
Abstract
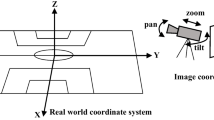
Given an image sequence featuring a portion of a sports field filmed by a moving and uncalibrated camera, such as the one of the smartphones, our goal is to compute automatically in real time the focal length and extrinsic camera parameters for each image in the sequence without using a priori knowledges of the position and orientation of the camera.To this end, we propose a novel framework that combines accurate localization and robust identification of specific keypoints in the image by using a fully convolutional deep architecture.Our algorithm exploits both the field lines and the players’ image locations, assuming their ground plane positions to be given, to achieve accuracy and robustness that is beyond the current state of the art.We will demonstrate its effectiveness on challenging soccer, basketball, and volleyball benchmark datasets.









Similar content being viewed by others


References
Alvarez, L., Caselles, V.: Homography estimation using one ellipse correspondence and minimal additional information. In: International Conference on Image Processing, pp. 4842–4846 (2014)
Bay, H., Ess, A., Tuytelaars, T., Van Gool, L.: SURF: speeded up robust features. Comput. Vis. Image Underst. 10(3), 346–359 (2008)
Calonder, M., Lepetit, V., Strecha, C., Fua, P.: BRIEF: binary robust independent elementary features. In: European Conference on Computer Vision, pp. 778–792 (2010)
Cao, Z., Simon, T., Wei, S., Sheikh, Y.: Realtime multi-person 2D pose estimation using part affinity fields. In: Conference on Computer Vision and Pattern Recognition, pp. 1302–1310 (2017)
Chen, J., Zhu, F., Little, J.J.: A two-point method for PTZ camera calibration in sports. In: IEEE Winter Conference on Applications of Computer Vision, pp. 287–295 (2018)
Chen, J., Little, J.J.: Sports camera calibration via synthetic data. In: Conference on computer vision and pattern recognition (Workshops) (2019)
David, P., Dementhon, D., Duraiswami, R., Samet, H.: SoftPOSIT: simultaneous pose and correspondence determination. Int. J. Comput. Vis. 59(3), 259–284 (2004)
Fischler, M., Bolles, R.: Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 24(6), 381–395 (1981)
Gupta, A., Little, J.J., Woodham, R.: Using line and ellipse features for rectification of broadcast hockey video. In: Canadian Conference on Computer and Robot Vision, pp. 32–39 (2011)
Hartley, R., Zisserman, A.: Multiple View Geometry in Computer Vision. Cambridge University Press, Cambridge (2000)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Homayounfar, N., Fidler, S., Urtasun, R.: Sports field localization via deep structured models. In: Conference on Computer Vision and Pattern Recognition, pp. 4012–4020 (2017)
Ibrahim, M.S., Muralidharan, S., Deng, Z., Vahdat, A., Mori, G.: A hierarchical deep temporal model for group activity recognition. In: Conference on Computer Vision and Pattern Recognition, pp. 1971–1980 (2016)
Isard, M., Blake, A.: Condensation—conditional density propagation for visual tracking. Int. J. Comput. Vis. 1, 5–28 (1998)
Jiang, W., Higuera, J.C.G., Angles, B., Sun, W., Javan, M., Yi, K.M.: Optimizing Through Learned Errors for Accurate Sports Field Registration. In: IEEE Winter Conference on Applications of Computer Vision (2019)
Kendall, A., Grimes, M., Cipolla, R.: Posenet: a convolutional network for real-time 6-DOF camera relocalization. In: International Conference on Computer Vision, pp. 2938–2946 (2015)
Kingma, D., Ba, J.: Adam: a method for stochastic optimisation. In: International Conference on Learning Representations (2015)
Liu, S., Chen, J., Chang, C., Ai. Y.: A new accurate and fast homography computation algorithm for sports and traffic video analysis. In: IEEE Transactions on Circuits and Systems for Video Technology, pp. 2993–3006 (2018)
Lowe, D.: Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 20(2), 91–110 (2004)
Moreno-Noguer, F., Lepetit, V., Fua, P.: Pose priors for simultaneously solving alignment and correspondence. In: European Conference on Computer Vision, pp. 405–418 (2008)
Ronneberger, O., Fischer, P., Brox, T.: U-Net: convolutional networks for biomedical image segmentation. In: Conference on Medical Image Computing and Computer Assisted Intervention, pp. 234–241 (2015)
Sattler, T., Maddern, W., Toft, C., Torii, A., Hammarstrand, L., Stenborg, E., Safari, D., Okutomi, M., Pollefeys, M., Sivic, J., Kahl, F., Pajdla, T.: Benchmarking 6DOF outdoor visual localization in changing conditions. In: Conference on Computer Vision and Pattern Recognition (2018)
Second Spectrum (2015). http://www.secondspectrum.com/
Sharma, R.A., Bhat, B., Gandhi, V., Jawahar, C.V.: Automated top view registration of broadcast football videos. In: IEEE Winter Conference on Applications of Computer Vision, pp. 305–313 (2018)
Tompson, J., Goroshin, R., Jain, A., LeCun, Y., Bregler, C.: Efficient object localization using convolutional networks. In: Conference on Computer Vision and Pattern Recognition, pp. 648–656 (2015)
Acknowledgements
This work was supported in part under an Innosuisse Grant funding the collaboration between Second Spectrum and EPFL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Appendices
Appendix
From homography to camera parameters
