Combined Generative Adversarial Network and Fuzzy C-Means Clustering for Multi-Class Voice Disorder Detection with an Imbalanced Dataset


Abstract
:1. Introduction and Literature Review
1.1. Literature Review
1.2. Research Gaps and Motivation
- Some existing works [12,16,17] did not apply cross-validation during their performance evaluation of the algorithms. The first concern is that one may pick up a biased training dataset to train the detection model, which takes advantages of this bias by yielding high accuracy. Secondly, not all the data were evaluated, which may affect the fine tuning of the model and the robustness of its applicability in real-world scenarios.
- There is room for improvement in the accuracy, sensitivity, and specificity of voice disorder detection models [13,14,15,16,18]. Particularly in smart healthcare applications, the performance of the machine learning model has high expectations, as such applications are related to the health status of humans.
- Current works [12,13,14,15,16,17,18] have formulated the voice disorder detection problem as binary detection that only outputs a healthy or pathological result. It is desirable for machine learning algorithms to suggest the actual type of voice disorder to minimize screening time by medical professions.
- A 10-fold cross validation is adopted for the performance evaluation of the voice disorder detection algorithm.
- The proposed algorithm incorporates a generative adversarial network and fuzzy c-means clustering to improve the performance of the detection model.
- Voice disorder classification is formulated as a multi-class detection problem, thereby allowing the actual type of voice disorder to be suggested.
- A generative adversarial network is proposed to generate new training data, which will reduce the influence of imbalanced datasets and improve the performance of the voice disorder detection model.
1.3. Research Contributions
- A conditional generative adversarial network (CGAN) and improved fuzzy c-means clustering (IFCM) algorithm named CGAN-IFCM is proposed to enable the multi-class detection of voice disorders.
- CGAN offers dual benefits, not only reducing the influence of imbalanced datasets but also generating new training data to improve the performance of the voice disorder detection model. In this way, the gap between sensitivity and specificity in the detection model can be reduced. The results indicate that the proposed CGAN-IFCM outperforms stand-alone IFCM by 10–12.6% and 5.8–16.2% for the true negative rate (TNR) and true positive rate (TPR), respectively.
- IFCM addresses the limitations of existing fuzzy c-means clustering (FCM). IFCM increases performance by introducing interactions between adjacent data points in the fuzzy membership function. The data point and its neighboring data points in feature space will have a high probability to be grouped into the same cluster. The results reveal that the proposed CGAN-IFCM improves the TNR and TPR by 7.3–9% and 3.1–12%, respectively.
- Compared with existing works, the proposed CGAN-IFCM improves the TNR and TPR by 9.9–43.5% and 9.1–44.8%, respectively.
2. Materials and Methods
2.1. Voice Disorders Databases
2.1.1. Saarbruechen Voice Database (SVD)
2.1.2. Voice ICar fEDerico II (VOICED)
2.2. Design of the Voice Disorder Detection Model using CGAN-IFCM
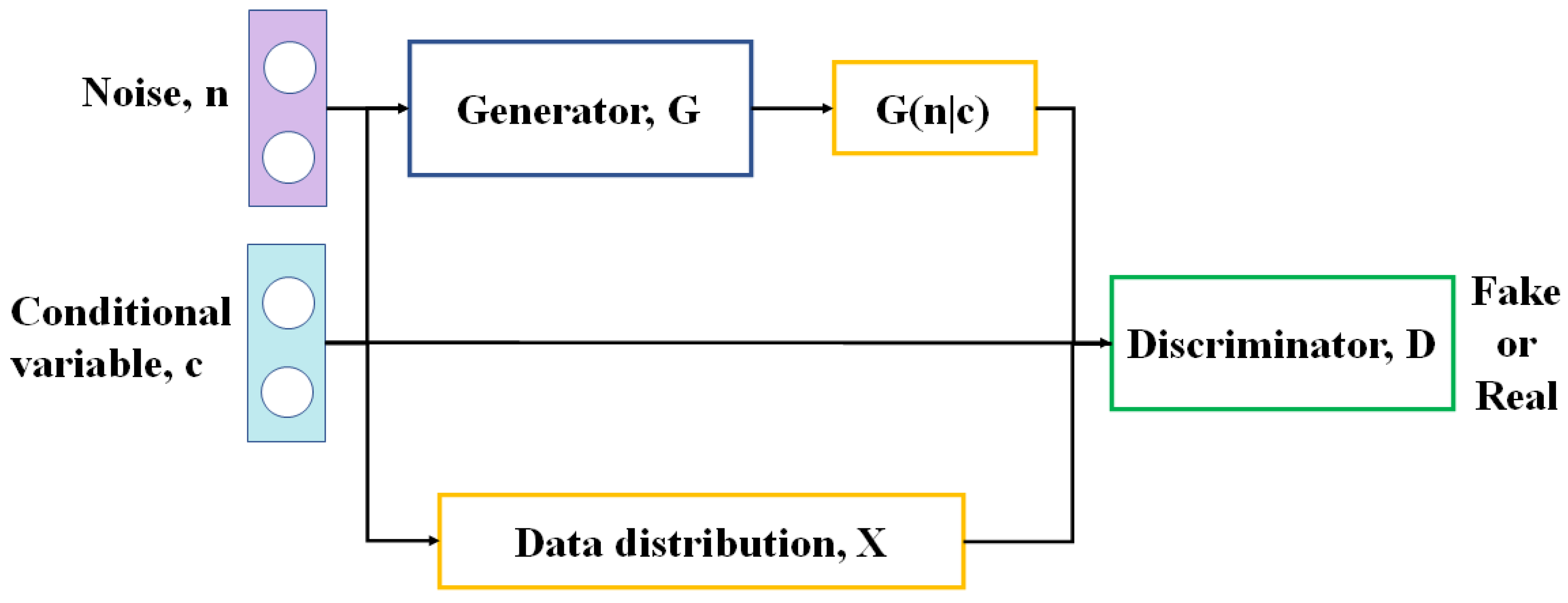
2.2.1. Generation of Additional Training Data Using CGAN
2.2.2. Voice Disorder Detection Model Using IFCM
| Algorithm 1 |
| Input: {Xp}train, m = 2 |
| Output: Model |
| 1. Generation count g = 1; |
| 2. Initialize population; |
| 3. Evaluate the individuals with the fitness functions (F1, F2, F3, and F4); |
| 4. Rank the fitness values of individuals based on step 3; |
| 5. Calculate the Niche count; |
| while generations <= max_generation do |
| 6. Select two parents from the population; |
| 7. Create offspring using Roulette wheel selection (RWS), crossover, and mutation; |
| 8. Train a MOGA-based IFCM model for each individual; |
| 9. Evaluate the offspring with the fitness functions (F1, F2, F3, and F4); |
| 10. Rank the offspring by their fitness values according to step 9 |
| 11. Calculate the Niche count; |
| 12. Decide the new population based on the offspring; |
| 13. g = g + 1; |
| End while |
| Model←Pareto solutions |
3. Analysis and Results of CGAN-IFCM
3.1. Performance Evaluation of CGAN-IFCM
3.1.1. Binary Detection Model using CGAN-IFCM
- (): The membership is more dominated by . Therefore, increases as the TNR and TPR decrease.
