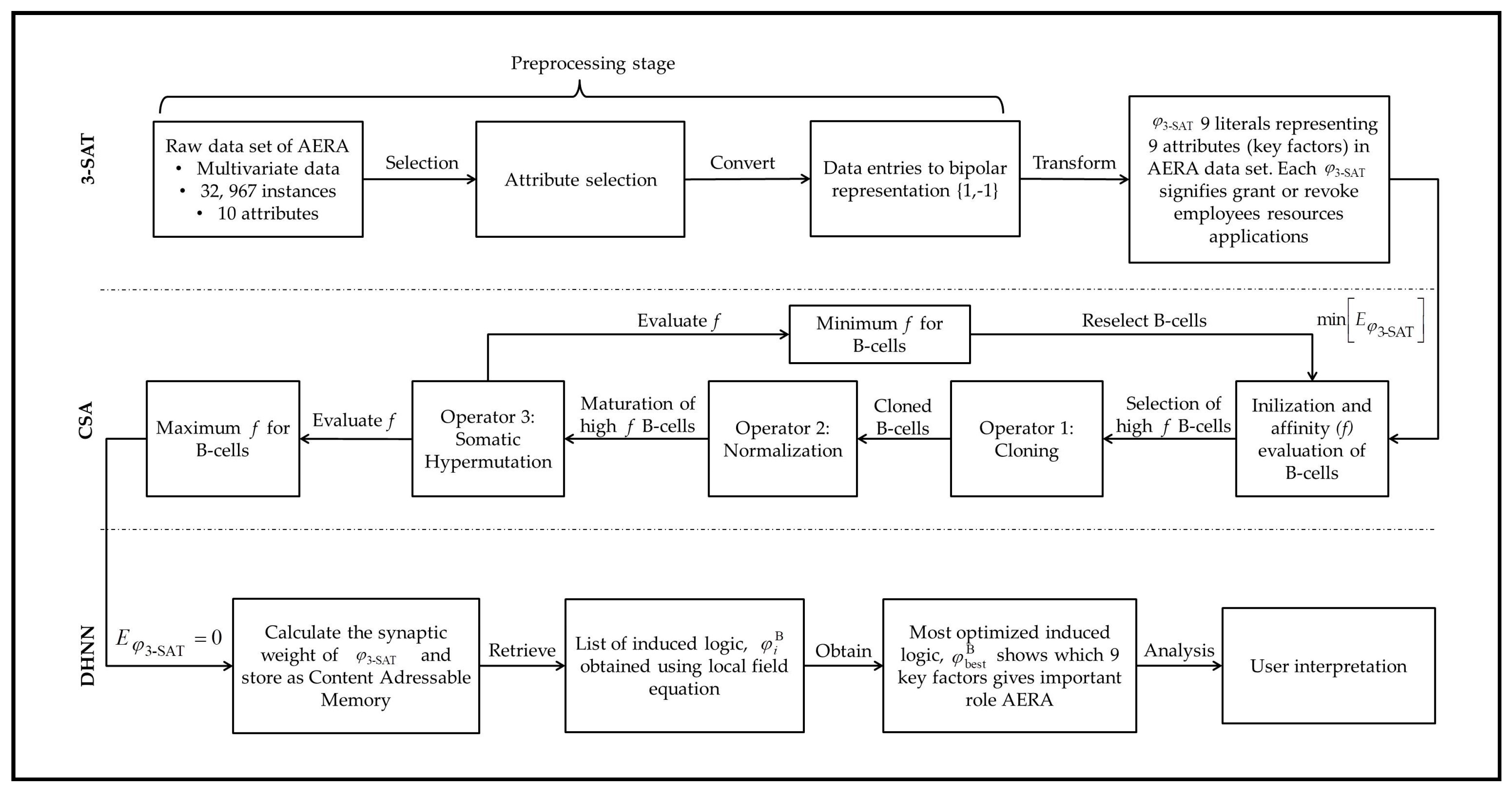
1. Introduction
Amazon.com Inc. operates internationally by offering consumers products and subscriptions through more than 10 owned retail websites and physical stores in 600 locations across the United States of America (US). As reported in 2019, the company has increasing numbers of employees, and more than 600,000 employees worldwide [
1]. Thus, with a large number of employees, there is always a risk of highly complicated employees and resources situations [
2]. Within any company, new employees require a variety access of systems, portals or appliances related on the role, designation or unit of the employee. Technology companies like Amazon.com Inc. provide various types of resources; from computing to storage resources, accessible by their employees to be utilized optimally [
3]. However, most of the time, employees encounter some complications prior to fulfilling their daily tasks. For example, computing resources opt to have Wi-Fi connection or they are unable to log in into Amazon.com Inc. human resources portal. Commonly, new resources applications are being processed and reviewed by distinct human administrators. It is worth mentioning that the downside of this common practice involves a chain of human involvement that could lead to higher cost of resource maintenance and could be time-consuming. Therefore, Amazon.com Inc. made public their historical data from 2010–2011 of Amazon Employees Resources Access (AERA) data set, provisioned by Ken Montanez from Information Security of Amazon.com Inc. in partnership with Kaggle. Their motive is to seek alternative models that will prioritize the needs of employees and minimize manual resources access applications. A study by [
4] proposed a forecasting model by using random forest (RF), logistic regression (LR) and gradient boosting (GB). However, the suggested approach was restricted to statistical linear classifiers and required a preprocessing step due to the imbalanced entries of AERA. One may question what makes this experiment significant from the work by [
4]? In this paper, the main objective is to propose an alternative model in the field of data science by incorporating Artificial Neural Networks (ANNs) with Metaheuristic and Satisfiability representation (SAT). The proposed model act as a platform of knowledge extraction to handle big data which could benefit other big companies like Walmart Inc., Apple Inc., Samsung Electronics etc. in resources management.
ANN comprises parallel and nonparallel computing networks that are inspired by the mechanism of human biological brain [
5]. ANN has several comprehensive architectures of feed-forward or feedback networks. Artificial Intelligence (AI) practitioners utilized ANN as a platform in applications such as entity classification problems [
6], conducting analysis [
7,
8], pattern recognition [
9,
10], clustering problems [
11,
12] and circuits [
13,
14]. Nonetheless, another popular network of feedback ANN is the Hopfield Neural Network (HNN), which was formulated by [
15] to solve optimization tasks. The extensive structure of HNN comprises energy function and associative property of content addressable memory (CAM). The work of [
16] utilized HNN for transmitting binary amplitude modulated signals based on the potential energy function yielding lower probability of error. In addition, the work of [
17] emphasized HNN as one of the most studied attractor-memory models due to the feature of useful Content Addressable Memory (CAM) for an optimization model. Note that HNN can be split into continuous HNN (CHNN) and discrete HNN (DHNN). The structure of DHNN consists of input and output neurons that store bipolar
or binary
pattern [
18]. In addition, DHNN utilizes the Lyapunov energy function to determine degree of convergence of the solution [
19]. This paper incorporates the Wan Abdullah (WA) method of finding the synaptic weights by comparing the Lyapunov energy function with the cost function [
20]. The core impetus of the presented works is the relevancy of utilizing DHNN as a comprehensive model of AI as a platform to solve optimization tasks. Although DHNN is a “black box” model, the best way to observe DHNN behaviour is by implementing a systematic symbolic rule during the learning phase and a retrieved phase equation. Hence, one of the alternative ways to represent information theory is by the concept of satisfiability.
Satisfiability representation (SAT) is a logical and mathematical knowledge representation that plays a significant role in AI. SAT is utilized in various applications and areas such as quantum chemistry [
21], approximation model [
22], classification [
23], chaos computing [
24] and fault detection [
25]. The SAT structure consists of clauses comprises of literals or variables. Why is SAT needed in DHNN? SAT is essential to provide symbolic instruction in attempt to represent the output of DHNN. Pioneer work by [
26] showed the adaptability of Horn-SAT to represent information in executing the DHNN model that was improved later by [
27]. The work improvised the existing model in neuro-symbolic integration model that gained more than 90% of global minimum energy. However, the restricted component in using Horn formula is limited in representing real-life data sets, which indicate not all real-life problem can be formulated in Horn-SAT [
28]. Therefore, several researchers further extend the fundamental of Horn-SAT by proposing of DHNN model with different
k-Satisfiability (
k-SAT) logical representation [
29,
30,
31]. These works emphasized on utilizing
k-SAT, Maximum
k-SAT (MAX
k-SAT) and Maximum 2-SAT (MAX2-SAT) to investigate the ability of DHNN to process
k-SAT patterns. In another development, data mining is a process of recognizing sequences or patterns in real-life data sets that involve various platforms. The difference between data mining and logic mining is that the logical rule mining utilizes logic to convey the information to the end user. Contingent upon that, the earliest logic mining method, the reverse analysis (RA) method, was introduced by [
32] and it accommodates the combination of RA and logic programming in DHNN to deduce the pattern and relationship of the real-life data sets. Subsequently, [
33] utilized previous work of building a knowledge extraction tool by forming
k-Satisfiability-based Reverse Analysis (
k-SATRA).
k-SATRA carries an important role in logic mining to display the true behaviour or pattern of a real-life data set by extracting the optimum logic that represents the relationship of the attributes. The extracted logic will represent information aligned with the specifics classification tasks. An interesting application of
k-SATRA is reported by the work of [
34], which investigates students’ performance in identifying related factors of underachievement students. The work entrenched several real-life data sets and obtained higher accuracy than two other existing educational data mining methods. Another development of utilizing
k-SATRA was by [
35] and [
36] which exhibited the ability 2-SATRA to extract key findings of online games and football matches. The common denominator of these works exhibits the practicability of
k-SATRA in extracting knowledge from a real-life data set. The extracted knowledge identifies relationships of attributes that affect the final outcome. However, there are no current works creating a platform to bridge logic and data mining methods with specific optimization tasks such as those encountered by Amazon.com Inc. of detecting which factor should be prioritized in order to grant or revoke employees resources applications. The incorporation of metaheuristics like the Clonal Selection Algorithm (CSA) in the training phase would capitalize better on the learning environment for an optimal optimization model.
