A Bayesian Approach to Heavy-Tailed Finite Mixture Autoregressive Models
by
 , , ,
, , ,
Mohammad Reza Mahmoudi
1,2 ,
,
Mohsen Maleki
3 ,
,
Dumitru Baleanu
4,5,
Vu-Thanh Nguyen
6 and
Kim-Hung Pho
7,* 1
Institute of Research and Development, Duy Tan University, Da Nang 550000, Vietnam
2
Department of Statistics, Faculty of Science, Fasa University, Fasa 74616-86131, Iran
3
Department of Statistics, University of Isfahan, Isfahan 8174673441, Iran
4
Department of Mathematics, Faculty of Art and Sciences, Cankaya University, Balgat, 06530 Ankara, Turkey
5
Institute of Space Sciences, 077125 Magurele-Bucharest, Romania
6
University of Economics and Law, Ho Chi Minh City 700000, Vietnam
7
Fractional Calculus, Optimization and Algebra Research Group, Faculty of Mathematics and Statistics, Ton Duc Thang University, Ho Chi Minh City 758307, Vietnam
*
Author to whom correspondence should be addressed.
Symmetry 2020, 12(6), 929; https://doi.org/10.3390/sym12060929
Submission received: 10 March 2020
/
Revised: 9 May 2020
/
Accepted: 18 May 2020
/
Published: 2 June 2020
(This article belongs to the Special Issue Composite Structures with Symmetry)
Abstract
:In this paper, a Bayesian analysis of finite mixture autoregressive (MAR) models based on the assumption of scale mixtures of skew-normal (SMSN) innovations (called SMSN–MAR) is considered. This model is not simultaneously sensitive to outliers, as the celebrated SMSN distributions, because the proposed MAR model covers the lightly/heavily-tailed symmetric and asymmetric innovations. This model allows us to have robust inferences on some non-linear time series with skewness and heavy tails. Classical inferences about the mixture models have some problematic issues that can be solved using Bayesian approaches. The stochastic representation of the SMSN family allows us to develop a Bayesian analysis considering the informative prior distributions in the proposed model. Some simulations and real data are also presented to illustrate the usefulness of the proposed models.
1. Introduction
Data analysts apply computational models to describe and infer statements about complex datasets. Mixture models are a valuable class of these models. Finite mixture models are of great importance in statistical inferences. The multimodality, skewness, kurtosis, and unobserved heterogeneity are usually observed in many datasets, for example time series datasets. Importance of mixture distributions, which are the main tools for statistical mixture models, has been noted by many references [1,2,3,4,5,6,7,8]. Various statistical fields containing time series modeling and regression analysis frequently use the mixture modeling. In fact, in analyzing time series data, some events may affect and change the behavior of data over time, for example, finance crises in many financial or panel time series datasets. The finite mixture autoregressive (MAR) models were suggested by Wong and Li [7], to catch the multimodal phenomena, are flexible and applicable in many fields, such as electroencephalogram modeling in medicine [8], interest rates and bond pricing [9], Forex rate [10], and other various fields such as telecommunications, hydrology, biology, sociology, and medical sciences.
Most researchers considered the MAR models based on Gaussian distribution, which are called Gaussian mixture of autoregressive (GMAR) models [7,8,9,10,11]. The GMAR models are sensitive to the existence of outliers, heavy tailed distribution and asymmetry in datasets, and thus some authors considered MAR models based on non-Gaussian, heavy tailed and/or asymmetric distributions. Wong and Li [12] introduced logistic mixture autoregressive model. Wong and Chan [13] also introduced a student t–mixture autoregressive model and discussed its inferences and then applied this model to the heavy tailed financial data.
The SMSN family, introduced by Branco [1], is a rich family containing famous symmetric scale mixtures of normal (SMN; [14]) distributions and asymmetric distributions such as the skew-t, skew-slash and skew-contaminated-normal distribution. The MAR model based on the SMSN innovations, hereafter called SMSN–MAR models, has reasonable performance to model real time series data with outliers and skewness. The various MAR model members can determine weights to each observation, and therefore each single observation affects the estimation of the model’s parameters, and it leads to robust inferences. Bayesian inferences of the MAR models have some advantages compared to classical methods, that some of them are discussed below.
