Digital Trade Feature Map: A New Method for Visualization and Analysis of Spatial Patterns in Bilateral Trade

 , , , ,
, , , ,
Abstract
:1. Introduction
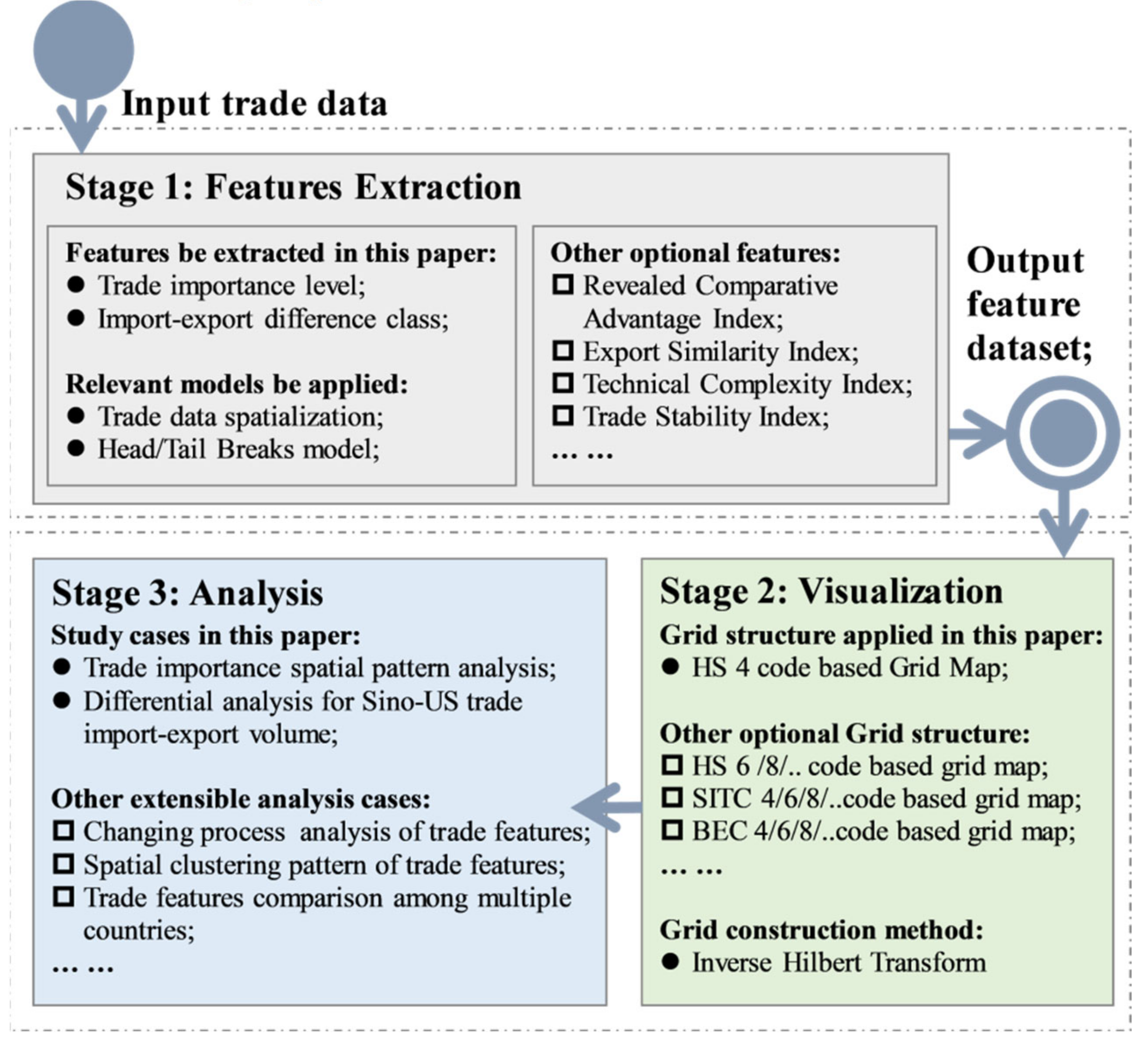
2. Materials and Methods
2.1. Data
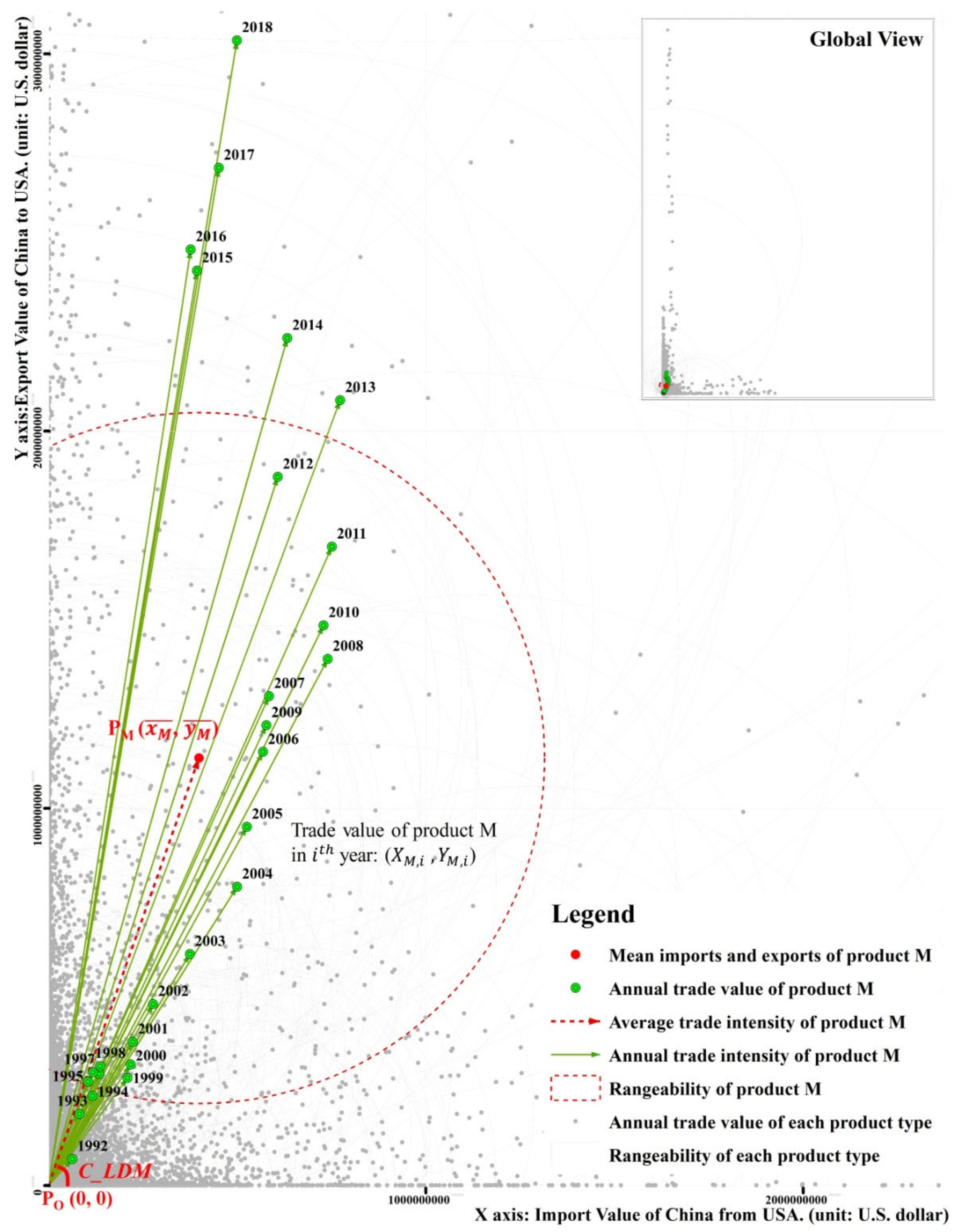
2.2. Trade Data Spatialization Method
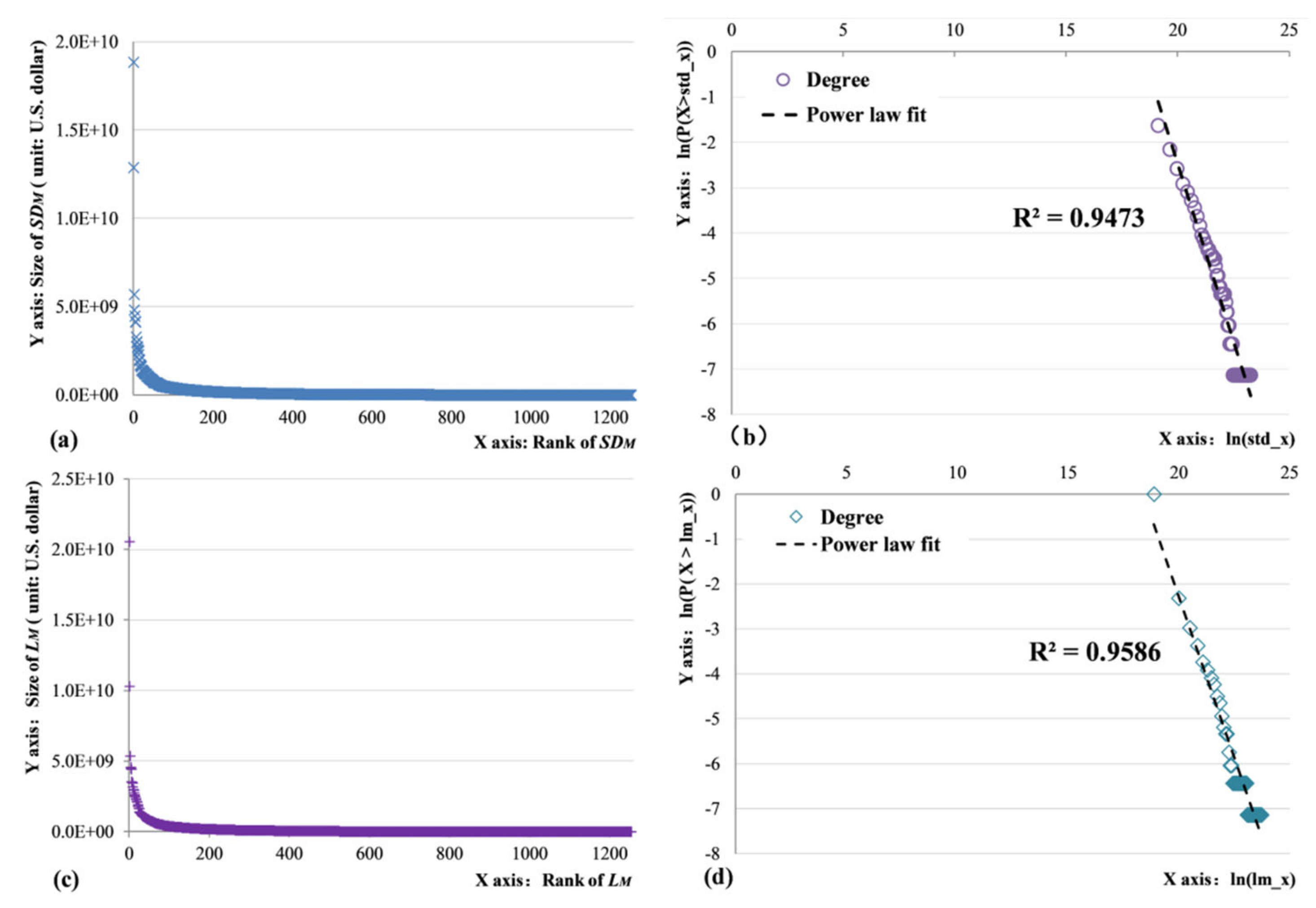
2.3. Head/Tail Breaks Method
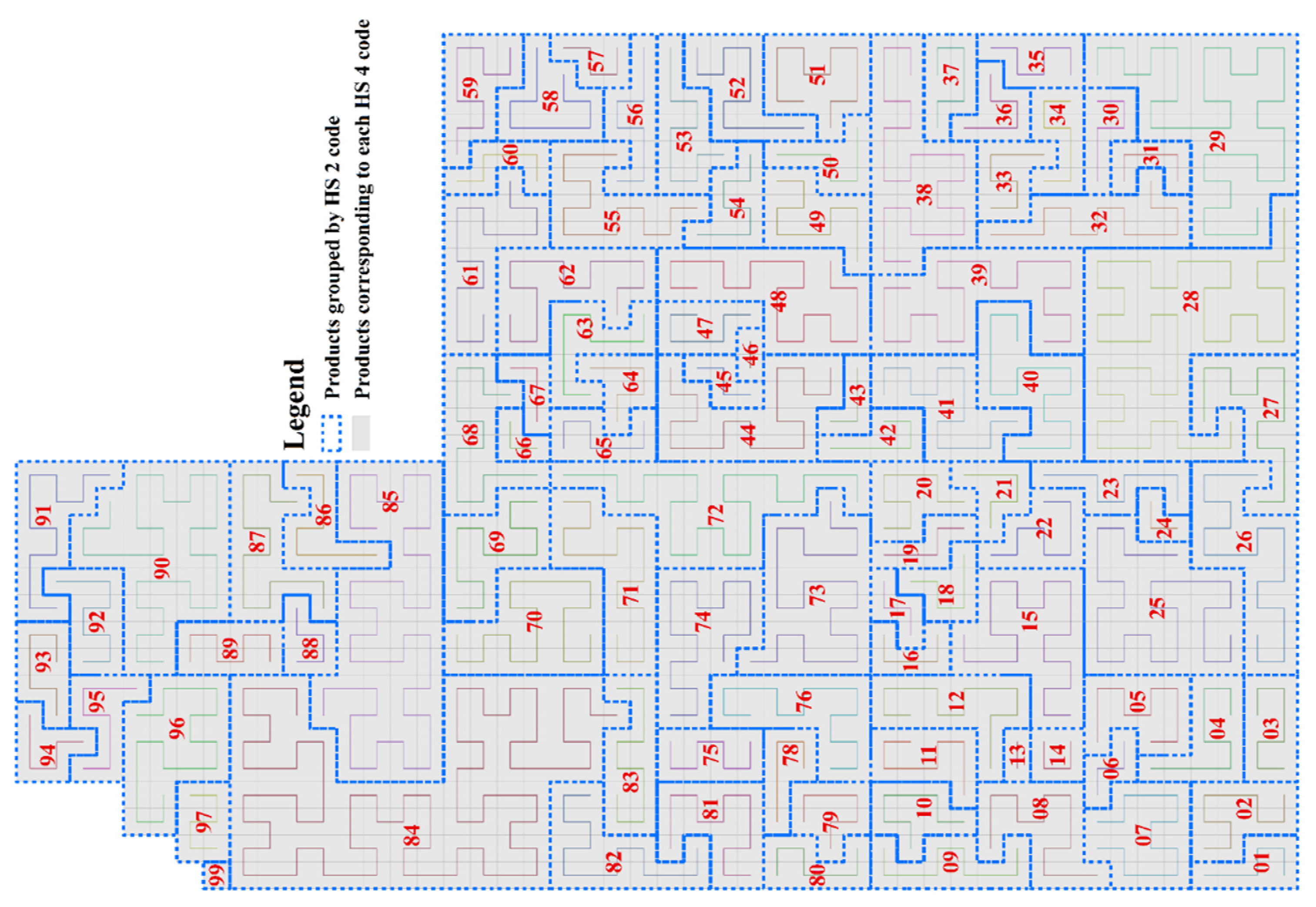
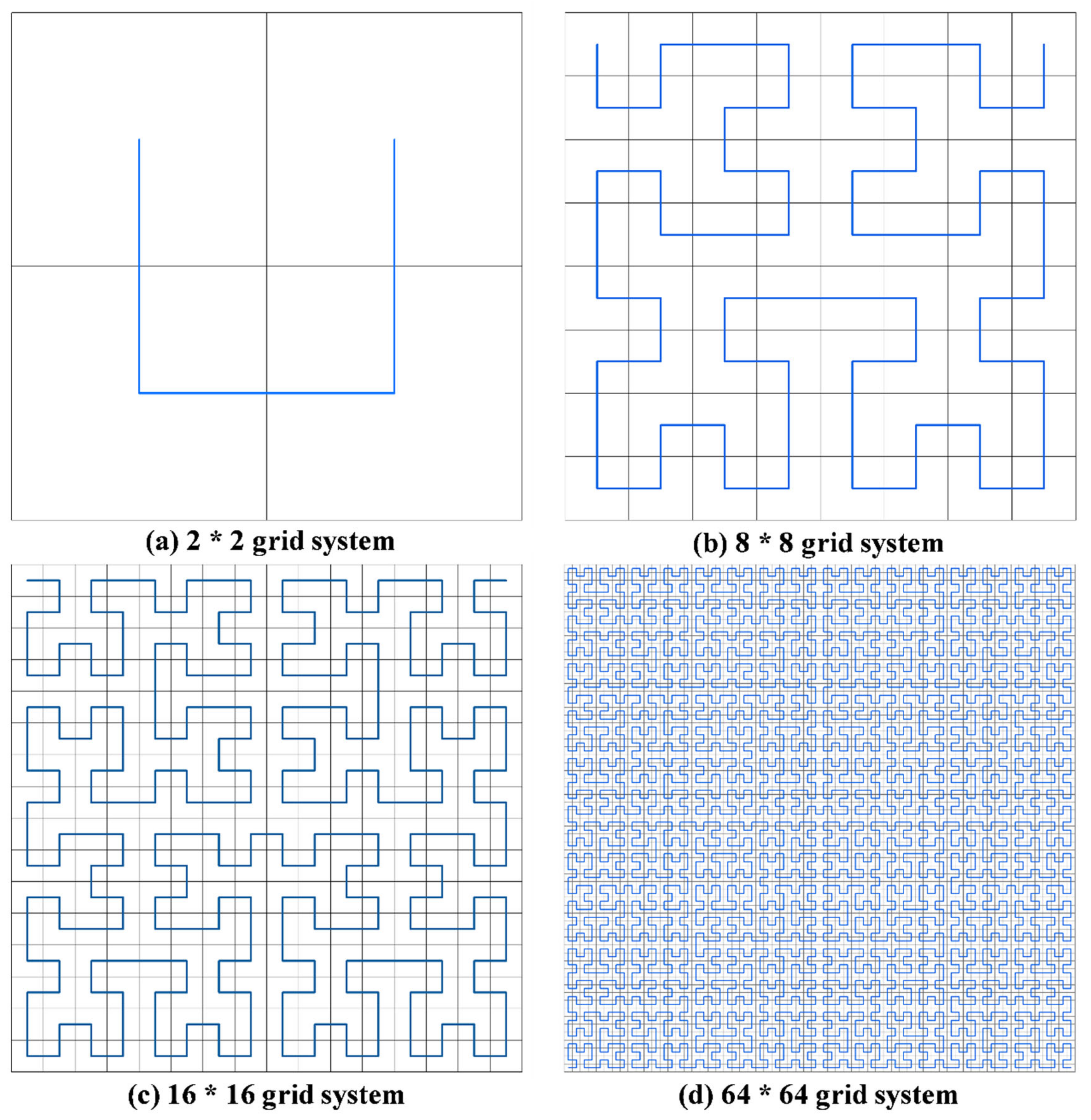
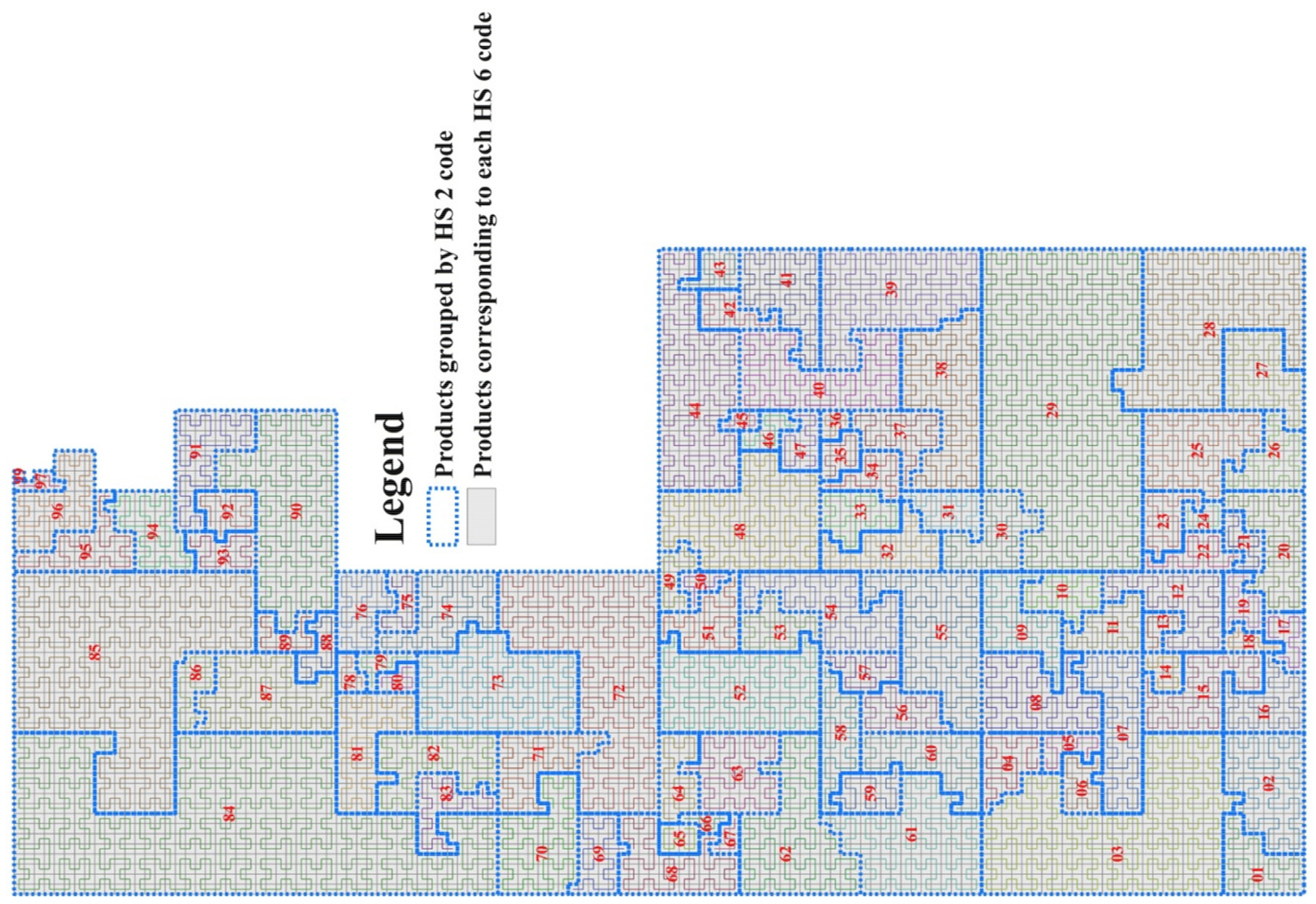
2.4. Hilbert Curve-Based Products Grids Generation Method
3. Case Studies
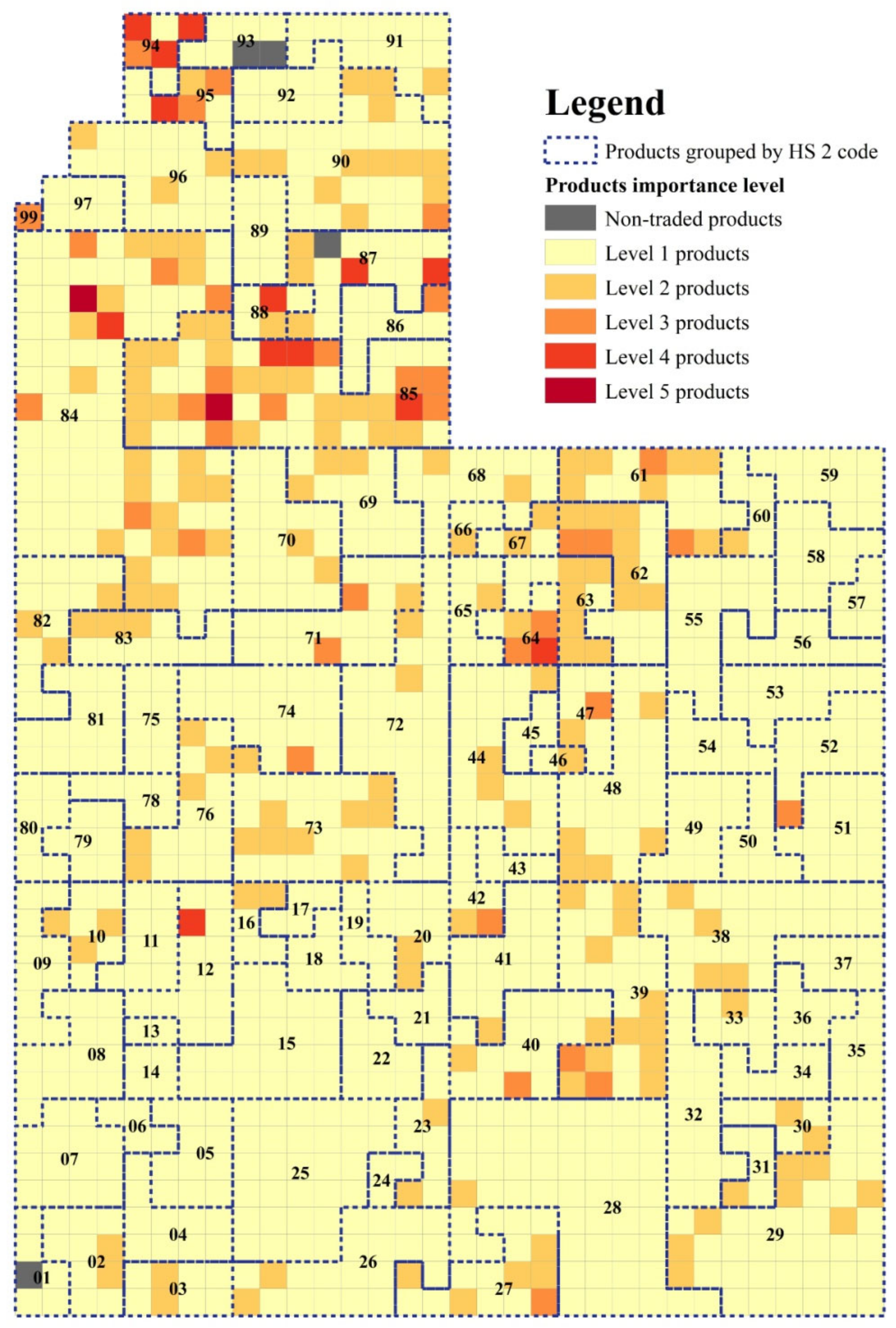
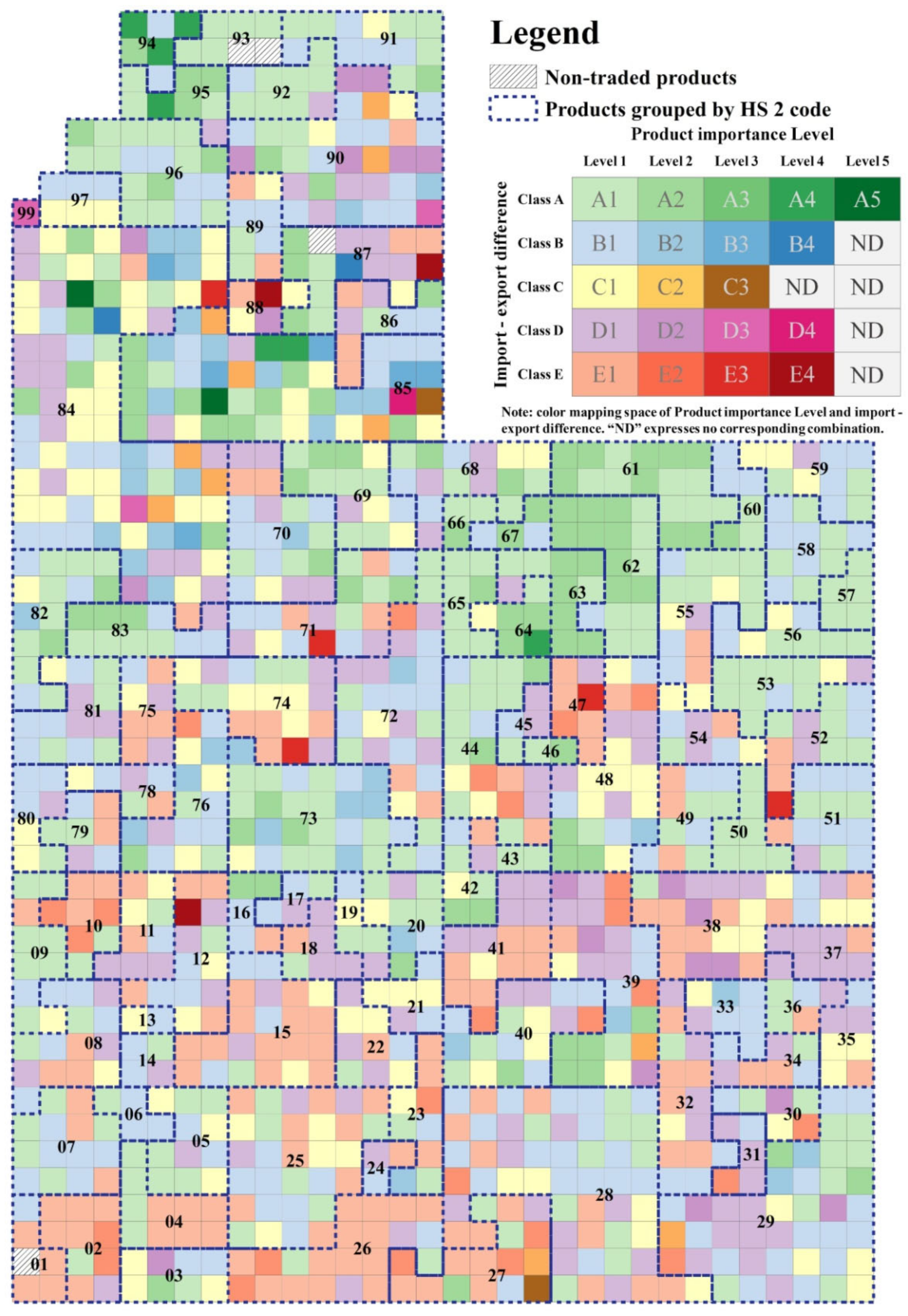
3.1. Case Study 1: Spatial Pattern Analysis of Product Importance Level
3.2. Case Study 2: Spatial Pattern Analysis of Product Import–Export Difference Class
4. Discussion: Extensible DTFM Application Framework and Development Path
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A.—HS 2-Digit Coding Rule

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| HS 2-Digit Code | Product Type | HS 2-Digit Code | Product Type | HS 2-Digit Code | Product Type |
|---|---|---|---|---|---|
| 01 | Animals; live | 34 | Soap, organic surface-active agents; washing, lubricating, polishing or scouring preparations; artificial or prepared waxes, candles and similar articles, modelling pastes, dental waxes and dental preparations with a basis of plaster | 67 | Feathers and down, prepared; and articles made of feather or of down; artificial flowers; articles of human hair |
| 02 | Meat and edible meat offal | 35 | Albuminoidal substances; modified starches; glues; enzymes | 68 | Stone, plaster, cement, asbestos, mica or similar materials; articles thereof |
| 03 | Fish and crustaceans, mollusks and other aquatic invertebrates | 36 | Explosives; pyrotechnic products; matches; pyrophoric alloys; certain combustible preparations | 69 | Ceramic products |
| 04 | Dairy produce; birds’ eggs; natural honey; edible products of animal origin, not elsewhere specified or included | 37 | Photographic or cinematographic goods | 70 | Glass and glassware |
| 05 | Animal originated products; not elsewhere specified or included | 38 | Chemical products n.e.c. | 71 | Natural, cultured pearls; precious, semi-precious stones; precious metals, metals clad with precious metal, and articles thereof; imitation jewelry; coin |
| 06 | Trees and other plants, live; bulbs, roots and the like; cut flowers and ornamental foliage | 39 | Plastics and articles thereof | 72 | Iron and steel |
| 07 | Vegetables and certain roots and tubers; edible | 40 | Rubber and articles thereof | 73 | Iron or steel articles |
| 08 | Fruit and nuts, edible; peel of citrus fruit or melons | 41 | Raw hides and skins (other than furskins) and leather | 74 | Copper and articles thereof |
