Non-Targeted Detection of Adulterants in Almond Powder Using Spectroscopic Techniques Combined with Chemometrics

 , and
, and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Sample Preparation
2.2. Spectral Collection
3. Data Analysis
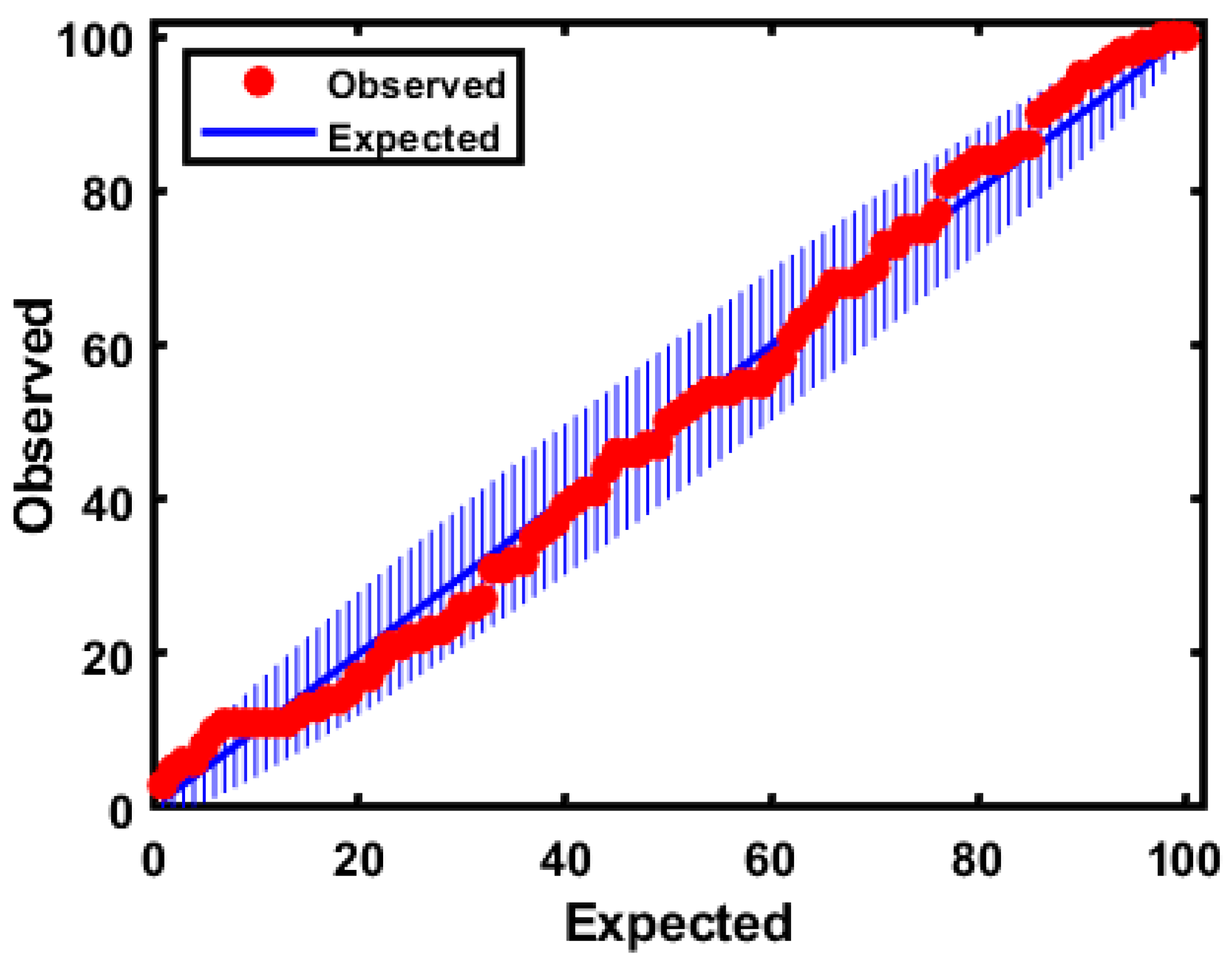
3.1. Spectral Preprocessing
3.2. DD-SIMCA and OCPLS
4. Results and Discussion
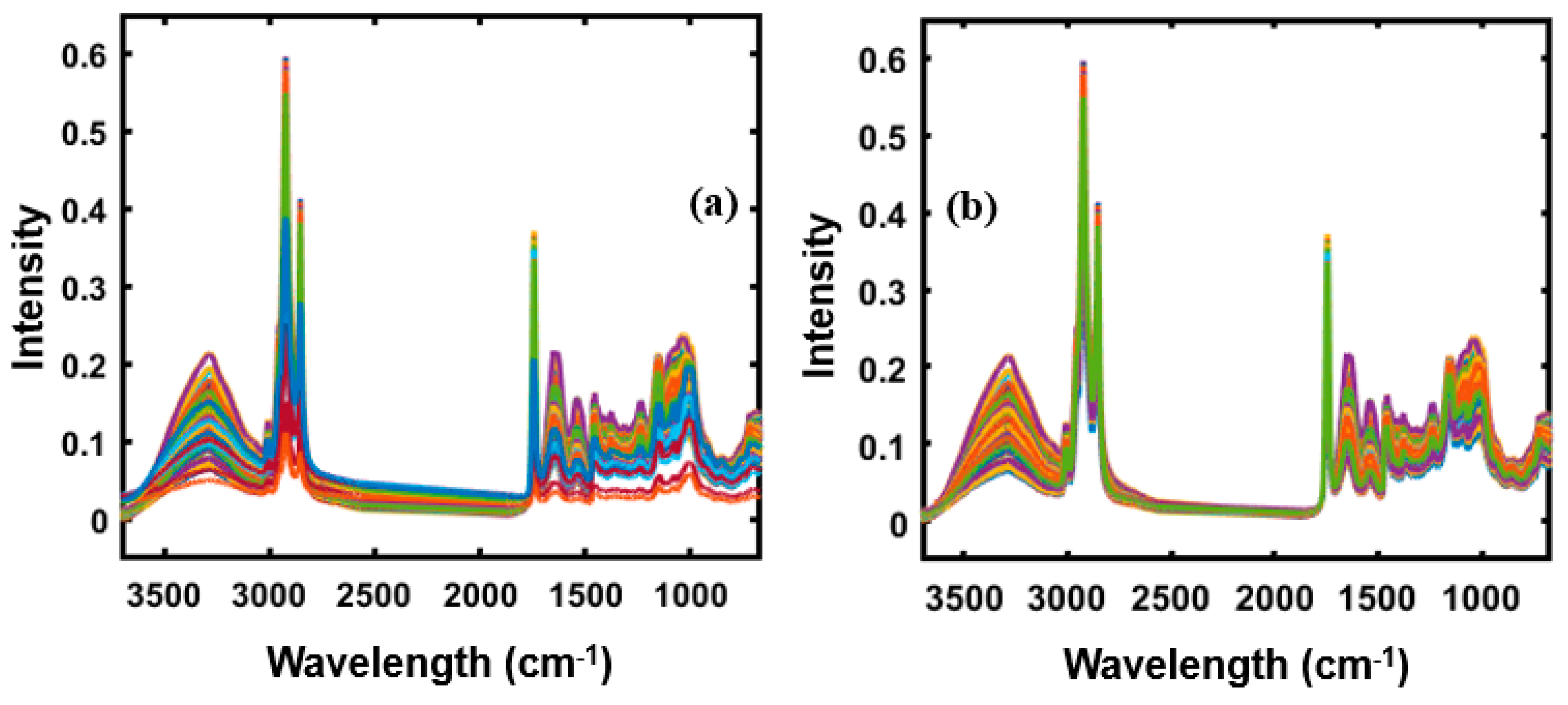
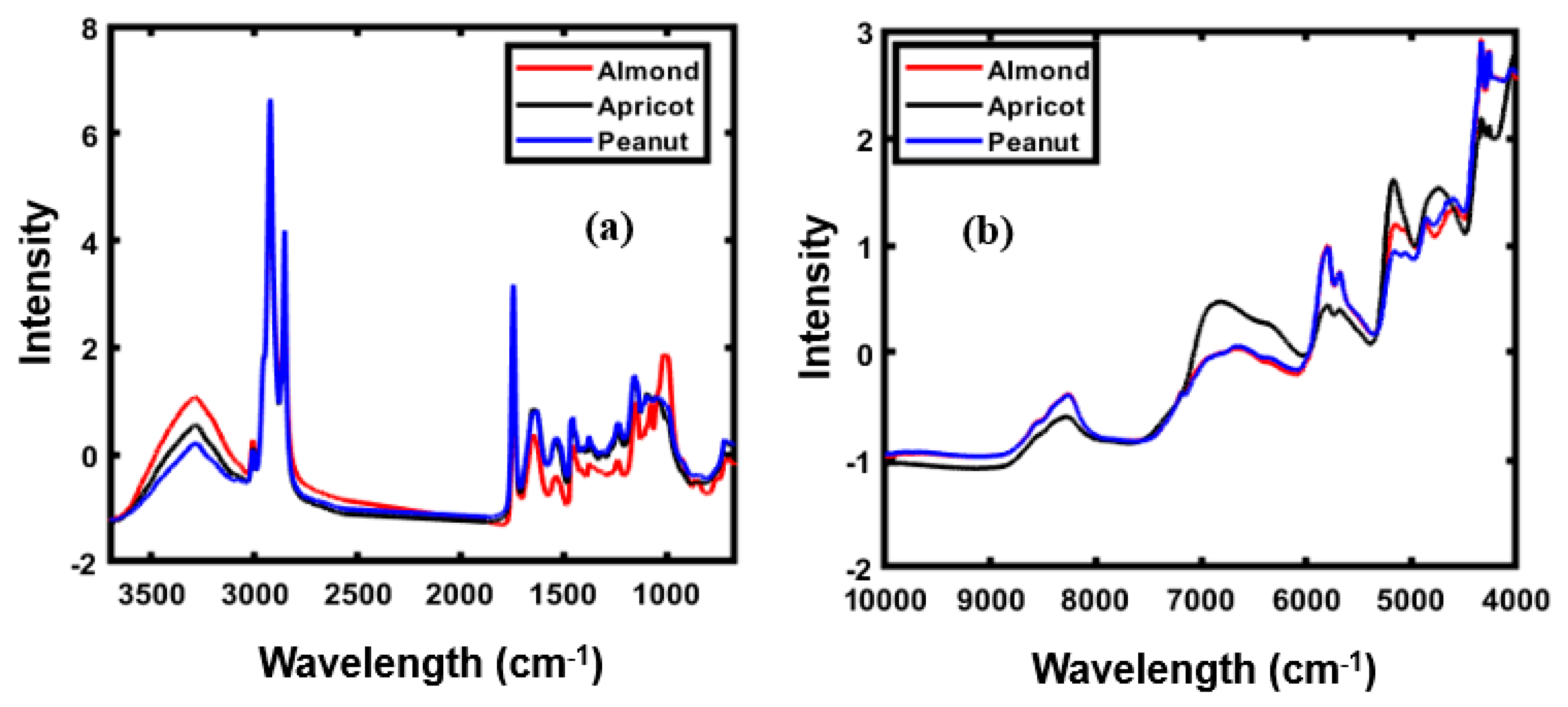
4.1. Spectral Profile of Almond Samples and Adulterants
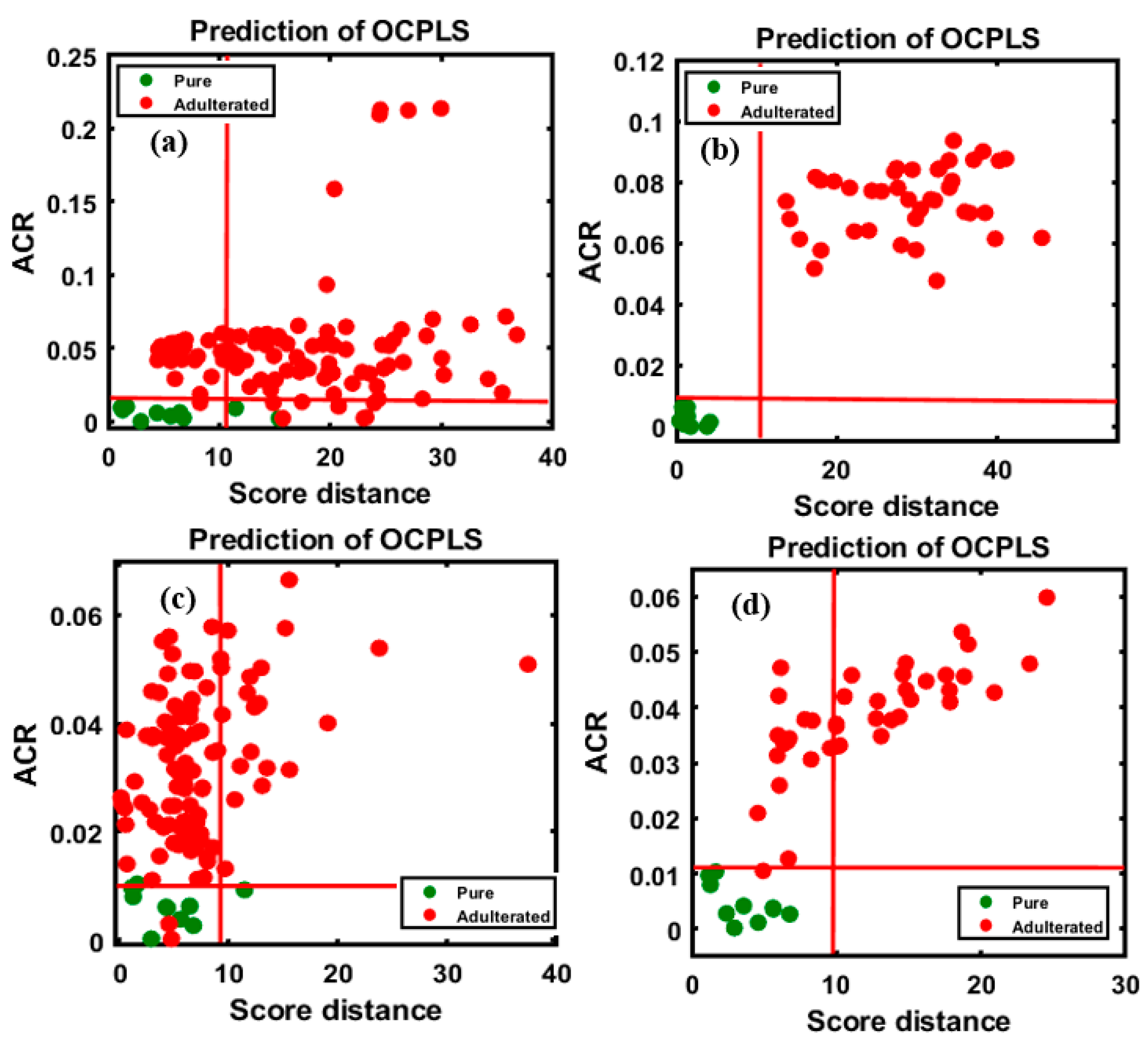
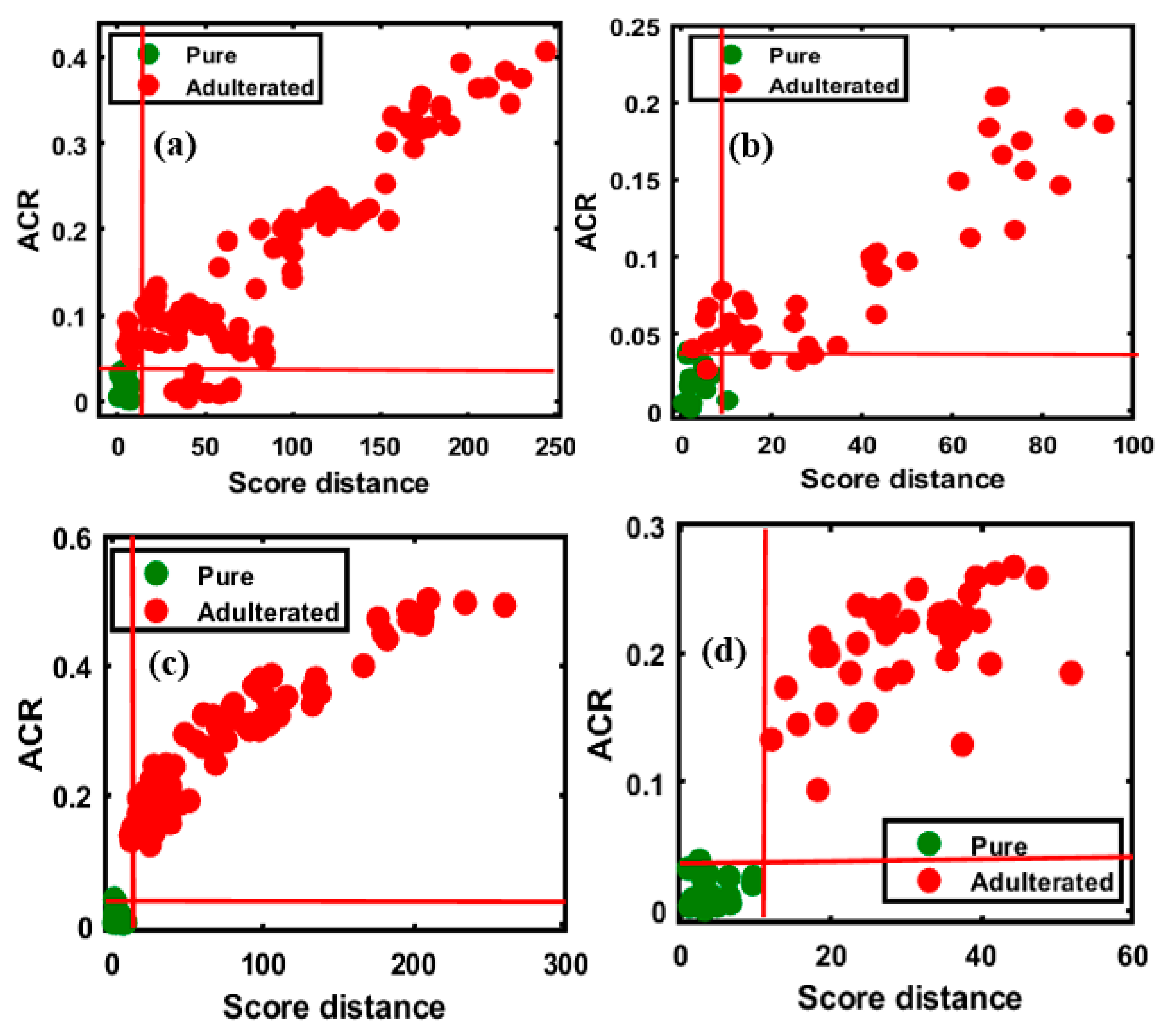
4.2. OCPLS-Based Non-Targeted Detection
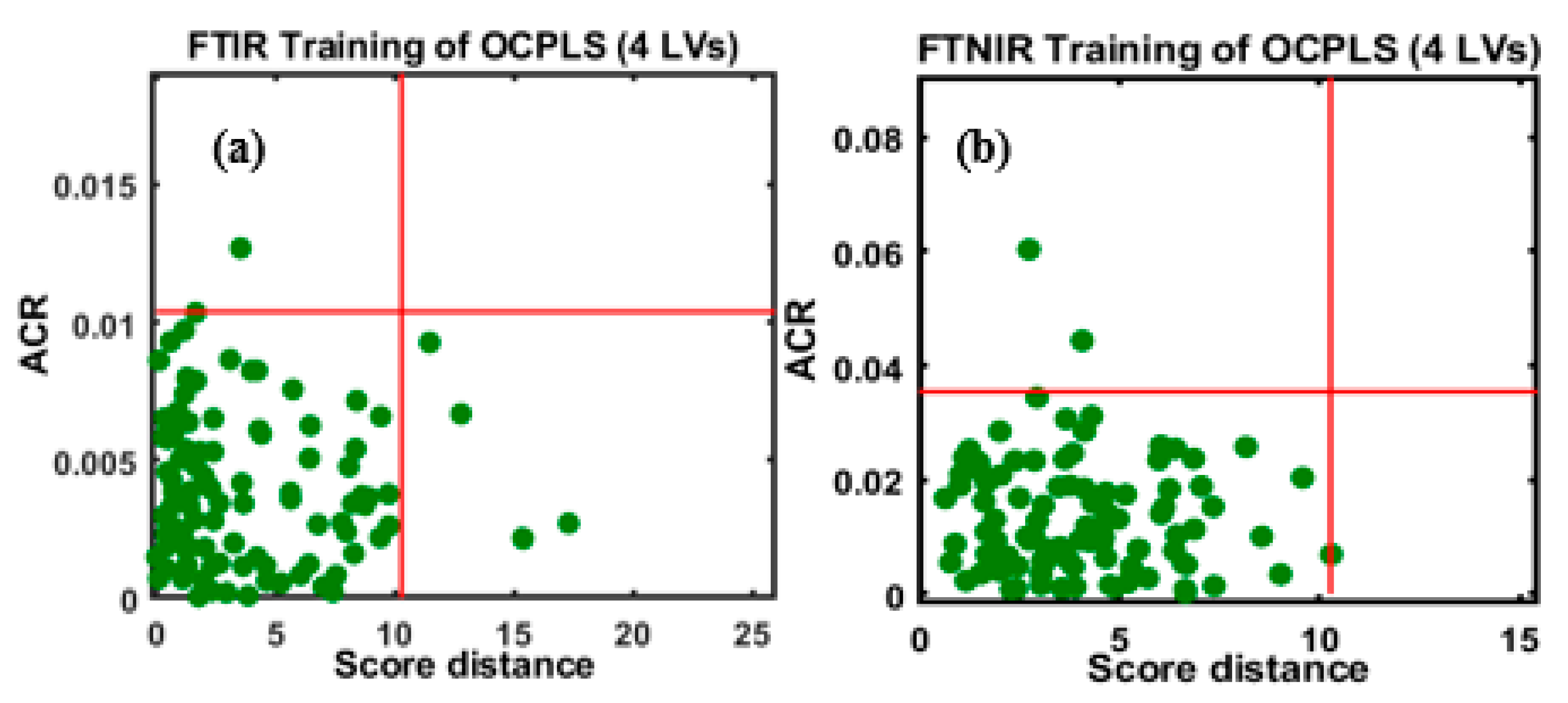
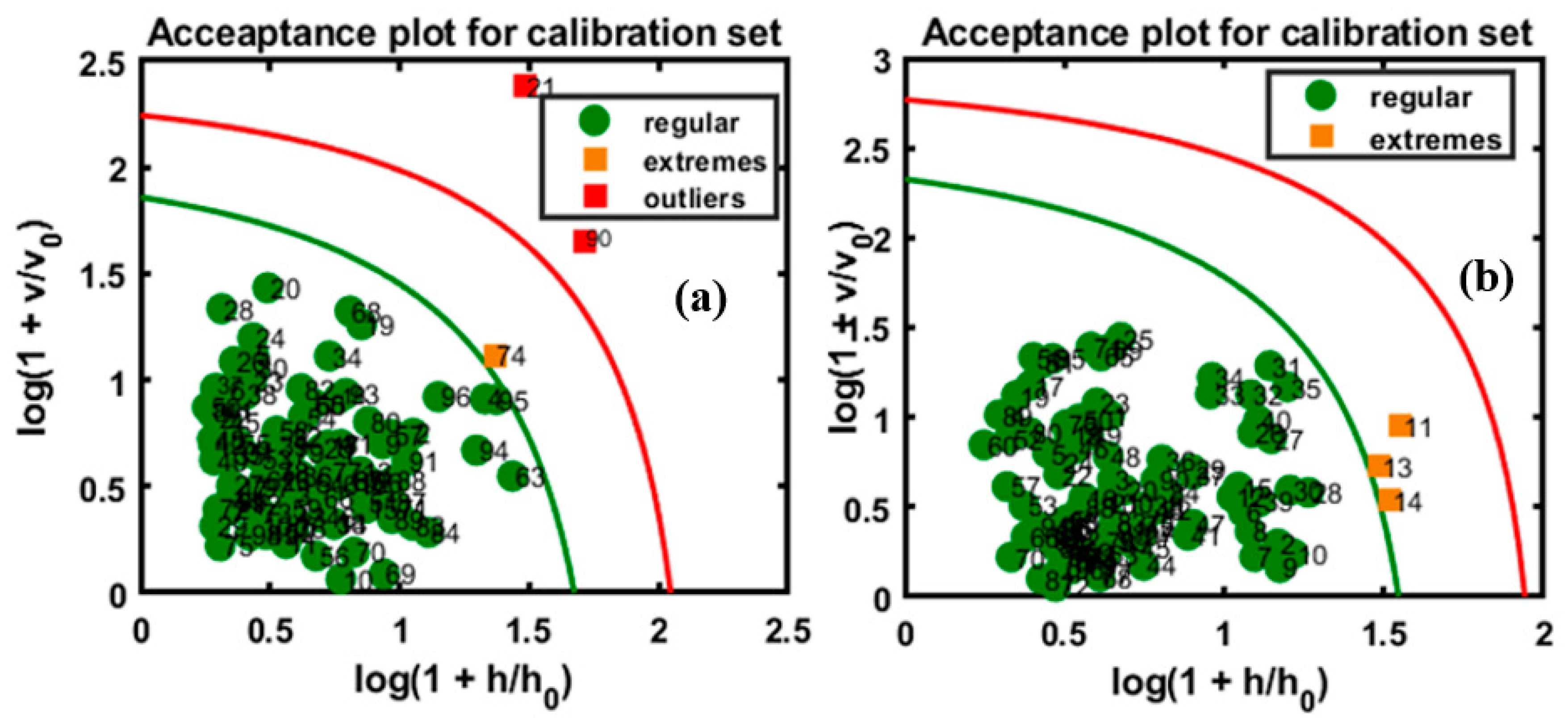
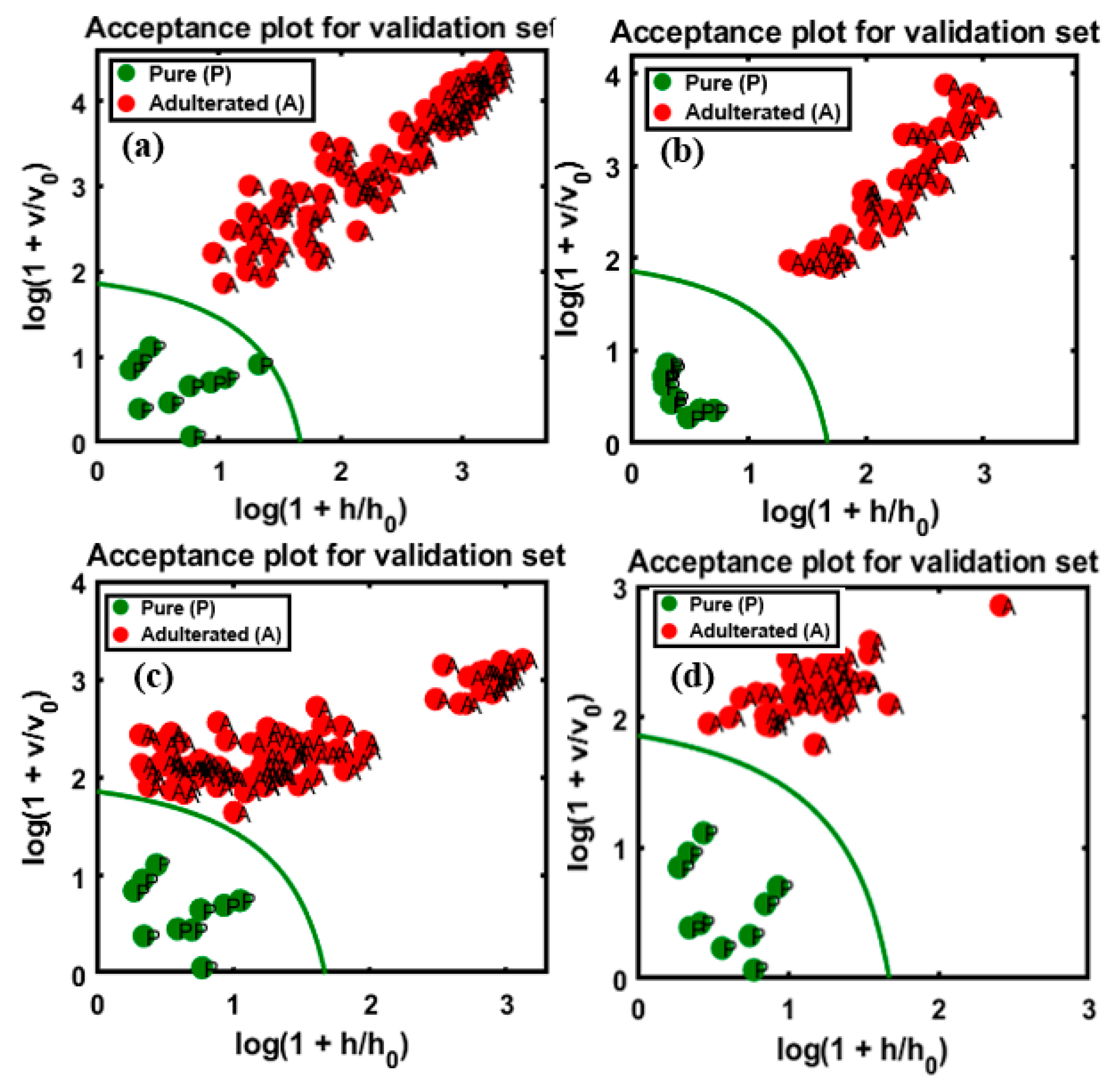
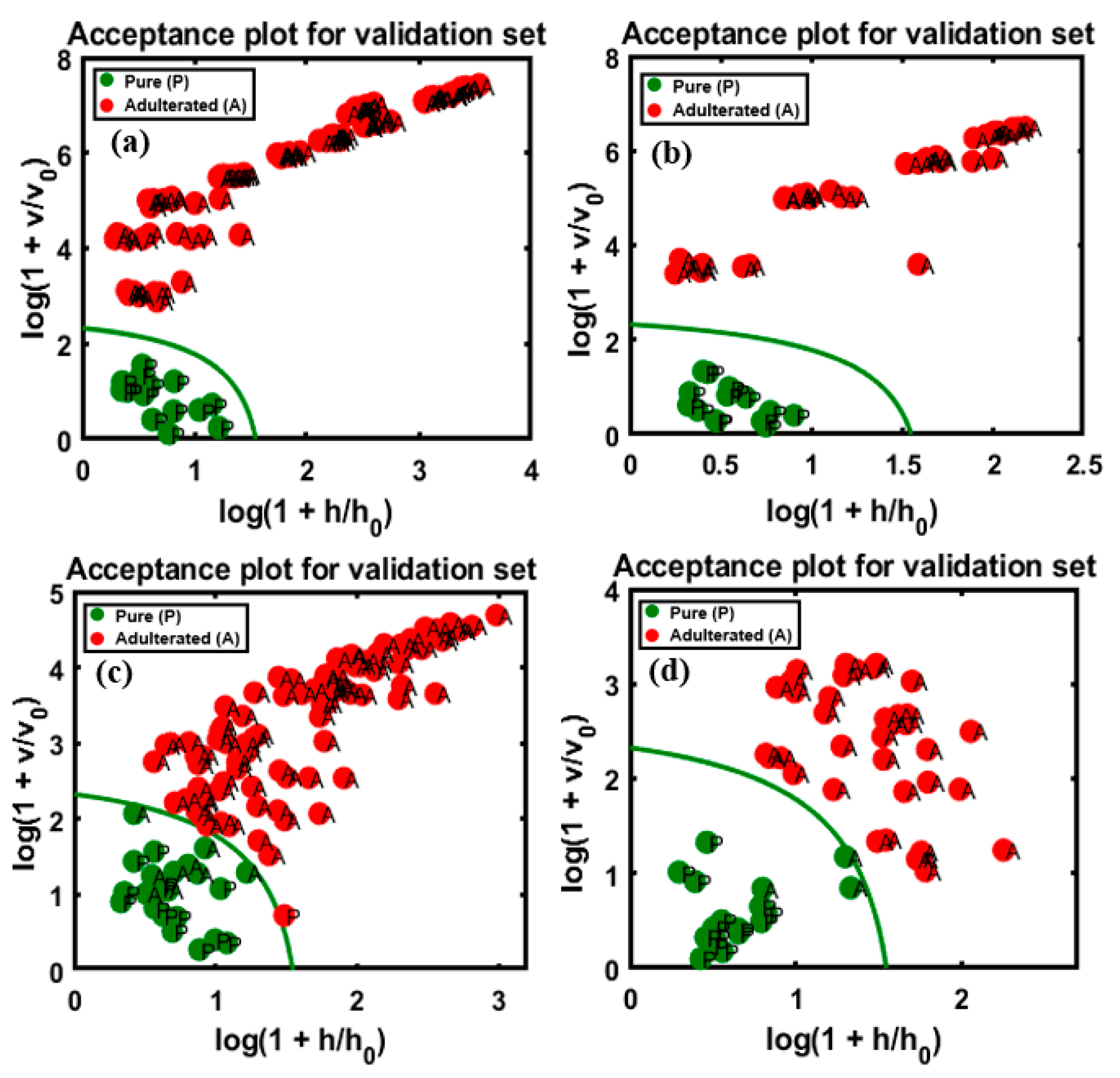
4.3. DD-SIMCA Model Based on FT-IR and FT-NIR Data
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Dourado, F.; Barros, A.; Mota, M.; Coimbra, M.A.; Gama, F.M. Anatomy and Cell Wall Polysaccharides of Almond ( Prunus dulcis D. A. Webb) Seeds. J. Agric. Food Chem. 2004, 52, 1364–1370. [Google Scholar] [CrossRef] [Green Version]
- Esteki, M.; Farajmand, B.; Kolahderazi, Y.; Simal-Gandara, J. Chromatographic Fingerprinting with Multivariate Data Analysis for Detection and Quantification of Apricot Kernel in Almond Powder. Food Anal. Methods 2017, 10, 3312–3320. [Google Scholar] [CrossRef]
- Esteki, M.; Vander, H.Y.; Farajmand, B.; Kolahderazi, Y. Qualitative and quantitative analysis of peanut adulteration in almond powder samples using multi-elemental fingerprinting combined with multivariate data analysis methods. Food Control 2017, 82, 31–41. [Google Scholar] [CrossRef]
