
Abstract
The satisfactory recovery of the hydrocarbon gases has made them a reliable choice for gas injection-based enhanced oil recovery (EOR) techniques. The minimum miscibility pressure (MMP) is a pivotal parameter governing the recovery factor during gas injection processes. Therefore, the determination of the authentic MMP is of a crucial importance. Due to the drawback of the experimental techniques (time and cost), empirical correlations are valuable tools in MMP determination. In this study, a multi-gene genetic programming and another software known as LINGO as an optimization tool are applied to offer a dependable MMP formula based on a comprehensive MMP dataset (a total of 108 MMP data). The independent parameters of reservoir temperature, pseudocritical temperature of the injection gas, molecular weight of C5+ components of the reservoir fluid and the intermediate (H2S, CO2, C2–C4)-to-volatile (N2 and C1) ratio are considered as input variables. A comprehensive set of experimental data covers wide span of primary parameters. Furthermore, in order to judge the accuracy of the suggested model and assess the precision and compare the predicted MMP by the current model with those estimated by preexisting correlations, the statistical and graphical error analyses have been employed. Based on the results, the proposed model can estimate MMP of the associated gas with an average absolute relative error of 9.86%. Also, the proposed correlation is more trustworthy and precise than the preexisting models in an extensive spectrum of thermodynamic circumstances. Eventually, the relevancy factor has depicted that the pseudocritical temperature of the injected gas has the most severe role in miscibility achievement.
Similar content being viewed by others


Introduction
The maturity of crude oil reservoirs has compelled us toward enhanced oil recovery methods to increase recovery efficiency from such reservoirs. Among these EOR techniques, the gas injection is one of the most competent ones attributing to reservoir fluid withdrawal. In fact, during the gas injection, aggregating of the different mechanisms such as reservoir fluid viscosity reduction and tapering the interfacial tension by means of mass transfer of light and intermediate components between the reservoir oil and injected gas leads to ascendance in reservoir fluid production (Taber et al. 1997).
Since during gas injection processes both condensing and vaporization mechanisms contribute in miscibility achievement (Ahmadi and Johns 2011), the injected gas components change dramatically toward that of the associated gas during the gas injection processes. On the other hand, sometimes recycling the associated gas during the crude production is more beneficial than the injection of the CO2 and N2. To be more precise, due to the prerequisite high pressure to reach miscibility and the high cost of the N2 production by cryogenic processes for nitrogen injection, it is not very pragmatic. On the other hand, asphaltene precipitation and its consequence formation damage problems caused by CO2 injection (Fathinasab and Ayatollahi 2016; Hagedorn and Orr Jr 1994) are among the drawbacks of CO2 injections.
Accurate determination of the minimum miscibility pressure is the most decisive factor in associated gas injection operations. There are some techniques that can be employed in MMP determination. Despite of the expensive and cumbersome experimental techniques like the slim tube (Elsharkawy et al. 1992), rising bubble apparatus (Mihcakan 1994) and vanishing interfacial tension (VIT) method (Fathinasab et al. 2018), the MMP-estimating correlations are trustworthy auxiliary tools in feasibility assessment of gas injection techniques. Moreover, these correlations can be exploited in screening gas injection operations before undertaking to the costly and time-consuming experimental techniques.
Although there are so many correlations in MMP determination during the carbon dioxide (CO2) and nitrogen (N2) injection (Fathinasab and Ayatollahi 2016; Fathinasab et al. 2015), there is no robust correlation in MMP estimation of the associated gas. To be more precise, although there are a few empirical models for MMP prediction of associated gas flooding including Kuo (1985), Maklavani et al. (2010) and Firoozabadi and Khalid (1986), these formulas have been drawn based on the skimp data points that cannot predict reliably the minimum miscibility pressure during hydrocarbon gas injection processes. That is because the independent parameters cover narrow range of affecting thermodynamic parameters. Moreover, due to the fact that these models were engendered based on incomplete data, they cannot precisely estimate the minimum miscibility pressure even in the acclaimed range of the independent factors by their authors.
