Taylor’s Law in Innovation Processes


1
Physics Department, Sapienza University of Rome, P.le Aldo Moro 5, 00185 Rome, Italy
2
IMT School for Advanced Studies Lucca, Piazza San Ponziano 6, 55100 Lucca, Italy
3
ADAMSS Center, Università Degli Studi di Milano, 20133 Milan, Italy
4
Complexity Science Hub Vienna, Josefstädter Strasse 39, A-1080 Vienna, Austria
*
Author to whom correspondence should be addressed.
Entropy 2020, 22(5), 573; https://doi.org/10.3390/e22050573
Submission received: 24 April 2020
/
Revised: 11 May 2020
/
Accepted: 13 May 2020
/
Published: 19 May 2020
(This article belongs to the Special Issue Statistical Mechanics of Complex Systems)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Taylor’s law quantifies the scaling properties of the fluctuations of the number of innovations occurring in open systems. Urn-based modeling schemes have already proven to be effective in modeling this complex behaviour. Here, we present analytical estimations of Taylor’s law exponents in such models, by leveraging on their representation in terms of triangular urn models. We also highlight the correspondence of these models with Poisson–Dirichlet processes and demonstrate how a non-trivial Taylor’s law exponent is a kind of universal feature in systems related to human activities. We base this result on the analysis of four collections of data generated by human activity: (i) written language (from a Gutenberg corpus); (ii) an online music website (Last.fm); (iii) Twitter hashtags; (iv) an online collaborative tagging system (Del.icio.us). While Taylor’s law observed in the last two datasets agrees with the plain model predictions, we need to introduce a generalization to fully characterize the behaviour of the first two datasets, where temporal correlations are possibly more relevant. We suggest that Taylor’s law is a fundamental complement to Zipf’s and Heaps’ laws in unveiling the complex dynamical processes underlying the evolution of systems featuring innovation.
1. Introduction
The laws of Zipf [1,2,3], Heaps [4,5] and Taylor [6,7], which quantify, respectively, the frequency distribution of elements in a given system, the rate at which new elements enter a given system, and fluctuations in that rate, are recognized as the more general statistical laws characterizing complex systems featuring innovations. As such, they also set minimal requirements for the predictions a given modeling scheme should have to correctly address the fundamental mechanisms driving innovation processes. Zipf’s law, or generalized Zipf’s law predicting a frequency-rank distribution of the form , with (whereas the strict Zipf’s law refers to ) characterizes disparate systems, from cities population to earthquakes amplitudes to the frequency of words in written texts, and different explanations for its emergence have been proposed so far [8,9,10]. While Zipf’s law is a static property of the system, Heaps’ law explicitly refers to its evolution and states that the number of distinct elements when the system consists of n elements follows a power law , . This points to two fundamental properties shared by different systems related to human activity, from natural language, to the way humans listen to music or interact in a collaborative online systems, or build up collaborations in a research activity: (i) new elements continuously enter the system; (ii) the rate at which innovation occurs slows down with the intrinsic time of the system (when the strict inequality holds), e.g., it is easier and easier to continue with established collaborations than linking to new ones. These two simple laws puzzled the scientific community to a large extent, and although it was recognized that in some conditions one law implies the other [11], a general model able to account for both in a common ground, without deriving one from the other, and from microscopic mechanisms, was only recently proposed [12]. This model was based on the notion of the adjacent possible [13], and was generalized in different forms [14,15] to account for higher-level properties of the systems under study.
Taylor’s law was more recently related to the onset of complex behaviour. The law was originally formulated in the context of population ecology, where the observation was made [6] that the variance of the population density of different species scales as a power-law of the mean population density: , with the exponent . While arises in the case of random distribution of species in the environment, a value points to correlated patterns. During the past half-century, Taylor’s power law was then observed both in biological and non-biological contexts, from ecology to life-sciences, from physics to economics [7]. In the framework of populations ecology, different mechanisms have been proposed to account for the observed Taylor’s law exponents, from (negative) interaction between species in an ecosystem [16], to correlations between individuals reproduction ability [17]. In [18,19], a simple stochastic multiplicative process is shown to produce Taylor’s exponents ranging from zero to infinity depending on the population’s growth regime, and in this context the value observed in real systems is shown to be ascribable to a sampling artifact [20]. In the contest of complex systems, Taylor’s law was measured for the first time in [21] referred to the number of different elements at a given text’s length n. In particular, it was observed that the standard deviation as a function of the mean scales in written texts as , with . Here, an exponent was expected if successive introductions of novel elements in the words sequence were independent of previous innovations. This is the case for instance in Simon-like models [22,23], both with constant and time-dependent innovation rate, where the introduction of novelties follows a Poissonian process, respectively homogeneous and inhomogeneous, thus the variance being proportional to the mean. Correlations between the introduction of different novelties have to be considered to predict . The model introduced in [12] was recognized [24] to predict exponents for Taylor’s law ranging from to 1, depending on the relative importance of the processes of innovation versus reinforcement of old elements, thus better accounting for the values observed in real systems.
The contribution of the present study is twofold. Firstly, we fully characterize the prediction for Taylor’s law of the recently introduced modeling scheme [12] based on the adjacent possible. We recall results for its exchangeable [25,26], counterpart and, relying on known results on triangular urn models, extend them for all the spectrum of the parameter values of the original model, including the non exchangeable region. We further give results for two generalizations of the model, allowing to also predict exponents for Taylor’s law greater than one, as observed in real systems: (i) a version with random quenched parameters and (ii) a version where semantic triggering is introduced, as in [12]. We devote a particular emphasis to the connection of the urn model with triggering with the two parameters Poisson–Dirichlet process [27,28]. The two parameters Poisson–Dirichlet process is the state-of-the-art reference process for language modeling [29], and in its hierarchical form [30], for the search of underlying semantic categories or topics [31], since it reproduces the correct basic statistics of words, namely the Zipf’s and Heaps’ laws and Taylor’s law with exponent . In general, by choosing the underlying stochastic process, that defines the space of probability over which one performs the optimization, we steer the prediction on key statistical features of the system. In this perspective, adopting the best model becomes crucial, and the urn model with triggering opens the way for generalizations that go beyond exchangeability, for instance by considering semantic triggering, as already introduced in [12], thus posing the ground for more effective inference schemes.
Secondly, we extend the observation of Taylor’s law, referred to fluctuations in innovation rate, in several datasets, showing that a non-trivial behaviour of Taylor’s law seems to be universal in those systems. In particular, we consider four datasets related to human activities: (i) written language from a subset of the Gutenberg corpus of English texts; (ii) Twitter hashtags; (iii) a collaborative tagging system (Delicious); (vi) the list of temporarily ordered songs listened by many users in the Last.fm website. We observe how Taylor’s law of the actual sequences of events follows in all the dataset the form , with . Furthermore, we highlight how the randomized sequences, obtained by retaining all the elements of the original sequences and changing their temporal order (see Section 5 for details), show different behavior in the Gutenberg corpus and Last.fm compared to Twitter and Delicious. This issue remains still not fully explained, and leaves open the need of a deeper understanding of the process responsible for this behavior.