- Lohumi, S.; Lee, S.; Lee, W.H.; Kim, M.S.; Mo, C.; Bae, H.; Cho, B.K. Detection of starch adulteration in onion powder by FT-NIR and FT-IR spectroscopy. J. Agric. Food Chem. 2014, 62, 9246–9251. [Google Scholar] [CrossRef] [PubMed]
- Lohumi, S.; Joshi, R.; Kandpal, L.M.; Lee, H.; Kim, M.S.; Cho, H.; Mo, C.; Seo, Y.W.; Rahman, A.; Cho, B.K. Quantitative analysis of Sudan dye adulteration in paprika powder using FTIR spectroscopy. Food Addit. Contam. Part A Chem. Anal. Control. Expo. Risk Assess. 2017, 34, 678–686. [Google Scholar] [CrossRef] [PubMed]
- Dhakal, S.; Chao, K.; Qin, J.; Kim, M.; Schmidt, W.; Chan, D. Detection of metanil yellow contamination in turmeric using FT-Raman and FT-IR spectroscopy. Sens. Agric. Food Qual. Saf. VIII 2016, 9864, 98640A. [Google Scholar]
- Cattaneo, T.M.P.; Holroyd, S.E. The use of near infrared spectroscopy for determination of adulteration and contamination in milk and milk powder: Updating knowledge. J. Near Infrared Spectrosc. 2013, 21, 341–349. [Google Scholar] [CrossRef]
- Li, G.-F.; Yin, Q.-B.; Zhang, L.; Kang, M.; Fu, H.-Y.; Cai, C.-B.; Xu, L. Fine classification and untargeted detection of multiple adulterants of Gastrodia elata BI. (GE) by near-infrared spectroscopy coupled with chemometrics. Anal. Methods 2017, 9, 1897–1904. [Google Scholar] [CrossRef]
- Araújo, A.; Marinho, W.; de Araújo Gomes, A. A Fast and Inexpensive Chemometric-Assisted Method to Identify Adulteration in Acai (Euterpe oleracea) Using Digital Images. Food Anal. Methods 2018, 11, 1920–1926. [Google Scholar] [CrossRef]
