
Abstract
Short term food security issues require reliable crop forecasting data to identify the population at risk of food insecurity and quantify the anticipated food deficit. The assessment of the current early warning and crop forecasting system which was designed in mid 80’s identified a number of deficiencies that have serious impact on the timeliness and reliability of the data. We developed a new method to forecast maize yield across smallholder farmers’ fields in Tanzania (Morogoro, Kagera and Tanga districts) by integrating field-based survey with a process-based mechanistic crop simulation model. The method has shown to provide acceptable forecasts (r2 values of 0.94, 0.88 and 0.5 in Tanga, Morogoro and Kagera districts, respectively) 14–77 days prior to crop harvest across the three districts, in spite of wide range of maize growing conditions (final yields ranged from 0.2–5.9 t/ha). This study highlights the possibility of achieving accurate yield forecasts, and scaling up to regional levels for smallholder farming systems, where uncertainties in management conditions and field size are large.
Similar content being viewed by others

1 Introduction
Crop yield forecasts provide a distribution of expected yield prior to crop harvests (Basso and Liu 2019). Knowing the expected yield of major food commodities in advance of harvesting is critical for national food security (Jayne and Rashid 2010; Stone and Meinke 2005). At a national level, food production forecasts are used for to make decisions on importing or exporting food commodities and their trading prices (Delincé 2017). Food policies regarding trading affect national food supply and food security in Africa (Wright and Cafiero 2011; Sitko et al. 2018). At a field level, food supply is determined by crop productivity. In-season crop yield forecasts provide management suggestions to optimize resource use efficiency (e.g. nitrogen fertilizer) and to achieve yield potential at a field level (Raun et al. 2005; Zinyengere et al. 2011).
Many countries have institutional infrastructure for operational crop yield forecasts for strategic planning. Government agencies are involved in providing information about field conditions, crop status and weather conditions to release multiple stage yield forecasts before planting, during the growing season, and prior to harvest (Gennari and Fonteneau 2016). The assessment of the current early warning and crop forecasting system which was designed in mid 80’s identified a number of deficiencies that have serious impact on the timeliness and reliability of the data (Basso and Liu 2019; Gennari and Fonteneau 2016; Luo et al. 2011).
There are three major approaches to forecasting crop yield: expert-based assessments (e.g. interviews and field surveys), statistical models, and process-based models (Basso and Liu 2019). Interviews with farmers can provide subjective expectations on end-of-season yield (Nandram et al. 2014; Pease et al. 1993). Field surveys with crop cutting provide objective yield estimate prior to harvesting. Statistical models apply different techniques (regression, Bayesian approaches, machine learning techniques) to relate historical yield records to historical within-season agrometeorological variables, variables derived from remotely sensed vegetation indices and/or crop simulation model outputs to predict yield based on the growing-season information (Johnson 2014; Lobell et al. 2015). Crop simulation models produce not only end-of-season yield but also yield distributions based on crop genotypes, soil conditions, typical management practices, and in-season weather based on historical climate or weather forecasts, or by assimilating remotely sensed information (Arkin et al. 1980; Jones et al. 2017; Kadaja et al. 2009; Reynolds et al. 2000).
Despite the extensive studies on yield forecasting methodology, most of the work has been done for developed nations where fields are likely to be large with one single crop per growing season, while only a small fraction of the literature has focused on yield forecasting methods for smallholder farming systems, either pure stands or intercropping (Basso and Liu 2019). Much work done so far in yield prediction has explored the use of statistical agrometeorological models, where yield is forecasted based on in-season agronomic (e.g. leaf area index, fertilizer use, and planting date) and meteorological data, either from observations or derived from satellites (Basso and Liu 2019; Choularton and Krishnamurthy 2019; Coughlan de Perez et al. 2019). Because the accuracy is constrained by the ranges of agrometeorological conditions that were included in the model development, the scalability of the statistical models to different years, to other regions and to other crops is limited (Katz 1977). A few researchers have used process-based model with previous seasonal weather data to provide yield forecasts for sorghum in Burkina Faso (Mishra et al. 2008), and within-season satellite-derived rainfall estimate for maize yield forecasting in South Africa and Kenya (Lourens and De Jager 1997; Reynolds et al. 2000).
A recent advance in the statistical models for yield forecasts for smallholder farmers was the development of regression models with growing-season weather, remotely sensed vegetation indices, and crop simulation model outputs and their applications to estimate final yield (Burke and Lobell 2017; Lobell et al. 2015). This approach relies on growing-season weather information (e.g. rainfall in the last months of the growing season) or vegetation indices (e.g. peak normalized difference vegetation index) and provides yield estimates before the end of the growing season.
The lead time and skills of maize yield forecasts are limited for smallholder maize cropping systems in Africa. In most studies, the yield forecast was delivered at harvest time but not during the growing season (Basso and Liu 2019). One attempt was made to forecast maize yield using agrometeorological models, which were based on both climatic variables from weather stations and vegetation indices derived from satellite imageries, at initial and vegetative stage in Kenya (Rojas 2007). The reported r-squared values from the forecasted and observed yield regression model were mostly less than 0.5 when the forecasts were made at vegetative or reproductive stage (Mkhabela et al. 2005; Rojas 2007; Schauberger et al. 2017). A few cases in Kenya and Swaziland had higher correlation between the forecasted yield, made a few months before harvest, and the final yield, with r-squared values greater than 0.7 (Mkhabela et al. 2005; Rojas 2007). Others used regression models to forecast yield in Zimbabwe and Botswana at maturity based on climatic variables (Manatsa et al. 2011; Vossen 1990) and satellite derived vegetation indices (Kuri et al. 2014; Unganai and Kogan 1998), and obtained adequate forecasting accuracy, with r-squared values over 0.8. It has also been noted that forecasting procedures, particularly when statistically based, performed much worse when applied to smallholder farming systems in Africa, compared to large farms in the US (Azzari et al. 2017; Schauberger et al. 2017).