- (): The highest TNR and TPR are obtained at . This can be explained by the case that if . Recall that Xp and its neighbor Xp share similar characteristics and tend to group under the same . However, when , both TNR and TPR decrease.
- The performance of CGAN-IFCM is better when compared to and deteriorates significantly when , as some clusters could be redundant and lead to errors in voice disorder detection.
- The detection model is dominated by a class of candidates with voice disorders because the number of samples of voice disorders remains larger than the number of samples of healthy candidates after the adoption of CGAN. In other words, as shown in Table 3, there is a notable gap (on average, 3.94% versus 0.79%, as shown in Table 2) between TNR and TPR, where TPR is higher than TNR.
- The overall accuracy of the binary detection model with the VOICED database is less than that of the SVD database. This could be explained in two ways: the imbalanced dataset in SVD and the number of samples in SVD, which is 10 times that in VOICED.
3.1.2. Multi-Class Detection Model using CGAN-IFCM
- The performance of CGAN-IFCM is better when compared to and . It achieves lower performance when and as either an insufficient number of clusters or redundant clusters are considered.
- The detection model is dominated by the class of healthy candidates because the number of samples of healthy candidates is far greater than the number of samples of candidates with hyperkinetic dysphonia, hypokinetic dysphonia, or reflux laryngitis after the adoption of CGAN. In Table 4, there difference between TNR and TPR (where TNR is higher than TPR) is further increased (on average, by 4.56% versus 3.94%, as shown in Table 3) between TNR and TPR, where TPR is higher than TNR.
- The overall accuracy of the multi-class detection model is lower than that of the binary-class detection model. Basically, the multi-class detection model is a more complicated problem compared to the binary classifier. Further, the issue of an imbalanced dataset is especially significant given the small sample size of patients with hypokinetic dysphonia (2% of the samples of healthy candidates).
- The performance of CGAN-IFCM is better when compared to and . It achieves lower performance when and , as either an insufficient number of clusters or redundant clusters are considered.
- The multi-class detection model is formulated using an equal sample size in each class after the adoption of CGAN. The difference between TNR and TPR is not significant, and there is no bias in TNR, which is either always higher than TPR, or TPR is always higher than TNR.
3.2. Comparison Between CGAN-IFCM and IFCM
3.3. Comparison Between CGAN-IFCM and CGAN-FCM
3.4. Comparison Between CGAN, SMOTE, and CSL
3.5. Comparison Between CGAN-IFCM and Existing Works
3.6. Comparison Between CGAN-IFCM with Other Approaches using Wilcoxon Signed-Rank Test
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Vilkman, E. Voice problems at work: A challenge for occupational safety and health arrangement. Folia Phoniatrica et Logopaedica 2000, 52, 120–125. [Google Scholar] [CrossRef] [PubMed]
- Dodderi, T.; Philip, N.E.; Mutum, K. Prevalence of voice disorders in the Department of Speech Language Pathology of a tertiary care hospital of Mangaluru: A retrospective study of 11 years. Nitte Univ. J. Health Sci. 2018, 8, 12–16. [Google Scholar]
- Lyberg-Åhlander, V.; Rydell, R.; Fredlund, P.; Magnusson, C.; Wilén, S. Prevalence of voice disorders in the general population, based on the Stockholm public health cohort. J. Voice 2019, 33, 900–905. [Google Scholar] [CrossRef]
- Vertanen-Greis, H.; Löyttyniemi, E.; Uitti, J. Voice disorders are associated with stress among teachers: A cross-sectional study in Finland. J. Voice 2018, 34, 488.e1–488.e8. [Google Scholar] [CrossRef]
- Roy, N.; Merrill, R.M.; Gray, S.D.; Smith, E.M. Voice disorders in the general population: Prevalence, risk factors, and occupational impact. Laryngoscope 2005, 115, 1988–1995. [Google Scholar] [CrossRef] [PubMed]
- Leão, S.H.D.S.; Oates, J.M.; Purdy, S.C.; Scott, D.; Morton, R.P. Voice problems in New Zealand teachers: A national survey. J. Voice 2015, 29, 645-e1. [Google Scholar] [CrossRef]
- Muhammad, G.; Alhamid, M.F.; Alsulaiman, M.; Gupta, B. Edge computing with cloud for voice disorder assessment and treatment. IEEE Commun. Mag. 2018, 56, 60–65. [Google Scholar] [CrossRef]
- Alhussein, M.; Muhammad, G. Voice pathology detection using deep learning on mobile healthcare framework. IEEE Access 2018, 6, 41034–41041. [Google Scholar] [CrossRef]
- Amami, R.; Amami, R.; Eleraky, H.A. An Incremental System for Voice Pathology Detection Combining Possibilistic SVM and HMM. In Proceedings of the International Conference on Statistical Language and Speech Processing, Ljubljana, Slovenia, 14–16 October 2019; pp. 127–138. [Google Scholar]
- Fang, S.H.; Tsao, Y.; Hsiao, M.J.; Chen, J.Y.; Lai, Y.H.; Lin, F.C.; Wang, C.T. Detection of pathological voice using cepstrum vectors: A deep learning approach. J. Voice 2019, 33, 634–641. [Google Scholar] [CrossRef] [PubMed]
- Ali, Z.; Imran, M.; Alsulaiman, M.; Zia, T.; Shoaib, M. A zero-watermarking algorithm for privacy protection in biomedical signals. Future Gener. Comput. Syst 2018, 82, 290–303. [Google Scholar] [CrossRef] [Green Version]
- Amara, F.; Fezari, M.; Bourouba, H. An improved GMM-SVM system based on distance metric for voice pathology detection. Appl. Math 2016, 10, 1061–1070. [Google Scholar] [CrossRef]
- Verde, L.; De Pietro, G.; Sannino, G. Voice disorder identification by using machine learning techniques. IEEE Access 2018, 6, 16246–16255. [Google Scholar] [CrossRef]
- Guedes, V.; Teixeira, F.; Oliveira, A.; Fernandes, J.; Silva, L.; Junior, A.; Teixeira, J.P. Transfer Learning with AudioSet to Voice Pathologies Identification in Continuous Speech. Procedia Comput. Sci. 2019, 164, 662–669. [Google Scholar] [CrossRef]
- Kadiri, S.R.; Alku, P. Analysis and Detection of Pathological Voice using Glottal Source Features. IEEE J. Sel. Top. Signal Process. 2020, 14, 367–379. [Google Scholar] [CrossRef] [Green Version]
- Verde, L.; De Pietro, G.; Alrashoud, M.; Ghoneim, A.; Al-Mutib, K.N.; Sannino, G. Dysphonia Detection Index (DDI): A New Multi-Parametric Marker to Evaluate Voice Quality. IEEE Access 2019, 7, 55689–55697. [Google Scholar] [CrossRef]
- Chen, L.; Wang, C.; Chen, J.; Xiang, Z.; Hu, X. Voice Disorder Identification by using Hilbert-Huang Transform (HHT) and K Nearest Neighbor (KNN). J. Voice 2020. [Google Scholar] [CrossRef]
- Verde, L.; De Pietro, G.; Alrashoud, M.; Ghoneim, A.; Al-Mutib, K.N.; Sannino, G. Leveraging Artificial Intelligence to Improve Voice Disorder Identification Through the Use of a Reliable Mobile App. IEEE Access 2019, 7, 124048–124054. [Google Scholar] [CrossRef]
- Pützer, M.; Koreman, J. A German database of patterns of pathological vocal fold vibration. Phonus 1997, 3, 143–153. [Google Scholar]
- Saarbruecken Voice Database: Handbook. Available online: http://www.stimmdatenbank.coli.uni-saarland.de/help_en.php4 (accessed on 20 February 2020).
