
Abstract
Folding grid value vectors of size \(2^L\) into Lth-order tensors of mode size \(2\times \cdots \times 2\), combined with low-rank representation in the tensor train format, has been shown to result in highly efficient approximations for various classes of functions. These include solutions of elliptic PDEs on nonsmooth domains or with oscillatory data. This tensor-structured approach is attractive because it leads to highly compressed, adaptive approximations based on simple discretizations. Standard choices of the underlying bases, such as piecewise multilinear finite elements on uniform tensor product grids, entail the well-known matrix ill-conditioning of discrete operators. We demonstrate that, for low-rank representations, the use of tensor structure itself additionally introduces representation ill-conditioning, a new effect specific to computations in tensor networks. We analyze the tensor structure of a BPX preconditioner for a second-order linear elliptic operator and construct an explicit tensor-structured representation of the preconditioner, with ranks independent of the number L of discretization levels. The straightforward application of the preconditioner yields discrete operators whose matrix conditioning is uniform with respect to the discretization parameter, but in decompositions that suffer from representation ill-conditioning. By additionally eliminating certain redundancies in the representations of the preconditioned discrete operators, we obtain reduced-rank decompositions that are free of both matrix and representation ill-conditioning. For an iterative solver based on soft thresholding of low-rank tensors, we obtain convergence and complexity estimates and demonstrate its reliability and efficiency for discretizations with up to \(2^{50}\) nodes in each dimension.
Similar content being viewed by others