| 09 | Coffee, tea, mate and spices | 42 | Articles of leather; saddlery and harness; travel goods, handbags and similar containers; articles of animal gut (other than silk-worm gut) | 75 | Nickel and articles thereof |
| 10 | Cereals | 43 | Furskins and artificial fur; manufactures thereof | 76 | Aluminum and articles thereof |
| 11 | Products of the milling industry; malt, starches, inulin, wheat gluten | 44 | Wood and articles of wood; wood charcoal | 78 | Lead and articles thereof |
| 12 | Oil seeds and oleaginous fruits; miscellaneous grains, seeds and fruit, industrial or medicinal plants; straw and fodder | 45 | Cork and articles of cork | 79 | Zinc and articles thereof |
| 13 | Lac; gums, resins and other vegetable saps and extracts | 46 | Manufactures of straw, esparto or other plaiting materials; basketware and wickerwork | 80 | Tin; articles thereof |
| 14 | Vegetable plaiting materials; vegetable products not elsewhere specified or included | 47 | Pulp of wood or other fibrous cellulosic material; recovered (waste and scrap) paper or paperboard | 81 | Metals; n.e.c., cermets and articles thereof |
| 15 | Animal or vegetable fats and oils and their cleavage products; prepared animal fats; animal or vegetable waxes | 48 | Paper and paperboard; articles of paper pulp, of paper or paperboard | 82 | Tools, implements, cutlery, spoons and forks, of base metal; parts thereof, of base metal |
| 16 | Meat, fish or crustaceans; mollusks or other aquatic invertebrates; preparations thereof | 49 | Printed books, newspapers, pictures and other products of the printing industry; manuscripts, typescripts and plans | 83 | Metal; miscellaneous products of base metal |
| 17 | Sugars and sugar confectionery | 50 | Silk | 84 | Nuclear reactors, boilers, machinery and mechanical appliances; parts thereof |
| 18 | Cocoa and cocoa preparations | 51 | Wool, fine or coarse animal hair; horsehair yarn and woven fabric | 85 | Electrical machinery and equipment and parts thereof; sound recorders and reproducers; television image and sound recorders and reproducers, parts and accessories of such articles |
| 19 | Preparations of cereals, flour, starch or milk; pastrycooks’ products | 52 | Cotton | 86 | Railway, tramway locomotives, rolling-stock and parts thereof; railway or tramway track fixtures and fittings and parts thereof; mechanical (including electro-mechanical) traffic signaling equipment of all kinds |
| 20 | Preparations of vegetables, fruit, nuts or other parts of plants | 53 | Vegetable textile fibers; paper yarn and woven fabrics of paper yarn | 87 | Vehicles; other than railway or tramway rolling stock, and parts and accessories thereof |
| 21 | Miscellaneous edible preparations | 54 | Man-made filaments; strip and the like of man-made textile materials | 88 | Aircraft, spacecraft and parts thereof |