The Metaheuristics Algorithm is a nonderivative method that searches near optimal solutions with specific constraints. [
37] presented various applications of metaheuristics to find high-quality solutions to increasing number of ill-defined and complex real-world problems. Metaheuristics garnered much attention, especially from ANN practitioners, because metaheuristics provides a better learning mechanism of ANN networks by specifying the searching space of solutions and focusing on gradual solution improvement [
38]. Conventionally, DHNN deployed the primitive learning rule of exhaustive search (ES), a trial and error mechanism to find solutions [
39]. ES increases the probability of overfitting [
40] and generates less variation of solutions [
41]. CSA is an evolutionary algorithm, inspired by the natural phenomenon of the biological immune system, which defends the body against external microorganisms. [
42] reviewed recent works by researchers implementing CSA into their proposed network to deal with constraint optimization tasks, such as pattern recognition [
43], scheduling [
44], fault detection [
45] and dynamic optimization [
46]. Mechanisms of CSA gives the inspiration of specific cells to recognize specific antigens which are later selected to proliferate. This resulted in a learning algorithm of evolving candidate solutions by selection, cloning and somatic hypermutation procedures, which established variation of solutions. Conjointly, the mechanism of CSA sets a new paradigm of solving optimization tasks. Pioneer work by [
47] introduced the affinity-based interaction for modified CSA as a solver with the tabu search technique for the Maximum 3-SAT (MAX3-SAT) problem. The suggested model yielded quality solutions. Therefore, to predict the resources access applications for future sets of employees of AERA, this paper capitalizes on fundamental DHNN by incorporating CSA in the learning phase to overcome conventional metaheuristic drawbacks. The proposed model sets apart from previous literature due to different role of CSA to facilitate the learning phase of DHNN for 3-SAT logic, resulting a single intelligent unit that incorporates real-life data set to help Amazon.com Inc. resources access management.
To our best knowledge, no current work has proposed the incorporation of DHNN with CSA for 3-SATRA logic-mining methods. An optimal model may result in better management from Amazon.com Inc. in providing the best care for their employees. Subsequently, the contributions of this work are stated as follows: (1) To transform AERA into a 3-SAT logical representation to best represent the relationship of AERA. (2) To construct a modified DHNN model with CSA to enhance the learning phase of DHNN. (3) To utilize the 3-SATRA method into our proposed model as an alternative method to extract information from AERA in the form of logical representation. (4) To demonstrate the capability of our proposed model by conducting a simulated data set, benchmark data sets and the AERA data set in comparison with other existing methods. The comparison will be also evaluated by using appropriate performance evaluation metrics. The findings of this paper displayed the competency of our proposed model outperformed other existing methods for all type of data sets.
Figure 1 illustrates the implementation of our contribution in this paper.
2. Boolean Satisfiability
Boolean satisfiability logic (SAT) represents a task in determining truth assignments that makes the logical rule satisfiable. SAT is a nondeterministic polynomial time, NP-complete problem where SAT can be solved in polynomial time by a nondeterministics Turing machine [
48]. In this paper, SAT is represented in a conjunctive normal form (CNF) and composed of three significant elements [
49]:
A group of variables: where .
A group of literals: A literal is a variable or a negation of a variable .
A group of clauses: .
The above elements can be explicitly represented in the following Equation (1):
This paper utilized 3-Satisfiability (3-SAT) logical rule,
, in each clause of which only exist three variables. Equation (2) governed an example of
. Note that
represents the objective or outcome of the logical rule.
Table 1 shows an example of cases for the
logical rule. The outcomes of each case are known by substituting the values of
(neuron states) into Equation (2). For instance, case 1 is satisfiable since each clause gives a truth value. Besides that, case 3 is in full consistency since all literals give a truth value. Additionally, the work by [
49] states that the algorithm needs to learn more inconsistent interpretations to obtain the satisfied
, which we described as the checking clause satisfaction process. To undergo this process, a suitable metaheuristic algorithm is needed to attain
[
47]. In this paper, the
logical rule is employed in our proposed model to govern our model and represent each entry of AERA.
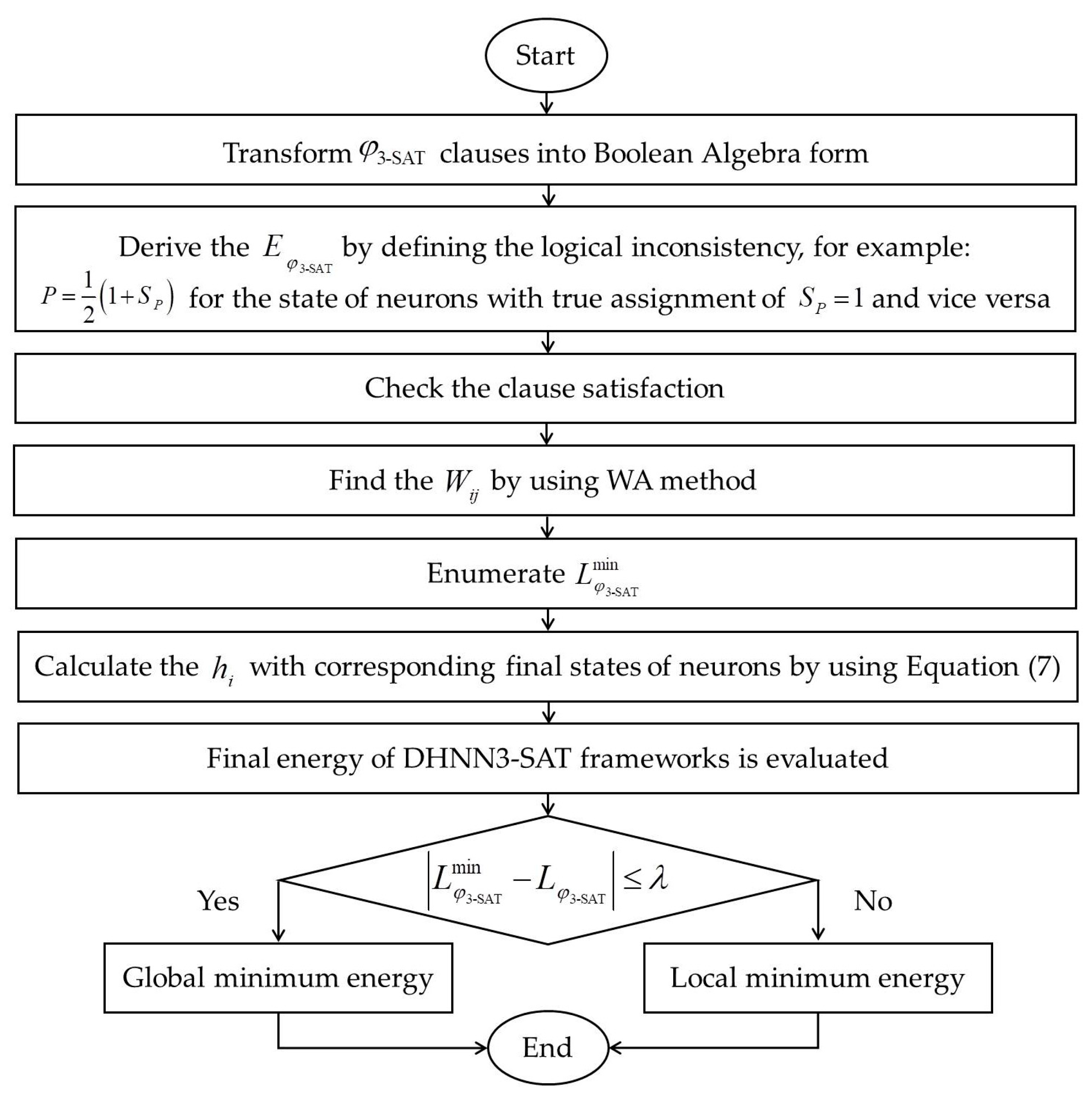
3. 3-Satisfiability in Discrete Hopfield Neural Network
The Discrete Hopfield Neural Network (DHNN) is another variant of the Hopfield Neural Network that is commonly utilized to solve practical optimization problems [
50]. DHNN consists of interconnected neurons with no hidden layer. Each neuron in DHNN is bipolar
,
, which exemplifies the interpretation of the defined problem. Several properties of DHNN include associative memory, fault tolerance and energy minimization as the neuron state changes. There are two types of neuron updates in DHNN: asynchronous and synchronous update. We limit our discussion to asynchronous update because we only consider one neuron state at the time. Each neuron spin resembles an Ising spin variable model [
51], which contributes to updating neurons in each cycle. The general updating rule of the general DHNN is given as follows:
where
and
are the synaptic weight and threshold of the contraints. It is worth mentioning that we consider
to ensure the energy of DHNN decreases uniformly [
52].
in each neurons connection is formally defined in a matrix of
with the threshold of the neuron updates given by
. Note that DHNN has no self-looping
for all neurons and the connection is symmetrical
which results in a matrix with zeros diagonal. The updating rule of general DHNN is important to ensure the neuron state will converge to the optimal solution. In this section, we capitalize the logical rule of
into the structure of DHNN by defining the cost function of the network.
can be implemented in DHNN by minimizing the cost function
:
where
and
are the number of clauses and number of literals accordingly.
is defined as follows:
where
is one possible variable in
. Note that the lowest value of the cost function is
where all the inconsistencies of the
are minimized. Hence the updating rule or local field of the
in DHNN is given as follows:
where
,
and
are synaptic weight for the third, second and first order connection respectively. The threshold for the proposed DHNN is
and can be flexibly defined by the user. According to [
53], the final neuron state,
, can be optimized by the usage of a squashing function such as a Hyperbolic Activation Function (HTAF). Interested readers on this aspect may refer to [
49,
53,
54]. Furthermore, Equations (6) and (7) are vital to ensure the final neuron state always converges to
. Theorem 1 explains the behaviour of the synaptic weight with respect to the final state of the neuron.