1 Introduction
The direct textbook treatment of elliptic PDEs by low-order discretizations on uniform grids becomes unaffordable for many important problem classes. The high computational costs are due to the prohibitively large number of degrees of freedom required to resolve specific features of solutions, such as singularities and high-frequency oscillations, that arise in problems with nonsmooth or oscillatory data. More efficient discretizations can be obtained with basis functions that are adapted to the given problem and require fewer degrees of freedom. However, the construction and analysis of such methods (for instance, of hp-adaptive solvers) generally depends on specific features of the considered problem classes and accordingly specialized analytical tools.
By the approach considered in this work, efficiency is achieved in a different way: extremely large arrays of coefficients parametrizing simple, uniformly refined low-order discretizations are themselves parametrized as nonlinear functions of relatively few effective degrees of freedom. The latter parametrization is based on representing the coefficient arrays, reshaped into high-order tensors, in the tensor train decomposition with low ranks. This representation exploits low-rank structure with respect to a hierarchy of dyadic scales, providing, at each scale, a problem-adapted basis that can be computed using standard techniques of numerical linear algebra. In other words, for the identification of suitable degrees of freedom, this approach avoids relying on problem-specific a priori information; instead, suitable degrees of freedom are found by the low-rank tensor compression of generic, conceptually straightforward discretizations.
In numerical solvers for PDE problems that operate on such highly compressed, nonlinear representations of basis coefficients, new difficulties arise compared to a standard entrywise representation. As we demonstrate in this contribution, specific types of ill-conditioning in such tensor representations can dramatically affect the numerical stability of solvers. We show how a special low-rank representation of a BPX preconditioner allows to overcome these difficulties and obtain estimates for the total computational complexity of computing solutions with low-rank tensor train structure.
1.1 Low-Rank Tensor Approximations
The development of low-rank tensor representations [18, 25, 45, 47, 50], such as the tensor train format, has originally been motivated by applications to high-dimensional PDEs. As observed in [19, 37, 43, 44], the artificial treatment of coefficient vectors in lower-dimensional problems as high-dimensional quantities, known in the literature as quantized tensor train (QTT) decomposition or tensorization, leads to highly efficient approximations in many problems of interest. See [38] for a general overview and, for instance, [29, 36] for further applications.
To briefly illustrate this concept, let us suppose that a function u has an accurate approximation \(u \approx \sum _{j = 1}^N \varvec{u}_j \phi _j\) in terms of the basis functions \(\{ \phi _j \}_{j = 1, \ldots , N}\) with the coefficient vector \(\varvec{u}= (\varvec{u}_{j} )_{j=1,\ldots ,N} \in {{\mathbb {R}}}^N\). The basic idea is to reinterpret \(\varvec{u}\) as a higher-order tensor of mode sizes \(n_1\times \cdots \times n_L\) with \(\prod _{\ell =1}^L n_\ell = N\) via the identification
provided by the unique decomposition
We assume a simple choice of basis functions, such as low-order splines, combined with a compressed, nonlinearly parametrized approximation of the corresponding coefficients \(\varvec{u}\) in the tensor train format,
The actual degrees of freedom are now the entries of the third-order tensors \(U_\ell \in {{\mathbb {R}}}^{r_{\ell -1} \times n_\ell \times r_\ell }\) with \(\ell \in \{1,\ldots ,L\}\), which are referred to as cores (where \(r_0 = r_L=1\) for notational convenience). In the case of \(n_\ell = n\in {{\mathbb {N}}}\) for all \(\ell \), which we consider in this work, the total number of parameters defining this approximation equals \(\sum _{\ell = 1}^L n_\ell \, r_{\ell -1} \, r_\ell \lesssim (\log N) \max \{ r_1^2,\ldots ,r_{L-1}^2\}\).
For certain representative approximation problems (such as functions with isolated singularities or high-frequency oscillations), as shown in [19, 31, 34, 37], one obtains approximations where the rank parameters \(r_1,\ldots ,r_{L-1}\) grow at most polylogarithmically in the corresponding error. This suggests the possibility of constructing numerical methods with complexity scaling as \((\log N)^\alpha \) for a fixed \(\alpha \).
1.2 Multilevel Low-Rank Approximations for Elliptic Boundary Value Problems
In this work, we focus on the application of low-rank tensor techniques for solving second-order elliptic boundary value problems on domains \(\varOmega \subset {{\mathbb {R}}}^D\), where we are mainly interested in the cases of \(D\in \{1,2,3\}\). First, consider the exact solution u and finite element solutions \(u_h\), where \(h>0\) is a mesh-size parameter, that are simple, low-order finite element functions with coefficient vectors \(\varvec{u}_h\). These are given by suitable linear systems of the form \(\varvec{A}_h \varvec{u}_h = \varvec{f}_h\). For each mesh size h, one can seek instead \(u^{\mathrm {LR}}_h\) from the same finite element space whose coefficient vector \(\varvec{u}_h^{\mathrm {LR}}\) is a low-rank approximation in form (1) of \(\varvec{u}_h\). In order to benefit from the complexity reduction afforded by representation (1), the vector \(\varvec{u}_h^\mathrm {LR}\) needs to be computed directly in this low-rank representation. Using corresponding representations of \(\varvec{A}_h\) and \(\varvec{f}_h\), this can be achieved by iteratively solving the nonlinear problem in terms of the cores \(U_1,\ldots ,U_L\) of \(\varvec{u}_h^\mathrm {LR}\) in (1). In our setting, the binary indexing \((i_1,\ldots ,i_L)\) used in the interpretation of \(\varvec{u}_h\) as a tensor of order L corresponds to uniform grid refinement with L levels, and thus \(h\sim 2^{-L}\). The separation of variables expressed by (1) therefore applies not to the spatial dimensions but rather to the dyadic scales of \(u^{\mathrm {LR}}_h\).
In our model problem, the underlying discretization uses piecewise D-linear finite elements. Using the triangle inequality, we can decompose the error \(u - u^\mathrm {LR}_h\) into a discretization error \(u-u_h\), for which on uniform meshes one obtains bounds of the form
with \(C_u>0\) depending only on u and \(0<s\le 1\), and the computation error \(u_h - u^\mathrm {LR}_h\) including the error of low-rank approximation. In problems where u exhibits, for instance, singularities or high-frequency oscillations, one may be dealing with \(C_u\) extremely large or with \(s \ll 1\). Thus, achieving reasonable total errors may require values of h that are so small that the entrywise representations of coefficient vectors and matrices are computationally infeasible.
Under natural assumptions on the data and on the underlying mesh, the problem of finding \(u_h\) remains well-conditioned with respect to the problem data independently of h. However, for very small h as considered here, it becomes a nontrivial issue to ensure numerical stability of algorithms, since these are affected by the condition numbers \({\mathscr {O}}(h^{-2})\) of \(\varvec{A}_h\). Regardless of the type of solver that is employed, preconditioning \(\varvec{A}_h\) becomes a necessity for avoiding numerical instabilities even for moderately small h. As a first step, we therefore construct a preconditioner for \(\varvec{A}_h\) that can be applied directly in low-rank form, where both the resulting matrix condition numbers after preconditioning and the tensor representation ranks are uniformly bounded with respect to the discretization level L.
However, we also find that when such a preconditioner is applied as usual by the standard matrix-vector multiplication in the tensor format, numerical solvers still stagnate at an error \(\Vert u_h - u_h^\mathrm {LR} \Vert _{\mathrm {H}^{1}_{}}\) of order \({\mathscr {O}}(h^{-2} \varepsilon )\), where \(\varepsilon \) is the machine precision. This shows that ensuring uniformly bounded matrix condition numbers by preconditioning is not sufficient for low-rank tensor methods to remain numerically stable for very small h. It turns out that tensor representations of vectors in the form of (1) generated by the action of \(\varvec{A}_h\) can be extremely sensitive to perturbations of each single core. This new type of ill-conditioning cannot be eradicated by simply multiplying by the preconditioner, and any further numerical manipulations of the resulting tensor representations are prone to large round-off errors. To quantify this effect, we introduce the notion of representation condition numbers.
Without addressing the issue of representation ill-conditioning, one can therefore only expect \(\Vert u - u_h \Vert _{\mathrm {H}^{1}_{}} = {\mathscr {O}}( C_u h^s + h^{-2} \varepsilon )\). With the optimal choice of h, this yields a total error of order \({\mathscr {O}}(C_u^{2/(2+s)} \varepsilon ^{s/(2+s)})\); even in the ideal case \(s=1\), one thus has a limitation to \({\mathscr {O}}(\varepsilon ^{1/3})\). In the present paper, by analytically combining the low-rank representations of the preconditioner and of the stiffness matrix, we obtain a tensor representation that retains favorable representation condition numbers also for large L and leads to solvers that remain numerically stable even for h on the order of the machine precision \(\varepsilon \). For the problems preconditioned in this manner, we can apply results from [4, 6] to obtain bounds for the number of operations required for computing \(\varvec{u}_h^\mathrm {LR}\), in terms of the ranks of low-rank best approximations of \(\varvec{u}_h\) with the same error. Since the costs depend only weakly on the discretization level L, one may then in fact simply choose L so large that \(h \approx \varepsilon \). This ensures that the discretization error \(\Vert u - u_h\Vert _{\mathrm {H}^{1}_{}}\) is negligible in all practical situations and only the explicitly controllable low-rank approximation error \(\Vert u_h - u_h^\mathrm {LR}\Vert _{\mathrm {H}^{1}_{}}\) remains.
1.3 Conditioning of Tensor Train Representations
Let us now briefly outline the source of numerical instability that we need to mitigate here. Subspace-based tensor decompositions such as the Tucker format, hierarchical tensors [25] or the presently considered tensor train format [45] share the basic stability property that the existence of low-rank best approximations with fixed-rank parameters is guaranteed. In contrast, such best approximation problems for canonical tensors are in general ill-posed [14], and one has the well-known border rank phenomena where given tensors can be approximated arbitrarily well by tensors of lower canonical ranks. In subspace-based formats, such pathologies of the canonical rank are avoided by working only with matrix ranks of certain tensor matricizations. This leads to natural higher-order generalizations of the singular value decomposition (SVD), in particular the TT-SVD algorithm for tensor trains.
However, when performing computations in such tensor formats, tensors in general do not remain in orthogonalized standard representations, such as those given by the TT-SVD. For instance, the action of low-rank representations of finite element stiffness matrices in iterative solvers may create tensor train representations with substantial redundancies that are far from their respective SVD forms. A return to the rank-reduced SVD form can then in principle be accomplished by applying standard linear algebra operations (such as QR decomposition and SVD) to the representation components.
As we demonstrate in what follows, in relevant cases, tensor train representations can become so ill-conditioned that performing this rank reduction with machine precision no longer produces useful results. To our knowledge, this particular point has not received attention in the literature so far. As we consider in further detail in Sect. 4, a particular instance where this effect occurs is multilevel low-rank representations of discretization matrices of differential operators.
In order to illustrate these issues, let us consider a low-rank matrix \(M=A B^{\mathsf {T}}\!\) with \(A \in {{\mathbb {R}}}^{m\times r}\) and \(B \in {{\mathbb {R}}}^{n\times r}\). Performing numerical manipulations of A, for instance a QR factorization with machine precision, amounts to replacing M by \({{\tilde{M}}} = {{\tilde{A}}} B^{\mathsf {T}}\!\) with \(\Vert A - \tilde{A}\Vert _F \le \delta \Vert A\Vert _F\), where \(\delta \) will ideally be close to the relative machine precision. Similarly to standard perturbation estimates for matrix products (see, e.g., [27, Sec. 3]), one obtains the generally sharp worst-case bound
In the case of high-order tensor train representations, one may think of B as composed of many individual cores. Even when each of these cores looks completely innocent, their cumulative effect can lead to very large \(\Vert B\Vert _{2\rightarrow 2}\). In cases where cancellations occur in the product with A, the size of \(\Vert M\Vert _F\), however, can be small compared to \(\Vert B\Vert _{2\rightarrow 2}\), and perturbations to A are strongly amplified. This means that any numerical manipulation of such representations (such as orthogonalization, which is also the first step in performing a TT-SVD, see Sect. 3.6) can introduce extremely large errors in the represented tensor.
We define the representation condition number of an operator in low-rank representation as the factor by which its action may deteriorate the conditioning of tensor train representations. In the case of the finite element stiffness matrices \(\varvec{A}_h\), we find that this condition number scales (matching the standard matrix condition number) as \({\mathscr {O}}(h^{-2})\), which agrees with the numerically observed loss of precision. One may regard this as a tensor-decomposition analogue of the classical amplification of relative errors by ill-conditioned matrices. However, this error amplification manifests itself not in the action of the tensor representation of \(\varvec{A}_h\) on any single tensor core, which by itself is harmless, but rather in the cumulative effect that emerges when further operations are performed on the resulting output cores.
1.4 Novelty and Relation to Previous Work
As a main contribution of this work, we introduce basic notions and auxiliary results for studying the representation conditioning of tensor train representations. In particular, our finding that the stiffness matrix represented in low-rank format has a representation condition number of order \(2^{2 L}\) explains numerical instabilities in its direct application for large L as observed in tests in [11]. We prove a new result on a BPX preconditioner for second-order elliptic problems that is tailored to our purposes, and we construct a low-rank decomposition of the preconditioned stiffness matrix with the following properties: it is well-conditioned uniformly in discretization level L as a matrix; its ranks are independent of L; and its representation condition numbers remain moderate for large L. Based on these properties, we establish an estimate for the total computational complexity of finding approximate solutions in low-rank form. These complexity bounds are shown for an iterative solver based on the soft thresholding of tensors [6], for which the ranks of approximate solutions can be estimated in terms of the ranks of the exact Galerkin solution. We identify appropriate approximability assumptions on solutions in the present context, which are slightly different from those proved in [34].
Difficulties with the numerical stability of solvers for large L have also been noted previously in [34]. In [11, 46], a reformulation as a constrained minimization problem with Volterra integral operators is proposed. It is demonstrated numerically in [11] up to \(L \approx 20\) to lead to improved numerical stability, compared to a direct finite difference discretization, for Poisson-type problems with \(D=2\) dimensions. However, in this reformulation, which so far has been studied only experimentally, the matrix condition number still grows exponentially with respect to L, and numerical stability is still observed to be lacking for larger values of L.
A different class of preconditioners based on approximate matrix exponentials has been proposed for QTT decompositions in [39]. In the different context of separation of spatial coordinates in high-dimensional problems, tensor representations have been combined with multilevel preconditioners based on multigrid methods [8, 23], BPX preconditioners [1] and wavelet Riesz bases [5]. There the required representation ranks of preconditioners have been observed to increase with discretization levels, in contrast to the uniformly bounded ranks that we obtain in our present setting of tensor separation between scales.
1.5 Outline
In Sect. 2, we consider the structure of discretization matrices in detail and establish a result on symmetric BPX preconditioning. In Sect. 3, we recapitulate basic notation and operations for the tensor train format. In Sect. 4, we introduce notions of representation condition numbers of tensor decompositions and investigate some of their basic properties. Building on these concepts, in Sect. 5 we construct well-conditioned multilevel low-rank representations of preconditioned discretization matrices. In Sect. 6, we discuss the implications of our findings on the complexity of finding approximate solutions and illustrate the performance of numerical solvers in Sect. 7.
We use the following general notational conventions: \(A\lesssim B\) denotes \(A \le C B\) with C independent of any parameters explicitly appearing in the expressions A and B, and \(A\sim B\) denotes \(A\lesssim B \wedge A \gtrsim B\). We use \(\Vert \cdot \Vert _2\) to denote the \(\ell ^2\)-norm both of vectors and of higher-order tensors, and \(\Vert \cdot \Vert _{2\rightarrow 2}\) to denote the associated operator norm. In addition, \(\Vert \cdot \Vert _F\) denotes the Frobenius norm of matrices. By \(\langle \cdot ,\cdot \rangle \), we denote the \(\ell ^2\)-inner product of vectors and tensors or the \(\mathrm {L}^{2}_{}\)-inner product of functions, as well as the corresponding duality product.
2 Discretization and Preconditioning
The model problem that we focus on in what follows is posed on the product domain \(\varOmega ={\hat{\varOmega }}^D \subset {{\mathbb {R}}}^D\) with  . With
. With  , we consider the corresponding Sobolev space of functions defined on \(\varOmega \) and vanishing on \(\varGamma \),
, we consider the corresponding Sobolev space of functions defined on \(\varOmega \) and vanishing on \(\varGamma \),

