doi.org/10.3390/math8071108
Submission received: 21 February 2020
/
Revised: 19 June 2020
/
Accepted: 22 June 2020
/
Published: 6 July 2020
(This article belongs to the Special Issue New Trends in Machine Learning: Theory and Practice)
{kind=link}
{kind=link}
{kind=link}
Abstract
:Many problems in medical image reconstruction and machine learning can be formulated as nonconvex set theoretic feasibility problems. Among efficient methods that can be put to work in practice, successive projection algorithms have received a lot of attention in the case of convex constraint sets. In the present work, we provide a theoretical study of a general projection method in the case where the constraint sets are nonconvex and satisfy some other structural properties. We apply our algorithm to image recovery in magnetic resonance imaging (MRI) and to a signal denoising in the spirit of Cadzow’s method.
1. Introduction
1.1. Background and Goal of the Paper
Many problems in applied mathematics, engineering, statistics and machine learning can be reduced to finding a point in the intersection of some subsets of a real separable Hilbert space . In mathematical terms, let be a finite family of proximinal subsets (i.e., sets S such that any admits a closest point in S) [1] of with a non-empty intersection, we address the problem of finding a point in the intersection of the sets using a successive projection method.
When the sets are closed and convex, the problem is known as the convex feasibility problem, and is the subject of extensive literature; see [2,3,4,5] and references therein. In this paper, we take one step further into the scarcely investigated topic of finding a common point in the intersection of nonconvex sets. Convex feasibility problems have been applied to an extremely wide range of topics in systems analysis and control, signal and image processing. Important examples are: model order reduction [6], controller design [7], tensor analysis [8], image recovery [9], electrical capacitance tomography [10], MRI [11,12], and stabilisation of quantum systems and application to quantum computation [13,14].
Extension of this problem to the nonconvex setting also has many applications, related to sparse estimation and more specifically low rank constraints, such as in control theory [15], signal denoising [16], phase retrieval [17], structured matrix estimation [18,19] and has great potential impact on the design of scalable algorithm in many machine learning problems such as Deep Neural Networks [20]. Studies of projection methods in the nonconvex settings have been quite scarce in the literature [21,22,23] and a lot of work still remains to be done in order to understand the behavior of such methods for these difficult problems.
In the present paper, our goal is to investigate how the results in [22] can be improved in such a way that strong convergence can be obtained. The results proved in [22] make the assumption that the sets involved in the feasibility problem can be written as a possibly not countable union of closed convex sets, and one of the sets is boundedly compact. Our study will be based on the assumption that the convex sets in the family are uniformly convex, which allows to remove the boundedly compactness assumption. As will be seen in Section 4, uniform convexity can be obtained by simply modifying the algorithm even in the case where the sets are not expandable into a family of uniformly convex sets.
1.2. Preliminary on Projections and Expansion into Convex Sets
The notation Card will denote the cardinality of a set. will denote a real separable Hilbert space with scalar product , norm , and distance d. Let S be a subset of . denotes the closure of S. S is proximinal if each point in has at least one projection onto S. If S is proximinal, then S is closed. When S is proximinal, is the projection point-to-set mapping onto S defined by
denotes an arbitrary element of and . denotes the closed ball of center x and radius . In the case of a projection onto a convex set C, Kolmogorov’s criterion is:
for all . Our work is a follow-on project to the work in [22] which introduced the notion of convex expandable sets in order to tackle certain feasibility problems involving rank-constrained matrices as described in [23]. We recall what it means for a nonconvex set to be expandable into a family of convex sets.
Definition 1.
A subset S of is said to be expandable into a family of convex sets when it is the union of non-trivial, i.e., not reduced to a single point, convex subsets of , i.e.,
where J is a possibly uncountable index set. Any family satisfying (2) is called a convex expansion of S.
Remark 1.
Uncountable unions often appear in practice. An important example is the set of matrices of rank r in for . This set is the union of the rays passing through the null matrix and any matrix of rank r different from zero. This constraint often appears in signal processing problems such as signal denoising [16] and more generally, structured matrix estimation problems [19].
Uniform convexity is an important concept, which allows to prove many strong convergence results in the framework of successive projection methods ([4], Section 5.3).
Definition 2.
A convex subset C of is uniformly convex with respect to a positive-valued nondecreasing function if
Uniform convexity will be instrumental in our analysis. We define the following condition which is stronger than the condition of being expandable into a family of convex sets.
1.3. The Projection Algorithm
For any point x in , for the sake of simplicity, will be noted by . We will assume throughout that the family is finite.
Definition 4.
(Method of Projection onto Uniformly Convex Expandable Sets)
Given a point in , two real numbers α and λ in , a nonnegative integer M and a sequence of subsets of I satisfying the following conditions
the projection-like method considered in this paper is iteratively defined by
with satisfying
Remark 2.
Using the assumption , the coefficients , , can be chosen in such a way that the denominator in the definition of is not equal to zero. Note that one can relax the constraint in the case where is well defined at every iteration, thus allowing to recover the cyclic projection method.
