
Abstract
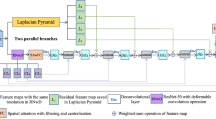
Encoder–decoder structure is an universal method for semantic image segmentation. However, some important information of images will lost with the increasing depth of convolutional neural network (CNN), and the correlation between arbitrary pixels will get worse. This paper designs a novel image segmentation model to obtain dense feature maps and promote segmentation effects. In encoder stage, we employ ResNet-50 to extract features, and then add a spatial pooling pyramid (SPP) to achieve multi-scale feature fusion. In decoder stage, we provide an improved position attention module to integrate contextual information effectively and remove the trivial information through changing the construction way of attention matrix. Furthermore, we also propose the feature fusion structure to generate dense feature maps by preforming element–wise sum operation on the upsampling features and corresponding encoder features. The simulation results illustrate that the average accuracy and mIOU on CamVid dataset can reach 90.7% and 63.1% respectively. It verifies the effectiveness and reliability of the proposed method.













Similar content being viewed by others

References
Kaneko AM, Yamamoto K (2016) Landmark recognition based on image characterization by segmentation points for autonomous driving. In: IEEE sice international symposium on control systems, pp 1–8
Xu W, Li B, Liu S, Qiu W (2018) Real-time object detection and semantic segmentation for autonomous driving. Autom Target Recognition Navig. https://doi.org/10.1117/12.2288713
Hong C, Yu J, Zhang J, Jin X, Lee KH (2018) Multimodal face-pose estimation with multitask manifold deep learning. IEEE Trans Ind Inf 15(7):3952–3961
Yu J, Tao D, Wang M, Rui Y (2014) Learning to rank using user clicks and visual features for image retrieval. IEEE Trans Cybern 45(4):767–779
Hong C, Yu J, Tao D, Wang M (2014) Image-based three-dimensional human pose recovery by multiview locality-sensitive sparse retrieval. IEEE Trans Ind Electron 62(6):3742–3751
Breiman L (2001) Random forests. IEEE Trans Pattern Anal Mach Intell 45(1):5–32
Kontschieder P, Bulo SR, Bischof H, Pelillo M (2011) Structuredclass-labels in random forests for semantic image labelling. In: International conference on computer vision, pp 2190–2197
Shotton J, Johnson M, Cipolla R (2008) Semantic texton forests for image categorization and segmentation. IEEE Trans Pattern Anal Mach Intell 5(7):1–8
Aneja J, Deshpande A, Schwing AG (2018) Convolutional image captioning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 5561–5570
Papandreou G, Kokkinos I, Savalle PA (2015) Modeling local and global deformations in deep learning: epitomic convolution, multiple instance learning, and sliding window detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 390–399
Yao J, Yu Z, Yu J, Tao D (2020) Single pixel reconstruction for one-stage instance segmentation. IEEE TCYB. https://doi.org/10.1109/TCYB.2020.2969046
Yu J, Tan M, Zhang H, Tao D, Rui Y (2019) Hierarchical deep click feature prediction for fine-grained image recognition. IEEE Trans Pattern Anal Mach Intell. https://doi.org/10.1109/TPAMI.2019.2932058
Zhang J, Yu J, Tao D (2018) Local deep-feature alignment for unsupervised dimension reduction. IEEE Trans Image Process 27(5):2420–2432
LeCun Y, Boser B, Denker J, Henderson D, Howard RE, Hubbard W, Jackel LD (1989) Backpropagation applied to handwritten zip code recognition. Neural Comput 1(4):541–551
He K–M, Zhang X–Y, Ren S–Q, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 770–778
Krizhevsky A, Sutskever I, Hinton GE (2012) ImageNet classification with deep convolutional neural networks. In: Proceedings of the advances in neural information processing systems, pp 1097–1105
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556
Szegedy C, Liu W, Jia Y, Sermanet P, Reed S, Anguelov D, Erhan D, Vanhoucke V, Rabinovich A (2015) Going deeper with convolutions. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1–9
Yan Z, Zhang H, Piramuthu R, Jagadeesh V, DeCoste D, Di W, Yu Y (2015) HD-CNN: hierarchical deep convolutional neural networks for large scale visual recognition. In: Proceedings of the IEEE international conference on computer vision, pp 2740-2748
Long J, Shelhamer E, Darrell T (2015) Fully convolutional networks for semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3431–3440
Noh H, Hong S, Han B (2015) Learning deconvolution network for semantic segmentation. arXiv preprint arXiv:1505.04366