The paper is organized as follows. In the next section, we recall the urn model with triggering, devoting a particular emphasis to its connection with the two parameters Poisson–Dirichlet process [27,28]. We recall, in particular, how the urn model with triggering can be recast to be equivalent to the latter stochastic process. At the same time, it extends the Poisson–Dirichlet process in the region where the latter is not defined, i.e., in the region of linear innovation growth. In Section 3, relying on known results on triangular urn models [32,33], we characterize the limit distribution for the number of distinct elements and Taylor’s law for the urn model with triggering (Section 4). In Section 5, we discuss the Taylor’s law in the four datasets mentioned above. Finally, in Section 6, we discuss two different mechanisms that can increase the exponent of Taylor’s law at a value , as observed in the considered real-world systems.
2. The Urn Model with Triggering
The urn model with triggering, introduced in [12], is a minimal model based on Pólya’s urn able to reproduce the main statistical signatures of innovation processes, namely Zipf’s, Heaps’ and Taylor’s law. It casts in a mathematical framework the idea of the expansion into the adjacent possible [13,34,35] where the space of possibilities is continuously enlarged, due to the realization of part of them. A crucial element is thus correlations between the emergence of novel elements in the system. The model works as follows. An urn initially contains distinct balls of different colors. Then, at each time step t, a ball is drawn at random from the urn to construct a sequence of events, and it is put back in the urn. Further,
- if the color of the extracted ball is a new one, (it appears for the first time in , i.e., it is a realization of a novelty), then we add balls of the same color plus distinct balls of different new colors, which were not yet present in the urn; note that we use here the word new in two different acceptations: on one hand we refer to events that occur for the first time, on the other one to new colors that enter the space of events
- if the color of the extracted ball is already present in , we add balls of the same color.
Therefore, if is the color of the extracted ball at time and is the number of different colors extracted until time t, we have:
where . Moreover, if c denotes an old color, we have
where denotes the number of extractions of the color c until time t.
Values of the Model Parameters
Note that we have for each t when . The model can be defined also for , but this implies and for all t. Moreover, the value is possible, but in that case would not depend on , e.g., no reinforcement effect would be present. Therefore, we focus on the case , and .
In [24], an interesting particular case was highlighted. When , i.e., the above model corresponds to the Poisson–Dirichlet (PD) process, also called Chinese restaurant model [27,28,36]. Indeed, we have
More precisely, it corresponds to the PD process with parameters and . Note that the condition becomes (hence ) and so . The particular case is also known as Dirichlet process with parameter . Moreover, if we also set , we find a particular Dirichlet process, known as the Hoppe’s model [37]. The PD process is a well-known example of exchangeable “species sampling sequence” [27] and a generalization of this process with random weights can be found in [38].
3. Triangular Urn Schemes and Innovation Rate
Concerning the behavior of the number of distinct elements , the above urn model can be seen as a triangular two-color urn scheme [32,33,39,40]. More precisely, we can consider an urn model with the following dynamics. The urn initially contains black balls. Then, at each time step t, a ball is drawn at random from the urn and
- if the color of the extracted ball is black, then we replace the extracted ball with a white ball and we add white balls plus black balls;
- if the color of the extracted ball is white, we return the extracted ball in the urn together with additional white balls.
Therefore, in this urn scheme the extraction of a black (resp. white) ball corresponds to the extraction of a new (resp. old) color in the urn model with triggering. If we denote by and , respectively, the number of black and white balls in the urn at time step t and by a random variable taking values in such that if the extracted ball at time step t is black, then we have , and, for each ,
with and . A dynamics of this kind is a two-color urn model with triangular replacement matrix
The balance condition, which requires that the number of added balls is the same at each time step, independently of the color of the extracted ball, corresponds to the particular case . Recalling that we are assuming , and , the balance condition is possible only if . According to the above notation, we can write , , , so that . Therefore, when , the asymptotic behaviour of coincides with the one of and from the results in [32,33,39] (simply translating the results proven in that papers in terms of the considered model) we immediately obtain (in the following means almost sure convergence and means convergence in the distribution sense):
- (Case )where D is a suitable random variable with finite moments. In particular, when , the random variable D has probability density function given bywhere c is a normalizing constant and denotes the probability density function of the Mittag-Leffler distribution with parameter . Hence, for , we have
- (Case )andwhere Z is a suitable random variable.
- (Case )and the second-order behaviour depends on the value of . Precisely, denoting by the normal distribution with mean value equal to zero and variance equal to , we have:
- –
- for ,
- –
- for ,
- –
- for ,where V is a suitable random variable.
For the degenerate case , we trivially have for each t. Moreover, we recall that and . Hence, when , the asymptotic behaviour of follows from the results on (see [33]), that is we have
and
The balance condition with means and in this case we have a Dirichlet process with parameter and the above convergence results still hold true.
4. Taylor’s Law
The Taylor’s law connects the standard deviation of a random variable to its mean. In the considered model, when the balance condition is satisfied, we can obtain explicit formulas for the moments of : indeed, from [33,41], using the relation , we get for
Therefore, we find . For the Dirichlet process (, ), we simply have
and so .
To our knowledge, in the unbalanced case we have not explicit formulas for the first and the second asymptotic moments of . Here, we conjecture that suitable uniform integrability conditions hold for the convergence results in Section 3 in order to infer the convergence of the first two moments having only almost sure convergence and convergence in distribution (see, e.g., [42,43]). In other words, we leverage the convergence results in Section 3 in order to guess the corresponding Taylor’s law.
