Storage Space Allocation Strategy for Digital Data with Message Importance


1
Department of Electronic Engineering, Tsinghua University, Beijing 100084, China
2
Beijing National Research Center for Information Science and Technology (BNRist), Beijing 100084, China
*
Author to whom correspondence should be addressed.
Entropy 2020, 22(5), 591; https://doi.org/10.3390/e22050591
Submission received: 29 April 2020
/
Accepted: 19 May 2020
/
Published: 25 May 2020
(This article belongs to the Special Issue Entropy Measures for Data Analysis II: Theory, Algorithms and Applications)
Abstract
:This paper mainly focuses on the problem of lossy compression storage based on the data value that represents the subjective assessment of users when the storage size is still not enough after the conventional lossless data compression. To this end, we transform this problem to an optimization, which pursues the least importance-weighted reconstruction error in data reconstruction within limited total storage size, where the importance is adopted to characterize the data value from the viewpoint of users. Based on it, this paper puts forward an optimal allocation strategy in the storage of digital data by the exponential distortion measurement, which can make rational use of all the storage space. In fact, the theoretical results show that it is a kind of restrictive water-filling. It also characterizes the trade-off between the relative weighted reconstruction error and the available storage size. Consequently, if a relatively small part of total data value is allowed to lose, this strategy will improve the performance of data compression. Furthermore, this paper also presents that both the users’ preferences and the special characteristics of data distribution can trigger the small-probability event scenarios where only a fraction of data can cover the vast majority of users’ interests. Whether it is for one of the reasons above, the data with highly clustered message importance is beneficial to compression storage. In contrast, from the perspective of optimal storage space allocation based on data value, the data with a uniform information distribution is incompressible, which is consistent with that in the information theory.
1. Introduction
As large amounts of mobile devices such as Internet of things (IoT) devices or smartphones are utilized, the contradiction between limited storage space and sharply increasing data deluge becomes increasingly serious in the era of big data [1,2]. This exceedingly massive data makes the conventional data storage mechanisms inadequate within a tolerable time, and therefore the data storage is one of the major challenges in big data [3]. Note that storing all the data becomes more and more dispensable nowadays, and it is also not conducive to reduce data transmission costs [4,5]. In fact, data compression storage is widely adopted in many applications, such as IoT [2], industrial data platform [6], bioinformatics [7], wireless networking [8]. Thus, the research on data compression storage becomes increasingly paramount and compelling nowadays.
In conventional source coding, data compression is carried out by removing the data redundancy, where short descriptions are assigned to the most frequent class [9]. Based on it, the tight bounds for lossless data compression are given. In order to further increase the compression rate, one needs to use more information. A quintessential example is to use some side information [10]. Another possible solution is to compress the data with quite a few losses first and then reconstruct them with acceptable distortion, which is referred to as lossy compression [11,12,13]. Some adaptive compressions are adopted extensively. For example, Reference [14] proposed an adaptive compression scheme in IoT systems, and Reference [15] investigated the backlog-adaptive source coding system in terms of age of information. In fact, most of the previous compression methods usually carried out compression by means of contextual data or leveraging data transformation techniques [4].
Although these previous methods of data compression perform satisfactorily in their respective application scenarios, there is still much room for improvement when facing rapidly growing large-scale data. Moreover, they also do not take the data value into account. This paper focuses on the problem of how to further compress data with acceptable distortion to implement the specified requirements in data storage when the storage size is still not enough to guarantee the lossless storage after the conventional lossless data compression. This paper will realize this goal by reallocating storage space based on the data value which represents the subjective assessment of users. Here, we take the importance-aware weighting in the weighted reconstruction error to measure the total cost in data storage with unequal costs.
Generally, users prefer to care about the crucial part of data that attracts their attention rather than the whole data itself. In many real-world applications, such as cost-sensitive learning [16,17,18] and unequal error protection [19,20], different errors bring different costs. To be specific, the distortion in the data that users care about may be catastrophic if the loss of some data being insignificant for users is allowed. Similar to coresets [21], the data needing to be processed was reduced to those users as the main focus rather than the whole data set. Unlike coresets, the data needing to be processed in this paper no longer pursues approximately representing the raw data, and it is expected to minimize the storage cost with respect to the importance weighting value. In fact, although the data deluge sharply increases, the significant data that users care about is still rare in a lot of scenarios of big data. In this sense, it can be regarded as the sparse representation from the perspective of the data value, and we can use it to compress data.
Alternatively, it is interesting to achieve data compression by storing a fraction of data, which preserves as much information as possible regarding the data that users care about [22,23]. This paper also employs this strategy. However, there are subtle but critical differences between the compression storage strategy proposed in this paper with those in Reference [22,23]. In fact, Reference [22] focused on Pareto-optimal data compression, which presents the trade-off between retained entropy and class information. However, this paper puts forward an optimal compression storage strategy for digital data from the viewpoint of message importance, and it gives the trade-off between the relative weighted reconstruction error (RWRE) and the available storage size. Furthermore, the compression method based on message importance was preliminarily discussed in Reference [23] to solve the big data storage problem in wireless communications, while this paper will aim to discuss the optimal storage space allocation strategy with limited storage space, in general, based on message importance. Moreover, the constraints are also different. That is, the available storage size is limited in this paper, while the total code length of all the events is given in Reference [23].
From users’ attention viewpoint, the data value can be considered as the subjective assessment of users on the importance of data. Actually, much of the research in the last decade suggested that the study from the perspective of message importance is rewarding to obtain new findings [20,24,25]. Thus, there may be effective performance improvement in storage systems when taking message importance into account. For example, Reference [26] discussed the lossy image compression method with the aid of a content-weighted importance map. Since any quantity can be seen as important if it agrees with the intuitive characterization of the user’s subjective degree of concern of data, the cost in data reconstruction for specific user preferences is regarded as the importance in this paper, which will be used as the weight in the weighted reconstruction error.
Since we desire to achieve data compression by keeping only a small portion of important data and abandoning less important data, this paper mainly focuses on the case where only a fraction of data take up the vast majority of the users’ interests. Actually, these scenarios are not rare in big data. A quintessential example should be cited that the minority subset detection is overwhelmingly paramount in intrusion detection [27,28]. Moreover, this phenomenon is also exceedingly typical in financial crime detection systems for the fact that only a few illicit identities catch our eyes to prevent financial frauds [29]. Actually, when a certain degree of information loss can be acceptable, people prefer to take high-probability events for granted and abandon them to maximize the compressibility. These cases are referred to as small-probability event scenarios in this paper. In order to depict the message importance in small-probability event scenarios, message importance measure (MIM) was proposed in Reference [30]. Furthermore, MIM is fairly effective in many applications of big data, such as IoT [31], mobile edge computing [32]. In addition, Reference [33] expanded MIM to the general case, and it presented that MIM can be adopted as a special weight in designing the recommendation system. Since there is no universal data value model, we might as well take the case where the MIM describes the cost of the error as a quintessential example to analyze the property of the optimal storage space allocation strategy.
In this paper, we firstly propose a particular storage space allocation strategy for digital data on the best effort in minimizing the importance-weighted reconstruction error when the total available storage size is provided. For digital data, we formulate this problem as an optimization problem, and present the optimal storage strategy by means of a kind of restrictive water-filling. For the given available storage size, the storage size is mainly determined by the values of message importance and probability distribution of event class in a data sequence. In fact, this optimal allocation strategy adaptively prefers to provide more storage size for crucial data classes in order to make the rational use of resources, which is in accord with the cognitive mechanism of human beings.
Afterward, we focus on the properties of this optimal storage space allocation strategy when the importance weights are characterized by MIM. It is noted that there is a trade-off between the RWRE and the available storage size. The constraints on the performance of this storage system are true, and they depend on the importance coefficient and the probability distribution of events classes. On the one hand, the RWRE increases with the increasing of the absolute value of importance coefficient for the fact that the overwhelming majority of important information will gather in a fraction of data as the importance coefficient increases to negative/positive infinity, which suggests the influence of users’ preferences. On the other hand, the compression performance is also affected by probability distribution of event classes. In fact, the more closely the probability distribution matches the requirement of the small-probability event scenarios, the more effective this compression strategy becomes. Furthermore, it is also obtained that the RWRE in a uniform distribution is larger than any other distributions for the same available storage size. In this regard, the uniform distribution is incompressible from the perspective of optimal storage space allocation based on data value, which is consistent with the conclusion in information theory [34].
The main contributions of this paper can be summarized as follows. (1) It proposes a new digital data compression strategy taking message importance into account, which can help improve the design of a big data storage system. (2) We illuminate the properties of this new method, which can characterize the trade-off between the RWRE and the available storage size. (3) It shows that the data with highly clustered message importance is beneficial to compression storage, and it also finds that the data with a uniform information distribution is incompressible from the perspective of optimal storage space allocation based on data value, which is consistent with that in information theory.
The rest of this paper is organized as follows. The system model is introduced in Section 2, including the definition of weighted reconstruction error, distortion measure, and problem formulation. In Section 3, we solve the problem of optimal storage space allocation in three kinds of system models and give the solutions. The properties of this optimal storage space allocation strategy based on MIM are fully discussed in Section 4. The effects of the importance coefficient and the probability of event classes on RWRE are also investigated in detail. Section 5 illuminates the properties of this optimal storage strategy when the importance weight is characterized by Non-parametric MIM. The numerical results are shown and discussed in Section 6, which verifies the validity of the developed theoretical results in this paper. Finally, we give the conclusion in Section 7.
2. System Model
This section introduces the system model, including the definition of the weighted reconstruction error, the modeling of distortion measure, in order to illustrate how we formulate the lossy compression problem as an optimization problem for digital data based on message importance. In order to make the formulation and discussion more clear, the main notations in this paper are listed in Table 1.