For maximum likelihood computations and classical inference of a MAR model, although the numerical optimization algorithms such as the EM–algorithm can be applied, converging to the major mode may fail, while this is not an issue in Bayesian inferences. Furthermore, in the MAR models there exist many situations with indirect information about the parameters or large changes in the results by small changes in the data. When we consider a sample from a MAR model, the sample includes no information about the parameters of one or more components with a positive probability. Therefore, the likelihood function can be unbounded and consequently the resultant likelihood estimates are only local maximum. Using suitable priors and some Bayesian techniques can solve such problems. Another problematic issue on the classical likelihood–based inference is that, in MAR model, the component parameters are not identifiable marginally, so distinguishing any component from other components in the likelihood is hard. The identifiability is not an important problem in Bayesian inferences. Some of the other advantages of the Bayesian inferences of the mixture models are given in [15,16].
In this paper, we consider a Bayesian technique to find estimates of the SMSN–MAR models by the Gibb sampling scheme and application of the Markov Chain Monte Carlo (MCMC) methods. The main characteristics of the SMSN distributions are reviewed in Section 2. In Section 3, we consider the MAR models and apply the Bayesian methodology for estimating the proposed MAR model’s parameters. To evaluate the Bayesian estimates of parameters and performance of the proposed model, numerical studies and a real practical example are reported in Section 4. The conclusion is provided in the last section.
2. The SMSN Distributions
A random variable is belonged to the scale mixtures of skew normal (SMSN) family, if it has the following representation:
where the random variable follows a skew-normal distribution in [17], where and are respectively scale and skewness parameters, the function is positive respect to , is the scale random variable with density function or pmf and distribution function , and the vector or scalar indexes the distribution of . The random variable is denoted by , and in this work, because of its suitable mathematical properties, we let , so . Therefore, the density ofis given by
where, and and are density and distribution functions of the standard normal distribution, respectively.
Proposition 1.
Let ,
- (a)
- If , then ,
- (b)
- If , then ,
- (c)
- has a stochastic representation given bywhere, , , , , and and are independent standard normal random variables.
3. The SMSN–MAR Model and Bayesian Estimates
3.1. The SMSN–MAR Model
In this paper, we study the MAR model, which has been studied by Wong and Li [7], and Wong and Chan [20], due to its flexibility in use for non-linear time series analysis. This model is represented by
or equivalently,
where
- g is a known positive integer which indicates the number of components in the model;
- each component occurs with probabilities which obeys a discrete distribution ;
- for each ,
- ➢
- the ith autoregressive component is of order ;
- ➢
- , are the autoregressive coefficients of the ith components;
- ➢
- each ith innovation’s component distributed as following:where , , and . Also in each ith component, are jointly independent and are independent of past s and also independent of other component’s innovations.
Hereafter, this model will be called SMSN–MAR(p,g). Note that in each component, when exists, and. Note that we can assume that the vector of coefficients in MAR models, distributed as, therefore, this model can be also interpreted as random coefficients autoregressive (RCA) model.
Without loss of generality, it is convenient to set and for. Also, let be an i.i.d. sequence of random variables which are distributed as (Multinomial), such that, that determines the components, and be independent of innovations and random history of model. Therefore, obeys from ith component of MAR model, if. Thus, Equation (3) can be written as
where.
It is convenient to set vector and matrix notations of sample in the form of ,, and be the matrix whose tth row is , in the rest of the paper. Thus, the following matrix representation
Note that in Equation (7), where and distributed as, so by Equation (5) we have
Therefore, the density of is given by
where
is the pdf of defined in Equation (2), hereafter note that , where be the vector of parameters.
By using Markovian property of this model, we have that , where be the density of. An auxiliary determiner of components in MAR models (6), can be expressed in the random vector , where
Therefore, under the above approach, the latent random vector has the following multinomial with the following probability mass function:
such that ,
. Therefore,
Also, to provide a MCMC method, we have:
for . Let as the complete data, where is the observed part of data, is the missing parts of data, and is the vector of unknown parameters. The conditional likelihood function based on the complete data is provided by
3.2. Bayesian Approach
In this part, we use the Bayesian approach by applying MCMC algorithms for the model in Equation (3). We consider informative priors under squared error loss function (SEL). To consider the prior distributions for the parameters of the considered model, we assign prior distributions to the parameters as follow:
for where and IG denote the Dirichlet distribution and the Inverse-Gamma distribution, respectively.