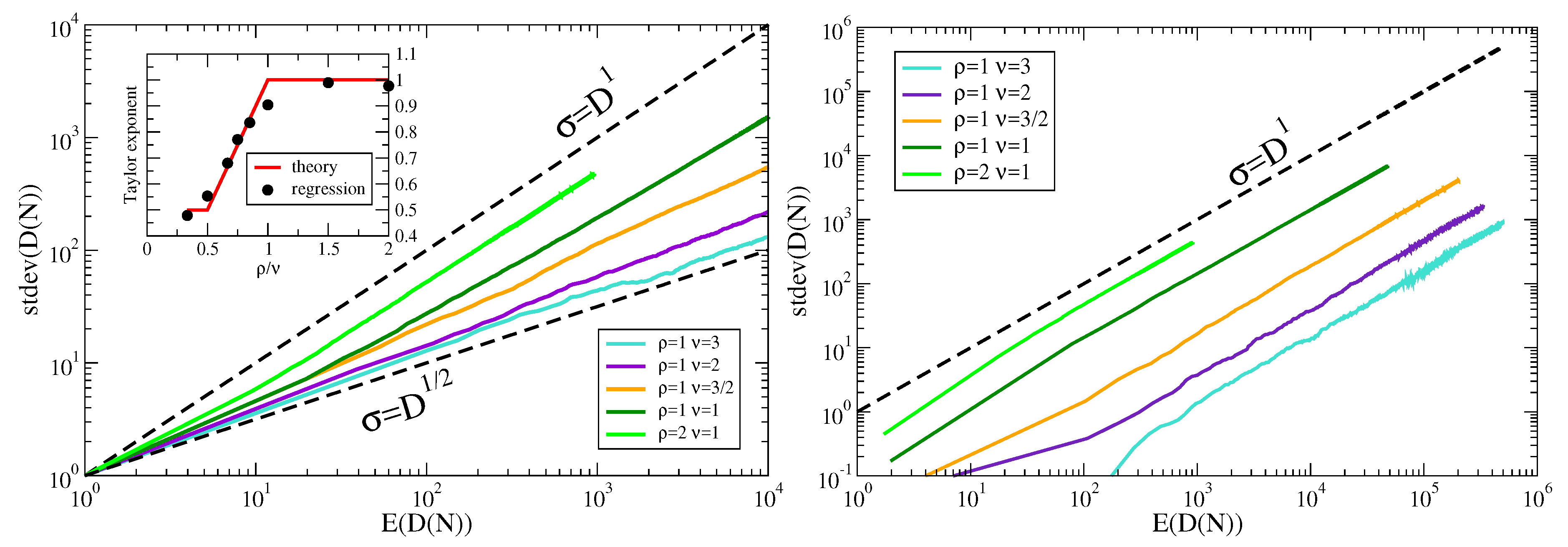
- (Case ) From the almost sure convergence (6), we guess , where the constant of proportionality is .
- (Case ) Since the limit in (7) is a constant, we can not exploit the almost sure convergence (7) in order to obtain a Taylor’s law as done for the previous case . However, from the convergence in distribution (8), we can guessandHence, combining together the above two limit relations, we find
- (Case ) Since for all t, the almost sure convergence (9) implies the convergence of the moments (see [43]) for that equation. However, it is not enough in order to get a Taylor’s law, but we need to use (10), (11) and (12). First of all, we observe thatHence:
- –
- for , we guess from (10) that the first term on the right hand of the above equality behaves as , while the second term is , and so we get andwith the constant of proportionality equal to ;
- –
- for , we guess from (11) that the first term on the right hand of the above equality behaves as , while the second term is and so we get andwith the constant of proportionality equal to ;
- –
- for , we guess from (12) that the first term and the second term on the right hand of the above equality behave as and respectively and so we get andwith the constant of proportionality equal to .
In the degenerate case , from the almost sure convergence (13) we guess . Moreover, we observe that
and, from the convergence in distribution (14), we guess that the first term on the right hand of above equality converges to , while the second term converges to zero. Hence, we find and so .
All the above theoretical predictions are supported by simulations, shown in Figure 1, left. We also report in Figure 1, right, the Taylor’s law for the corresponding reshuffled sequences, where the elements are the same as in the original sequences but the temporal order (their ordering in the sequence) is lost. For a discussion on the shuffling procedure see the next section.
5. Taylor’s Law in Real World Systems
We base our empirical analysis on four datasets whose content is the result of voluntary human activity. The first dataset consists of english written texts from the on-line collection of public domain books hosted at the Gutenberg project [44]. This dataset was crawled in year 2007. From that, we selected the longest 100 books. In this case, innovations are represented by new words entering the text. The second dataset contains the list of songs listened by 1000 Last.fm users until the 5th of May 2009 [45]. This list has been ordered according to the time of listening. Songs listened for the first time in the Last.fm platform are considered as innovations. The third dataset contains the time ordered list of tags in the platform Del.icio.us [46], where users used keywords (tags) to categorize bookmarked URLs. The dataset contains the tag sequence of users activity from early 2004 up to the end of 2006. The Del.icio.us platform has been discontinued. We treat as innovation the very first usage of a tag in Del.icio.us. The fourth and last dataset contains the time ordered sequence of the 10% of all the hashtags appeared in January 2013 on the micro-blogging platform Twitter [47]. Also in this database, we consider brand new hashtags entering the system as innovations. All these four datasets were already studied in previous works [12,14].
In order to estimate the average number of different tokens and their standard deviation, we preprocessed data such to split them into sequences of given fixed length. We use the generic term token to address the elements of the sequences, which are words in the Gutenberg dataset, song titles in Last.fm, tags in Del.icio.us and hashtags in Twitter. In Gutenberg we consider the natural splitting, each sequence being a book. To obtain sequences with the same length, we cut all the books at the length of the shortest one, so that we extracted the first 200,000 words of each of the 100 books. In Del.icio.us we took the last tags and split them into 1000 chunks with 20,000 tags each. In Last.fm, we selected the last titles and split them into 190 chunks of length 100,000. In Twitter we selected the last hashtags and created 346 chunks of length 100,000.
The estimation of the average number of distinct tokens, as well as the standard deviation, is done by determining the number of distinct tokens appeared before a certain position in all the split chunks in parallel. For example, in Gutenberg, we count the number of different words appeared after N total words for all the books and calculate
We plot these two quantities one against each other for each N and display the result in Figure 3.