with norm  . On this space, we consider the variational problem
. On this space, we consider the variational problem
where \(a: V \times V \rightarrow {{\mathbb {R}}}\) is the bilinear form given by

and \(f \in V'\) is a given linear form. We assume the diffusion and reaction coefficients  and
and  to be strongly elliptic and nonnegative, respectively:
to be strongly elliptic and nonnegative, respectively:

Problem (4) is a variational formulation of a boundary value problem for a reaction-diffusion equation with homogeneous mixed boundary conditions: of Dirichlet type on \(\varGamma \) and of Neumann type on \(\partial \varOmega \backslash \varGamma \).
Under the assumptions on the data made so far, the bilinear form a is continuous and coercive and the linear form f is continuous. By the Lax–Milgram theorem, (4) has a unique solution satisfying

Additional assumptions on the data of problem (4), essential for its tensor-structured preconditioning and solution, are stated in Sects. 2 and 5.
In what follows, we consider a hierarchy of discretizations based on piecewise D-linear nodal basis functions on a sequence of uniform grids with cell sizes \(2^{-\ell }\times \cdots \times 2^{-\ell }\), \(\ell = 0,1,2,\ldots \); the basis functions can be written as tensor products of standard univariate hat functions.
In this section, we describe \(V_\ell \) with \(\ell \in {{\mathbb {N}}}_0\), nested finite-dimensional subspaces of V introduced in (3). We will use these subspaces to approximate the solution of the variational problem stated in (4).
2.1 Finite Element Spaces for 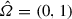
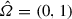
Throughout this section, we assume that an arbitrary number \(\ell \in {{\mathbb {N}}}_0\) of refinement levels is fixed. We consider a uniform partition of \({\hat{\varOmega }}\) into \(2^\ell \) subintervals and corresponding \(2^\ell \) continuous piecewise linear functions defined on \({\hat{\varOmega }}\). Then, by tensorization, we introduce basis functions defined on \(\varOmega \).
First, we consider the uniform partition of \({\hat{\varOmega }}\) that consists of the \(2^{\ell }\) intervals

given by the \(2^{\ell } + 1\) nodes
For each \(i\in {\hat{{\mathscr {J}}}}_\ell \), we introduce an affine mapping \({\hat{\phi }}_{\ell ,{\,}\!i}\) from  onto \({\hat{\varOmega }}_{\ell ,{\,}\!i}\):
onto \({\hat{\varOmega }}_{\ell ,{\,}\!i}\):

for all  .
.
Further, we consider nodal functions defined on \({\hat{\varOmega }}\) and associated with these nodes: for each \(j\in {\hat{{\mathscr {J}}}}_\ell \), by \({\hat{\varphi }}_{\ell ,{\,}\!j}\) we denote the function that is linear on each \({\hat{\varOmega }}_{\ell ,{\,}\!i}\) with \(i\in {\hat{{\mathscr {J}}}}_\ell \), continuous on \({\hat{\varOmega }}\) and such that

The \(\ell \)-dependent normalization factor in the right-hand side of (10) results in the uniform normalization

By the above construction of basis functions, each \({\hat{\varphi }}_{\ell ,{\,}\!j}\) with \(j\in {\hat{{\mathscr {J}}}}_\ell \) is a degree-one polynomial on every \({\hat{\varOmega }}_{\ell ,{\,}\!i}\) with \(i\in {\hat{{\mathscr {J}}}}_\ell \). This implies that, for \(\alpha =0,1\), there exist matrices \(\hat{\varvec{M}}_{\ell ,{\,}\!\alpha }\) with rows and columns indexed by  and \({\hat{{\mathscr {J}}}}_\ell \), respectively, such that
and \({\hat{{\mathscr {J}}}}_\ell \), respectively, such that

for all \(i,j\in {\hat{{\mathscr {J}}}}_\ell \), where \({{\hat{\psi }}}_0\) and \({{\hat{\psi }}}_1\) are the standard monomials of degree zero and one,

We note that the matrix \(\hat{\varvec{M}}_{\ell ,{\,}\!0}\) is rectangular of size \(2^{\ell +1} \times 2^\ell \) and the matrix \(\hat{\varvec{M}}_{\ell ,{\,}\!1}\) is a square matrix of order \(2^{\ell }\).
For the basis functions defined in (12b), since \({\hat{\psi }}_1' = {\hat{\psi }}_0\), the odd rows of \(\hat{\varvec{M}}_{\ell ,{\,}\!0}\) form a multiple of \(\hat{\varvec{M}}_{\ell ,{\,}\!1}\): for \(\beta = 1\) and all \(i,j\in {\hat{{\mathscr {J}}}}_\ell \), we have

Furthermore, the matrices \(\hat{\varvec{M}}_{\ell ,{\,}\!0}\) and \(\hat{\varvec{M}}_{\ell ,{\,}\!1}\) have the following explicit form, which will be used below:

where
are square matrices of order \(2^\ell \).
The finite element spaces  with \(\ell \in {{\mathbb {N}}}_0\) are nested: for all \(L,\ell \in {{\mathbb {N}}}_0\) such that \(\ell \le L\), we have
with \(\ell \in {{\mathbb {N}}}_0\) are nested: for all \(L,\ell \in {{\mathbb {N}}}_0\) such that \(\ell \le L\), we have

where \(\hat{\varvec{P}}_{\ell ,L}\) is the matrix of the identity operator from  to
to  with respect to the bases defined in (10):
with respect to the bases defined in (10):

where
are \(2^k\)-component vectors for each \(k\in {{\mathbb {N}}}_0\).
2.2 Finite Element Spaces for 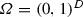
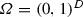
Partition (7) induces a uniform tensor product partition of \(\varOmega \) that consists of the \(2^{D \ell }\) elements

Tensorizing (10), we obtain the \(2^{D \ell }\) functions

which are continuous on \({\overline{\varOmega }}\) and D-linear on each of the partition elements given by (16). We will use these functions as a basis of a finite-dimensional subspace of V,