2.1. Modeling Weighted Reconstruction Error Based on Message Importance
The data storage system may lack storage space frequently when facing a super-large scale of data to store. When the storage size is still not enough after the lossless conventional data compression, the optimum allocation of storage space based on data value may be imperative. For this purpose, we consider the following storage system, which stores K pieces of data. Let be the sequence of raw data. Assume that all the data redundancy have been removed after the lossless conventional data compression, and each data needs to take up storage space with size of if this data can be recovered without any distortion. However, in many scenarios of big data, the storage size is still not enough in this case. That is to say, the actual required storage space is larger than the maximum available storage space , where T is the maximum available average storage size.
In fact, users prefer to care about the paramount part of data that attracts their attention rather than the whole data itself. In this perspective, storing all data without distortion may be unnecessary. Considering that the natural distribution of storage space is not invariably reasonable and the high value data in big data is usually sparse, the rational storage space allocation by minimizing the loss of data value may solve the above problem of insufficient storage space, if a certain amount of data value is allowed to be lost. After the data compression by means of the rational storage space allocation, we use to denote the compressed data sequence, and assume that the compressed data takes up storage space with size of in practice for .
The lossy data compression usually pursues the least the storage cost while retaining as much information users required as possible [22]. In the lossless conventional data compression, the costs of different data are assumed to be the same. However, different kinds of errors may result in unequal costs in many real-world applications [16,17,18,19]. In this model, we use the notation to denote the error cost for the reconstructed data. Namely, is with respect to the data value of data , and it is regarded as the message importance in this paper. Here, we define the weighted reconstruction error to describe the total cost in data storage with unequal costs, which is given by
where characterizes the distortion between the raw data and the compressed data in data reconstruction, which characterizes the loss degree of data value with allocated storage size.
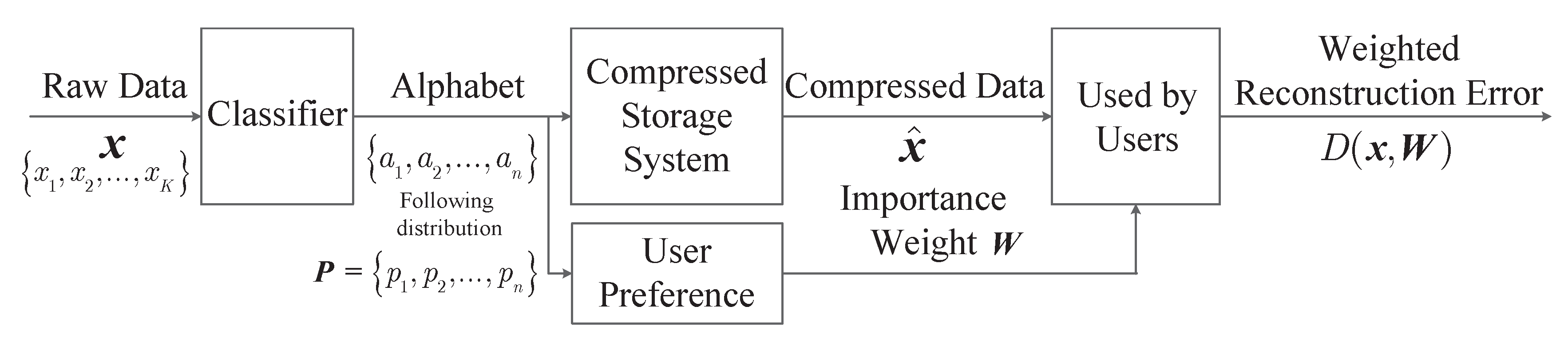
Consider the situation where the data is stored according to its category for easier retrieval, which can also make the recommendation system based on it more effective [33]. Since data classification is becoming increasingly convenient and accurate nowadays due to the rapid development of machine learning [35,36], this paper assumes that the event class can be easily detected and known in the storage system. Moreover, assume the data that belongs to the same class has the same importance-weight and occupies the same storage size. Hence, can be seen as a sequence of K symbols from an alphabet where represents event class i. This storage model is summarized and shown in Figure 1. In this case, the weighted reconstruction error based on importance is formulated as
where is the number of times the i-class occurs in the sequence . Let denote the probability of event class i in data sequence .
2.2. Modeling Distortion between the Raw Data and the Compressed Data
We focus on the formula of in this part, which characterizes the distortion between the raw data and the compressed data with specified storage size. Usually, there is no universal characterization of distortion measure, especially in speech coding and image coding [34]. In fact, should characterize the loss degree of data value with allocated storage size. In this respect, the conventional distortion measures are not appropriate since they do not take unequal costs into account. In order to facilitate the analysis and design, this paper proposes an exponential distortion measure to discuss the following special case.
We assume that the data is digital and ignore the storage formats and standards in concrete application environments. On its application fields, it may be useful in some scenarios with counting systems, such as finance, or medicine, as the general merchandise. Let the description of the raw data be bits, and where r is radix (). Actually, the radix represents the base of the system in practical application, such as in a binary system. In particular, will approach the infinite number if is an arbitrary real number. When the storage size is still not enough after the lossless conventional data compression, there is only bits assigned to it in order to compress data further based on the message importance. For convenience, the smaller numbers are discarded in this process. When restoring the compressed data, the discarded digits are set to the same pre-specified number or random numbers in the actual system. Let be the -th discarded digit for , and assume that is a random number in . In this case, the compressed data is . As a result, the absolute error is , which meets
When , which means there is no information stored, the supremum of absolute error reaches the maximum and it is . In order to better weigh the different costs, we define the relative error by normalizing the absolute error to the interval based on the above maximum absolute error . Moreover, we adopt the supremum of this relative error as the distortion measure , which is given by
In particular, we obtain and . Moreover, it is easy to check that and decreases with the increasing of . In fact, can be regarded as the percentage of data value loss in this case. Thus, the weighted reconstruction error in Equation (1) represents the total cost in data storage based on the loss degree.
In this stored procedure, the compression rate is , and the total saving storage size is . Actually, K denotes the number of data, and it is extremely big due to the sharply increasing data deluge in the era of big data. Therefore, although is not always large, the saving storage size is still exceedingly substantial since K is exceedingly large.
Furthermore, to simplify the comparisons under different conditions, the weighted reconstruction error is also normalized to the relative weighted reconstruction error (RWRE). In fact, the RWRE characterizes the relative total cost in the data compression, and it is given by
where and .
2.3. Problem Formulation
2.3.1. General Storage System
In fact, the actual storage size of each data after the compression can then be expressed as . For each given maximum available storage space constraint , where T denotes the maximum available average storage size, we shall optimize the storage resources allocation strategy of this system by minimizing the RWRE, which can be expressed as
The storage systems, which can be characterized by Problem , are referred to as the general storage system.
Remark 1.
In fact, this paper focuses on allocating resources by category with taking message importance into account, while the conventional source coding searches the shortest average description length of a random variable.
2.3.2. Ideal Storage System
In practice, the storage size of raw data is usually assigned to be the same for ease of use. Thus, we mainly consider the case where the original storage size of each data is the same, and use L to denote it (i.e., for ). As a result, we have
Thus, the problem can be rewritten as
For convenience, we use the ideal storage system to represent the storage systems, which can be described by Problem . Moreover, we will mainly focus on the characteristics of the solutions in Problem in this paper.
2.3.3. Quantification Storage System
A quantification storage system quantizes and stores the real data acquired from sensors in the real world. The data is usually a real number, which requires an infinite number of bits to describe it accurately. That is, the original storage size of each class approaches the infinite number, (i.e., for ), in this case. As a result, the RWRE can be rewritten as
Therefore, the problem in this case is reduced to
3. Optimal Allocation Strategy with Limited Storage Space
In this section, we shall first solve the problem and give the solutions. In fact, the solutions provide the optimal storage space allocation strategy for digital data on the best effort in minimizing the relative weighted reconstruction error (RWRE) when the total available storage size is limited. Then, the problem will be solved, the solutions of which characterize the optimal storage space allocation strategy with the same original storage size. Moreover, we shall also discuss the solutions in the case where the original storage size of each class approaches the infinite number by studying the problem .
3.1. Optimal Allocation Strategy in General Storage System
Theorem 1.
For a storage system with probability distribution , is the storage size of the raw data of the class i for . For a given maximum available average storage size T (), when the radix is r (), the solution of Problem is given by
where is chosen so that .
Proof.
By means of Lagrange multipliers and Karush–Kuhn–Tucher conditions, when ignoring the constant , we set up the functional
Differentiating with respect to and setting the derivative to zero, we have
Hence, we obtain
First, it is easy to check that Equations (13b)–(13d) hold when and . Hence, we have
Second, if in Equation (14) is larger than , we will have and due to Equations (13b)–(13d).
Third, if , we will let according to Equation (13e).
Moreover, is chosen so that due to Equation (13a).
Therefore, based on the discussion above, we get Equation (11) in order to ensure . □
Remark 2.
Let be the number of which meets and is part of the sequence of which satisfies . Furthermore, is used to denote the part of the sequence of which satisfies .
Substituting Equation (11) in the constraint , we have
Hence, for , we obtain
In fact, T, , r, are usually constraints for a given storage system, and therefore is only determined by the second and the third items on the right side of Equation (17), which means the storage size depends on the message importance and the probability distribution of class for the given available storage size.
Remark 3.
Since the actual compressed storage size must be an integer, the actual storage size allocation strategy is
where is equal to x when , and it is zero when . In addition, is the largest integer smaller than or equal to x.
3.2. Optimal Allocation Strategy in Ideal Storage System
Then, we pay attention to the case where the original storage size of each data is the same. Based on Theorem 1, we get the following corollary in the ideal storage system.
Corollary 1.
For a storage system with probability distribution , the original storage size of each class is the same, which is given by for . For a given maximum available average storage size T (), when the radix is r (), the solution of Problem is given by
where λ is chosen so that .
Proof.
Substituting Equation (19) in the constraint , we obtain
where , , , is still given by Remark 2 with letting . In addition, . Hence, for , we obtain
Remark 4.
Since the actual compressed storage size must be an integer, the actual storage size allocation strategy is
Remark 5.
When , always holds for , and the actual storage size is given by
In order to illustrate the geometric interpretation of this algorithm, let
Hence, the optimal storage size can be simplified to
The monotonicity of optimal storage size with respect to importance weight is discussed in the following theorem.