- Granato, D.; Putnik, P.; Kovačević, D.B.; Santos, J.S.; Calado, V.; Rocha, R.S.; Da Cruz, A.G.; Jarvis, B.; Rodionova, O.Y.; Pomerantsev, A. Trends in Chemometrics: Food Authentication, Microbiology, and Effects of Processing. Compr. Rev. Food Sci. Food Saf. 2018, 17, 663–677. [Google Scholar] [CrossRef] [Green Version]
- Karunathilaka, S.R.; Farris, S.; Mossoba, M.M.; Moore, J.C.; Yakes, B.J. Non-targeted detection of milk powder adulteration using Raman spectroscopy and chemometrics: Melamine case study. Food Addit. Contam. Part A Chem. Anal. Control. Expo. Risk Assess. 2017, 34, 170–182. [Google Scholar]
- Chen, H.; Tan, C.; Lin, Z. Non-destructive identification of native egg by near-infrared spectroscopy and data driven-based class-modeling. Spectrochim. Acta-Part A Mol. Biomol. Spectrosc. 2019, 206, 484–490. [Google Scholar] [CrossRef] [PubMed]
- Fidelis, M.; Santos, J.S.; Coelho, A.L.K.; Rodionova, O.Y.; Pomerantsev, A.; Granato, D. Authentication of juices from antioxidant and chemical perspectives: A feasibility quality control study using chemometrics. Food Control 2017, 73, 796–805. [Google Scholar] [CrossRef]
- Zontov, Y.V.; Balyklova, K.S.; Titova, A.V.; Rodionova, O.Y.; Pomerantsev, A.L. Chemometric aided NIR portable instrument for rapid assessment of medicine quality. J. Pharm. Biomed. Anal. 2016, 131, 87–93. [Google Scholar] [CrossRef]
- Rodionova, O.Y.; Balyklova, K.S.; Titova, A.V.; Pomerantsev, A.L. Application of NIR spectroscopy and chemometrics for revealing of the ‘high quality fakes’ among the medicines. Forensic Chem. 2018, 8, 82–89. [Google Scholar] [CrossRef]
- Rendon, J.L. IR Spectra of Powder Hematite: Effects of Particle Size and Shape. Clay Miner. 1981, 16, 375–382. [Google Scholar] [CrossRef]