The normalization of univariate factors in (11) implies

and hence

with equivalence constants independent of \(\ell \in {{\mathbb {N}}}\). Also, relationship (12a) results in

for all  and \(i,j\in {\mathscr {J}}_\ell \) with
and \(i,j\in {\mathscr {J}}_\ell \) with
for all  and
and  and with \(\varvec{M}_{\ell ,{\,}\!\alpha }\) given by
and with \(\varvec{M}_{\ell ,{\,}\!\alpha }\) given by

for all  ,
,  and
and  . Note that, for each
. Note that, for each  , the rows and columns of \(\varvec{M}_{L ,{\,}\!\alpha }\) are indexed by
, the rows and columns of \(\varvec{M}_{L ,{\,}\!\alpha }\) are indexed by  and \({\mathscr {J}}_L\), respectively. The embedding (12c) implies
and \({\mathscr {J}}_L\), respectively. The embedding (12c) implies

for all \(i,j\in {\mathscr {J}}_\ell \) and  such that \(\alpha _k \le \alpha '_k \le \beta _k\) for each \(k=1,\ldots ,D\).
such that \(\alpha _k \le \alpha '_k \le \beta _k\) for each \(k=1,\ldots ,D\).
The finite element spaces \(V_\ell \) with \(\ell \in {{\mathbb {N}}}_0\) are also nested: for all \(L,\ell \in {{\mathbb {N}}}_0\) such that \(\ell \le L\), we have \(V_\ell \subset V_L\). In particular, the basis functions of \(V_\ell \) and \(V_L\) introduced in (17) satisfy the refinement relation

where
with \(\hat{\varvec{P}}_{\ell ,L}\) given by (14).
The stiffness matrix for the bilinear form a and discretization level \(\ell \) is given by
Note that due to (19),
For the right-hand side, we set \( \varvec{f}_\ell = \bigl ( f(\varphi _{\ell ,{\,}\!i}) \bigr )_{i \in {\mathscr {J}}_\ell } \).
2.3 Representation of Differential Operators
The bilinear form \(a\!:\, V \times V \rightarrow {{\mathbb {R}}}\) in (5) can be rewritten in the form

with a  . We assume that each coefficient function
. We assume that each coefficient function  with
with  is given by
is given by

in terms of the affine transformations \(\phi _{L ,{\,}\!i}\) with \(i \in {\mathscr {J}}_L\) defined by (9) and (20b), a finite index set \(\varGamma _{\! \alpha \alpha '}\) of cardinality  , functions
, functions  with \(\gamma \in \varGamma _{\! \alpha \alpha '}\) and a coefficient vector \( \varvec{c}_{L ,{\,}\!\alpha ,{\,}\!\alpha '} \in {{\mathbb {R}}}^{{\mathscr {J}}_L \times \varGamma _{\! \alpha \alpha '}} \simeq {{\mathbb {R}}}^{2^{DL} R_{\alpha \alpha '}} \).
with \(\gamma \in \varGamma _{\! \alpha \alpha '}\) and a coefficient vector \( \varvec{c}_{L ,{\,}\!\alpha ,{\,}\!\alpha '} \in {{\mathbb {R}}}^{{\mathscr {J}}_L \times \varGamma _{\! \alpha \alpha '}} \simeq {{\mathbb {R}}}^{2^{DL} R_{\alpha \alpha '}} \).
In this section, we analyze the dimension structure of the matrix \(\varvec{A}_L\) of a restricted to \(V_L \times V_L\) with respect to the basis of \(\varphi _{L ,{\,}\!j}\) with \(j\in {\mathscr {J}}_L\), whose entries are

induced by the tensor product dimension structure of the basis. Splitting integration over the elements \(\varOmega _{\ell ,{\,}\!i}\) with \(i\in {\mathscr {J}}_L\), given by (16), and applying (20a), we obtain

Let us now, for all \(\alpha ,\alpha '\in {\mathscr {D}}\), introduce a matrix \(\varvec{\varLambda }_{L ,{\,}\!\alpha ,{\,}\!\alpha '}\) of size  :
:

for all \(i,i'\in {\mathscr {J}}_L\),  and
and  . Using these matrices, we can rewrite (25b) as
. Using these matrices, we can rewrite (25b) as

Example 1
In the case of the negative Laplacian, we deal with a bilinear form given by (24a) with  and \(c_{\alpha \alpha '} = 1\) for all
and \(c_{\alpha \alpha '} = 1\) for all  . For each
. For each  , the corresponding coefficient is of form (24b) with
, the corresponding coefficient is of form (24b) with  , \(\chi _{\alpha \alpha ' {\,}\!0}=1\) and
, \(\chi _{\alpha \alpha ' {\,}\!0}=1\) and  for all \(i\in {\mathscr {J}}_L\). The corresponding matrix \(\varvec{\varLambda }_{L ,{\,}\!\alpha ,{\,}\!\alpha }\) given by (26a) takes the Kronecker product form
for all \(i\in {\mathscr {J}}_L\). The corresponding matrix \(\varvec{\varLambda }_{L ,{\,}\!\alpha ,{\,}\!\alpha }\) given by (26a) takes the Kronecker product form
where the factors \(\hat{\varvec{\varLambda }}_{L ,{\,}\!0 ,{\,}\!0}\) and \(\hat{\varvec{\varLambda }}_{L ,{\,}\!1 ,{\,}\!1}\) are diagonal matrices independent of  whose rows and columns are indexed by
whose rows and columns are indexed by  and
and  , respectively. Specifically, their nonzero entries are
, respectively. Specifically, their nonzero entries are

The multilevel tensor structure of the factorization (26b) and, in particular, of \(\varvec{\varLambda }_{L ,{\,}\!\alpha ,{\,}\!\alpha '}\) with  is investigated in Sect. 5. This analysis applies to the case of general nonconstant coefficients \(c_{\alpha \alpha '}\) with
is investigated in Sect. 5. This analysis applies to the case of general nonconstant coefficients \(c_{\alpha \alpha '}\) with  under the assumption that each of them exhibits the multilevel low-rank structure in the sense of Sect. 3. Specifically, in Sect. 5, we analyze the low-rank structure of every factor matrix \(\varvec{M}_{L ,{\,}\!\alpha }\) with
under the assumption that each of them exhibits the multilevel low-rank structure in the sense of Sect. 3. Specifically, in Sect. 5, we analyze the low-rank structure of every factor matrix \(\varvec{M}_{L ,{\,}\!\alpha }\) with  and also show how the low-rank structure of \(c_{\alpha \alpha '}\) with
and also show how the low-rank structure of \(c_{\alpha \alpha '}\) with  translates into that of \(\varvec{\varLambda }_{L ,{\,}\!\alpha ,{\,}\!\alpha '}\). First, however, in the remainder of Sect. 2 we turn to the multilevel preconditioning of \(\varvec{A}_{L}\). This gives rise to the preconditioned operator \(\varvec{B}_L\) and matrices \(\varvec{Q}_{L ,{\,}\!\alpha }\) with
translates into that of \(\varvec{\varLambda }_{L ,{\,}\!\alpha ,{\,}\!\alpha '}\). First, however, in the remainder of Sect. 2 we turn to the multilevel preconditioning of \(\varvec{A}_{L}\). This gives rise to the preconditioned operator \(\varvec{B}_L\) and matrices \(\varvec{Q}_{L ,{\,}\!\alpha }\) with  , defined in (33c), which relate to \(\varvec{B}_L\) as \(\varvec{M}_{L ,{\,}\!\alpha }\) with
, defined in (33c), which relate to \(\varvec{B}_L\) as \(\varvec{M}_{L ,{\,}\!\alpha }\) with  to \(\varvec{A}_L\). The low-rank multilevel structure of \(\varvec{B}_L\) and \(\varvec{Q}_{L ,{\,}\!\alpha }\) with
to \(\varvec{A}_L\). The low-rank multilevel structure of \(\varvec{B}_L\) and \(\varvec{Q}_{L ,{\,}\!\alpha }\) with  is the main topic of Sect. 5.
is the main topic of Sect. 5.
Remark 1
In the case of one dimension (\(D=1\)), let us consider a diffusion operator with a coefficient c that is piecewise constant:  on
on  for all \(i \in {\hat{{\mathscr {J}}}}_L\), cf. (24b). Such coefficients appear, for example, as approximations in the midpoint quadrature rule. Then, representation (25b) takes the form
for all \(i \in {\hat{{\mathscr {J}}}}_L\), cf. (24b). Such coefficients appear, for example, as approximations in the midpoint quadrature rule. Then, representation (25b) takes the form

