
Abstract
We present a convergence rate analysis for biased stochastic gradient descent (SGD), where individual gradient updates are corrupted by computation errors. We develop stochastic quadratic constraints to formulate a small linear matrix inequality (LMI) whose feasible points lead to convergence bounds of biased SGD. Based on this LMI condition, we develop a sequential minimization approach to analyze the intricate trade-offs that couple stepsize selection, convergence rate, optimization accuracy, and robustness to gradient inaccuracy. We also provide feasible points for this LMI and obtain theoretical formulas that quantify the convergence properties of biased SGD under various assumptions on the loss functions.
Similar content being viewed by others

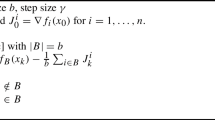

Notes
When \(\delta =c=0\), this rate bound does not reduce to \(\rho ^2=1-2m\alpha +O(\alpha ^2)\). This is due to the inherent differences between the analyses of biased SGD and the standard SGD. See Remark 4 for a detailed explanation.
This case is a variant of the common assumption \(\frac{1}{n}\sum _{i=1}^n\left\| \nabla f_i(x)\right\| ^2 \le \beta \). One can check that this case holds for several \(\ell _2\)-regularized problems including SVM and logistic regression.
The loss functions for SVM are non-smooth, and \(u_k\) is actually updated using the subgradient information. For simplicity, we abuse our notation and use \(\nabla f_i\) to denote the subgradient of \(f_i\) for SVM problems.
Ensuring such a condition in practice can be challenging for many cases since it heavily relies on the estimations of problem parameters.
When \(M_{21}=0\), this condition always holds. When \(\delta =0\), this condition is equivalent to \(M_{21}\alpha \le 1\). Hence the above corollary can be directly applied if \(M_{21}=0\) or \(\delta =0\). If \(M_{21}> 0\) and \(\delta >0\), the condition \(M_{21}\left( \alpha +\frac{\delta ^2}{m}\right) \le 1\) can be rewritten as a condition on \(\alpha \) in a case-by-case manner.
References
Agarwal, A., Bartlett, P.L., Ravikumar, P., Wainwright, M.J.: Information-theoretic lower bounds on the oracle complexity of stochastic convex optimization. IEEE Trans. Inf. Theory 58(5), 3235–3249 (2012)
Arora, S., Ge, R., Ma, T., Moitra, A.: Simple, efficient, and neural algorithms for sparse coding. In: Conference on Learning Theory, pp. 113–149 (2015)
Bertsekas, D.: Nonlinear Programming, 2nd edn. Athena scientific, Belmont (2002)
Bottou, L.: Large-scale machine learning with stochastic gradient descent. In: Proceedings of COMPSTAT’2010, pp. 177–186 (2010)
Bottou, L., Curtis, F., Nocedal, J.: Optimization methods for large-scale machine learning. SIAM Rev. 60(2), 223–311 (2018)
Bottou, L., LeCun, Y.: Large scale online learning. Adv. Neural Inf. Process. Syst. 16, 217 (2004)
Bubeck, S.: Convex optimization: algorithms and complexity. Found. Trends® Mach. Learn. 8(3–4), 231–357 (2015)
Chen, Y., Candes, E.: Solving random quadratic systems of equations is nearly as easy as solving linear systems. In: Advances in Neural Information Processing Systems, pp. 739–747 (2015)
d’Aspremont, A.: Smooth optimization with approximate gradient. SIAM J. Optim. 19(3), 1171–1183 (2008)
De Klerk, E., Glineur, F., Taylor, A.: On the worst-case complexity of the gradient method with exact line search for smooth strongly convex functions. Optim. Lett. 11(7), 1185–1199 (2017)
Defazio, A., Bach, F., Lacoste-Julien, S.: Saga: A fast incremental gradient method with support for non-strongly convex composite objectives. In: Advances in Neural Information Processing Systems (2014)
Defazio, A., Domke, J., Caetano, T.: Finito: A faster, permutable incremental gradient method for big data problems. In: Proceedings of the 31st International Conference on Machine Learning, pp. 1125–1133 (2014)
Devolder, O., Glineur, F., Nesterov, Y.: First-order methods of smooth convex optimization with inexact oracle. Math. Program. 146(1–2), 37–75 (2014)
Drori, Y., Teboulle, M.: Performance of first-order methods for smooth convex minimization: a novel approach. Math. Program. 145(1–2), 451–482 (2014)
Feyzmahdavian, H., Aytekin, A., Johansson, M.: A delayed proximal gradient method with linear convergence rate. In: 2014 IEEE International Workshop on Machine Learning for Signal Processing, pp. 1–6 (2014)