| 22 | Beverages, spirits and vinegar | 55 | Man-made staple fibers | 89 | Ships, boats and floating structures |
| 23 | Food industries, residues and wastes thereof; prepared animal fodder | 56 | Wadding, felt and nonwovens, special yarns; twine, cordage, ropes and cables and articles thereof | 90 | Optical, photographic, cinematographic, measuring, checking, medical or surgical instruments and apparatus; parts and accessories |
| 24 | Tobacco and manufactured tobacco substitutes | 57 | Carpets and other textile floor coverings | 91 | Clocks and watches and parts thereof |
| 25 | Salt; sulfur; earths, stone; plastering materials, lime and cement | 58 | Fabrics; special woven fabrics, tufted textile fabrics, lace, tapestries, trimmings, embroidery | 92 | Musical instruments; parts and accessories of such articles |
| 26 | Ores, slag, and ash | 59 | Textile fabrics; impregnated, coated, covered or laminated; textile articles of a kind suitable for industrial use | 93 | Arms and ammunition; parts and accessories thereof |
| 27 | Mineral fuels, mineral oils and products of their distillation; bituminous substances; mineral waxes | 60 | Fabrics; knitted or crocheted | 94 | Furniture; bedding, mattresses, mattress supports, cushions and similar stuffed furnishings; lamps and lighting fittings, n.e.c.; illuminated signs, illuminated name-plates and the like; prefabricated buildings |
| 28 | Inorganic chemicals; organic and inorganic compounds of precious metals; of rare earth metals, of radio-active elements and of isotopes | 61 | Apparel and clothing accessories; knitted or crocheted | 95 | Toys, games and sports requisites; parts and accessories thereof |
| 29 | Organic chemicals | 62 | Apparel and clothing accessories; not knitted or crocheted | 96 | Miscellaneous manufactured articles |
| 30 | Pharmaceutical products | 63 | Textiles, made up articles; sets; worn clothing and worn textile articles; rags | 97 | Works of art; collectors’ pieces and antiques |
| 31 | Fertilizers | 64 | Footwear; gaiters and the like; parts of such articles | 99 | Commodities not specified according to kind |
| 32 | Tanning or dyeing extracts; tannins and their derivatives; dyes, pigments and other coloring matter; paints, varnishes; putty, other mastics; inks | 65 | Headgear and parts thereof | ||
| 33 | Essential oils and resinoids; perfumery, cosmetic or toilet preparations | 66 | Umbrellas, sun umbrellas, walking-sticks, seat sticks, whips, riding crops; and parts thereof |
Appendix B.—Hilbert Curve in Different Grid System

Appendix C.—Hilbert Curve in Different Grid System

Appendix D.—Heavy-Tailed Distribution of Cot(c_ldm) and Tan(c_ldm)

Appendix E.—Detailed Information for Spatial Pattern Of Products Import–Export Difference Class