- Kandpal, L.M.; Lee, J.; Bae, H.; Kim, M.S.; Baek, I.; Cho, B.K. Near-infrared transmittance spectral imaging for nondestructive measurement of internal disorder in Korean Ginseng. Sensors 2020, 20, 273. [Google Scholar] [CrossRef] [Green Version]
- Rahman, A.; Faqeerzada, M.A.; Cho, B.K. Hyperspectral imaging for predicting the allicin and soluble solid content of garlic with variable selection algorithms and chemometric models. J. Sci. Food Agric. 2018, 98, 4715–4725. [Google Scholar] [CrossRef] [PubMed]
- Rahman, A.; Park, E.; Bae, H.; Cho, B.-K. Hyperspectral imaging technique to evaluate the firmness and the sweetness index of tomatoes. Agric. Sci. Korean J. Agric. Sci. 2018, 45, 823–837. [Google Scholar]
- Kandpal, L.M.; Lee, J.; Bae, J.; Lohumi, S.; Cho, B.K. Development of a Low-Cost Multi-Waveband LED Illumination Imaging Technique for Rapid Evaluation of Fresh Meat Quality. Appl. Sci. 2019, 9, 912. [Google Scholar] [CrossRef] [Green Version]
- Rinnan, Å.; van den Berg, F.; Engelsen, S.B. Review of the most common pre-processing techniques for near-infrared spectra. TrAC-Trends Anal. Chem. 2009, 28, 1201–1222. [Google Scholar] [CrossRef]
- Zontov, Y.V.; Rodionova, O.Y.; Kucheryavskiy, S.V.; Pomerantsev, A.L. DD-SIMCA – A MATLAB GUI tool for data driven SIMCA approach. Chemom. Intell. Lab. Syst. 2017, 167, 23–28. [Google Scholar] [CrossRef]
- Xu, L.; Yan, S.M.; Cai, C.B.; Yu, X.P. One-class partial least squares (OCPLS) classifier. Chemom. Intell. Lab. Syst. 2013, 126, 1–5. [Google Scholar] [CrossRef]
- Sanahuja Beltrán, A.; Moya, M.S.P.; Pérez, S.E.M.; Teruel, N.G.; Carratalá, M.L.M. Classification of four almond cultivars using oil degradation parameters based on FTIR and GC data. JAOCS J. Am. Oil Chem. Soc. 2009, 86, 51–58. [Google Scholar] [CrossRef]