Nowadays, one of the techniques that have received painstaking attention and have been widely exploited in providing accurate estimation for the various properties of chemical fluids in chemical and petroleum industries is artificial neural network (Shafiei et al. 2013; Shateri et al. 2015; Talebi et al. 2014; Zendehboudi et al. 2013, 2014). Nonetheless, since these smart techniques are black box, they do not afford a vivid interaction among the predicted value by the model as output and impressing parameters as inputs. On the other hand, genetic programming (GP), as an intelligent tool that creates a meaningful relationship (mathematical equation) among the estimated value by these models and influential parameters, has been beneficial in petroleum and chemical engineering to model some crucial properties (Bagheri et al. 2013; Gharagheizi et al. 2012; Kamari et al. 2015). This technique, so far, has not been used for development of a correlation in predicting of MMP during associated gas streams.
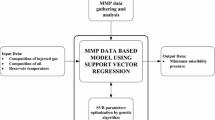
This work is targeted to create a more precise MMP model for hydrocarbon gas injection based on a collection of exhaustive experimental data that covers a wide range of thermodynamic conditions (temperature and pressure), injection gas and crude oil compositions that gathered from the literature (Al-Ajmi et al. 2009; Eakin and Mitch 1988; Firoozabadi and Khalid 1986; Jacobson 1972; Jaubert et al. 2002; Zuo et al. 1993). The input variables of the proposed model include reservoir temperature, average critical temperature of injection gas as the property of injection fluid, the ratio of the intermediate to volatile components and the molecular weight of pentane plus fraction of crude oil. For this purpose, GP is utilized to find an acceptable and easily usable mathematical structure for the MMP model. One of the drawbacks of GP is that it is time-consuming. To encounter this shortcoming, some other optimization methods can be coupled with it to accelerate the model development processes. One of the techniques that can be advantageous is the constrained multivariable search methods. There are numerous cases that, previously, have benefitted from the softwares employing this technique, in development of plain and precise models for anticipation of crude oil characteristics such as density and viscosity and some other PVT properties of reservoir fluid (Arabloo et al. 2014; Hemmati-Sarapardeh et al. 2013). For the prominent privileges of constrained multivariable search methods, they are considered as optimization tools that can be merged with GP to boost the precision of the developed prototype by GP. Finally, statistical and graphical error analyses as criterions to assess the precision and credibility of the obtained model and compare it with the existing models have been used. In addition, in order to find which independent parameters have more effect on the MMP, sensitivity analysis was performed. One of the potential usage of the proposed correlation is that it can be applied in any simulation software due to its more reliable predictions over the existing models.
Model development
Genetic programming
Genetic programming is among the most efficient evolutionary algorithms that, on the base of mathematically rational representation, develops an empirical model of the existing data. In fact, GP by automatically evolving a structure from different parameters constructs the mathematical model representing the system. In order to construct a model, GP firstly generates an initial random population which contains distinct individuals composed of various parameters. Each one of these individuals incorporates some trees (depending on GP parameters) that the weighted linear assemblage of these trees constructs an individual. To better illustrate, Fig. 1 shows the following formula:

Tree structure of a multi-gene symbolic model
Depending on the precision of each individual in anticipating the experimental values in the current population, it will be selected for performing different genetic operations consisting of changing (mutation), merging (crossover) and elitism or replication of best submodels for construction of the next generation. Through an iterative process of implementation of the genetic operations on the basis of the individual fitness until the construction of an individual with a reasonable accuracy or satisfying the predetermined criterion, the best model will be obtained by GP (Fathinasab and Ayatollahi 2016; Talebi et al. 2014).
