When Inaccuracies in Value Functions Do Not Propagate on Optima and Equilibria


1
Institute of Applied Mathematics and Mechanics, Faculty of Mathematics, Informatics and Mechanics, University of Warsaw, 02-097 Warsaw, Poland
2
Department of Digitalization, Copenhagen Business School, 2000 Copenhagen, Denmark
*
Authors to whom correspondence should be addressed.
Mathematics 2020, 8(7), 1109; https://doi.org/10.3390/math8071109
Submission received: 16 May 2020
/
Revised: 27 June 2020
/
Accepted: 30 June 2020
/
Published: 6 July 2020
(This article belongs to the Special Issue Statistical and Probabilistic Methods in the Game Theory)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:We study general classes of discrete time dynamic optimization problems and dynamic games with feedback controls. In such problems, the solution is usually found by using the Bellman or Hamilton–Jacobi–Bellman equation for the value function in the case of dynamic optimization and a set of such coupled equations for dynamic games, which is not always possible accurately. We derive general rules stating what kind of errors in the calculation or computation of the value function do not result in errors in calculation or computation of an optimal control or a Nash equilibrium along the corresponding trajectory. This general result concerns not only errors resulting from using numerical methods but also errors resulting from some preliminary assumptions related to replacing the actual value functions by some a priori assumed constraints for them on certain subsets. We illustrate the results by a motivating example of the Fish Wars, with singularities in payoffs.
Keywords:
optimal control; dynamic programming; Bellman equation; dynamic games; Nash equilibria; Pareto optimality; value function; approximate solution; singularity; Fish WarsJEL Classification:
C02; C61; C72; C73; Q221. Introduction
Finding an optimal control in the feedback form or a feedback Nash equilibrium in a dynamic game is complicated, especially if the analytic solution cannot be found. The appropriate methods, based on the Bellman equation or a set of coupled Bellman equations, respectively, require finding the value function on the whole state space or at least a large invariant subset of it (for the principle of optimality, i.e., necessity of the Bellman equation in the infinite horizon see e.g., Stokey, Lucas and Prescott [1], Kamihigashi [2], Wiszniewska-Matyszkiel and Singh [3]) with appropriate terminal condition (for the infinite horizon, necessity has been proven in Wiszniewska-Matyszkiel and Singh [3]).
Currently, the substantial focus in research by mathematicians is on high accuracy of the solution of the Bellman equation or the set of Bellman equations in the case of numerical solutions, as well as the existence and uniqueness in some classes of functions or methods of estimating the infinite horizon value function and accuracy of this estimation (e.g., Martins-Da-Rocha and Vailakis [4], Le Van and Morhaim [5], Rincón-Zapatero and Rodríguez-Palmero [6], Matkowski and Nowak [7], Kamihigashi [8], Wiszniewska-Matyszkiel, and Singh [3]).
An error in calculation or computation of the solution of the Bellman equation even on a very small set may result in finding a function that is far from the actual value function while the resulting candidate for the optimal control differs substantially from the actual optimal control on a considerable part of the state set (see, e.g., Singh and Wiszniewska-Matyszkiel [9]). Moreover, the Bellman equation may have multiple solutions (Rincón-Zapatero and Rodríguez-Palmero [6], Singh and Wiszniewska-Matyszkiel [10], Wiszniewska-Matyszkiel, and Singh [3], with the false value function more plausible than the actual one in [3,10]). However, sometimes, errors in calculation and computation of the value function do not propagate on optima and equilibria.
The research presented in this paper has been motivated by an analysis of the well-known Fish Wars model as an example of games, which may be regarded as intractable by numerical methods due to singularities in payoffs. Nevertheless, after applying numerical methods not taking into account preliminary assumptions about the form of the solutions, and leaving the grid purposely sparse on some sets, we have obtained an unexpectedly high level of accuracy of numerically computed optima and Nash equilibria along the corresponding state trajectories in spite of inaccuracy of approximation of the value functions on some intervals. This implies that, in some cases, using numerical methods to solve dynamic games or dynamic optimization problems with singularities in payoffs may turn out to be successful even if the type of singularity is not known a priori.
To explain this paradox, we derive general rules stating what kind of errors in calculation or computation of the value function do not result in errors in calculation or computation of the optimal control or a Nash equilibrium in a wide class of dynamic optimization problems or dynamic games, depending on partial knowlegde about the optimal or Nash trajectory or its approximation. These general results concern not only errors resulting from using numerical methods but also errors resulting from some preliminary assumptions related to obvious constraints on the value function or iterates approximating it as in Stokey, Lucas and Prescott [1], Martins-Da-Rocha and Vailakis [4], Kamihigashi [8], and Wiszniewska-Matyszkiel and Singh [3].
Thus, the main result is theoretical—we study the conditions under which the paradox that we have obtained in the motivating example appears in dynamic optimization problems or dynamic games and we derive general conclusions concerning some simplifications which can be applied while solving dynamic optimum or Nash equilibrium problems, not only in the case of singularities in payoffs. Those conditions are related to some preliminary constraints of the region in which the optimal or Nash trajectory, correspondingly, is, or to some constraints on where its approximate is, which can be checked ex post.
Our research has been preceded by some papers on theory and applications in which the feedback optimal control has been solved only along the optimal trajectory (e.g., Bock [11]), at the neighborhood of the steady state of the optimal trajectory (e.g., Horwood and Whittle [12,13]), or at the steady state only (e.g, Krawczyk and Tolwinsky [14]). This restriction is caused by either the fact that it is impossible to solve the problem analytically or by the fact that computation in real time is needed. All of those papers are dedicated to finding a partial solution of a dynamic optimization problem even if initially the model is a dynamic game.
Another reason to restrict the calculation of the optimal control or Nash equilibrium problem only to certain subsets of the state space or the product of the time set and the state space is the presence of singularities, as in our motivating example—a model of exploitation of a common fishery by at least two players (countries or fishermen) whose subsistence is based on fishing—which is an extension of the Fish Wars model of Levhari and Mirman [15]. In the model, there is a singularity at the point of extinction, which is not viable, and singularities at zero fishing decisions. The Fish Wars term comes from the Cod Wars between Iceland and UK, which has been the motivation to the seminal paper of Levhari and Mirman [15]. It is the first model of Fish Wars using tools of dynamic games, and it has been designed to describe the situation of extraction of common resources which are the base of subsistence of the fishing countries. In such a case, the depletion of the resource, which may mean even extinction of the species being the base of subsistence of the community extracting it, is disastrous to the community. Because of the same reason, not extracting at all at some time instant (i.e., year) means starvation and is also not acceptable. To emphasize this fact, logarithmic instantaneous and terminal payoff functions are introduced.
The results of Levhari and Mirman have been generalized to n players by Okuguchi [16], Mazalov and Rettieva [17,18] and Rettieva [19], where also cooperative issues were considered. Besides the standard game with the discounted payoff, Nowak [20,21] considers an analogous problem without discounting but either the overtaking optimality criterion or the limiting average and he proves the convergence as the discount factor converges to 1.
Because of the simplicity of calculation of analytic solutions, especially for the infinite time horizon, the model has been analyzed in many aspects and slight modifications. A far from exhausive selection from the literature encompasses: Fischer and Mirman [22,23] (two species); Wiszniewska-Matyszkiel [24] (increasing the number of players, considered not as a process of new actual players entering the game, but the decomposition of the decision-making process among increasing number of subsets of the same set of players), and [25] (analogous with asymmetric players); Kwon [26] (partial cooperation); Breton and Keoula [27] (cooperation and coalition stability in the case of delay in information) and [28] (asymmetric players); Koulovatianos [29] (randomness in the growth function of the resource and assumption that players rationally learn about it); Dutta and Sundaram [30] (a wider class of problems, defining “the tragedy of the commons” as overexploitation of the resource above the “golden rule” level, and looking for dynamics for which the inequality is opposite); Wiszniewska-Matyszkiel [31,32] (games with distorted information in which players do not exactly know the actual bio-economic structure of the problem in which they are involved, i.e., their influence on the resource, and belief-distorted Nash equilibria for such games—in which players introduce beliefs, not necessarily consistent with the actual dynamics, they best-respond to their beliefs, which results in self-verification of those beliefs) and Wiszniewska-Matyszkiel [33] (continuous time); Hanneson [34] (similar games treated as infinitely repeated supergame in which logarithmic part appears) and Górniewicz and Wiszniewska-Matyszkiel [35] (Allee effect causing depletion below some minimal sustainable state), Breton, Daumouni and Zaccour [36] (two species and many specialized players with different levels of cooperation examined). For more exhaustive surveys of the subject of exploitation of common renewable resources, see, e.g., Carraro and Filar [37] or Long [38,39]. This short selection of the papers on this subject shows how important this model is in resource economics. Moreover, it has applications in games of capital accumulation (e.g., Nowak [20]).
If the model is substantially modified, then the analytic calculation of optima and equilibria ceases to be feasible. In such a case, only numerical methods can be used. Therefore, the analysis of dynamic optimization problems or dynamic games of this type using numerical methods is really needed. To that end, one of the consequences of this paper is an answer to the question whether using numerical methods in a dynamic game or dynamic optimization problems with singularities in payoffs resulting from considering instantaneous and terminal payoffs with a logarithmic part, may result in reasonable outcomes. Surprisingly, in this study, the answer is positive even without using any knowledge about the type of singularity a priori.
The main theoretical finding is an answer to the question, whether such a phenomenon may appear in a more general class of dynamic optimization problems or dynamic games and how one can use very incomplete initial knowledge about the solution considered (the optimal control or Nash equilibrium) and the value function to simplify derivation of this solution.
The paper is composed as follows. In Section 2, the Motivating Example of the Fish Wars model with a finite horizon is presented. The problems of finding the dynamic optimum and Nash equilibrium in feedback strategies are solved numerically by an algorithm that does not assume a priori any specific form of solution and the grid is deliberately inaccurate on some subsets of the state space, and the numerical solutions are compared to the analytical solution graphically in Section 2.2, while the computational algorithms are presented in the Appendix. The results for this Motivating Example are the motivation to the theoretical analysis of this paper: Section 3 analyses when, given a certain set of initial conditions, the errors in the value function do not propagate on the optimal paths for a dynamic optimization problem in the general form, while Section 4 analyses possible extensions of those results to Nash equilibria in dynamic games in the general form.
2. The Motivating Example—Fish Wars—The Optima and Equilibria
We consider a dynamic game with n players, being countries exploiting the same marine fishery with one species of fish.
The terminal time T is finite, while the initial time instant is . At , we calculate the salvage value.
The state variable is the biomass, and it is denoted by x. The set of its possible values is . At state x, each of the countries can extract/consume not more than , which reflects the situation in which fish is uniformly distributed over the sea and each country can fish only in its Exclusive Economic Zone, equal for each country.