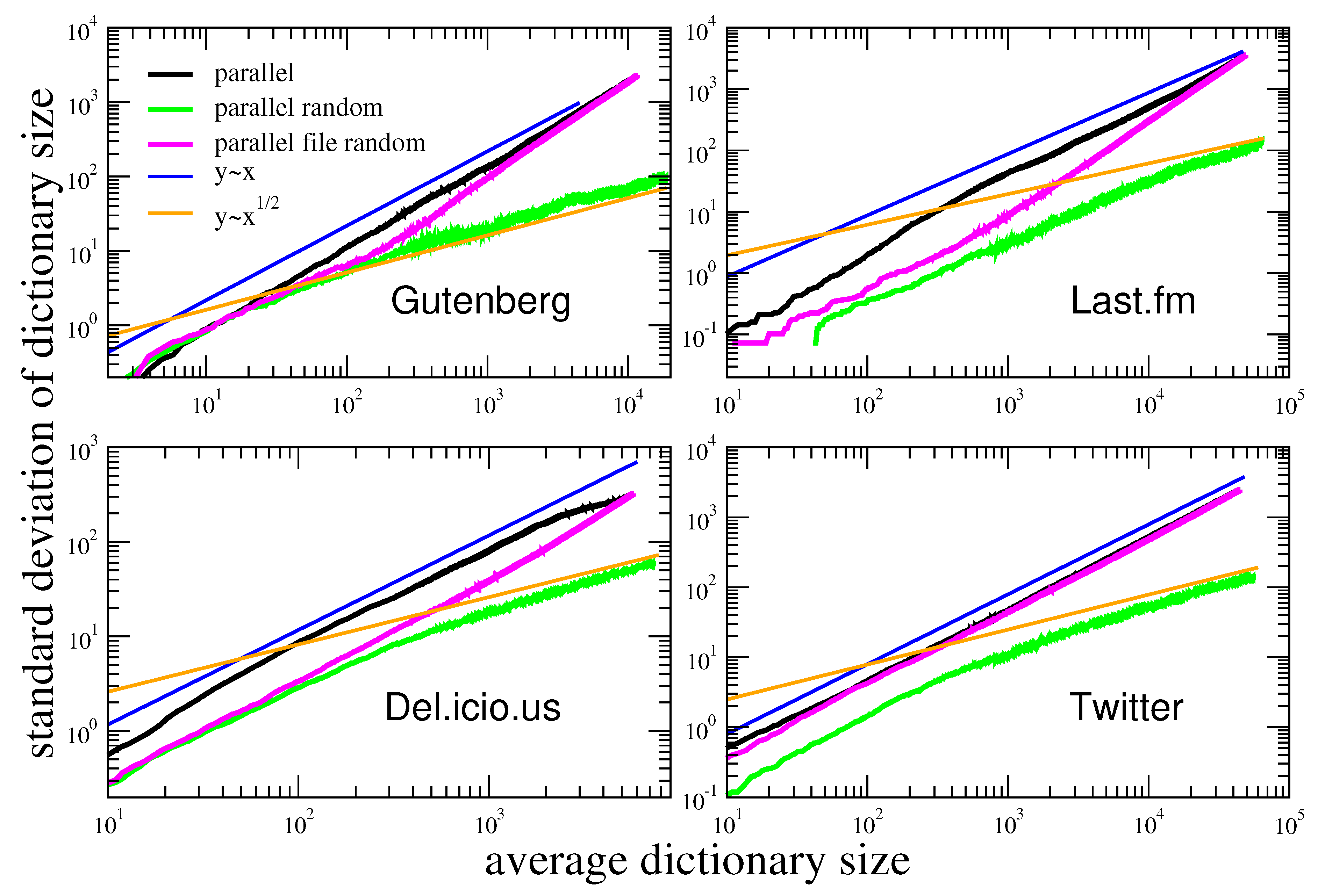
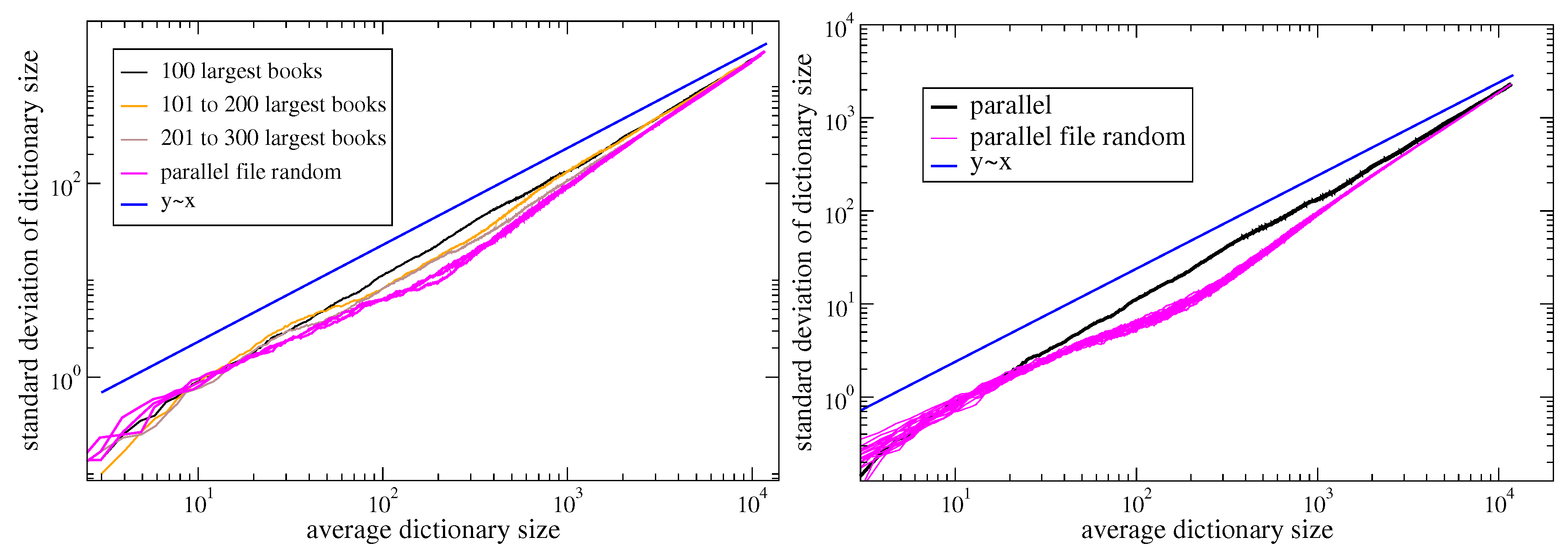
In order to evaluate the influence of the token macroscopic statistical properties, e.g., the Zipf’s law, on Taylor’s law, we destroy the correlations by reshuffling the sequences. We perform two different shuffles, with increasing randomization, as displayed in Figure 2. In the first one, which we denote as parallel file random, we shuffle the tokens inside the same sequence. In the other one, which we call parallel random, we shuffle the tokens throughout the all sequences. The results of these randomization schemes on Taylor’s law are shown in Figure 3. Let us first comment that the Del.icio.us and Twitter datasets feature a Taylor exponent, that is the exponent in the relation , approximately equal to one. This behavior is well reproduced by the urn model with triggering discussed in Section 2, in the parameters region (refer to Figure 1), that is the region where its exchangeable counterpart, namely the two parameters Poisson–Dirichlet process, is defined. Conversely, the Gutenbeng and Last.fm datasets show a significant deviation from the linear relation between the standard deviation and mean of , featuring a Taylor’s exponent . The simple urn model with triggering, as well as the two parameters Poisson–Dirichlet process, fails in predicting this deviation from an unitary exponent. However, simple generalization of the considered model can account for it. In the next section we will discuss two possible approaches leading to similar effect on the Taylor’s exponent. Before doing that, we wish to further comment on the results obtained on the reshuffled sequences. The parallel random procedure produces asymptotically a trivial (equal to ) Taylor’s exponent for all the datasets, and this reflects the fact that a random sampling from a power law distribution produces a Taylor’s exponent [7,21]. The (parallel file random) procedure poses the need to distinguish again the Gutenbeng and Last.fm datasets from Del.icio.us and Twitter. While in the latter datasets the locally reshuffled sequences behave essentially as the original (temporarily ordered) one, in the first two dataset a peculiar behavior of the locally reshuffled sequences emerges, similar in the two datasets and stable against different choices of sets of books in the Gutenberg dataset (Figure 4). The discrepancy between the Taylor’s law in the reshuffled sequences with respect to the original ones points to the fact that randomly sampling from different power law distributions cannot account for the observations, and a different dynamical process has to be considered. The exact mechanism leading to the observed behavior remains an open question, that calls for a more detailed analysis probably adopting hierarchical models, where correlations between the words distributions in different books are taken into account. This will be the topic of a further work.