Grant, M., Boyd, S.: Graph implementations for nonsmooth convex programs. In: Blondel, V., Boyd, S., Kimura, H. (eds.) Recent Advances in Learning and Control. Lecture Notes in Control and Information Sciences, pp. 95–110. Springer (2008). http://stanford.edu/~boyd/graph_dcp.html
Grant, M., Boyd, S.: CVX: Matlab software for disciplined convex programming, version 2.1. http://cvxr.com/cvx (2014)
Hu, B., Seiler, P., Rantzer, A.: A unified analysis of stochastic optimization methods using jump system theory and quadratic constraints. In: Proceedings of the 2017 Conference on Learning Theory, vol. 65, pp. 1157–1189 (2017)
Johnson, R., Zhang, T.: Accelerating stochastic gradient descent using predictive variance reduction. In: Advances in Neural Information Processing Systems, pp. 315–323 (2013)
Lee, J.C., Valiant, P.: Optimizing star-convex functions. In: 2016 IEEE 57th Annual Symposium on Foundations of Computer Science (FOCS), pp. 603–614 (2016)
Lessard, L., Recht, B., Packard, A.: Analysis and design of optimization algorithms via integral quadratic constraints. SIAM J. Optim. 26(1), 57–95 (2016)
Moulines, E., Bach, F.: Non-asymptotic analysis of stochastic approximation algorithms for machine learning. In: Advances in Neural Information Processing Systems, pp. 451–459 (2011)
Nedić, A., Bertsekas, D.: Convergence rate of incremental subgradient algorithms. In: Stochastic Optimization: Algorithms and Applications, pp. 223–264 (2001)
Needell, D., Ward, R., Srebro, N.: Stochastic gradient descent, weighted sampling, and the randomized Kaczmarz algorithm. In: Advances in Neural Information Processing Systems, pp. 1017–1025 (2014)
Nishihara, R., Lessard, L., Recht, B., Packard, A., Jordan, M.: A general analysis of the convergence of ADMM. In: Proceedings of the 32nd International Conference on Machine Learning, pp. 343–352 (2015)
Robbins, H., Monro, S.: A stochastic approximation method. Ann. Math. Stat. 22(3), 400–407 (1951)
Roux, N., Schmidt, M., Bach, F.: A stochastic gradient method with an exponential convergence rate for strongly-convex optimization with finite training sets. In: Advances in Neural Information Processing Systems (2012)
Schmidt, M., Roux, N., Bach, F.: Minimizing finite sums with the stochastic average gradient. Math. Program. 162(1–2), 83–112 (2017)
Schmidt, M., Roux, N.L., Bach, F.R.: Convergence rates of inexact proximal-gradient methods for convex optimization. In: Advances in Neural Information Processing Systems, pp. 1458–1466 (2011)
Shalev-Shwartz, S., Zhang, T.: Stochastic dual coordinate ascent methods for regularized loss. J. Mach. Learn. Res. 14(1), 567–599 (2013)
Sun, R., Luo, Z.Q.: Guaranteed matrix completion via non-convex factorization. IEEE Trans. Inf. Theory 62(11), 6535–6579 (2016)
Taylor, A., Bach, F.: Stochastic first-order methods: non-asymptotic and computer-aided analyses via potential functions. In: Proceedings of the 2019 Conference on Learning Theory, pp. 2934–2992 (2019)
Taylor, A., Hendrickx, J., Glineur, F.: Smooth strongly convex interpolation and exact worst-case performance of first-order methods. Math. Program. 161(1–2), 307–345 (2017)
Taylor, A., Hendrickx, J.M., Glineur, F.: Exact worst-case performance of first-order methods for composite convex optimization. SIAM J. Optim. 27(3), 1283–1313 (2017)
Taylor, A., Van Scoy, B., Lessard, L.: Lyapunov functions for first-order methods: Tight automated convergence guarantees. In: Proceedings of the 35th International Conference on Machine Learning, pp. 4897–4906 (2018)
Teo, C., Smola, A., Vishwanathan, S., Le, Q.: A scalable modular convex solver for regularized risk minimization. In: Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 727–736 (2007)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work is supported by the NSF Awards 1656951, 1750162, 1254129, and the NASA Langley NRA Cooperative Agreement NNX12AM55A. Bin Hu and Laurent Lessard also acknowledge support from the Wisconsin Institute for Discovery, the College of Engineering, and the Department of Electrical and Computer Engineering at the University of Wisconsin–Madison.
Appendices
Appendix
Proof of Theorem 1
First notice that since \(i_k\) is uniformly distributed on \(\{1,\dots ,n\}\) and \(x_k\) and \(i_k\) are independent, we have:
Consequently, we have:
where the inequality in (54) follows from the definition of \(g \in {\mathcal {S}}(m,\infty )\).