where  is defined by (12a) and is given explicitly by (12d). The representation (28) has been used for this one-dimensional case in [15, 16, 31]; representation (26b) provides a generalization to higher dimensions and general coefficients.
is defined by (12a) and is given explicitly by (12d). The representation (28) has been used for this one-dimensional case in [15, 16, 31]; representation (26b) provides a generalization to higher dimensions and general coefficients.
2.4 Multilevel Preconditioning
Among the various existing methods for preconditioning discretization matrices of second-order elliptic problems, we are especially interested in approaches that provide optimal preconditioning and at the same time lead to favorable multilevel low-rank structures. A choice that meets these criteria is based on the classical BPX preconditioner [10]. For our particular purposes, in what follows we also obtain a new result on symmetric preconditioning by this method.
The BPX preconditioner requires a hierarchy of nested finite element spaces \(V_0 \subset V_1 \subset \cdots \subset V_L \subset V\), which in the present case are the uniformly refined spaces defined in (18). The standard implementable form of the preconditioner (cf. [10, 53]) is then given by
Interpreting \(C_{2,L}\) as a mapping of coefficient sequences \((\langle v, \varphi _{L ,{\,}\!j}\rangle )_{j\in {\mathscr {J}}_L}\) to nodal values of finite element functions, one obtains the corresponding matrix representation
where \(\varvec{P}_{\ell ,L}\) is as in (21), (22). The following result on the BPX preconditioner (29) was established in [12, 48], see also [9, 54].
Theorem 1
Let \(\varvec{A}_{L}\) and \(\varvec{C}_{2,L}\) be as in (23) and (29). Then, there exist \(c,C>0\) independent of L such that
This preconditioner is therefore optimal; that is, the condition numbers of preconditioned systems remain bounded uniformly in the discretization level. It is usually applied in the form of a left-sided preconditioning: it implies in particular that \({\text {cond}}(\varvec{C}_{2,L}^{1/2} \varvec{A}_L \, \varvec{C}_{2,L}^{1/2})\) is uniformly bounded with respect to L and that there exists \(\omega >0\) such that the iteration \( \varvec{u}^{k+1} = \varvec{u}^k - \omega \, \varvec{C}_{2,L} \bigl ( \varvec{A}_L \varvec{u}^k - \varvec{f}_L \bigr ) \) converges at an L-independent rate. Also standard implementations of the preconditioned conjugate gradient method use only the action of \(\varvec{C}_{2,L}\).
For our purposes, for several reasons explained in further detail in what follows, we require symmetric preconditioning, that is, an implementable operator \(\varvec{C}_L\) such that \(\varvec{C}_L \varvec{A}_{L} \varvec{C}_L\) is well-conditioned. Although \(\varvec{C}_{2,L}^{1/2}\) provides optimal symmetric preconditioning by Theorem 1, this is not directly numerically realizable.
We thus instead consider two-sided preconditioning by the implementable operator
For bounding the condition number of the symmetrically preconditioned operator \(\varvec{C}_{L} \varvec{A}_{L} \varvec{C}_{L}\), we need to establish spectral equivalence of \(\varvec{A}_L\) and \(\varvec{C}_{L}^{-2}\). This is not a direct consequence of Theorem 1. Although relying mainly on adaptations of established techniques as in [26, 51, 54], the following result appears to be new. The proof is given in “Appendix A.”
Theorem 2
With \(\varvec{A}_{L}\) as in (23) and \(\varvec{C}_{L}\) as in (30), there exist \(c,C>0\) independent of L such that
Remark 2
As an immediate consequence of Theorem 2,
which means that the functions \(\sum _{i\in {\mathscr {J}}_L} (\varvec{C}_L)_{ij} \varphi _{L ,{\,}\!i}\), \(j\in {\mathscr {J}}_L\), form a Riesz basis of the subspace \(V_L \subset \mathrm {H}^{1}_{}(\varOmega )\) with bounds independent of L.
In what follows, we consider the symmetrically preconditioned problem of finding \(\varvec{u}_{L}\) such that
Then, \(\bar{\varvec{u}}_{L} = \varvec{C}_{L} \varvec{u}_{L}\) satisfies \(\varvec{A}_{L} \bar{\varvec{u}}_{L}=\varvec{f}_{L}\); that is, \(\bar{\varvec{u}}_{L}\) are the (rescaled) nodal values of the Galerkin solution at level L. Using (26b), we obtain

where
for all  .
.
For our purposes, the symmetrically preconditioned operator is preferable mainly for two reasons. On the one hand, an important advantage of the symmetric preconditioning (33b) consists in the norm equivalence (32), since ultimately we are interested in numerical schemes with guaranteed convergence in the \(\mathrm {H}^{1}_{}\) norm. With low-rank methods using SVD-based rank truncations, as considered in further detail in Sect. 6, for any \(\varepsilon >0\) we can find \(\varvec{v}\) such that \(\Vert \varvec{u}_L - \varvec{v}\Vert _2 \le \varepsilon \) with \(\varvec{u}_L\) as in (33a). With the nodal basis coefficients \(\bar{\varvec{v}} = \varvec{C}_{L} \varvec{v}\), for the corresponding finite element functions \(v = \sum _{j\in {\mathscr {J}}_L} \bar{\varvec{v}}_j \, \varphi _{L ,{\,}\!j}\) and \(u_L = \sum _{j\in {\mathscr {J}}_L} \bar{\varvec{u}}_{L,j} \, \varphi _{L ,{\,}\!j}\) we have \( \Vert u_L - v\Vert _{\mathrm {H}^{1}_{}} \lesssim \Vert \varvec{C}_L^{-1}(\bar{\varvec{u}}_L - \bar{\varvec{v}} ) \Vert _2 = \Vert \varvec{u}_L - \varvec{v}\Vert _2 \le \varepsilon \) by (32). On the other hand, the symmetric preconditioning (33b) allows for the explicit assembly of the preconditioned operator \(\varvec{B}_{L}\) directly in the low-rank form, as considered in detail in Sect. 5.
3 Tensor Train Decomposition
In this section, we recapitulate the definition of the tensor train (TT) decomposition of multidimensional arrays and present the notation that we need for the following sections.
3.1 Tensor Train Decomposition of Multidimensional Arrays
Throughout this section, we assume that \(L\in {{\mathbb {N}}}\). Let \(n_1, \ldots , n_L \in {{\mathbb {N}}}\) and \(\varvec{u}\) be a multidimensional vector of dimension \(n_1 \cdots n_L\). Let \(r_1,\ldots ,r_{L-1}\in {{\mathbb {N}}}\) and, for \(\ell =1,\ldots ,L\), let \(U_\ell \) be arrays of size \(r_{\ell -1} \times n_\ell \times r_\ell \), where \(r_0 = 1\) and \(r_L = 1\). The vector \(\varvec{u}\) is said to be represented in the tensor train (TT) decomposition [45, 47] with ranks \(r_1,\ldots ,r_{L-1}\) and cores \(U_1,\ldots ,U_L\) if
for all \(j_\ell = 1,\ldots ,n_\ell \) with \(\ell = 1,\ldots ,L\), where \(\alpha _0 \equiv 1\) and \(\alpha _L \equiv 1\) are dummy indices.
The TT decomposition for matrices is defined analogously. Assume that \(m_1,n_1, \ldots , m_L,n_L \in {{\mathbb {N}}}\) and that \(\varvec{A}\) is a matrix of size \((m_1 \cdots m_L) \times (n_1 \cdots n_L)\). Let \(p_1,\ldots ,p_{L-1}\in {{\mathbb {N}}}\) and, for each \(\ell =1,\ldots ,L\), let \(A_\ell \) be an array of size \(p_{\ell -1} \times m_\ell \times n_\ell \times p_\ell \), where \(p_0 = 1\) and \(p_L = 1\). Then, the representation
for all \(i_\ell = 1,\ldots ,n_\ell \) with \(\ell = 1,\ldots ,L\), where \(\beta _0 \equiv 1\) and \(\beta _L \equiv 1\) are dummy indices, is called a tensor train decomposition of the matrix \(\varvec{A}\) with ranks \(p_1,\ldots ,p_{L-1}\) and cores \(A_1,\ldots ,A_L\).
The TT decomposition uses one of many possible ways to separate variables in multidimensional arrays; see, e.g., the survey [40] and the monograph [22]. The TT decomposition is a particular case of the more general hierarchical tensor representation, also known as the hierarchical Tucker representation [18, 25]. Both the TT and hierarchical tensor representations can be interpreted as successive subspace approximation or low-rank matrix factorization, and this relation allows for the quasi-optimal low-rank approximation of tensors built upon standard matrix algorithms.
The number of parameters of the representation, formally linear in L, is mainly governed by the ranks, such as \(r_1,\ldots r_{L-1}\) in (34a) and \(p_1,\ldots ,p_{L-1}\) in (34b). In many applications, the complexity is observed, theoretically as well as numerically, to depend moderately on L (see, e.g., [20]), which allows to lift or completely avoid the so-called curse of dimensionality associated with the entrywise storage of high-dimensional arrays.
The use of L for the dimensionality of tensors in this section is not accidental: in the present paper, the “dimension” index  enumerates the levels of discretization, and each of the mode indices (\(i_\ell \) and \(j_\ell \) with
enumerates the levels of discretization, and each of the mode indices (\(i_\ell \) and \(j_\ell \) with  above) represents the corresponding D bits of the D “physical” dimensions. In this case, the TT format separates not “physical” dimensions of tensors but rather the levels of the “physical” dimensions and adaptive low-rank approximation allows to resolve this multilevel structure in vectors and matrices. In this setting, the TT decomposition is known as the quantized tensor train (QTT) decomposition [21, 37, 43, 44]. This idea is further explained in Sect. 3.7.
above) represents the corresponding D bits of the D “physical” dimensions. In this case, the TT format separates not “physical” dimensions of tensors but rather the levels of the “physical” dimensions and adaptive low-rank approximation allows to resolve this multilevel structure in vectors and matrices. In this setting, the TT decomposition is known as the quantized tensor train (QTT) decomposition [21, 37, 43, 44]. This idea is further explained in Sect. 3.7.
3.2 Core Notation
In this section, we present the notation developed in [30, 32, 35], which we extensively use to work with TT representations. For the sake of brevity, several definitions and properties will be stated for cores with two mode indices, which naturally arise in TT representations of matrices. The setting with a single mode index per core can be considered a particular case in the same way as vectors can be considered one-column matrices.
If  with \(\alpha =1,\ldots ,p\) and \(\beta =1,\ldots ,q\) are tensors of size \(m \times n\), we call the array U of size \(p \times m \times n \times q\) given by
with \(\alpha =1,\ldots ,p\) and \(\beta =1,\ldots ,q\) are tensors of size \(m \times n\), we call the array U of size \(p \times m \times n \times q\) given by

