Well Logging Based Lithology Identification Model Establishment Under Data Drift: A Transfer Learning Method
by
 ,
,
Haining Liu
1,2, 
Yuping Wu
3,
Yingchang Cao
1,
Wenjun Lv
4,*,
Hongwei Han
2,
Zerui Li
4 and
Ji Chang
4 1
School of Geosciences, China University of Petroleum, Qingdao 266580, China
2
Shengli Geophysical Research Institute of SINOPEC, Dongying 257022, China
3
School of Electrical Engineering, Yanshan University, Qinhuangdao 066004, China
4
Department of Automation, University of Science and Technology of China, Hefei 230027, China
*
Author to whom correspondence should be addressed.
Sensors 2020, 20(13), 3643; https://doi.org/10.3390/s20133643
Submission received: 29 May 2020
/
Revised: 21 June 2020
/
Accepted: 23 June 2020
/
Published: 29 June 2020
(This article belongs to the Section Intelligent Sensors)
Abstract
:Recent years have witnessed the development of the applications of machine learning technologies to well logging-based lithology identification. Most of the existing work assumes that the well loggings gathered from different wells share the same probability distribution; however, the variations in sedimentary environment and well-logging technique might cause the data drift problem; i.e., data of different wells have different probability distributions. Therefore, the model trained on old wells does not perform well in predicting the lithologies in newly-coming wells, which motivates us to propose a transfer learning method named the data drift joint adaptation extreme learning machine (DDJA-ELM) to increase the accuracy of the old model applying to new wells. In such a method, three key points, i.e., the project mean maximum mean discrepancy, joint distribution domain adaptation, and manifold regularization, are incorporated into extreme learning machine. As found experimentally in multiple wells in Jiyang Depression, Bohai Bay Basin, DDJA-ELM could significantly increase the accuracy of an old model when identifying the lithologies in new wells.
1. Introduction
Well logging data have grown dramatically over the past few decades due to the widespread deployment of oil wells and the rapid development of sensing technology. A large amount of data not only brings us more opportunities to understand the underground but also brings more great challenges to the interpretation of logging data [1,2]. Well logging provides an objective and continuous method with which to observe the properties of the rocks through which the drill bit passes and to describe the deposition process quantitatively. As a bridge between surface geophysical survey and subsurface geology, well logging is an effective and irreplaceable method to understand reservoir characteristics. As conventional reservoirs dry up, oil and gas companies are turning to unconventional exploration and development in shale and low-permeability reservoirs, posing more challenges for logging interpretation [3].
In traditional logging interpretation, lithology determination, porosity, and permeability calculations are performed by specialists in exploration and geology with specialized knowledge. Lithology identification is a fundamental problem in well logging interpretation and is of considerable significance in petroleum exploration engineering. It is the basis of reservoir parameter calculation (such as porosity, shale volume, permeability) and geological research (such as formation correlation, sedimentary modeling, favorable zone prediction, etc.). Due to the complexity of reservoir geological conditions, the uncertainty of exploration data and the inconsistency of expert experience, the results of lithology identification are mainly dependent on expertise. With the increasing diversity of logging data, the traditional logging interpretation methods which rely on human experience have some shortcomings and limitations. As a result, researchers are turning to more advanced data analysis methods for breakthroughs in lithology identification.
In recent years, with the rapid development of machine learning technology, its application in lithology identification has also attracted full attention [4]. In order to accurately and effectively determine the lithology type, a large amount of application work based on different machine learning began to emerge [5]. For example, G. Askari [6] used satellite remote sensing data to find the lithological information in Deh-Molla sedimentary succession by principal component analysis. Al-Anazi et al. [7] proposed a support vector machine-based classification feature method and selection method based on fuzzy theory to realize the recognition of potential features and the improvement of lithology recognition performance. Wang et al. [8] proposed a novel back propagation (BP) model by modifying the self-adapting algorithm and activation function, which is proven to be effective in predicting the lithologies of the Kela-2 gas field. The experimental results show that, compared with discriminant analysis and probabilistic neural network, support vector machines can identify different lithology of heterogeneous sandstone reservoirs more accurately. Xie et al. [9] evaluated five typical machine learning methods of naive Bayes, support vector machines, artificial neural networks, random forest and gradient tree enhancement based on the formation lithology identification data of the Danudui gas field and the Hangjinqi gas field. Experimental results show that the integrated method, including random forest and gradient tree enhancement, has a lower prediction error. At the same time, the gradient tree enhancement method has the highest accuracy compared with the other four methods. In order to reduce exploration uncertainty, Bhattacharya et al. [10] compared different methods of facies division and prediction of mudstone in the current conventional logging data, and applied them to the Devonian Bakken and Mamentago–Marsilus formations in North America. In this study, support vector machines (SVM), artificial neural networks (ANN), self-organizing mapping (SFM), and multi-resolution map based clustering (MRMC) are compared experimentally. Dev et al. [11] analyzed the data from China’s Danuci gas field and Hangjinqi gas field by the gradient lifting decision tree system (i.e., XGBoost, LightGBM, and CatBoost) to study formation lithology classification, and compared their performance with random forest, AdaBoost, and gradient boosting machines. Experiments show that LightGBM and CatBoost are the preferred algorithms for lithology classification by using well logging data. A large number of similar studies can be seen in [12,13,14,15,16].
In addition to these directly-applied studies, more and more scholars are focusing on how to improve existing machine learning tools to solve practical problems in lithology identification. Due to the different distribution of underground lithology, there is a severe class imbalance problem in the training data set. Furthermore, Deng et al. [17] introduced a borderline-stroke technique for dealing with unbalanced data, and the results showed that this method could effectively improve the classification accuracy of SVM, especially for the minority classes. There are many free hyper-parameters in machine learning algorithms, and the settings of these hyper-parameters will have significant influences on the performance of lithology identification. Therefore, Saporetti et al. [18] adopted an evolutionary parameter tuning strategy, and combined gradient boosting (GB) with differential evolution (DE) to achieve the optimization of super parameters, thereby making the lithology identification more stable. In the study of [19], the wavelet decomposition was used to construct multi-channel images of logging data, and then the lithology identification problem based on the logging curve was skillfully transformed into an image segmentation problem. Finally, the feasibility of this method was verified by the application in the Daqing oilfield. Aiming at the issue of data drift between different wells, Ao et al. [20] proposed a hybrid algorithm for lithology identification that combines the mean drift algorithm and the random forest algorithm in the prototype similarity space. It is pointed out that a more accurate lithology identification model can be obtained by transforming the classification problem into prototype similarity space. Li et al. [21] proposed a semi-supervised algorithm based on Generated Adversarial Network, which uses logging curves as the labeled data and seismic data as the unlabeled data. The model was trained by Adam algorithm and uses the discriminator to identify the lithologies. Compared with the experimental results of various supervised methods, the model can effectively use unlabeled data to achieve higher prediction accuracy. Similar work can be found in [22,23,24].