In this study, we present a new maize yield forecasting method that provides yield forecast for governmental agencies before the crop is harvested (14–77 days prior to harvest). The objective of this paper was to develop and validate a new method to forecast maize grain yield based on the integration of field survey and crop simulation model in three regions in the United Republic of Tanzania (Tanzania hereafter).
2 Materials and methods
2.1 Context of the research project
Accurate and reliable crop yield forecasting data to identify the population at risk of food insecurity and quantify the anticipated food deficit is a key policy concern of the Government of Tanzania. The current forecasting system of Tanzania presents a number of deficiencies that have serious impact on the timeliness and reliability of the data.
Improvement of the crop forecasting system was one of the actions identified under Strategic Objective 3 (“rationalize statistical operations and processes, improving quality and relevance to users of agriculture statistics data”) of Tanzania Agricultural Statistics Strategic Plan (ASSP) recently prepared and adopted by the government. This research project, designed to develop a new and practical method to provide accurate and timely crop yield forecasts for the Government of Tanzania, was selected under the framework of the Global Strategy to Improve Agricultural and Rural Statistics coordinated by the United Nations Food and Agriculture Organization (UN FAO TCP URT 3504).
2.2 Descriptions of the new yield forecasting method
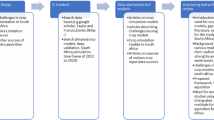
The new yield forecasting method presented in this study is based on the integration of field based surveys and the process-based crop simulation model SALUS (Systems Approach to Land Use Sustainability) (Fig. 1).

Overview of the new yield forecasting method based on the integration of field surveys and the SALUS crop simulation model
2.2.1 Description of the SALUS crop model
The SALUS model is a process-based crop simulation model (Basso et al. 2006; Basso and Ritchie 2015). The model uses daily weather information (minimum and maximum temperature, precipitation, and solar radiation), soil layer properties (e.g. clay and silt content, bulk density, and organic carbon content), management (e.g. planting dates, planting density, and fertilization rates) and crop genetics parameters (growth duration, maximum kernel number and filling rate) as inputs. The model simulates agronomic outputs (e.g. yield, total biomass, leaf area index) and environmental outcomes (e.g. nitrate leaching, greenhouse gas emission, water fluxes, soil carbon dynamics) on a daily basis. The SALUS model was adapted from the CERES model with various improvements in the soil nutrient and soil water dynamics (Basso et al. 2016b). The three interconnected modules — crop growth and development, soil nutrient dynamics, and water balance modules — are the main components of the SALUS model. SALUS initializes soil carbon, and nitrogen (N) pools using the procedure developed by Basso et al. (2011). The SALUS model does not have an explicit module to account for pest, weeds and diseases. The detailed descriptions of the model and key algorithms have been presented in Basso et al. (2006), Dzotsi et al. (2013) and Ritchie and Basso (2008) and Basso et al. (2018).
The SALUS model has been validated for various cropping systems under different climatic conditions. It has been validated to simulate maize and pigeonpea aboveground biomass and grain yield under the humid subtropical and the tropical savanna climate in Malawi (Liu and Basso 2017). Other SALUS model testing includes grain yield (Basso and Ritchie 2015), soil water content (Basso et al. 2010; Hamilton et al. 2015), soil carbon (Cillis et al. 2018; Pezzuolo et al. 2017), and soil nitrate and nitrate leaching (Basso et al. 2016a; Giola et al. 2012) under the Mediterranean and humid continental climates. For this study, we tested SALUS model to evaluate its capability to reproduce interannual maize grain yield at regional level (Fig. S1–2).
In this study, we ran SALUS using weather, crop, soil, and management inputs that captured possible scenarios reported by field surveys. The weather data in the study were based on the 0.25°-resolution AgMIP climate forcing based on the Modern-Era Retrospective Analysis (AgMERRA) dataset and the 0.05°-resolution Climate Hazards Group InfraRed Precipitation with Station (CHRIPS) dataset (Funk et al. 2015; Ruane et al. 2015). We extracted daily temperature and solar radiation data in 1981–2010 from the AgMEERA, and daily precipitation data from the CHIRPS gridded dataset. We used three maize cultivars in the simulations to represent short, medium and long duration cultivars (Fig. S3). We included four options to describe soils: poor, medium, fertile and extremely fertile (Table S1). Management practices (planting densities, N fertilizer application rates irrigation amounts) were reported by field survey information for the districts of Morogoro, Kagera, and Tanga).
2.2.2 Field questionnaire survey
Currently, the Government of Tanzania collects in season information from farmers’ fields using 7 field questionnaire surveys to monitor crop conditions and forecast crop yield and production. We designed a simple questionnaire to collect field data as model input on agronomic management, weather and plant information.
Management information included data on number of plants present in selected fields at the time of the field survey, maize cultivar characteristics (short versus long duration), planting time, planting density, fertilizers and irrigation amounts and timing of applications. For the weather conditions, we asked qualitative descriptions of the current growing-season temperature and rainfall conditions when compared to historical averages (options included: hotter than normal, colder than normal, normal, drier than normal, wetter than normal). For the plant conditions at the survey date, we asked the enumerators to take photos of the maize plants grown in the fields to detect presence of diseases, weeds and insects. The questionnaire is available in the online supplementary material.
During the season, data collection, both interviews and field sampling, were conducted by 55 enumerators to complete the questionnaire. A quadrant design method was used to collect planting density and plant condition information. One or two experimental plots (6 × 6 meter) were first randomly established at each sampling field. Quadrants were then formed within the experimental plot. Planting density was based on the number of plants across the four quadrants. Two plants in each quadrant were randomly marked for the end-of-season field survey. In the end-of-season field survey, crop cut and kernel numbers were performed to estimate grain yield. Cobs in the experimental plots were harvested and weighed. The two plants previously marked within each quadrant were sampled for total number of kernels and kernel weight. The kernel information was then converted to determine the grain yield.