6. Two Mechanisms that Increase Fluctuations
We here propose two mechanisms that generalize the basic model and that are able to account for that higher exponent. On the one hand, increasing fluctuations can be obtained by a quenched stochasticity in the model parameters. That is, each book can be considered as an instance of the considered stochastic process with parameters extracted from a given probability distribution. The term quenched refer to the fact that the parameters are extracted from each realization of the process and remain fixed all along the sequence generation. As a second mechanism, we consider the urn model with semantic triggering introduced in [12] to account for observed clusterization in the emergence on novelties.
6.1. Random Parameters
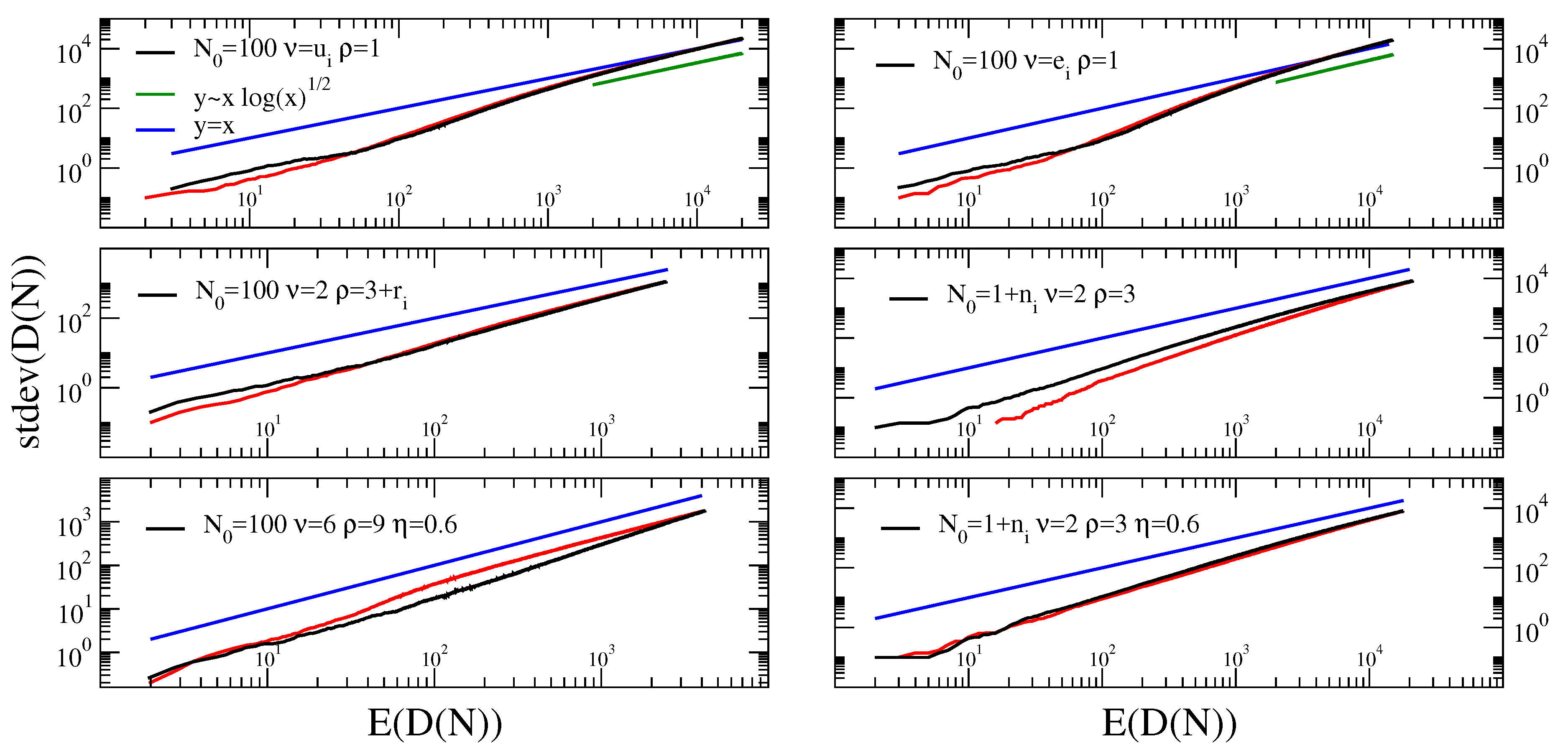
For the sake of analytical simplicity, we here discuss in detail only the case with as the random parameter. We show from simulations that similar behaviors are obtained when we take or as the random (Figure 5).
- (Case ) As seen before, the Taylor’s exponent in the case is always smaller than 1. Suppose now that and are constants and there exists a random variable , with , that gives the value of . Given the value of , the urn process behaves as described before. If is concentrated on , that is almost surely, then, on the event , the sequence converges almost surely to the value . Therefore, since is bounded, we have [43]Therefore, by setting , we findThis means that while a deterministic parameter gives a Taylor’s exponent smaller than 1, a random parameter , with almost surely, gives a Taylor’s exponent equal to 1.
- (Case ) As seen before, the Taylor’s exponent in the case is equal to 1. Suppose now, as before, that is a random variable, with , that gives the value of , while the other parameters are constant. If is concentrated on , that is almost surely, then, on the event , the sequence converges almost surely to a suitable random variable . Moreover, from [33], we haveAssuming, as in the previous section, a condition of uniform integrability, we can say thatwhere is the function given in (17) with . Similarly,where is the function given in (17) with .If we neglect the terms in the above mean values, we havewhere is the moment-generating function of . For instance, if is uniformly distributed on , we getand so . Finally, if we use the approximation , we obtain .Similarly, if is exponentially distributed on , that is with and , we getand so, as above, .From Figure 5 we see that the above predictions are valid asymptotically, after a long transient where a law , seems to be valid.
