
Abstract
Learnae is a system aiming to achieve a fully distributed way of neural network training. It follows a “Vires in Numeris” approach, combining the resources of commodity personal computers. It has a full peer-to-peer model of operation; all participating nodes share the exact same privileges and obligations. Another significant feature of Learnae is its high degree of fault tolerance. All training data and metadata are propagated through the network using resilient gossip protocols. This robust approach is essential in environments with unreliable connections and frequently changing set of nodes. It is based on a versatile working scheme and supports different roles, depending on processing power and training data availability of each peer. In this way, it allows an expanded application scope, ranging from powerful workstations to online sensors. To maintain a decentralized architecture, all underlying tech should be fully distributed too. Learnae’s coordinating algorithm is platform agnostic, but for the purpose of this research two novel projects have been used: (1) IPFS, a decentralized filesystem, as a means to distribute data in a permissionless environment and (2) IOTA, a decentralized network targeting the world of low energy “Internet of Things” devices. In our previous work, a first approach was attempted on the feasibility of using distributed ledger technology to collaboratively train a neural network. Now, our research is extended by applying Learnae to a fully deployed computer network and drawing the first experimental results. This article focuses on use cases that require data privacy; thus, there is only exchanging of model weights and not training data.













Similar content being viewed by others
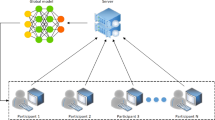

Notes
Bitswap homepage, https://github.com/ipfs/specs/tree/master/bitswap
IOTA Foundation homepage, https://www.iota.org
Serguei Popov, “The Tangle”, https://iota.org/IOTA_Whitepaper.pdf
HEPMASS Dataset homepage, http://archive.ics.uci.edu/ml/datasets/hepmass
References
Nikolaidis S, Refanidis I (2019) Learnae: distributed and resilient deep neural network training for heterogeneous peer to peer topologies. In: International conference engineering applications of neural networks, pp 286–298
Abadi M, Barham P, Chen J, Chen Z, Davis A, Dean J, Devin M, Ghemawat S, Irving G, Isard M, Kudlur M, Levenberg J, Monga R, Moore S, Murray DG, Steiner B, Tucker P, Vasudevan V, Warden P, Wicke M, Yu Y, Zheng X (2016) TensorFlow: a system for large-scale machine learning. In: Proceedings of the 12th USENIX symposium on operating systems design and implementation, pp 265–283
Dean J, Corrado GS, Monga R, Chen K, Devin M, Le QV, Mao M, Razato M, Senior A, Tucker P, Yang K, Ng AY (2012) Large scale distributed deep networks In: Advances in neural information processing systems, pp 1223–1231
Dekel O, Gilad-Bachrach R, Shamir O, Xiao L (2012) Optimal distributed online prediction using mini-batches. J Mach Learn Res 13:165–202
Li M, Andersen DG, Smola AJ, Yu K (2014) Communication efficient distributed machine learning with the parameter server In: Advances in neural information processing systems (NIPS), 2014
Zhang S, Choromanska A, LeCun Y (2015) Deep learning with elastic averaging SGD. In: Advances in neural information processing systems, pp 685–693
Niu F, Recht B, Re C, Wright SJ (2011) “HOGWILD!: A lock-free approach to parallelizing stochastic gradient descent”, arXiv:1106.5730v2, 2011
Shokri R, Shmatikov V (2015) Privacy-preserving deep learning. In: Proceedings of the 22nd ACM SIGSAC, 2015, pp 1310–1321
Zinkevich M, Weimer M, Li L, Smola AJ (2010) Parallelized stochastic gradient descent. In: advances in neural information processing systems (NIPS)
McDonald R, Hall K, Mann G (2010) Distributed training strategies for the structured perceptron. In: Proceedings of North American chapter of the association for computational linguistics (NAACL)
Chen T, Li M, Li Y, Lin M, Wang N, Wang M, Xiao T, Xu B, Zhang C, Zhang Z (2015) MXNet: a flexible and efficient machine learning library for heterogeneous distributed systems. In: Proceedings of learningsys, 2015
Iandola FN, Ashraf K, Moskewicz MW, Keutzer K (2015) FireCaffe: near-linear acceleration of deep neural network training on compute clusters. In: Proceedings of the IEEE conference on computer vision and pattern recognition
Lian X, Zhang C, Zhang H, Hsieh CJ, Zhang W, Liu J (2017) Can decentralized algorithms outperform centralized algorithms? A case study for decentralized parallel stochastic gradient descent. In: Advances in neural information processing systems (NIPS)
Jiang Z, Balu A, Hegde C, Sarkar S (2017) Collaborative deep learning in fixed topology networks. In: Advances in neural information processing systems (NIPS)