In this paper, we consider the feedback information structure (according to the notation of Haurie et al. [40]; in dynamic games called also closed loop no-memory or Markovian, while in optimal control also closed loop), i.e., the strategies which we consider are feedback strategies, by which we understand that consumption is a function of both time and state and it is independent of the initial state. Explicitly stating the form of strategies is important, since, although for dynamic optimization, the form of strategies does not influence the results, Nash equilibria for open loop and feedback strategies are usually different, as well as methods to obtain them are different (discussion about difference and rare cases of coincidence of those two kinds of equilibria can be found in e.g., Wiszniewska-Matyszkiel [25]).
The consumption of country i is with . The set of all such functions is denoted by , while
Instantaneous payoff of country i for given is (with ).
The terminal payoff is , which means that after the termination of the game the countries divide the remaining biomass equally.
Payoffs are discounted by a discount factor .
The trajectory X of the biomass resulting from choosing a strategy profile c is
with the initial condition and for some constant .
If we start at from the state , then the total payoff (payoff for short) of player i in the game is
where denotes the vector of all for .
The first notion we are interested in is the social optimum. Analogously to Levhari and Mirman [15] and Okuguchi [16], where such profiles are called cooperative solutions, from a wide class of Pareto optimal profiles, we restrict to strategy profiles c maximizing the sum of payoffs, . This is an obvious choice from the set of optimal profiles if we assume that players’ payoffs are transferable. We shall call such a profile the social optimum. It can be regarded as the optimization of an abstract social planner whose aim is to maximize the joint payoff.
The other concept we are interested in is the Nash equilibrium.
Definition 1.
a) A profile of strategies is a social optimum if
b) A Nash equilibrium is a profile of strategies , such that no player can benefit from unilateral deviation from it, i.e.,
2.1. Analytic Solutions
The results for this model are regarded as quite standard and they have been calculated by applying the standard backwards induction reasoning using the Bellman equation. Although the original papers of Levhari and Mirman [15] and Okuguchi [16] do not state the whole finite horizon solutions and value functions, they can be easily derived to the form presented below. The specific form we cite here together with the proof can be found in Singh [41], the unpublished thesis whose Chapter 5 is based on a part of this paper.
First, we cite the results for the problem of social optimum.
Proposition 1.
There is a unique social optimum profile . It is symmetric and such that, for , for every player, we have
where for . Moreover, for the value function
for .
Next, we state the results for the Nash equilibrium.
Proposition 2.
There is a unique Nash equilibrium profile . It is symmetric and such that for , for every player i, we have
where for . Moreover, for the value function of player i given the strategies of the other players are
for
2.2. Comparison of Analytic and Numerical Results
Here, we compare the actual results, calculated in Section 2.1, to the results of numerical computation according to the Algorithms A1 and A2 (precisely described in Appendix A).
The figures are for the values of the parameters: , , , , , , where is the steady state of the infinite horizon social optimum problem. Nevertheless, due to the reduction of the initial problem to Equations (A1) and (A2) for the social optimum problem and to Equations (A3) and (A4) for the Nash equilibrium problem, as it was done in Appendix A, increasing n increases neither the complexity nor the errors.
We compare the actual results to the numerical results with an initial uniform grid for x of 100 points refined on the interval to about points. For the Nash equilibrium, the number of grid points for o—the sum of decisions of the other players (see Algorithm A2 in Appendix A), for each iteration is 21, and the number of iterations is 4. Intentionally, we do not increase further the number of points in the grid for state variable for very small x or .
2.2.1. The Social Optimum
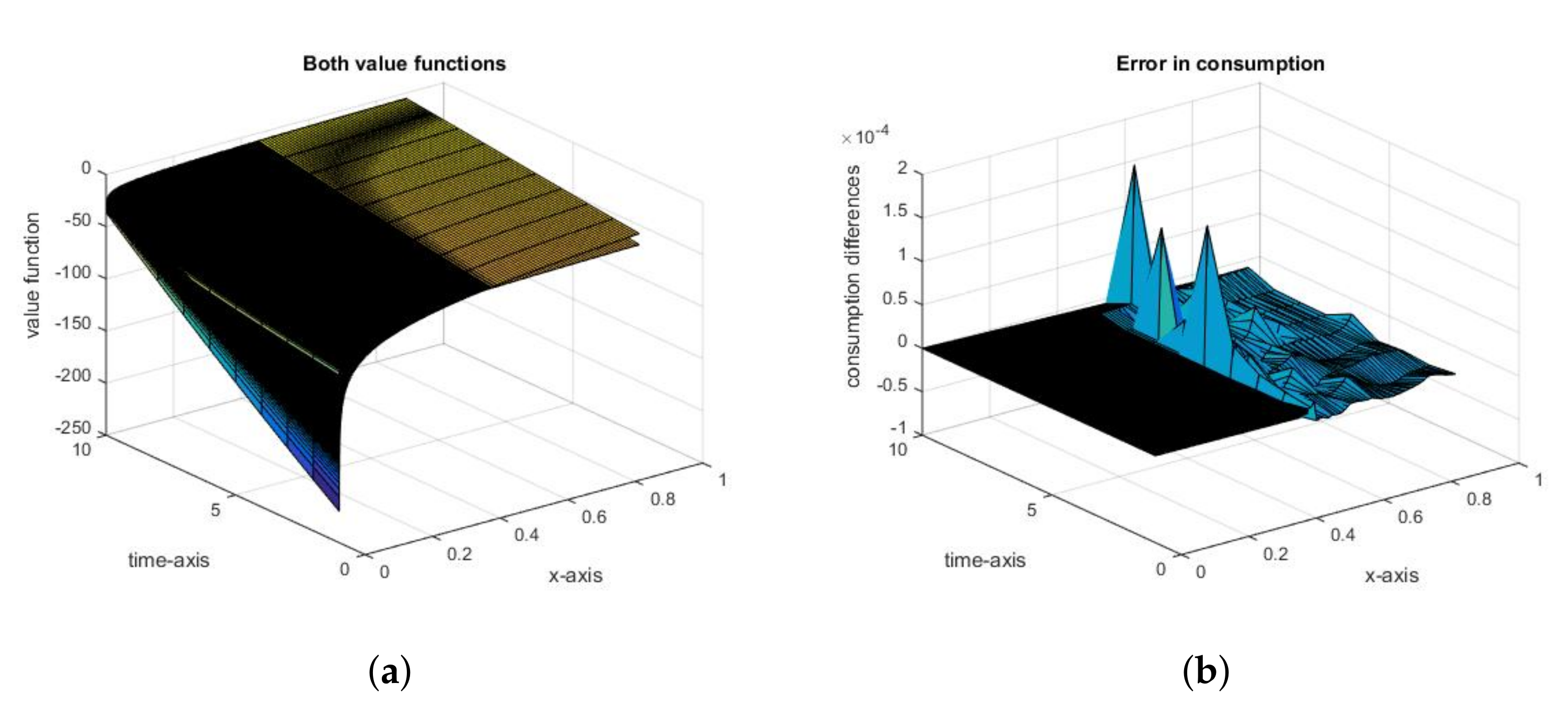
As we can see in Figure 1a, there is a substantial difference between the actual and numerical value functions for two regions of the set of states x: close to 0, the point of a singularity of the actual value function, where the approximate value function is substantially greater, and the interval at which the grid is sparse and the approximate value function is substantially less. In fact, using numerical methods for problems with known points of singularities and not making the grid substantially finer as it converges to the singularity point of the calculated function means that we purposely leave the grid too sparse also for this region. Thus, our procedure means that we a priori allowed the value function to have errors substantially larger on some regions than inherent errors resulting from using numerical methods (if appropriate grids are used).
Despite those differences, both numerical and actual consumptions are apparently identical with errors of rank (see Figure 1b, mainly at the region with the sparse grid).