Theorem 1. Letwhereis the threshold of the model of DHNN. Assumingoperates in asynchronous mode andis a symmetric matrix with the elements of the diagonal being nonnegative. Then DHNN will always converge to a stable state.
In addition, the Lyapunov energy function
that corresponds to the
rule is given as follows:
The value of
indicates the quality of the final state obtained from Equation (8). According to [
20], the synaptic weight of the DHNN can be obtained by comparing Equations (4) and (6). The energy value of the
,
, can be predetermined before the learning phase because the energy value from each clause in
is always constant. It is worth mentioning that the optimal DHNN always converges to
or
, where
is the tolerance value of the Lyapunov energy function. In this paper, the information from the data set will be represented in terms of
and embedded into DHNN. The implementation of
in DHNN is abbreviated as DHNN-3SAT. One of the main obstacles in implementing DHNN-3SAT is to find a set of
that corresponds to
. By that standard, optimal learning method is required to effectively minimize
.
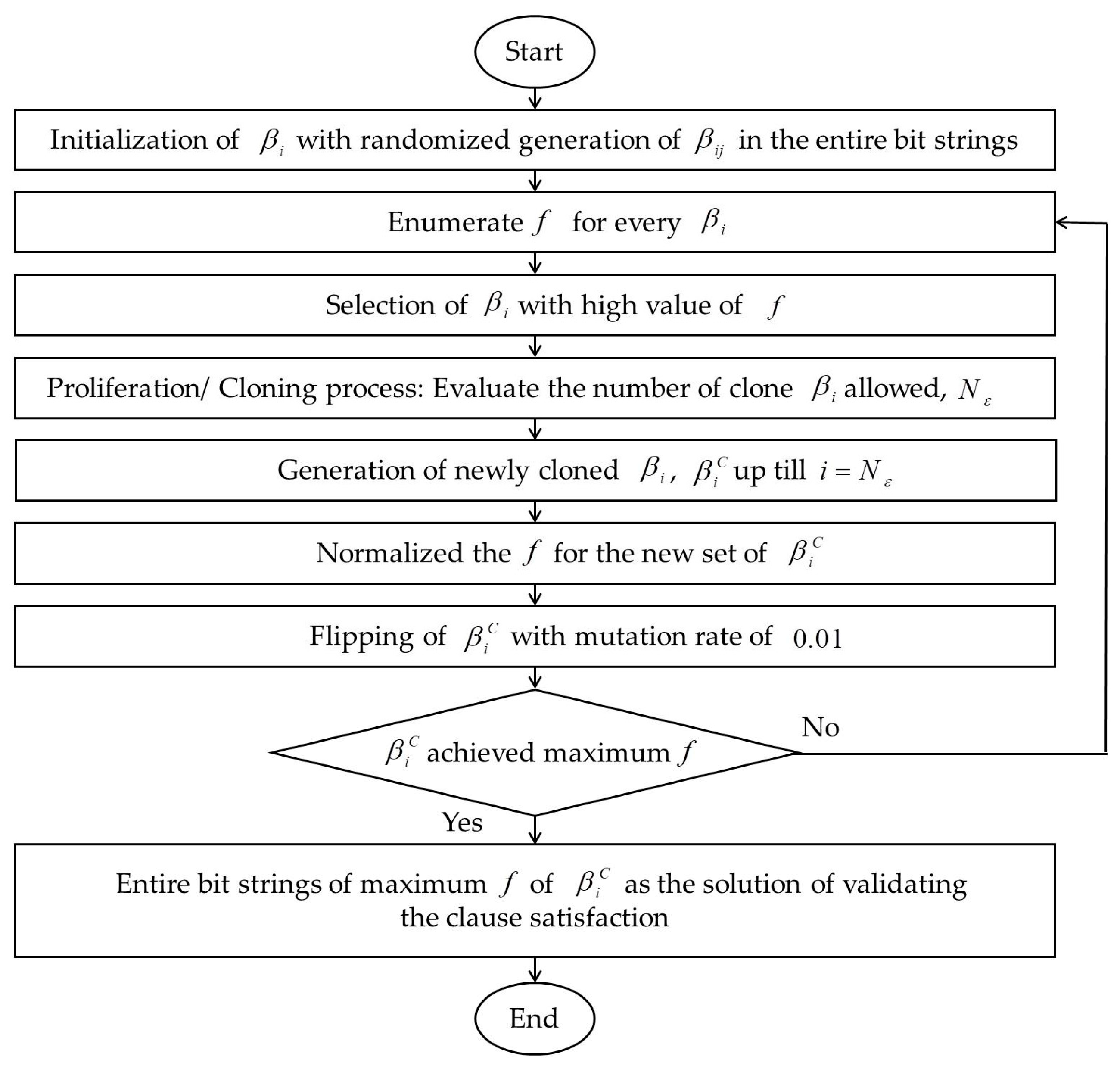
4. Clonal Selection Algorithm
The learning phase of an ANN can be further improved via metaheuristics to provide more global solutions, a better learning mechanism and to ascertain the convergence of the ANN models [
55]. A work proposed by [
56] indicated that these algorithms required less execution time to complete the training process. Generally, metaheuristics have two types of searching algorithms, trajectory-based and population-based. The work is focusing on the population-based nature-inspired algorithm of evolutionary algorithms (EA). CSA is a class of Artificial Immune System (AIS) algorithms that is motivated by the natural immune system process that build particular antibodies against antigens. B-cells
will produce specific antibodies once a new antigen is identified. Through the cloning process, the chosen
will proliferate to form a clone of
and fight against antigens [
57]. The cloned
developed into two types of cell, memory cells and plasma cells. Memory cells are recognized as long-lived cells that can react instantly to any illness. As for the plasma cells, they are active and able to secrete specific antibodies for the antigens, but they do not last long.
The findings by Layeb [
47] presented modified CSA with the tabu search method to resolve the satisfiability problem. The affinity computation in [
47] utilized the adaptive affinity function, which considers the summation of weight with the clauses and complies with the binary vector form of MAX-SAT logical representation. On the other hand, our proposed CSA model complies to bipolar representation of
as the affinity function being formulated in terms of clause representation that corresponds to
. The operations involved in the CSA mechanism are where
produces a specific antibody to destroy a specific antigen, which signifies the adaptive system of CSA principle. Proliferation, normalization and somatic hypermutation processes ensure a better variation of the
population. This paper implements the CSA mechanism to provide an optimal learning model, where CSA helps to achieve maximum number of satisfied clauses from the affinity or fitness of
. The implementation of CSA in the proposed model (DHNN3-SATCSA) is presented as follows [
58]:
Stage 1: Initialization of
(interpretations) were initialized.
Stage 2: Affinity Evaluation
Compute affinity of all
in the entire population,
. The
examines the number of clauses satisfied in
.
is the number of clauses learned by CSA and
is the number of clauses in
.
where
given that
.
Stage 3: Proliferation via Cloning
The top five
with higher affinity were chosen to proliferate in cloning process. In this process,
will be duplicated by applying the roulette wheel mechanism [
59]. The number of cloned
,
will be computed by using Equation (12).
where
, known as initial affinity, is the population clone size which the software seeks to implement into the searching space. [
58] suggested selecting
.
Stage 4: Normalization
Equation (13) shows the list of cloned
;
.
Normalization of
is often called immune response maturation throughout the system. It is important to normalize the
before proceeding to the next step. Next, we calculate the affinity for each
, which is abbreviated as
.
where
Note that because the probability of getting is almost zero.
Stage 5: Somatic Hypermutation
The somatic hypermutation process is significant since it will ensure the
to achieve highest affinity which results in a feasible solution. Equation (16) shows the calculation of the number of mutations
for each
.
where
is the number of variables in
,
and
[
58]. For every mutation that occurs in
, one or more
will be flipped from 1 to −1 or vice versa.
Finally, the
of mature population will be computed and we will choose the best
as the candidate cell to be kept in the memory cell. The solution will be selected if
. On the other hand, the process will repeat from stages 2 to 5 if
.
Figure 2 shows the summary of all steps involved in CSA.