- Yasmin, J.; Lohumi, S.; Ahmed, M.R.; Kandpal, L.M.; Faqeerzada, M.A.; Kim, M.S.; Cho, B.K. Improvement in purity of healthy tomato seeds using an image-based one-class classification method. Sensors 2020, 20, 2690. [Google Scholar] [CrossRef] [PubMed]
- Lohumi, S.; Mo, C.; Kang, J.-S.; Hong, S.-J.; Cho, B.-K. Nondestructive Evaluation for the Viability of Watermelon (Citrullus lanatus) Seeds Using Fourier Transform Near Infrared Spectroscopy. J. Biosyst. Eng. 2013, 38, 312–317. [Google Scholar] [CrossRef] [Green Version]
- Vlachos, N.; Skopelitis, Y.; Psaroudaki, M.; Konstantinidou, V.; Chatzilazarou, A.; Tegou, E. Applications of Fourier transform-infrared spectroscopy to edible oils. Anal. Chim. Acta 2006, 573–574, 459–465. [Google Scholar] [CrossRef]
- Lohumi, S.; Lee, S.; Lee, H.; Cho, B.K. A review of vibrational spectroscopic techniques for the detection of food authenticity and adulteration. Trends Food Sci. Technol. 2015, 46, 85–98. [Google Scholar] [CrossRef]
- Subramanian, A.; Harper, W.J.; Rodriguez-Saona, L.E. Rapid prediction of composition and flavor quality of cheddar cheese using ATR-FTIR spectroscopy. J. Food Sci. 2009, 74, C292–C297. [Google Scholar] [CrossRef]
- Hernández, S.A.; Zacconi, F.C.M. Sweet almond oil: Extraction, characterization and application. Quim. Nova 2009, 32, 1342–1345. [Google Scholar] [CrossRef] [Green Version]
- Aenugu, H.P.R.; Sathis Kumar, D.; Srisudharson, N.P.; Ghosh, S.S.; Banji, D. Near infra red spectroscopy—An overview. Int. J. ChemTech Res. 2011, 3, 825–836. [Google Scholar]