References
- Boschma, R.; Capone, G. Relatedness and diversification in the European Union (EU-27) and European Neighbourhood Policy countries. Environ. Plan. C 2016, 34, 617–637. [Google Scholar] [CrossRef] [Green Version]
- Balassa, B. Trade liberalization and revealed comparative advantage. Manch. Sch. Econ. Soc. Stud. 1965, 33, 99–123. [Google Scholar] [CrossRef]
- Casanova, C.; Xia, L.; Ferreira, R. Measuring Latin America’s export dependency on China. JCEFTS 2016, 9, 213–233. [Google Scholar] [CrossRef]
- Dingemans, A.; Ross, C. Free trade agreements in Latin America since 1990: An evaluation of export diversification. CEPAL Rev. 2012, 108, 27–48. [Google Scholar] [CrossRef]
- Haddou, A.; Young, J. Comparative Intra-industry trade analysis on the asymmetric effects of the FTA: Korea and MENA Countries. J. Int. Trade Commer. 2018, 14, 49–62. [Google Scholar] [CrossRef]
- Cristelli, M.; Tacchella, A.; Gabrielli, A.; Pietronero, L.; Scala, A.; Caldarelli, G. Competitors’ communities and taxonomy of products according to export fluxes. EPJST 2012, 212, 115–120. [Google Scholar] [CrossRef]
- Ermann, L.; Shepelyansky, D. Ecological analysis of world trade. Phys. Lett. A 2013, 377, 3–4. [Google Scholar] [CrossRef] [Green Version]
- Ermann, L.; Shepelyansky, D. Google matrix analysis of the multiproduct world trade network. EPJB 2015, 88, 84. [Google Scholar] [CrossRef] [Green Version]
- Dong, C.; Yin, Q.; Lane, K.; Yan, Z.; Shi, T.; Liu, Y.; Bell, M.L. Competition and transmission evolution of global food trade: A case study of wheat. Phys. A 2018, 509, 998–1008. [Google Scholar] [CrossRef]
- Basso, F.; Geciane, P.; Kannebley, J. International Trade Relations of Products for Wind Energy Production: A Study from the Dynamic Social Network Analysis (DSNA). In Proceedings of the 2017 Portland International Conference on Management of Engineering and Technology, Portland, OR, USA, 9–13 July 2017; pp. 1–18. [Google Scholar]
- Fu, X.; Yang, Y.; Dong, W.; Wang, C.; Liu, Y. Spatial structure, inequality and trading community of renewable energy networks: A comparative study of solar and hydro energy product trades. Energy Policy 2017, 106, 22–31. [Google Scholar] [CrossRef]
- Hao, X.; An, H.; Sun, X.; Zhong, W. The import competition relationship and intensity in the international iron ore trade: From network perspective. Resour. Policy 2018, 57, 45–54. [Google Scholar] [CrossRef]
- Pappalardo, G.; Allegra, V.; Zarba, A. The effects of the bsec on regional trade flows of agri-food products. In Proceedings of the SGEM 2014 Scientific Subconference on Political Sciences, Law, Finance, Economics and Tourism, Sofia, Bulgaria, 3–9 September 2014; Volume 4. [Google Scholar]