2.2.3 Yield forecast method
The SALUS crop model was executed using a combination of a series of soils, weather, genotypes and management practices. The method searched for the simulation scenarios that best represented the growing season conditions reported by the field survey questionnaire, and the simulated yields of the selected simulations served as one of the forecasted yields depending on the remaining weather to reach crop maturity. For each of the sampling fields, the yield forecasting algorithm used the reported coordinates to identify historical weather scenarios among the climate dataset, and then selected years in which temperature and precipitation matched the reported in-season temperature and precipitation characteristics. The algorithm first grouped historical years into three categories based on the 33.3th and 66.7th percentile values of average seasonal temperature in 1981–2010. Years where the in-season average temperature was less than 33.3th percentile of the average temperature in 1981–2010 were categorized as colder than normal; years where the in-season average temperature was more than 66.7th percentile of the average temperature in 1981–2010 were categorized as hotter than normal; years where the in-season average temperature was between the 33.3th and 66.7th values was normal. Similarly, years were also grouped into drier than normal, normal and wetter than normal categories based on the 33.3th and 66.7th percentile values of total seasonal precipitation in 1981–2010. The algorithm then selected weather series where the temperature and precipitation categories matched with the reported in-season weather characteristics. In the cases where the no historical record was found to match with both in-season temperature and precipitation characteristics, the algorithm prioritized matching with the reported precipitation condition. The algorithm narrowed management scenarios based on the reported planted time, plant densities, and fertilizer and irrigation applied. The yield forecasting algorithm used the reported maize duration to exclude simulation scenarios in which the duration did not match the reported value. The yield forecasting algorithm used the overall evaluation of the field to select soil used in the simulations. The reported stress level due to water and nitrogen deficit, together with the photos taken during the survey determined the overall field condition. We developed a protocol to evaluate the overall condition of maize fields based on the photos and reported stress level. When a field had maize with healthy dark green leaves and relatively thick stalks, it was categorized as extremely good condition. When the plant was mostly dark green but under minor stress, it was categorized as in good condition. Medium condition indicated plants with light green leaves and under nitrogen and/or water deficit stress. Poor condition indicated short plants with yellow-green leaves and thin stalks and were under severe stress level. We used the photo to cross check the reported stress level due to water and nitrogen deficit and biotic stressors (i.e. weeds, pests and diseases). The selected simulation scenarios (at least one simulation runs) contained combinations of the selected weather, management, crop and soil scenarios, which resulted from the yield forecasting algorithm. Lastly, the simulated yields of the selected simulations were adjusted based on the severity of insects, weeds and diseases. We applied a 15% reduction to the simulated yield when the severity of insects, weeds or diseases was reported minor, and a 30% reduction when the severity was reported major (Tollenaar et al. 1994). The simulated yields, with adjustment for weeds and insects if reported, were the forecasted yield for each sampling field.
2.3 Study sites and date collection
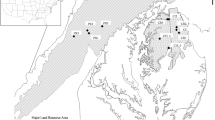
The method was applied to three districts in Tanzania, Morogoro, Kagera and Tanga. The study sites were selected by officials from the Government of Tanzania and the UN FAO (Fig. 2a). The three districts have equatorial climate but have distinct agro-climatic characteristics (Kottek et al. 2006). Kagera is located in northern Tanzania and has bimodal rainfall pattern, where short rain starts in October and ends in December, and long rains start in March and end in May. Tanga is located in northeastern Tanzania and also has bimodal rainfall pattern. Maize is widely cultivated in Tanga whereas banana is an important crop in Kagera (Smale and Tushemereirwe 2007). Morogoro is located in central Tanzania transitioning between bimodal and unimodal rainfall (unimodal rainfall occurs between November and May) (Paavola 2008).

Sampling locations across Morogoro, Kagera and Tanga districts of Tanzania. a Map of Tanzania and the three districts, b spatial distribution of sampling fields in Morogoro, c spatial distribution of sampling fields in Kagera and (c) spatial distribution of sampling fields in Tanga
A total of 92 sampling fields across three districts were determined. Specifically, 28 sampling fields were located across Morogoro, 39 across Kagera and 25 across Tanga. The enumerators conducted within-season field questionnaire surveys spanning from late April to June 2017 for Morogoro, from mid-January to the end of February for Kagera, and from late January to late March for Tanga. The majority of the surveys were completed by end of May in Morogoro, and by early January in Kagera and Tanga. Of the predetermined sampling fields, 17 fields in Morogoro had maize plant that were not mature during the in-season field survey, as well as 24 fields in Kagera and 21 fields in Tanga (Fig. 2b-c). For the remaining fields, maize either reached maturity (11 fields in Morogoro, 13 in Kagera and 4 in Tanga) or the field survey was incomplete (two fields in Kagera), and thus they were not included in the analysis. The 62 sampling fields were across 55 households in the three districts.
The questionnaire we developed was coded in the Survey Solutions application in both English and Swahili. Survey Solutions is a computer-assisted personal interviewing software developed by the World Bank. The trained enumerators administered the field questionnaire survey using tablets with the questionnaire coded in the Survey Solutions application. The enumerators recorded the geographic location and surveyed the physical characteristics of the within-season plant (including planting density, stress level due to N, drought, weeds, pests and diseases) condition. Other in-season information (including weather characteristics and maize cultivar, sowing time, irrigation and fertilization levels) were from enumerators’ interviews with the farmers or farm workers. The complete survey was synchronized to the cloud storage. We processed the within-season information immediately after we received it through the cloud storage and provided the maize yield forecast for each of the sampling fields. We provided yield forecasts ranging from 14 to 77 days prior to harvest. The 25th and 75th percentile of the forecasting lead time was 30 and 55 days before harvest, respectively.