Although much work has been done, a practical problem, i.e., the well loggings from different wells are different in the probability distribution, is not taken into consideration. Hence, the model trained on old wells might not perform well on new wells. As illustrated in Figure 1, the phenomenon of data drift occurs between two wells, even when they are geospatially near. In particular, applying the model trained on well to well has many errors, as shown in Figure 1a. To suppress the data drift-induced accuracy decrease, we propose a transfer learning method named the data drift joint adaptation extreme learning machine (DDJA-ELM) to increase the accuracy of the old model applying to new wells. By incorporating the project mean maximum mean discrepancy, joint distribution domain adaptation, and manifold regularization into the extreme learning machine, we realize the knowledge transfer from old wells to new wells. As experimented in multiple wells in Jiyang Depression, Bohai Bay Basin, DDJA-ELM could increase the accuracy of an old model significantly when identifying the lithologies in new wells. In the remainder of the paper, Section 2 expatiates on the proposed DDJA-ELM, which is evaluated in Section 3. The last section concludes the paper.
2. Methodology
2.1. Notation
The dataset is composed of the sample with d dimension and the label if belongs to the k-th class, where n and c are the numbers of samples and classes, respectively. In well logging-based lithology identification, d generally means the number of loggings types, and c denotes the number of lithology types. A sample is composed of the logging values at a certain depth. Considering the problem of data drift, we use and to differentiate the datasets with drift; i.e., and represent the source dataset for training and the target dataset to predict, respectively. Specifically, the source dataset is labeled and the target dataset is unlabeled, thereby denoting and with and samples accordingly, and , where and are source and target-dataset samples, respectively; and is a source-dataset label of . By defining , , and , then the and .
2.2. Problem Definition and Formulation
In general, a classifier trained on classifies well on those samples that satisfied the independent identically distributed (i.i.d.) assumption. However, the classifier trained on might not perform well on because the data drift means that the i.i.d. assumption does not hold; i.e., the knowledge learned from cannot transfer to . In this case, it is necessary to add some new constraint conditions to achieve expected performance while learning the classifier f. Exactly, the expected performance can be concluded as the following constraint conditions: (i) minimizing the structural risk to avoid overfitting; (ii) minimizing the data drift between the source dataset and the target dataset; (iii) minimizing the prediction inconsistency within the target dataset. If considering the ELM as the basic classifier f, where is the output weight matrix of ELM.
According to the structural risk minimization (SRM) and regularization techniques [26], the classifier f can be denoted as
where the first term represents the empirical loss on samples (i.e., describing the fitness of applying the model to predict the training data); the second term represents the regularization term (i.e., representing the formulation of constraint conditions). Thus, combined with the constraint conditions mentioned above, the objective function is formulated mathematically as follows
where the empirical loss term and the structural risk regularization term compose the model accuracy and complexity of ELM. The term indicates the extent of data drift between and . Additionally, we introduce the manifold regularization term to improve the prediction consistency within the target dataset. and are the regularization parameters accordingly.
In the remainder of this section, we will expatiate on each term of the objective function.
2.2.1. ELM
Recent years have witnessed the development of a promising machine learning model; i.e., extreme learning machine (ELM). ELM is actually an artificial neural network with a single hidden layer, which was first proposed by Huang et al. [27] and found its application in many domains, such as robotic perception, hyperspectral image classification, lithology identification, and human activity recognition [28,29,30,31,32]. Compared with support vector machine and other artificial neural networks, ELM has significant superiority in generalization performance and training time. In addition, many variants for ELM have been investigated, including semi-supervised ELM, multi-kernel ELM, rough ELM, one-class ELM, etc. [33,34,35,36].
According to the objective function (2), we first describe the mathematical model of ELM as follows [37],
where represents the error vector with respect to the i-th training sample, and is the sum of prediction errors. The tradeoff coefficient C is used to balance the contribution between the two terms. Since the target dataset is unlabeled, if ; otherwise, ; and equals a zero vector if . The output of hidden layer is equal to where ; z is the number of hidden neurons; are the j-th random generated weight vector and bias constant; is a piecewise continuous nonlinear activation function, such as the sigmoid function or the Gaussian function . In this paper, the sigmoid function is used as the activation function.
2.2.2. Weighted ELM
Additionally, since each lithology in dataset usually contains the samples of different amounts, appropriate weights should be assigned to each error vectors for the samples imbalance issue, so (3) is rewritten as
where denotes the weight, and is a constant, and is the number of samples belonging to , thereby modifying the ELM to the weighted ELM (WELM).
Substituting the constraints (4b) into (4a) yields the equivalent unconstrained optimization problem and the matrix form:
where ; is a diagonal matrix with each item ; and , , , where and are the zero matrix and the identity matrix with appropriate dimension, respectively. By setting the gradient of (5) over to zero, we have
where ′ represents the transpose of matrix. There are two forms of an optimal solution to the . When the number of the training data is larger or smaller than the number of hidden neurons, then has more or fewer rows than columns, thereby resulting in an underdetermined or overdetermined least squares problem. The closed-form solution for (6) can be described as
where and are the identity matrix of and z dimensions.
2.2.3. Data Drift Adaptation
In general, the data distribution properties can be used to statistically describe the correlation among the samples , thus the data drift-induced distribution discrepancy can be estimated by statistical criteria. In this paper, we utilize the projected maximum mean discrepancy (PMMD) criterion for distribution discrepancy measure [38]. Thus, the regularization term with PMMD is formulated as
Further, (8) can be rewritten to a matrix form; that is,
where denotes the trace of a matrix. The elements of matrix are calculated by
According to (8), the samples and are transformed from the feature space to the mapping space by , where the distribution discrepancy between the source and target datasets can be reduced by adjusting . Thus, the modified WELM named data drift adaptation WELM (DDA-WELM) classifier can be achieved by introducing the regularization term to adapt the data drift.
However, the overall accuracy is increased with sacrificing the accuracies of some classes, because DDA-WELM is a method of reducing the distribution discrepancy between two datasets as a whole. Consequently, we modify the PMMD to propose the joint PMMD (JPMMD) that aims to reduce the distribution discrepancy between classes of two datasets, respectively. The regularization term with JPMMD is formulated as
where is the real label of and is the pseudo label of which is generated by the DDA-WELM classifier; and are the number of source-dataset samples which belong to the class k and the number of target-dataset samples whose pseudo labels are k, respectively.
Similarly, (11) can be rewritten to the matrix form; that is,
where the elements of matrix are computed by
Thus, the data drift joint adaptation WELM (DDJA-WELM) classifier can be obtained by introducing the regularization term and the DDA-WELM classifier to improve the WELM.
2.2.4. Manifold Regularization
Manifold regularization is widely used to improve the smoothness of predictions and suppress the classifier cutting through the high-density regions [39]. Specifically, we introduce the manifold regularization to assign smooth labels within the target dataset and make the classifier more adaptable to the target dataset.
The formulation of the manifold regularization is that
where the similarity between the sample and is calculated by
where is the set of -nearest neighboring samples of under the metric of Euclidean distance in feature space, and is the width of Guassian kernel. Additionally, (14) can be rewritten to a matrix form
where , is the target dataset Laplacian matrix, and , is a diagonal matrix with diagonal elements .