Theorem 2.
Let be a probability distribution and be importance weights. L and r are fixed positive integers (). The solution of Problem meets: if for .
Proof.
Refer to the Appendix A. □
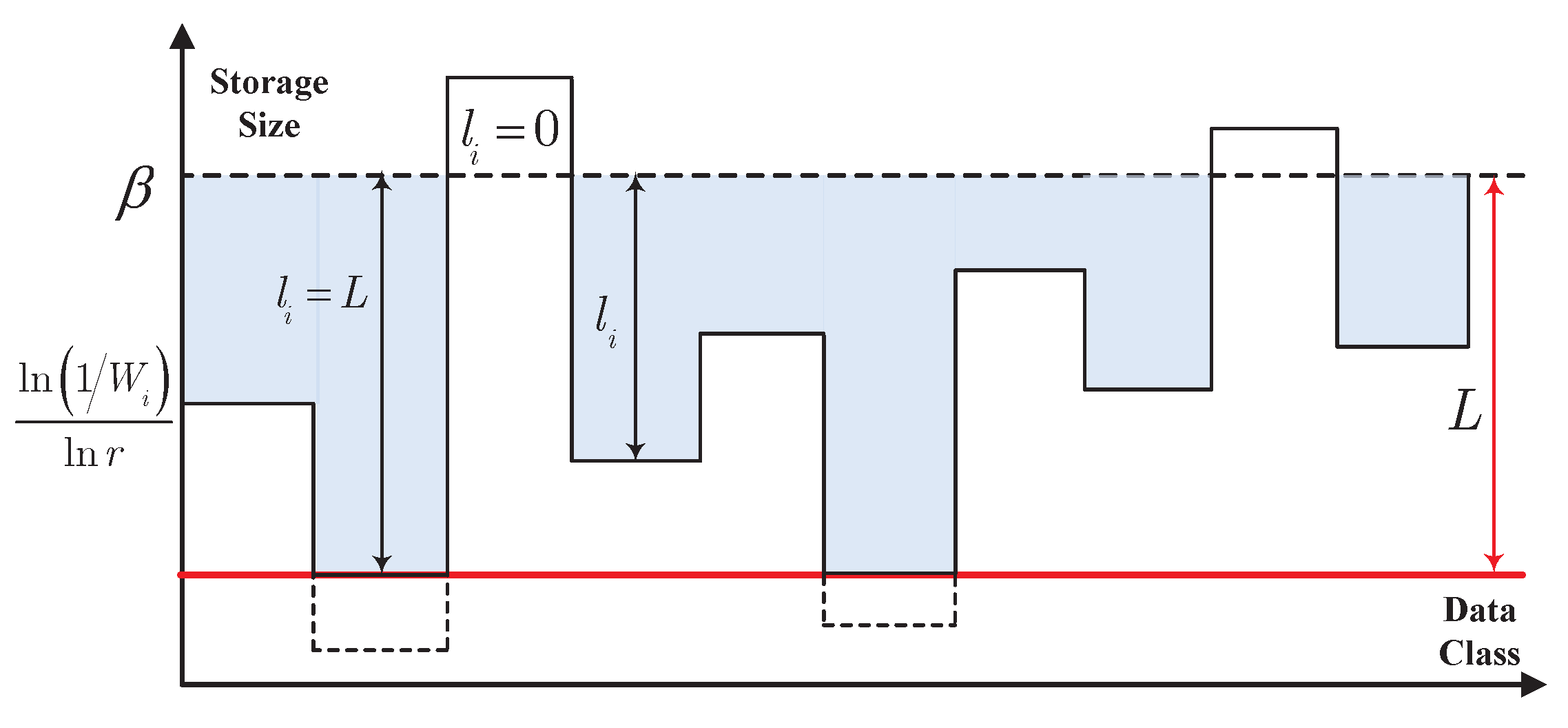
This gives rise to a kind of restrictive water-filling, which is presented in Figure 2. Choose a constant so that . The storage size depends on the difference between and . In Figure 2, we obtain that characterizes the height of water surface, and determines the bottom of the pool. Actually, no storage space is assigned to the data when this difference is less than zero. When the difference is in the interval , this difference is exactly the storage size. Furthermore, the storage size will be truncated to L bits if the difference is larger than L. Compared with the conventional water-filling, the lowest height of the bottom of the pool is constricted in this restrictive water-filling.
Remark 6.
The restrictive water-filling in Figure 2 is summarized as follows.
- For the data with extremely small message importance, is so large that the bottom of the pool is above the water surface. Thus, the storage size of this kind of data is zero.
- For the data with small message importance, is large, and therefore the bottom of the pool is high. Thus, the storage size of this kind of data is small.
- For the data with large message importance, is small, and therefore the bottom of the pool is low. Thus, the storage size of this kind of data is large.
- For the data with extremely large message importance, is so small that the bottom of the pool is constricted in order to truncate the storage size to L.
Thus, this optimal storage space allocation strategy is a high efficient adaptive storage allocation algorithm for the fact that it can make rational use of all the storage space according to message importance to minimize the RWRE.
This solution can be gotten by means of the recursive algorithm in practice, which is shown in Algorithm 1, where we define an auxiliary function as
3.3. Optimal Allocation Strategy in Quantification Storage System
Corollary 2.
For a given maximum available average storage size T (), when probability distribution is and the radix is r (), the solution of Problem is given by
where λ is chosen so that .
In fact, the optimal storage space allocation strategy in this case can be seen as a kind of water-filling, which gets rid of the constraint on the lowest height of the bottom of the pool.
| Algorithm 1 Storage Space Allocation Algorithm |
| Require: |
| The message importance, (Sort it to satisfy ) |
| The probability distribution of source, |
| The original storage size, L and |
| The maximum available average storage size, T |
| The radix, r |
| The auxiliary variables, (Let as the original values) |
| Ensure: |
| The compressed storage size, |
| Denote this recursive algorithm as |
|
4. Property of Optimal Storage Strategy Based on Message Importance Measure
Considering that the ideal storage system can capture most of the characteristics of the lossy compression storage model in this paper, we focus on the properties of optimal storage strategy in it in this section for ease of analysis. Specifically, we ignore rounding and adopt in Equation (19) as the optimal storage size of the i-th class in this section. Moreover, we focus on a special kind of the importance weight. Namely, the message importance measure (MIM) is adopted as the importance weight in this part, for the fact that it can effectively measure the cost of the error in data reconstruction in the small-probability event scenarios [23,31].
4.1. Normalized Message Importance Measure
In order to facilitate comparison under different parameters, the normalized MIM is used and we can write
where is the importance coefficient, whose selection is discussed in Reference [37]. In fact, the MIM characterizes the user’s subjective concern degree of data, and is an indicator that reflects the user preferences. In practice, the values of depend on the user preferences. For instance, when is positive, the user only focuses on the small-probability events, while the large-probability events are focused on when is negative [33].
Actually, it is easy to check that for . Moreover, it is obvious that the sum of those in all event classes is one.
4.1.1. Positive Importance Coefficient
For positive importance coefficient (i.e., ), let and assume for . The derivative of it with respect to the importance coefficient is
Therefore, increases as increases. In particular, as approaches positive infinity, we have
Obviously, for .
Remark 7.
As ϖ approaches positive infinity, the importance weight with the smallest probability is one and others are all zero, which means only a fraction of data almost contains all of the critical information that users care about in the viewpoint of this message importance.
4.1.2. Negative Importance Coefficient
When the importance coefficient is negative (i.e., ), let and assume for . Its derivative with respect to the importance coefficient is
Therefore, decreases as increases. In particular, as approaches negative infinity, we have
Obviously, for .
Remark 8.
As ϖ approaches negative infinity, the importance weight with the biggest probability is one and others are all zero. If the biggest probability is far from 1, the majority of message importance can also be included in those data with the highest probability, and the corresponding part of the data is not too much.
4.2. Optimal Storage Size for Each Class
Assume and ignore rounding, due to Equation (23), we obtain
where is an auxiliary variable and it is given by
In fact, it is a functional of the minus Rényi entropy of order two, i.e., where is the Rényi entropy when [38]. Furthermore, we have the following lemma on .
Lemma 1.
Let be a probability distribution, then we have
Proof.
Refer to Appendix B. □
Thus, we find if . Furthermore, we obtain when .
Theorem 3.
Let be a probability distribution and be the importance weight. The optimal storage sizes in the ideal storage system have the following properties:
- (1)
- if for when ;
- (2)
- if for when .
Proof.
Refer to Appendix C. □
Remark 9.
As noted in [31], the data with smaller probability usually possesses larger importance when , while the data with larger probability usually possesses larger importance when . Therefore, this optimal allocation strategy makes rational use of all the storage space by providing more storage size for the paramount data and less storage size for the insignificance data. It agrees with the intuitive idea, which is that users generally are more concerned about the data that they need rather than the whole data itself.
Lemma 2.
Let be a probability distribution and r be radix. L and T are positive integers, and . If ϖ meets , then we have .
Proof.
According to Equation (33a) and constraint , we obtain for . In this case, . □
4.3. Relative Weighted Reconstruction Error
For convenience, we also use to denote the relative weighted reconstruction error (RWRE) . Due to Equation (7), we have
If the maximum available average storage size T is zero, then we will have for . In this case, . On the contrary, when for .
Theorem 4.
has the following properties:
- (1)
- is monotonically decreasing with ϖ in ;
- (2)
- is monotonically increasing with ϖ in ;
- (3)
- .
Proof.
Refer to Appendix D. □
Remark 10.
As shown in Remark 7 and Remark 8, the overwhelming majority of important information will gather in a fraction of data as the importance coefficient increases to negative/positive infinity. Therefore, we can heavily reduce the storage space with extremely small of RWRE with the increasing of the absolute value of the importance coefficient. In fact, this special characteristic of weight reflects the effect of users’ preferences. That is, it is beneficial for data compression that the data that users care about is highly clustered. Moreover, when , all the importance weights are the same, which leads to the incompressibility, in a sense, for the fact that there is no special characteristic of weight for users to make rational use of storage space.