The numbers and ensure that the steps taken at each iteration are sufficiently large as compared to the distance of the iterations to their projections on each , . The use of the integer M ensures that each is involved at least every M iterations. The “If” condition in Step 1 of the algorithm ensures that will move at each iteration by enforcing that it does not yet belong to all the selected sets , . Our method is an extension of Ottavy’s method [4] to the case of nonconvex sets. The idea of using a potentially variable index set at each iteration allows to recover several variants, such as cyclic projections [2,21,22,24] or parallel projections [2,23,24]. Notice that, due to finiteness of the cardinality of I, finding an index j such that is easy if such an index exists.
1.4. Our Contributions
The main contributions of our work are a proof that strong convergence holds in the proposed setting, and a new constructive modification of the projection method in order to accommodate the case of non-necessarily uniformly convex expandable sets. Based on our findings, we will then weaken our assumptions and provide a new algorithm which does not need uniform convexity, while preserving strong convergence to a feasible solution. Applications to an infinite dimensional MRI problem and to low rank matrix estimation for signal denoising are presented in Section 5.
2. Ottavy’s Framework
2.1. Successive Projection Point-to-Set Mapping
Let and be two real numbers chosen in . Define the point-to-set mapping
where is a weighted average,
is a subset of selected constraints such that
, is a set of normalized nonvanishing weightings such that
is the relaxation parameter such that
with
2.2. Ottavy’s Lemma
In [4], Ottavy proved the very useful lemma.
Lemma 1.
For any and , the following results hold:
3. A Strong Convergence Result
Let be the sequence of iterates of the projection method defined by (3). In the present section, we show strong convergence of this sequence to a point in .
For every n in and for each , define
When the (finite) family is expandable into a family of convex sets, for every n in and for each .
Lemma 2.
If the following conditions are satisfied
then, for every n in and for every in , we have
Proof.
Fix n in and in . According to , each point belongs to a set , a convex set in the uniformly convex expansion of indexed by . Hence is also the projection of onto , and . Replacing respectively x, and z by , and in Ottavy’s Lemma (Lemma 1, or [4] Lemma 7.1), we obtain the desired results. ☐
Lemma 3.
If the conditions , , and
are satisfied, then
Proof.
(i) Let be a sequence satisfying , and let k in . We deduce from Lemma 2(i) that . Then we have
Therefore
and then ensures that the sequences and are bounded.
(ii) Now, the cosine law, followed by the Cauchy-Schwarz inequality give
Using Lemma 2(i), we then obtain that
Thus
Since the sequence is bounded and the series is convergent, the result (i) follows at once.
(iii) Lemma 3(i) and Lemma 2(iii), imply that . Thus for any ,
Then we deduce from that , which completes the proof of (iii).
Since the sequence is bounded, and is convergent, we deduce from the last inequality that is convergent. Then using Lemma 3(i), we obtain that the series is convergent, which is equivalent to the convergence of the sequence .
(v) Since, by , is a Cauchy sequence, it is strongly convergent to a point z in the Hilbert space . For every n in , . Fix i in I. Due to condition , there exists a subsequence of satisfying for all . Therefore, . Since this assertion is true for all i in I, and each is closed, we obtain that . ☐
Remark 3.
In the convex case, Lemma 3(iii) is known in the simpler case where is chosen to be a constant sequence in and is a consequence of the Fejér monotonicity [5].
We now state the main result of this section, which is strong convergence under the assumption that the sets , , are expandable in uniformly convex sets.
Theorem 1.
If the conditions , , and .
The finite family
is expandable in uniformly convex sets with respect to a function b are satisfied, then the sequence converges strongly to a point in .
Proof.
Notice that implies . According to , each point belongs to a convex set in the uniformly convex expansion of , indexed by . Hence is also the projection of onto , and . Let be a sequence satisfying . Fix n in , and i in I. Define
According to , and belong to a uniformly convex set . Thus
where . Since is also the projection of onto , it results from the Kolmogorov criterion (1) that
Then
Now, consider the translation . Clearly,
On the other hand, using , we get that implies . Indeed,
and since , Kolmogorov’s criterion gives
which implies
and, after recalling that ,
which implies that as desired. Hence (5), together with (6) imply
Now, assume , and define
One easily checks that , i.e., . Thus, using (2.2), we get , i.e., . Therefore
Since this inequality is obviously satisfied when , it holds whether or not. Now, let
and
The case: .
In the case where , we have
- either there exist in and in , such that ,
- or .
In the first case, since vanishes only at zero, we have and . According to (3), , and for all , . Therefore, the sequence has converged to a solution in a finite number of steps. In the second case, there exists a subsequence which converges to zero. Fix i in I. Since is nondecreasing,
According to Lemma 3(ii) and (iii), converges to zero for all j in I, and converges to a limit c independent of i. Hence, for all there exists N in such that for all , and for all j in I. Thus, for all , and for all j in I, .
Assume , and take . Then, since is nondecreasing and vanishes only at zero, we deduce from (8) that for all , , which contradicts . Hence, , and for all i in I. Using Lemma 3(ii), we deduce that , and it results from Lemma 3(iv) that converges strongly to a point in .
The case .