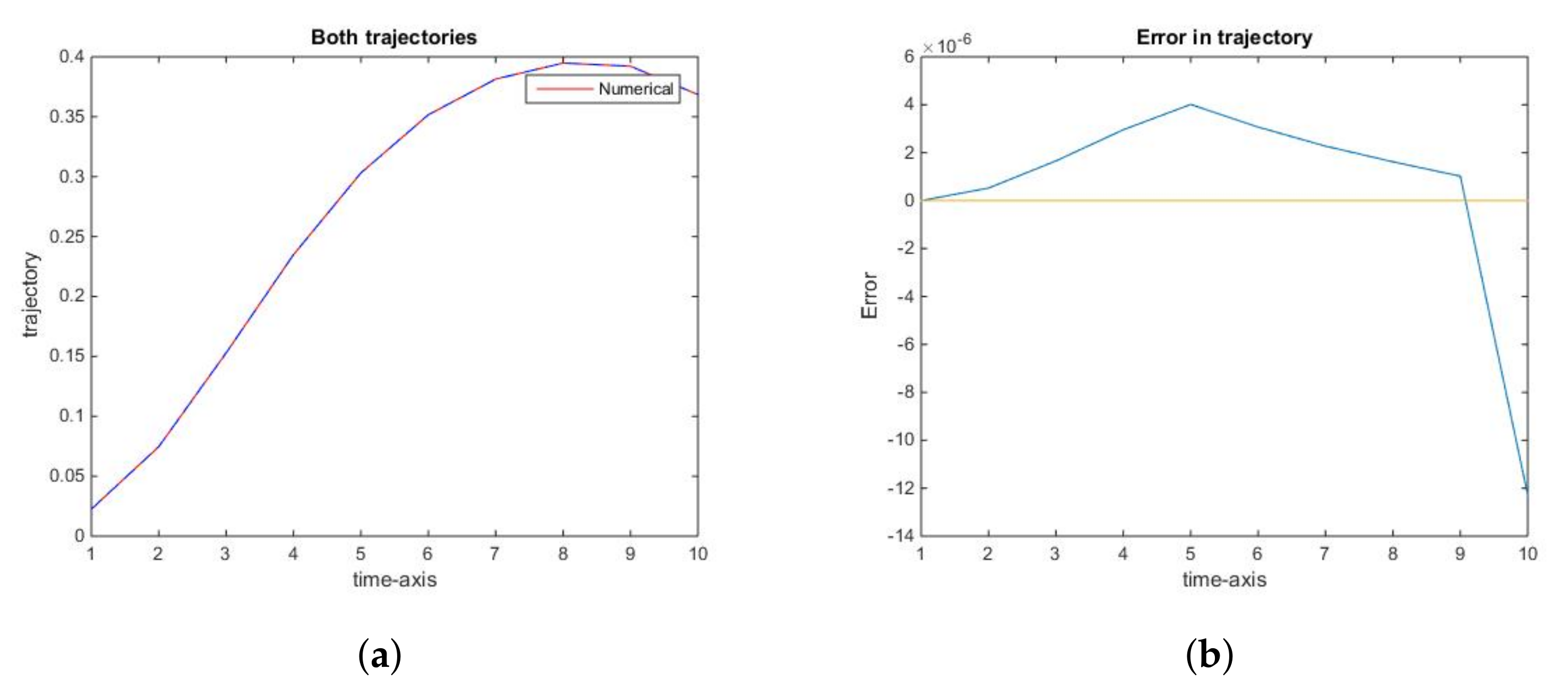
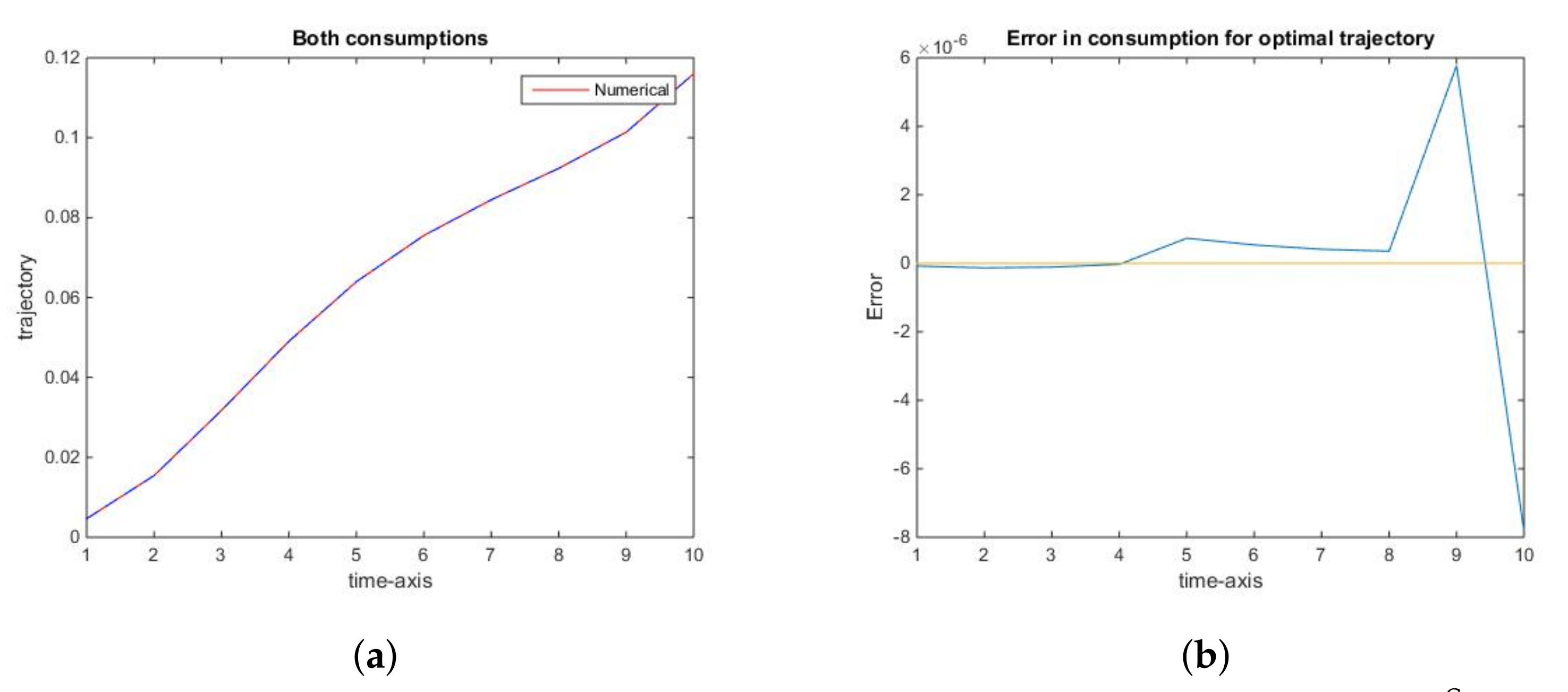
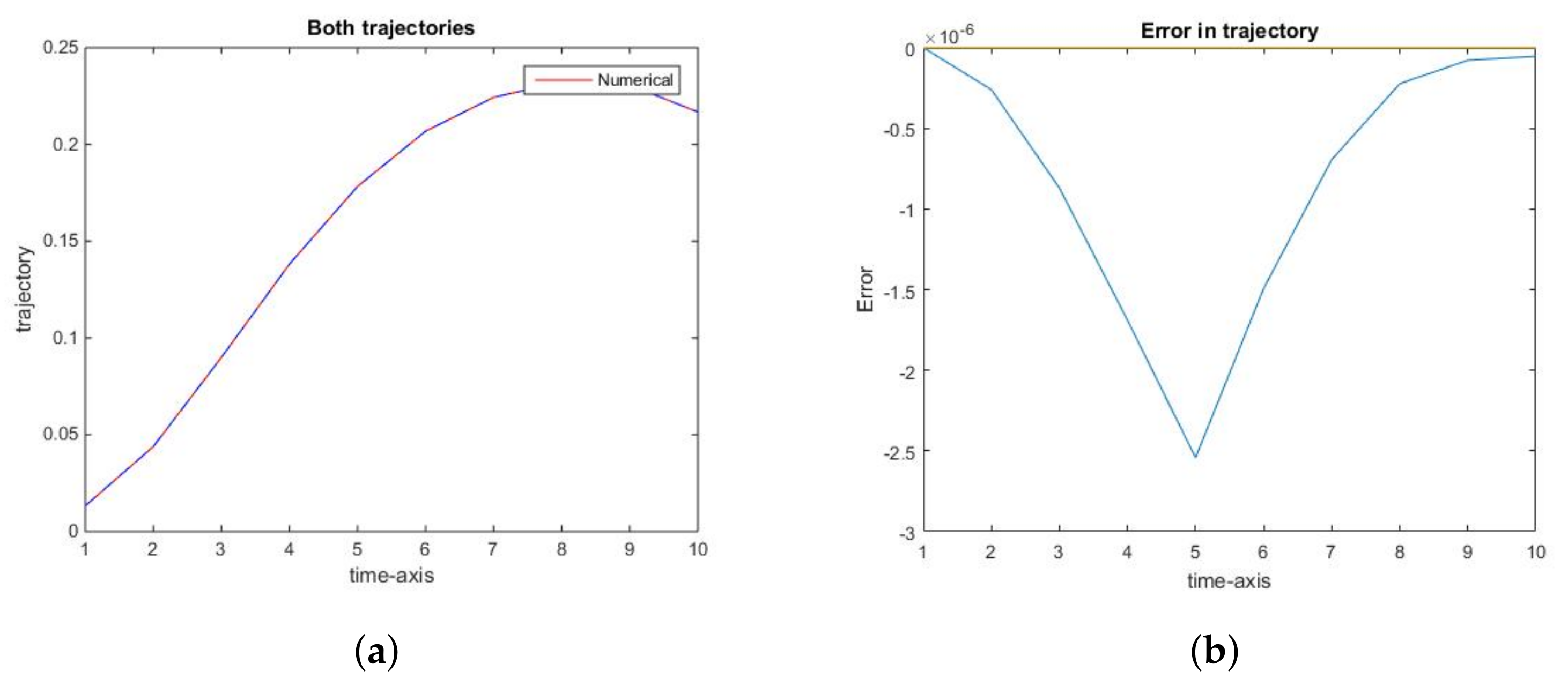
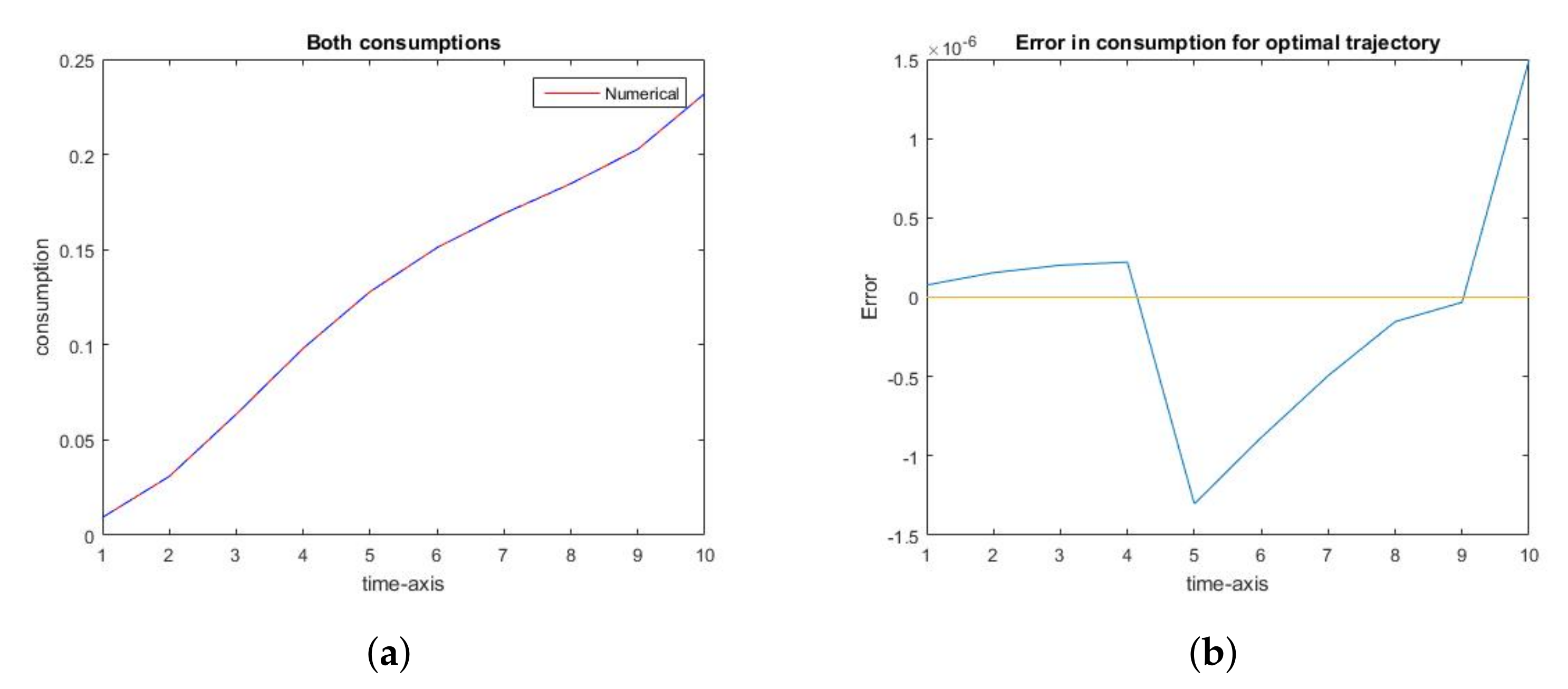
Similarly, the optimal trajectory, as well as the optimal consumption along it, are apparently identical to their numerically computed counterparts (Figure 2a and Figure 3a). In this case, the rank of error decreases to (Figure 2b and Figure 3b). This fact is explained by Theorem 1, especially 1c). Thus, there is no need to refine the grid for x at the interval at which it is sparse, as well as on the set of points close to the singularity at 0, since neither numerical nor analytic optimal trajectory has a non-empty intersection with those sets.