- Lohumi, S.; Kandpal, L.M.; Seo, Y.W.; Cho, B.K. Net Analyte Signal-based Quantitative Determination of Fusel Oil in Korean Alcoholic Beverage Using FT-NIR Spectroscopy. J. Biosyst. Eng. 2016, 41, 208–220. [Google Scholar] [CrossRef] [Green Version]
- Noah, L.; Robert, P.; Millar, S.; Champ, M. Near-Infrared Spectroscopy As Applied to Starch Analysis of Digestive Contents. J. Agric. Food Chem. 1997, 45, 2593–2597. [Google Scholar] [CrossRef]
- Shenk, J.S.; Jerome, J.; Workman, J.; Westerhaus, M.O. Application of NIR Spectroscopy to Agricultural Products. In Handbook of Near-Infrared Analysis, 3rd ed.; CRC Press: Boca Ratona, FL, USA, 2007. [Google Scholar]
- Yasmin, J.; Ahmed, M.R.; Lohumi, S.; Wakholi, C.; Kim, M.S.; Cho, B.K. Classification method for viability screening of naturally aged watermelon seeds using FT-NIR spectroscopy. Sensors 2019, 19, 1190. [Google Scholar] [CrossRef] [Green Version]
- Kusumaningrum, D.; Lee, H.; Lohumi, S.; Mo, C.; Kim, M.S.; Cho, B.K. Non-destructive technique for determining the viability of soybean (Glycine max) seeds using FT-NIR spectroscopy. J. Sci. Food Agric. 2018, 98, 1734–1742. [Google Scholar] [CrossRef]
- Guille, M.D.; Cabo, N. Infrared Spectroscop y in the Stud y of Edible Oils and Fats. J. Sci. Food Agric. 1997, 75, 1–11. [Google Scholar] [CrossRef]
- Contal, L.; Leon, V.; Downey, G. Detection and quantification of apple adulteration in strawberry and raspberry purees using visible and near infrared spectroscopy. Near Inferared Spectrosc. 2002, 10, 289–299. [Google Scholar] [CrossRef]
- Laasonen, M.; Harmia-Pulkkinen, T.; Simard, C.L.; Michiels, E.; Räsänen, M.; Vuorela, H. Fast Identification of Echinacea purpurea Dried Roots Using Near-Infrared Spectroscopy. Anal. Chem. 2002, 74, 2493–2499. [Google Scholar] [CrossRef]