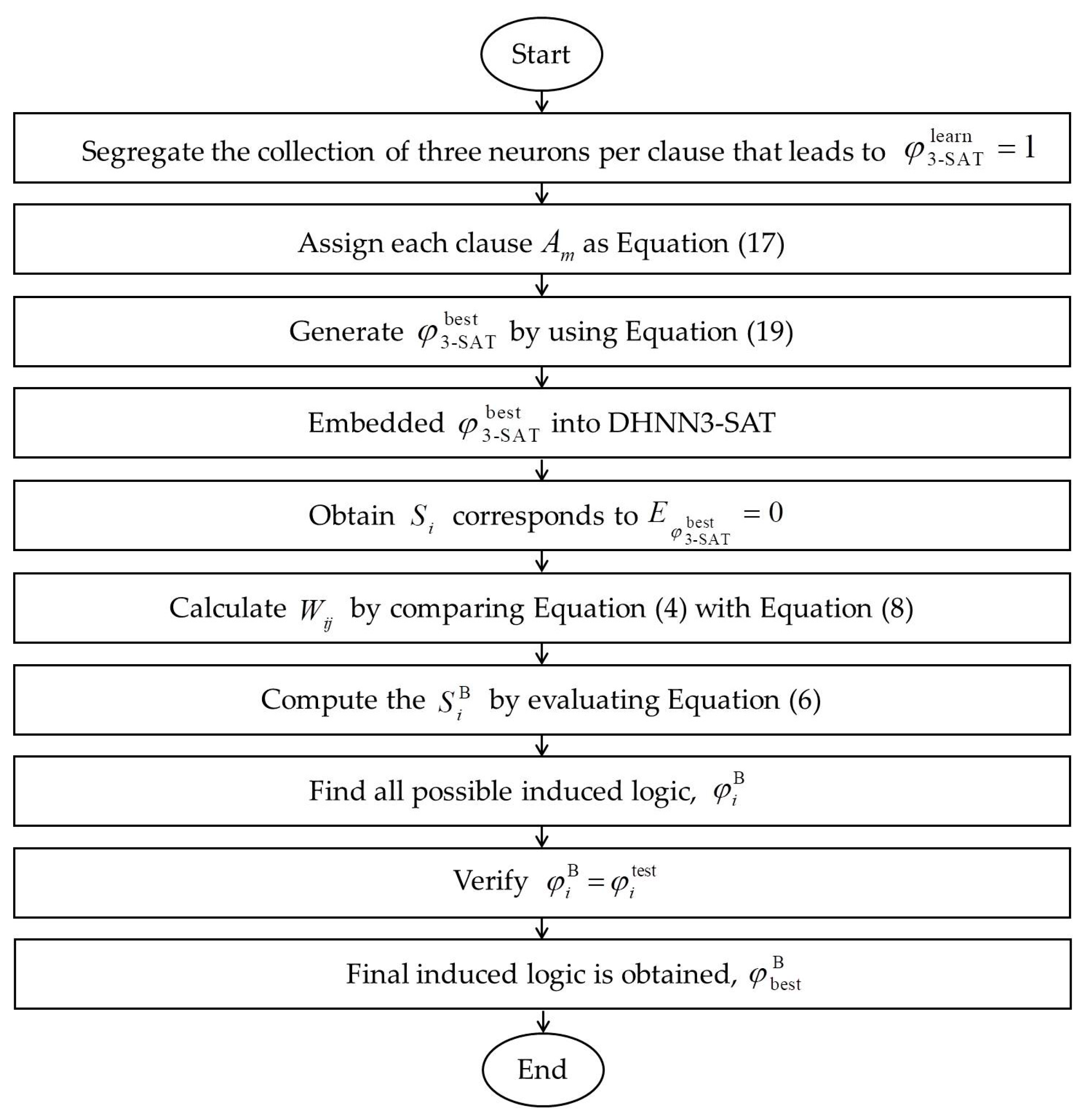
5. 3-Satisfiability Based Reverse Analysis Method
Logic mining is a process that utilizes logic programming to extract information from a data set. In this regard, this section will explain how the logic mining tool named 3-Satisfiability-based Reverse Analysis Method (3-SATRA) is implemented in our DHNN3-SATCSA model to extract the relationship of AERA entries. Consider
attributes of the data sets
, where
. Note that all binary representations must be represented in terms of bipolar states. Since this paper investigates
, the arrangement of each
consists of
,
,
where
. Note that
is the number of clauses in
. For
that leads
, we assign
Note that
signifies the highest frequency of
. In this case, each
is given as follows:
By using the obtained
, we can formulate
:
For example, we will choose
if
,
and
. Next,
will be embedded into DHNN. Henceforth, we will obtain the states of
that correspond to
. By comparing Equation (4) with Equation (8), the corresponding
will be obtained. During the testing phase, the induced states,
, will be obtained by using Equation (6). Subsequently, the induced logic,
will be constructed based on the rule given in Equation (2). Finally, the chosen induced logic is obtained based on