2.2.2. Nash Equilibrium
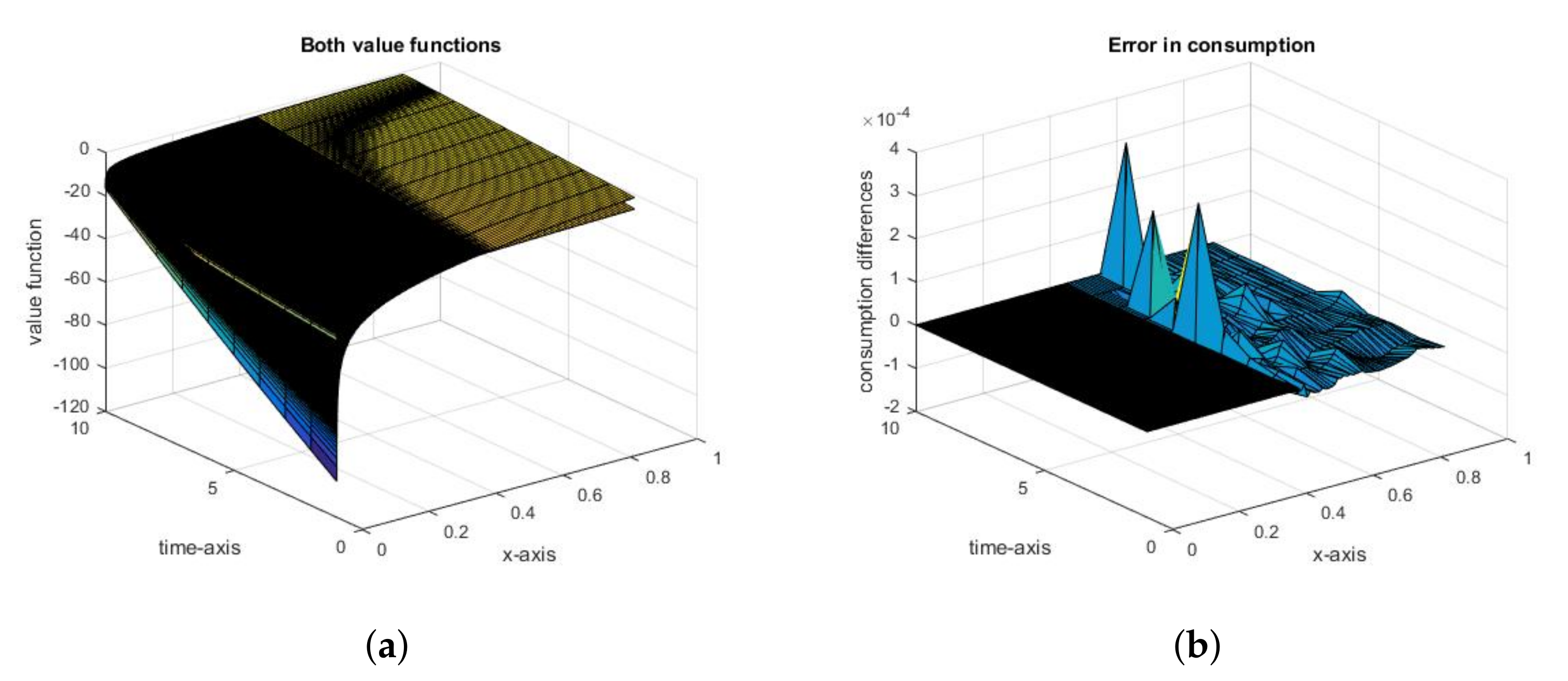
Analogously, for the Nash equilibrium, when we compare the actual results with the results of the numerical analysis, we have the same observations: the difference between the value functions (Figure 4a) is large on the same regions as for the social optimum, with apparently equal consumptions, of error of rank (Figure 4b), with two ranks having better accuracy of the Nash equilibrium consumption and state trajectories (Figure 5a and Figure 6a) with errors of rank (Figure 5b and Figure 6b).
Note that the rank of accuracy for computing equilibria is the same as for the less complex problem of computing social optima. It means that the accuracy of finding the fixed point was very high. Thanks to the iterative procedure of refining the grid on small intervals (see Algorithm A2 described in the Appendix A), it was at a reasonable time cost.
2.3. General Conclusions from the Analysis of the Fish Wars Example
In both cases: the social optimum and the Nash equilibrium, we obtained a substantial error in the value functions on some intervals and high accuracy of the optimum/equilibrium trajectory and consumption path. This situation is rather unusual.
It is worth emphasizing that this holds not only for specific parameters and grids which we present graphically in this paper, but it is a more general rule. Even the first results obtained for the procedure of finding social optima, with quite few points of the grid, assumed to be used to test the code, before refinement of the grid on certain subsets of the set of states was introduced, revealed the same apparent paradox. While there was a considerable error in the value function, especially at the initial time and the regions close to boundaries of the set of states, the social optimum consumption path as well as was computed with unexpected (for this inaccuracy of V) accuracy.
A similar paradox took place while computing the Nash equilibrium. In spite of inaccurate computation of the value function close to the boundaries, the accuracy of computing the equilibrium path is comparable to the distance between the grid points for the sum of decisions of the other players o—the maximal precision that can be expected.
This has been obtained although we haven’t used knowledge about the actual value function and optimal strategy/equilibrium specific to this model while preparing the code for the numerical part, in order to be able to assess the applicability of this approach to a wider class of problems with similar properties.
The only information that we have used is the fact that the value function is continuous, regular for and , the optimal trajectory remains below a certain level, (here, we took ) whenever the initial condition is below this level and it is over some small whenever is, while, in computation of equilibrium, we have also used the fact that the best response of a player is a decreasing function of joint consumption of the others and that the equilibrium exists.
3. When and What Kind of Inaccuracies in Computation or Calculation of the Value Function Do Not Propagate on the Optimal Path in Dynamic Optimization Problems
In this section, we return to the general theoretical motivation of this paper, which is the explanation when paradoxes similar to those obtained for the Motivating Example in Section 2.3: high accuracy of derived optimal state trajectory and consumption path despite the inaccuracy of the corresponding value function on some intervals.
We want to emphasize that a situation in which substantial inaccuracy in a calculation of the value function does not propagate on the optimum path is very unusual. There are examples of a sequence of, regarded as regular, linear quadratic optimization problems, in which an error in calculation of the value function and the resulting “candidate for the optimal control”, for which the Bellman sufficient condition is fulfilled besides an interval with a length converging to zero as some parameter converges to zero that result in false value function and false optimal control on a considerable part of the set of states (Singh and Wiszniewska-Matyszkiel [9]).
We can prove the following theorems, which allow, in a very general environment of dynamic optimization problems, to determine the type of errors in approximation of the value function—either resulting from using numerical computation with low accuracy on some sets, or from replacing the actual value function by some a priori estimation of it on some sets—which do not influence the accuracy of the optimal trajectory and the optimal control path, i.e., the trajectory of the optimal control along the corresponding trajectory.
We consider any discrete time dynamic optimization problem:
- with the time set or , denoted by ; the finite or infinite horizon is denoted by T;
- with discount factor ;
- the set of states ;
- the set of control parameters ;
- the current payoff function ;
- where we consider the feedback controls (which, if independent of time, are denoted as )
- with admissibility constraint for all and for ; the set of admissible controls is denoted by , and
- the transformation of the state variable is given by a function or, more generallywith for all with . In the latter case, there is no need to specify , as it does not influence the results.
- In the case when the time horizon is finite, we also consider a terminal payoff given by a function , paid after the termination of the game.
The aim is to maximize, given and , the objective functional over the set of admissible controls , where is defined by
- for the infinite time horizon, while
- for a finite time horizon T,
- where the trajectory X corresponding to c is given bywith the initial condition .
- Whenever we want to emphasize the dependence of X on a control c, we write , if we want to emphasize the dependence of X on the initial condition, we write , while if we want to emphasize both.
- We assume that the problem is such that J is always well defined although it may be .
- We restrict the set of initial conditions to .
In the finite time horizon case, the necessary and sufficient condition for a function to be the value function, i.e., to fulfill for every , and an admissible control to be the optimal control, is the Bellman equation (see, e.g., Bellman [42], Blackwell [43], Stokey and Lucas [1] Başar and Olsder [44] or Haurie, Krawczyk and Zaccour [40] for various versions)
with the terminal condition
and the inclusion
For the infinite time horizon optimization, the Bellman Equation (3) and the inclusion (5) remain the necessary condition, they also consitute a sufficient condition with certain terminal condition: usually, the standard terminal condition (see, e.g., Stokey, Lucas and Prescott [1], Theorems 4.2–4.4)
Obviously, in the infinite time horizon version of our motivating example, the standard terminal condition (6) does not hold, so it has to be replaced by a weaker one, which, together with the Bellman Equation (3) and the inclusion (5), forms a sufficient condition (Wiszniewska-Matyszkiel [45], Theorem 1):
Terminal conditions (7) and (8) have been proven to be necessary in a large class of optimal control problems including Fish Wars in Wiszniewska-Matyszkiel and Singh [3].
We introduce the following notation:
- V—the actual value function of the dynamic optimization problem;
- —another function regarded as an approximation of V; it may be either a solution of a numerical procedure or the actual V with values on certain subsets replaced by another value, e.g., some constraint known a priori.
- —the maximized function on the right-hand side of the Bellman Equation bellman-general (as a function of c).
- —the maximized function on the right-hand side of the Bellman Equation (3) with V replaced by (as a function of c).
- —the set of optimal controls; we assume that it is non-empty.
- —the set of controls such that ; we assume that it is non-empty.
- .
- For , }.
- .
We can state the following theorem, explaining the apparent paradox of low errors in the computation of the optimal control path despite substantial errors in the computation of the value function in our Motivating Example.
Theorem 1.
Assume also that one of the following holds:
a) for all , and for all ;
b) for all , and for all ;
c) for all .
Then, , for every there exist such that and for every there exist such that .
To prove Theorem 1, we formulate the following lemmata.
Lemma 1.
Consider an arbitrary set and two functions with for all and otherwise.
Then, .
Proof.
Take and any other c.
By the assumptions, . Thus, .