Constrained multivariable search methods
Since finding an accurate model just by the GP algorithm takes a long time, for hastening the process and boosting the model’s precision, the GP and two other constrained multivariable search methods, namely generalized reduced gradient (GRG) and successive linear programming (SLP), were merged together. GRG utilizes nonlinear constraints manners by developing strategies for linear constraints. In order to know more about GRG, one can be referred to studies (David et al. 1986; Sharma and Glemmestad 2013). SLP method, by using linear programming as a search technique, is extensively used in oil and gas industry (Griffith and Stewart 1961). These algorithms are available in a popular software that is broadly utilized in science and technology known as Linear Interactive and General Optimizer (LINGO).
These algorithms along with the branch-and-bound approaches to discrete the model into different convex parts and the multi-start character of the LINGO that resumes the nonlinear solver from a few of ingeniously generated points (Carvalho et al. 2012) circumvent the obstacle of falling at local optimal solutions. The competency of this software in developing a model for predicting crude oil properties has been tested over the course of time (Fathinasab and Ayatollahi 2016; Fathinasab et al. 2015; Naseri et al. 2012).
To be more precise, the LINGO improves the GP proposed model estimations through optimizing of the model coefficients. The cooperation of GP and LINGO is by the way that after the construction of ten of the satisfactory models by GP, their coefficients will be optimized by LINGO. Finally, the best model based on its ability in MMP approximation has been selected as a model for associated gas MMP determination. Figure 2 manifests the cooperation of GP and LINGO algorithms in model development.

Flowchart for GP and LINGO cooperation used in this study
Development of the new model
An exhaustive dataset enveloping a broad span of reservoir temperature, oil and gas diversity has been gathered from the literature. The data bank was indiscriminately segregated into two separate subsections of the developing and examining sets. The developing set covers the 80% of the total data. (86 data were made to work for creation of the proposed model.) The rest 20% of the data bank were considered as the testing set. During the model development process, firstly, GP constructs a primary functional format to estimate the best approximation of the MMP. Then, some of the best primary correlations drawn from GP are selected for optimization of their coefficients by LINGO software. In Table 1, the parameters of GP for the best developed model from easiness and precision aspect have been shown.
The final proposed model is as follows:
where
where T and TCM are the temperature of reservoir and critical temperature of injecting gas, respectively. Moreover, temperatures are in Kelvin (K) and MMP is in Mpa.
Model assessment
To evaluate the proficiency of the suggested correlation for MMP, we compare the estimated values by this model to the predicted MMPs by three previously offered famous equations, namely Firoozabadi and Khalid (1986), Kuo (1985) and Maklavani et al. (2010), through statistical and graphical error assessment.
Statistical error assessment
We use some statistical criterions including average relative error [APRE (%)], average absolute relative error [AAPRE (%)], standard deviation of error (SD) and root mean square error (RMSE) to evaluate the efficiency of the new formula and compare it with old ones. These criterions can be calculated based on the following equations.
Average relative error
It measures the relative deflection from the experimentally measured base data and is calculated by the following formula:
where Ei % is the relative deviance of an approximated MMP by the correlation from a true MMP and is presented as percent relative error:
Average absolute relative error
That is the relative absolute deviance of the experimental data, earned by:
Root mean square error
It is expressive of data scattering in vicinity of zero deviance and is described by:
Standard deviation
This parameter is an illustrative of dissipation. The lower its magnitude, the smaller the degree of scattering. However, it is defined as:
Graphical error analysis
To better perceive the preciseness and competency of the suggested correlation in MMP estimation, various graphical error analyses such as cross-plot and cumulative frequency have been used.
Cross-plots
These graphs reveal all approximated MMP by the specific model against their corresponding experimentally measured values. Also, a line known as unit slope line (Y = X) among the approximated MMPs and real MMPs is plotted on the cross-plot. The closer the plotted data to 45o line, the more robust the correlation is.
Cumulative frequency
In this plot, a portion of the data points that have absolute percent relative errors below specific absolute percent relative error is plotted in an ascending order against the cumulative number of data for distinct model. To visually compare the results of different models, we sketched the results of cumulative error of various correlations on the same plot.