- Kivel, M.; Arenas, A.; Barthelemy, M.; Gleeson, J.; Moreno, Y.; Porter, M. Multilayer networks. J. Complex Netw. 2014, 2, 203–271. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Stanley, H.; Gao, J. Breakdown of interdependent directed networks. Proc. Natl. Acad. Sci. USA 2016, 113, 1138–1143. [Google Scholar] [CrossRef] [Green Version]
- Latapy, M.; Magnien, C.; Vecchio, N. Basic notions for the analysis of large two-mode networks. Soc. Netw. 2008, 30, 31–48. [Google Scholar] [CrossRef]
- Hidalgo, C.; Klinger, B.; Barabsi, A.; Hausmann, R. The product space conditions the development of nations. Science 2007, 317, 482–487. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hidalgo, C.; Hausmann, R. The building blocks of economic complexity. Proc. Natl. Acad. Sci. USA 2009, 106, 10570–10575. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vidmer, A.; Zeng, A.; Medo, M.; Zhang, Y.-C. Prediction in complex systems: The case of the international trade network. Phys. A 2015, 436, 188–199. [Google Scholar] [CrossRef] [Green Version]
- Mealy, P.; Farmer, J.; Teytelboym, A. Interpreting economic complexity. Sci. Adv. 2019, 51, 1705. [Google Scholar] [CrossRef] [Green Version]
- Hausmann, R.; Hidalgo, C. The Atlas of Economic Complexity: Mapping Paths to Prosperity; MIT Press Books; The MIT Press: Cambridge, UK, 2014; Volume 1. [Google Scholar]
- Fadeyi, O.; Bahta, T.; Ogundeji, A.; Willemse, B.J. Impacts of the SADC Free Trade Agreement on South African agricultural trade. Int. J. Entrep. Innov. 2014, 15, 53–59. [Google Scholar] [CrossRef]
- Mupela, E.; Szirmai, A. Communication costs and trade in sub Saharan Africa: A gravity approach. In e-Infrastructure and e-Services for Developing Countries. In AFRICOMM 2013. Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering; Bissyandé, T., van Stam, G., Eds.; Springer: Cham, Switzerland, 2013; p. 135. [Google Scholar]
- Matkovski, B.; Radovanov, B.; Zekic, S. The effects of Foreign agri-food trade liberalization in South East Europe. Ekonomicky Casopis 2018, 66, 945–966. [Google Scholar]
- De, F.; De, S.; VIeira, J. Evaluation of logistic performance indexes of brazil in the international trade. RAM. Rev. Admin. Mackenzie 2015, 16, 213–235. [Google Scholar]
- Goodchild, M. Geographical information-science. IJGIS 1992, 6, 31–45. [Google Scholar] [CrossRef]
- Goodchild, M.; Haining, R.; Wise, S. Integrating GIS and spatial data analysis: Problems and possibilities. IJGIS 1992, 6, 407–423. [Google Scholar] [CrossRef]
- Goodchild, M.; Yuan, M.; Cova, T. Towards a general theory of geographic representation in GIS. IJGIS 2007, 21, 239–260. [Google Scholar] [CrossRef] [Green Version]
- Zipf, G.K. Human Behaviour and the Principles of Least Effort; AddisonWesley: Cambridge, MA, USA, 1949. [Google Scholar]