Next, take and assume that . Take .
By the assumptions, , which is a contradiction. □
Lemma 2.
Consider an arbitrary set and two functions with for all with both .
Then, .
Proof.
Take and .
By the assumptions, , which implies that and . Thus, and . □
Proof of Theorem 1.
We start by noting that if , then
and if , then
The proof will be by induction over t.
Together with , we prove that for all (and, consequently, for all ).
First, consider and arbitrary .
In this case, in all the cases a)–c).
Next, consider any and any x such that .
Assume that .
By Lemma 1 applied to the functions and , and Equations (10) and (9), respectively, we obtain in cases a) and b).
By Lemma 2 applied to the functions and , and any of Equation (10) or (9), we obtain that in case c).
Consequently, in all cases a)–c), .
This ends the proof that and that for all .
Take any . Define such that for all and being any selection from , otherwise.
By the fact that also the Bellman equation is fulfilled, so .
Next, take any . Define such that for all and being any selection from , otherwise. Since , by the definition, . □
Theorem 1 states that any error described by a), b), or c) does not influence the quality of computation or calculation of the optimal state trajectory of the state variable and the optimal control path, , i.e., the approximate X and are the same as for an optimal control and every optimal control can be calculated using such an approximate value function and the result will be correct along the corresponding trajectory. Thus, overestimation of V on the set of points (i.e., states or time-state pairs) which never belong to the trajectory corresponding to the control defined by maximization of the Bellman equation with the approximate value function, as well as underestimation of the value function on the set of points which are suboptimal along the optimal trajectory, does not lead to any errors in calculation of the optimal consumption path and the optimal trajectory of the state variable. Similarly, this holds for any errors at points which are neither at the optimal trajectory nor the trajectory corresponding to the control defined by maximization of the Bellman equation with the approximate value function.
This is why we have purposely decreased the number of grid points in computation of the solutions in the Fish Wars example for , although on this set there is a very visible difference between the actual and approximate value functions, in addition to us not caring about large, opposite in sign, differences between the value functions for x very close to 0.
Theorem 2.
Consider a control .
Assume also that one of the following holds:
a) If and for all , and for all , then there exist such that and .
b) If and for all , and all , then there exist such that .
Proof.
Following almost the same lines as proof of Theorem 1, we only concentrate on a single control from or . □
Illustration of Usefulness of Theorems 1 and 2 by Examples
For simplicity, we consider the social optimum problem and we show how Theorem 1 can be applied in order to simplify the computation of the social optimum.
We consider the social optimum in the Levhari and Mirman model, either with a finite horizon, like those analyzed in Section 2, or its infinite horizon version. In the analysis of the infinite horizon problem, we consider the value function and controls dependent on the state variable only, while in the finite horizon, they are dependent also on time.
To show that the method is general and it can be applied for the infinite time horizon, we introduce the limit game of our Motivating Example with the infinite time horizon.
Proposition 3.
Consider the game from Section 2 but with . The social optimum for the infinite horizon problem is with the value function , for and , while the Nash equilibrium is , with the value function for and .
Proof.
The formulae have been proposed by Levhari, Mirman [15], and Okuguchi [16]. Checking that the Bellman Equations (3) and (5) hold is just a substitution. Nevertheless, the proofs of [15,16] lack checking the necessary terminal conditions (7) and (8), while the standard sufficient terminal condition (6) does not hold.
Thus, to complete the proof, we check the terminal conditions (7) and (8). Equation (7) is immediate by the fact that for all admissible .
To prove Equation (8) for the social optimum, we consider a strategy c for which . Thus, there exists a subsequence such that . Thus, .
.
The proof for the Nash equilibrium is analogous. □
Example 1.
Assume that some preliminary analysis has been done for the problem resulted in finding an for which it has been proven that the optimal trajectory for all t. Such an ϵ obviously exists.
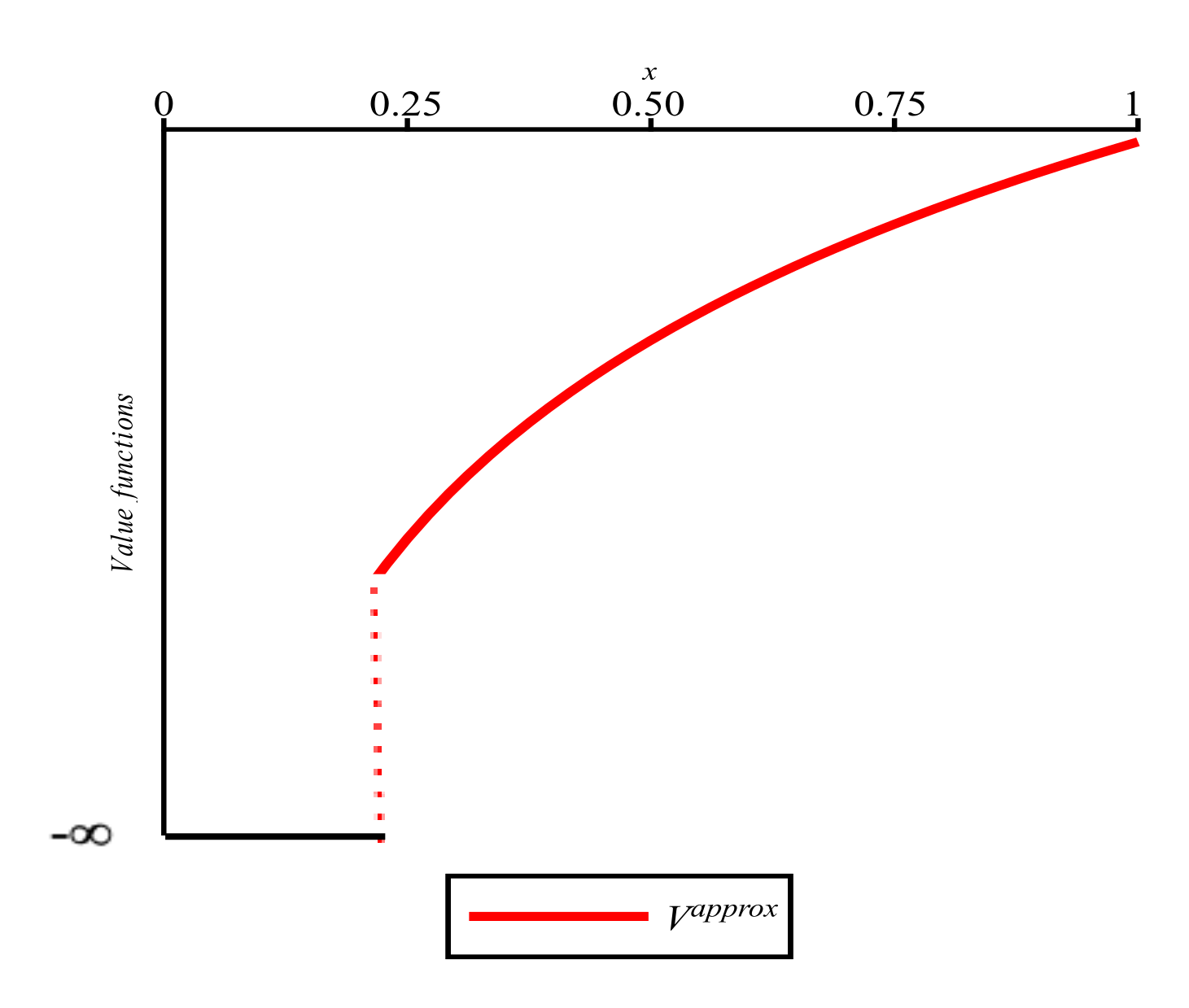
Changing V by assigning for all (see Figure 7) changes neither the optimal trajectory nor the optimal control path.
Thus, if we want to compute the optimal control, this substitution allows us to look for the social optimum and the value function for only and to avoid problems resulting from inaccuracies resulting from closeness to the actual singularity.
Example 2.
Assume again that some preliminary analysis done for the problem has resulted in finding an for which we know that the optimal trajectory for all t.
Since for every control c, changing V by assigning for all , for any control changes neither the optimal trajectory nor the optimal control path.
Thus, if we want to compute the optimal control, this substitution allows us to look for the value function for only (and the resulting optimal control).
Example 3.
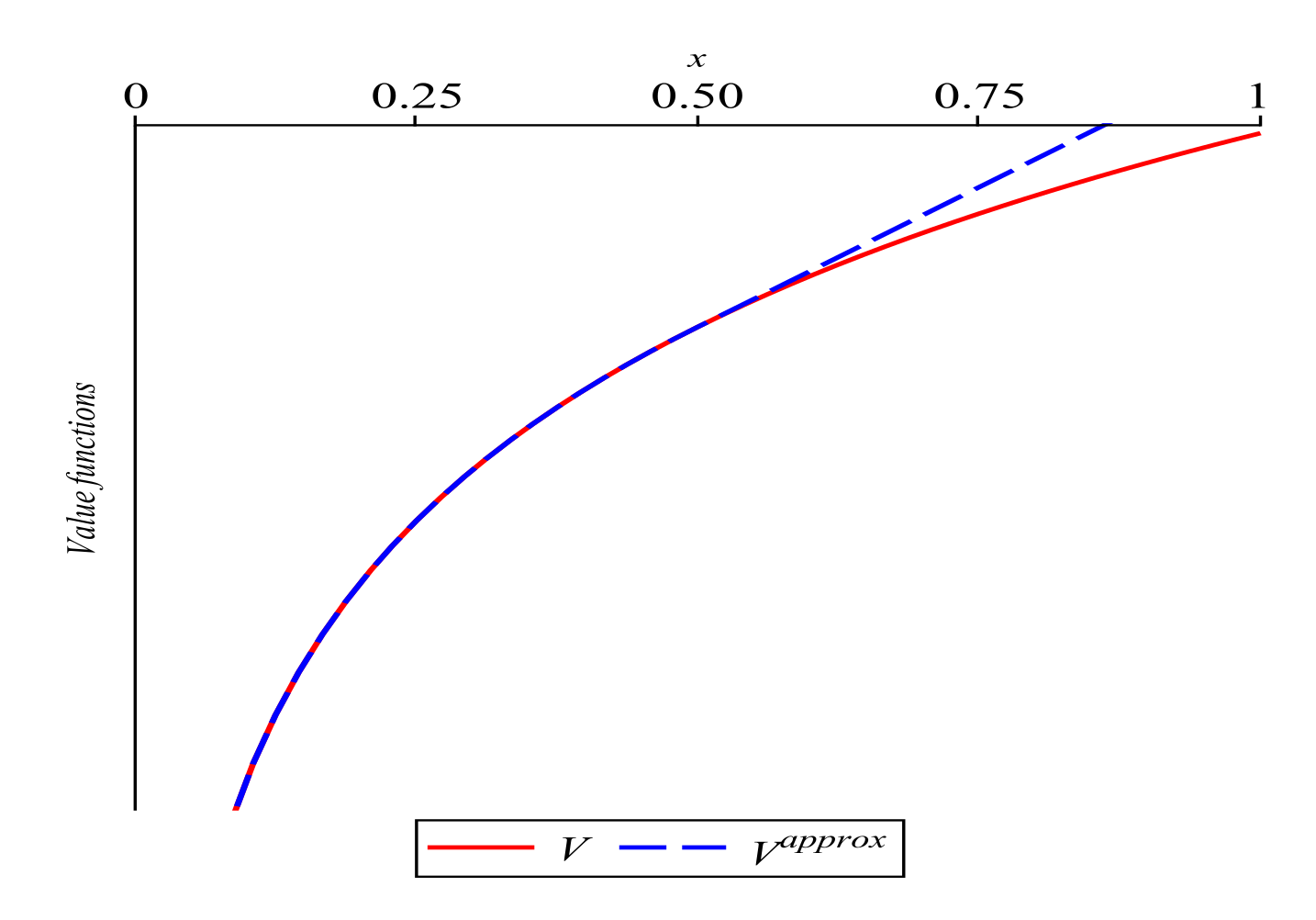
Assume that preliminary analysis done for the problem resulted in finding constants a and b for which we know that is an upper bound for the value function for (see Figure 8) and in discovering the fact that if , then, for all t, the optimal trajectory .