Therefore, combining the definition of and (9), we have
Using Lemma 2(ii) and Lemma 3(i), we deduce that the series is convergent. Then is a Cauchy sequence, and is therefore strongly convergent to a point in . Using Lemma 3(ii), we deduce that is also strongly convergent to for any i in I. Since each set is closed, we immediately conclude that , which completes the proof. ☐
4. Projections onto Stepwise Generated Uniformly Convex Sets
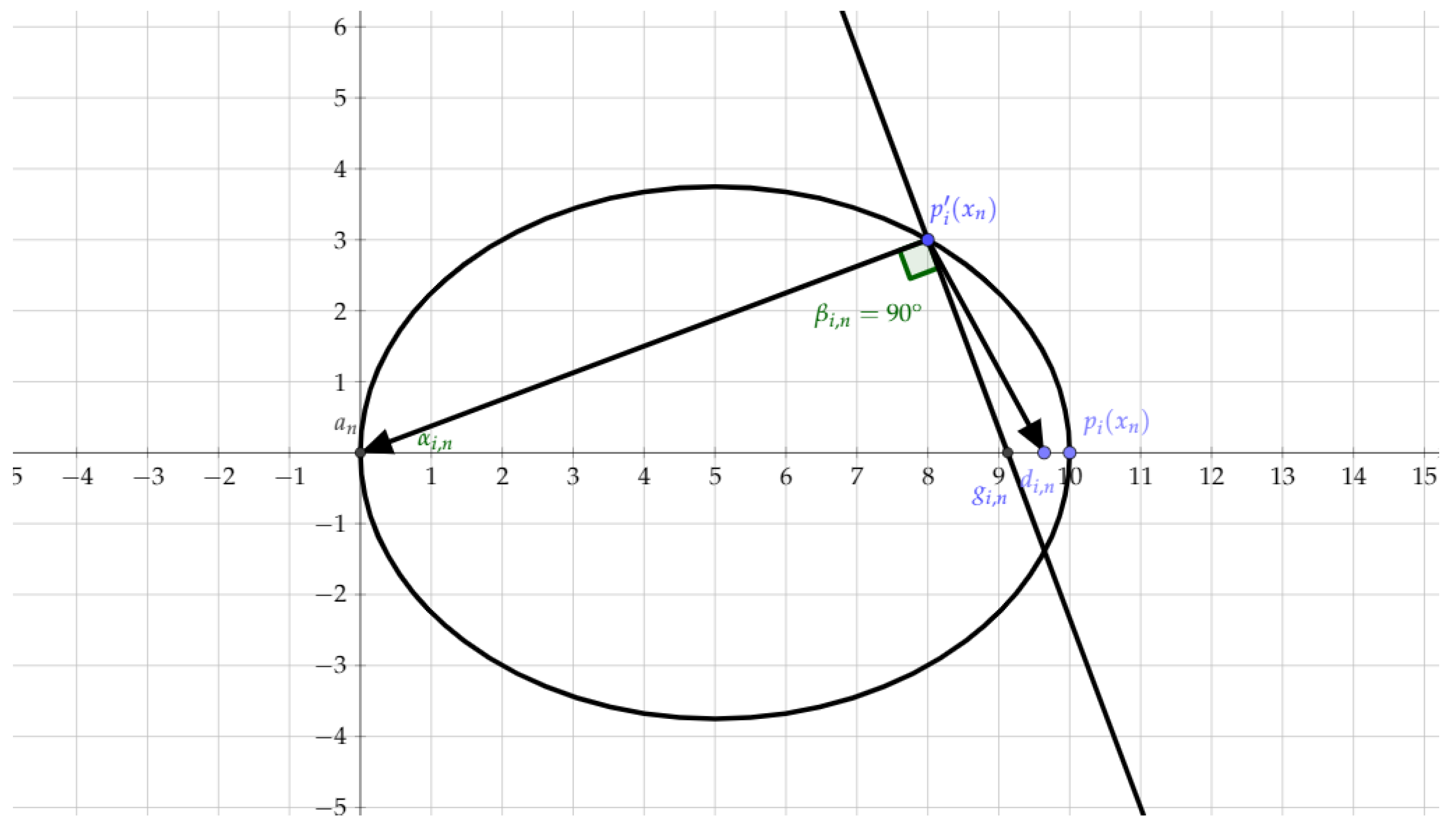
In this section, we show how the results of Section 3 may be used to define a strongly convergent cyclic projection algorithm in the case where the sets are only expandable in convex sets, but not into uniformly convex sets. To our knowledge, this method is new, even in the convex case. The underlying idea of the algorithm is as follows. First, note that the condition is realistic for the type of nonconvex sets considered in this paper, and may be interpreted as a strong consistency condition. On the other hand, in many cases, a trivial sequence where for all n in is already known, as in the applications presented in Section 5. Using this sequence, we define a projection method which converges strongly to a point in . For every n in , i in I, and in , will denote the closed ellipsoid with main axis , with center , which is rotationally invariant around this axis and with maximal radius equal to and with minimal radius equal to for some . We denote by the projection of onto ; see Figure 1.
Definition 5.
(Method of Double Projection onto Convex Expandable Sets)
Assume is satisfied. Given a point in , two real number α and λ in , a nonnegative integer M, a sequence of subsets of I and a sequence where for all n in , the projection method onto stepwise generated uniformly convex sets is iteratively defined by
under the conditions , , and
In the remainder of this section, the sequence is defined by the algorithm of Definition 5. The main result is the following.
Theorem 2.
If the condition is satisfied, and the sequence introduced in Definition 5 satisfies , then the sequence converges strongly to a point in .
Proof.