In the following part of this section, we will discuss the cases where for , which means all can be given by Equation (33a) and due to Lemma 2. In this case, substituting Equation (33a) in Equation (7), the RWRE is
where , which characterizes the average compressed storage space of each data.
Since , we have
Hence,
where
and
Theorem 5.
For a given storage system with the probability distribution of data sequence , let L, r be fixed positive integers (), and ϖ meets for . For the given least upper bound of the RWRE δ ( where and is defined in Equation (41)), the maximum average compressed storage size of each data is given by
where , and the equality of Equation (44a) holds if the probability distribution of the data sequence is a uniform distribution or the importance coefficient is zero.
Proof.
It is easy to check that according to Lemma 2 for the fact that . Let . By means of Equation (39), we solve this inequality and obtain
where . Then we have the following inequality:
where follows from Jensen’s inequality. Since the exponential function is strictly convex, the equality holds only if is constant everywhere, which means is a uniform distribution or the importance coefficient is zero. □
Remark 11.
In conventional source coding, the encoding length depends on the entropy of sequence, and a sequence is incompressible if its probability distribution is a uniform distribution [34]. In Theorem 5, the uniform distribution is also the worst case, since the system achieves the minimum compressed storage size. Although the focus is different, they both show that the uniform distribution is detrimental for compression.
Furthermore, taking as an example, it is also noted that
for the fact that . In order to make approaches L, should be as close to zero as possible in the range where for holds.
When the importance coefficient is constant, for two probability distributions and , if , then we will obtain in is larger than that in . In fact, is defined as MIM in [30], and [38]. Thus, the maximum average compressed storage size of each data is under the control of MIM and Rényi entropy of order two. For typical small-probability event scenarios where there is an exceedingly small probability, the MIM is usually large, and is also not small simultaneously with big probability. Therefore, is usually large in this case. As a result, much more compressed storage space can be saved in typical small-probability event scenarios while compared to that in uniform probability distribution. Namely, the data can be compressed by means of the characteristic of the typical small-probability events, which may help to improve the design of practical storage systems in big data.
5. Property of Optimal Storage Strategy Based on Non-Parametric Message Importance Measure
In this section, we define the importance weight based on the form of non-parametric message importance measure (NMIM) to characterize the relative weighted reconstruction error (RWRE) [23]. Then, the importance weight of i-th class in this section is given by
Due to Equation (22), the optimal storage size in the ideal storage system by this importance weight is given by
For two probabilities and , if , then we will have . In this case, we obtain according to Theorem 2.
Assume and ignore rounding, due to Equation (23), we obtain
Let in this case, we find
Generally, this constraint does not invariably hold, and therefore we usually do not have .
For the quantification storage system as shown in in this section, if the maximum available average storage size satisfies , an arbitrary probability distribution will make Equation (50) hold, which means . In this case, substituting Equation (47) in Equation (9), the RWRE can be expressed as
where , which is defined as the NMIM [23].
It is noted as T approaches positive infinity. Since , we find . Furthermore, since that according to Reference [23], we obtain . Let , we have
Obviously, for a given RWRE, the minimum average required storage size for the quantification storage system decreases with increasing of . That is to say, the data with large NMIM will get a large compression ratio. In fact, the NMIM in the typical small-probability event scenarios is generally large according to Reference [23]. Thus, this compression strategy is effective in the typical small-probability event scenarios.
Furthermore, due to Reference [23], when is small. Hence, for small , the RWRE in this case can be reduced to
It is easy to check that increases as increases in this case.
6. Numerical Results
We now present numerical results to validate the developed theoretical results in this paper. In this section, we assume all the data is digital, and the exponential distortion measure in Equation (4) is adopted. Furthermore, the relative weighted reconstruction error (RWRE) in Equation (5) is used to characterize the change of total data value before and after the lossy compression based on data value, which represents the total cost of this compression.
6.1. Success Rate of Compressed Storage in General Storage System
This part presents the success rate of compressed storage in the general storage system to show the effectiveness of our method, and it considers the following scenario of data storage.
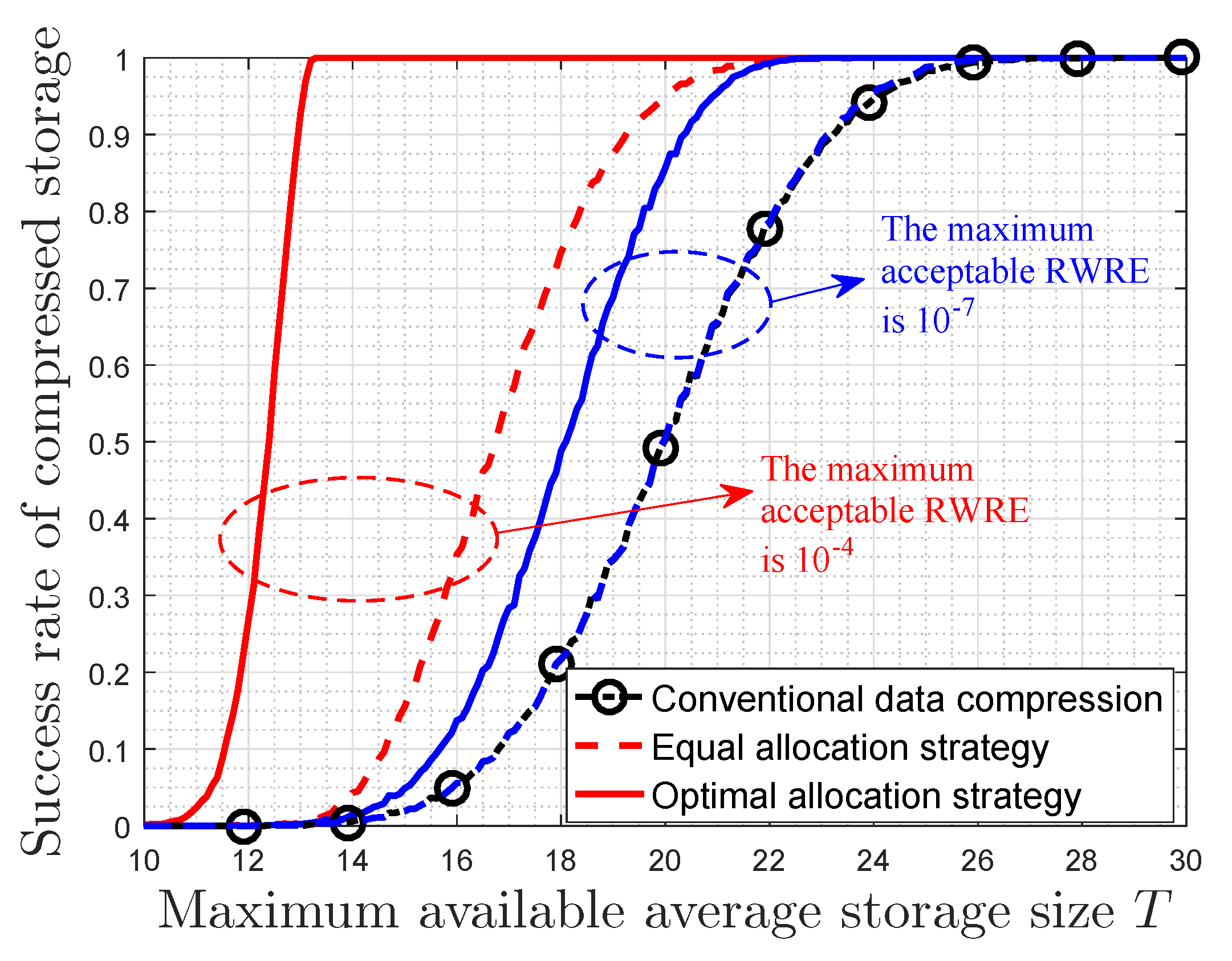
There are eight categories of data, and the probability distribution of the data category randomly generates in each storing. Moreover, each category of data gets a randomly generated data value, which is in the interval . After the lossless conventional data compression, where the data value is assumed to be unchanged, the storage size of each data is a randomly generated number between 10 and 30. The maximum available average storage size T is also varying from 10 to 30 bits. It is considered as a successful data compression when the compressed storage size is not larger than the maximum available storage size. However, when the amount of data to be stored is extremely big, the compressed storage size may still not be enough after the lossless conventional data compression. In this case, the optimal storage space allocation strategy in this paper can be used if a certain amount of data value is allowed to be lost. As a contrast, we also divide up the maximum available storage space equally among all categories of data on the basis of the lossless conventional data compression, which is presented as the equal allocation strategy in Figure 3. Assume that it can also be seen as a successful data compression if the RWRE in this process is less than or equal to the specified amount that can be acceptable by users. For each value of T, this numerical simulation is repeated 10,000 times. The success rate of compressed storage is given by /10,000, where is the number of times the successful data compression happens in all the experiments.
Figure 3 shows the relationship between the success rate of compressed storage and the maximum available average storage size T. It is observed that the success rate of conventional data compression is almost one when the available storage size is large ( bits). However, when the available storage size is not big ( bits), the success rate of conventional data compression decreases with decreasing of the maximum available average storage size until it is zero. Furthermore, when a certain amount of data value is allowed to be lost, the success rate can be improved on the basis of the lossless conventional data compression for the same T. More important, the success rate of the optimal allocation strategy is the largest among these three considered compression strategies. For the same maximum available average storage size, the success rates of the optimal allocation strategy and the equal allocation strategy increase as the maximum acceptable RWRE increases. In fact, the success rate of equal allocation strategy is exceedingly close to that of conventional data compression when the maximum acceptable RWRE is small (e.g., ). In general, if a small quantity of total data value is allowed to be lost, our optimal allocation strategy will further improve the performance of data compression on the basis of the lossless conventional data compression.