Thus, the classifiers DDA-WELM and DDJA-WELM can be upgraded to the DDA-S2WELM and DDJA-S2WELM by introducing the manifold regularization term . Moreover, the regularization term with pseudo labels generated by the DDA-S2WELM classifier can further improve the data drift adaptation performance of the DDJA-WELM and DDJA-S2WELM classifiers.
2.3. Solution of Objective Function
The solution of the objective function (2) is introduced in this section. Especially, the regularization term is divided into with PMMD and with JPMMD so that we will discuss them in the followings, respectively.
2.3.1. Solution of Objective Function with
By setting the gradient of f with respect to to be zero
According to (18), the closed-form solution of the optimal is
where z is the number of hidden neurons.
2.3.2. Solution of Objective Function with
3. Experimental Verification
In this section, we conduct extensive experiments to verify the effectiveness of our method, using the well-logging data collected from multiple wells in Jiyang Depression, Bohai Bay Basin. The experimental datasets and settings will be described first. Then, the performance and impact of each regularization terms are shown in detail. The analysis of hyper-parameters sensibility is presented at last.
3.1. Experimental Settings
As shown in Table 1, the experimental datasets are composed of three datasets collected from different regions in the Jiyang Depression, Bohai Bay Basin and contain 3, 2 and 2 wells, respectively (The wells in Figure 1 do not appear in the experimental datasets). Their relative positions are shown in Figure 2. Table 2 describes the data drift statistically by maximum mean discrepancy. In one experiment, we set the well A as the training data and the well B as the testing