Jegou S, Drozdzal M, Vazquez D, Romero A, Bengio Y (2017) The one hundred layers tiramisu: fully convolutional denseNets for semantic segmentation. In: IEEE conference on computer vision and pattern recognition workshops, pp 11–19
Visin F, Ciccone M, Romero A, Kastner K, Cho K, Bengio Y, Matteucci M, Courville A (2016) Reseg: A recurrent neural network-based model for semantic segmentation. In: IEEE conference on computer vision and pattern recognition workshops, pp 41–48
Badrinarayanan V, Kendall A, Cipolla R (2017) SegNet: a deep convolutional encoder–decoder architecture for scene segmentation. IEEE Trans Pattern Anal Mach Intell 39(12):2481–2495
Chen L–C, Papandreou G, Kokkinos I, Murphy K, Yuille AL (2015) Semantic image segmentation with deep convolutional nets and fully connected CRFs. In: International conference on learning representations, pp 357–361
Chen L-C, Papandreou G, Kokkinos I, Murphy K, Yuille AL (2017) DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans Pattern Anal Mach Intell 40(4):834–848
Ren Z, Kong Q, Han J, Plumbley MD, Schuller BW (2019) Attention-based atrous convolutional neural networks: visualisation and understanding perspectives of acoustic scenes. In: Proceedings of the advances in international conference on acoustics, speech and signal processing, pp 56–60
Zhu H-G, Wang B-Y, Zhang X-D, Liu J-H (2020) Semantic image segmentation with shared decomposition convolution and boundary reinforcement structure. Appl Intell. https://doi.org/10.1007/s10489-020-01671-x
Huang G, Liu Z, Van Der Maaten L, Weinberger KQ (2017) Densely connected convolutional networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4700–4708
Ronneberger O, Fischer P, Brox T (2015) U-net: convolutional networks for biomedical image segmentation. In: International conference on medical image computing and computer-assisted intervention, pp 234–241
Dubuissonjolly M, Gupta A (2000) Color and texture fusion: application to aerial image segmentation and gis updating. Image Vis Comput 18(10):823–832
Hazirbas C, Ma L, Domokos C, Cremers D (2016) Fusenet: incorporating depth into semantic segmentation via fusion-based cnn architecture. In: Asian conference on computer vision Springer, pp 213–228
Dai J, He K, Sun J (2015) Boxsup: exploiting bounding boxes to supervise convolutional networks for semantic segmentation. In: IEEE International conference on computer vision, pp 1635–1643
Li H, Xiong P, Fan H–Q, Sun J (2019) Dfanet: Deep feature aggregation for real-time semantic segmentation. In: Proceedings of the ieee conference on computer vision and pattern recognition, pp 9522–9531
Saleh FS, Aliakbarian MS, Salzmann M, Petersson L, Alvarez JM (2018) Effective use of synthetic data for urban scene semantic segmentation. In: European conference on computer vision, pp 86-103
He K, Zhang X, Ren S, Sun J (2014) Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans Pattern Anal Mach Intell 37(9):1904–1916
Fu J, Liu J, Tian HJ, Li Y, Bao YJ, Fang ZW, Lu HQ (2019) Dual attention network for scene segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3146–3154
Yu C–Q, Wang J–B Peng C, Gao C–X, Yu G, Sang N (2018) Learning a discriminative feature network for semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1857–1866
Yu T, Yu J, Yu Z, Tao D (2019) Compositional attention networks with two-stream fusion for video question answering. IEEE Trans Image Process. https://doi.org/10.1109/TIP.2019.29406772019
Zhao H, Shi J, Qi X, Wang X, Jia J (2017) Pyramid scene parsing network. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2881–2890
Yu J, Zhu C, Zhang J, Huang Q, Tao D (2020) Spatial pyramid-enhanced NetVLAD with weighted triplet loss for place recognition. IEEE Trans Neural Netw Learn Syst 31(2):661–674
Gong Y, Wang L, Guo R, Lazebnik S (2014) Multi-scale orderless pooling of deep convolutional activation features. In: European conference on computer vision, pp 392–407
Brostow G, Fauqueur J, Cipolla R (2009) Semantic object classes in video: a high-definition ground truth database. Pattern Recogn Lett 30(2):88–97
Acknowledgements
This study was funded by the National Key R&D Program of China (No. 2017YFF0108800), the Fundamental Research Funds for the Central Universities (No. N2005032).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Zhu, H., Miao, Y. & Zhang, X. Semantic Image Segmentation with Improved Position Attention and Feature Fusion. Neural Process Lett 52, 329–351 (2020). https://doi.org/10.1007/s11063-020-10240-9
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11063-020-10240-9