6.2. Optimal Storage Size Based on Message Importance Measure in Ideal Storage System
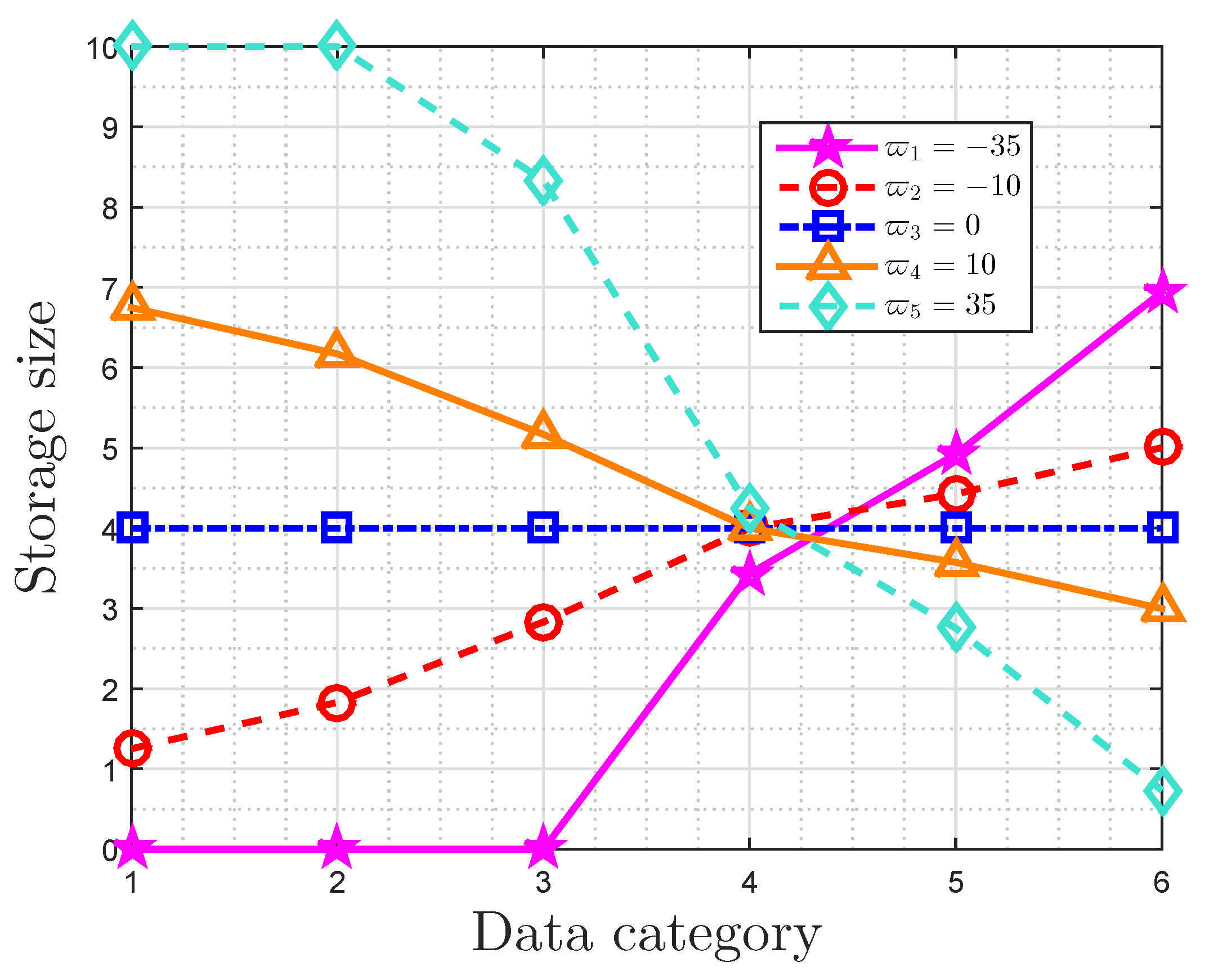
We illustrate the characteristics of optimal storage size based on message importance measure (MIM) in an ideal storage system in this part by means of a broken line graph, which demonstrates the theoretical analyses in Section 4.2. For ease of illustrating, we ignore rounding and the optimal storage size of the i-th class is given by in Equation (19).
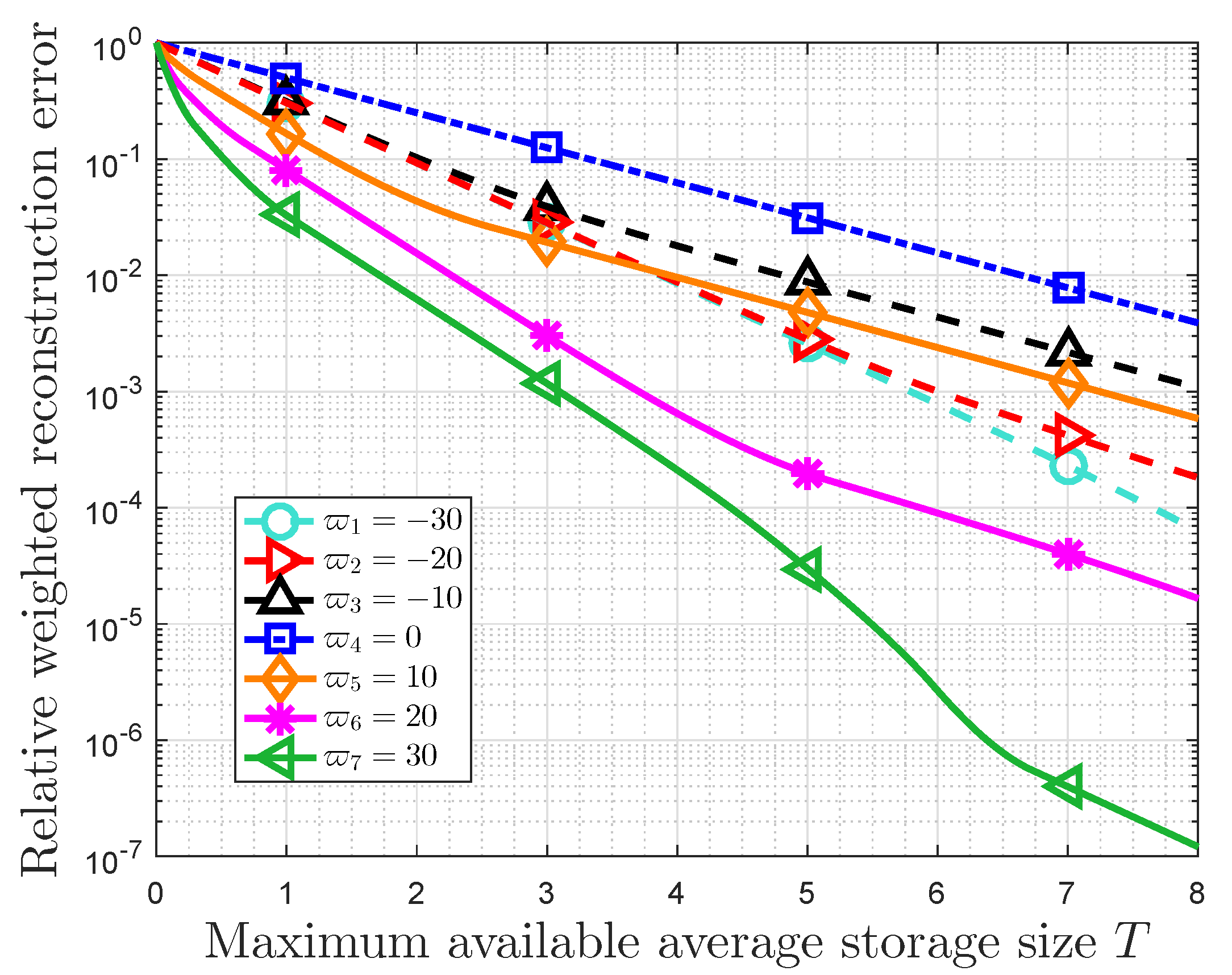
The broken line graph of the optimal storage size is shown in Figure 4, when the probability distribution is . In fact, and . The maximum available average storage size T is 4 bits, and the original storage size of each data is 10 bits. The importance coefficients are given by , respectively. Some observations can be obtained. When , the optimal storage size of the i-th class decreases with the increasing of its probability. On the contrary, the optimal storage size of the i-th class increases as its probability increases when . In addition, the optimal storage size is invariably equal to T () when . Furthermore, increases as increases for , and it decreases with for . For importance coefficients with small absolute values (), holds for , and is extremely close to T ().
6.3. The Property of the RWRE Based on MIM in Ideal Storage System
Then we focus on the properties of the RWRE. In this part, we will give several numerical results as quintessential examples to validate our theoretical founds in Section 4.3. Without loss of generality, let the original storage size of each data be 16 bits, and the maximum available average storage size T is varying from 0 to 8 bits. Although any range of T can be used, we choose this range to make the results more clear. Moreover, the normalized MIM is adopted to describe the data value that represents the subjective assessment of users.
Figure 5 and Figure 6 both present the relationship between the RWRE and the maximum available average storage size with the probability distribution . In fact, the compression ratio is given by in this case, and the RWRE represents the total cost, which measures the compression distortion from the viewpoint of data value. Therefore, these two figures essentially show the trade-off between the compression ratio and the total compressed storage cost.
