
Abstract
This paper presents a new optimized design to implement Fast Fourier Transform in orthogonal frequency division multiplexing for real valued signals. The proposed method is a new pipelined design, it is the combination of serial as well as parallel split and merge processing butterfly units. The proposed design initially has a single processing unit, in second stage, processing unit splits into two parallel processing units, and thereafter from stage three onwards, merges into a single processing until the last stage. The proposed design is optimized to reduce the latency as well as the hardware complexity for real inputs and complex inputs, as real valued signals itself reduce half of the computations, redundant data paths are eliminated effectively by this design. The parallel processing unit speeds up the processing at the initial stage, whereas single processing units reduce the hardware complexity. This design is a solution for ambiguity between Latency and hardware. The proposed design is very effective for real valued signals. The proposed design is implemented in Radix-22 model, in which multipliers are required for every two stages. The proposed design reduces Latency parameter more than 50% with a small cost of adders and multipliers, also power consumption for higher order FFT’s is low.















Similar content being viewed by others

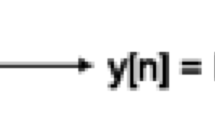

References
Rabiner, L. R., & Gold, B. (1975). Theory and application of digital signal processing. Englewood Cliffs, NJ: Prentice-Hall Inc.
Guan, W., & Xiang, H. (2012). Low-complexity channel estimation using short-point FFT/IFFT for an iterative receiver in an LDPC-coded OFDM system. Wireless Personal Communications, 64(4), 739–747.
Cooley, J. W., & Tukey, J. W. (1965). An algorithm for the machine calculation of complex Fourier series. Mathematics of Computation, 19(90), 297–301.
Wold, E. H., & Despain, A. M. (1984). Pipeline and parallel-pipeline FFT processors for VLSI implementations. IEEE Transactions on Computers, 5, 414–426.
Hassan, S. L. M., Sulaiman, N., & Halim, I. S. A. (2018) Low power pipelined FFT processor architecture on FPGA. In 2018 9th IEEE control and system graduate research colloquium (ICSGRC) (pp. 31–34).
Bi, G., & Jones, E. V. (1989). A pipelined FFT processor for word-sequential data. IEEE Transactions on Acoustics, Speech and Signal Processing, 37(12), 1982–1985.
Parhi, K. K., Wang, C.-Y., & Brown, A. P. (1992). Synthesis of control circuits in folded pipelined DSP architectures. IEEE Journal of Solid-State Circuits, 27(1), 29–43.
Swartzlander, E. E., Jain, V. K., & Hikawa, H. (1992). A radix-8 wafer scale FFT processor. Journal of VLSI Signal Processing Systems for Signal, Image and Video Technology, 4(2–3), 165–176.
Sundararajan, M., & Govindaswamy, U. (2014). Multicarrier spread spectrum modulation schemes and efficient FFT algorithms for cognitive radio systems. Electronics, 3(3), 419–443.
Thyagaturu, A. S., Alharbi, Z., & Reisslein, M. (2018). R-FFT: Function split at IFFT/FFT in unified LTE CRAN and cable access network. IEEE Transactions on Broadcasting, 64(3), 648–665.
Shih, X.-Y., Chou, H.-R., & Liu, Y.-Q. (2017). VLSI design and implementation of reconfigurable 46-mode combined-radix-based FFT hardware architecture for 3GPP-LTE applications. IEEE Transactions on Circuits and Systems I: Regular Papers, 65(1), 118–129.
Kanders, H., Mellqvist, T., Garrido, M., Palmkvist, K., & Gustafsson, O. (2019). A 1 million-Point FFT on a single FPGA. IEEE Transactions on Circuits and Systems I: Regular Papers, 66(10), 3863–3873.
Yazicioglu, R. F., Merken, P., Puers, R., & Van Hoof, C. (2006). Low-power low-noise 8-channel EEG front-end ASIC for ambulatory acquisition systems. In 2006 proceedings of the 32nd European solid-state circuits conference (pp. 247–250).
Noor, S. M., John, E., & Panday, M. (2018). Design and implementation of an ultralow-energy FFT ASIC for processing ECG in cardiac pacemakers. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 27(4), 983–987.
Sekhar, B. R., & Prabhu, K. M. M. (1999). Radix-2 decimation-in-frequency algorithm for the computation of the real-valued FFT. IEEE Transactions on Signal Processing, 47(4), 1181–1184.
Andersson, R. (2013). FFT hardware architectures with reduced twiddle factor sets.
Lin, Y.-T., Tsai, P.-Y., & Chiueh, T.-D. (2005). Low-power variable-length fast Fourier transform processor. IEE Proceedings-Computers and Digital Techniques, 152(4), 499–506.
Yeh, W.-C., & Jen, C.-W. (2003). High-speed and low-power split-radix FFT. IEEE Transactions on Signal Processing, 51(3), 864–874.
Yang, L., Zhang, K., Liu, H., Huang, J., & Huang, S. (2006). An efficient locally pipelined FFT processor. IEEE Transactions on Circuits and Systems II Express Briefs, 53(7), 585–589.
Shin, M., & Lee, H. (2008). A high-speed four-parallel radix-2 4 FFT/IFFT processor for UWB applications. In 2008 IEEE international symposium on circuits and systems (pp. 960–963).
Ayinala, M., & Parhi, K. K. (2013). FFT architectures for real-valued signals based on radix-23 and radix-24 algorithms. IEEE Transactions on Circuits and Systems I: Regular Papers, 60(9), 2422–2430.
Garrido, M., Parhi, K. K., & Grajal, J. (2009). A pipelined FFT architecture for real-valued signals. IEEE Transactions on Circuits and Systems I: Regular Papers, 56(12), 2634–2643.
Yang, K.-J., Tsai, S.-H., & Chuang, G. C. H. (2012). MDC FFT/IFFT processor with variable length for MIMO–OFDM systems. IEEE Transactions on Circuits and Systems I: Regular Papers, 21(4), 720–731.
Langemeyer, S., Pirsch, P., & Blume, H. (2011). A FPGA architecture for real-time processing of variable-length FFTs. In 2011 IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 1705–1708).
Ayinala, M., Brown, M., & Parhi, K. K. (2012). Pipelined parallel FFT architectures via folding transformation. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 20(6), 1068–1081.
Garrido, M., Grajal, J., Sanchez, M. A., & Gustafsson, O. (2011). Pipelined radix-2k feedforward FFT architectures. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 21(1), 23–32.
Salehi, S. A., Amirfattahi, R., & Parhi, K. K. (2013). Pipelined architectures for real-valued FFT and hermitian-symmetric IFFT with real datapaths. IEEE Transactions on Circuits and Systems II: Express Briefs, 60(8), 507–511.
Glittas, A. X., Sellathurai, M., & Lakshminarayanan, G. (2016). A normal I/O order radix-2 FFT architecture to process twin data streams for MIMO. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 24(6), 2402–2406.
Nash, J. (2018). Distributed-memory-based FFT architecture and FPGA implementations. Electronics, 7(7), 116.
Nguyen, H., Khan, S., Kim, C.-H., & Kim, J.-M. (2018). A Pipelined FFT processor using an optimal hybrid rotation scheme for complex multiplication: Design, FPGA implementation and analysis. Electronics, 7(8), 137.
Chen, S.-G., Huang, S.-J., Garrido, M., & Jou, S.-J. (2014). Continuous-flow parallel bit-reversal circuit for MDF and MDC FFT architectures. IEEE Transactions on Circuits and Systems I: Regular Papers, 61(10), 2869–2877.
Tang, T., Pan, J., Yang, D., & Wang, E. (2018). Frequency measurement by FFT based on FPGA. In 2018 IEEE 3rd advanced information technology, electronic and automation control conference (IAEAC) (pp. 453–456).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
1.1 Latency Convergence Phenomenon
The latency convergence curve for 16-input pipelined FFT is with respect to parallel units is shown in Fig. 16, 1-parallel to 8-parallel units along x-axis and latency along y-axis. The curve clearly shows that 1-parallel designs has very high latency and 8-parallel design has no latency and as the number of parallel units increases Latency reduces.