Lian X, Zhang W, Zhang C, Liu J 2018 Asynchronous decentralized parallel stochastic gradient descent. In: Proceedings of international conference on machine learning (ICML)
Yu H, Yang S, Zhu S (2018) Parallel restarted SGD with faster convergence and less communication: demystifying why model averaging works for deep learning”, arXiv:1807.06629
Agarwal A, Duchi JC (2011) Distributed delayed stochastic optimization. In: NIPS, 2011
Feyzmahdavian HR, Aytekin A, Johansson M (2016) An asynchronous mini-batch algorithm for regularized stochastic optimization. IEEE Trans Autom Control 61:3740
Paine T, Jin H, Yang J, Lin Z, Huang T (2013) Gpu asynchronous stochastic gradient descent to speed up neural network training, arXiv:1312.6186
Recht B, Re C, Wright S, Niu F (2011) Hogwild: a lock-free approach to parallelizing stochastic gradient descent. In: Advances in neural information processing systems
Seide F, Fu H, Droppo J, Li G, Yu D (2014) 1-bit stochastic gradient descent and its application to data-parallel distributed training of speech DNNs. In: Annual conference of the international speech communication association (INTERSPEECH)
Alistarh D, Grubic D, Li J, Tomioka R, Vojnovic M (2017) QSGD: Communication-efficient SGD via gradient quantization and encoding. In: Advances in neural information processing systems (NIPS)
Wen W, Xu C, Yan F, Wu C, Wang Y, Chen Y, Li H (2017) Terngrad: ternary gradients to reduce communication in distributed deep learning. In: Advances in neural information processing systems (NIPS)
Strom N (2015) Scalable distributed DNN training using commodity GPU cloud computing. In: Annual conference of the international speech communication association (INTERSPEECH)
Dryden N, Moon T, Jacobs SA, Van Essen B (2016) Communication quantization for data-parallel training of deep neural networks. In: Workshop on machine learning in HPC environments (MLHPC)
Aji AF, Heafield K (2017) Sparse communication for distributed gradient descent. In: Conference on empirical methods in natural language processing (EMNLP)
McMahan HB, Moore E, Ramage D, Hampson S, et al (2017) Communication-efficient learning of deep networks from decentralized data. In: International conference on artificial intelligence and statistics (AISTATS)
Benet J, IPFS-content addressed, versioned, P2P File System”, arXiv:1407.3561, 2014
Mashtizadeh AJ, Bittau A, Huang YF, Mazieres D (2013) Replication, history, and grafting in the ori file system. In: Proceedings of the twenty-fourth ACM symposium on operating systems principles, ACM, 2013 pp 151–166
Cohen B (2003) Incentives build robustness in bittorrent. In: Workshop on economics of peer-to-peer systems, vol 6. pp 68–72
Baumgart I, Mies S (2007) S/kademlia: a practicable approach towards secure key based routing. In: Parallel and distributed systems international conference
Freedman MJ, Freudenthal E, Mazieres D (2004) Democratizing content publication with coral. NSDI 4:18–18
Wang L, Kangasharju J (2013) Measuring large-scale distributed systems: case of bittorrent mainline dht. In: 2013 IEEE thirteenth international conference, IEEE, 2013 pp 1–10
Levin D, LaCurts K, Spring N, Bhattacharjee B (2008) Bittorrent is an auction: analyzing and improving bittorrent’s incentives. In: ACM SIGCOMM computer communication review, vol 38. ACM, pp 243–254
Dean J, Ghemawat S (2011) Leveldb–a fast and lightweight key/value database library by google
Popov S, Saa O, Finardi P (2018) Equilibria in the tangle arXiv:1712.05385, 2018
Coates A, Huval B, Wang T Wu D, Catanzaro B, Andrew N (2013) Deep learning with cots hpc systems. In: Proceedings of the 30th international conference on machine learning, 2013, pp 1337–1345
Zhang X, Trmal J, Povey D, Khudanpur S (2014) Improving deep neural network acoustic models using generalized maxout networks. In: Acoustics, speech and signal processing (ICASSP), 2014 IEEE international conference, 2014
Miao Y, Zhang H, Metze F (2014) Distributed learning of multilingual dnn feature extractors using GPUs. In: Fifteenth Annual Conference of the International Speech Communication Association
Povey D, Zhang X, Khudanpur S (2014) Parallel training of deep neural networks with natural gradient and parameter averaging. arXiv:1410.7455
Seide F, Fu H, Droppo J, Li G, Yu D (2014) 1-bit stochastic gradient descent and its application to data-parallel distributed training of speech dnns. In: Fifteenth annual conference of the international speech communication association,
Acknowledgements
This research is funded by the University of Macedonia Research Committee as part of the “Principal Research 2019” funding program.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Nikolaidis, S., Refanidis, I. Privacy preserving distributed training of neural networks. Neural Comput & Applic 32, 17333–17350 (2020). https://doi.org/10.1007/s00521-020-04880-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-020-04880-0