- Cesari, U.; De Pietro, G.; Marciano, E.; Niri, C.; Sannino, G.; Verde, L. A new database of healthy and pathological voices. Comput. Elect. Eng. 2018, 68, 310–321. [Google Scholar] [CrossRef]
- Pan, Z.; Yu, W.; Yi, X.; Khan, A.; Yuan, F.; Zheng, Y. Recent progress on generative adversarial networks (GANs): A survey. IEEE Access 2019, 7, 36322–36333. [Google Scholar] [CrossRef]
- Odena, A.; Olah, C.; Shlens, J. Conditional image synthesis with auxiliary classifier gans. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2642–2651. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. Available online: https://arxiv.org/abs/1411.1784 (accessed on 10 April 2020).
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2172–2180. [Google Scholar]
- Brockmann, M.; Drinnan, M.J.; Storck, C.; Carding, P.N. Reliable jitter and shimmer measurements in voice clinics: The relevance of vowel, gender, vocal intensity, and fundamental frequency effects in a typical clinical task. J. Voice 2011, 25, 44–53. [Google Scholar] [CrossRef] [PubMed]
- Lopes, L.W.; da Silva, J.D.; Simões, L.B.; da Silva Evangelista, D.; Silva, P.O.C.; Almeida, A.A.; de Lima-Silva, M.F.B. Relationship between acoustic measurements and self-evaluation in patients with voice disorders. J. Voice 2017, 31, 119.e1–119.e10. [Google Scholar] [CrossRef] [PubMed]
- Severin, F.; Bozkurt, B.; Dutoit, T. HNR extraction in voiced speech, oriented towards voice quality analysis. In Proceedings of the 2005 13th European Signal Processing Conference, Antalya, Turkey, 4–8 September 2005; pp. 1–4. [Google Scholar]
- Farrús, M.; Hernando, J.; Ejarque, P. Jitter and shimmer measurements for speaker recognition. In Proceedings of the Eighth Annual Conference of the International Speech Communication Association, Antwerp, Belgium, August 27–31 2007; pp. 778–781. [Google Scholar]
- Verde, L.; De Pietro, G.; Sannino, G. A methodology for voice classification based on the personalized fundamental frequency estimation. Biomed. Signal Process. Control 2018, 42, 134–144. [Google Scholar] [CrossRef]
- Grimm, K.J.; Mazza, G.L.; Davoudzadeh, P. Model selection in finite mixture models: A k-fold cross-validation approach. Struct. Equ. Model. 2017, 24, 246–256. [Google Scholar] [CrossRef]
- Varoquaux, G.; Raamana, P.R.; Engemann, D.A.; Hoyos-Idrobo, A.; Schwartz, Y.; Thirion, B. Assessing and tuning brain decoders: Cross-validation, caveats, and guidelines. NeuroImage 2017, 145, 166–179. [Google Scholar] [CrossRef] [Green Version]
- Bezdek, J.C. Pattern Recognition with Fuzzy Objective Function Algorithms; Kluwer Academic Publishers: Norwell, MA, USA, 1981. [Google Scholar]
- Maulik, U.; Bandyopadhyay, S. Performance evaluation of some clustering algorithms and validity indices. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 1650–1654. [Google Scholar] [CrossRef] [Green Version]
- Foneseca, C.M.; Flemming, P. Genetic algorithms for multi-objective optimization: Formulation, discussion, and generalization. In Proceedings of the 5th International Conference on Genetic Algorithms, Urbana-Champaign, Champaign, IL, USA, 17–21 July 1993; Morgan Kaufmann: San Francisco, CA, USA, 1993; pp. 416–423. [Google Scholar]
- Deb, K. Multi-Objective Optimization Using Evolutionary Algorithms; John Wiley & Sons, Inc.: New York, NY, USA, 2001. [Google Scholar]
- Jensen, M.T. Reducing the run-time complexity of multiobjective EAs: The NSGA-II and other algorithms. IEEE Trans. Evol. Comput. 2003, 7, 503–515. [Google Scholar] [CrossRef]
- Dutta, S.; Das, K.N. A survey on pareto-based eas to solve multi-objective optimization problems. In Soft Computing for Problem Solving; Bansal, J., Das, K., Nagar, A., Deep, K., Ojha, A., Eds.; Advances in Intelligent Systems and Computing; Springer: Singapore, 2019. [Google Scholar]