data, thereby verifying the effectiveness of our method through A → B. In this case, the other experiments are denoted as A → C, B → A, B → C, C → A, C → B, D → E, E → D, F → G, and G → F, respectively. Considering the different ranges of measurements, the value of samples are transformed to [0, 1] by a min-max normalization method. In the experiments, we adopt the index Recall (i.e., the number of classify correctly divided by the number of samples) to calculate the classification accuracy, thus denoting the average recall (Macro-R) to represent the overall classification accuracy.
3.2. Experimental Results
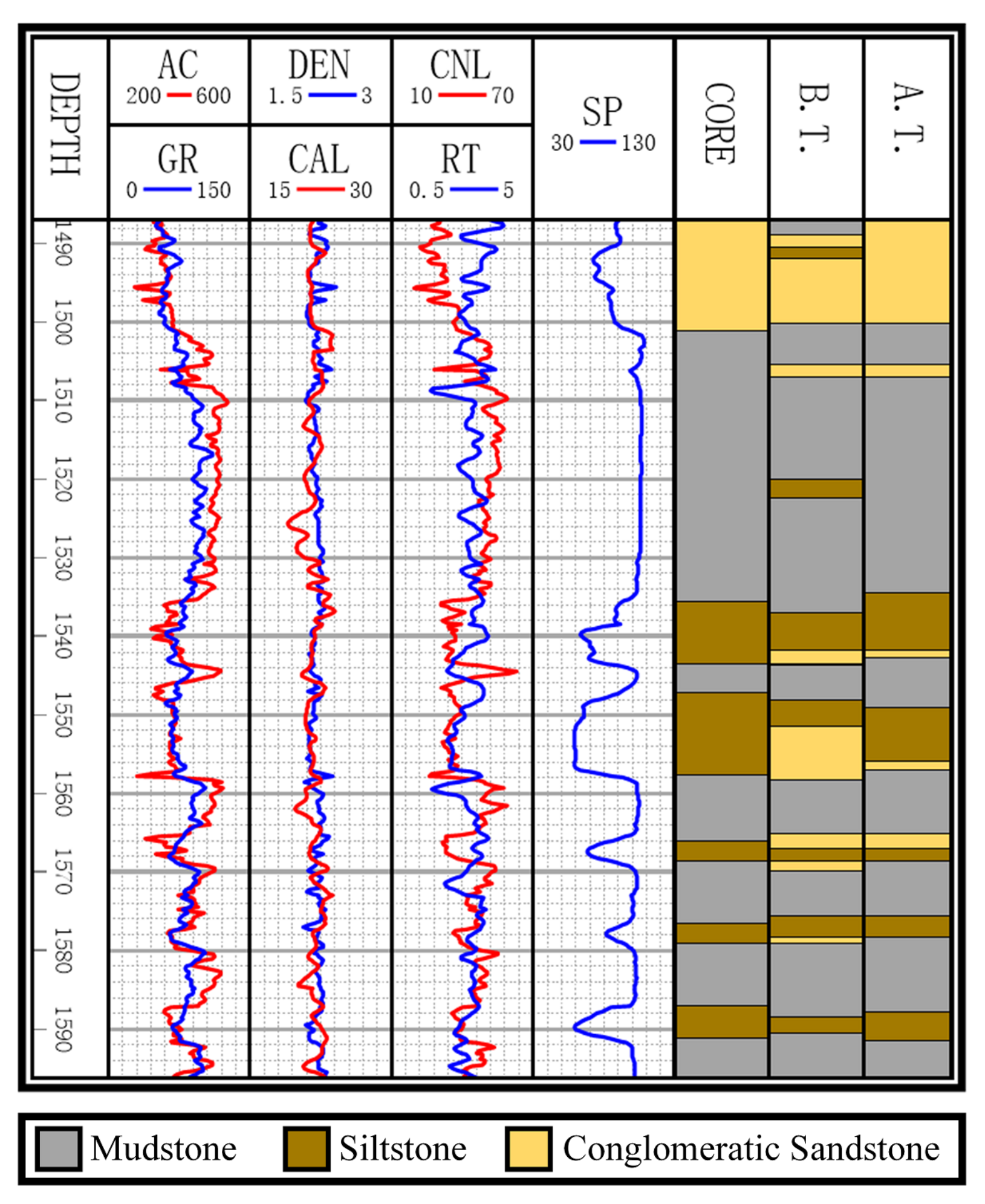
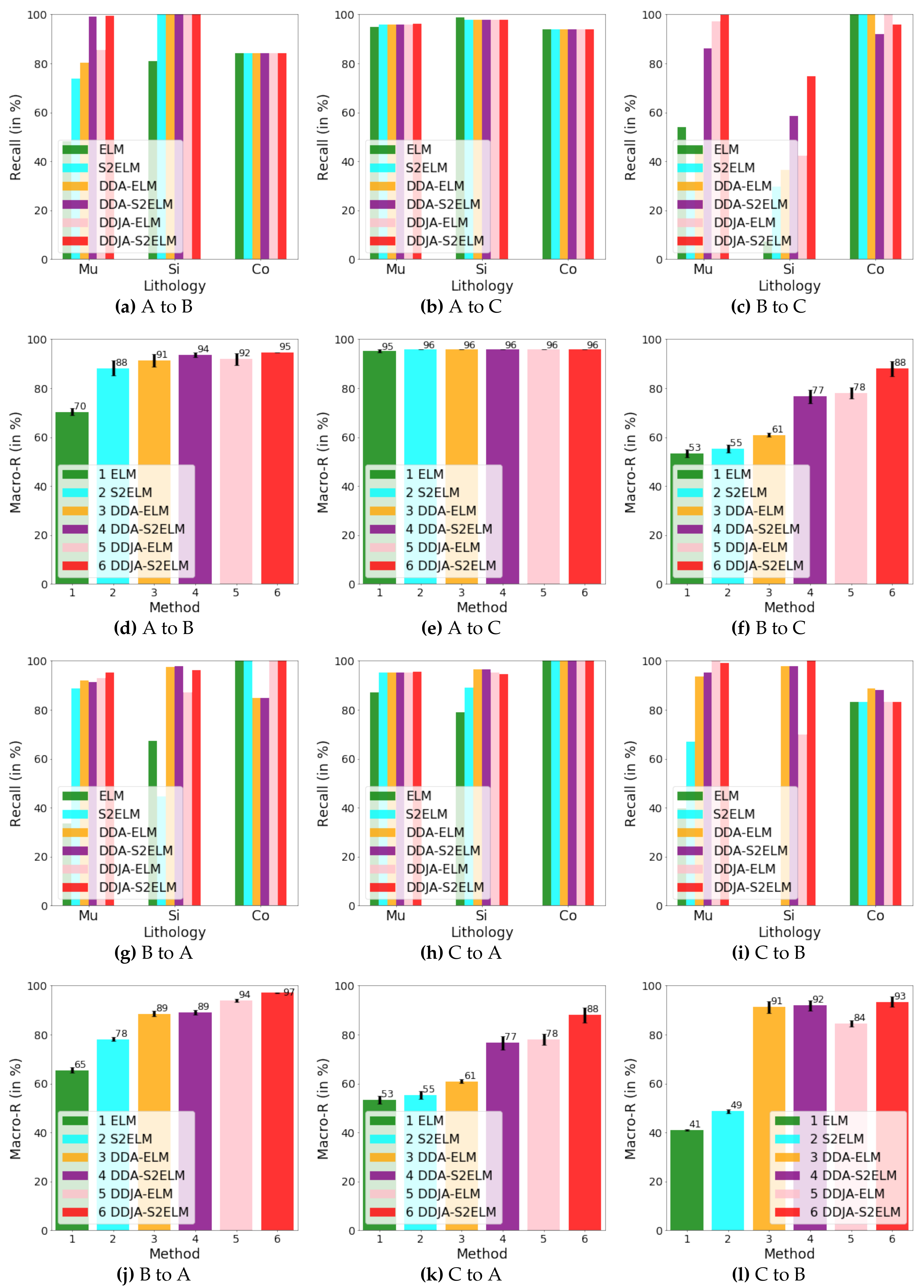
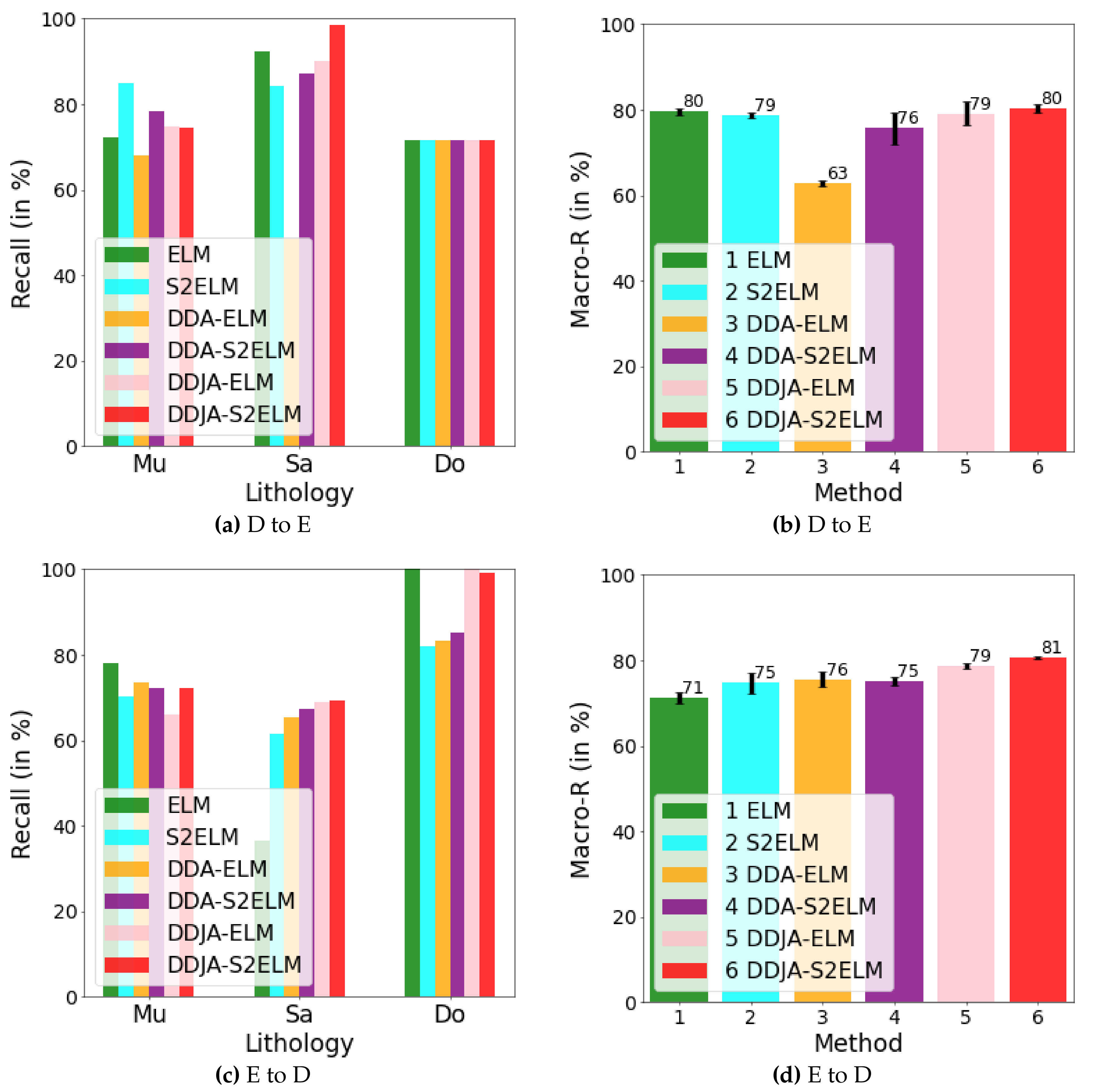
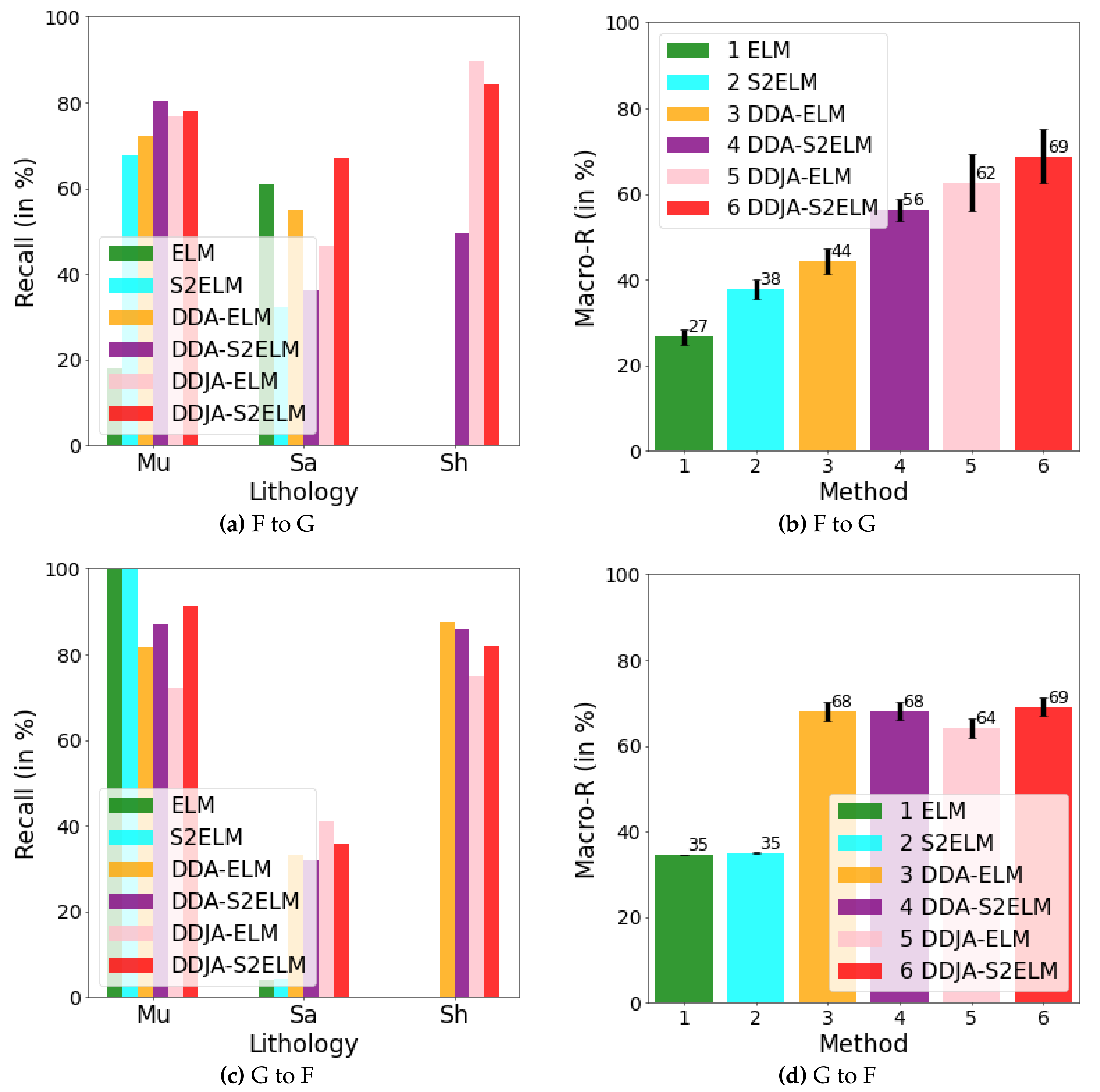
Figure 3 exhibits the logging curves, core (i.e., label), classification performance before B → A transfer (i.e., using model trained on data B to directly predict data A), and classification performance after B → A transfer. It is observed that transfer learning could eliminate the data drift-induced accuracy loss. As shown in Figure 4, Figure 5, and Figure 6, the classification performances of applying the classifiers ELM, S2ELM, DDA-ELM, DDA-S2ELM, DDJA-ELM, and DDJA-S2ELM to datasets 1, 2, and 3 are presented, respectively. It can be obviously observed from Figure 4a–c,g–i, Figure 5a,c, and Figure 6a,c, that the accuracy of each class is gradually increased with the introducing of DDJA regularization terms, especially when it comes to the accuracy of Si and Sh that increase from 0 to more than 80 in Figure 4i, Figure 6a,c, respectively. Additionally, the ELM and S2ELM classifiers without DDJA regularization term are insufficient to the tasks with data drift.