2.4 Accuracy assessment
We assessed the accuracy of the maize yield forecasts submitted before harvest based on three accuracy indicators. We first regressed the forecasted versus the observed yield and used the coefficients of determination (R2) of the linear model to evaluate the overall agreement between the yield forecasts and yield observations. We then calculated the root mean square of deviation (RMSD) based on the Eq. (1) to assess the deviation of the forecasted values from the observed ones. The RMSD value is sensitive to extreme values. Lastly, we calculated the Mean Absolute Error (MAE) (Eq. (2)) to assess the accuracy of our methodology. The MAE value represents the overall error. It is a more direct representation of model biases and is less sensitive to extreme values compared to the RMSD (van der Velde and Nisini 2019; Willmott and Matsuura 2005).
where N is the total number of sampling fields, i is each sampling field, F is forecasted yield and O is observed yield.
We showed the accuracy of the yield forecasts for all sampled maize fields, regardless of the maize development stages during initial visit, and the accuracy for sampled fields where maize was present during the growing season.
3 Results
3.1 Descriptive statistics of within-season data collection
More than 90% of the sampling fields across Morogoro, Kagera and Tanga were smallholder (less than 2 ha farm area) farming systems. The size of the fields ranged from 0.056 ha to 7.49 ha with a median value of 0.83 ha in Morogoro. For the other two districts, all sampling fields were under 2 ha. The field size was 0.19–1.30 ha with a median value of 0.47 ha for Kagera and was 0.02–1.92 ha with a median value of 0.71 ha for Tanga (Fig. S4).
Across the three districts, maize was at early to mid grain filling stage for all sampling fields except for one field in Morogoro, where maize was at vegetative stage during the field survey. The agronomic and climatic conditions varied across the sampling sites in the three districts.
In Morogoro, more than 75% of the fields were monoculture maize and four fields had maize intercropped with either pigeonpea or field peas. Long-duration maize cultivars were reported for 12 fields and the remaining five fields had short-duration maize. The reported sowing time was between early February and early March for most of the fields, and in mid March for three fields. Maize planting density across the 17 sampling fields ranged from 1.0 plants/m2 to 5.7 plants/m2 with an average value of 2.8 plants/m2. Most of the fields was unfertilized and rainfed. Irrigation was reported for two fields and manure application was reported for one field. No synthetic fertilizer was reported across the fields in Morogoro (Fig. 3). Water deficit was not reported. No N deficit was reported for 9 fields, minor N deficit for 7 fields and severe N deficit for one field. During the in-season field survey, weeds were not present for 8 fields, whereas the other 8 fields experienced minor weed problems, and one field had severe weed issues. Insects were not present in 12 sampling fields, four fields had a minor insect problem and one field had a severe insect problem. Only three fields were reported to have minor disease issues and the remaining majority of fields did not have disease problems. Based on photos taken during the in-season field survey, one field was assessed in extremely good condition with dense plants, healthy green leaves and relatively thick stalks, eight fields were in good condition, four fields were in medium condition with yellow spots on green leaves and relatively thin stalks, and four fields were in poor condition with short plants, very thin stalks and/or unhealthy leaves (Fig. 4).

Reported maize growing conditions, including pure crop stands versus intercropping, maize duration, sowing time, plant density, irrigation and manure use and growing season weather characteristics across the three districts

Maize status, including water and N deficit, weed, insect and disease presence, and overall plant condition based on photos taken during in-season survey across the three districts
In Kagera, slightly more than half of the sampling fields (14 out of 24 sampling fields) were pure maize stands and the remaining fields were maize intercropped with banana (four fields), banana and beans (one field), banana and cassava (one field), beans (two fields), or cassava and beans (two fields). More than 60% of the sampling fields (15 fields) had long-duration maize cultivars and the remaining fields had short-duration cultivars. Early October or late August were the predominant sowing times. The sowing time was in early, mid or late September for a total of 7 fields. Maize plant density was low across the sampling fields, ranging from 0.3 plants/m2 to 3.3 plants/ m2 with an average value of 1.3 plants/ m2. Rainfed maize was reported for 23 out of 24 fields. A few fields (four fields) had manure applications by the survey date and none had synthetic fertilizer input. A majority of the maize fields were had no water deficit whereas three fields were had minor water deficit conditions (Fig. 3). Minor N deficit was reported for a majority of the fields (22 fields) and only two fields had no N deficit conditions. Half or more of the fields were reported to have minor weed, insect and disease problems. Weeds, insects and diseases were not reported in 7, 5 and 11 of the sampling fields in each district, respectively. Severe weed, insect and disease problems were reported for one or two fields. We assessed that 10 fields were in good condition, 9 were in medium condition and five were in poor condition (Fig. 4).
Maize was grown in pure stands across the 21 sampled fields in the Tanga district. Of the sampled fields, 14 fields were sown with a short-duration cultivar and seven had long-duration cultivar maize. Maize was sown in early October for more than 90% of the fields and was planted in late September for two fields. Maize plant density ranged from 0.4 plants/m2 to 3.6 plants/m2, averaging at 1.9 plants/m2. A majority of the maize fields were rainfed and unfertilized. Irrigation was reported for three fields. Manure application was reported for two fields (Fig. 3). None of the sampled fields had synthetic fertilizer input. Maize experienced minor water deficit conditions in more than half of the fields, while severe water deficit stress was reported for four fields. A majority of maize fields experienced minor N deficit and two fields had adequate N supply. Most maize fields had minor or severe weed, insect and disease problems. Overall, three fields were in extremely good condition, four were in good condition, 9 were in medium condition and five were in poor condition (Fig. 4).