- Goldberg, D.; Richardson, J. Genetic Algorithms with Sharing for Multi-modal Function Optimization. In Proceedings of the International Conference on Genetic Algorithms, Cambridge, MA, USA, 28–31 July 1987; pp. 41–49. [Google Scholar]
- Mahfoud, S.W. Niching Methods for Genetic Algorithms. Ph.D. Thesis, University of Illinois at Urbana-Champaign, Urbana Champaign, IL, USA, 1995. [Google Scholar]
- Ji, J.Y.; Yu, W.J.; Zhong, J.; Zhang, J. Density-Enhanced Multiobjective Evolutionary Approach for Power Economic Dispatch Problems. IEEE Trans. Syst. Man Cybern. Syst. 2019. [Google Scholar] [CrossRef]
- Maldonado, S.; López, J.; Vairetti, C. An alternative SMOTE oversampling strategy for high-dimensional datasets. Appl. Soft Comput. 2019, 76, 380–389. [Google Scholar] [CrossRef]
- Sun, J.; Li, H.; Fujita, H.; Fu, B.; Ai, W. Class-imbalanced dynamic financial distress prediction based on Adaboost-SVM ensemble combined with SMOTE and time weighting. Inf. Fusion 2020, 54, 128–144. [Google Scholar] [CrossRef]
- Jia, X.; Li, W.; Shang, L. A multiphase cost-sensitive learning method based on the multiclass three-way decision-theoretic rough set model. Inf. Sci. 2019, 485, 248–262. [Google Scholar] [CrossRef]
- Feng, F.; Li, K.C.; Shen, J.; Zhou, Q.; Yang, X. Using cost-sensitive learning and feature selection algorithms to improve the performance of imbalanced classification. IEEE Access 2020, 8, 69979–69996. [Google Scholar] [CrossRef]
- Limpert, E.; Stahel, W.A. Problems with using the normal distribution–and ways to improve quality and efficiency of data analysis. PLoS ONE 2011, 6, e21403. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- De Winter, J.C. Using the Student’s t-test with extremely small sample sizes. Pract. Assess. Res. Eval. 2013, 18, 10. [Google Scholar]
- Ngyen, K.A.; Chen, W.; Lin, B.S.; Seeboonruang, U. Using Machine Learning-Based Algorithms to Analyze Erosion Rates of a Watershed in Northern Taiwan. Sustainability 2020, 12, 2022. [Google Scholar] [CrossRef] [Green Version]
- Meek, G.E.; Ozgur, C.; Dunning, K. Comparison of the t vs. Wilcoxon signed-rank test for Likert scale data and small samples. J. Mod. Appl. Stat. Methods 2007, 6, 10. [Google Scholar] [CrossRef]


{kind=link}
| Database | Signal Characteristics | Information Included | Binary Detection Model | Multi-Class Detection Model |
|---|---|---|---|---|
| SVD [19,20] | 16-bit resolution at 50 kHz | Gender, age, and clinical diagnosis | 869 healthy candidates and 1356 candidates with voice disorders | 869 healthy candidates, 213 with hyperkinetic dysphonia, 16 with hypokinetic dysphonia, and 140 with reflux laryngitis |
| VOICED [21] | 32-bit resolution at 8 kHz | Gender, age, clinical diagnosis, smoking status, alcohol consumption, hydration, eating habits, voice handicap index, and reflux symptom index | 58 healthy candidates and 150 candidates with voice disorders | 58 healthy candidates, 70 with hyperkinetic dysphonia, 41 with hypokinetic dysphonia, and 39 with reflux laryngitis |
| Control Weighting Factors | TNR (%)/TPR (%) with Varying | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ||
| 2 | 2 | 90.9/90.2 | 93.6/95.2 | 91.3/93.6 | 88.2/89.3 | 85.3/86.3 | 82.6/83.3 | 77.7/78.8 | 74.3/73.8 |
| 2.1 | 87.8/88.5 | 89.7/90.2 | 87.3/88.2 | 85.4/87.0 | 82.9/82.1 | 80.1/80.8 | 75.6/74.5 | 72.3/71.7 | |
| 2.2 | 86.1/85.8 | 87.7/86.9 | 86.8/85.0 | 84.2/84.5 | 81.3/81.5 | 78.8/78.0 | 74.1/73.2 | 70.8/71.8 | |
| 2.3 | 84.9/84.6 | 85.8/86.1 | 84.2/83.5 | 83.3/82.7 | 80.8/81.2 | 77.1/77.3 | 73.8/72.5 | 69.8/70.2 | |
| 2.4 | 82.5/82.1 | 83.9/84.1 | 83.1/82.7 | 82.4/81.8 | 80.4/79.7 | 75.5/76.3 | 71.8/73.1 | 68.6/69.1 | |
| 2.1 | 2 | 91.6/91.8 | 94.3/95.1 | 92.8/92.1 | 89.7/90.6 | 86.8/85.6 | 84.2/84.8 | 78.3/79.6 | 74.3/73.8 |