6.2. Urn Model with Semantic Triggering
For the sake of completeness, we recall here the urn model with semantic triggering introduced in [12], where it was shown that this generalization with respect to the basic model discussed in Section 2 was crucial in order to reproduce higher level features ruling the introduction of novelties in real systems. Let us again consider an urn initially containing distinct balls with different colors. Each ball is endowed by a color and by a label as well. Balls with different colors can share the same label, each label defining a semantic group, while balls with different labels necessarily have different colors. The balls belong to groups, the elements in the same group sharing a common label. In the following, we will say that an element a triggered the enter in the urn of the element b, if the element b is one of the elements added in the urn when a is drawn for the first time. We thus define the following process. To construct the sequence , we randomly choose the first element. Then, at each time step t:
- (i)
- we give weight 1 to: (a) each element in with the same label, say C, as (the last element added in the sequence), (b) to the element that triggered the enter in the urn of , and (c) to the elements triggered by ; a weight is given to any other element in ;
- (ii)
- The element is chosen by drawing randomly from , each element with a probability proportional to its weight;
- (iii)
- the element is added to the sequence and put back into along with additional copies of it;
- (iv)
- if and only if the chosen element is new (i.e., it appears for the first time in the sequence ), brand new distinct elements (balls with different colors, not yet present in the urn), all with a common brand new label, are added to .
We thus introduced a mechanism through which the occurrence of a ball with a given label facilitates further occurrences, close in time, of other balls with the same label, i.e., semantically related to it. Note that if the dynamics of this model reduces to that of the model described in Section 2. We do not analyzed in details the behavior of this model (the interested reader can refer to [12], but we remind here that it produces again power laws for the Heaps and Zipf’s laws, with exponents respectively and . The behavior for the Taylor’s law is reported in Figure 5 for some choices of the model parameters, showing that it also account for an exponent . For the sake of completeness, we show in Figure 5 also a case where the model with semantic triggering is coupled with a random choice of the model parameters, observing that this does not lead to any substantial different behavior.
7. Conclusions
In this paper, we discussed predictions for the Taylor’s law both of a recently introduced modeling scheme based on the notion of the adjacent possible [12], and in four open systems characterized by human activities, where a notion of innovation can be defined. We obtained rigorous mathematical predictions relying on known results for triangular urn models. We supported analytical results and conjectures with simulations of the discussed stochastic process. Further, contrasting model’s predictions and observations from real data, we proposed two, not necessary alternative, generalizations of the model to account for deviations of real data from a pure linear dependence of from . Namely, we consider the effect of a quenched stochasticity of the model parameters, and the introduction of semantic correlations, already discussed in [12].
By providing a rigorous mathematical framework to characterize the recently introduced urn model with triggering, the present paper opens the way to a deeper comprehension of the basic mechanisms underlying the observed universalities. On the other hand, a careful analysis of real data highlights relevant observables that unveil distinct behaviours in different systems, possibly due to varying degrees of correlations. A deeper understanding of this subtle behavior could shed some light on distinctive features of human language or on the cognitive and social pressure driving cultural production and fruition.
We finally note that we do not consider here hierarchical models, which we plan to investigate in further works. Hierarchical generalizations of the Poisson–Dirichlet process have proved to be extremely promising in inference problems adopting a Bayesian approach, such as topic modeling in textual corpora. We think that a hierarchical approach can be fundamental to reproduce further statistical features observed in written texts and not already fully explained, such, for instance, the double slope observed in Zipf’s law in large text corpora and the subtle behaviour of Taylor’s law discussed in Section 5.
Author Contributions
Conceptualization, F.T., I.C., G.A. and V.D.P.S.; Methodology, F.T., I.C., G.A. and V.D.P.S.; Software, F.T. and V.D.P.S.; Validation, F.T., I.C., G.A. and V.D.P.S.; Formal Analysis, F.T., I.C. and G.A.; Investigation, F.T., I.C., G.A. and V.D.P.S.; Resources, F.T and V.D.P.S.; Data Curation, F.T. and V.D.P.S.; Writing—Original Draft Preparation, F.T., I.C., G.A. and V.D.P.S.; Writing—Review & Editing, F.T., I.C., G.A. and V.D.P.S.; Visualization, F.T. and V.D.P.S.; Supervision, F.T. and I.C.; Project Administration, F.T. and I.C.; Funding Acquisition, F.T., I.C., G.A. and V.D.P.S. All authors have read and agreed to the published version of the manuscript.
Funding
F.T. is partially supported by the Sony CSL-Sapienza joint initiative. I.C. is partially supported by the Italian “Programma di Attività Integrata” (PAI), project “TOol for Fighting FakEs” (TOFFE) funded by IMT School for Advanced Studies Lucca. V.D.P.S. was supported by the Austrian Research Promotion Agency FFG under grant 857136.
Acknowledgments
F.T. and V.D.P.S. are grateful to V. Loreto for inspiring discussion and relevant suggestions. We thank G. Caldarelli for setting up this multidisciplinary collaboration. G.A. is a member of the Italian Group “Gruppo Nazionale per il Calcolo Scientifico” of the Italian Institute “Istituto Nazionale di Alta Matematica” and I.C. is a member of the Italian Group “Gruppo Nazionale per l’Analisi Matematica, la Probabilità e le loro Applicazioni” of the Italian Institute “Istituto Nazionale di Alta Matematica”.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zipf, G.K. Relative Frequency as a Determinant of Phonetic Change. Harv. Stud. Class. Philol. 1929, 40, 1–95. [Google Scholar] [CrossRef]
- Zipf, G.K. The Psychobiology of Language; Houghton-Mifflin: New York, NY, USA, 1935. [Google Scholar]
- Zipf, G.K. Human Behavior and the Principle of Least Effort; Addison-Wesley: Reading MA, USA, 1949. [Google Scholar]
- Herdan, G. Type-Token Mathematics: A Textbook of Mathematical Linguistics; Janua linguarum. series maior. no. 4; Mouton en Company: Berlin, Germany, 1960. [Google Scholar]