Next we prove (12), let’s start with Case I, the boundedness constraint \(\Vert \nabla f_i(x_k)\Vert \le \beta \) implies that \(\left\| u_k\right\| \le \beta \) for all k. Rewrite as a quadratic form to obtain:
The boundedness constraint \(\Vert \nabla f_i(x_k)-mx_k\Vert \le \beta \) implies that:
As in the proof of Case I, rewrite the above inequality as a quadratic form and we obtain the second row of Table 1.
To prove the three remaining cases, we begin by showing that an inequality of the following form holds for each \(f_i\):
The verification for (56) follows directly from the definitions of L-smoothness and convexity. In the smooth case (Definition 1), for example, \(\Vert \nabla f_i(x_k)-\nabla f_i(x_\star )\Vert \le L\Vert x_k-x_\star \Vert \). So (56) holds with \(M_{11}=2L^2\), \(M_{12}=M_{21}=0\). The cases for \({\mathcal {F}}(0,L)\) and \({\mathcal {F}}(m,L)\) follow directly from Definition 2. In Table 1, we always have \(M_{22}=-1\). Therefore,
Since \(\frac{1}{n}\sum _{i=1}^n \nabla f_i(x_\star ) = \nabla g(x_\star ) = 0\), the first term on the right side of (57) is equal to
Based on the constraint condition (56), we know that the above term is greater than or equal to \(\frac{2}{n} \sum _{i=1}^n \Vert \nabla f_i(x_k)-\nabla f_i(x_\star ) \Vert ^2\). Substituting this fact back into (57) leads to the inequality:
Taking the expectation of both sides, we arrive at (12), as desired. Now we are ready to prove our main theorem. By Schur complement, (10) is equivalent to (15), which can be further rewritten as
Since \(x_{k+1}-x_\star =x_k-x_\star -\alpha _k(u_k+e_k)\), we have
Now we can left and right multiply (59) by \([(x_k-x_\star )^{\mathsf {T}}, u_k^{\mathsf {T}}, e_k^{\mathsf {T}}]\) and \([(x_k-x_\star )^{\mathsf {T}}, u_k^{\mathsf {T}}, e_k^{\mathsf {T}}]^{\mathsf {T}}\), and apply the inequalities (4), (54), and (12) to get the desired conclusion. \(\square \)
Proof of Lemma 2
We use an induction argument to prove Item 1. For simplicity, we denote (48) as \(V_{k+1}=h(V_k)\). Suppose we have \(V_k=h(V_{k-1})\) and \(V_{k-1}>V_\star \). We are going to show \(V_{k+1}=h(V_k)\) and \(V_k>V_\star \). We can rewrite (48) as
where \(A_k\), \(B_k\), and \(Z_k\) are defined as
Note that \(A_k \ge 0\) and \(B_k \ge 0\) due to the condition \(2G^2(1-\delta ^2) \ge c^2\). The objective in (61) therefore has a form very similar to the objective in (26). Applying Lemma 1, we deduce that \(V_{k+1} =(\sqrt{A_k}+\sqrt{B_k})^2\), which is the same as (49). The associated \(Z_k^opt \) is \(\sqrt{\tfrac{A_k}{B_k}}\). To ensure this is a feasible choice, it remains to check that the associated \(\zeta _k^opt > 0\) as well. Via algebraic manipulations, one can show that \(\zeta _k > 0\) is equivalent to \(V_k > V_\star \). We can also verify \(A_k\) is a monotonically increasing function of \(V_k\), and \(B_k\) is a monotonically nondecreasing function of \(V_k\). Hence h is a monotonically increasing function. Also notice \(V_\star \) is a fixed point of (49). Therefore, if we assume \(V_k=h(V_{k-1})\) and \(V_{k-1}>V_\star \), we have \(V_k=h(V_{k-1})>h(V_\star )=V_\star \). Hence we guarantee \(\zeta _k>0\) and \(V_{k+1}=h(V_k)\). By similar arguments, one can verify \(V_1=h(V_0)\). And it is assumed that \(V_0>V_\star \). This completes the induction argument.
Item 2 follows from a similar argument to the one used in Sect. 2.2. Finally, Item 3 can be proven by choosing a sufficiently small constant stepsize \(\alpha \) to make \({\hat{U}}_k\) arbitrarily close to \(V_\star \). Since \(V_\star \le V_k \le {\hat{U}}_k\), we conclude that \(\lim _{k\rightarrow \infty } V_k = V_\star \), as required. \(\square \)
Rights and permissions
About this article

Cite this article
Hu, B., Seiler, P. & Lessard, L. Analysis of biased stochastic gradient descent using sequential semidefinite programs. Math. Program. 187, 383–408 (2021). https://doi.org/10.1007/s10107-020-01486-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10107-020-01486-1
Keywords
- Biased stochastic gradient
- Robustness to inexact gradient
- Convergence rates
- Convex optimization
- First-order methods