If we change V by assigning for all , and calculate the maximand of the right-hand side of the Bellman equation with , then, if the trajectory for all t, then is the accurate solution path.
Thus, if we want to compute the optimal control, this substitution allows us to restrict the computation of the value function for with one restriction: it is proven that our result is really the optimal control only when for all , the computed is such that for all t.
Example 4.
To define our next , we consider two small numbers ( is fixed, while ϵ will be adjusted) and some obvious overestimation , e.g., . Next, we define as the solution the Bellman equation with one change— in its rhs is replaced by whenever —that fulfills the terminal conditions (7) and (8). Note that such a solution obviously exists and it is unique and it coincides with the actual value function of the problem with an additional constraint on controls besides a small neighbourhood of 0 if ϵ is small enough.
If ϵ is such that the solution is invariant with respect to for on the interval , then we can consider
This assumption is easy to check—it is enough to find ϵ for which the maximum in the rhs of the Bellman equation with the corresponding is attained only for c for which whenever . For our example, it obviously holds, since as .
Then, every control maximizing coincides with the actual optimal control whenever .
Note that, in this case, the only knowledge that we used about the value function is its obvious overestimation .
A theorem stating how to find over- and under-estimations of the actual value function by solving some inequalities analogous to the Bellman equation with the terminal conditions (7) and (8) are in, e.g., Kamihigashi [8].
Those two types of over- and under-estimations of the value functions in the infinite horizon may also appear as a result of approximating the infinite horizon value function by its finite horizon truncations—for nonnegative payoffs, they are underestimations while, for the nonpositive payoffs, they are overestimations—or a result of an iterative procedure. Such procedures of estimating the value function by value iterations is currently being extensively studied in the infinite horizon problems (for various versions, see, e.g., Martins-da-Rocha and Vailakis [4] and Le Van and Morhaim [5] for continuous problems and Kamihigashi [8] for discontinuous problems).
4. When and What Kind of Inaccuracies in Computation or Calculation of the Value Functions Do Not Propagate on the Nash Equilibrium Path in Dynamic Games
Here, we extend the results of Section 3 for Nash equilibria in dynamic games.
We consider a discrete time dynamic game:
- with n players;
- with finite or infinite horizon T;
- the time set or is denoted by ;
- with discount factor ;
- the set of states ;
- players’ sets of decisions
- with notation and ;
- players’ current payoff functions ;
- where we consider feedback strategies (if independent of time, they are written as )
- which fulfill the admissibility constraint for all and for .
- We denote the set of admissible strategies of player i by , while the set of strategies of the remaining players by and the set of strategy profiles by ;
- For simplicity, we introduce the symbol to denote the profile at which player i chooses while the remaining players choose their strategies , which are their strategies resulting from ;
- the transformation of the state variable is determined by or, more generally,with for all with . Specifying is unnecessary since it does not influence the results.
- In the case when the time horizon is finite, we also consider terminal payoffs given by functions , paid after termination of the game.
- The payoff is in the case of the infinite time horizon
- and for finite time horizon T,
- where the trajectory X corresponding to a strategy profile c is given bywith the initial condition .
- Whenever we want to emphasize the dependence of X on a strategy of player i, we write , if we want to emphasize the dependence of X on the initial condition, we write , while if we want to emphasize both. If we also want to emphasize the strategies of the remaining players, we write , or whenever c denotes the whole profile.
- We assume that the problem is such that is always well defined although it may be .
- We restrict the initial condition to .
At a feedback Nash equilibrium, given strategies of the other players , the aim of each player is to maximize, for each and , the objective functional over the set of admissible controls . Formally, it can be defined as
Definition 2.
A feedback Nash equilibrium is a profile of strategies such that for every player i, for every strategy of player i, for every and ,
First, consider a profile of strategies and we fix the strategies of the others .
We introduce the following notations:
- —the actual value function of the dynamic optimization problem of player i given , i.e., .
- —another function regarded as approximation of ; it may be either a solution of a numerical procedure or the actual with values on certain subsets replaced by another values, e.g., some constraints; we assume a priori that, in the finite time horizon T, .
- —the maximized function on the right-hand side of the Bellman Equation (3) rewritten to maximization of player i given ;
- —the maximized function on the right-hand side of the Bellman Equation (3) rewritten to maximization of player i given with replaced by .
- —the set of strategies of player i which are best responses to ; we assume that it is non-empty;
- —the set of strategies such that; we assume that it is non-empty;
- For : ;
- For : ;
- ;
- .
We can state the following theorem, being an immediate corollary of Theorem 1.
Theorem 3.
Consider a profile and assume that all players besides i play and in the case of the infinite time horizon fulfills the terminal conditions (7) and (8).
Assume also that one of the following holds:
a) for all and , otherwise;
b) for all and , otherwise;
c) for all .
Then, , for every there exist such that and for every there exist such that .
Proof.
Immediately, by Theorem 1 applied to the optimization of player i given the strategies of the others . □
Theorem 3 for being the Nash equilibrium profile states that, given the initial state and correct expectation of the other players’ strategies , overestimation of on the set of which never belong to the trajectory corresponding to the control defined by maximization of the corresponding Bellman equation with the approximate value function, as well as underestimation of the value function on the set of points which are suboptimal along the Nash equilibrium trajectory, as well as any error appearing outside the union of those sets does not lead to any errors in calculation of the Nash equilibrium consumption path and trajectory of the state variable. It may help in calculation or computation of a Nash equilibrium only if we know Nash equilibrium strategies of all players but one.
The next question is what we can expect if the expectation of the other players’ strategies is correct only on some subset of .
Generally, we cannot expect that a profile resulting from solving the approximate equation is a Nash equilibrium, since the fixed point may be violated on state or time-state pairs outside , while the definition of feedback Nash equilibrium requires that the whole profile is a fixed point of the joint best response correspondence. Nevertheless, we are able to prove some results.
Theorem 4.
Consider player i and two profiles of strategies of the other players and and assume that .
In the case of the infinite time horizon, we assume also that
Then,
Proof.
First, we prove that and that for every .
We start the proof from the case of a finite time horizon T.
By the definition of the value function, .
We use Lemma 2 to and .
First, note that for every x such that , for every , .
Thus, for every x such that , and by Lemma 2.
Similarly, we obtain the same for every x such that .
Consequently, by the Bellman Equation (3) (rewritten to the game notation), for every x such that , .
Next, consider any and assume that for every x such that , .
We apply Lemma 2 to and .
First, note that for every x such that , for every , .
Thus, for every x such that , and .
Similarly, we obtain the same for every x such that .
Consequently, for every x such that , and , which ends the proof that and in the case of finite time horizon T.
To prove for the infinite time horizon, consider truncations of the game with finite time horizon T and the terminal payoff 0. We denote the payoffs in those games by , the values function by and the best response by .
First, note that, with our assumption for the infinite time horizon, if converges (to a finite or infinite limit), then is equal to the limit (by Wiszniewska-Matyszkiel and Singh [3]). Thus, since for every finite T, , the same applies to the limit.
Does converge?
There are the following cases:
a) is finite. Denote an optimal control by .
Then, , such that for , and
for every .
Thus,
for which implies existence of a limit.
b) . Denote an optimal control by .
Then, , there exists such that for all , .
Thus, , which implies that the limit is .
c) . This means that for every , .
Thus, , there exists such that for all , . Since this holds for all , , which implies convergence to .
This ends the proof that . for all in the case of the infinite time horizon.
The proof that is immediate by the fact that, by (5) rewritten to the game notation, is the set of all functions defined by (by Wiszniewska-Matyszkiel and Singh [3]).
The only thing that remains to be proven is , which we prove by forward induction, as in the proof of Theorem 1.
First, consider and arbitrary .
In this case, .
Next, consider any and any x such that .
Assume that .
Since , .
This ends the proof that . □
Nevertheless, the above results do not guarantee the equivalence of equilibria and profiles calculated using the approximate value function even on the graph of the optimal trajectory, since for a profile to be a feedback Nash equilibrium, also its values for other matter, since it may happen a Nash equilibrium being an extension of a profile with a Nash equilibrium along the corresponding strategy does not exist.
Therefore, let us introduce the following notation.
Consider a profile . For this c, we introduce two types of one stage games.
- —a one stage game with strategies , and payoffs .
- —a one stage game with strategies , and payoffs .
Note that, in and , dependence on reduces to for only.
Since feedback Nash equilibrium has to be defined for all and its value at should coincide with the Nash equilibrium in , to prove the equivalence, we have to guarantee that there will be no problem with the existence of a Nash equilibrium also off the steady state trajectory.
- is the set of profiles from for which a Nash equilibrium in exists for each .We assume that , which is equivalent to the existence of a Nash equilibrium.
- is the set of profiles from for which a Nash equilibrium in exists for each .We assume that .
In the finite horizon, these two sequences of sets of strategy profiles can be defined recursively starting from downwards as follows.
- by:
- –
- ,
- –
- being the set of profiles from for which a Nash equilibrium in exists for each .
- by
- –
- ,
- –
- being the set of profiles from for which a Nash equilibrium in exists for each .
For finite T, we can also define the following sets of profiles.
- being the set of feedback Nash equilibria.
- being the set of profiles that fulfill, starting from T backwards, that is a Nash equilibrium of the static game .