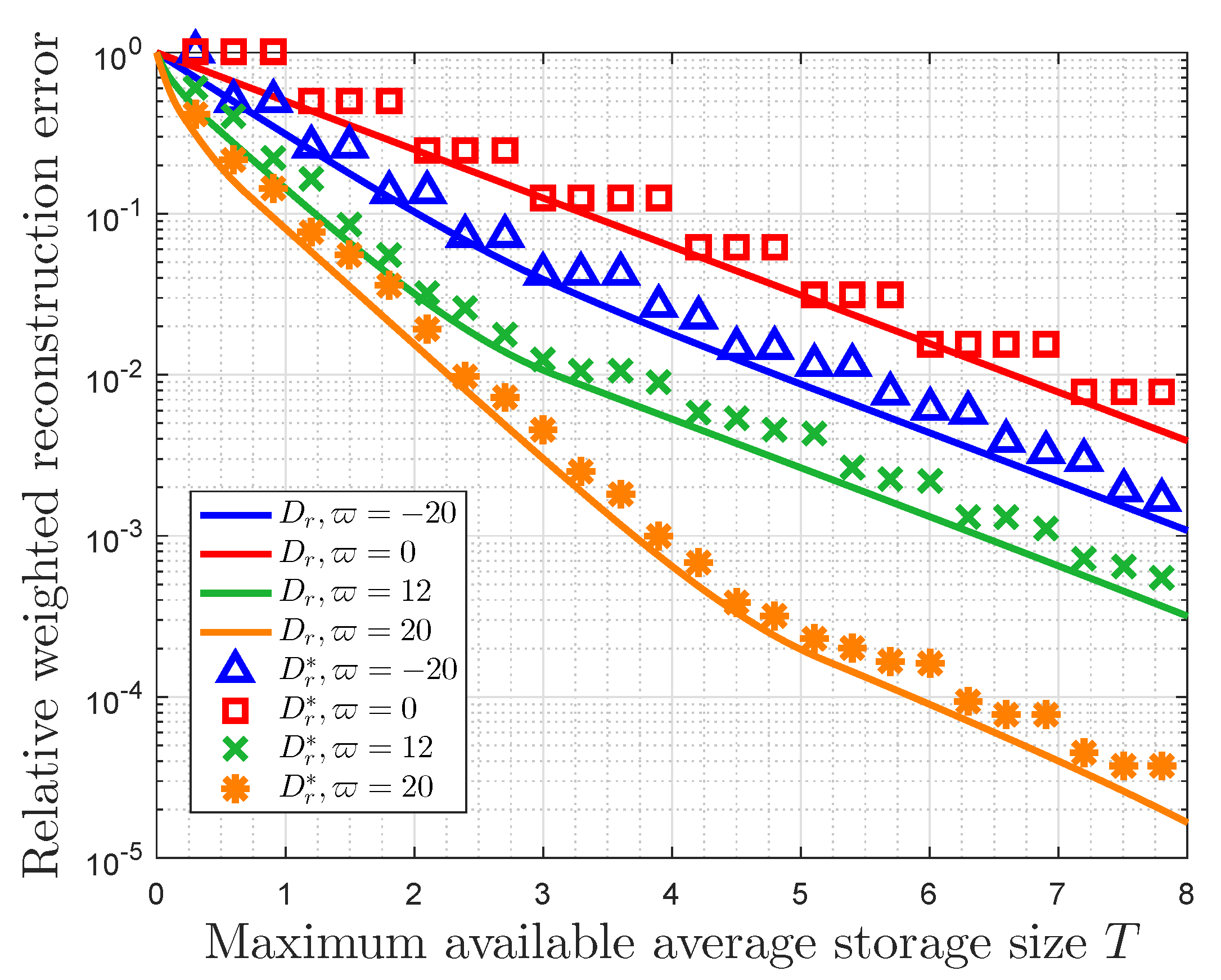
Figure 5 focuses on the error of RWRE by rounding number with different values of the importance coefficient (). In Figure 5, the RWRE is acquired by substituting Equation (19) in Equation (38), while the RWRE is obtained by substituting Equation (22) in Equation (38). In this figure, has a tiered descent as the available average storage size increases, while monotonically decreases with increasing in the available average storage size. Figure 5 also shows that is always less than or equal to and they are very close to each other for the same importance coefficient, which means that can be used as the lower bound of to reflect the characteristics of .
Furthermore, some other observations can be obtained in Figure 6. For the same T, the RWRE increases as increases when , while the RWRE decreases with increasing of when . In addition, the RWRE is the largest when . These results prove the validity of Theorem 4. It is also observed that the RWRE always decreases with increasing of T for given . Furthermore, for any importance coefficient, the RWRE will be 1 if available average storage size is zero. Generally, there is a trade-off between the RWRE and the available storage size, and the results in this paper propose an alternative lossy compression strategy based on message importance.
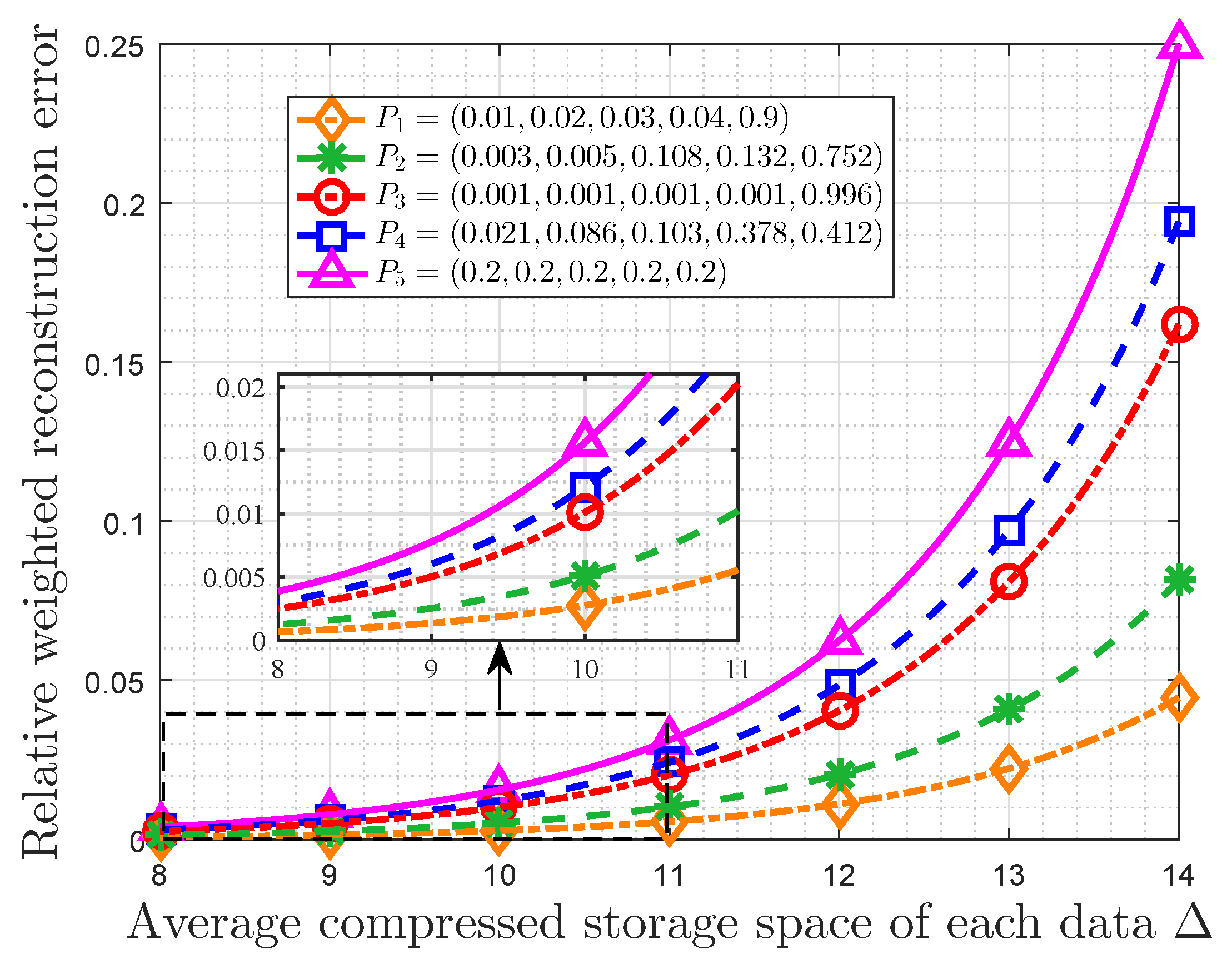
Then let the importance coefficient be five and the maximum available average storage size T be varying from two to eight bits. Although any range of T can be used, we choose this range to make the results more clear. In addition, the original storage size is still 16 bits. Furthermore, the average compressed storage space of each data is given by . In this case, Figure 7 shows that the relationship between the RWRE and the average compressed storage space of each data for different probability distributions. In fact, it can also be seen as reflecting the relationship between the total compressed storage cost and the average saving storage size. The probability distributions and some auxiliary variables are listed in Table 2. In fact, we take these five probability distributions as examples, and of them decreases monotonously. Obviously, all probability distributions satisfy . It is observed that the RWRE always increases with increasing of for a given probability distribution. Some other observations are also obtained. For the same , the RWRE of uniform distribution is the largest all the time. Furthermore, if the RWRE is required to be less than a specified value, which is exceedingly common in actual systems in order to make the difference between the raw data and the stored data accepted, the maximum average compressed storage size of each data will increase with increasing of . As an example, when the RWRE is required to be smaller than , the maximum average compressed storage size of , , , , of each data is , , , , , respectively. In particular, the maximum average compressed storage size of each data in a uniform distribution is the smallest, which suggests the data with a uniform distribution is incompressible from the perspective of optimal storage space allocation based on the data value.