for all \(\alpha =1,\ldots ,p\), \(i=1,\ldots ,m\), \(j=1,\ldots ,n\) and \(\beta =1,\ldots ,q\) a core of rank \(p \times q\) and mode size \(m \times n\). Conversely, for any core U of rank \(p \times q\) and mode size \(m \times n\), we refer to each tensor  with \(\alpha =1,\ldots ,p\) and \(\beta =1,\ldots ,q\) as block \((\alpha ,\beta )\) of the core U.
with \(\alpha =1,\ldots ,p\) and \(\beta =1,\ldots ,q\) as block \((\alpha ,\beta )\) of the core U.
For explicitly defining a core U, as a tensor of order four as in (35), in terms of its blocks (which in turn can be matrices or vectors), we use the notation

where square brackets are used for distinction from matrices. The following matrices are examples of blocks that we frequently use in this paper:
To apply the usual matrix transposition to TT decompositions of matrices, we will use the transposition of mode indices of cores:

in terms of matrix transposition, for all values of the indices.
Similarly to (35), for any core U of rank \(p \times q\) and mode size \(m \times n\), we refer to each matrix  with
with  and
and  given by
given by

for all \(\alpha =1,\ldots ,p\) and \(\beta =1,\ldots ,q\) as slice (i, j) of the core U.
3.3 Strong Kronecker Product
We are interested in cores as factors of TT decompositions, and now we present how decompositions of forms (34a)–(34b) can be expressed in terms of cores. For that purpose, we use the strong Kronecker product, introduced for two-level matrices in [13]. In order to avoid confusion with the Hadamard and tensor products, we denote this operation by \({{\,\mathrm{\bowtie }\,}}\), as in [35, Definition 2.1], where it was introduced specifically for connecting cores into TT representations.
Definition 1
(Strong Kronecker product of cores) Let \(p,q,r\in {{\mathbb {N}}}\) and \(m_1,m_2,n_1,n_2\in {{\mathbb {N}}}\). Consider cores U and V of ranks \(p \times r\) and \(r \times q\) and of mode size \(m_1 \times m_2\) and \(n_1 \times n_2\), respectively. The strong Kronecker product \(U {{\,\mathrm{\bowtie }\,}}V\) of U and V is the core of rank \(p \times q\) and mode size \(m_1 m_2 \times n_1 n_2\) given, in terms of the matrix multiplication of slices (of size \(p \times r\) and \(r \times q\)), by

for all combinations of  and
and  with \(k=1,2\).
with \(k=1,2\).
In other words, we define \(U {{\,\mathrm{\bowtie }\,}}V\) as the usual matrix product of the corresponding core matrices, their entries (blocks) being multiplied by means of the Kronecker product. For example, we have
for two cores of rank \(2 \times 2\). Using the strong Kronecker product, we can rewrite (34a) and (34b) as follows:

where the first equalities indicate that any tensor of dimension \(m \times n\) can be identified with a core of rank \(1 \times 1\) and mode size \(m \times n\).
3.4 Representation Map
Since many different tuples of cores may represent (or approximate) the same tensor, we need to distinguish representations as tuples of cores. We denote such tuples by sans-serif letters; for example,
for the decompositions given by (34a) and (34b). Further, we denote by \(\tau \) the function mapping tuples of cores into cores (in particular, into tensors when the rank of the resulting core is \(1\times 1\)):
for any cores \(U_1,\ldots ,U_L\) such that the right-hand side exists in the sense of Definition 1. Under (42a), this allows to rewrite (34a)–(34b) and (41) as

For the sets of all tuples of \(L\in {{\mathbb {N}}}\) cores with compatible ranks, we write \(\mathrm {TT}_L=\mathrm {TT}^1_L\) in the case of blocks with one mode index, and \(\mathrm {TT}^2_L\) in the case of two mode indices as in (35).
Furthermore, let us assume that \(\mathsf {U} = (U_1,\ldots ,U_L) \in \mathrm {TT}_L\), i.e., that \(U_1,\ldots ,U_L\) are cores such that \(\tau (U_1,\ldots ,U_L)\) is a core of rank \(r_0 \times r_L\) and mode size n, where \(r_0,r_L,n\in {{\mathbb {N}}}\). Then, by \(\tau ^-\) and \(\tau ^+\), we denote the matrices of size \(r_0 n \times r_L\) and \(r_0 \times n r_L\), respectively, given as follows:

and

for all \(\beta _0=1,\ldots ,r_0\), \(i=1,\ldots ,n\) and \(\beta _L=1,\ldots ,r_L\). These matrices may be called matricizations of the core \(\tau (U_1,\ldots ,U_L)\): they are obtained by interpreting the rank indices as row and column indices, which is consistent with (36), and by interpreting all mode indices as either row or column indices. For notational convenience, we set \(\tau ^-(\varnothing ) = 1\) and \(\tau ^+(\varnothing ) = 1\) for empty lists of cores.
Moreover, for each \(\ell =1,\ldots ,L\), we define
and
In particular, we have \(\tau ^-_1(U_1,\ldots ,U_L)= 1\), \(\tau ^-_{L+1}(U_1,\ldots ,U_L)=\tau ^-(U_1,\ldots ,U_L)\) and \(\tau ^+_L(U_1,\ldots ,U_L) = 1\), \(\tau ^+_{0}(U_1,\ldots ,U_L)=\tau ^+(U_1,\ldots ,U_L)\).
3.5 Unfolding Matrices, Ranks and Orthogonality
Let us consider a vector \(\varvec{u}\) of size \(n_1 \cdots n_L\) and a matrix \(\varvec{A}\) of size \(m_1 \cdots m_L \times n_1 \cdots n_L\). For every \(\ell =1,\ldots ,L-1\), we denote by \(\mathrm {U}_{\ell }(\varvec{u})\) and \(\mathrm {U}_{\ell }(\varvec{A})\) the \(\ell \)th unfolding matrices of \(\varvec{u}\) and \(\varvec{A}\), which are the matrices of size \(n_1 \cdots n_\ell \times n_{\ell +1} \cdots n_L\) and \(m_1 n_1 \cdots m_\ell n_\ell \times m_{\ell +1} n_{\ell +1} \cdots m_L n_L\) given by