Considering the ELM–based classifier with the random weights and biases parameters, we conduct multiple experiments by setting different random seeds to generate different weights and biases parameters which yield the experimental results in Figure 4d–f,j–l, Figure 5b,d and Figure 6b,d. According to the results, we have the following observations: (i) The overall Macro-R shows a trend of increasing step by step and the DDJA-S2ELM classifiers achieve the highest accuracy. Moreover, the Macro-R of DDJA-S2ELM are increased to 88% at least compared with the ELM on dataset 1 (B → C and C→ A), 80% on dataset 2 (D → E), and 69% on dataset 3 (F →G and G → F). Additionally, compared the ELM classifier with the DDJA-S2ELM classifier, the Macro-R of our method are increased 52% on dataset 1 (C→ B), 10% on dataset 2 (E→ D), and 42% on dataset 3 (F→ G). (ii) Although the Macro-R is not increased on dataset 1 (A → C) and dataset 2 (D → E), the standard deviation can be kept at a lower level. Thus, the stability can be improved by introducing the DDJA-S2ELM. (iii) Comparing the experimental results on dataset 3 with datasets 1 and 2, the ELM classifiers only achieve 27% (F→ G) and 35% (G→ F). The performance is significantly enhanced with our method regarding the data drift-induced accuracy decrease surges.
3.3. Parameters’ Sensitivity
In this section, we aim to analyze the sensitivity on the key hyper-parameters of the DDJA-S2ELM: the trade-off coefficient C, the contribution coefficient of DDJA regularization term , and the contribution coefficient of semi-supervised regularization term . By analyzing the Macro-R over different settings of hyper-parameters, the configuration of these parameters is given. To avoid repetition, we only show the results of B → C.