6.4. The Property of the RWRE Based on Non-Parametric MIM in a Quantification Storage System
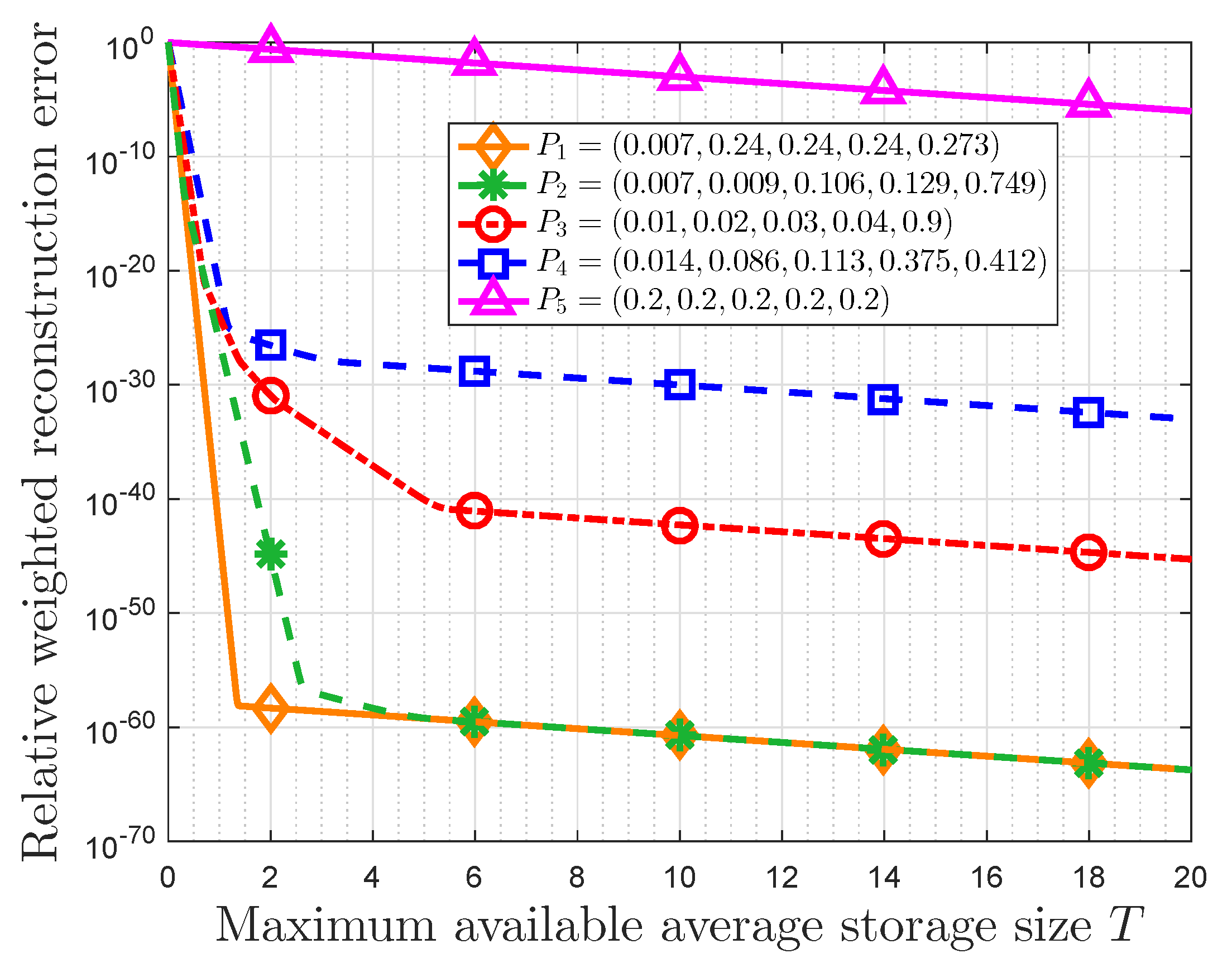
Figure 8 presents the relationship between the RWRE and the maximum available average storage size T for different probability distributions in a quantification storage system, which proves the validity of theoretical results in Section 5. In this part, we use the normalized non-parametric message importance measure (NMIM) to characterize the data value that represents the subjective assessment of users. The probability distributions and some auxiliary variables are listed in Table 3.
Some observations can be obtained. First, the RWRE always decreases with the increasing of the maximum available average storage size for a given probability distribution, and there is a trade-off between the RWRE and the maximum available average storage size. When the maximum available average storage size is small (), the RWRE decreases largely compared to the case where T is large. In addition, when the maximum available average storage size is large (), the difference between these RWREs remains the same at the logarithmic Y-axis. In fact, according to Equation (51), this difference between two probabilities in this figure is the difference of NMIM divided by . As an example, the difference between and in this figure is 30, which satisfies this conclusion for the fact that . Moreover, the RWRE in is very close to that in , and the minimum probabilities in these two probability distributions are the same, i.e., . It suggests that the data with the same minimum probability will have the same compression performance no matter how the distribution changes, if the minimum probability is very small. In addition, it is also observed that the RWRE decreases as NMIM increases for the same T, which means this compression strategy is more effective in the large NMIM cases.
7. Conclusions
In this paper, we focused on the problem of lossy compression storage when the storage size is still not enough after conventional lossless data compression. By means of the message importance to characterize the data value, we define the weighted reconstruction error to describe the total cost in data storage. Based on it, we presented an optimal storage space allocation strategy for digital data from the perspective of data value by the exponential distortion measure, which pursues the least error with respect to the data value for restricted storage size. We gave the solutions by a kind of restrictive water-filling, which presented an alternative way to design an effective storage space allocation strategy. In fact, this optimal allocation strategy prefers to provide more storage size for crucial event classes in order to make the rational use of resources, which agrees with the individuals’ cognitive mechanism.
Then, we presented the properties of this strategy based on the message importance measure (MIM) detailedly. It is obtained that there is a trade-off between the relative weighted reconstruction error (RWRE) and available storage size. In fact, if a small quantity of loss of total data value is accepted by users, this strategy will further compress data based on the conventional methods of data compression. Moreover, the compression performance of this storage system improves as the absolute value of importance coefficient increases. This is due to the fact that a fraction of data can contain the overwhelming majority of useful information that exerts a tremendous fascination on users as the importance coefficient approaches negative/positive infinity, which suggests that the users’ interest is highly-concentrated. On the other hand, the probability distribution of event classes also has an effect on the compression results. When the useful information is only highly enriched in a small portion of raw data naturally from the viewpoint of users, such as the small-probability event scenarios, it is obvious that we can compress the data greatly with the aid of these characteristics of distribution. Furthermore, the properties of storage size and RWRE based on non-parametric MIM were also discussed. In fact, the RWRE in the data with a uniform distribution was invariably the largest in any case. Therefore, this paper harbors the idea that the data with uniform information distribution is incompressible from the perspective of optimal storage size allocation based on data value, which is consistent with the well known conclusion in information theory in a sense.
Proposing a more general distortion measure between the raw data and the compressed data, which no longer only applies to digital data, and using it to acquire the high-efficiency lossy data compression systems from the perspective of message importance are of our future interests. In addition, we are also interested in using this optimal storage space allocation strategy in a real application with a real data stream in the future.
Author Contributions
Conceptualization, S.L., R.S. and P.F.; Formal analysis, S.L., R.S., Z.Z. and P.F.; methodology, S.L., R.S. and P.F.; writing—original draft, S.L.; writing—review and editing, S.L., R.S., Z.Z. and P.F. All authors have read and agreed to the published version of the manuscript.
Funding
The authors are very thankful for the support of the National Natural Science Foundation of China (NSFC) No. 61771283 and Beijing Natural Science Foundation (4202030).
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| IoT | Internet of things |
| MIM | message importance measure |
| RWRE | relative weighted reconstruction error |
| NMIM | non-parametric message importance measure |
Appendix A. Proof of Theorem 2
In fact, Equation (25) can be rewritten as
When , we have
Due to Equation (8b), we obtain that , and therefore . Furthermore, it is easy to check that since that . Thus, if for . The proof is completed.
Appendix B. Proof of Lemma 1
(1) For , it is noted that
where the equality holds only if is a uniform distribution. Moreover,
where the equality holds only if there is only () and for .
(2) For , we have . We have equality if and only if and for . Therefore, we only need to check .
First, if , we obtain .
Second, if , we obtain . It is easy to check that .
Third, if , we use the method of Lagrange multipliers. Let
Setting the derivative to 0, we obtain
Substituting in the constraint , we have
Hence, we find and
In this case, we get
Thus, Lemma 1 is proved.
Appendix C. Proof of Theorem 3
(1) First, let when . It is noted that
Therefore, we find since that , due to Theorem 2.
(2) Second, let when . It is noted that
Therefore, we find since that , due to Theorem 2. The proof is completed.
Appendix D. Proof of Theorem 4
We define an auxiliary function as
According to Equation (38), it is noted that the the monotonicity of with respect to is the same with that of .
Without loss of generality, let of be
where is given by Equation (20) where and .
The derivative of with respect to is given by
Hence,
where and .
(1) When , we have
In fact, if , then we will have due to Theorem 3. Thus, in this case. With taking into account, we have Equation (A16a). Furthermore, Equation (A16b) is obtained by exchanging the notation of subscript in the second item.
For and , we have
where .
Based on the discussions above, we have
Since that when , is monotonically decreasing with in .
(2) Similarly, when , if , then we will have due to Theorem 3. Thus, in this case. With taking into account, we have
where Equation (A19a) is obtained by exchanging the notation of subscript in the second item.
In addition, is still given by Equation (A17), and . As a result, when . Therefore is monotonically increasing with in .
(3) When , the storage size for will be all equal to T, and therefore . Based on the discussion in (1) and (2), we obtain . The proof is completed.