for all \(i_k = 1,\ldots ,m_k\) and \(j_k = 1,\ldots ,n_k\) with \(k=1,\ldots ,L\). For the ranks of the unfolding matrices, we use the notation
for each \(\ell =1,\ldots ,L-1\).
The decompositions given by (34a)–(34b) or, equivalently, by (42c) imply \({{\,\mathrm{rank}\,}}_\ell (\varvec{u}) \le r_\ell \) and \({{\,\mathrm{rank}\,}}_\ell (\varvec{A}) \le p_\ell \) for each \(\ell =1,\ldots ,L-1\); furthermore, the decompositions provide low-rank factorizations of the unfolding matrices with the respective numbers of rank-one terms. For example, in the case of a vector, using the notation introduced in (43c)–(43d), we can write \( \mathrm {U}_{\ell }(\varvec{u}) = \tau ^-_{\ell +1}(\mathsf {U}) {\,}\!\tau ^+_{\ell }(\mathsf {U}) \).
Conversely, if \(\varvec{u}\) and \(\varvec{A}\) are such that, for every \(\ell =1,\ldots ,L-1\), the unfolding matrices \(\mathrm {U}_{\ell }(\varvec{u})\) and \(\mathrm {U}_{\ell }(\varvec{A})\) have approximations of ranks \(r_\ell \) and \(p_\ell \), respectively, and of accuracy \(\varepsilon _\ell \) in the Frobenius norm, then representations \(\mathsf {U}=(U_1,\ldots ,U_L)\) and \(\mathsf {A}=(A_1,\ldots ,A_L)\) of ranks \(r_1,\ldots ,r_{L-1}\) and \(p_1,\ldots ,p_{L-1}\) such that

with \(\varepsilon ^2 = \varepsilon _1^2 +\cdots + \varepsilon _{\ell -1}^2\) exist [45, Theorem 2.2] and can be constructed by the TT-SVD algorithm [45, Algorithm 1].
Next, we recapitulate the notion of orthogonality of decompositions in terms of the matricization operators defined in (43a)–(43d). If a core U is such that the matrix \(\tau ^-(U)\) has orthonormal columns, then the core is called left-orthogonal. Similarly, if the matrix \(\tau ^+(U)\) has orthonormal rows, then the core is called right-orthogonal. Further, if \(\mathsf {U} \in \mathrm {TT}_L\) is such that the columns of each matrix \(\tau ^-_\ell (\mathsf {U})\) with \(\ell =2,\ldots ,L+1\) are orthonormal, then the decomposition is called left-orthogonal. Analogously, if the rows of each matrix \(\tau ^+_\ell (\mathsf {U})\) with \(\ell =0,\ldots ,L-1\) are orthonormal, then the decomposition is called right-orthogonal. It is easy to see that any core U of the form \(U = U_1 {{\,\mathrm{\bowtie }\,}}U_2\) is left- or right-orthogonal if both \(U_1\) and \(U_2\) are left- or right-orthogonal, respectively. As a result, any decomposition \(\mathsf {U}=(U_1,\ldots ,U_{L})\) is left- or right-orthogonal if each of the cores \(U_1,\ldots ,U_{L}\) is left- or right-orthogonal.
Moreover, we say that \(\mathsf {U}\) is in left-orthogonal TT-SVD form if \(\tau ^-_{\ell +1} (\mathsf {U})\) has orthonormal columns and \(\tau ^+_{\ell }(\mathsf {U})\) has orthogonal rows for each \(\ell =1,\ldots ,L-1\); in other words, these matrices provide the SVD of \(\mathrm {U}_{\ell }(\varvec{u})\) for each \(\ell \), where the norms of the rows of \(\tau ^+_{\ell }(\mathsf {U})\) are the corresponding singular values, and \(\Vert \varvec{u}\Vert _2 = \Vert U_L\Vert _2\). Analogously, \(\mathsf {U}\) is in right-orthogonal TT-SVD form if \(\tau ^-_{\ell +1} (\mathsf {U})\) has orthogonal columns and \(\tau ^+_{\ell }(\mathsf {U})\) has orthonormal rows. These TT-SVD forms can be obtained numerically for any given \(\mathsf {U}\) by the procedure [45, Algorithm 1] without rank truncation.
3.6 Operations on Cores
We require several further operations, which are explained in this section. We start with the mode product of cores, which was introduced in [30, Definition 2.2] and which generalizes matrix multiplication to the case of cores.
Definition 2
(Mode product of cores) Let \(p,p',r,r'\in {{\mathbb {N}}}\) and \(m,n,k\in {{\mathbb {N}}}\). Consider cores A and B of ranks \(p \times p'\) and \(r \times r'\) and of mode size \(m \times k\) and \(k \times n\), respectively. The mode core product \(A \bullet B\) of A and B is the core of rank \(pq \times p'q'\) and mode size \(m \times n\) given, in terms of the matrix multiplication of blocks (of sizes \(m \times k\) and \(k \times n\)), by

for all combinations of \(\alpha =1,\ldots ,p\), \(\alpha '=1,\ldots ,p'\), \(\beta =1,\ldots ,q\) and \(\beta =1,\ldots ,q'\). If B has only one mode index, we apply the above definition, introducing a dummy mode size \(n=1\) in B and discarding it in \(A \bullet B\).
For example, for a core A with two mode indices and a core B with one or two mode indices, each core being of rank \(2 \times 2\), we have
if the first mode size of B equals the second of A.
The mode product and the strong Kronecker product inherit distributivity from the usual matrix product and from the Kronecker product: for  and
and  such that the products \(A_\ell \bullet U_\ell \) with \(\ell =1,\ldots ,L\) are all defined, we have that the product
such that the products \(A_\ell \bullet U_\ell \) with \(\ell =1,\ldots ,L\) are all defined, we have that the product  is defined and is given by
is defined and is given by

When  and
and  are both of rank \(1 \times 1\) and can therefore be identified with matrices,
are both of rank \(1 \times 1\) and can therefore be identified with matrices,  is the core of rank \(1 \times 1\) identified with the matrix–matrix product of these matrices, and (46) gives a representation for the product of a matrix
is the core of rank \(1 \times 1\) identified with the matrix–matrix product of these matrices, and (46) gives a representation for the product of a matrix  and a vector
and a vector  given by (34b) and (34a).
given by (34b) and (34a).
Finally, our derivations involve Kronecker products of cores, which are defined as the Kronecker product of the corresponding arrays. For any \(p,p',q,q'\in {{\mathbb {N}}}\) and \(m,n,m',n'\in {{\mathbb {N}}}\), let A be a core of rank \(p \times p'\) and mode size \(m \times n\) and let B be a core of rank \(q \times q'\) and mode size \(m' \times n'\). Then, the Kronecker product \(A {{\,\mathrm{\otimes }\,}}B\) of A and B is the core of rank \(pq \times p'q'\) and mode size \(m m' \times n n'\) given by

in terms of the Kronecker products of all pairs of block tensors or, equivalently, by

in terms of the Kronecker products of all pairs of slice matrices. Similarly to (46), we have

for any representation  and
and  . Relations (46) and (48) indicate the well-known fact that the matrix and Kronecker products can be recast core-wise; see, e.g., [22, 40, 45].
. Relations (46) and (48) indicate the well-known fact that the matrix and Kronecker products can be recast core-wise; see, e.g., [22, 40, 45].
One of the most important properties of the TT decomposition of tensors is that any representation can be made left- or right-orthogonal in the sense of Sect. 3.5 by the successive application of the QR decomposition [18, 22, 25, 41, 45]. We now briefly present an algorithm for the left-orthogonalization of a decomposition, which we use as an example in the discussion of representation conditioning. This scheme is also the first step in the computation of the TT-SVD form of a TT representation, as in [45, Algorithm 2].