- Jiang, B.; Liu, X. Scaling of geographic space from the perspective of city and field blocks and using volunteered geographic information. IJGIS 2012, 26, 215–229. [Google Scholar] [CrossRef] [Green Version]
- Jiang, B. A topological pattern of urban street networks: Universality and peculiarity. Phys. A 2007, 384, 647–655. [Google Scholar] [CrossRef] [Green Version]
- Jiang, B. Street hierarchies: A minority of streets account for a majority of traffic flow. IJGIS 2009, 23, 1033–1048. [Google Scholar] [CrossRef]
- Fisher, W.D. On grouping for maximum homogeneity. J. ASA 1958, 53, 789–798. [Google Scholar] [CrossRef]
- Jenks, G.F. Generalization in statistical mapping. Ann. AAG 1963, 53, 15–26. [Google Scholar] [CrossRef]
- Wang, J.F.; Li, X.H.; Christakos, G.; Liao, Y.; Zhang, T.; Gu, X.; Zheng, X. Geographical detectors-based health risk assessment and its application in the neural tube defects study of the Heshun region, China. IJGIS 2010, 24, 107–127. [Google Scholar] [CrossRef]
- Jiang, B.; Ma, D. How complex is a fractal? Head/tail breaks and fractional hierarchy. J. Geovisualization Spat. Anal. 2018, 2, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Jiang, B.; Yin, J. Ht-Index for quantifying the fractal or scaling structure of geographic features. Ann. AAG 2014, 104, 530–540. [Google Scholar] [CrossRef]
- Taleb, N.N. The Black Swan: The Impact of the Highly Improbable; Allen Lane: London, UK, 2007. [Google Scholar]
- Jiang, B. Head/Tail Breaks: A new classification scheme for data with a heavy-tailed distribution. Prof. Geogr. 2012, 65, 482–494. [Google Scholar] [CrossRef]
- Ye, S.J.; Zhang, C.; Wang, Y.; Liu, D.; Du, Z.; Zhu, D. Design and implementation of automatic orthorectification system based on GF-1 big data. TCSAE 2017, 33, 266–273. [Google Scholar]
- Ye, S.J. Research on application of Remote Sensing Tupu-take monitoring of meteorological disaster for example. AGCS 2018, 47, 892, (In Chinese with English abstract). [Google Scholar]
- Ye, S.; Liu, D.; Yao, X.; Tang, H.; Xiong, Q.; Zhuo, W.; Du, Z.; Huang, J.; Su, W.; Shen, S.; et al. RDCRMG: A raster dataset clean & reconstitution multi-grid architecture for remote sensing monitoring of vegetation dryness. Remote Sens. 2018, 10, 1376. [Google Scholar]
- Yao, X.; Mokbel, M.; AlArabi, L.; Eldawy, A.; Yang, J.; Yun, W.; Li, L.; Ye, S.; Zhu, D. Spatial coding-based approach for partitioning big spatial data in Hadoop. Comput. Geosci. 2017, 106, 60–67. [Google Scholar] [CrossRef] [Green Version]
- Ye, S.J.; Yan, T.L.; Yue, Y.-L.; Lin, W.-Y.; Li, L.; Yao, X.; Mu, Q.-Y.; Li, Y.-Q.; Zhu, D.-H. Developing a reversible rapid coordinate transformation model for the cylindrical projection. Comput. Geosci. 2016, 89, 44–56. [Google Scholar] [CrossRef]
- Wang, S.; Xu, X. A new algorithm of hilbert scanning matrix and its MATLAB program. J. Image Graph. 2006, 1, 119–122. [Google Scholar]