Latency convergence curve
The proposed design is in between 1 and 2 parallel designs, so that in the it is represented as 1.5. The proposed design with additional one BU unit placed based on the reduction of latency. The optimum reduction in latency is obtained by splitting the BU units in appropriate stage.
1.2 Optimum Reduction in Latency
Figure 17 shows the latency comparison of proposed split and merge designs, with different stages of splitting. The one parallel design has very high latency, split and merge in stage 2(sp2) has lower latency compared to third(sp3) and fourth stage(sp4) splitting.so that optimum reduction in latency is obtained with the splitting section in 1-parallel pipelined architecture is placed in stage-2.

Optimum reduction in latency using split and merge design
1.3 Statistical Data Analysis of the Proposed Method
Figure 18 shows correlation analysis of the proposed design with some existing designs. in almost all designs throughput is highly correlated and utilization of hardware is moderately correlated. The statistical data analysis of the number of adders and latency is for N = 16 is measured in Rx643.5.3 with estimation package.

Correlation comparison Analysis of proposed design with existing designs
The histogram of number adders and latency is shown in Fig. 19, it clearly shows that histogram is uniform, QQ plot is shown in Fig. 20. The correlation analysis shown in Fig. 21, it shows that the latency of proposed design is highly uncorrelated to existing designs, number of adders are weakly correlated to existing designs.

Histogram of adders and latency

QQ plot of number of adders and latency

Correlation analysis of number of adders and latency
1.4 Butterfly Units (BU)
The internal operation of the Butterfly Unit is shown in Fig. 22, BU1, BU21 and BU22 are the butterfly units for processing real signals, Bu1 is the butterfly unit in stage -1, BU21 and BU22 are the two parallel butterfly units in stage-2, BU3 and BU4 are butterfly units in stage -3 and stage-4. The internal design of BU unit for real signal consists of two real adders, whereas for complex signals requires four real adders.

Butterfly unit. a Complex signals, b real signals
Rights and permissions
About this article

Cite this article
Prasanna Kumar, G., Krishna, B.T. & Pushpa, K. Optimized Pipelined Fast Fourier Transform Using Split and Merge Parallel Processing Units for OFDM. Wireless Pers Commun 117, 3067–3089 (2021). https://doi.org/10.1007/s11277-020-07471-3
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11277-020-07471-3