In the infinite horizon, those sets still fulfill the recurrence relation, but we lack a terminal condition.
Theorem 5.
Consider a game with a finite time horizon T.
a) If is a Nash equilibrium, and for every i, both the pair and as well as the pairs and for every fulfill the assumptions of Theorem 3, then there exists a profile which fulfills
and such that for all i, .
b) If and for every i, both the pair and as well as the pairs and for every (Nash equilibrium) fulfill the assumptions of Theorem 3, there exists a Nash equilibrium which fulfills .
Proof.
The proof is based on a recursive construction of a profile coinciding with or , respectively.
By Theorem 3, for every , from a) and b), , for every , there exist such that and for every there exist such that .
a) This applies both to and the profile which we are going to construct. To simplify the notation, let us denote by the union of all .
We define recursively, starting from as follows.
(i) for all x such that and is an equilibrium of . For another x, this part of defining a profile is correct whatever c we write, since is independent of c.
(ii) having defined for all , , define for all x such that , being any equilibrium of for other .
This definition is correct since depends only on for .
By Theorem 4, has the assumed property.
b) Analogously, in the opposite direction. □
Example 5.
Application to the Motivating Example.
Assume that, by some preliminary analysis, we know that the equilibrium profile exists and we know some superset of given (e.g., the fact that for , for all t). We also know that the assumption of Theorem 5 b) is fulfilled. By Theorem 5, there exists a profile with such that .
We have obtained a single-valued for every i and every , and a unique solution to the fixed point problem of the approximate joint best response (if we do not assume symmetry a priori, then we get it as a result, recursively, starting from the terminal time).
Thus, by Theorem 5, the profile calculated by the approximate procedure coincides with the Nash equilibrium profile on . Thus, having calculated , we know the equilibrium on the set .
5. Conclusions and Further Research
After analyzing numerically the problems of social optima and Nash equilibria for Levhari and Mirman Fish Wars model, a dynamic game with logarithmic instantaneous and terminal payoffs, with an algorithm in which we have purposely left the grid sparse on some sets and we haven’t assumed a specific form of solutions a priori, we have obtained a surprisingly good quality of approximation of optima and equilibria along the corresponding trajectories although the value functions were substantially overestimated on some sets and underestimated on some other sets.
This has been a starting point to the main achievement of the paper: formulation of general rules of what type of over- or under-estimation of the value function does result either in incorrectness of the optimal trajectory or in incorrectness of the optimal strategy along it. This applies both to dynamic optimization problems and to Nash equilibria in dynamic games. In this general rule, the over- or under-estimation is not restricted to over- or under-estimation resulting from using numerical methods with grids sparse on some sets, it may also be a result of replacing the value function which is not known exactly by a constraint for it on some intervals a priori in order to simplify further computation or calculation. Depending on whether we allow the value function to be under-estimated, over-estimated, or just incorrectly calculated, on some subsets, we do it at the cost of previous knowledge about the regions in which the optimal trajectory is never in, checking ex post whether the approximate trajectory has non-empty intersection with those subsets, or both, respectively.
Among other things, our results prove that, in some dynamic optimization problems, solving the Bellman equation and finding the maximand of its rhs as the candidate for optimal control for the steady state of the state variable only, may yield a correct result. It also justifies the procedure of calculating the optimal control only along the optimal trajectory. Those two hold with the restrictions as stated above.
The results of this paper are mainly theoretical. Some of them assume some other method of restriction of the set in which the optimal trajectory may be, which has to be used a priori. Some of them require checking ex post whether the calculated trajectory has empty intersections with the sets on which the value function is incorrectly calculated. Although we are able to do this in a specific example, as we have done in Example 4, further research is required to develop more general methods of applying the theoretical results to larger classes of problems. Similarly, how the theoretical findings of this paper can be used for developing numerical methods, in which the approximate solution is not exactly equal to the accurate solution, to obtain criteria of determining when the paradox from our motivating example holds, has to be further studied.
It is worth emphasizing that the results for Nash equilibria are weaker than those for optima. They require an additional assumption that the procedure of calculation of a feedback Nash equilibrium never ends by a dead end. This is because of coupling the players’ dynamic optimization problems in order to find a fixed point in the space of profiles of feedback strategies. This coupling is reduced to finding a sequence of fixed points in spaces of profiles of decisions only if we replace the concept of Nash equilibrium by pre-belief distorted Nash equilibrium (pre-BDNE) mentioned in the introduction in the context of their applications to Fish Wars. Thus, an extension of the results for that solution concept seems a natural next step of this analysis and, by partial de-coupling of the solutions, stronger results can be expected. Another next step is extension of the results to stochastic optimal control problems and stochastic games.
Author Contributions
Conceptualization, A.W.-M.; methodology, A.W.-M.; software, R.S.; validation, A.W.-M. and R.S.; formal analysis, A.W.-M and R.S.; investigation, A.W.-M. and R.S.; resources, A.W.-M. and R.S.; data curation, R.S.; writing—original draft preparation, A.W.-M. and R.S.; writing—review and editing, A.W.-M. and R.S.; visualization, R.S.; supervision, A.W.-M.; project administration, A.W.-M.; funding acquisition, A.W.-M. and R.S. All authors have read and agreed to the published version of the manuscript.
Funding
The project was financed by funds of National Science Centre, Poland, Grant No. 2016/21/B/HS4/00695 (Agnieszka Wiszniewska-Matyszkiel) and 2016/21/N/HS4/00258 (Rajani Singh).
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Numerical Solutions for the Motivating Example
In this Appendix, we present the algorithms used for the motivating Fish Wars example. Generally, the same method of dynamic programming or Bellman equation is used both in analytic and numerical approaches, but, in numerical analysis, we restrict ourselves a priori to symmetric solutions only.
In the numerical approach, like in the analytic approach, we use the Bellman equation to find the value function first, then the optimal solution using it (the social optimum or the best response to the others’ strategies, depending on the case), starting from terminal time T. We do it stage by stage, recursively.
It is important that we purposely don’t use any knowledge about the value function having a special form (in the opposite case, it is enough to approximate numerically the unknown coefficients). All the theoretical assumptions that we make before solving the problem numerically are that the solution exists, it is unique, and symmetric. For the Nash equilibrium, we additionally assume monotonicity of the best responses.
In the procedure of computing the Nash equilibrium, starting from the terminal time, we first calculate an approximate of the value function of a player for optimization given the sum of decisions of the remaining players at this stage o—which, since we assume symmetry, simplifies to knowing the current decision of the other players, , and the best response to o; then, we look for a fixed point at this stage. Subsequently, with the fixed point and the value function for the equilibrium at this stage, we switch to the previous period.
In the calculation of the value function for each stage, we approximate the continuous state space by a finite grid. In the case of computing the Nash equilibrium, we also need a grid for the sum of consumptions of the other players o.
Appendix A.1. Computation of Social Optimum
In this approach, we assume the symmetry of the solution (all identical) a priori, which reduces the computation of the maximum at each stage to one-dimensional.
Since we know that the social optimum profile is symmetric, we can a priori assume this in the Bellman equation and reduce optimization in each stage to one-dimensional.
In this case, the Bellman equation and maximization of its right hand simplify to
and
There is no need to do it a priori in the analytic approach since the symmetry is obtained almost immediately in calculations; nevertheless, in the numerical approach, it substantially reduces complexity.
We use a grid for the state variable . The grid is not uniform—we refine it on the subinterval . The same applies to the computation of a Nash equilibrium.
| Algorithm A1. Computation of the social optimum. |
|
Appendix A.2. Computation of Nash Equilibria
Since we look for symmetric equilibria only, this can be further reduced to one V and one for all players and finding being the best response to the sum of strategies chosen by the others ; therefore, the Bellman equation and maximization of its right-hand side given a profile of strategies of the others can be replaced by the following:
while the equilibrium profile is every profile which fulfills for every t
Again, this restriction is not needed for analytic calculation of equilibrium, in which we obtain uniqueness of Nash equilibrium, and we are able to prove that this unique equilibrium is symmetric.
In the case of numerical computation, we use the reduced Conditions (A3) and (A4) in order to reduce dimensionality.
Besides the grid for the state variable, we need a grid for . The initial grid for o is not very fine since its size is the main component of the cost—we are going to further refine it only on small subsets; initially, it is obtained by taking a uniform grid in and multiplying it by x.
From the fact that the value function tends to as x tends to 0, as well as instantaneous payoff tends to as c tends to 0, we recognize that, for small x, we need a finer grid for o. Therefore, c in the social optimization and both c and o in computation of equilibrium are written in a form and optimization is taken for a over fixed interval or and the grid is uniform in a.
For the same reason, the grid for x was not uniform—it was denser for small x.