(testing data).
Figure 3 demonstrates how 3-SATRA was implemented in the DHNN model. In this paper, we will represent each neuron with entries of AERA.
6. Experimental Setup
A standard procedure among ANN practitioners is to investigate the proposed model with other comparative studies. Therefore, the simulation process is divided into three sections. Firstly, the performance of DHNN3-SATCSA is analyzed by using simulated data sets. In this case, the ability of CSA in the learning phase of the proposed model will be compared with other existing methods [
58,
60]. Secondly, several benchmark data sets will be implemented into DHNN3-SATCSA. The comparison of the retrieval properties of DHNN3-SATCSA will be also evaluated based on
. The third section presents the implementation of AERA into the proposed model. All real-life data sets that were converted to bipolar representation and information extraction will be conducted via 3-SATRA and incorporated with DHNN3-SAT models.
In the first section, DHNN with linearized initial neuron states might result in the biasedness of the retrieval state because the network simply memorizes the final state without producing a new state [
61]. Therefore, possible positive and negative biases can be reduced by generating all the neuron states randomly as in Equation (20):
where
is defined as in Equation (3). The simulated data set will be initiated by generating randomized clauses and literals for each
. A similar approach has been implemented in several studies such as [
19,
60] in generating the initial neuron states. It is worth mentioning that all simulations will be measured against existing methods by evaluating appropriate performance evaluation metrics. By quoting several relevant studies that implemented such experimentations [
35,
49,
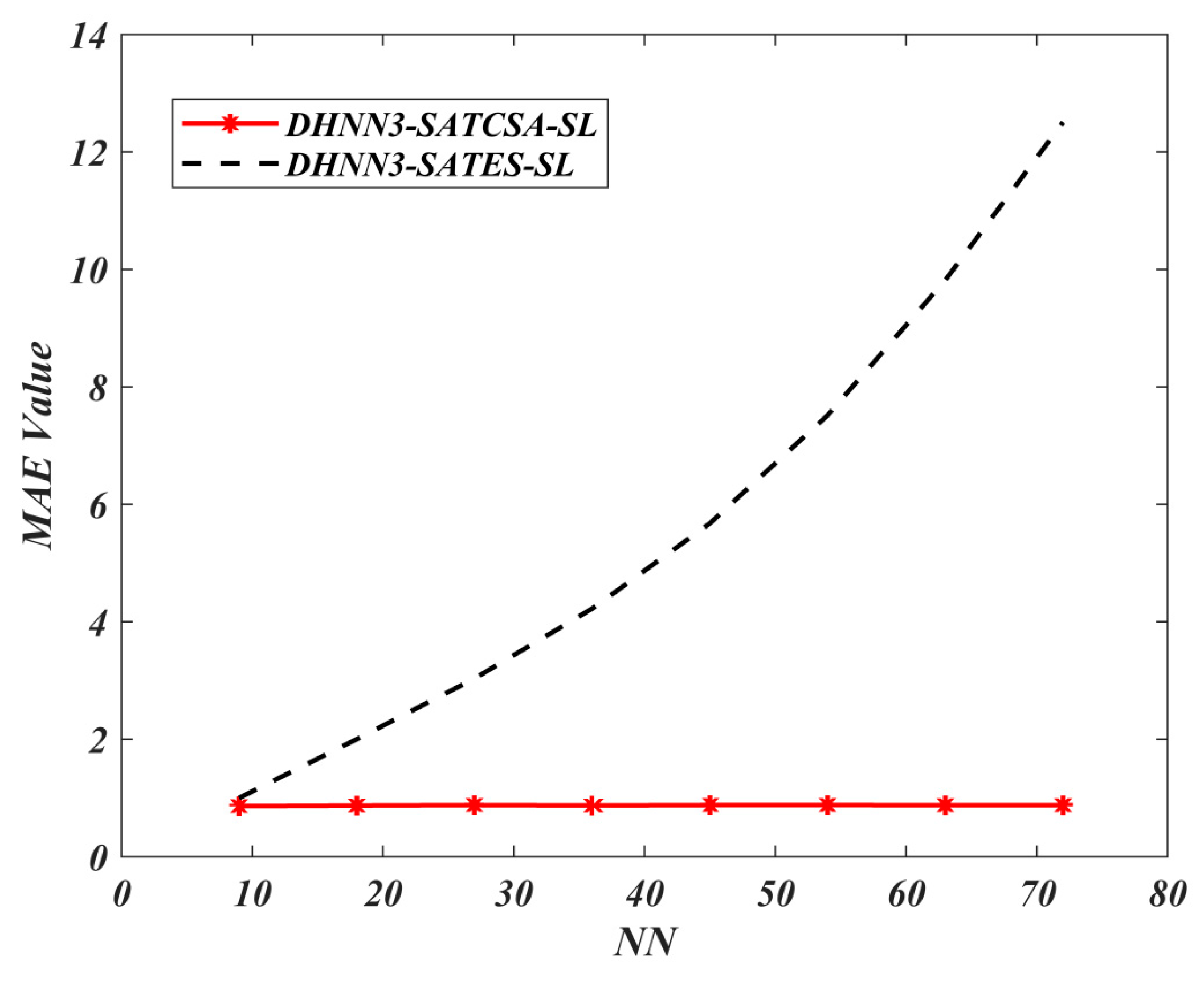
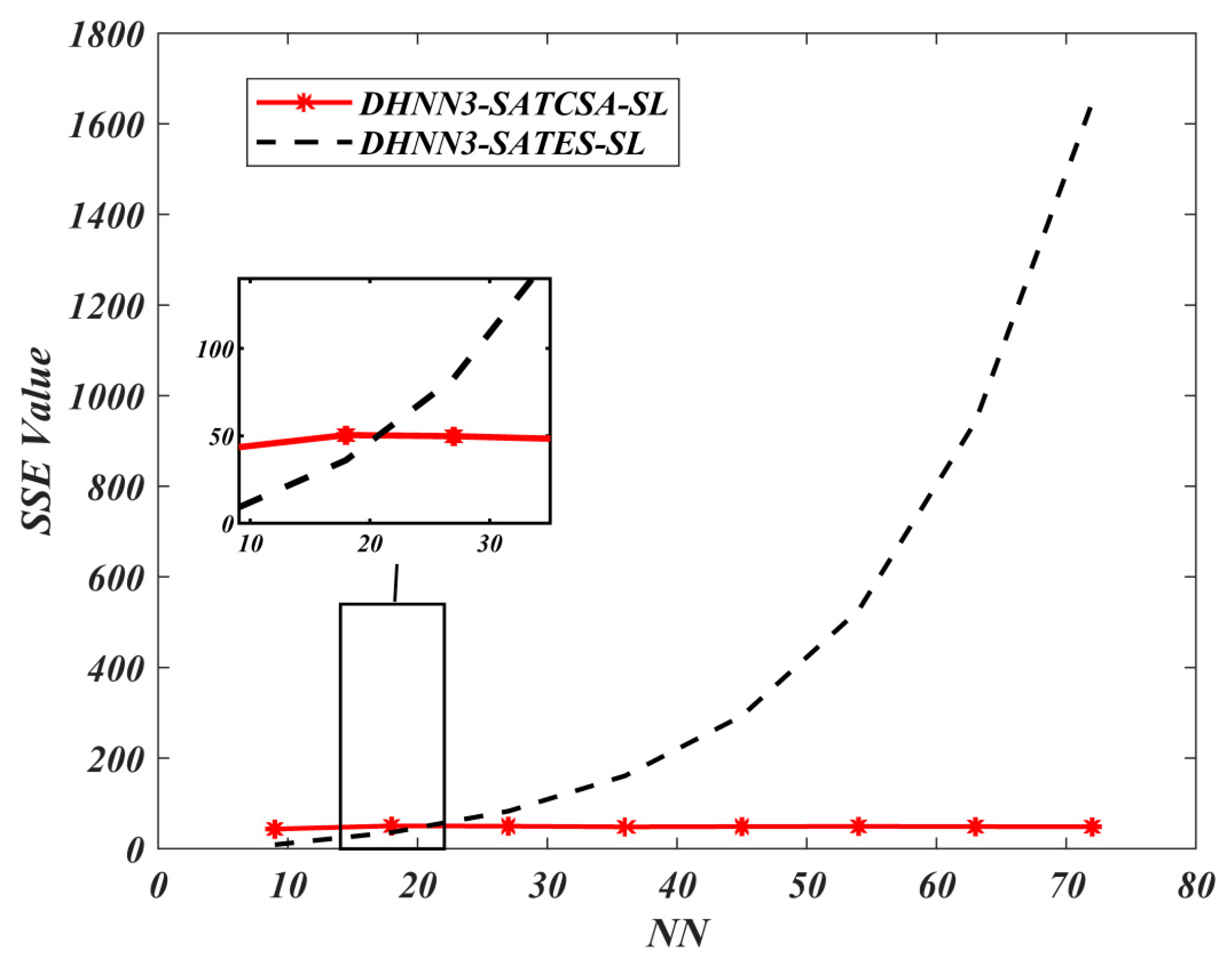
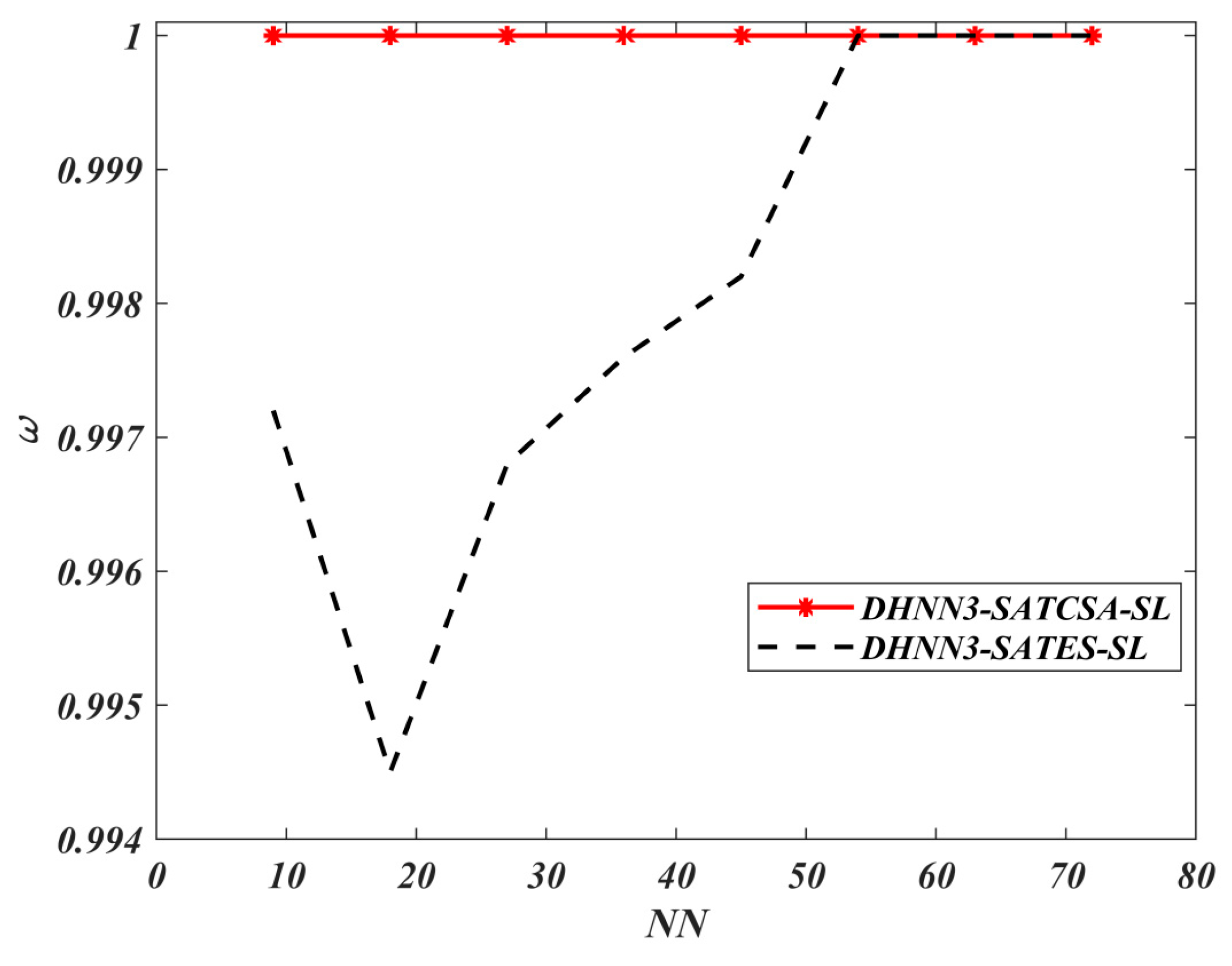
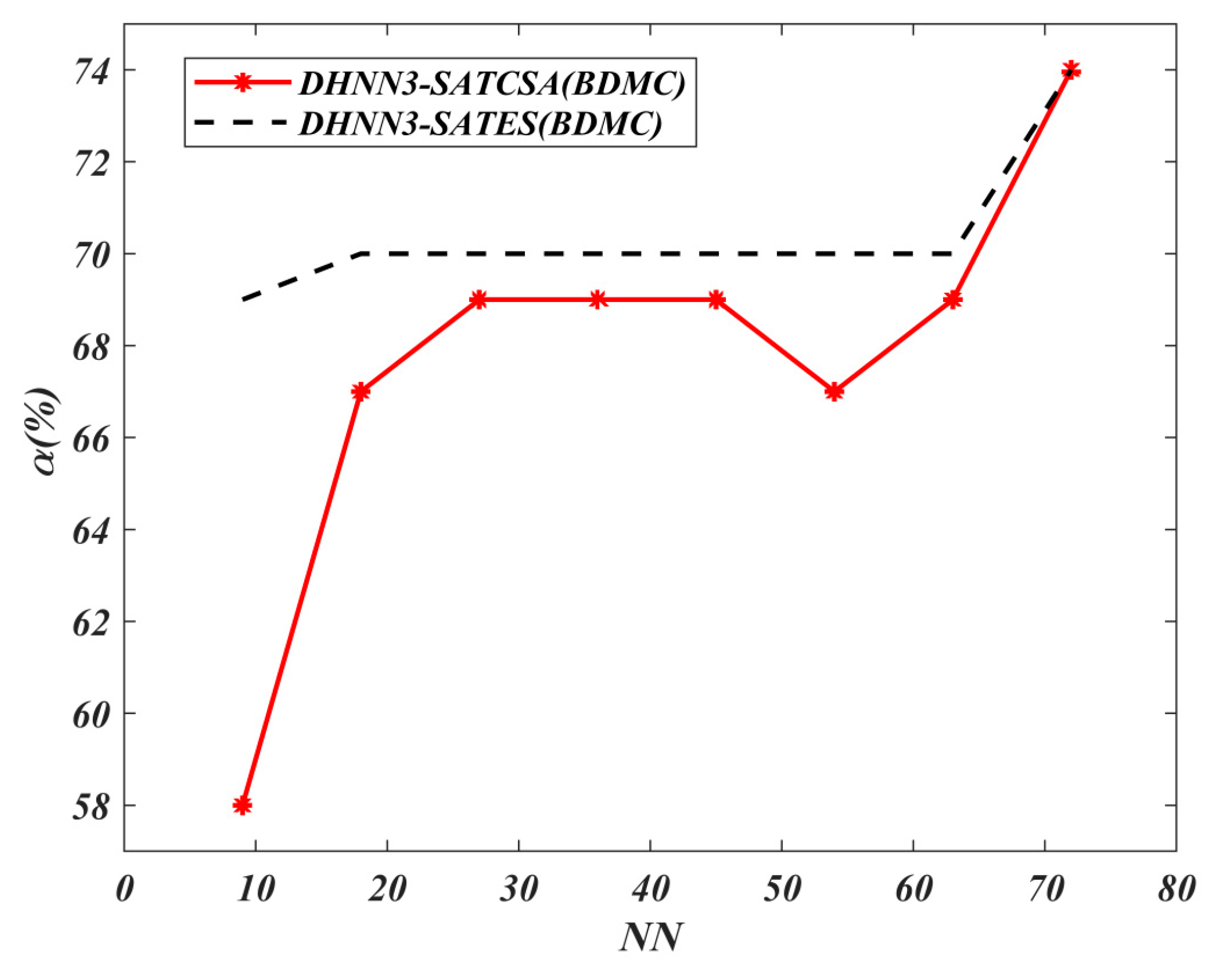
62], the proposed performance metrics in this experiment are mean absolute error (MAE), sum of square error (SSE), global minima ratio
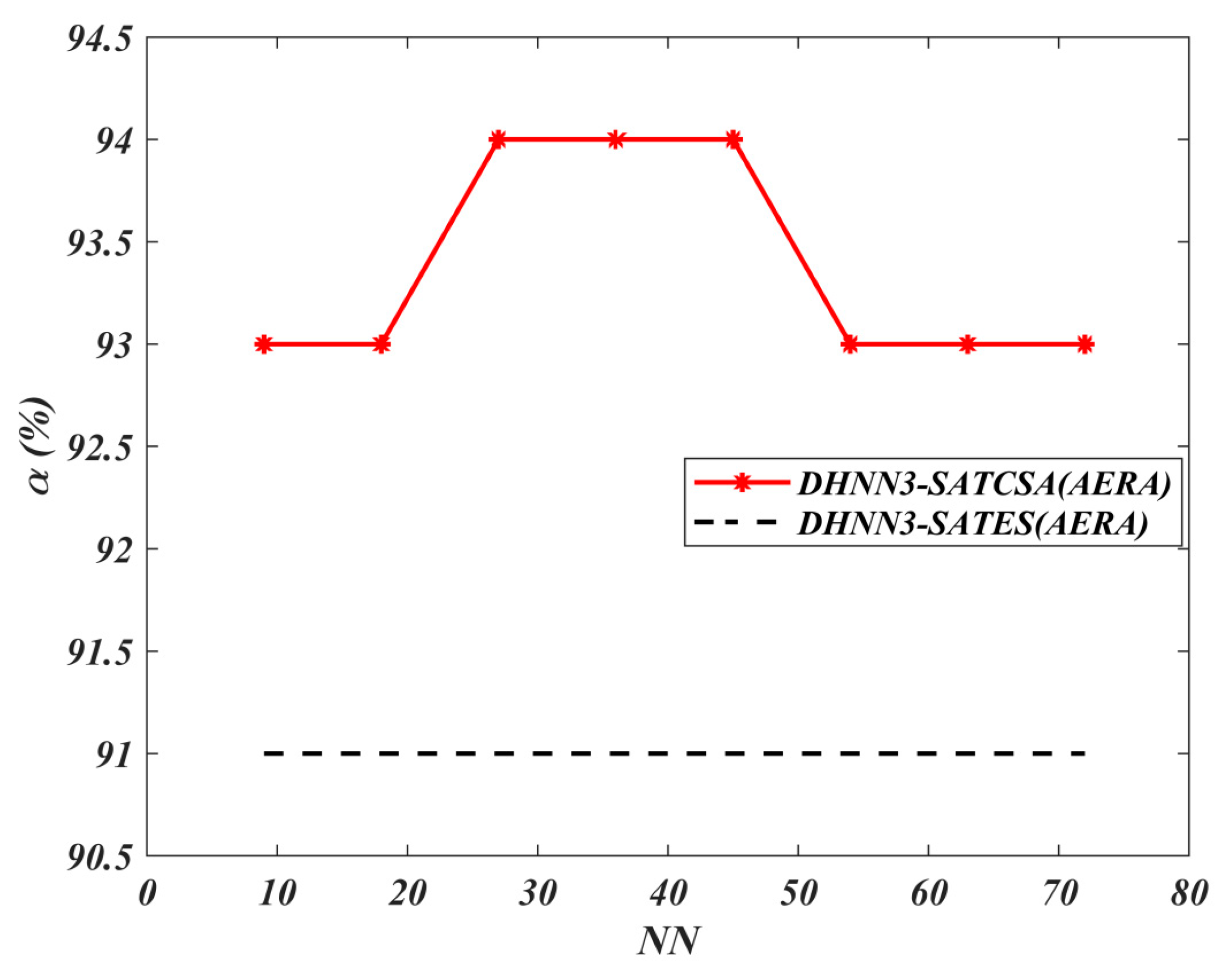
, accuracy in percentage
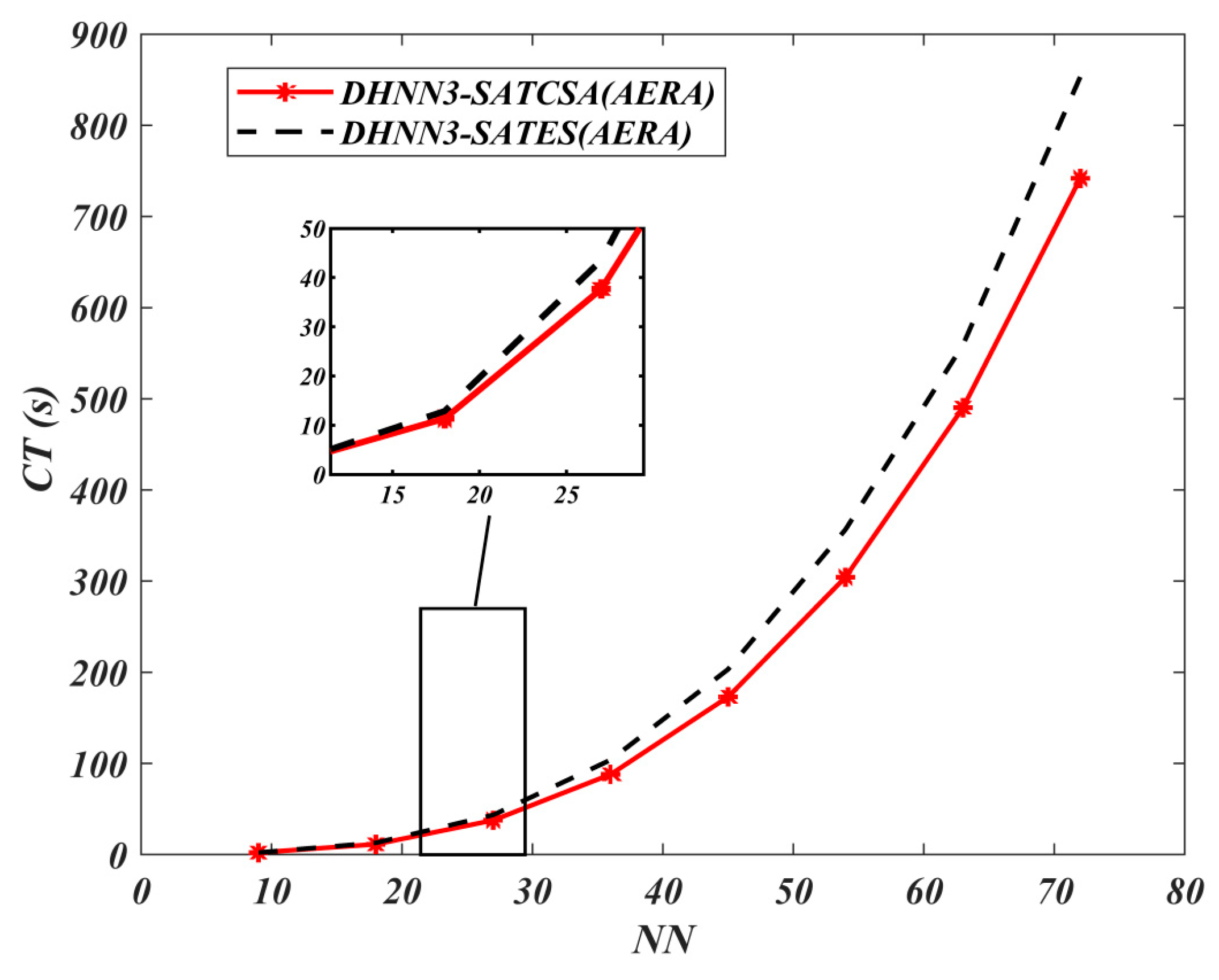
and computational time in SI unit of second
. According to [
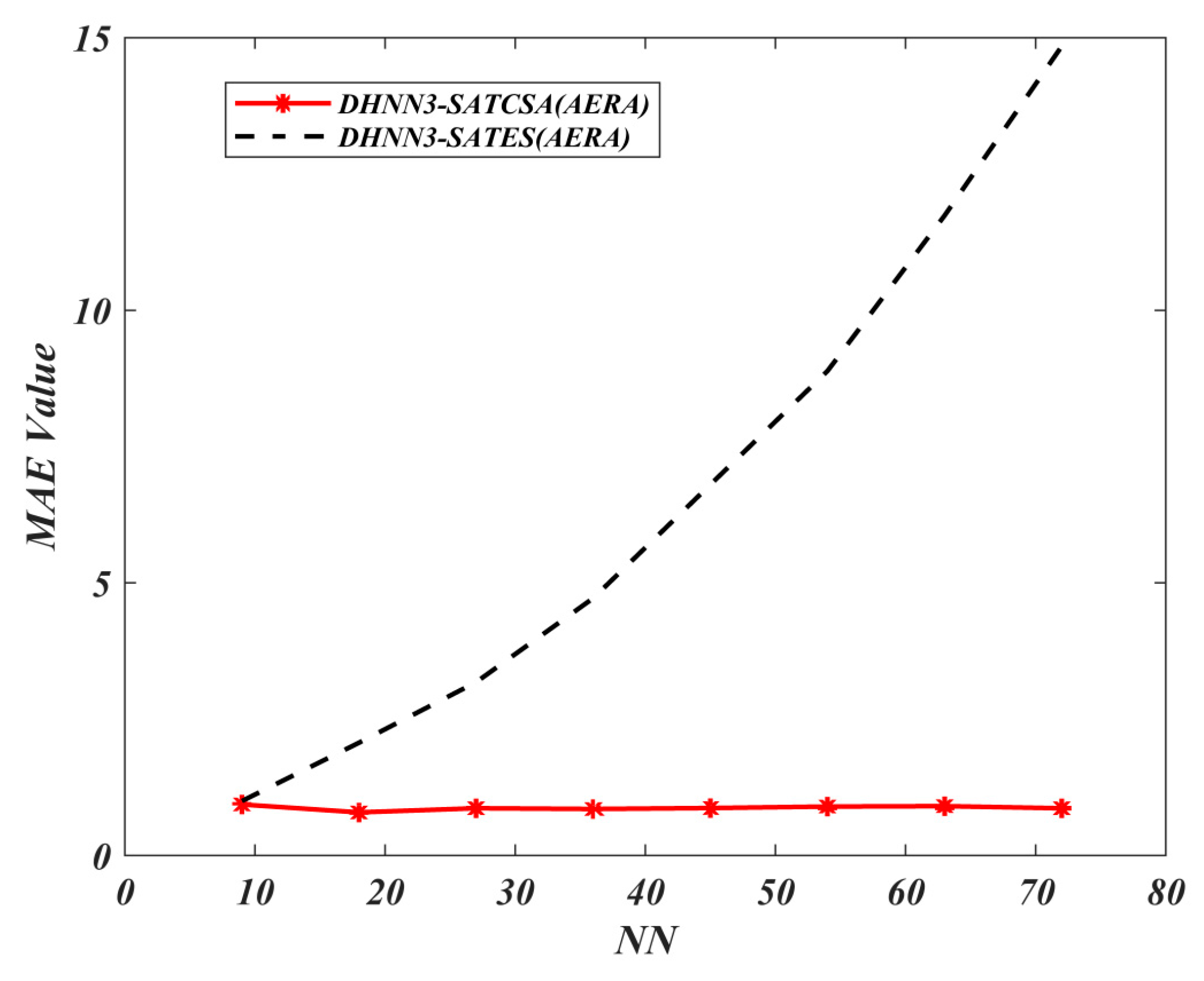