| 2.1 | 90.3/91.2 | 93.7/92.8 | 92.0/91.7 | 90.1/89.2 | 86.3/85.7 | 83.5/82.9 | 77.3/77.8 | 73.6/73.1 | |
| 2.2 | 89.1/89.4 | 91.6/92.0 | 90.7/91.1 | 89.5/88.8 | 85.3/84.6 | 82.4/82.1 | 76.5/76.9 | 72.1/72.9 | |
| 2.3 | 87.6/87.0 | 90.2/90.5 | 88.9/87.7 | 87.4/85.8 | 84.7/84.0 | 81.8/81.1 | 75.9/75.2 | 71.4/72.0 | |
| 2.4 | 85.8/85.1 | 88.4/88.9 | 86.5/86.1 | 85.4/85.1 | 84.1/84.5 | 80.6/80.0 | 73.6/73.5 | 72.1/71.2 | |
| 2.2 | 2 | 91.9/92.3 | 94.6/95.4 | 93.2/92.3 | 89.9/91.0 | 87.5/85.9 | 84.6/85.2 | 78.7/78.2 | 74.8/74.2 |
| 2.1 | 90.6/91.4 | 94.1/93.2 | 92.4/92.2 | 90.5/89.6 | 86.7/86.2 | 84.0/83.3 | 77.7/78.1 | 73.9/73.3 | |
| 2.2 | 89.6/89.9 | 91.8/92.3 | 91.0/91.3 | 89.8/88.9 | 85.7/84.9 | 82.8/82.4 | 76.9/77.2 | 72.4/73.5 | |
| 2.3 | 87.8/87.3 | 90.4/90.6 | 89.2/87.9 | 87.8/87.5 | 85.2/84.5 | 82.4/81.3 | 76.3/75.5 | 71.7/72.3 | |
| 2.4 | 86.0/85.5 | 88.8/89.2 | 86.8/86.3 | 85.8/86.3 | 84.6/84.8 | 80.9/80.3 | 74.0/73.9 | 72.5/71.4 | |
| 2.3 | 2 | 91.2/92.3 | 94.3/95.3 | 93.1/91.9 | 89.8/90.6 | 86.9/85.7 | 84.6/84.6 | 77.6/77.2 | 73.0/73.5 |
| 2.1 | 90.1/90.4 | 93.8/92.9 | 91.3/91.6 | 90.0/89.1 | 85.8/85.3 | 83.3/82.9 | 77.3/77.1 | 72.8/72.3 | |
| 2.2 | 87.8/88.2 | 90.2/91.1 | 90.3/89.9 | 88.7/88.1 | 84.9/84.1 | 82.2/81.8 | 76.4/76.8 | 71.1/70.9 | |
| 2.3 | 86.5/87.1 | 88.9/89.5 | 89.6/88.8 | 87.4/87.0 | 84.2/83.6 | 81.2/80.5 | 75.6/76.1 | 70.9/70.3 | |
| 2.4 | 85.4/86.3 | 87.5/88.2 | 88.2/87.3 | 86.8/86.2 | 83.6/82.8 | 80.3/79.7 | 74.2/74.5 | 69.5/69.8 | |
| 2.4 | 2 | 90.4/91.8 | 93.1/94.2 | 92.5/91.3 | 88.6/89.5 | 86.1/84.9 | 83.5/83.9 | 76.9/76.3 | 72.1/72.3 |
| 2.1 | 89.2/89.1 | 92.8/92.4 | 90.7/91.1 | 89.2/88.4 | 85.2/84.7 | 82.7/82.2 | 76.7/76.2 | 72.0/71.5 | |
| 2.2 | 87.5/87.9 | 89.7/90.8 | 89.6/89.2 | 88.2/87.4 | 84.4/82.6 | 81.7/81.1 | 75.8/76.0 | 70.4/70.1 | |
| 2.3 | 85.8/86.3 | 88.1/88.9 | 89.0/88.1 | 86.9/86.3 | 83.8/83.2 | 80.4/79.8 | 75.1/75.7 | 70.2/69.9 | |
| 2.4 | 84.9/85.8 | 87.1/87.8 | 87.5/86.8 | 86.2/85.8 | 83.1/82.5 | 80.0/79.5 | 73.7/74.1 | 69.2/69.5 | |
| Control Weighting Factors | TNR (%)/TPR (%) with Varying | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ||
| 2 | 2 | 83.7/87.9 | 88.3/92.1 | 87.5/90.8 | 84.6/87.9 | 81.6/84.7 | 79.8/82.3 | 73.7/77.3 | 70.2/73.0 |
| 2.1 | 82.1/86.0 | 86.8/89.6 | 85.9/88.8 | 83.7/86.9 | 79.7/82.4 | 77.5/80.0 | 73.5/75.9 | 69.8/72.1 | |
| 2.2 | 81.3/85.2 | 85.1/87.5 | 83.1/85.5 | 82.1/85.6 | 78.9/81.9 | 76.4/78.9 | 71.5/74.2 | 68.6/71.5 | |
| 2.3 | 80.2/84.8 | 83.3/86.6 | 81.8/84.2 | 81.0/83.9 | 77.5/81.4 | 74.9/77.8 | 70.6/73.2 | 67.3/70.8 | |
| 2.4 | 79.7/83.5 | 82.1/85.3 | 80.2/83.5 | 80.3/82.6 | 76.9/80.3 | 73.8/77.2 | 69.7/72.4 | 66.8/70.1 | |
| 2.1 | 2 | 87.0/90.4 | 90.9/93.6 | 89.7/92.3 | 86.3/90.8 | 83.2/86.5 | 81.4/84.5 | 76.6/80.3 | 71.5/74.9 |
| 2.1 | 86.2/89.7 | 89.6/92.2 | 88.3/91.5 | 85.6/89.3 | 81.8/85.5 | 80.1/83.5 | 75.8/78.5 | 70.1/73.8 | |
| 2.2 | 85.5/88.8 | 88.7/91.5 | 87.4/90.9 | 84.9/88.5 | 80.4/84.8 | 80.0/83.1 | 74.2/77.4 | 68.8/72.8 | |
| 2.3 | 84.7/87.3 | 87.4/90.9 | 85.3/88.6 | 83.8/87.4 | 79.6/83.8 | 78.7/82.0 | 73.3/76.8 | 67.9/71.7 | |
| 2.4 | 82.8/85.7 | 85.3/89.2 | 84.2/87.2 | 82.7/86.3 | 78.6/82.9 | 77.3/80.5 | 71.0/74.2 | 67.3/71.1 | |
| 2.2 | 2 | 88.2/91.4 | 91.1/93.8 | 89.9/92.5 | 86.7/91.6 | 84.0/87.4 | 82.1/86.1 | 77.6/80.3 | 72.6/75.6 |
| 2.1 | 87.2/90.6 | 90.2/93.1 | 89.3/92.1 | 86.9/90.3 | 83.0/86.6 | 81.7/84.0 | 75.1/79.2 | 71.5/74.2 | |
| 2.2 | 86.1/89.4 | 89.2/92.0 | 88.1/91.5 | 85.6/89.4 | 82.4/85.3 | 81.4/83.7 | 74.5/78.6 | 69.3/73.3 | |
| 2.3 | 85.2/88.1 | 88.2/91.3 | 85.7/88.7 | 84.9/88.1 | 81.8/84.7 | 80.1/83.2 | 73.6/76.3 | 68.9/72.1 | |
| 2.4 | 83.1/86.7 | 86.4/90.6 | 83.8/87.9 | 82.8/87.2 | 80.6/83.5 | 78.7/81.9 | 72.3/75.6 | 68.6/71.8 | |
| 2.3 | 2 | 89.2/92.3 | 91.5/94.3 | 90.6/93.4 | 87.8/92.0 | 85.3/88.6 | 82.5/86.8 | 78.0/81.6 | 72.9/76.3 |