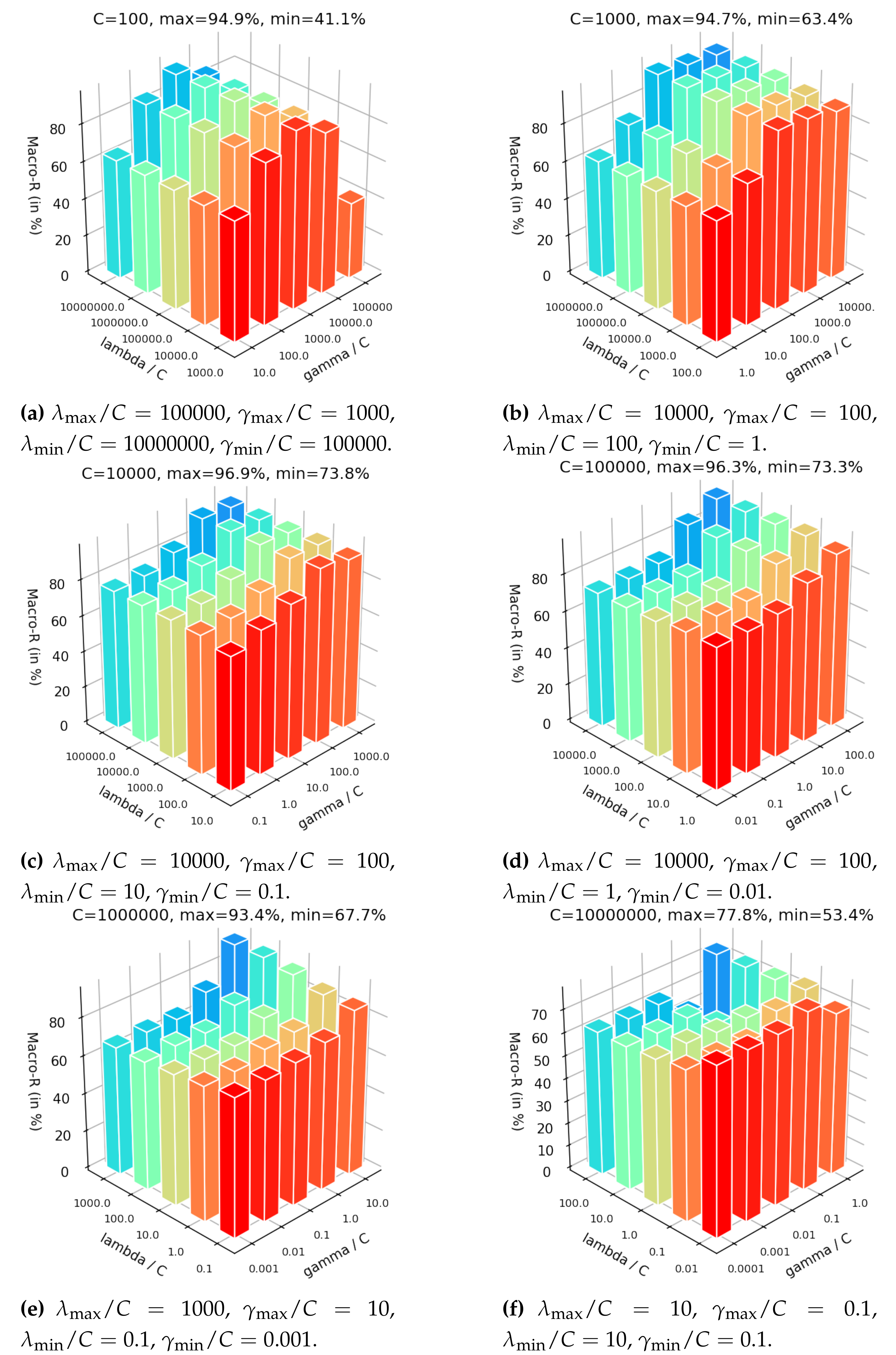
In the Figure 7, we set the hyper-parameter C range from 100 to 10,000,000. It can be seen from these figures in Figure 7 that the maximum and minimum Macro-R are increased first and then decreased with the increasing of C, indicating that a small C incurs under-fitting in classification and a high C causes the over-fitting. Additionally, when C is set too small or too big, the overall accuracies are preserved in the large variation range highest 94.9% in Figure 7a and lowest 41.1% in Figure 7a or the overall just more than 70% sightly in Figure 7f. According to Figure 7c,d with and , respectively, the overall Macro-R are held steady highest 96.9% in Figure 7c and lowest 73.8% in Figure 7c and the accuracies are presented a trend of increasing gradually. Therefore, it is important to configure a moderate C first.
The influence of adjusting and are given by fixing the C. It can be seen from Figure 7 that the maximum Macro-R is achieved 96.9% in Figure 7c when set and . Additionally, the Macro-R almost increase first and then decrease with getting larger under fixed showing in Figure 7a–c. Moreover, these results show that the maximum is achieved almost when setting the larger than by two to four orders of magnitude. Since the control the contribution of semi-supervised regularization term that based on the manifold assumption, but the assumption is invalid when the dataset with data drift. We introduce the DDJA regularization term to suppress the data drift, so the coefficient should be more than .
According to the analysis of setting C, , and mentioned above, it can be concluded that: (i) C should be set a relatively larger range first to configure a moderate value; (ii) the setting of should be bigger than by two to four orders of magnitude. Here are some suggested settings: , , .
Furthermore, we use Sobol method (In our experiment, the python tool "SALib" is employed, which can be found at https://salib.readthedocs.io/en/latest/index.html). Ref. [41] to implement a global sensitivity analysis where all parameters are varied simultaneously over the entire parameter space. The sensitivities shown in Table 3 demonstrate that: (i) C and contribute mainly compared with , (ii) C contributes more than slightly, and (iii) the interactions between these parameters are weak, so they are relatively independent.
4. Conclusions
In this paper, we have investigated the well logging-based lithology identification under data drift, thus proposing a transfer Extreme Learning Machine method to handle it. According to the projected maximum mean discrepancy (PMMD) criterion and extreme learning machine, we introduce a new PMMD criterion and then propose the DDJA-ELM to minimize the data drift between the source dataset and the target dataset. Additionally, in order to improve the prediction consistency within the target dataset, the manifold regularization is introduced to promote the DDJA-ELM to the DDJA-S2ELM. Extensive experiments have validated the high and stable accuracy of our method.
Author Contributions
Conceptualization, H.L. and W.L.; Data curation, Y.C.; Formal analysis, H.L.; Funding acquisition, H.H.; Investigation, Y.W. and T.X.; Methodology, Y.W.; Project administration, H.H.; Resources, Z.L.; Software, Z.L.; supervision, W.L.; Validation, Y.C. and J.C.; Visualization, J.C.; Writing—Original draft, H.L.; Writing—Review and editing, W.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Natural Science Foundation of China (61903353), SINOPEC Programmes for Science and Technology Development (PE19008-8), and Fundamental Research Funds for the Central Universities (WK2100000013).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Bergen, K.J.; Johnson, P.A.; Maarten, V.; Beroza, G.C. Machine learning for data-driven discovery in solid Earth geoscience. Science 2019, 363, eaau0323. [Google Scholar] [CrossRef] [PubMed]
- Van Natijne, A.; Lindenbergh, R.C.; Bogaard, T.A. Machine Learning: New Potential for Local and Regional Deep-Seated Landslide Nowcasting. Sensors 2020, 20, 1425. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Verma, S.; Zhao, T.; Marfurt, K.J.; Devegowda, D. Estimation of total organic carbon and brittleness volume. Interpretation 2016, 4, T373–T385. [Google Scholar] [CrossRef] [Green Version]
- Keynejad, S.; Sbar, M.L.; Johnson, R.A. Assessment of machine-learning techniques in predicting lithofluid facies logs in hydrocarbon wells. Interpretation 2019, 7, SF1–SF13. [Google Scholar] [CrossRef]
- Zhang, T.F.; Tilke, P.; Dupont, E.; Zhu, L.C.; Liang, L.; Bailey, W. Generating geologically realistic 3D reservoir facies models using deep learning of sedimentary architecture with generative adversarial networks. Pet. Sci. 2019, 16, 541–549. [Google Scholar] [CrossRef] [Green Version]
- Askari, G.; Pour, A.B.; Pradhan, B.; Sarfi, M.; Nazemnejad, F. Band Ratios Matrix Transformation (BRMT): A Sedimentary Lithology Mapping Approach Using ASTER Satellite Sensor. Sensors 2018, 18, 3213. [Google Scholar] [CrossRef] [Green Version]
- Al-Anazi, A.; Gates, I. On the capability of support vector machines to classify lithology from well logs. Nat. Resour. Res. 2010, 19, 125–139. [Google Scholar] [CrossRef]
- Wang, K.; Zhang, L. Predicting formation lithology from log data by using a neural network. Pet. Sci. 2008, 5, 242–246. [Google Scholar] [CrossRef] [Green Version]
- Xie, Y.; Zhu, C.; Zhou, W.; Li, Z.; Liu, X.; Tu, M. Evaluation of machine learning methods for formation lithology identification: A comparison of tuning processes and model performances. J. Pet. Sci. Eng. 2018, 160, 182–193. [Google Scholar] [CrossRef]
- Bhattacharya, S.; Carr, T.R.; Pal, M. Comparison of supervised and unsupervised approaches for mudstone lithofacies classification: Case studies from the Bakken and Mahantango-Marcellus Shale, USA. J. Nat. Gas Sci. Eng. 2016, 33, 1119–1133. [Google Scholar] [CrossRef] [Green Version]
- Dev, V.A.; Eden, M.R. Formation lithology classification using scalable gradient boosted decision trees. Comput. Chem. Eng. 2019, 128, 392–404. [Google Scholar] [CrossRef]