Results and discussion
The precision of the developed correlation was examined. Table 2 reveals the results of the implemented statistical error assessment for the MMP equations. This table attests most of previously developed formulas that approximate the MMP with huge error and cannot exactly show MMP during associated gas injection. Kuo correlation (Kuo 1985) is the worst model for MMP prediction, while Maklavani et al. (2010) correlation has given the best predictions among the previously offered correlations for the available data bank. Comparison of AARE (%) and ARE (%) for each individual correlation manifests; despite of other two correlations, Kuo (1985) correlation underestimates MMP.
Although the results of predicted MMP by Maklavani et al. (2010) correlation are more reliable among other two correlations, by no means it is sufficiently precise. The depicted results in Table 2 are a justification that the offered model is more reliable for its smallest average absolute percent relative error [AARE (%)], average percent relative error [ARE(%)], root mean square error (RMSE) and standard deviation (SD).
It should be mentioned that the proposed model predicted the developing and examining set data with the error of 9.74% and 10.32%, respectively. The root mean square error and standard deviation of the total data are 3.47 and 0.13, respectively.
In order to examine the correctness of different correlations, the experimentally measured MMP data and the estimated values by the offered formula and three existing correlations for MMP approximation are shown in cross-plot. As shown in Fig. 3, most of the predicted values for their corresponding experimental values are in the proximity of 45° line that validates the reliability of the proposed model. On the contrary, there is more scattering for other three rival correlations.

Cross-plot for the proposed MMP correlation and the previously published ones
Afterward, comparing the precision and reliability of the offered model and other three models for hydrocarbon MMP estimation [Firoozabadi and Khalid (Fathinasab and Ayatollahi 2016); Kuo 1985 and the Maklavani et al. (Fathinasab and Ayatollahi 2016) models] has been implemented. Figure 4 shows the cumulative frequency for these models. It is vivid that the predicted MMP of developing set has ARE of less than 15%, while the other two well-known correlations predict just 50% of the data points with the ARE of 15%. It is seen that only the 10% of the predicted MMPs by the new correlation have the ARE higher than 20%. It is worth to mention that the Firoozabadi and Khalid (Fathinasab and Ayatollahi 2016) and the Maklavani et al. (2010) models have the relative error of the 25% and 21%, respectively.

Cumulative frequency of the offered model and two previously published ones as a function of absolute percent relative error (%)
In order to investigate the magnitude and direction of the influence of each primary variable on the MMP, relevancy factor (r(Inpk, MMP)) as a sensitivity analysis was calculated. To expound, the absolute value of r between any input and its corresponding output and its sign represents the magnitude of the impression of that independent input parameter on the predicted output value and the direction of the effect of input parameters on the MMP, respectively. In fact, negative r values of an input parameter demonstrate the reduction in MMP with increase in that input variable and vice versa. The following equation represents the r value formula:
where Inpk,i and Inpave,k are indications for the ith proposed value by the model and the average value of the kth independent input variable, correspondingly (k = T, MWC5+, RInterm/Vol, TCM), and MMPi and MMPave are representatives for the ith approximated measure of MMP and the average value of the predicted MMP, respectively. The comparative effect of these independent variables is shown in Fig. 5.

Relevancy factor for input parameters with MMP
This figure demonstrates that the increase in the ratio of the crude intermediate to volatile fractions reduces the required pressure for achieving miscibility. On the other hand, increase in MWC5+ increases the MMP and that is due to the fact that increase in MWC5+ means increase in heavy fractions of crude oil that leads to reduction in mass transfer and hence boost in MMP. Furthermore, it is evident that the pseudocritical temperature of the injected gas has a reverse relation with the MMP and that is due to the fact that increase in TCM is an indication of enrichment of the injecting gas by the intermediate components that assists in more mass transfer between the reservoir oil and injection gas and, therefore, decrease in MMP. It is also obvious that the injection gas components (that is represented by TCM) are the governing parameter in miscibility achievement. Finally, the reservoir temperature has a direct relation with the MMP. It can be interpreted by the way that the more the reservoir temperature, the less the gas components condensation or mass transfer, and therefore the higher the MMP. It should be mentioned that comparison between the proposed model and the preexisting ones has been done only on the data with the values of independent variable in the claimed span by these models.