The prior distribution assigned to , varies with the particular SMSN distributions. For skew–t model, we can consider exponential distribution with mean before truncation, for skew–slash model, we can consider with small positive values and such that , and for skew–contaminated–normal model, the independent and non-informative prior distributions are considered for each component of . We also assume that priors are independent and all hyper-parameters (parameters of priors) are known, which guarantees that all posteriors are proper. The joint posterior of and missing variables is in the form of , which is not analytically tractable, but the MCMC methods such as the Gibbs sampling, will be applied to draw samples from the marginal of conditional posteriors which are shown as follows, when , means the mth
element of has been removed (Algorithm 1).
| Algorithm 1: MCMC |
For, and,
|
Finally, in order to complete the specifications of the sampling via MCMC methods, the posterior distribution of the latent variable , , and its indexed parameter, , should be determined. Set , we then have, for and the several models given as:
- ∎
- ST–MAR:and
- ∎
- SSL–MAR:
- ∎
- SCN–MAR:where , , and
Note that Equations for
and do not have closed forms, but a Metropolis–Hasting algorithm which has used in [21] can be employed to obtain draws of them.
In the Bayesian technique, some model selection criteria such as the expected Bayesian information criterion (EBIC) and the expected Akaike information criterion (EAIC) [22,23] can be considered. Let as a sample from . The posterior mean of the deviance is estimated by, such that and is the density given in Equation (8). These criteria can be respectively estimated by and , where is the number of parameters, is the sample size and where.
4. Numerical Studies
In this section, numerical studies and a real data example are given to study the ability of the considered SMSN–MAR(p,g) model. The statistical R software version 3.6.1 is used. A sample size of , and the following prior distributions are selected: , and , with for the skew-t model, for the skew-slash model, and and independent of for the skew-contaminated normal model. Also, a Gibbs sampling with iterations equal to 60,000 and a burn-in of 10,000 cycles is applied.