Regarding in-season climatic characteristics, a majority of the respondents in Morogoro reported hotter than normal and drier than normal condition, one respondent reported colder and drier than normal conditions, and the other three reported normal temperature and rainfall conditions. By contrast, most respondents in Kagera district reported average rainfall and temperature conditions when compared to the historical norm, three reported wetter and colder than the norm, and the other three reported wetter but hotter conditions than the norm. For Tanga, 13 respondents reported drier and hotter than normal conditions, 7 reported average rainfall and temperature conditions, and one reported drier and colder than the norm (Fig. 3).
3.2 Maize yield forecasts
Our proposed method was able to accurately forecast maize yield before the harvest across the three districts under varying conditions. Maize yield ranged from 0.74 to 5.63 t/ha with an average value of 2.36 t/ha and standard deviation of 1.2 t/ha in Morogoro. The forecasted yield captured the variations in the reported final yield, with an r2 value of 0.88. The RMSD value between the forecasted yield and the reported yield was 0.47 t/ha and the MAE value was 0.36 t/ha (Fig. 5a).

Comparisons between the forecasted yield and reported final yield across a Morogoro, b Kagera and c Tanga (note that the ranges for both axes in a–c differ)
Maize yield in Kagera was low, 0.19–1.94 t/ha with an average value of 0.94 t/ha and standard deviation of 0.51 t/ha. Using our proposed method, we were able to closely forecast the final yield for most fields (r2 = 0.5). The RMSD was 0.38 t/ha and the MAE was 0.25 t/ha (Fig. 5b).
For Tanga, where all maize fields were monoculture, maize yield ranged from 0.28 to 5.84 t/ha, with an average value of 2.03 t/ha and standard deviation of 1.59 t/ha. The forecasted yield closely matched with the reported yield with r2 value of 0.94. The RMSD value between the forecasted and the reported yield was 0.43 t/ha and the MAE value was 0.32 t/ha (Fig. 5c).
4 Discussion
Forecasting grain yield before harvest for smallholder farming systems has been a major challenge for scientists and government officials working on this important topic. Crop simulation models supplied with daily weather observation till the forecasting date combined with historical observations for the remaining growing season, weather analog or seasonal weather forecast have been used to generate yield forecasts (Hansen and Indeje 2004). Due to lack of extensive weather station network in Africa, weather observations are limited and seasonal climate forecasts have low skills (Sheffield et al. 2014; Singh et al. 2018). Quality real-time weather data was not publicaly accessible for our studied site. Intead of relying on real-time weather data to simulate in-season crop growth and development, we used descriptive in-season weather characteristics from the field questionnaire survey to select analog years in long-term reanalysis climate datasets (AgMERRA and CHIRPS). This was the first study, to the authors’ knowledge, that linked field surveys with a crop simulation model to forecast crop yield. The other innovation featured in our study was the use of digital photos, taken with inexpensive and widely available mobile computer tablets. The photos were used to assess growing season plant conditions, including nutrient and water deficit levels, and weed, insect and disease issues. These photos provided valuable mid-season information for experts to cross validate the answers reported by the enumerators in the field survey questionnaire. We also implemented a simple reduction factor to consider the effect of biotic stress (weeds, diseases and pests) on yield, which was not simulated by crop models but prevalent in smallholder farms.
We demonstrated that it was feasible to make accurate yield forecasts by collecting both subjective and objective in-season yield assessment as well as running the crop simulation model. The use of subjective evaluation of field condition in yield forecasts has been employed by the US Department of Agriculture and has been documented in the literature (Pease et al. 1993; USDA 2012). Our methodology produced accurate yield forecasts for smallholder farming systems (less than 2 ha) across three districts in Tanzania one to two months before harvest (r2 values of 0.94, 0.88 and 0.5 in Tanga, Morogoro and Kagera districts, respectively). The accuracy of our method was much higher than most of the yield-forecasting studies for Africa. The r2 values between the forecasted yield and final yield were mostly under 0.5 when forecasts were made during maize vegetative to reproductive stages (Abo-Shetaia et al. 2005; Mkhabela et al. 2005; Schauberger et al. 2017) with an exception of Unganai and Kogan (1998), where regional maize yield in Zimbabwe was accurately forecasted (r2 > 0.9) by the peaked Temperature Condition Index and Vegetation Condition Index derived from the Advanced Very High Resolution Radiometer satellite. There were a few studies reported comparably accurate yield forecasts at maturity (r2 > 0.8) but our method offered accurate forecasts 1–2 months before harvest (Manatsa et al. 2011; Rojas 2007; Vossen 1990). Basso and Liu (2019) has provided a comprehensive review on crop yield forecasting methods and their accuracy.
Despite that statistical-based models could provide accurate crop yield forecasts for smallholder fields in African countries (e.g. Manatsa et al. 2011; Rojas 2007), statistical yield forecasting model may not be applicable to growing conditions that are beyond the model development boundary. Crop simulation models have an advantage over statistical models regarding capabilities of representing crop growth and development under climate change (Lobell and Asseng 2017; Jones et al. 2017). Our approach of integrating crop simulation modeling and surveys provides a framework to develop new yield forecasting methodology for other sites and other crops during other years. Our approach can be applied to forecasting maize yield in Tanzania under the long-term climate change conditions as well. To apply our method to maize yield forecasts in another country or region, one needs to identify proper soil information and to determine historical or in-season climate to cover the growth conditions. In this study, we focused on maize, the dominant staple food crop in Tanzania. Our yield forecasting procedure, nonetheless, can be applied to other crops, as long as the crops of interest can be simulated by the crop model. Regardless of crops of interest, the field questionnaire survey should include plant density, within-season information about weather, crop growing status (including stress levels due to weeds, pests, diseases, and N and water deficiency), and soil information.