Conclusion
In this article, a comprehensive dataset gathered from the literature and by combination of the GP and LINGO, a new correlation for estimation of the hydrocarbon gas–crude oil MMP was proposed. In this model, MMP is an explicit function of the reservoir temperature, MWC5+, pseudocritical temperature of the injection gas and the ratio of intermediate components to volatile ones. The offered model was accredited by experimentally measured data and the well-known correlations. The followings can be concluded from the results:
-
Hydrocarbon gas–crude oil MMP is strongly affected by injection gas compositions, and the TCM of the injection gas has the strongest effect on MMP.
-
The proposed correlation outperforms the well-known models and has a reasonable precision in MMP estimation with the relative error of the 9.86%.
-
The comprehensive data bank guarantees the reliability of the proposed model compared to preexisting models in a wide range of independent parameters such as reservoir temperature.
References
Ahmadi K, Johns RT (2011) Multiple-mixing-cell method for MMP calculations. SPE J 16:733–742
Al-Ajmi MF, Alomair OA, Elsharkawy AM (2009) Planning miscibility tests and gas injection projects for four major Kuwaiti reservoirs. In: Kuwait international petroleum conference and exhibition, 2009. Society of Petroleum Engineers
Arabloo M, Amooie M-A, Hemmati-Sarapardeh A, Ghazanfari M-H, Mohammadi AH (2014) Application of constrained multi-variable search methods for prediction of PVT properties of crude oil systems. Fluid Phase Equilib 363:121–130
Bagheri M, Gandomi AH, Bagheri M, Shahbaznezhad M (2013) Multi-expression programming based model for prediction of formation enthalpies of nitro-energetic materials. Expert Syst 30:66–78
Carvalho M, Lozano MA, Serra LM, Wohlgemuth V (2012) Modeling simple trigeneration systems for the distribution of environmental loads. Environ Model Softw 30:71–80
David CY, Fagan JE, Foote B, Aly AA (1986) An optimal load flow study by the generalized reduced gradient approach. Electr Power Syst Res 10:47–53
Eakin B, Mitch F (1988) Measurement and correlation of miscibility pressures of reservoir oils. In: SPE annual technical conference and exhibition, 1988. Society of Petroleum Engineers
Elsharkawy A, Poettmann F, Christiansen R (1992) Measuring minimum miscibility pressure: slim-tube or rising-bubble method? In: SPE/DOE enhanced oil recovery symposium, 1992. Society of Petroleum Engineers
Fathinasab M, Ayatollahi S (2016) On the determination of CO2—crude oil minimum miscibility pressure using genetic programming combined with constrained multivariable search methods. Fuel 173:180–188
Fathinasab M, Ayatollahi S, Hemmati-Sarapardeh A (2015) A rigorous approach to predict nitrogen-crude oil minimum miscibility pressure of pure and nitrogen mixtures. Fluid Phase Equilib 399:30–39
Fathinasab M, Ayatollahi S, Taghikhani V, Shokouh SP (2018) Minimum miscibility pressure and interfacial tension measurements for N2 and CO2 gases in contact with W/O emulsions for different temperatures and pressures. Fuel 225:623–631
Firoozabadi A, Khalid A (1986) Analysis and correlation of nitrogen and lean-gas miscibility pressure (includes associated paper 16463). SPE Reserv Eng 1:575–582
Gharagheizi F, Ilani-Kashkouli P, Farahani N, Mohammadi AH (2012) Gene expression programming strategy for estimation of flash point temperature of non-electrolyte organic compounds. Fluid Phase Equilib 329:71–77