| 2.1 | 87.8/90.9 | 88.6/93.6 | 88.5/92.5 | 87.4/90.5 | 83.6/87.7 | 81.9/84.6 | 75.5/79.8 | 72.1/74.7 | |
| 2.2 | 86.6/90.1 | 88.4/91.5 | 88.2/90.3 | 86.5/89.8 | 83.4/86.3 | 81.6/82.5 | 74.9/79.3 | 70.2/72.5 | |
| 2.3 | 85.5/88.5 | 88.4/91.1 | 86.3/89.4 | 85.7/88.4 | 82.5/85.8 | 80.2/83.1 | 74.2/76.8 | 69.6/72.0 | |
| 2.4 | 84.1/87.3 | 87.1/90.9 | 85.5/88.8 | 84.5/87.8 | 81.1/84.3 | 79.8/80.5 | 73.2/76.2 | 69.1/71.2 | |
| 2.4 | 2 | 87.1/90.4 | 88.5/92.3 | 86.7/89.9 | 85.2/88.0 | 83.8/86.6 | 81.8/85.3 | 76.5/79.8 | 72.5/75.8 |
| 2.1 | 85.8/88.5 | 87.4/90.7 | 86.2/89.3 | 84.6/87.1 | 83.0/85.9 | 79.7/83.8 | 75.3/78.9 | 71.7/74.9 | |
| 2.2 | 85.0/87.5 | 86.5/89.2 | 85.3/88.5 | 84.1/87.0 | 82.2/85.3 | 78.5/82.9 | 74.3/77.0 | 70.4/73.6 | |
| 2.3 | 84.2/87.2 | 85.5/88.6 | 84.7/87.5 | 83.6/86.6 | 81.7/84.3 | 79.8/80.3 | 73.7/76.3 | 69.7/72.4 | |
| 2.4 | 83.4/86.5 | 84.7/87.3 | 83.7/86.6 | 82.7/85.5 | 82.0/83.7 | 76.3/79.3 | 72.4/75.6 | 68.5/70.7 | |
| Control Weighting Factors | TNR (%)/TPR (%) with Varying | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ||
| 2 | 2 | 83.2/79.6 | 84.3/80.0 | 85.6/80.8 | 86.1/81.9 | 90.3/86.3 | 89.2/85.1 | 86.0/83.6 | 83.8/79.5 |
| 2.1 | 82.2/78.7 | 83.0/79.1 | 83.5/79.6 | 84.4/80.3 | 87.8/84.6 | 87.0/83.8 | 85.4/82.5 | 81.2/77.7 | |
| 2.2 | 81.2/77.0 | 82.0/77.9 | 82.6/78.7 | 83.4/79.8 | 85.7/83.6 | 83.6/81.4 | 83.8/80.2 | 80.1/76.8 | |
| 2.3 | 79.8/75.9 | 80.6/76.8 | 81.6/77.9 | 82.2/78.4 | 84.8/81.8 | 82.1/80.1 | 82.3/79.4 | 79.7/75.3 | |
| 2.4 | 78.9/75.5 | 80.0/75.7 | 80.3/76.5 | 81.3/77.5 | 83.7/80.6 | 81.7/78.6 | 81.1/78.5 | 78.3/74.3 | |
| 2.1 | 2 | 85.4/80.3 | 86.2/81.2 | 87.0/82.3 | 88.2/84.6 | 91.2/86.8 | 89.9/85.5 | 88.3/84.9 | 86.1/82.6 |
| 2.1 | 84.2/79.5 | 85.4/80.6 | 86.3/81.4 | 87.4/83.2 | 90.3/85.6 | 89.5/84.7 | 87.6/83.1 | 85.3/81.3 | |
| 2.2 | 83.6/78.7 | 84.3/80.0 | 85.2/80.3 | 86.3/82.3 | 89.5/84.2 | 88.6/83.6 | 87.1/82.3 | 84.4/80.5 | |
| 2.3 | 82.5/77.7 | 83.2/79.1 | 84.1/79.7 | 85.3/81.6 | 88.8/83.1 | 87.5/82.6 | 86.3/81.2 | 83.2/79.8 | |
| 2.4 | 81.3/76.9 | 82.4/78.1 | 83.4/78.7 | 84.5/80.9 | 86.3/82.0 | 84.9/81.3 | 84.1/80.5 | 82.3/79.1 | |
| 2.2 | 2 | 86.1/81.8 | 87.2/82.5 | 88.2/84.0 | 89.3/85.6 | 91.6/87.6 | 90.3/86.4 | 88.9/85.3 | 87.6/84.1 |
| 2.1 | 85.2/80.5 | 86.0/81.3 | 87.1/83.5 | 88.0/84.2 | 90.3/86.3 | 89.6/85.0 | 87.8/84.1 | 86.4/83.7 | |
| 2.2 | 84.3/79.6 | 85.3/80.7 | 86.3/82.0 | 87.2/83.6 | 89.6/85.5 | 88.8/84.3 | 86.3/83.2 | 85.6/82.7 | |
| 2.3 | 83.4/78.7 | 84.6/79.9 | 85.6/80.9 | 86.4/82.8 | 89.1/84.6 | 88.5/83.8 | 85.5/82.6 | 84.8/81.2 | |
| 2.4 | 81.5/77.9 | 82.6/79.2 | 83.3/80.0 | 83.8/81.8 | 87.5/83.8 | 86.8/82.6 | 85.0/81.3 | 83.6/80.8 | |
| 2.3 | 2 | 87.6/82.1 | 88.5/83.4 | 89.4/85.3 | 90.6/85.9 | 92.1/88.5 | 90.4/86.9 | 89.7/86.2 | 88.8/85.3 |
| 2.1 | 86.3/81.3 | 87.6/82.8 | 88.5/84.5 | 88.8/84.8 | 91.2/87.3 | 90.0/85.8 | 88.7/85.1 | 87.2/84.6 | |
| 2.2 | 85.4/80.1 | 86.2/81.3 | 87.3/83.6 | 86.3/84.1 | 90.2/86.6 | 89.3/85.3 | 87.2/84.1 | 86.6/83.5 | |
| 2.3 | 84.6/79.6 | 85.8/80.5 | 86.2/81.3 | 85.3/83.6 | 89.7/85.3 | 89.0/84.2 | 86.0/83.5 | 85.2/82.6 | |
| 2.4 | 82.5/79.3 | 83.1/80.5 | 83.8/81.5 | 84.3/82.5 | 88.8/84.3 | 87.8/83.6 | 86.3/82.6 | 83.9/81.2 | |
| 2.4 | 2 | 84.5/80.0 | 85.8/81.3 | 87.1/82.6 | 88.4/83.5 | 90.2/86.1 | 87.3/84.8 | 85.1/83.7 | 83.6/82.4 |
| 2.1 | 83.8/79.1 | 85.0/81.2 | 86.0/81.4 | 87.1/82.3 | 89.6/85.2 | 86.6/83.1 | 84.0/82.5 | 82.3/81.5 | |
| 2.2 | 82.4/78.0 | 83.5/79.5 | 84.2/80.3 | 85.1/81.6 | 88.2/84.5 | 85.8/82.2 | 82.6/81.7 | 81.0/80.4 | |
| 2.3 | 81.3/77.2 | 82.4/78.7 | 83.5/79.6 | 84.7/80.8 | 86.8/83.2 | 84.9/81.6 | 81.1/80.8 | 80.1/79.8 | |
| 2.4 | 80.4/76.3 | 81.5/77.5 | 82.0/78.5 | 83.2/79.4 | 85.6/81.3 | 83.6/80.3 | 80.2/78.1 | 79.6/76.7 | |
| Control Weighting Factors | TNR (%)/TPR (%) with Varying | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ||