| Algorithm A2. Computation of the Nash Equilibrium. |
|
References
- Stokey, N.L. Recursive Methods in Economic Dynamics; Harvard University Press: Cambridge, MA, USA, 1989. [Google Scholar]
- Kamihigashi, T. On the principle of optimality for nonstationary deterministic dynamic programming. Int. J. Econ. Theory 2008, 4, 519–525. [Google Scholar] [CrossRef]
- Wiszniewska-Matyszkiel, A.; Singh, R. Infinite horizon dynamic optimization with unbounded returns—Necessity, sufficiency, existence, uniqueness, convergence and a sequence of counterexamples. SSRN Electron. J. 2018. [Google Scholar] [CrossRef]
- Martins-da Rocha, V.F.; Vailakis, Y. Existence and uniqueness of a fixed point for local contractions. Econometrica 2010, 78, 1127–1141. [Google Scholar] [CrossRef] [Green Version]
- Le Van, C.; Morhaim, L. Optimal growth models with bounded or unbounded returns: A unifying approach. J. Econ. Theory 2002, 105, 158–187. [Google Scholar] [CrossRef] [Green Version]
- Rincón-Zapatero, J.P.; Rodríguez-Palmero, C. Existence and uniqueness of solutions to the Bellman equation in the unbounded case. Econometrica 2003, 71, 1519–1555. [Google Scholar] [CrossRef] [Green Version]
- Matkowski, J.; Nowak, A. On discounted dynamic programming with unbounded returns. Econ. Theory 2011, 46, 455–474. [Google Scholar] [CrossRef] [Green Version]
- Kamihigashi, T. Elementary results on solutions to the Bellman equation of dynamic programming: Existence, uniqueness, and convergence. Econ. Theory 2014, 56, 251–273. [Google Scholar] [CrossRef] [Green Version]
- Singh, R.; Wiszniewska-Matyszkiel, A. A class of linear quadratic dynamic optimization problems with state dependent constraints. Math. Methods Oper. Res. 2020, 91, 325–355. [Google Scholar] [CrossRef] [Green Version]
- Singh, R.; Wiszniewska-Matyszkiel, A. Linear quadratic game of exploitation of common renewable resources with inherent constraints. Topol. Methods Nonl. Anal. 2018, 51, 23–54. [Google Scholar] [CrossRef]
- Bock, H.G. Nonlinear mixed-integer optimal control–from the Maximum Principle Approach to online computation of closed loop controls in real time. In Proceedings of the 14th Viennese Conference on Optimal Control and Dynamic Games, Vienna, Austria, 3–6 July 2018. [Google Scholar]
- Horwood, J.; Whittle, P. Optimal control in the neighbourhood of an optimal equilibrium with examples from fisheries models. Math. Med. Biol. A J. IMA 1986, 3, 129–142. [Google Scholar] [CrossRef]
- Horwood, J.; Whittle, P. The optimal harvest from a multicohort stock. Math. Med. Biol. A J. IMA 1986, 3, 143–155. [Google Scholar] [CrossRef]
- Krawczyk, J.B.; Tolwinski, B. A cooperative solution for the three-nation problem of exploitation of the southern bluefin tuna. Math. Med. Biol. A J. IMA 1993, 10, 135–147. [Google Scholar] [CrossRef]
- Levhari, D.; Mirman, L.J. The great fish war: An example using a dynamic Cournot-Nash solution. Bell J. Econ. 1980, 11, 322–334. [Google Scholar] [CrossRef]
- Okuguchi, K. A dynamic Cournot-Nash equilibrium in fishery: The effects of entry. Decis. Econ. Financ. 1981, 4, 59–64. [Google Scholar] [CrossRef]
- Mazalov, V.V.; Rettieva, A.N. Fish wars with many players. Int. Game Theory Rev. 2010, 12, 385–405. [Google Scholar] [CrossRef]
- Mazalov, V.V.; Rettieva, A.N. The compleat fish wars with changing area for fishery. IFAC Proc. Vol. 2009, 42, 168–172. [Google Scholar] [CrossRef]
- Rettieva, A. A discrete-time bioresource management problem with asymmetric players. Autom. Remote Control 2014, 75, 1665–1676. [Google Scholar] [CrossRef]
- Nowak, A.S. Equilibrium in a dynamic game of capital accumulation with the overtaking criterion. Econ. Lett. 2008, 99, 233–237. [Google Scholar] [CrossRef]
- Nowak, A.S. A note on an equilibrium in the great fish war game. Econ. Bull. 2006, 17, 1–10. [Google Scholar]
- Fischer, R.D.; Mirman, L.J. Strategic dynamic interaction: Fish wars. J. Econ. Dyn. Control 1992, 16, 267–287. [Google Scholar] [CrossRef]
- Fischer, R.D.; Mirman, L.J. The compleat fish wars: Biological and dynamic interactions. J. Environ. Econ. Manag. 1996, 30, 34–42. [Google Scholar] [CrossRef]
- Wiszniewska-Matyszkiel, A. A Dynamic Game with Continuum of Players and Its Counterpart with Finitely Many Players. In Advances in Dynamic Games; Springer: Berlin, Germany, 2005; pp. 455–469. [Google Scholar]
- Wiszniewska-Matyszkiel, A. Open and closed loop Nash equilibria in games with a continuum of players. J. Optim. Theory Appl. 2014, 160, 280–301. [Google Scholar] [CrossRef] [Green Version]
- Kwon, O.S. Partial international coordination in the great fish war. Environ. Resour. Econ. 2006, 33, 463–483. [Google Scholar] [CrossRef]
- Breton, M.; Keoula, M.Y. Farsightedness in a coalitional great fish war. Environ. Resour. Econ. 2012, 51, 297–315. [Google Scholar] [CrossRef]
- Breton, M.; Keoula, M.Y. A great fish war model with asymmetric players. Ecol. Econ. 2014, 97, 209–223. [Google Scholar] [CrossRef]
- Koulovatianos, C. Strategic exploitation of a common-property resource under rational learning about its reproduction. Dyn. Games Appl. 2015, 5, 94–119. [Google Scholar] [CrossRef]
- Dutta, P.K.; Sundaram, R.K. The tragedy of the commons? Econ. Theory 1993, 3, 413–426. [Google Scholar] [CrossRef]
- Wiszniewska-Matyszkiel, A. When beliefs about future create future—Exploitation of a common ecosystem from a new perspective. Strat. Behav. Environ. 2014, 4, 237–261. [Google Scholar] [CrossRef]
- Wiszniewska-Matyszkiel, A. Belief distorted Nash equilibria: Introduction of a new kind of equilibrium in dynamic games with distorted information. Ann. Oper. Res. 2016, 243, 147–177. [Google Scholar] [CrossRef] [Green Version]
- Wiszniewska-Matyszkiel, A. Common resources, optimality and taxes in dynamic games with increasing number of players. J. Math. Anal. Appl. 2008, 337, 840–861. [Google Scholar] [CrossRef] [Green Version]
- Hannesson, R. Fishing as a Supergame. J. Environ. Econ. Manag. 1997, 32, 309–322. [Google Scholar] [CrossRef]
- Górniewicz, O.; Wiszniewska-Matyszkiel, A. Verification and refinement of a two species Fish Wars model. Fisheries Res. 2018, 203, 22–34. [Google Scholar] [CrossRef]
- Breton, M.; Dahmouni, I.; Zaccour, G. Equilibria in a two-species fishery. Math. Biosci. 2019, 309, 78–91. [Google Scholar] [CrossRef] [PubMed]
- Carraro, C.; Filar, J. Control and Game-Theoretic Models of the Environment; Springer Science & Business Media: Berlin, Germany, 2012; Volume 2. [Google Scholar]
- Van Long, N. Dynamic games in the economics of natural resources: A survey. Dyn. Games Appl. 2011, 1, 115–148. [Google Scholar] [CrossRef]
- Van Long, N. Applications of dynamic games to global and transboundary environmental issues: A review of the literature. Strat. Behav. Environ. 2012, 2, 1–59. [Google Scholar] [CrossRef]
- Haurie, A.; Krawczyk, J.B.; Zaccour, G. Games and Dynamic Games; World Scientific Publishing Company: Singapore, 2012; Volume 1. [Google Scholar]
- Singh, R. Calculation of Optima and Equilibria in Dynamic Resource Extraction Problems. Available online: https://depotuw.ceon.pl/handle/item/3317 (accessed on 16 May 2020).
- Bellman, R. Dynamic Programming; Princeton University Press: Princeton, NJ, USA, 1957. [Google Scholar]
- Blackwell, D. Discounted dynamic programming. Ann. Math. Stat. 1965, 36, 226–235. [Google Scholar] [CrossRef]
- Başar, T.; Olsder, G.J. Dynamic Noncooperative Game Theory; SIAM: Bangkok, Thailand, 1998. [Google Scholar]
- Wiszniewska-Matyszkiel, A. On the terminal condition for the Bellman equation for dynamic optimization with an infinite horizon. Appl. Math. Lett. 2011, 24, 943–949. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
(In-)accuracy of the value function versus the accuracy of the optimal control. (a): Numerical and actual value functions, for the social optimum; (b): The error in (the difference between numerical and actual values) for the social optimum.
Figure 1.
(In-)accuracy of the value function versus the accuracy of the optimal control. (a): Numerical and actual value functions, for the social optimum; (b): The error in (the difference between numerical and actual values) for the social optimum.

Figure 2.
Accuracy of the optimal state trajectory. (a): The trajectories of numerical (red) and actual (blue dashed) state variable, , for the social optimum; (b): The error in the trajectory of the state variable, , for the social optimum.
Figure 2.
Accuracy of the optimal state trajectory. (a): The trajectories of numerical (red) and actual (blue dashed) state variable, , for the social optimum; (b): The error in the trajectory of the state variable, , for the social optimum.

Figure 3.
Accuracy of the optimal control trajectory. (a): The optimal consumption path, for the social optimum: numerical (red) and actual (blue dashed); (b): The error in the optimal consumption path, for the social optimum.
Figure 3.
Accuracy of the optimal control trajectory. (a): The optimal consumption path, for the social optimum: numerical (red) and actual (blue dashed); (b): The error in the optimal consumption path, for the social optimum.

Figure 4.
(In-)accuracy of the value function of a players versus the accuracy of the Nash equilibrium strategy. (a): Numerical and actual value functions, , for the Nash equilibrium; (b): The error in (difference between numerical and actual values) for the Nash equilibrium.
Figure 4.
(In-)accuracy of the value function of a players versus the accuracy of the Nash equilibrium strategy. (a): Numerical and actual value functions, , for the Nash equilibrium; (b): The error in (difference between numerical and actual values) for the Nash equilibrium.

Figure 5.
Accuracy of the Nash equilibrium trajectory. (a): The trajectories of numerical (red) and actual (blue dashed) state variable, , for the Nash equilibrium; (b): The error in the trajectory of the state variable, , for the Nash equilibrium.
Figure 5.
Accuracy of the Nash equilibrium trajectory. (a): The trajectories of numerical (red) and actual (blue dashed) state variable, , for the Nash equilibrium; (b): The error in the trajectory of the state variable, , for the Nash equilibrium.

Figure 6.
Accuracy of the trajectory of the Nash equilibrium strategy. (a): The optimal consumption path, numerical (red) and actual (blue dashed) for the Nash equilibrium; (b): The error in the optimal consumption path, for the Nash equilibrium.
Figure 6.
Accuracy of the trajectory of the Nash equilibrium strategy. (a): The optimal consumption path, numerical (red) and actual (blue dashed) for the Nash equilibrium; (b): The error in the optimal consumption path, for the Nash equilibrium.

Figure 7.
Intentional underestimation of the value function on some interval not influencing the optimal state and consumption trajectories in Example 1.
Figure 7.
Intentional underestimation of the value function on some interval not influencing the optimal state and consumption trajectories in Example 1.

Figure 8.
Intentional overestimation of the value function on some interval not influencing the optimal state and consumption trajectories in Example 3.
Figure 8.
Intentional overestimation of the value function on some interval not influencing the optimal state and consumption trajectories in Example 3.

© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Wiszniewska-Matyszkiel, A.; Singh, R. When Inaccuracies in Value Functions Do Not Propagate on Optima and Equilibria. Mathematics 2020, 8, 1109. https://doi.org/10.3390/math8071109
AMA Style
Wiszniewska-Matyszkiel A, Singh R. When Inaccuracies in Value Functions Do Not Propagate on Optima and Equilibria. Mathematics. 2020; 8(7):1109. https://doi.org/10.3390/math8071109
Chicago/Turabian StyleWiszniewska-Matyszkiel, Agnieszka, and Rajani Singh. 2020. "When Inaccuracies in Value Functions Do Not Propagate on Optima and Equilibria" Mathematics 8, no. 7: 1109. https://doi.org/10.3390/math8071109
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.