The method introduced in Definition 5 is a general projection algorithm onto specific uniformly convex sets constructed at each iteration. For every n in and each i in I, and belong to . Then Lemma 2 and Lemma 3 where and are respectively replaced with and hold true. In the same way, taking in the proof of Theorem 1, we deduce that the sequence converges strongly to some point in . Nevertheless, since is replaced with , it is still not clear why . Let us now address this specific point. Fix n in , i in I, and in . According to , and belong to a convex set , and is also the projection of onto . Hence the Kolmogorov criterion (1) gives . Therefore
which implies
Moreover, since the segment is the main axis of the ellipsoid and , we have . Combining this with (10), we get
We deduce from Lemma 3(iii) where is replaced with that . On the other hand, as is the projection of onto , and , we have . Moreover, following the same steps as in the proof of Lemma 3(i) gives that is bounded, from which we deduce that is bounded as well. Therefore we deduce from the last inequality that
Let and . Then, we have
and
for all .
Assume that . Using Claim 1, we get that
as long as we enforce
In particular, we can take
for any appropriately chosen . Using Niculescu’s Lemma 4 in Appendix B, we obtain that
Note that this inequality also holds without resorting to Claim 1 if . According to Theorem 1, and are strongly convergent to a point in . We now split the remainder of the argument into the following complementary cases involving an increasing function : which parametrises possible subsequences.
- If the sequence converges to zero, then using Claim 2, also converges to zero. Therefore, is also strongly convergent to for each i in I. Since each set is closed, we again conclude that .
- If the sequence does not converge to zero, and the sequence converges to zero, then we must have for some and some subsequence indexed by an appropriately chosen increasing function . This implies in particular thatAs a result, eitherorNotice further that (16) holds only if converges to zero. Thus, both cases simplify into the conclusion that converges to zero. Therefore is also strongly convergent to for each i in I. Since each set is closed, we again conclude that .
- If both sequences and do not converge to zero, then and for some and for some subsequence indexed by an appropriately chosen increasing function . Since is the length of the main axis of , and, as such, bounds from above the distance between any two points in , we deduce that . Furthermore, since the sequences and are bounded, we deduce thatfor some . Then using the Cauchy-Schwarz inequality in the numerator in (14), we getfor some . Since , we deduce from (11) and (15) that converges to zero. Therefore, is also strongly convergent to for each i in I. Since each set is closed, we again conclude that .
These previous cases cover all the possible cases and all lead to the conclusion that . The proof is thus complete. ☐
The two following claims were instrumental in the proof of Theorem 2. We now provide their proofs.
Claim 1.
Assume that . Then
is a well defined nonnegative real number. Moreover, we have
for all
Proof.
We have . Indeed, assume for contradiction that . This would imply that lies in the interior of and therefore . However, since by convexity of , , this would imply that , and therefore , the sought-after contradiction.
Consider now the 2D plane containing , and . Set to be at the intersection of the line perpendicular at to with the segment (see Figure 1). First, we have
and
from which we obtain
Since is an ellipse with maximal axis , our next step is to express as the convex combination
of and for some . Notice that (20) implies
which itself gives
Using (19), we get
Notice further that, by construction, since is the main axis of and since, by assumption, , we have (see Figure 1)
Then, setting
we see that we need to take , i.e.,
(which, owing to (21), is well defined), in order to ensure that
i.e., (18) holds. Finally, (19) and (21) together ensure that (17) is nonnegative. ☐
Claim 2.
We have
Proof.
By definition of , the fact that implies that
Thus belongs to the half space
which is the set of points in which are closer to than . Clearly, as well, which completes the proof. ☐
5. Applications
5.1. MRI Image Reconstruction: The Infinite-Dimensional Hilbert Space Setting
The field of inverse problems was extensively investigated in the last five decades, fueled in particular by the many challenged in medical imaging. Projection methods have played an important role in the development of efficient reconstruction techniques [25], a well studied example being the method of projection onto convex sets (POCS) [2]. In recent years, techniques from penalised estimation have gained increasing popularity since the discovery of the compressed sensing paradigm, allowing for fewer measurements to be collected whilst achieving remarkable reconstruction performance. One penalisation approach which has been a center of focus since its introduction is the Rudin Osher Fatemi functional [26], which can be described as follows: the reconstructed image u is the solution of the minimization problem,
where is a positive relaxation parameter and the term is defined in Appendix A. The term is called the fidelity term and the term is called the regularisation term. This infinite-dimensional minimization problem enforces the solution, which is a priori in , to satisfy a finite bounded variation (BV) norm constraint.
One important remark is that the optimisation problem can be turned into a pure feasibility problem by imposing the -norm and the fidelity terms to be less than or equal to a certain tolerance. Using this approach, one can define an alternating projection procedure as in Algorithm 1 below, where we will use the forward operator , the partial Fourier Transform which plays a central role in MRI. The usual Fourier transform will be denoted by as usual.
In this example, we will use the projections on the sets
The set is not convex for , but, since the epigraph of is a cone, the set is expandable into convex sets as discussed in [22,23]. Notice that when the scaling factor is dropped in the definition of and , the problem is equivalent to the standard -penalised reconstruction approach. Introducing this scaling factor allows to recover a solution up to a scaling, which can easily be recovered by rescaling the solution by using the constraint as a post-processing step. The introduction of the scaling in these definition allows the null function to belong to the intersection of the sets , and . Thus, we will set , in the sequel. In what follows, will be the function will value equal to zero except for the observed frequencies which are taken as the observed values.