Our approach has a few limitations. First, it was constrained by the trained enumerators’ ability to conduct field questionnaire surveys. While enumerator availability may not be the constraining resources in developing countries, field campaigns can be labor intensive and time consuming. Second, the yield forecast product resulted from this study was subject to the quality of the questionnaire response. Our algorithm relied on the subjective evaluation of the weed, disease and pest presence and the overall plant status assessment. In addition, AgMERRA weather dataset, which provided temperature and solar radiation input for the yield forecasting algorithm, had a limited temporal coverage, from 1980 to 2010. AgMERRA dataset may not be adequate to forecast crop yield with the rapid changing climate since the weather analog assumption will be violated as we are moving to a new climate regime. National Aeronautics and Space Administration Prediction Of Worldwide Energy Resource (NASA POWER) provides daily weather data since 1997 (https://power.larc.nasa.gov). The NASA POWER dataset may be an alternative to AgMERRA, though the POWER dataset has a coarser spatial resolution (0.5 arc degree). There are a few sources of uncertainties in our study. Though the soil and maize cultivar information we used for crop modeling and for creating yield database before the field questionnaire surveys adequately represented soils and maize cultivars in Tanzania, we did not have on-site soil data by depths across our study sites or the genetic parameters of cultivars grown in the sampling fields. There were uncertainties in soil and plant parameters of the SALUS model. The other uncertainty was the evaluation of in-season photos taken by enumerators. Different interpretation of the photos can lead to different forecasted maize yields. Another source of uncertainty was the final grain yield. Due to the logistics of the field survey, we asked for kernels number and cob weight but we did not shell maize cobs to weigh the kernel. We found inconsistencies between estimated yield based on kernel number and estimated yield derived from cob weight and planting density across the sampling fields, perhaps due to precipitation event before conducting the final field survey and moisture contribution to the cob weight. Due to missing cob weight and the quality of the cob weight, final grain yield was estimated based on total kernel number.
To overcome the limitations of field questionnaire survey, high resolution commercial remote sensing imageries that are increasingly available to research use may provide within-season vegetation status and information about management practices (e.g. planting date). Two research advances are needed to achieve accurate yield forecasts at the regional level using the proposed framework. First, high resolution cultivated crop maps are required to scale up our proposed framework. Second, vegetation status, planting date and plants density needs to be extracted from high resolution satellite imageries, such as PlanetScope and SkySat (https://www.planet.com).
5 Conclusions
We have presented a new method that integrates within-season field survey and crop simulation modeling to forecast yield for smallholder farming system. We applied our proposed method to forecast maize yield at field scale across three districts in Tanzania, where maize was cultivated under different planting densities, varied intercropping plants and distinct growing-season weather conditions. The results showed that we achieved accurate yield forecasts across diverse maize fields. This study provided the most accurate field-level yield forecasting method for smallholder farming systems in Tanzania to date, which is a critical piece of information toward understanding areas within regions affected by food shortages or overproduction, leading to more informed decision by government officials.
References
Abo-Shetaia, A. M., Ashoub, M. A., Ismail, M., & Al-Khaled, E. A. (2005). Estimation of some summer crops area and yield prediction using remote sensing techniques. Annals of Agricultural Science (Cairo), 50, 481–498.
Arkin, G. F., Maas, S. J., & Richardson, C. W. (1980). Forecasting grain Sorghum yields using simulated weather data and updating techniques. Transactions of ASAE, 23, 676–0680.
Azzari, G., Jain, M., & Lobell, D. B. (2017). Towards fine resolution global maps of crop yields: Testing multiple methods and satellites in three countries. Remote Sensing of Environment, 202, 129–141.
Basso, B., and Liu, L. (2019). Seasonal crop yield forecast: Methods, applications, and accuracies. In "advances in agronomy". Vol. 154, pp. 201-255. Academic press.
Basso, B., & Ritchie, J. T. (2015). Simulating crop growth and biogeochemical fluxes in response to land management using the SALUS model. In S. K. Hamilton, J. E. Doll, & G. P. Robertson (Eds.), The ecology of agricultural landscapes: Long-term research on the path to sustainability (pp. 252–274). New York: Oxford University Press.
Basso, B., Ritchie, J. T., Grace, P. R., & Sartori, L. (2006). Simulation of tillage systems impact on soil biophysical properties using the SALUS model. Italian Journal of Agronomy, 1, 677–688.
Basso, B., Cammarano, D., Troccoli, A., Chen, D., & Ritchie, J. T. (2010). Long-term wheat response to nitrogen in a Rainfed Mediterranean environment: Field data and simulation analysis. European Journal of Agronomy, 33, 132–138.
Basso, B., Gargiulo, O., Paustian, K., Robertson, G. P., Porter, C., Grace, P. R., & Jones, J. W. (2011). Procedures for initializing soil organic carbon pools in the Dssat-century model for agricultural systems. Soil Science Society of America Journal, 75, 69–78.
Basso, B., Giola, P., Dumont, B., Migliorati, M. D. A., Cammarano, D., Pruneddu, G., & Giunta, F. (2016a). Tradeoffs between maize silage yield and nitrate leaching in a Mediterranean nitrate-vulnerable zone under current and projected climate scenarios. PLoS One, 11, e0146360.
Basso, B., Liu, L., & Ritchie, J. T. (2016b). A comprehensive review of the Ceres-wheat, −maize and -Rice models’ performances. In L. S. Donald (Ed.), Advances in Agronomy (Vol. 136, pp. 27–132). Academic Press.
Basso, B., Dumont, B., Maestrini, B., et al. (2018). Soil organic carbon and nitrogen feedbacks on crop yields under climate change. Agricultural & Environmental Letters, 3, 180026.
Burke, M., & Lobell, D. B. (2017). Satellite-based assessment of yield variation and its determinants in smallholder African systems. Proceedings of the National Academy of Sciences, 114, 2189–2194.
Choularton, R. J., & Krishnamurthy, P. K. (2019). How accurate is food security early warning? Evaluation of FEWS NET accuracy in Ethiopia. Food Security, 11, 333–344.
Cillis, D., Maestrini, B., Pezzuolo, A., Marinello, F., & Sartori, L. (2018). Modeling soil organic carbon and carbon dioxide emissions in different tillage systems supported by precision agriculture technologies under current climatic conditions. Soil and Tillage Research, 183, 51–59.