- Osborne, B. Near-Infrared Spectroscopy in Food Analysis; Wiley: Hoboken, NJ, USA; Chichester, UK, 2000; ISBN 0582494893. [Google Scholar]
- Arbuckle, G.A.; Buecheler, N.M.; Hall, J.W.; Valentine, K.G.; Lefrant, S.; Mevellec, J.Y.; Mulazzi, E. Spectroscopic properties of polyacetylenes synthesized via three modifications of Ziegler-Natta catalytic system. Synth. Met. 1996, 79, 183–188. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DD-SIMCA and OCPLS | Number of Samples | Maximum | Minimum | |
|---|---|---|---|---|
| FT-IR | Calibration | 100 | 100 | 0 |
| Validation 1 | 110 | 50 | 0 | |
| Validation 2 | 50 | 30 | 0 | |
| FT-NIR | Calibration | 100 | 100 | 0 |
| Validation 1 | 110 | 50 | 0 | |
| Validation 2 | 50 | 30 | 0 | |
| Adulterants | Sensitivity (%) | Number of Correctly Classified Samples/Total Number of Samples | Specificity (%) | Number of Correctly Classified Samples/Total Number of Samples | Accuracy (%) | |
|---|---|---|---|---|---|---|
| DD-SIMCA Result | Val-1st variety (almond + apricot) | 100 | 100/100 | 80 | 8/10 | 98.18 |
| Val-2nd variety (almond + apricot) | 100 | 40/40 | 100 | 10/10 | 100 | |
| Val-1st variety (almond + peanut) | 98 | 98/100 | 90 | 9/10 | 97.27 | |
| Val-12nd variety (almond + peanut) | 100 | 40/40 | 100 | 10/10 | 100 | |
| OCPLS Result | Val-1st variety (almond + apricot) | 100 | 100/100 | 100 | 10/10 | 100 |
| Val-2nd variety (almond + apricot) | 100 | 100/100 | 100 | 10/10 | 100 | |
| Val-1st variety (almond + peanut) | 100 | 100/100 | 100 | 10/10 | 100 | |
| Val-2nd variety (almond + peanut) | 100 | 100/100 | 100 | 10/10 | 100 | |