63], MAE computes the average absolute error of the fitness during the learning phase in our proposed model. The formulation of MAE is as follows:
where
and
are the total number of clauses and the number of satisfied clauses in
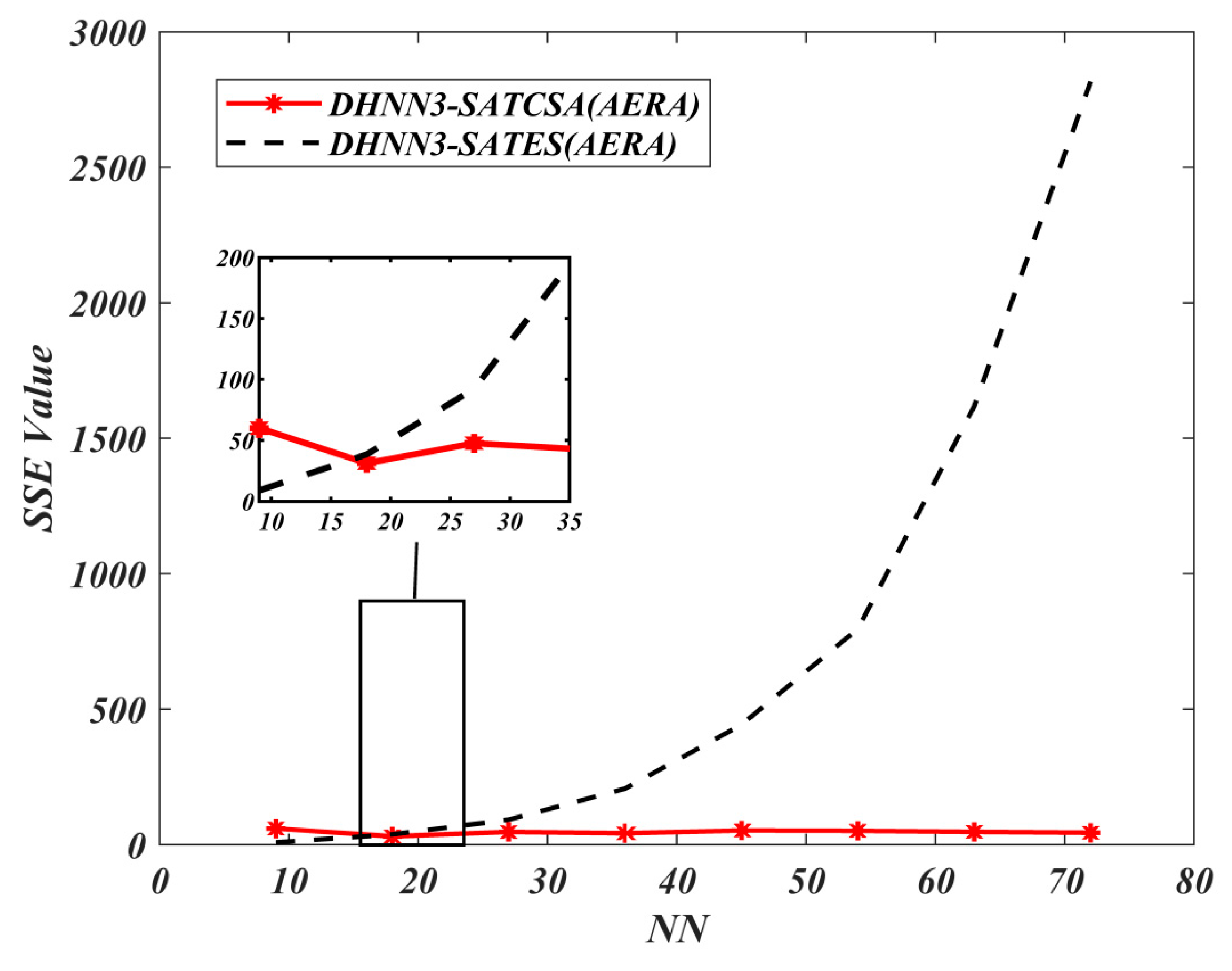
respectively. In relation to Equation (21), the accumulation of errors in each model can be also effectively evaluated by using SSE. The formulation of SSE is described by the following equation:
On the other hand, we examine the final neuron states of the proposed model via
.
According to [
52], if the final neuron states of the proposed model is
, the model will prone to
. Hence, the best model will attain the lowest value of MAE and SSE with
. Notably,
indicates
where
and
are number of trials and neuron combinations, respectively. In another development, we utilize the value of
and
to investigate the effectiveness and efficiency of 3-SATRA in the testing phase of DHNN3-SATCSA. We describe two formulations:
Note that
if
, where
in our case is depicted by
of instances in a data set. In practice, the best model requires
and the minimum value of
. Learning time and retrieval time are denoted as total time executed by DHNN3-SAT models in the learning phase and retrieval phase respectively.