| 2 | 2 | 81.5/82.1 | 83.0/82.6 | 83.4/82.7 | 84.9/85.3 | 87.6/87.0 | 86.2/86.7 | 84.3/83.1 | 82.6/81.8 |
| 2.1 | 80.3/81.4 | 82.3/81.8 | 83.0/82.3 | 83.5/84.1 | 85.9/86.2 | 84.5/85.9 | 83.6/82.1 | 82.0/80.4 | |
| 2.2 | 79.5/78.7 | 80.7/80.3 | 81.5/82.1 | 82.7/83.5 | 84.6/84.0 | 83.2/82.7 | 83.1/82.6 | 81.3/79.3 | |
| 2.3 | 77.6/78.0 | 78.6/78.5 | 80.2/80.7 | 81.6/82.3 | 83.3/82.4 | 82.5/81.8 | 81.7/80.7 | 80.5/78.6 | |
| 2.4 | 77.0/76.8 | 78.1/77.3 | 79.6/78.5 | 80.7/81.2 | 82.4/81.8 | 81.2/80.7 | 80.3/79.6 | 79.2/77.7 | |
| 2.1 | 2 | 82.5/82.8 | 84.0/83.1 | 85.1/84.0 | 86.3/85.8 | 88.5/88.0 | 87.2/86.8 | 85.8/85.2 | 83.1/83.3 |
| 2.1 | 81.4/81.6 | 83.2/82.2 | 84.0/83.5 | 85.7/84.8 | 86.9/87.1 | 85.9/86.3 | 84.5/84.8 | 82.6/82.2 | |
| 2.2 | 80.8/80.3 | 82.1/81.6 | 83.2/82.6 | 84.0/83.9 | 85.3/86.0 | 84.1/85.0 | 83.6/83.9 | 82.1/81.5 | |
| 2.3 | 79.3/78.9 | 81.0/80.4 | 82.3/81.5 | 83.6/82.9 | 84.6/83.9 | 83.9/83.3 | 82.1/82.6 | 81.1/80.5 | |
| 2.4 | 78.1/77.5 | 79.6/79.0 | 81.1/80.8 | 82.3/81.6 | 83.5/82.6 | 82.5/82.4 | 81.0/81.4 | 80.6/79.6 | |
| 2.2 | 2 | 84.2/83.7 | 85.3/84.4 | 86.7/85.9 | 87.5/86.7 | 88.7/88.8 | 87.5/87.1 | 86.4/86.0 | 84.9/85.1 |
| 2.1 | 82.8/82.2 | 84.5/83.7 | 85.8/84.9 | 86.8/85.3 | 87.6/88.0 | 87.2/87.2 | 85.6/85.4 | 83.8/84.5 | |
| 2.2 | 81.1/80.9 | 83.2/81.8 | 84.8/83.5 | 85.7/84.7 | 86.3/87.2 | 86.3/85.9 | 84.5/84.7 | 83.1/84.0 | |
| 2.3 | 80.3/80.1 | 82.5/81.1 | 83.6/82.8 | 84.4/83.5 | 85.7/86.1 | 84.6/84.3 | 83.6/83.3 | 82.3/82.6 | |
| 2.4 | 79.3/78.7 | 81.2/80.6 | 82.6/82.1 | 83.4/82.6 | 84.8/85.3 | 83.9/83.5 | 83.1/82.7 | 81.6/81.5 | |
| 2.3 | 2 | 85.4/84.9 | 86.8/85.3 | 87.8/86.5 | 88.2/87.8 | 89.2/89.9 | 88.1/88.4 | 87.3/87.6 | 86.5/85.8 |
| 2.1 | 84.1/83.7 | 85.2/84.6 | 87.0/86.2 | 87.5/87.2 | 88.5/88.8 | 87.4/87.0 | 86.2/86.3 | 85.0/84.5 | |
| 2.2 | 83.2/82.6 | 84.5/83.4 | 86.1/85.7 | 87.1/86.5 | 87.9/88.2 | 86.1/86.5 | 85.5/85.2 | 84.1/83.8 | |
| 2.3 | 82.5/81.4 | 83.7/82.8 | 84.6/85.0 | 85.6/85.2 | 86.5/87.1 | 85.3/86.1 | 84.8/84.1 | 83.6/82.0 | |
| 2.4 | 81.3/80.5 | 82.6/81.8 | 83.5/83.6 | 84.9/84.4 | 85.6/86.0 | 84.5/85.0 | 83.6/83.9 | 82.5/81.1 | |
| 2.4 | 2 | 83.2/82.6 | 84.3/83.7 | 85.8/84.3 | 86.5/85.4 | 87.8/87.2 | 86.4/85.3 | 84.3/83.2 | 83.1/82.5 |
| 2.1 | 82.5/82.0 | 83.6/82.8 | 84.5/83.7 | 85.8/85.0 | 86.5/86.1 | 85.3/84.4 | 83.1/82.9 | 82.0/81.3 | |
| 2.2 | 81.2/81.5 | 82.7/82.3 | 83.6/82.9 | 84.6/84.1 | 85.8/84.5 | 84.5/83.2 | 83.7/82.6 | 81.4/80.8 | |
| 2.3 | 80.4/81.0 | 81.8/81.5 | 82.7/82.3 | 83.9/83.4 | 85.2/83.6 | 83.5/82.7 | 82.5/81.9 | 80.5/79.3 | |
| 2.4 | 79.6/80.1 | 80.3/80.8 | 81.5/81.3 | 82.6/82.8 | 84.9/83.3 | 82.8/81.9 | 81.7/80.5 | 79.3/78.5 | |
| Cases | IFCM TNR (%)/TPR (%) | Proposed CGAN-IFCM TNR (%)/TPR (%) | Percentage Improvement by Proposed Work |
|---|---|---|---|
| Binary detection model with SVD | 85.9/89.8 | 94.7/95.6 | 10.2/6.5 |
| Binary detection model with VOICED | 83.3/89.2 | 91.6/94.4 | 10.0/5.8 |
| Multi-class detection model with SVD | 81.9/76.5 | 92.2/88.9 | 12.6/16.2 |
| Multi-class detection model with VOICED | 80.7/79.2 | 89.4/90.1 | 10.8/13.8 |
| Cases | CGAN-FCM TNR (%)/TPR (%) | Proposed CGAN-IFCM TNR (%)/TPR (%) | Percentage Improvement by Proposed Work |
|---|---|---|---|
| Binary detection model with SVD | 87.8/91.3 | 94.7/95.6 | 7.9/4.7 |
| Binary detection model with VOICED | 85.3/91.6 | 91.6/94.4 | 7.4/3.1 |
| Multi-class detection model with SVD | 84.6/79.4 | 92.2/88.9 | 9.0/12.0 |
| Multi-class detection model with VOICED | 83.3/81.6 | 89.4/90.1 | 7.3/10.4 |
| Cases | CGAN-IFCM TNR (%)/TPR (%) | SMOTE-IFCM TNR (%)/TPR (%) | CSL-IFCM TNR (%)/TPR (%) | Percentage Improvement by Proposed Work |
|---|---|---|---|---|
| Binary detection model with SVD | 94.7/95.6 | 90.1/91.6 | 89.2/90.3 | (4.4–5.1)/(6–6.2) |