| Adulterants | Sensitivity (%) | Number of Correctly Classified Samples/Total Number of Samples | Specificity (%) | Number of Correctly Classified Samples/Total Number of Samples | Accuracy (%) | |
|---|---|---|---|---|---|---|
| DD-SIMCA Result | Val-1st variety (almond + apricot) | 100 | 100/100 | 93 | 14/15 | 99.13 |
| Val-2nd variety (almond + apricot) | 97 | 39/40 | 93 | 1/15 | 90.90 | |
| Val-1st variety (almond + peanut) | 100 | 100/100 | 93 | 14/15 | 99.13 | |
| Val-2nd variety (almond + peanut) | 100 | 40/40 | 93 | 14/15 | 98.18 | |
| OCPLS Result | Val-1st variety (almond + apricot) | 100 | 100/100 | 100 | 15/15 | 100 |
| Val-2nd variety (almond + apricot) | 100 | 40/40 | 100 | 15/15 | 100 | |
| Val-1st variety (almond + peanut) | 91 | 91/100 | 93 | 14/15 | 91.30 | |
| Val-2nd variety (almond + peanut) | 92.5 | 37/40 | 100 | 15/15 | 94.54 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Faqeerzada, M.A.; Lohumi, S.; Joshi, R.; Kim, M.S.; Baek, I.; Cho, B.-K. Non-Targeted Detection of Adulterants in Almond Powder Using Spectroscopic Techniques Combined with Chemometrics. Foods 2020, 9, 876. https://doi.org/10.3390/foods9070876
Faqeerzada MA, Lohumi S, Joshi R, Kim MS, Baek I, Cho B-K. Non-Targeted Detection of Adulterants in Almond Powder Using Spectroscopic Techniques Combined with Chemometrics. Foods. 2020; 9(7):876. https://doi.org/10.3390/foods9070876
Chicago/Turabian StyleFaqeerzada, Mohammad Akbar, Santosh Lohumi, Rahul Joshi, Moon S. Kim, Insuck Baek, and Byoung-Kwan Cho. 2020. "Non-Targeted Detection of Adulterants in Almond Powder Using Spectroscopic Techniques Combined with Chemometrics" Foods 9, no. 7: 876. https://doi.org/10.3390/foods9070876