- Heaps, H.S. Information Retrieval-Computational and Theoretical Aspects; Academic Press: Cambridge, MA, USA, 1978. [Google Scholar]
- Taylor, L. Aggregation, Variance and the Mean. Nature 1961, 189, 732. [Google Scholar] [CrossRef]
- Eisler, Z.; Bartos, I.; Kertész, J. Fluctuation scaling in complex systems: Taylor’s law and beyond. Adv. Phys. 2008, 57, 89–142. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E.J. Power laws, Pareto distributions and Zipf’s law. Contemp. Phys. 2005, 46, 323–351. [Google Scholar] [CrossRef] [Green Version]
- Corominas-Murtra, B.; Hanel, R.; Thurner, S. Understanding scaling through history-dependent processes with collapsing sample space. Proc. Natl. Acad. Sci. USA 2015, 112, 5348–5353. [Google Scholar] [CrossRef] [Green Version]
- Cubero, R.J.; Jo, J.; Marsili, M.; Roudi, Y.; Song, J. Statistical Criticality arises in Most Informative Representations. J. Stat. Mech. 2019, 1906, 063402. [Google Scholar] [CrossRef] [Green Version]
- Lü, L.; Zhang, Z.K.; Zhou, T. Zipf’s law leads to Heaps’ law: Analyzing their relation in finite-size systems. PLoS ONE 2010, 5, e14139. [Google Scholar] [CrossRef] [Green Version]
- Tria, F.; Loreto, V.; Servedio, V.D.P.; Strogatz, S.H. The dynamics of correlated novelties. Sci. Rep. 2014, 4. [Google Scholar] [CrossRef] [Green Version]
- Kauffman, S.A. Investigations; Oxford University Press: New York, NY, USA, 2000. [Google Scholar]
- Monechi, B.; Ruiz-Serrano, A.; Tria, F.; Loreto, V. Waves of novelties in the expansion into the adjacent possible. PLoS ONE 2017, 12, e0179303. [Google Scholar] [CrossRef]
- Iacopini, I.; Milojević, S.C.V.; Latora, V. Network Dynamics of Innovation Processes. Phys. Rev. Lett. 2018, 120, 048301. [Google Scholar] [CrossRef] [Green Version]
- Kilpatrick, A.M.; Ives, A.R. Species interactions can explain Taylor’s power law for ecological time series. Nature 2003, 422, 65–68. [Google Scholar] [CrossRef]
- Ballantyne, F.; Kerkhoff, A.J. The observed range for temporal mean-variance scaling exponents can be explained by reproductive correlation. Oikos 2007, 116, 174–180. [Google Scholar] [CrossRef]
- Cohen, J.E.; Xu, M.; Schuster, W.S.F. Stochastic multiplicative population growth predicts and interprets Taylor’s power law of fluctuation scaling. Proc. Biol. Sci. 2013, 280, 20122955. [Google Scholar] [CrossRef] [Green Version]
- Cohen, J.E. Stochastic population dynamics in a Markovian environment implies Taylor’s power law of fluctuation scaling. Theor. Popul. Biol. 2014, 93, 30–37. [Google Scholar] [CrossRef]
- Giometto, A.; Formentin, M.; Rinaldo, A.; Cohen, J.E.; Maritan, A. Sample and population exponents of generalized Taylor’s law. Proc. Natl. Acad. Sci. USA 2015, 112, 7755–7760. [Google Scholar] [CrossRef] [Green Version]
- Gerlach, M.; Altmann, E.G. Scaling laws and fluctuations in the statistics of word frequencies. New J. Phys. 2014, 16, 113010. [Google Scholar] [CrossRef]
- Simon, H. On a class of skew distribution functions. Biometrika 1955, 42, 425–440. [Google Scholar] [CrossRef]
- Zanette, D.; Montemurro, M. Dynamics of Text Generation with Realistic Zipf’s Distribution. J. Quant. Linguist. 2005, 12, 29. [Google Scholar] [CrossRef]
- Tria, F.; Loreto, V.; Servedio, V.D.P. Zipf’s, Heaps’ and Taylor’s Laws are Determined by the Expansion into the Adjacent Possible. Entropy 2018, 20, 752. [Google Scholar] [CrossRef] [Green Version]
- Zabell, S. Predicting the unpredictable. Synthese 1992, 90, 205–232. [Google Scholar] [CrossRef]
- Pitman, J. Exchangeable and partially exchangeable random partitions. Probab. Theory Relat. Fields 1995, 102, 145–158. [Google Scholar] [CrossRef]
- Pitman, J. Combinatorial Stochastic Processes; Ecole d’Eté de Probabilités de Saint-Flour XXXII; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Pitman, J.; Yor, M. The two-parameter Poisson-Dirichlet distribution derived from a stable subordinator. Ann. Appl. Probab. 1997, 25, 855–900. [Google Scholar] [CrossRef]
- Buntine, W.; Hutter, M. A Bayesian View of the Poisson-Dirichlet Process. arXiv 2010, arXiv:1007.0296. [Google Scholar]
- Teh, Y.W. A Hierarchical Bayesian Language Model based on Pitman-Yor Processes. In Proceedings of the 21st International Conference on Computational Linguistics and the 44th annual meeting of the Association for Computational Linguistics, Sydney, Australia, 17–21 July 2006. [Google Scholar] [CrossRef]
- Du, L.; Buntine, W.; Jin, H. A segmented topic model based on the two-parameter Poisson-Dirichlet process. Mach. Learn. 2010, 81, 5–19. [Google Scholar] [CrossRef] [Green Version]
- Janson, S. Functional limit theorems for multiple branching processes and generalized Pólya urns. Stoch. Process. Appl. 2004, 110, 177–245. [Google Scholar] [CrossRef] [Green Version]
- Janson, S. Limit theorems for triangular urn schemes. Probab. Theory Relat. Fields 2006, 134, 417–452. [Google Scholar] [CrossRef] [Green Version]
- Kauffman, S.A. The Origins of Order: Self-Organization and Selection in Evolution; Oxford University Press: New York, NY, USA, 1993. [Google Scholar]
- Kauffman, S.A. Investigations: The Nature of Autonomous Agents and the Worlds They Mutually Create; SFI Working Papers; Santa Fe Institute: Santa Fe, NM, USA, 1996. [Google Scholar]
- James, L.F. Large Sample Asymptotics for the Two-Parameter Poisson-Dirichlet Process. Pushing the Limits of Contemporary Statistics: Contributions in Honor of Jayanta K. Ghosh; Institute of Mathematical Statistics: Beachwood, OH, USA, 2008; pp. 187–199. [Google Scholar]
- Hoppe, F.M. The sampling theory of neutral alleles and an urn model in population genetics. J. Math. Biol. 1987, 25, 123–159. [Google Scholar] [CrossRef] [Green Version]
- Bassetti, F.; Crimaldi, I.; Leisen, F. Conditionally identically distributed species sampling sequences. Adv. Appl. Probab. 2010, 42, 433–459. [Google Scholar] [CrossRef] [Green Version]
- Aguech, R. Limit theorems for random triangular urn schemes. J. Appl. Probab. 2009, 46, 827–843. [Google Scholar] [CrossRef] [Green Version]
- Mahmoud, H.M. Pólya Urn Models; Texts in Statistical Science Series; CRC Press: Boca Raton, FL, USA, 2009; p. xii+290. [Google Scholar]
- Flajolet, P.; Dumas, P.; Puyhaubert, V. Some exactly solvable models of urn process theory. DMTCS Proc. 2006, 59–118. [Google Scholar]
- DasGupta, A. Moment Convergence and Uniform Integrability. In Asymptotic Theory of Statistics and Probability; Springer Texts in Statistics; Springer: New York, NY, USA, 2008. [Google Scholar]
- Williams, D. Probability with Martingales; Cambridge Mathematical Textbooks; Cambridge University Press: Cambridge, UK, 1991; p. xvi+251. [Google Scholar] [CrossRef]
- Hart, M. Project Gutenberg. 1971. Available online: https://www.gutenberg.org/ (accessed on 18 May 2020).