Griffith RE, Stewart R (1961) A nonlinear programming technique for the optimization of continuous processing systems. Manage Sci 7:379–392
Hagedorn K, Orr F Jr (1994) Component partitioning in CO2/crude oil systems: effects of oil composition on CO2 displacement performance. SPE Adv Technol Ser 2:177–184
Hemmati-Sarapardeh A, Khishvand M, Naseri A, Mohammadi AH (2013) Toward reservoir oil viscosity correlation. Chem Eng Sci 90:53–68
Jacobson H (1972) Acid gases and their contribution to miscibility. J Can Petrol Technol 11:56–59
Jaubert J-N, Avaullee L, Souvay J-F (2002) A crude oil data bank containing more than 5000 PVT and gas injection data. J Petrol Sci Eng 34:65–107
Kamari A, Arabloo M, Shokrollahi A, Gharagheizi F, Mohammadi AH (2015) Rapid method to estimate the minimum miscibility pressure (MMP) in live reservoir oil systems during CO2 flooding. Fuel 153:310–319
Kuo S (1985) Prediction of miscibility for the enriched-gas drive process. In: SPE annual technical conference and exhibition, 1985. Society of Petroleum Engineers
Maklavani AM, Vatani A, Moradi B, Tangsirifard J (2010) New minimum miscibility pressure (MMP) correlation for hydrocarbon miscible injections. Braz J Petrol Gas 4:011–018
Mihcakan M (1994) Minimum miscibility pressure, rising bubble apparatus, and phase behavior. In: SPE/DOE improved oil recovery symposium, 1994. Society of Petroleum Engineers
Naseri A, Yousefi S, Sanaei A, Gharesheikhlou A (2012) A neural network model and an updated correlation for estimation of dead crude oil viscosity. Braz J Petrol Gas. https://doi.org/10.5419/bjpg2012-0003
Shafiei A, Dusseault MB, Zendehboudi S, Chatzis I (2013) A new screening tool for evaluation of steam flooding performance in naturally fractured carbonate reservoirs. Fuel 108:502–514
Sharma R, Glemmestad B (2013) On generalized reduced gradient method with multi-start and self-optimizing control structure for gas lift allocation optimization. J Process Control 23:1129–1140
Shateri M, Ghorbani S, Hemmati-Sarapardeh A, Mohammadi AH (2015) Application of Wilcoxon generalized radial basis function network for prediction of natural gas compressibility factor. J Taiwan Inst Chem Eng 50:131–141
Taber JJ, Martin F, Seright R (1997) EOR screening criteria revisited-part 1: introduction to screening criteria and enhanced recovery field projects. SPE Reserv Eng 12:189–198
Talebi R, Ghiasi MM, Talebi H, Mohammadyian M, Zendehboudi S, Arabloo M, Bahadori A (2014) Application of soft computing approaches for modeling saturation pressure of reservoir oils. J Nat Gas Sci Eng 20:8–15
Zendehboudi S, Ahmadi MA, Bahadori A, Shafiei A, Babadagli T (2013) A developed smart technique to predict minimum miscible pressure—eor implications. Can J Chem Eng 91:1325–1337
Zendehboudi S, Shafiei A, Bahadori A, James LA, Elkamel A, Lohi A (2014) Asphaltene precipitation and deposition in oil reservoirs—technical aspects, experimental and hybrid neural network predictive tools. Chem Eng Res Des 92:857–875
Zuo Y-x, Chu J-z, Ke S-l, Guo T-m (1993) A study on the minimum miscibility pressure for miscible flooding systems. J Petrol Sci Eng 8:315–328
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Fathinasab, M., Shahbazi, K. A new correlation for estimation of minimum miscibility pressure (MMP) during hydrocarbon gas injection. J Petrol Explor Prod Technol 10, 2349–2356 (2020). https://doi.org/10.1007/s13202-020-00911-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13202-020-00911-7