| No. | Class | C_LDM Intervals | Illustration |
|---|---|---|---|
| 1 | Class A | [85, 90] | Sexp1 >> Simp2, Sexp / Simp > 11.43 |
| 2 | Class B | (60, 85) | Sexp > Simp, Sexp / Simp ∈ (1.73,11.43] |
| 3 | Class C | [30, 60] | Sexp ≈ Simp, Sexp / Simp or Simp / Sexp ∈ [1,1.73] |
| 4 | Class D | (5, 30) | Sexp < Simp, Simp / Sexp ∈ (1.73,11.43] |
| 5 | Class E | [0, 5] | Sexp << Simp, Simp / Sexp > 11.43 |
| HS 4 Code | Type of Product | Class, Level | HS 4 Code | Type of Product | Class, Level |
|---|---|---|---|---|---|
| Surplus (Class A / B) | Deficit (Class D / E) | ||||
| 3924 | Plastic table, kitchen, household, toilet articles | Class A, Level 3 | 1201 | Soya beans | Class E, Level 4 |
| 3926 | Plastic articles nes | Class A, Level 3 | 4707 | Waste or scrap of paper or paperboard | Class E, Level 3 |
| 4011 | New pneumatic tires, of rubber | Class A, Level 3 | 5201 | Cotton, not carded or combed | Class E, Level 3 |
| 4202 | Trunks, suitcases, camera cases, handbags, etc | Class A, Level 3 | 7108 | Gold, unwrought, semi-manufactured, powder form | Class E, Level 3 |
| 6104 | Women’s, girl’s suit, dress, skirt, etc, knit or crochet | Class A, Level 3 | 7404 | Copper, copper alloy, waste or scrap | Class E, Level 3 |
| 6110 | Jerseys, pullovers, cardigans, etc, knit or crochet | Class A, Level 3 | 8411 | Turbo-jets, turbo-propellers/other gas turbine engine | Class D, Level 3 |
| 6203 | Men’s or boy’s suits, jackets, trousers etc not knit | Class A, Level 3 | 8486 | Machines and apparatus of a kind used solely or principally for the manufacture of semiconductor boules or wafers, semiconductor devices, electronic integrated circuits or flat panel displays; machines and apparatus specified in Note 9 (C) of this Chapter | Class E, Level 3 |
| 6204 | Women’s, girl’s suits, jacket, dress, skirt, etc, woven | Class A, Level 3 | |||
| 6402 | Footwear nes, with outer sole, upper rubber or plastic | Class A, Level 3 | |||
| 6403 | Footwear with uppers of leather | Class A, Level 4 | 8542 | Electronic integrated circuits and microassemblies | Class D, Level 4 |
| 6404 | Footwear with uppers of textile materials | Class A, Level 3 | 8703 | Motor vehicles for transport of persons (except buses | Class E, Level 4 |
| 7113 | Jewelry and parts, containing precious metal | Class A, Level 3 | 8802 | Aircraft, spacecraft, satellites | Class E, Level 4 |
| 8414 | Air, vacuum pumps, compressors, ventilating fans, etc | Class B, Level 3 | 9018 | Instruments etc for medical, surgical, dental, etc us | Class D, Level 3 |
| 8443 | Printing and ancillary machinery | Class A, Level 3 | Approximate (Class C) | ||
| 8467 | Tools for working in the hand, non-electric motor | Class A, Level 3 | 8541 | Diodes, transistors, semi- conductors, etc | Class C, Level 3 |