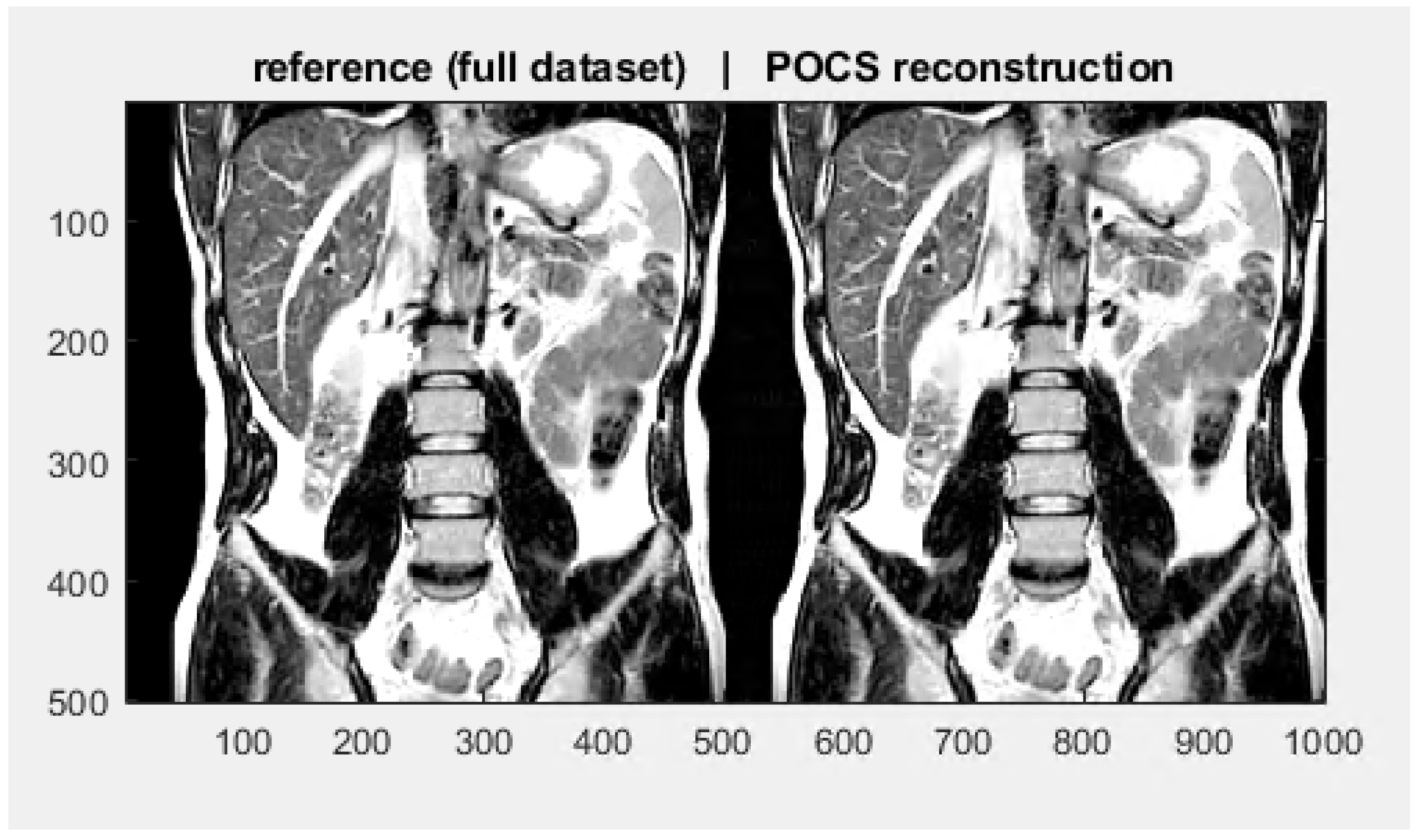
Our implementation is described in Algorithm 1. Experiments were made after incorporating the projection onto the ball into a freely available code provided in [27]. The fidelity term was set to and the regularisation term was tuned using cross validation. The projection onto the -ball was computed using the method described in [28]. In order to avoid numerical instabilities, the iterates were rescaled every 10 iteration, which does not change the convergence analysis due to conic invariance of our formulation. We chose very thin ellipsoids by setting . A numerical illustration is given in Figure 2 below. Extensive numerical simulations will be presented in a forthcoming paper devoted to a thorough study of projection methods for MRI and X-ray computed tomography (XCT).
| Algorithm 1: Alternating projection method for MRI for . |
 |
Since and are convex and is expandable into convex sets, we deduce from Theorem 2 that Algorithm 1 converges strongly to a point in .
5.2. A Uniformly Convex Version of Cadzow’s Method
The method presented in Section 4 is now applied to a denoising problem in the spirit of Cadzow’s method [16].
Let be a complex-valued vector of length N. Let be a linear operator which maps x into the set of Hankel matrices, with , , defined by setting the component to the value i.e.,
The adjoint operator associated with , denoted by , is a linear map from matrices to vectors of length N, obtained by averaging each skew-diagonal.
The denoising problem we consider in this section is the one of estimating a signal x corrupted by random noise, as described in the observation model
for , where
- is a sum of damped exponential components, i.e.,with , a real damping factor satisfying , a real number representing a frequency and a complex coefficient,
- is a random noise.