Coughlan de Perez, E., van Aalst, M., Choularton, R., van den Hurk, B., Mason, S., Nissan, H., & Schwager, S. (2019). From rain to famine: Assessing the utility of rainfall observations and seasonal forecasts to anticipate food insecurity in East Africa. Food Security, 11, 57–68.
Delincé, J. (2017). Recent practices and advances for Amis crop yield forecasting at farm/parcel level: A review. Rome: Food and Agriculture Organization of the United Nations Retrieved from http://www.fao.org/3/a-i7339e.pdf.
Dzotsi, K. A., Basso, B., & Jones, J. W. (2013). Development, uncertainty and sensitivity analysis of the simple SALSU crop model in Dssat. Ecological Modelling, 260, 62–76.
Funk, C., Peterson, P., Landsfeld, M., Pedreros, D., Verdin, J., Shukla, S., Husak, G., Rowland, J., Harrison, L., & Hoell, A. (2015). The climate hazards Infrared precipitation with stations—A new environmental record for monitoring extremes. Scientific Data, 2, 150066.
Gennari, P., & Fonteneau, F. (2016). Crop yield forecasting: Methodological and institutional aspects. Rome: Food and Agriculture Organization of the United Nations Retrieved from http://gsars.org/wp-content/uploads/2016/03/AMIS_CYF-Methodological-and-Institutional-Aspects_0303-web.pdf.
Giola, P., Basso, B., Pruneddu, G., Giunta, F., & Jones, J. W. (2012). Impact of manure and slurry applications on soil nitrate in a maize–triticale rotation: Field study and long term simulation analysis. European Journal of Agronomy, 38, 43–53.
Hamilton, S. K., Hussain, M. Z., Bhardwaj, A. K., Basso, B., & Robertson, G. P. (2015). Comparative water use by maize, perennial crops, restored prairie, and poplar trees in the us Midwest. Environmental Research Letters, 10, 064015.
Hansen, J. W., & Indeje, M. (2004). Linking dynamic seasonal climate forecasts with crop simulation for maize yield prediction in semi-arid Kenya. Agricultural and Forest Meteorology, 125, 143–157.
Jayne, T. S., & Rashid, S. (2010). The value of accurate crop production forecasts. East Lansing: Michigan State University.
Johnson, D. M. (2014). An assessment of pre- and within-season remotely sensed variables for forecasting corn and soybean yields in the United States. Remote Sensing of Environment, 141, 116–128.
Jones, J. W., Antle, J. M., Basso, B., Boote, K. J., Conant, R. T., Foster, I., Godfray, H. C. J., Herrero, M., Howitt, R. E., Janssen, S., Keating, B. A., Munoz-Carpena, R., Porter, C. H., Rosenzweig, C., & Wheeler, T. R. (2017). Brief history of agricultural systems modeling. Agricultural Systems, 155, 240–254.
Kadaja, J., Saue, T., and Vii, P. (2009). Probabilistic yield forecast based on a production process model. In "Computer and Computing Technologies in Agriculture Ii, Vol 1" (D. Li and C. Zhao, eds.), Vol. 293, pp. 487–494.
Katz, R. W. (1977). Assessing the impact of climatic change on food production. Climatic Change, 1, 85–96.
Kottek, M., Grieser, J., Beck, C., Rudolf, B., & Rubel, F. (2006). World map of the Köppen-Geiger climate classification updated. Meteorologische Zeitschrift, 15, 259–263.
Kuri, F., Murwira, A., Murwira, K. S., & Masocha, M. (2014). Predicting maize yield in Zimbabwe using dry Dekads derived from remotely sensed vegetation condition index. International Journal of Applied Earth Observation and Geoinformation, 33, 39–46.
Liu, L., & Basso, B. (2017). Spatial evaluation of maize yield in Malawi. Agricultural Systems, 157, 185–192.
Lobell, D. B., & Asseng, S. (2017). Comparing estimates of climate change impacts from process-based and statistical crop models. Environmental Research Letters, 12, 015001.
Lobell, D. B., Thau, D., Seifert, C., Engle, E., & Little, B. (2015). A scalable satellite-based crop yield mapper. Remote Sensing of Environment, 164, 324–333.
Lourens, U. W., & De Jager, J. M. (1997). A computerized crop-specific drought monitoring system: Design concepts and initial testing. Agricultural Systems, 53, 303–315.
Luo, Y., Ogle, K., Tucker, C., Fei, S., Gao, C., LaDeau, S., Clark, J. S., & Schimel, D. S. (2011). Ecological forecasting and data assimilation in a data-rich era. Ecological Applications, 21, 1429–1442.
Manatsa, D., Nyakudya, I. W., Mukwada, G., & Matsikwa, H. (2011). Maize yield forecasting for Zimbabwe farming sectors using satellite rainfall estimates. Natural Hazards, 59, 447–463.
Mishra, A., Hansen, J. W., Dingkuhn, M., Baron, C., Traore, S. B., Ndiaye, O., & Ward, M. N. (2008). Sorghum yield prediction from seasonal rainfall forecasts in Burkina Faso. Agricultural and Forest Meteorology, 148, 1798–1814.
Mkhabela, M. S., Mkhabela, M. S., & Mashinini, N. N. (2005). Early maize yield forecasting in the four agro-ecological regions of Swaziland using Ndvi data derived from Noaa's-Avhrr. Agricultural and Forest Meteorology, 129, 1–9.
Nandram, B., Berg, E., & Barboza, W. (2014). A hierarchical Bayesian model for forecasting state-level corn yield. Environmental and Ecological Statistics, 21, 507–530.
Paavola, J. (2008). Livelihoods, vulnerability and adaptation to climate change in Morogoro, Tanzania. Environmental Science & Policy, 11, 642–654.