Let us consider a \(w \times h\) image I along with the homography \(\mathbf {H}\) between ground plane and its image plane, which is to be decomposed into \(\mathbf {K}\) and \(\mathbf {M}= [\mathbf {R},\mathbf {t}]\), a \(3 \times 3\) matrix of intrinsic parameters, and a \(3 \times 4\) matrix of extrinsic parameters, as defined in Sect. 3.1. In this section, we outline how to derive \(\mathbf {M}\) and \(\mathbf {K}\) from \(\mathbf {H}\). For a full treatment, we refer the interested reader to [10].
Intrinsic parameters In practice, the principal point of modern cameras is located close to the center of the image and there is no skew. We can therefore write
where f is the initially unknown focal length and the only parameter to be estimated. It can be shown that knowing \(\mathbf {H}\), two linear constraints on the intrinsics parameters can be solved for the unknown f which yield two solutions of the form:
where \(\mathbf {h_1}\) and \(\mathbf {h_2}\) are the first two columns of \(\mathbf {H}\), \(h_7\) and \(h_8\) the first two elements of \(\mathbf {H}\) third row, and \(g_1\), \(g_2\) are algebraic functions.
\(f_1\) and \(f_2\) are only defined when the denominators are nonzero and the closer to zero they are, the less the precision. In practice we compare the value of these denominators and use the following heuristic
Extrinsic parameters To extract the rotation and translation matrices \(\mathbf {R}\) and \({\mathbf {t}}\) from \(\mathbf {H}\), we first define the \(3 \times 3\) matrix \({\mathbf {B}}=[\mathbf {b_1}, \mathbf {b_2}, \mathbf {b_3} ]\) and a scale factor \(\lambda \) to write \(\mathbf {H}\) as \(\lambda \mathbf {K}{\mathbf {B}}\). \(\lambda \) can be computed as \((||\mathbf {K}^{-1} \mathbf {h_1} ||+||\mathbf {K}^{-1} \mathbf {h_2} ||)/2\). Then, assuming that the x-axis and y-axis define the ground plane, we obtain a first estimate of the rotation and translation matrices \({\tilde{\mathbf {R}}} = [{\mathbf {b}}_1, {\mathbf {b}}_2, \mathbf {b_1} \times \mathbf {b_2} ]\), and \({\mathbf {t}}=\mathbf {b_3}\). We orthogonalize the rotation using singular value decomposition \({\tilde{\mathbf {R}}} = {\mathbf {U}} {\varvec{\Sigma }} \mathbf {V^T}, \ \mathbf {R}= {\mathbf {U}}\mathbf {V^T}\). Finally, we refine the pose \([\mathbf {R},{\mathbf {t}} ]\) on \(\mathbf {H}\) by nonlinear least-squares minimization.
Complete framework
Recall from Sect. 3.2 that at each discrete time step t, we estimate the 2D locations of our keypoints \({\hat{\mathbf {z}}}^t\), which are noisy and sometimes plain wrong. As seen in Sect. A, they can be used to estimate the intrinsic and extrinsic parameters \(\mathbf {M}_d^t\) and \(\mathbf {K}^t\) for single frames. The intrinsic parameters computed from a single frame are sensitive to noise and depend on the accuracy of \(\mathbf {H}^t\); for this reason, at every time step t we estimate their values by considering past k frames. We perform outlier rejection over the past k estimate of the intrinsics and then compute the median, and this allows to increase robustness and precision admitting smooth variations of the parameters over time. If the parameter is known to be constant over time, k can be set so to consider all past estimates. Once the intrinsics are computed, we obtain the new robust pose \(\mathbf {M}^t\) from the filter and minimize the error in the least-squares sense using all the detected keypoints.
This particle filter is robust but can still fail if the camera moves very suddenly. To detect such events and re-initialize it, we keep track of the number of 3D model points whose reprojection falls within a distance t for the pose computed from point correspondences \({{\hat{\mathbf {M}}}}_d^t\) and the filtered pose \({{\hat{\mathbf {M}}}}^t\). When the count for \({{\hat{\mathbf {M}}}}_d^t\) is higher, we re-initialize the filter.
The pseudocode shown in Algorithm 1 summarizes these steps.

Intersection over union (IoU) of the visible area
In [24], the intersection-over-union metric is computed using only the area of the court that is visible in the image. This area is shown in gray in Fig. 10. After superimposition of the projected model (red frame) with the ground-truth one (blue frame) the area of the court that is not visible in the image is removed and therefore not taken into account in the computation of the IoU. It can be shown that the IoU of the gray area gives a perfect score, while in reality the estimate is far from correct. The worst case scenario is when the viewpoint leads to an image containing only grassy area of the playing field. In this case, as long as the projected model covers the ground-truth one, this metric gives perfect score. For this reason, we discourage the use of this version of IoU.

Example failure case of the intersection-over-union metric that only uses the visible part of the court in the image. The ground-truth model is shown in blue, the re-projected one is shown in red, and the gray area is the projected image plane. This version of IoU would give perfect score, while the one that takes the whole template into account would give around 0.6
Rights and permissions
About this article

Cite this article
Citraro, L., Márquez-Neila, P., Savarè, S. et al. Real-time camera pose estimation for sports fields. Machine Vision and Applications 31, 16 (2020). https://doi.org/10.1007/s00138-020-01064-7
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00138-020-01064-7