In the simulation parts, we considered two schemes. In the first scheme, simulations are based on the SMSN–MAR models to show the performances of the considered model and Bayesian estimates, and in the second scheme, simulations are mixture autoregressive model based on Generalized–Hyperbolic distribution (GH–MAR model). The GH distribution is well known because of it’s asymmetry and heavy-tailed nature [24,25]. The second scheme will show the performance of the proposed Bayesian estimates of the heavy-tailed SMSN–MAR models to the time series with heavy-tailed and asymmetric innovations. Finally, the SMSN–MAR model is applied on the closing price of the Iran Telecommunication Company stock via the proposed Bayesian methodology.
4.1. First Scheme
The first simulation study is devoted to the following SMSN–MAR(2,2) model with 1000 samples simulations from the SN, ST and SSL distributions for the innovations with parameters ,, , , and , and for ST and SSL, and for the SCN. Means and standard deviations of the proposed Bayesian estimates are shown in Table 1.
4.2. Second Scheme
The second simulation study is devoted to the following GH–MAR(2,2) model with 200 samples as follows:
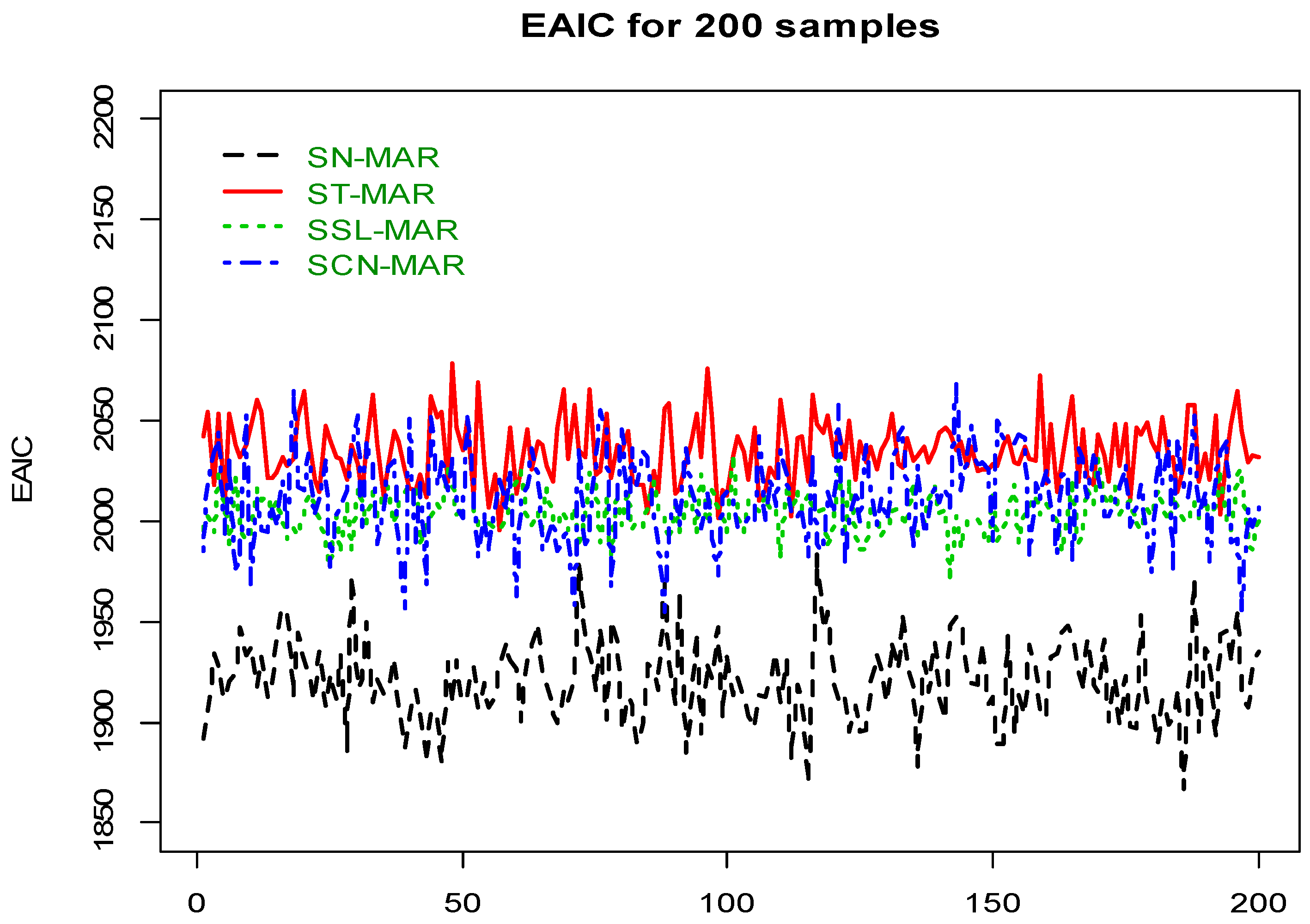
with the autoregressive coefficients in the first scheme, for which be an i.i.d. sequence of with weak skewness, and be an i.i.d. sequence of with strong skewness for innovations. The EAIC criteria of all Bayesian fitted SMSN–MAR models given in Figure 1, satisfies that the asymmetry and heavy-tailed members (i.e., ST–MAR, SSL–MAR and SCN–MAR models), especially ST–MAR, are the best fitted models in comparison with the light-tailed SN–MAR member.
4.3. Real Data
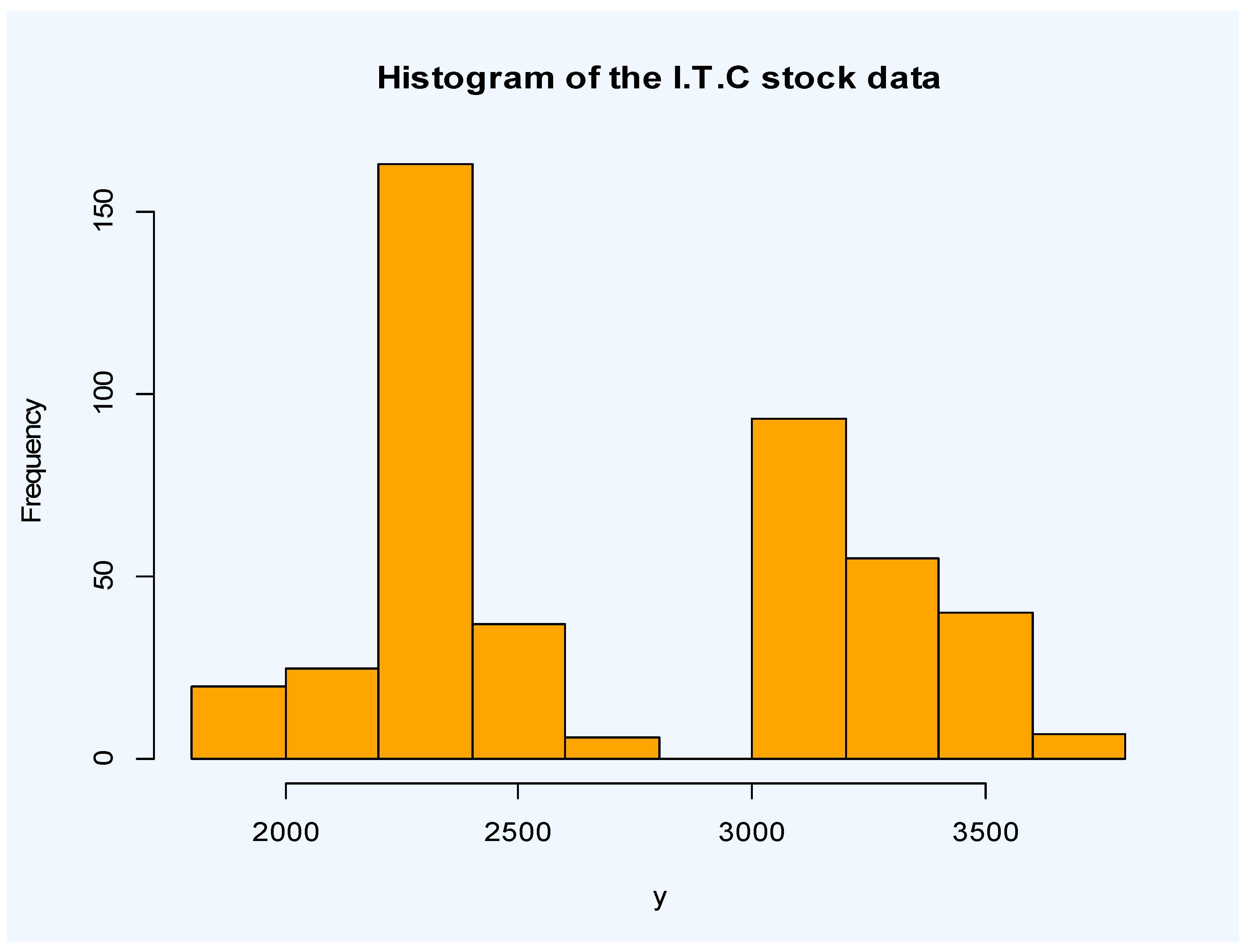
In this section, we consider the 446 daily observations of the closing price of Iran Telecommunication Company (I.T.C.) stock based on the Iranian Rial from 2011-07-02 up to 2013-07-02 (see data at Tehran securities exchange technology management company site: www.tsetmc.com). Original time series plot of the I.T.C. stock data where is the closing price at time are given in Figure 2. It can be observed that the time series is not stationary. A histogram of the data is plotted in Figure 3.