References
- Chen, M.; Mao, S.; Zhang, Y.; Leungm, V.C. Definition and features of big data. In Big Data: Related Technologies, Challenges and Future Prospects; Springer: New York, NY, USA, 2014; pp. 2–5. [Google Scholar]
- Cai, H.; Xu, B.; Jiang, L.; Vasilakos, A. IoT-based big data storage systems in cloud computing: Perspectives and challenges. IEEE Internet Things J. 2017, 4, 75–87. [Google Scholar] [CrossRef]
- Hu, H.; Wen, Y.; Chua, T.; Li, X. Toward scalable systems for big data analytics: A technology tutorial. IEEE Access 2014, 2, 652–687. [Google Scholar]
- Dong, D.; Herbert, J. Content-aware partial compression for textual big data analysis in hadoop. IEEE Trans. Big Data 2018, 4, 459–472. [Google Scholar] [CrossRef]
- Park, J.; Park, H.; Choi, Y. Data compression and prediction using machine learning for industrial IoT. In Proceedings of the IEEE International Conference on Information Networking (ICOIN), Chiang Mai, Thailand, 10–12 January 2018; pp. 818–820. [Google Scholar]
- Geng, D.; Zhang, C.; Xia, C.; Xia, X.; Liu, Q.; Fu, X. Big data-based improved data acquisition and storage system for designing industrial data platform. IEEE Access 2019, 7, 44574–44582. [Google Scholar] [CrossRef]
- Nalbantoglu, Ö.; Russell, D.; Sayood, K. Data compression concepts and algorithms and their applications to bioinformatics. Entropy 2010, 12, 34–52. [Google Scholar] [CrossRef] [Green Version]
- Cao, X.; Liu, L.; Cheng, Y.; Shen, X. Towards energy-efficient wireless networking in the big data era: A survey. IEEE Commun. Surv. Tutor. 2017, 20, 303–332. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Oohama, Y. Exponential strong converse for source coding with side information at the decoder. Entropy 2018, 20, 352. [Google Scholar] [CrossRef] [Green Version]
- Pourkamali-Anaraki, F.; Becker, S. Preconditioned data sparsification for big data with applications to pca and k-means. IEEE Trans. Inf. Theory 2017, 63, 2954–2974. [Google Scholar] [CrossRef]
- Aguerri, I.E.; Zaidi, A. Lossy compression for compute-and-forward in limited backhaul uplink multicell processing. IEEE Trans. Commun. 2016, 64, 5227–5238. [Google Scholar] [CrossRef] [Green Version]
- Cui, T.; Chen, L.; Ho, T. Distributed distortion optimization for correlated sources with network coding. IEEE Trans. Commun. 2012, 60, 1336–1344. [Google Scholar] [CrossRef]
- Ukil, A.; Bandyopadhyay, S.; Sinha, A.; Pal, A. Adaptive Sensor Data Compression in IoT systems: Sensor data analytics based approach. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia, 19–24 April 2015; pp. 5515–5519. [Google Scholar]
- Zhong, J.; Yates, R.D.; Soljanin, E. Backlog-adaptive compression: Age of information. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 566–570. [Google Scholar]
- Elkan, C. The foundations of cost-sensitive learning. In Proceedings of the the Seventeenth International Joint Conference on Artificial Intelligence, Seattle, WA, USA, 4–10 August 2001; pp. 973–978. [Google Scholar]
- Zhou, Z.; Liu, X. Training cost-sensitive neural networks with methods addressing the class imbalance problem. IEEE Trans. Knowl. Data Eng. 2006, 18, 63–77. [Google Scholar] [CrossRef]
- Lomax, S.; Vadera, S. A survey of cost-sensitive decision tree induction algorithms. ACM Comput. Surv. 2013, 45, 16:1–16:35. [Google Scholar] [CrossRef] [Green Version]
- Masnick, B.; Wolf, J. On linear unequal error protection codes. IEEE Trans. Inf. Theory 1967, 3, 600–607. [Google Scholar] [CrossRef]
- Sun, K.; Wu, D. Unequal error protection for video streaming using delay-aware fountain codes. In Proceedings of the IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017; pp. 1–6. [Google Scholar]
- Feldman, D.; Schmidt, M.; Sohler, C. Turning big data into tiny data: Constant-size coresets for k-means, pca and projective clustering. In Proceedings of the Twenty-Fourth Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 6–8 January 2013; pp. 1434–1453. [Google Scholar]
- Tegmark, M.; Wu, T. Pareto-optimal data compression for binary classification tasks. Entropy 2020, 22, 7. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; She, R.; Fan, P.; Letaief, K.B. Non-parametric message important measure: Storage code design and transmission planning for big data. IEEE Trans. Commun. 2018, 66, 5181–5196. [Google Scholar] [CrossRef]
- Ivanchev, J.; Aydt, H.; Knoll, A. Information maximizing optimal sensor placement robust against variations of traffic demand based on importance of nodes. IEEE Trans. Intell. Transp. Syst. 2016, 17, 714–725. [Google Scholar] [CrossRef]
- Kawanaka, T.; Rokugawa, S.; Yamashita, H. Information security in communication network of memory channel considering information importance. In Proceedings of the IEEE International Conference on Industrial Engineering and Engineering Management (IEEM), Singapore, 10–13 December 2017; pp. 1169–1173. [Google Scholar]
- Li, M.; Zuo, W.; Gu, S.; Zhao, D.; Zhang, D. Learning convolutional networks for content-weighted image compression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3214–3223. [Google Scholar]
- Zhang, X.; Hao, X. Research on intrusion detection based on improved combination of K-means and multi-level SVM. In Proceedings of the IEEE International Conference on Communication Technology (ICCT), Chengdu, China, 27–30 October 2017; pp. 2042–2045. [Google Scholar]
- Li, M. Application of cart decision tree combined with pca algorithm in intrusion detection. In Proceedings of the IEEE International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 24–26 November 2017; pp. 38–41. [Google Scholar]
- Beasley, M.S.; Carcello, J.V.; Hermanson, D.R.; Lapides, P.D. Fraudulent financial reporting: Consideration of industry traits and corporate governance mechanisms. Account. Horiz. 2000, 14, 441–454. [Google Scholar] [CrossRef]
- Fan, P.; Dong, Y.; Lu, J.; Liu, S. Message importance measure and its application to minority subset detection in big data. In Proceedings of the IEEE Globecom Workshops (GC Wkshps), Washington, DC, USA, 4–8 December 2016; pp. 1–6. [Google Scholar]
- She, R.; Liu, S.; Wan, S.; Xiong, K.; Fan, P. Importance of small probability events in big data: Information measures, applications, and challenges. IEEE Access 2019, 7, 100363–100382. [Google Scholar] [CrossRef]
- She, R.; Liu, S.; Fan, P. Recognizing Information Feature Variation: Message Importance Transfer Measure and Its Applications in Big Data. Entropy 2018, 20, 401. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Dong, Y.; Fan, P.; She, R.; Wan, S. Matching users’ preference under target revenue constraints in data recommendation systems. Entropy 2019, 21, 205. [Google Scholar] [CrossRef] [Green Version]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; Wiley: Hoboken, NJ, USA, 2006. [Google Scholar]
- Aggarwal, C.C. Data Classification: Algorithms and Applications; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Salvador–Meneses, J.; Ruiz–Chavez, Z.; Garcia–Rodriguez, J. Compressed kNN: K-nearest neighbors with data compression. Entropy 2019, 21, 234. [Google Scholar] [CrossRef] [Green Version]
- She, R.; Liu, S.; Dong, Y.; Fan, P. Focusing on a probability element: Parameter selection of message importance measure in big data. In Proceedings of the IEEE International Conference on Communications (ICC), Paris, France, 20–26 May 2017; pp. 1–6. [Google Scholar]
- Van Erven, T.; Harremoës, P. Rényi divergence and kullback-leibler divergence. IEEE Trans. Inf. Theory 2014, 60, 3797–3820. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
Pictorial representation of the system model.

Figure 2.
Restrictive water-filling for optimal storage sizes.

Figure 3.
The success rate of compressed storage versus the maximum available average storage size.

Figure 4.
Broken line graph of optimal storage size with the probability distribution , for a given maximum available average storage size and original storage size .
Figure 4.
Broken line graph of optimal storage size with the probability distribution , for a given maximum available average storage size and original storage size .

Figure 5.
Relative weighted reconstruction error (RWRE) versus maximum available average storage size T with the probability distribution in the case of the value of importance coefficient . is acquired by substituting Equation (19) in Equation (38), while is obtained by substituting Equation (22) in Equation (38).
Figure 5.
Relative weighted reconstruction error (RWRE) versus maximum available average storage size T with the probability distribution in the case of the value of importance coefficient . is acquired by substituting Equation (19) in Equation (38), while is obtained by substituting Equation (22) in Equation (38).

Figure 6.
RWRE versus maximum available average storage size T with the probability distribution in the case of the value of importance coefficient .
Figure 6.
RWRE versus maximum available average storage size T with the probability distribution in the case of the value of importance coefficient .

Figure 7.
RWRE vs. average compressed storage size of each data with importance coefficient .

Figure 8.
RWRE versus maximum available average storage size T.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Notations.
| Notation | Description |
|---|---|
| The sequence of raw data | |
| The sequence of compressed data | |
| The storage size of x | |
| The distortion measure function between and in data reconstruction | |
| n | The number of event classes |
| The alphabet of raw data | |
| The alphabet of compressed data | |
| The error cost for the reconstructed data | |
| The probability distribution of data class | |
| The weighted reconstruction error | |
| The relative weighted reconstruction error | |
| The storage size of raw data | |
| The storage size of compressed data | |
| The round optimal storage size of the data belonging to the i-th class | |
| T | The maximum available average storage size |
| The importance coefficient | |
| , | and |
| The message importance measure, which is given by | |
| The average compressed storage size of each data, which is given by | |
| The maximum available for the given supremum of the RWRE | |
| The non-parametric message importance measure, which is given by |
Table 2.
The auxiliary variables in ideal storage system.
| Variable | Probability Distribution | |||
|---|---|---|---|---|
| 5.7924 | −0.6276 | 6.7234 | ||
| 4.2679 | −1.1350 | 6.1305 | ||
| 7.1487 | −0.0287 | 5.4344 | ||
| 2.2367 | −0.5838 | 5.2530 | ||
| 0 | 0 | 5 |
Table 3.
The auxiliary variables in the quantification storage system.
| Variable | Probability Distribution | ||
|---|---|---|---|
| 0.007 | 136.8953 | ||
| 0.007 | 136.8953 | ||
| 0.01 | 94.3948 | ||
| 0.014 | 66.1599 | ||
| 0.2 | 4.0000 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Liu, S.; She, R.; Zhu, Z.; Fan, P. Storage Space Allocation Strategy for Digital Data with Message Importance. Entropy 2020, 22, 591. https://doi.org/10.3390/e22050591
AMA Style
Liu S, She R, Zhu Z, Fan P. Storage Space Allocation Strategy for Digital Data with Message Importance. Entropy. 2020; 22(5):591. https://doi.org/10.3390/e22050591
Chicago/Turabian StyleLiu, Shanyun, Rui She, Zheqi Zhu, and Pingyi Fan. 2020. "Storage Space Allocation Strategy for Digital Data with Message Importance" Entropy 22, no. 5: 591. https://doi.org/10.3390/e22050591
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.