This denoising problem is of crucial importance in many applications and is also known as super-resolution in the literature; see [16,29,30,31,32,33]. The main motivation behind Cadzow’s algorithm is that many signals of interest have low rank Hankelization. In mathematical terms, we can often look for approximations and denoising, for signals which satisfy the constraint that rank( where . Such constraints are important when the observed signal is corrupted with additive noise, which increases the rank of . Consequently, an intuitive way of estimating x from y is to do rank reduction: starting from , the Cadzow’s algorithm iteratively updates the estimate via the following rule
Here computes the truncated singular value decomposition (SVD) of any matrix X, that is,
with
being an SVD of X and with being the singular values. As is now well known, Cadzow’s algorithm is easily interpreted as a method of alternating projections in the matrix domain [23]. Denote by the projection onto the set of matrices of rank r, and by the projection onto the space of Hankel matrices. Then, Cadzow’s method is easily seen to be equivalent to the following matrix recursions
Since is convex and is expandable into convex sets, we deduce from the main result of [22] that Cadzow’s method has cluster points in . On the other hand, applying the method of Section 4 can be advantageous in the application of projection methods to the case of low rank matrix constraints such as in the application of Cadzow’s method. In particular, our method shows that the SVD can be computed only approximately in the first iterations and still belong to the ellipsoids , thus implying possibly important computational savings. Our new method converges to a point in .
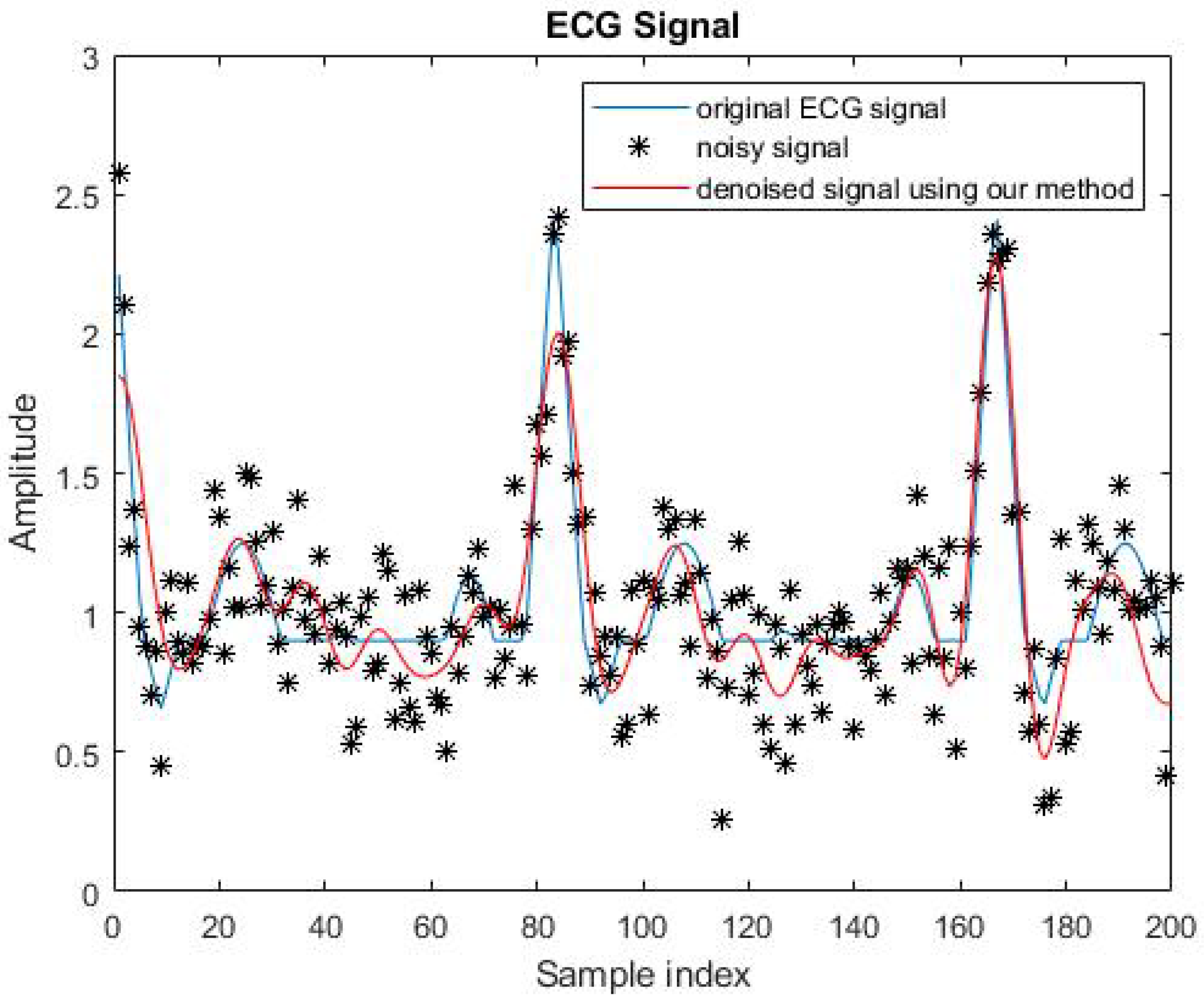
An example showing the efficiency of Cadzow’s method is presented in Figure 3 below. In this experiment, we set the signal-to-noise ratio (SNR) to 3.5 dB and the rank constraint equal to 15 (an appropriate choice for the rank can be made using statistical techniques such as cross-validation). We took .