Using the Box-Cox transformation with , and the difference with order of one, we have
where
The time series has been plotted in in Figure 4. The Dickey–Fuller test verifies that the transformed time series data are stationary (p-value = 0.01).
The EAIC and EBIC criteria demonstrate that the best SMSN–MAR model has two components with order p1 = 3 for the first AR component and p2 = 1 for the second AR component. Using the proposed Bayesian approach, we fitted the N–MAR (GMAR), SN–MAR, ST–MAR, SSL–MAR and SCN–MAR models with g = 1,2,3 components. The Bayesian model selection criteria for them are given in Table 2. The Bayesian estimates (posterior mean) of the ST–MAR (3,2) (the best fitted) model parameters for the return series of the I.T.C. stock data are given in Table 3.
5. Conclusions
In this paper, we have considered the robust MAR models based on the scale mixtures of skew normal distributions, called SMSN–MAR, and a Bayesian approach to estimate the models’ parameters. These models are used for modeling non-linear time series data, which involve GMAR models, and offer greater flexibility than normal distribution. Numerical studies verified the good performance of the considered models and suitability of Bayesian estimates. A real data example demonstrated that SMSN–MAR models can be useful tools for non-linear and non-stationary time series modeling. In future studies, the researchers can consider cyclostationary or almost cyclostationary processes [26,27,28,29,30,31,32,33] with SMSN errors or mixture models based on these processes.
Author Contributions
M.R.M.: Conceptualization, Methodology, Software, Supervision; M.M.: Data curation, Validation, Writing—Original draft preparation; D.B.: Visualization, Writing—Reviewing and Editing; V.-T.N.: Visualization, Writing—Reviewing and Editing; K.-H.P.: Visualization, Investigation, Writing—Reviewing and Editing. All authors have read and agreed to the published version of the manuscript
Funding
This research received no external funding.