- Wang, X.; Yang, S.; Zhao, Y.; Wang, Y. Lithology identification using an optimized KNN clustering method based on entropy-weighed cosine distance in Mesozoic strata of Gaoqing field, Jiyang depression. J. Pet. Sci. Eng. 2018, 166, 157–174. [Google Scholar] [CrossRef]
- Gu, Y.; Bao, Z.; Song, X.; Patil, S.; Ling, K. Complex lithology prediction using probabilistic neural network improved by continuous restricted Boltzmann machine and particle swarm optimization. J. Pet. Sci. Eng. 2019, 179, 966–978. [Google Scholar] [CrossRef]
- Zhong, Y.; Zhao, L.; Liu, Z.; Xu, Y.; Li, R. Using a support vector machine method to predict the development indices of very high water cut oilfields. Pet. Sci. 2010, 7, 379–384. [Google Scholar] [CrossRef] [Green Version]
- Dong, S.; Wang, Z.; Zeng, L. Lithology identification using kernel Fisher discriminant analysis with well logs. J. Pet. Sci. Eng. 2016, 143, 95–102. [Google Scholar] [CrossRef]
- Guo, D.; Zhu, K.; Wang, L.; Li, J.; Xu, J. A new methodology for identification of potential pay zones from well logs: Intelligent system establishment and application in the Eastern Junggar Basin, China. Pet. Sci. 2014, 11, 258–264. [Google Scholar] [CrossRef] [Green Version]
- Deng, C.; Pan, H.; Fang, S.; Konaté, A.A.; Qin, R. Support vector machine as an alternative method for lithology classification of crystalline rocks. J. Geophys. Eng. 2017, 14, 341–349. [Google Scholar] [CrossRef]
- Saporetti, C.M.; da Fonseca, L.G.; Pereira, E. A Lithology Identification Approach Based on Machine Learning With Evolutionary Parameter Tuning. IEEE Geosci. Remote. Sens. Lett. 2019, 16, 1819–1823. [Google Scholar] [CrossRef]
- Zhu, L.; Li, H.; Yang, Z.; Li, C.; Ao, Y. Intelligent Logging Lithological Interpretation With Convolution Neural Networks. Petrophysics 2018, 59, 799–810. [Google Scholar] [CrossRef]
- Ao, Y.; Li, H.; Zhu, L.; Ali, S.; Yang, Z. Logging lithology discrimination in the prototype similarity space with random forest. IEEE Geosci. Remote. Sens. Lett. 2018, 16, 687–691. [Google Scholar] [CrossRef]
- Li, G.; Qiao, Y.; Zheng, Y.; Li, Y.; Wu, W. Semi-Supervised Learning Based on Generative Adversarial Network and Its Applied to Lithology Recognition. IEEE Access 2019, 7, 67428–67437. [Google Scholar] [CrossRef]
- Li, Z.; Kang, Y.; Lv, W.; Zheng, W.X.; Wang, X.M. Interpretable Semisupervised Classification Method Under Multiple Smoothness Assumptions With Application to Lithology Identification. IEEE Geosci. Remote. Sens. Lett. 2020. [Google Scholar] [CrossRef]
- Dunham, M.W.; Malcolm, A.; Welford, J.K. Improved well log classification using semi-supervised algorithms. In SEG Technical Program Expanded Abstracts 2019; Society of Exploration Geophysicists: Houston, TX, USA, 2019; pp. 2398–2402. [Google Scholar]
- Saleem, A.; Choi, J.; Yoon, D.; Byun, J. Facies classification using semi-supervised deep learning with pseudo-labeling strategy. In SEG Technical Program Expanded Abstracts 2019; Society of Exploration Geophysicists: San Antonio, TX, USA, 2019; pp. 3171–3175. [Google Scholar]
- Maaten, L.v.d.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Vapnik, V.N.; Vapnik, V. Statistical Learning Theory; Wiley: New York, NY, USA, 1998; Volume 1. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhou, H.; Ding, X.; Zhang, R. Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybern 2011, 42, 513–529. [Google Scholar] [CrossRef] [Green Version]
- Lv, W.; Kang, Y.; Zheng, W.X.; Wu, Y.; Li, Z. Feature-temporal semi-supervised extreme learning machine for robotic terrain classification. IEEE Trans. Circuits Syst. II Express Briefs 2020. [Google Scholar] [CrossRef]
- Mei, M.; Chang, J.; Li, Y.; Li, Z.; Li, X.; Lv, W. Comparative study of different methods in vibration-based terrain classification for wheeled robots with shock absorbers. Sensors 2019, 19, 1137. [Google Scholar] [CrossRef] [Green Version]
- Ding, S.; Zhao, H.; Zhang, Y.; Xu, X.; Nie, R. Extreme learning machine: algorithm, theory and applications. Artif. Intell. Rev. 2015, 44, 103–115. [Google Scholar] [CrossRef]
- Fang, X.; Cai, Y.; Cai, Z.; Jiang, X.; Chen, Z. Sparse Feature Learning of Hyperspectral Imagery via Multiobjective-Based Extreme Learning Machine. Sensors 2020, 20, 1262. [Google Scholar] [CrossRef] [Green Version]
- Tian, Y.; Zhang, J.; Chen, L.; Geng, Y.; Wang, X. Selective Ensemble Based on Extreme Learning Machine for Sensor-Based Human Activity Recognition. Sensors 2019, 19, 3468. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Song, S.; Gupta, J.N.; Wu, C. Semi-supervised and unsupervised extreme learning machines. IEEE Trans. Cybern. 2014, 44, 2405–2417. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, Y.; Zhou, G.; Jin, J.; Wang, B.; Wang, X.; Cichocki, A. Multi-kernel extreme learning machine for EEG classification in brain-computer interfaces. Expert Syst. Appl. 2018, 96, 302–310. [Google Scholar] [CrossRef]
- Feng, L.; Xu, S.; Wang, F.; Liu, S.; Qiao, H. Rough extreme learning machine: A new classification method based on uncertainty measure. Neurocomputing 2019, 325, 269–282. [Google Scholar] [CrossRef] [Green Version]
- Dai, H.; Cao, J.; Wang, T.; Deng, M.; Yang, Z. Multilayer one-class extreme learning machine. Neural Netw. 2019, 115, 11–22. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Quanz, B.; Huan, J. Large margin transductive transfer learning. In Proceedings of the 18th ACM Conference on Information and Knowledge Management, Hong Kong, China, 2–6 November 2009; pp. 1327–1336. [Google Scholar]
- Shi, W.; Li, Z.; Lv, W.; Wu, Y.; Chang, J.; Li, X. Laplacian Support Vector Machine for Vibration-Based Robotic Terrain Classification. Electronics 2020, 9, 513. [Google Scholar] [CrossRef] [Green Version]
- Gretton, A.; Borgwardt, K.; Rasch, M.; Schölkopf, B.; Smola, A.J. A kernel method for the two-sample-problem. In Advances in Neural Information Processing Systems; NIPS: Vancouver, BC, Canada, 2007; pp. 513–520. [Google Scholar]
- Sobol, I.M. Global sensitivity indices for nonlinear mathematical models and their Monte Carlo estimates. Math. Comput. Simul. 2001, 55, 271–280. [Google Scholar] [CrossRef]
Figure 1.