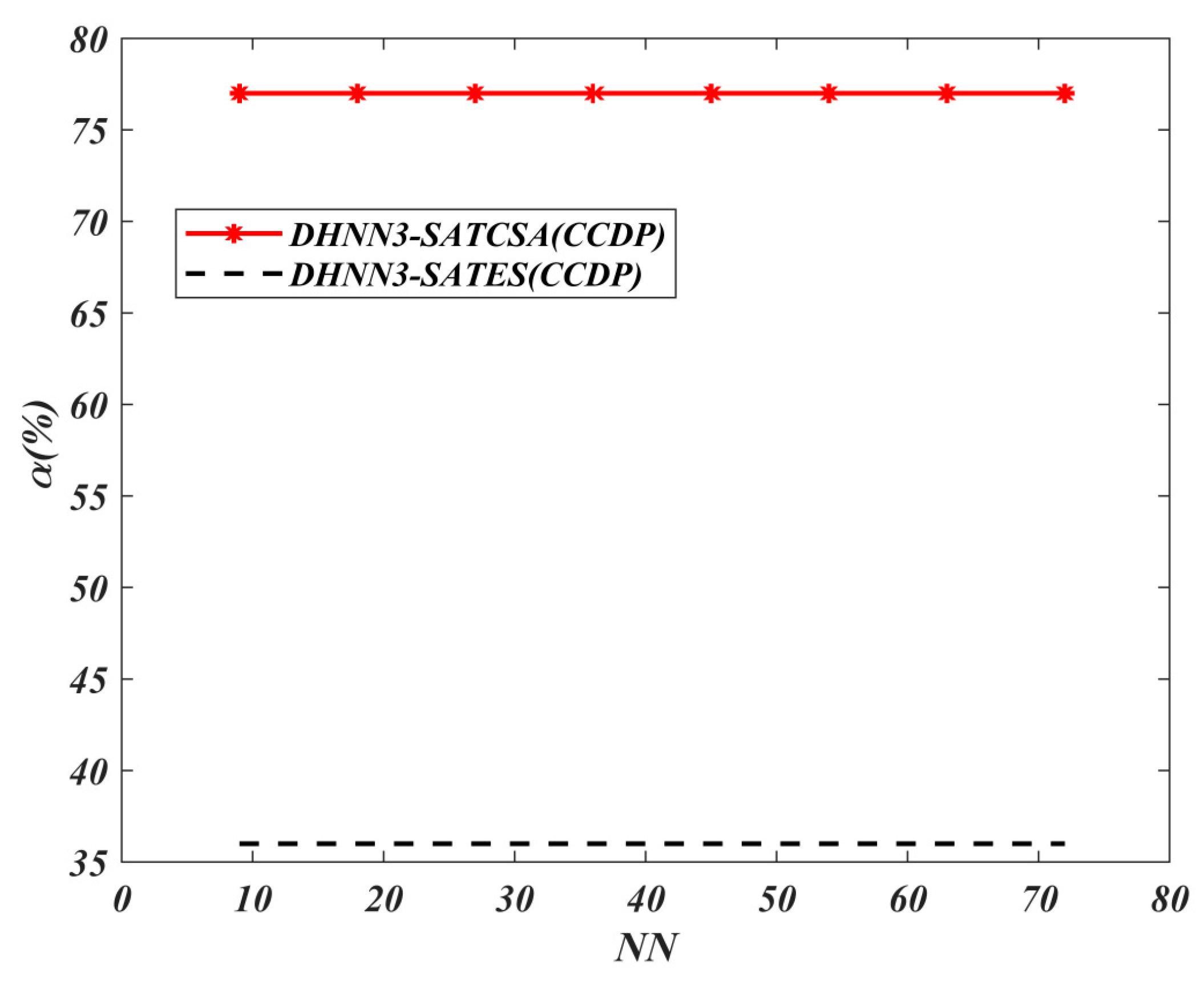
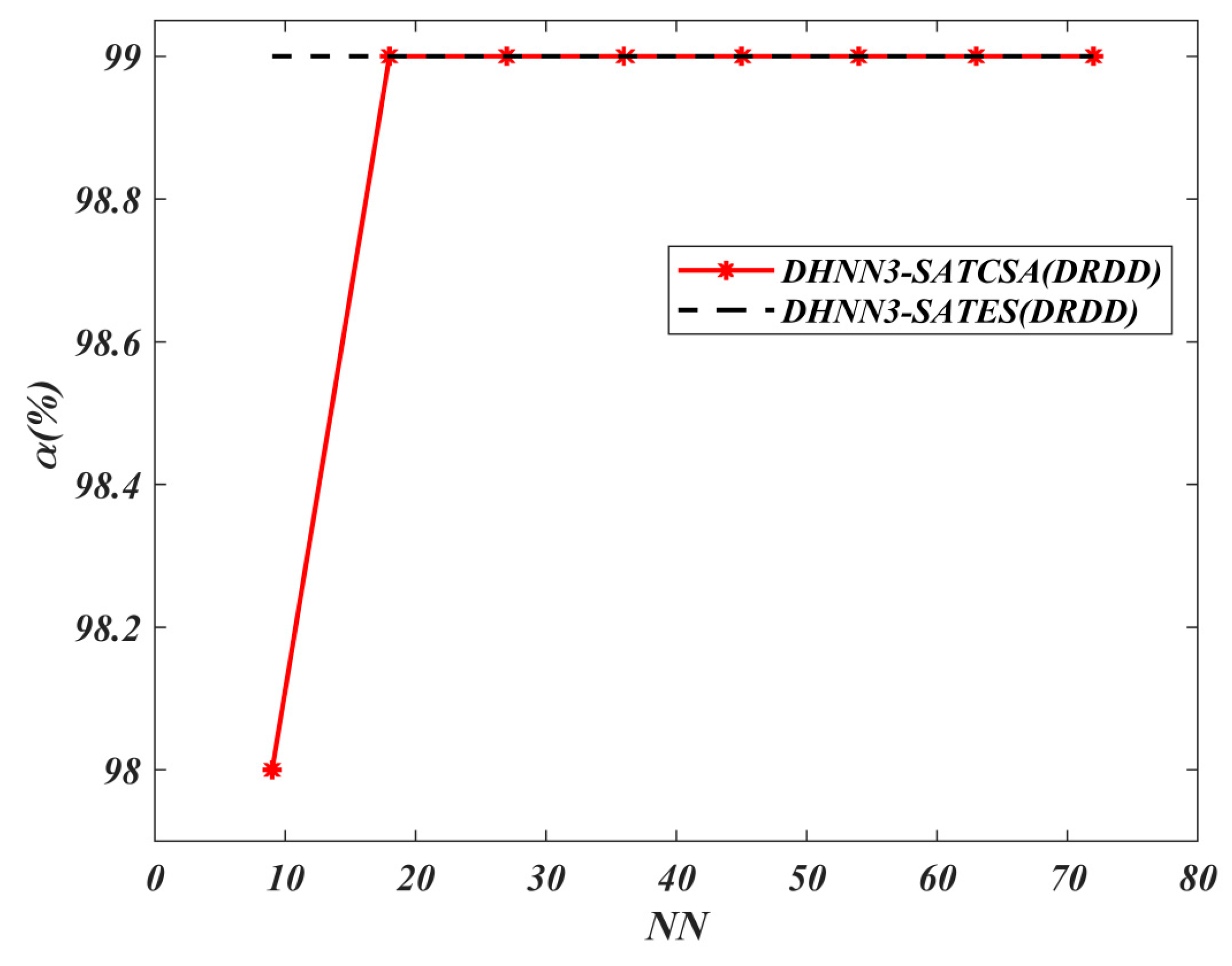
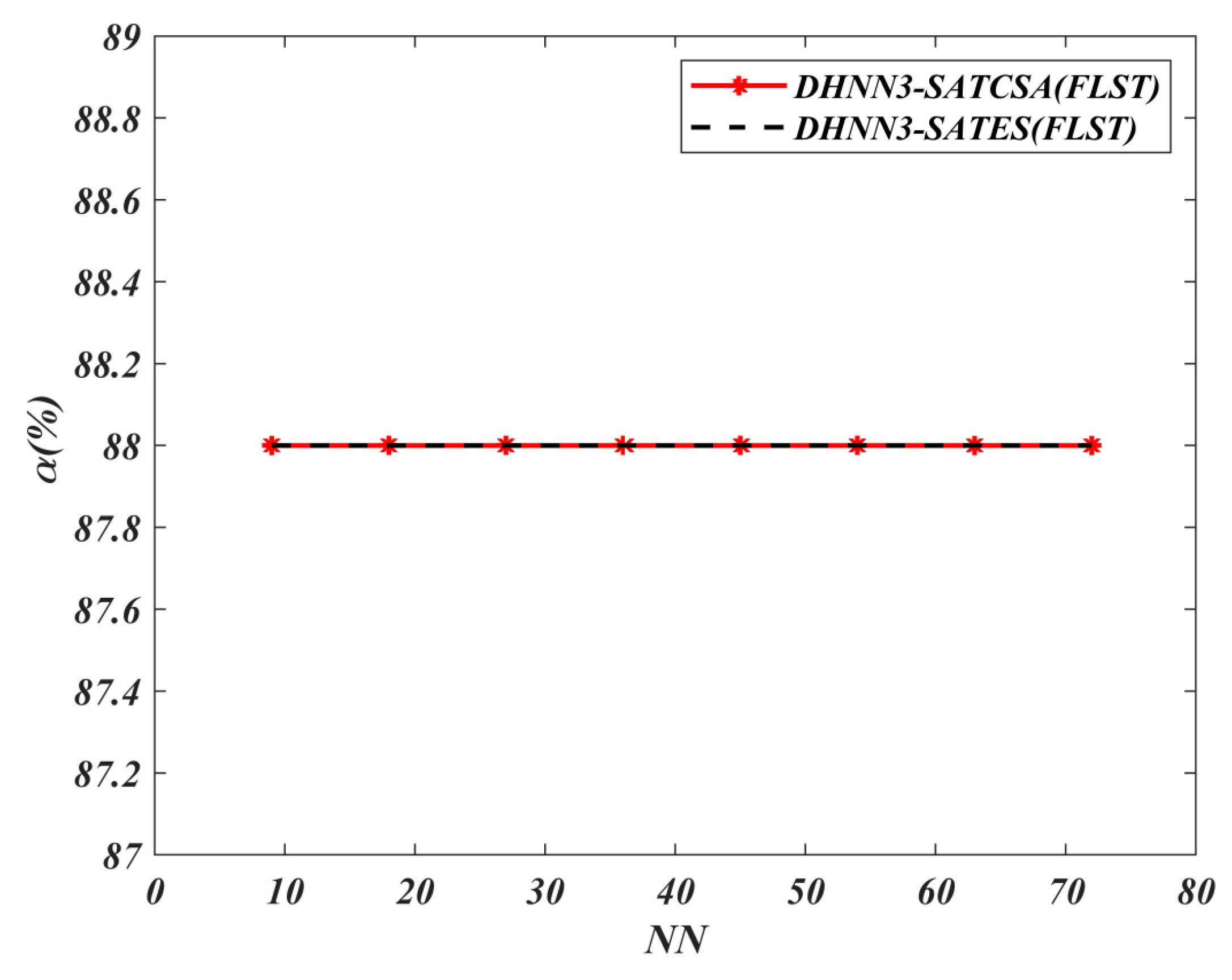
Table 2 and
Table 3 discuss the parameters involved in hybrid Hopfield Neural Network with Exhaustive Search (DHNN3-SATES) and hybrid model with Clonal Selection Algorithm (DHNN3-SATCSA) respectively.
The choice of
is important as a large population size requires a large searching space of the solutions, which may increase the computational cost. On the other hand, a small
can lead to local minima solutions. According to [
64], we should choose
as it is repeated to achieve a good result. The general implementation of the proposed model in a simulated data set can be summarized in
Figure 4. 3-SATRA is implemented to show the level of connectedness between
and neurons. Overall, simulated and real-life data sets will be implemented into DHNN3-SATCSA. The computational simulation for both data sets was conducted on Dev C++ Version 5.11 for Windows 7 in 2GB RAM with Intel Core I3. As for the simulated data set, the Dev C++ program will generate the initial bipolar data randomly. Throughout the simulations, the same device is being used to avoid any biases. On the whole, all simulations are utilized with different number of neurons (
), which is within the bound of not exceeding the threshold time of 24 h [
35]. Note that the proposed model will randomly select nine attributes for the real-life data set as well as their arrangements in
logical rule.

 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}