Acknowledgments
We would like to thank the anonymous referees for their careful reading of this manuscript and also for their constructive suggestions which considerably improved the article.
Conflicts of Interest
The authors declare that they have no conflict of interest.
References
- Branco, M.D.; Dey, D.K. A general class of multivariate skew-elliptical distributions. J. Multivar. Anal. 2001, 79, 99–113. [Google Scholar] [CrossRef] [Green Version]
- Lindsay, B.G. Mixture models: Theory geometry and applications. In NSF-CBMS Regional Conference Series in Probability and Statistics; Institute of Mathematical Statistics: Hayward, CA, USA, 1995; Volume 51. [Google Scholar]
- Böhning, D. Computer-assisted analysis of mixtures and applications. In Meta-Analysis, Disease Mapping and Others; Chapman&Hall/CRC: Boca Raton, FL, USA, 2000. [Google Scholar]
- McLachlan, G.J.; Peel, D. Finite Mixture Models; Wiley: New York, NY, USA, 2000. [Google Scholar]
- Frühwirth-Schnatter, S. Finite Mixture and Markov Switching Models; Springer: New York, NY, USA, 2006. [Google Scholar]
- Mengersen, K.; Robert, C.P.; Titterington, D.M. Mixtures: Estimation and Applications; John Wiley and Sons: New York, NY, USA, 2011. [Google Scholar]
- Wong, C.S.; Li, W.K. On a mixture autoregressive model. J. R. Stat. Soc. Ser. B 2000, 62, 95–115. [Google Scholar] [CrossRef]
- Maleki, M.; Nematollahi, A.R. Autoregressive Models with Mixture of Scale Mixtures of Gaussian Innovations. Iran. J. Sci. Technol. Trans. Sci. 2017, 41, 1099–1107. [Google Scholar] [CrossRef]
- Ni, H.; Yin, H. A self-organizing mixture autoregressive network for time series modeling and prediction. Neurocomputing 2008, 72, 3529–3537. [Google Scholar] [CrossRef]
- McCulloch, R.E.; Tsay, R.S. Statistical inference of macroeconomic time series via markov switching models. J. Time Ser. Anal. 1994, 15, 523–539. [Google Scholar] [CrossRef]
- Glasbey, C.A. Non-linear autoregressive time series with multivariate Gaussian mixtures as marginal distributions. J. R. Stat. Soc. Ser. C 2001, 50, 143–154. [Google Scholar] [CrossRef]
- Wong, C.S.; Li, W.K. On a logistic mixture autoregressive model. Biometrika 2001, 88, 833–846. [Google Scholar] [CrossRef]
- Wong, C.S.; Chan, W.S. A student t-mixture autoregressive model with applications to heavy tailed financial data. Biometrika 2009, 96, 751–760. [Google Scholar] [CrossRef] [Green Version]
- Andrews, D.F.; Mallows, C.L. Scale mixtures of normal distributions. J. R. Stat. Soc. Ser. B 1974, 36, 99–102. [Google Scholar] [CrossRef]
- Maleki, M.; Wraith, D.; Arellano-Valle, R.B. Robust finite mixture modeling of multivariate unrestricted skew-normal generalized hyperbolic distributions. Stat. Comput. 2019, 29, 415–428. [Google Scholar] [CrossRef]
- Maleki, M.; Wraith, D. Mixtures of multivariate restricted skew-normal factor analyzer models in a Bayesian framework. Comput. Stat. 2019, 34, 1039–1053. [Google Scholar] [CrossRef]
- Zarrin, P.; Maleki, M.; Khodadadi, Z.; Arellano-Valle, R.B. Time series models based on the unrestricted skew-normal process. J. Stat. Comput. Sim. 2019, 89, 38–51. [Google Scholar] [CrossRef]
- Zeller, C.B.; Cabral CR, B.; Lachos, V.H. Robust mixture regression modeling based on scale mixtures of skew-normal distributions. Comput. Stat. Data Anal. 2010, 54, 2926–2941. [Google Scholar] [CrossRef]