6. Conclusions and Future Work
The work presented in this paper is a follow on project to the work of [22]. We obtain strong convergence results in Hilbert spaces in the case of uniformly convex expandable sets, a notion which refines the definition of convex expandable sets introduced in [22,23]. We showed that the proposed methods apply to practical inverse and denoising problems which are instrumental in engineering and signal and data analytics.
Future work is planned in developing new and faster algorithms for nonconvex feasibility problems, using acceleration schemes such as Richardon’s extrapolation [34].
Author Contributions
S.C. and P.B. contributed to all the mathematical findings presented in the paper and to the various stages of the writing. All authors have read and agreed to the published version of the manuscript.
Funding
This research was partially supported by the iCODE Institute, research project of the IDEX Paris-Saclay, and by the Hadamard Mathematics LabEx (LMH) through the grant number ANR-11-LABX-0056-LMH in the “Programme d’Investissement d’Avenir’’.
Acknowledgments
The authors would like to thank the reviewers for the high quality of their comments, which greatly helped improve the quality of the manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Definition of the Total Variation (TV) Norm
Recall that a function u is in for a bounded open set if it is integrable and there exists a Radon measure such that
for all . This measure is the distributional gradient of u. When u is smooth, , and TV-norm is equivalently the integral of its gradient magnitude,
For , the -TV norm is defined by
For , formula (A1) defines a quasi-norm which is nonconvex, called the -TV norm by abuse of language, as is common in the image processing community.
Appendix B. Niculescu’ Lemma
Niculescu’s Lemma [35] (Theorem 2), [36] is a converse of the Cauchy-Schwarz inequality. It can be stated as follows.
Lemma 4.
Assume there exist two positive real numbers and such that
Then, we have
References
- Bauschke, H.H.; Combettes, P.L. Convex Analysis and Monotone Operator Theory in Hilbert Spaces; Springer: Berlin/Heidelberg, Germany, 2011; Volume 408. [Google Scholar]
- Escalante, R.; Raydan, M. Alternating Projection Methods; SIAM: Philadelphia, PA, USA, 2011. [Google Scholar]
- Gurin, L.; Polyak, B.T.; Raik, È.V. The method of projections for finding the common point of convex sets. Zhurnal Vychislitel’noi Matematiki i Matematicheskoi Fiziki 1967, 7, 1211–1228. [Google Scholar]
- Ottavy, N. Strong convergence of projection-like methods in Hilbert spaces. J. Optim. Theory Appl. 1988, 56, 433–461. [Google Scholar] [CrossRef]
- Combettes, P.L.; Puh, H. Iterations of parallel convex projections in Hilbert spaces. Numer. Funct. Anal. Optim. 1994, 15, 225–243. [Google Scholar] [CrossRef]
- Grigoriadis, K.M. Optimal H∞ model reduction via linear matrix inequalities: Continuous-and discrete-time cases. Syst. Control Lett. 1995, 26, 321–333. [Google Scholar] [CrossRef]
- Babazadeh, M.; Nobakhti, A. Direct Synthesis of Fixed-Order H∞ Controllers. IEEE Trans. Autom. Control 2015, 60, 2704–2709. [Google Scholar] [CrossRef]
- Li, Z.; Dai, Y.H.; Gao, H. Alternating projection method for a class of tensor equations. J. Comput. Appl. Math. 2019, 346, 490–504. [Google Scholar] [CrossRef]
- Combettes, P. The convex feasibility problem in image recovery. In Advances in Imaging and Electron Physics; Elsevier: Amsterdam, The Netherlands, 1996; Volume 95, pp. 155–270. [Google Scholar]
- Krol, A.; Li, S.; Shen, L.; Xu, Y. Preconditioned alternating projection algorithms for maximum a posteriori ECT reconstruction. Inverse Probl. 2012, 28, 115005. [Google Scholar] [CrossRef] [Green Version]
- Herman, G.T. Fundamentals of Computerized Tomography: Image Reconstruction From Projections; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- McGibney, G.; Smith, M.; Nichols, S.; Crawley, A. Quantitative evaluation of several partial Fourier reconstruction algorithms used in MRI. Magn. Reson. Med. 1993, 30, 51–59. [Google Scholar] [CrossRef]
- Ticozzi, F.; Zuccato, L.; Johnson, P.D.; Viola, L. Alternating projections methods for discrete-time stabilization of quantum states. IEEE Trans. Autom. Control 2017, 63, 819–826. [Google Scholar] [CrossRef]
- Drusvyatskiy, D.; Li, C.K.; Pelejo, D.C.; Voronin, Y.L.; Wolkowicz, H. Projection methods for quantum channel construction. Quantum Inf. Process. 2015, 14, 3075–3096. [Google Scholar] [CrossRef]
- Grigoriadis, K.M.; Beran, E.B. Alternating projection algorithms for linear matrix inequalities problems with rank constraints. In Advances in Linear Matrix Inequality Methods in Control; SIAM: Philadelphia, PA, USA, 2000; pp. 251–267. [Google Scholar]