- Miller, F.; Stiksel, M.; Breidenbruecker, M.; Willomitzer, T. Last.fm. 2002. Available online: https://www.last.fm/ (accessed on 7 April 2020).
- Schachter, J. del.icio.us. 2003. Available online: http://delicious.com/ (accessed on 8 January 2018).
- Jack, D.; Noah Glass, B.S.; Williams, E. Twitter.com. 2006. Available online: https://twitter.com/ (accessed on 7 April 2020).
Figure 1.
Taylor’s law in the urn model with triggering.Left: Taylor’s law from 100 realizations of the stochastic process described in Section 2 (the urn model with triggering), for each of the indicated values parameters. The values of parameters are chosen in order to have a representative curve for each of the analyzed regimes, i.e., , , , , . Each realization is a sequence of elements. Right: Taylor’s law from the same sequences as in the left side picture, individually reshuffled so that to loose the temporal order (refer to the parallel file random reshuffling procedure discussed in Section 5 and in Figure 2).
Figure 1.
Taylor’s law in the urn model with triggering.Left: Taylor’s law from 100 realizations of the stochastic process described in Section 2 (the urn model with triggering), for each of the indicated values parameters. The values of parameters are chosen in order to have a representative curve for each of the analyzed regimes, i.e., , , , , . Each realization is a sequence of elements. Right: Taylor’s law from the same sequences as in the left side picture, individually reshuffled so that to loose the temporal order (refer to the parallel file random reshuffling procedure discussed in Section 5 and in Figure 2).

Figure 2.
Shuffling procedures. In this example we consider three different streams A, B, C, consisting of five tokens each. When the analysis is carried in parallel the streams are aligned respecting their natural order (left panel). In the parallel file random case (middle panel), each stream is reshuffled singularly. Eventually, the parallel random case shuffles the elements all together (right panel).
Figure 2.
Shuffling procedures. In this example we consider three different streams A, B, C, consisting of five tokens each. When the analysis is carried in parallel the streams are aligned respecting their natural order (left panel). In the parallel file random case (middle panel), each stream is reshuffled singularly. Eventually, the parallel random case shuffles the elements all together (right panel).

Figure 3.
Taylor’s law in real systems and in their randomized instances. The standard deviation of the number of different tokens after N total tokens appeared, is plotted vs the average number of different tokens in four different datasets. The shuffled counterparts are also evaluated. The shuffling schemes are shown in Figure 2.
Figure 3.
Taylor’s law in real systems and in their randomized instances. The standard deviation of the number of different tokens after N total tokens appeared, is plotted vs the average number of different tokens in four different datasets. The shuffled counterparts are also evaluated. The shuffling schemes are shown in Figure 2.

Figure 4.
Stability of Taylor’s law results in the Gutenberg corpus.Left: the analogous of Figure 3 (top left) for three different sets of books from the Gutenberg corpus. Right: as in Figure 3 (top left), with 20 different realizations of the parallel file random reshuffling procedure. We see that the difference between the curve referred to the ordered sequences and those referred to the reshuffled ones is much higher than fluctuations due to different realizations of the reshuffling.
Figure 4.
Stability of Taylor’s law results in the Gutenberg corpus.Left: the analogous of Figure 3 (top left) for three different sets of books from the Gutenberg corpus. Right: as in Figure 3 (top left), with 20 different realizations of the parallel file random reshuffling procedure. We see that the difference between the curve referred to the ordered sequences and those referred to the reshuffled ones is much higher than fluctuations due to different realizations of the reshuffling.

Figure 5.
Taylor’s law in the urn model with triggering and quenched stochasticity of the parameters and in the urn model with semantic triggering.Top: Taylor’s law in the urn model with triggering, with parameter’s , and is randomly extracted for each simulation of the process from a uniform distribution on the interval (left) and from an exponential distribution on the interval and parameter (right), as discussed in the main text. Center: Taylor’s law in the urn model with triggering, with parameter’s respectively: (left) , , , with randomly extracted for each simulation of the process from an exponential distribution with mean ; , , , with randomly extracted for each simulation of the process from an exponential distribution with mean . Bottom: (left) Taylor’s law in the urn model with semantic triggering, with parameters , , , ; (right) Taylor’s law in the urn model with semantic triggering, with parameters , , , , with randomly extracted for each simulation of the process from an exponential distribution with mean . The parameters of the simulations were chosen such to lie in the regime . The parameter used in the bottom graphs was chosen in the regime where the Heaps’ and Zipfs’ laws feature exponents compatible with those observed in real systems. In all the figures the curves for the Taylor’s law are constructed from 100 independent realizations of the process (M = 100 in Equation (16)).
Figure 5.
Taylor’s law in the urn model with triggering and quenched stochasticity of the parameters and in the urn model with semantic triggering.Top: Taylor’s law in the urn model with triggering, with parameter’s , and is randomly extracted for each simulation of the process from a uniform distribution on the interval (left) and from an exponential distribution on the interval and parameter (right), as discussed in the main text. Center: Taylor’s law in the urn model with triggering, with parameter’s respectively: (left) , , , with randomly extracted for each simulation of the process from an exponential distribution with mean ; , , , with randomly extracted for each simulation of the process from an exponential distribution with mean . Bottom: (left) Taylor’s law in the urn model with semantic triggering, with parameters , , , ; (right) Taylor’s law in the urn model with semantic triggering, with parameters , , , , with randomly extracted for each simulation of the process from an exponential distribution with mean . The parameters of the simulations were chosen such to lie in the regime . The parameter used in the bottom graphs was chosen in the regime where the Heaps’ and Zipfs’ laws feature exponents compatible with those observed in real systems. In all the figures the curves for the Taylor’s law are constructed from 100 independent realizations of the process (M = 100 in Equation (16)).

© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Tria, F.; Crimaldi, I.; Aletti, G.; Servedio, V.D.P. Taylor’s Law in Innovation Processes. Entropy 2020, 22, 573. https://doi.org/10.3390/e22050573
AMA Style
Tria F, Crimaldi I, Aletti G, Servedio VDP. Taylor’s Law in Innovation Processes. Entropy. 2020; 22(5):573. https://doi.org/10.3390/e22050573
Chicago/Turabian StyleTria, Francesca, Irene Crimaldi, Giacomo Aletti, and Vito D. P. Servedio. 2020. "Taylor’s Law in Innovation Processes" Entropy 22, no. 5: 573. https://doi.org/10.3390/e22050573
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.