- Maleki, M.; Wraith, D.; Arellano-Valle, R.B. A flexible class of parametric distributions for Bayesian linear mixed models. TEST 2019, 28, 543–564. [Google Scholar] [CrossRef]
- Wong, C.S.; Chan, W.S. Statistical Inference for Non-Linear Time Series Models. Ph.D. Thesis, University of Hong Kong, Hong Kong, China, 1998. [Google Scholar]
- Moravveji, B.; Khodadadi, Z.; Maleki, M. A Bayesian Analysis of Two-Piece Distributions Based on the Scale Mixtures of Normal Family. Iran. J. Sci. Technol. Trans. Sci. 2019, 43, 991–1001. [Google Scholar] [CrossRef]
- Brooks, S.P. Discussion on the paper by Spiegelhalter, Best, Carlin, and van der Linde. J. R. Stat. Soc. B 2002, 64, 616–618. [Google Scholar]
- Carlin, B.P.; Louis, T.A. Bayes and Empirical Bayes Methods for Data Analysis, 2nd ed.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2001. [Google Scholar]
- Barndorff-Nielsen, O. Normal inverse Gaussian distributions and stochastic volatility modelling. Scand. J. Stat. 1997, 24, 1–13. [Google Scholar] [CrossRef]
- McNeil, A.J.; Frey, R.; Embrechts, P. Quantitative Risk Management: Concepts, Techniques and Tools; Princeton University Press: Princeton, NJ, USA, 2005. [Google Scholar]
- Mahmoudi, M.R.; Nematollahi, A.R.; Soltani, A.R. On the detection and estimation of the simple harmonizable processes. Iran. J. Sci. Technol. A (Sci.) 2015, 39, 239–242. [Google Scholar]
- Mahmoudi, M.R.; Maleki, M. A new method to detect periodically correlated structure. Comput. Stat. 2017, 32, 1569–1581. [Google Scholar] [CrossRef]
- Nematollahi, A.R.; Soltani, A.R.; Mahmoudi, M.R. Periodically correlated modeling by means of the periodograms asymptotic distributions. Stat. Pap. 2017, 58, 1267–1278. [Google Scholar] [CrossRef]
- Mahmoudi, M.R.; Heydari, M.H.; Avazzadeh, Z.; Pho, K.H. Goodness of fit test for almost cyclostationary processes. Digit. Signal Process. 2020, 96, 102597. [Google Scholar] [CrossRef]
- Mahmoudi, M.R.; Heydari, M.H.; Roohi, R. A new method to compare the spectral densities of two independent periodically correlated time series. Math. Comput. Simulat. 2019, 160, 103–110. [Google Scholar] [CrossRef]
- Mahmoudi, M.R.; Heydari, M.H.; Avazzadeh, Z. Testing the difference between spectral densities of two independent periodically correlated (cyclostationary) time series models. Commun. Stat. Theory Methods 2019, 48, 2320–2328. [Google Scholar] [CrossRef]
- Mahmoudi, M.R.; Maleki, M.; Pak, A. Testing the Difference between Two Independent Time Series Models. Iran. J. Sci. Technol. A (Sci.) 2017, 41, 665–669. [Google Scholar] [CrossRef]
- Mahmoudi, M.R.; Heydari, M.H.; Avazzadeh, Z. On the asymptotic distribution for the periodograms of almost periodically correlated (cyclostationary) processes. Digit. Signal Process. 2018, 81, 186–197. [Google Scholar] [CrossRef]
Figure 1.
EAIC criterion for 200 MAR samples based on the GH distributions.

Figure 2.
Time series plot of the I.T.C. stock from 2011-07-02 up to 2013-07-02.

Figure 3.
Histogram of the I.T.C. stock from 2011-07-02 up to 2013-07-02.

Figure 4.
Plot of returned I.C.T stock data.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Means and standard deviations of the Bayesian estimates of the simulated SMSN–MAR(2,2) models.
Table 1.
Means and standard deviations of the Bayesian estimates of the simulated SMSN–MAR(2,2) models.