- Cadzow, J.A. Signal enhancement-a composite property mapping algorithm. IEEE Trans. Acoust. Speech Signal Process. 1988, 36, 49–62. [Google Scholar] [CrossRef] [Green Version]
- Bauschke, H.H.; Combettes, P.L.; Luke, D.R. Phase retrieval, error reduction algorithm, and Fienup variants: A view from convex optimization. J. Opt. Soc. Am. A 2002, 19, 1334–1345. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chu, M.T.; Funderlic, R.E.; Plemmons, R.J. Structured low rank approximation. Linear Algebra Its Appl. 2003, 366, 157–172. [Google Scholar] [CrossRef] [Green Version]
- Markovsky, I.; Usevich, K. Structured low-rank approximation with missing data. SIAM J. Matrix Anal. Appl. 2013, 34, 814–830. [Google Scholar] [CrossRef] [Green Version]
- Elser, V. Learning Without Loss. arXiv 2019, arXiv:1911.00493. [Google Scholar]
- Combettes, P.L.; Trussell, H.J. Method of successive projections for finding a common point of sets in metric spaces. J. Optim. Theory Appl. 1990, 67, 487–507. [Google Scholar] [CrossRef]
- Chretien, S.; Bondon, P. Cyclic projection methods on a class of nonconvex sets. Numer. Funct. Anal. Optim. 1996, 17, 37–56. [Google Scholar]
- Chrétien, S. Methodes de projection pour L’optimisation ensembliste non convexe. Ph.D. Thesis, Sciences Po, Paris, France, 1996. [Google Scholar]
- Bauschke, H.H.; Borwein, J.M. On projection algorithms for solving convex feasibility problems. SIAM Rev. 1996, 38, 367–426. [Google Scholar] [CrossRef] [Green Version]
- Censor, Y.; Chen, W.; Combettes, P.L.; Davidi, R.; Herman, G.T. On the effectiveness of projection methods for convex feasibility problems with linear inequality constraints. Comput. Optim. Appl. 2012, 51, 1065–1088. [Google Scholar] [CrossRef]
- Rudin, L.I.; Osher, S.; Fatemi, E. Nonlinear total variation based noise removal algorithms. Phys. D Nonlinear Phenom. 1992, 60, 259–268. [Google Scholar] [CrossRef]
- Michael, V. MRI Partial Fourier Reconstruction with POCS. Available online: https://fr.mathworks.com/matlabcentral/fileexchange/39350-mri-partial-fourier-reconstruction-with-pocs?s_tid=prof_contriblnk (accessed on 13 February 2020).
- Condat, L. Discrete total variation: New definition and minimization. SIAM J. Imaging Sci. 2017, 10, 1258–1290. [Google Scholar] [CrossRef] [Green Version]
- Plonka, G.; Potts, D.; Steidl, G.; Tasche, M. Numerical Fourier Analysis: Theory and Applications; Book Manuscript; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Al Sarray, B.; Chrétien, S.; Clarkson, P.; Cottez, G. Enhancing Prony’s method by nuclear norm penalization and extension to missing data. Signal Image Video Process. 2017, 11, 1089–1096. [Google Scholar] [CrossRef]
- Barton, E.; Al-Sarray, B.; Chrétien, S.; Jagan, K. Decomposition of Dynamical Signals into Jumps, Oscillatory Patterns, and Possible Outliers. Mathematics 2018, 6, 124. [Google Scholar] [CrossRef] [Green Version]
- Moitra, A. Super-resolution, extremal functions and the condition number of Vandermonde matrices. In Proceedings of the Forty-Seventh Annual ACM Symposium on Theory Of Computing, Chicago, IL, USA, 22–26 June 2015; pp. 821–830. [Google Scholar]
- Chrétien, S.; Tyagi, H. Multi-kernel unmixing and super-resolution using the Modified Matrix Pencil method. J. Fourier Anal. Appl. 2020, 26, 18. [Google Scholar] [CrossRef] [Green Version]
- Bach, F. On the Unreasonable Effectiveness of Richardson Extrapolation. Available online: https://francisbach.com/richardson-extrapolation/ (accessed on 13 February 2020).
- Dragomir, S.S. A generalisation of the Cassels and Greub-Reinboldt inequalities in inner product spaces. arXiv 2003, arXiv:math/0306352. [Google Scholar]
- Niculescu, C.P. Converses of the Cauchy-Schwartz Inequality in the C*-Framework. RGMIA Research Report Collection. 2001, Volume 4. Available online: https://rgmia.org/v4n1.php (accessed on 15 February 2020).
Figure 1.
Section of the ellipsoid .

Figure 2.
POCS reconstruction with 30 iterations.

Figure 3.
Application of our method to denoising a benchmark Electrocardiogram (ECG) type signal.

© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Chrétien, S.; Bondon, P. Projection Methods for Uniformly Convex Expandable Sets. Mathematics 2020, 8, 1108. https://doi.org/10.3390/math8071108
AMA Style
Chrétien S, Bondon P. Projection Methods for Uniformly Convex Expandable Sets. Mathematics. 2020; 8(7):1108. https://doi.org/10.3390/math8071108
Chicago/Turabian StyleChrétien, Stéphane, and Pascal Bondon. 2020. "Projection Methods for Uniformly Convex Expandable Sets" Mathematics 8, no. 7: 1108. https://doi.org/10.3390/math8071108
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.