| 8471 | Automatic data processing machines (computers) | Class A, Level 5 | 2709 | Petroleum oils, oils from bituminous minerals, crude | Class C, Level 3 |
| 8473 | Parts, accessories, except covers, for office machine | Class B, Level 4 | Surplus (Class A / B) | ||
| 8481 | Taps, cocks, valves for pipes, tanks, boilers, etc | Class B, Level 3 | 8544 | Insulated wire and cable, optical fiber cable | Class B, Level 3 |
| 8504 | Electric transformers, static converters and rectifier | Class B, Level 3 | 8609 | Cargo containers designed for carriage of goods | Class A, Level 3 |
| 8516 | Electric equipment with heating element, domestic etc | Class A, Level 3 | 8708 | Parts and accessories for motor vehicles | Class B, Level 4 |
| 8517 | Electric apparatus for line telephony, telegraphy | Class A, Level 5 | 9401 | Seats (except dentist, barber, etc chairs) | Class A, Level 4 |
| 8518 | Audio-electronic equipment, except recording devices | Class A, Level 3 | 9405 | Lamps and lighting fittings, illuminated signs, etc | Class A, Level 4 |
| 8521 | Video recording and reproducing apparatus | Class A, Level 3 | 9404 | Mattress supports, mattresses, bedding | Class A, Level 3 |
| 8525 | Radio and TV transmitters, television cameras | Class A, Level 4 | 9403 | Other furniture and parts thereof | Class A, Level 4 |
| 8528 | Television receivers, video monitors, projectors | Class A, Level 4 | 9503 | Other toys, scale models, puzzles, etc | Class A, Level 4 |
| 8529 | Parts for radio, TV transmission, receive equipment | Class B, Level 3 | 9504 | Articles for funfairs, table and parlor games | Class A, Level 3 |
| 8543 | Electrical machinery and apparatus, nes | Class B, Level 3 | 9506 | Equipment for gymnastics, sports, outdoor games nes | Class A, Level 3 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, S.; Song, C.; Cheng, C.; Shen, S.; Gao, P.; Zhang, T.; Chen, X.; Wang, Y.; Wan, C. Digital Trade Feature Map: A New Method for Visualization and Analysis of Spatial Patterns in Bilateral Trade. ISPRS Int. J. Geo-Inf. 2020, 9, 363. https://doi.org/10.3390/ijgi9060363
Ye S, Song C, Cheng C, Shen S, Gao P, Zhang T, Chen X, Wang Y, Wan C. Digital Trade Feature Map: A New Method for Visualization and Analysis of Spatial Patterns in Bilateral Trade. ISPRS International Journal of Geo-Information. 2020; 9(6):363. https://doi.org/10.3390/ijgi9060363
Chicago/Turabian StyleYe, Sijing, Changqing Song, Changxiu Cheng, Shi Shen, Peichao Gao, Ting Zhang, Xiaoqiang Chen, Yuanhui Wang, and Changjun Wan. 2020. "Digital Trade Feature Map: A New Method for Visualization and Analysis of Spatial Patterns in Bilateral Trade" ISPRS International Journal of Geo-Information 9, no. 6: 363. https://doi.org/10.3390/ijgi9060363