| Binary detection model with VOICED | 91.6/94.4 | 87.2/90.1 | 86.5/89.2 | (4.8–5)/(5.8–5.9) |
| Multi-class detection model with SVD | 92.2/88.9 | 86.9/85.4 | 87.5/84.0 | (4.1–6.1)/(5.4–5.8) |
| Multi-class detection model with VOICED | 89.4/90.1 | 86.2/86.5 | 85.0/85.6 | (3.7–4.2)/(5.2–5.3) |
| Work | Database | Methodology | Types of Cross-Validation | Performance |
|---|---|---|---|---|
| [12] | SVD (binary class) | SVM and GMM | No | TNR: 99%; TPR: 94% |
| [13] | SVD (binary class) | SMO and SVM | 10-fold | TNR: 83.9%; TPR: 87.6% |
| [14] | SVD (binary class) | LSTM and CNN | 10-fold | Precision of 66–78% |
| [15] | SVD (binary class) | SVM | 20-fold | TNR: 78%; TPR: 72% |
| [16] | SVD (binary class) | Threshold-based detection | No | TNR: 90.2%; TPR: 70.6% |
| VOICED (binary class) | TNR: 64.3%; TPR: 45.8% | |||
| [17] | VOICED (binary class) | KNN | No | Accuracy of 93.3% |
| RF | Accuracy of 87.4% | |||
| [18] | VOICED (binary class) | Boosted tree | 5-fold | TNR: 86.2%; TPR: 82.9% |
| Proposed CGAN-IFCM | SVD (binary class) | CGAN and IFCM | 10-fold | TNR: 94.7%; TPR: 95.6% |
| VOICED (binary class) | TNR: 91.6%; TPR: 94.4% |
| Database | Methodology | Types of Cross-Validation | Performance |
|---|---|---|---|
| SVD | RF | 10-fold | TNR: 80.2%; TPR: 74.8% |
| SVM (radial basis kernel function) | TNR: 79.1%; TPR: 73.4% | ||
| Proposed CGAN-IFCM | TNR: 92.2%; TPR: 88.9% | ||
| VOICED | RF | 10-fold | TNR: 78.5%; TPR: 77.1% |
| SVM (radial basis kernel function) | TNR: 76.9%; TPR: 75.4% | ||
| Proposed CGAN-IFCM | TNR: 89.4%; TPR: 90.1% |
| Classification | Hypotheses | Results |
|---|---|---|
| Binary detection model | H0: EQAproposed = EQAIFCM Ha: EQAproposed >EQAIFCM | Reject H0 |
| Multi-class detection model | H0: EQAproposed = EQAIFCM Ha: EQAproposed >EQAIFCM | Reject H0 |
| Binary detection model | H0: EQAproposed = EQACGAN-FCM Ha: EQAproposed >EQACGAN-FCM | Reject H0 |
| Multi-class detection model | H0: EQAproposed = EQACGAN-FCM Ha: EQAproposed >EQACGAN-FCM | Reject H0 |
| Binary detection model | H0: EQAproposed = EQASMOTE-IFCM Ha: EQAproposed > EQASMOTE-IFCM | Reject H0 |
| Multi-class detection model | H0: EQAproposed = EQASMOTE-IFCM Ha: EQAproposed > EQASMOTE-IFCM | Reject H0 |
| Binary detection model | H0: EQAproposed = EQACSL-IFCM Ha: EQAproposed > EQACSL-IFCM | Reject H0 |
| Multi-class detection model | H0: EQAproposed = EQACSL-IFCM Ha: EQAproposed > EQACSL-IFCM | Reject H0 |
| Binary detection model | H0: EQAproposed = EQA[13] Ha: EQAproposed > EQA[13] | Reject H0 |
| Binary detection model | H0: EQAproposed = EQA[14] Ha: EQAproposed > EQA[14] | Reject H0 |
| Binary detection model | H0: EQAproposed = EQA[15] Ha: EQAproposed > EQA[15] | Reject H0 |
| Binary detection model | H0: EQAproposed = EQA[18] Ha: EQAproposed > EQA[18] | Reject H0 |
| Multi-class detection model | H0: EQAproposed = EQARF Ha: EQAproposed > EQARF | Reject H0 |
| Multi-class detection model | H0: EQAproposed = EQASVM-RBF Ha: EQAproposed > EQASVM-RBF | Reject H0 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chui, K.T.; Lytras, M.D.; Vasant, P. Combined Generative Adversarial Network and Fuzzy C-Means Clustering for Multi-Class Voice Disorder Detection with an Imbalanced Dataset. Appl. Sci. 2020, 10, 4571. https://doi.org/10.3390/app10134571
Chui KT, Lytras MD, Vasant P. Combined Generative Adversarial Network and Fuzzy C-Means Clustering for Multi-Class Voice Disorder Detection with an Imbalanced Dataset. Applied Sciences. 2020; 10(13):4571. https://doi.org/10.3390/app10134571
Chicago/Turabian StyleChui, Kwok Tai, Miltiadis D. Lytras, and Pandian Vasant. 2020. "Combined Generative Adversarial Network and Fuzzy C-Means Clustering for Multi-Class Voice Disorder Detection with an Imbalanced Dataset" Applied Sciences 10, no. 13: 4571. https://doi.org/10.3390/app10134571