| Model | SN–MAR | ST–MAR | SSL–MAR | SCN–MAR | ||||
|---|---|---|---|---|---|---|---|---|
| Parameters (Values) | Mean | SD | Mean | SD | Mean | SD | Mean | SD |
| 0.1003 | 0.02131 | 0.1001 | 0.02743 | 0.1004 | 0.02309 | 0.1010 | 0.02301 | |
| 0.1002 | 0.02242 | 0.1007 | 0.02436 | 0.1005 | 0.02419 | 0.1012 | 0.02502 | |
| 0.5017 | 0.01483 | 0.5011 | 0.01738 | 0.5010 | 0.01333 | 0.5033 | 0.01501 | |
| 0.3011 | 0.01746 | 0.3009 | 0.01846 | 0.3024 | 0.01963 | 0.3032 | 0.01758 | |
| 0.6032 | 0.01592 | 0.6048 | 0.01977 | 0.6024 | 0.01846 | 0.6101 | 0.01610 | |
| 0.2101 | 0.02032 | 0.2097 | 0.02006 | 0.2008 | 0.01926 | 0.2112 | 0.02094 | |
| 1.1023 | 0.02064 | 1.0969 | 0.31741 | 1.1021 | 0.27493 | 1.1026 | 0.02080 | |
| 2.1978 | 0.03027 | 2.2019 | 0.28950 | 2.1992 | 0.31171 | 2.2011 | 0.03311 | |
| 2.0184 | 0.81651 | 2.0025 | 0.94561 | 1.9367 | 0.82846 | 2.0221 | 0.82331 | |
| 4.0038 | 1.09817 | 3.9014 | 0.95928 | 3.9930 | 0.90563 | 4.0112 | 1.09831 | |
| -- | -- | 3.8957 | 0.56842 | 3.9473 | 1.14587 | 0.5211 | 0.01918 | |
| -- | -- | 3.8957 | 0.46877 | 3.9473 | 1.24587 | 0.5192 | 0.02111 | |
| -- | -- | -- | -- | -- | -- | 0.5103 | 0.02013 | |
| -- | -- | -- | -- | -- | -- | 0.5201 | 0.02321 | |
| 0.4011 | 0.04113 | 0.4008 | 0.02795 | 0.3957 | 0.01758 | 0.4011 | 0.04113 | |
Table 2.
Bayesian model selection criteria for the proposed SMSN–MAR(3,2) with various number of components .
Table 2.
Bayesian model selection criteria for the proposed SMSN–MAR(3,2) with various number of components .
| Model | Number of Component (g) | EAIC | EBIC |
|---|---|---|---|
| N-MAR | 1 | 3290.6352 | 3297.8210 |
| 2 | 3067.3456 | 3291.9571 | |
| 3 | 3175.4758 | 3210.9882 | |
| SN-MAR | 1 | 3262.7364 | 3271.7441 |
| 2 | 3038.7464 | 3165.0641 | |
| 3 | 3175.7387 | 3183.7251 | |
| ST-MAR | 1 | 2979.3748 | 2986.2951 |
| 2 | 2816.8374 | 2887.3601 | |
| 3 | 2910.6364 | 2977.6781 | |
| SSL-MAR | 1 | 3176.3647 | 3240.2990 |
| 2 | 2997.0694 | 3099.8811 | |
| 3 | 3146.7564 | 3157.6441 | |
| SCN-MAR | 1 | 3164.7564 | 3191.3452 |
| 2 | 3009.3745 | 3097.3383 | |
| 3 | 3165.7564 | 3182.6013 |
Note: The best values (between all possible models) are indicated in bold.
Table 3.
Bayesian estimates with standard deviations of the parameters of fitted ST–MAR (3,2) model for the return series of the I.T.C. stock data.
Table 3.
Bayesian estimates with standard deviations of the parameters of fitted ST–MAR (3,2) model for the return series of the I.T.C. stock data.
| Component | Parameters | Bayesian Estimates | S.E. |
|---|---|---|---|
| First AR Component | |||
| Second AR Component | |||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Mahmoudi, M.R.; Maleki, M.; Baleanu, D.; Nguyen, V.-T.; Pho, K.-H. A Bayesian Approach to Heavy-Tailed Finite Mixture Autoregressive Models. Symmetry 2020, 12, 929. https://doi.org/10.3390/sym12060929
AMA Style
Mahmoudi MR, Maleki M, Baleanu D, Nguyen V-T, Pho K-H. A Bayesian Approach to Heavy-Tailed Finite Mixture Autoregressive Models. Symmetry. 2020; 12(6):929. https://doi.org/10.3390/sym12060929
Chicago/Turabian StyleMahmoudi, Mohammad Reza, Mohsen Maleki, Dumitru Baleanu, Vu-Thanh Nguyen, and Kim-Hung Pho. 2020. "A Bayesian Approach to Heavy-Tailed Finite Mixture Autoregressive Models" Symmetry 12, no. 6: 929. https://doi.org/10.3390/sym12060929
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.