Illustration of data drift (a): Logging curves, core, and prediction results (using the model trained on well ) on well . (b) Logging curves, core, and prediction results (using the model trained on ) of . (c) t-SNE [25] visualization of data distribution for and . Gray, yellow, and green indicate mudstone, sandstone, and dolomite, respectively. Point and hollow square indicate data from and , respectively. and are geospatially near.
Figure 1.
Illustration of data drift (a): Logging curves, core, and prediction results (using the model trained on well ) on well . (b) Logging curves, core, and prediction results (using the model trained on ) of . (c) t-SNE [25] visualization of data distribution for and . Gray, yellow, and green indicate mudstone, sandstone, and dolomite, respectively. Point and hollow square indicate data from and , respectively. and are geospatially near.

Figure 2.
Relative positions of experimental wells.

Figure 3.
Logging curves, core, and classification results of B.T. (before transfer) and A.T. (after transfer).
Figure 3.
Logging curves, core, and classification results of B.T. (before transfer) and A.T. (after transfer).

Figure 4.
The results of performing our method on dataset 1. In (a)–(c), (g)–(i), we show the recalls for the classes of Mu, Si, and Co by using different methods. In (d)–(f), (j)–(l), we show the macro average recalls by using different methods.
Figure 4.
The results of performing our method on dataset 1. In (a)–(c), (g)–(i), we show the recalls for the classes of Mu, Si, and Co by using different methods. In (d)–(f), (j)–(l), we show the macro average recalls by using different methods.

Figure 5.
The results of performing our method on dataset 2. In (a) and (b), we show the recalls for the classes of Mu, Sa, and Do and their macro average recall by transferring D to E. In (c) and (d), we show those by transferring E to D.
Figure 5.
The results of performing our method on dataset 2. In (a) and (b), we show the recalls for the classes of Mu, Sa, and Do and their macro average recall by transferring D to E. In (c) and (d), we show those by transferring E to D.

Figure 6.
The results of performing our method on dataset 3. In (a) and (b), we show the recalls for the classes of Mu, Sa, and Sh and their macro average recall by transferring F to G. In (c) and (d), we show those by transferring G to F.
Figure 6.
The results of performing our method on dataset 3. In (a) and (b), we show the recalls for the classes of Mu, Sa, and Sh and their macro average recall by transferring F to G. In (c) and (d), we show those by transferring G to F.

Figure 7.
Classification accuracies of JDA-S2ELM on dataset 1 over the variation of C, and .


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Dataset description.
| Dataset | 1 | 2 | 3 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LOGS | AC, CAL, CNL, GR, RT, SP | AC, CAL, GR, R25, SP | AC, CAL, GR, R25, SP | |||||||||
| Samples | LITH | Mu | Si | Co | LITH | Mu | Sa | Do | LITH | Mu | Sa | Sh |
| Well A | 3820 | 2048 | 452 | Well D | 4508 | 3076 | 1000 | Well F | 6072 | 2852 | 1644 | |
| Well B | 2164 | 1584 | 432 | Well E | 5000 | 1464 | 1112 | Well G | 6996 | 3404 | 1548 | |
| Well C | 2368 | 1452 | 400 | - | - | |||||||
[1] Logging curves. AC: acoustic log, CAL: caliper log, CNL: compensated neutron log, GR: gamma ray log, RT: true formation resistivity, SP: spontaneous potential log, R25: 2.5 m bottom gradient resistivity. [2] Lithology. Mu: mudstone, Si: siltstone, Co: conglomeratic sandstone, Sa: sandstone, Do: dolomite, Sh: shale.
Table 2.
Data drift description.
| A and B | A and C | B and C | D and E | F and G | |
|---|---|---|---|---|---|
| MMD Class 1 | 0.107 | 0.182 | 0.281 | 0.109 | 0.090 |
| MMD Class 2 | 0.230 | 0.067 | 0.277 | 0.238 | 0.251 |
| MMD Class 3 | 0.203 | 0.026 | 0.384 | 0.189 | 0.601 |
| MMD Overall | 0.540 | 0.275 | 0.942 | 0.536 | 0.942 |
[1] MMD is short for maximum mean discrepancy, which can be found in [40]. [2] For (A,B), (A,C), and (B,C), classes 1–3 mean Mu, Si, and Co, respectively. For (D,E), classes 1–3 mean Mu, Sa, and Do, respectively. For (F,G), classes 1–3 mean Mu, Sa, and Sh, respectively.
Table 3.
Sensitivity analysis using Sobol method.
| Param. | First-Order Sensitivity | Total Sensitivity | Param. 1 | Param. 2 | Second-Order Sensitivity | |
|---|---|---|---|---|---|---|
| C | 0.511 | 0.575 | C | 0.074 | ||
| 0.337 | 0.495 | C | 0.008 | |||
| 0.051 | 0.102 | 0.085 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Liu, H.; Wu, Y.; Cao, Y.; Lv, W.; Han, H.; Li, Z.; Chang, J. Well Logging Based Lithology Identification Model Establishment Under Data Drift: A Transfer Learning Method. Sensors 2020, 20, 3643. https://doi.org/10.3390/s20133643
AMA Style
Liu H, Wu Y, Cao Y, Lv W, Han H, Li Z, Chang J. Well Logging Based Lithology Identification Model Establishment Under Data Drift: A Transfer Learning Method. Sensors. 2020; 20(13):3643. https://doi.org/10.3390/s20133643
Chicago/Turabian StyleLiu, Haining, Yuping Wu, Yingchang Cao, Wenjun Lv, Hongwei Han, Zerui Li, and Ji Chang. 2020. "Well Logging Based Lithology Identification Model Establishment Under Data Drift: A Transfer Learning Method" Sensors 20, no. 13: 3643. https://doi.org/10.3390/s20133643
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.