Pease, J. W., Wade, E. W., Skees, J. S., & Shrestha, C. M. (1993). Comparisons between subjective and statistical forecasts of crop yields. Review of Agricultural Economics, 15, 339–350.
Pezzuolo, A., Dumont, B., Sartori, L., Marinello, F., De Antoni Migliorati, M., & Basso, B. (2017). Evaluating the impact of soil conservation measures on soil organic carbon at the farm scale. Computers and Electronics in Agriculture, 135, 175–182.
Raun, W. R., Solie, J. B., Stone, M. L., Martin, K. L., Freeman, K. W., Mullen, R. W., Zhang, H., Schepers, J. S., & Johnson, G. V. (2005). Optical sensor-based algorithm for crop nitrogen fertilization. Communications in Soil Science and Plant Analysis, 36, 2759–2781.
Reynolds, C. A., Yitayew, M., Slack, D. C., Hutchinson, C. F., Huete, A., & Petersen, M. S. (2000). Estimating crop yields and production by integrating the FAO crop specific water balance model with real-time satellite data and ground-based ancillary data. International Journal of Remote Sensing, 21, 3487–3508.
Ritchie, J. T., & Basso, B. (2008). Water use efficiency is not constant when crop water supply is adequate or fixed: The role of agronomic management. European Journal of Agronomy, 28, 273–281.
Rojas, O. (2007). Operational maize yield model development and validation based on remote sensing and agro-meteorological data in Kenya. International Journal of Remote Sensing, 28, 3775–3793.
Ruane, A. C., Goldberg, R., & Chryssanthacopoulos, J. (2015). Climate forcing datasets for agricultural modeling: Merged products for gap-filling and historical climate series estimation. Agricultural and Forest Meteorology, 200, 233–248.
Schauberger, B., Gornott, C., & Wechsung, F. (2017). Global evaluation of a semi-empirical model for yield anomalies and application to within-season yield forecasting. Global Change Biology, 23, 4750–4764.
Sheffield, J., Wood, E. F., Chaney, N., Guan, K., Sadri, S., Yuan, X., Olang, L., Amani, A., Ali, A., & Demuth, S. (2014). A drought monitoring and forecasting system for sub-Sahara African water resources and food security. Bulletin of the American Meteorological Society, 95, 861–882.
Singh, C., Daron, J., Bazaz, A., Ziervogel, G., Spear, D., Krishnaswamy, J., Zaroug, M., & Kituyi, E. (2018). The utility of weather and climate information for adaptation decision-making: Current uses and future prospects in Africa and India. Climate and Development, 10, 389–405.
Sitko, N. J., Chisanga, B., Tschirley, D., & Jayne, T. S. (2018). An evolution in the middle: Examining the rise of multinational investment in smallholder grain trading in Zambia. Food Security, 10, 473–488.
Smale, M., & Tushemereirwe, W. (2007). An economic assessment of Banana genetic improvement and innovation in the Lake Victoria region of Uganda and Tanzania. Washington DC: International Food Policy Research Institute.
Stone, R. C., & Meinke, H. (2005). Operational seasonal forecasting of crop performance. Philosophical Transactions of the Royal Society of London B: Biological Sciences, 360, 2109–2124.
Tollenaar, M., Nissanka, S. P., Aguilera, A., Weise, S. F., & Swanton, C. J. (1994). Effect of weed interference and soil nitrogen on four maize hybrids. Agronomy Journal, 86, 596–601.
Unganai, L. S., & Kogan, F. N. (1998). Drought monitoring and corn yield estimation in southern Africa from AVHRR data. Remote Sensing of Environment, 63, 219–232.
USDA. (2012). "The Yield Forecasting Program of NASS." Retrieved from https://www.nass.usda.gov/Education_and_Outreach/Understanding_Statistics/Yield_Forecasting_Program.pdf
van der Velde, M., & Nisini, L. (2019). Performance of the Mars-crop yield forecasting system for the European Union: Assessing accuracy, in-season, and year-to-year improvements from 1993 to 2015. Agricultural Systems, 168, 203–212.
Vossen, P. (1990). Comparative statistical validation of 2 10-day water-use models and of 3 yield-reduction hypotheses for yield assessment in Botswana. Agricultural and Forest Meteorology, 51, 177–195.
Willmott, C. J., & Matsuura, K. (2005). Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Climate Research, 30, 79–82.
Wright, B., & Cafiero, C. (2011). Grain reserves and food security in the Middle East and North Africa. Food Security, 3, 61–76.
Zinyengere, N., Mhizha, T., Mashonjowa, E., Chipindu, B., Geerts, S., & Raes, D. (2011). Using seasonal climate forecasts to improve maize production decision support in Zimbabwe. Agricultural and Forest Meteorology, 151, 1792–1799.
Acknowledgements
This study was supported by the United Nation Food and Agriculture Organization (UNFAO) and the Government of Tanzania (GoT). The authors thank Carola Fabi, and Eloi Ouedraogo, Silvia Tireweshobwa of the UNFAO, Titus Miwsomba, Festo Mwemutsi from the GoT National Bureau of Statistics, Wilson Katunzi and Valerian Vitalis from the GoT Ministry of Agriculture. The authors were grateful for technical assistant from UNFAO’s Michael Rahija in accessing survey data in the cloud server. Lastly, the authors expressed gratitude to enumerators for collecting the field survey data.
Author information
Authors and Affiliations
Contributions
BB conceived and designed the research; LL and BB conducted data analysis, LL ran the simulations, BB and LL wrote the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declared that they have no conflict of interest.
Electronic supplementary material
ESM 1
(DOCX 2074 kb)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liu, L., Basso, B. Linking field survey with crop modeling to forecast maize yield in smallholder farmers’ fields in Tanzania. Food Sec. 12, 537–548 (2020). https://doi.org/10.1007/s12571-020-01020-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12571-020-01020-3