In exact arithmetic, we have \(\tau (\mathsf {V})=\tau (\mathsf {U})\) for any \(\mathsf {U}\in \mathrm {TT}^S_L\) with \(L,S\in {{\mathbb {N}}}\) and \(\mathsf {V}={\text {orth}}^-(\mathsf {U})\), and this is the view adhered to in the references cited above. However, the situation is drastically different when errors are introduced (e.g., due to round-off) in the course of orthogonalization, namely in lines 4 and 6 of Algorithm 3.1.
3.7 Low-Rank Multilevel Decomposition of Vectors and Matrices
Here, we discuss how we use the tensor train decomposition for the resolution of low-rank multilevel structure in vectors and matrices involved in the solution of (4).
To reorder the entries of Kronecker products, we use particular permutation matrices defined as follows. First, for every \(L\in {{\mathbb {N}}}\), we define \(\varvec{\varPi }_{L}\) as the permutation matrix of order \(2^{D L}\) such that

for all \(i_{k,\ell }=1,2\) with \(k=1,\ldots ,D\) and \(\ell =1,\ldots ,L\). In our present setting, we are interested in functions

whose coefficients admit low-rank TT representations in the following sense:
with some  .
.
The set \({\mathscr {J}}_L\), which is defined by (16), is isomorphic to  . The matrix \(\varvec{\varPi }_{L}\), when applied to a vector whose components are indexed by \({\mathscr {J}}_L\), folds the vector into a DL-dimensional array, transposes the DL indices according to the transformation of ordering in the product
. The matrix \(\varvec{\varPi }_{L}\), when applied to a vector whose components are indexed by \({\mathscr {J}}_L\), folds the vector into a DL-dimensional array, transposes the DL indices according to the transformation of ordering in the product  from big-endian to little-endian and unfolds the resulting array back into a vector.
from big-endian to little-endian and unfolds the resulting array back into a vector.
In other words, the matrix \(\varvec{\varPi }_{L}\), acting on a vector whose entries are enumerated so that the indices corresponding to each dimension and all of the levels occur one after another, rearranges the entries in such a way that the indices corresponding to each level and all of the dimensions occur one after another. In the present paper, we will use \(\varvec{\varPi }_{L}\) to permute the rows and columns of matrices, as the following example illustrates.
Example 2
In the case of \(D=2\) and \(L=3\), the following relation holds:

where we use the matrices that we defined in (37) above.
Similarly, for every \(L\in {{\mathbb {N}}}\) and  , we introduce \(\widetilde{\varvec{\varPi }}_{L,\alpha }\) as a permutation matrix of order
, we introduce \(\widetilde{\varvec{\varPi }}_{L,\alpha }\) as a permutation matrix of order  with rows and columns indexed by
with rows and columns indexed by  , where \({\mathscr {J}}_L\) is given by (16). Specifically, we define \(\widetilde{\varvec{\varPi }}_{L,\alpha }\) by
, where \({\mathscr {J}}_L\) is given by (16). Specifically, we define \(\widetilde{\varvec{\varPi }}_{L,\alpha }\) by

for all \(i_{k,\ell }=1,2\) with \(k=1,\ldots ,D\) and \(\ell =1,\ldots ,L\) and for all  with \(k=1,\ldots ,D\).
with \(k=1,\ldots ,D\).
4 Representation Conditioning
Since the TT decomposition is based on low-rank matrix factorization, redundancy (linear dependence) in explicit TT representations can be eliminated analytically. This is illustrated in “Appendix B”: see (114a)–(114c) and, for more practical examples, the proof of Lemma 5. On the other hand, in the course of computations, this reduction has to be done numerically. In exact arithmetic, it can always be achieved by the TT rounding algorithm [45, Algorithm 2] using the TT-SVD. In practice, however, it may fail due to round-off errors: a small perturbation of a single core in a TT decomposition may, through catastrophic cancellations, introduce a large perturbation in the represented tensor. This can occur even in the course of orthogonalization (Algorithm 3.1), which is essential for ensuring the stability of the TT rounding algorithm. We now turn to an analysis of the potential for such error amplification, which we refer to as representation conditioning.
4.1 Examples of Ill-Conditioned Tensor Representations
We first consider a simple example of a tensor where relative perturbations on the order of the machine precision can lead to large changes in the represented tensors.
Example 3
Take \(D=1\) (so that \({\mathscr {I}}=\{0,1\}\)) and let \(\varvec{x}\) be the tensor with all entries equal to one, \(\varvec{x}_{i_1,\ldots ,i_L} = 1\) for \(i_1,\ldots , i_L\in {\mathscr {I}}\). Clearly, \(\varvec{x}\) can be represented by \(\mathsf {X} = (X_\ell )_{\ell =1,\ldots ,L}\) with \({{\,\mathrm{ranks}\,}}(\mathsf {X}) = (1, \ldots , 1)\), where \(X_\ell = [(1,1)^{\mathsf {T}}\!\,]\) for each \(\ell \). However, we also have an alternative representation \(\mathsf {Y}\) with \({{\,\mathrm{ranks}\,}}(\mathsf {Y}) = (2, \ldots , 2)\): for any fixed \(R>0\) and \(y_0 = (0,0)^{\mathsf {T}}\!\), \(y_R = (R,R)^{\mathsf {T}}\!\), we instead set
For \(\varepsilon >0\), consider a perturbation of \(\mathsf {Y}\) by replacing \(Y_\ell \) for some fixed \(1<\ell <L\) by
This corresponds to a relative error of order \(\varepsilon \) with respect to \(\Vert Y_\ell \Vert _{2}\). The resulting perturbed tensor \(\varvec{x}_\varepsilon \) is again constant with entries \(1 + (R^L+1)\varepsilon \), and therefore satisfies
For instance, with \(R=4\) and \(L\ge 25\), we obtain \(R^L> 10^{15}\). Consequently, any numerical manipulation of the representations can then lead to very large round-off errors that leave no significant digits in the output; in particular, an automatic rank reduction of the representation by SVD will in general not produce any useful result.
To illustrate this numerically, we consider the left-orthogonalization \({\text {orth}}^-(\mathsf {Y})\) with \(R=4\) and machine precision \(\varepsilon \approx 2\times 10^{-16}\), which is also the first step in computing the TT-SVD. In exact arithmetic, the tensor \(\tau ({\text {orth}}^-(\mathsf {Y}))\) is identical to \(\tau (\mathsf {Y})\); however, in inexact arithmetic, this can be far from true. The associated relative numerical errors are compared to bound (53) in Table 1. We consider two ways of evaluating the difference in \(\ell ^2\)-norm: by extracting all tensor entries and computing the norm of their differences directly, or by assembling the difference in TT format and computing its norm using another orthogonalization. Due to numerical effects, the resulting values are not identical, but agree in their order of magnitude, which is also the same as predicted for a particular perturbation by (53).
The type of instability observed in Example 3 occurs in a similar way in other operations, for instance in the computation of inner products, or even in the extraction of a single entry of the tensor. Due to its fundamental importance in many algorithms, we use orthogonalization as an illustrative example in what follows.
Example 3 may seem artificial, since in the explicit construction of tensor representations one will usually try to avoid such redundant representations that can cause cancellations. However, redundancies of this kind may also be generated when matrix-vector products are performed. We next consider an example of practical relevance where a matrix and a vector are each given in a multilevel tensor representation of minimal ranks, but the resulting representation of their product has a similar ill-conditioning as the previous example.
Example 4
We consider the negative Laplacian with homogeneous Dirichlet boundary conditions on (0, 1), discretized by piecewise linear finite elements on a uniform grid with \(2^L\) interior nodes. The resulting stiffness matrix \(\varvec{A}^{\text {DD}}_L\in {{\mathbb {R}}}^{2^L\times 2^L}\) satisfies \(\varvec{A}^{\text {DD}}_L = A_1 {{\,\mathrm{\bowtie }\,}}\cdots {{\,\mathrm{\bowtie }\,}}A_L\) with \(A_1 = 4 \begin{bmatrix} I&J^{\mathsf {T}}\!&J \end{bmatrix}\),
as derived in [35, Cor. 3.2], where \(H = 1 + 2^{-L}\) and the elementary blocks are as defined in (37). The first eigenvector of \(\varvec{A}^{\text {DD}}_L\), corresponding to the lowest eigenvalue \(\lambda _{\text {min},L} \approx \pi ^2\), is \(\varvec{x}_{\text {min},L} = \bigl ( \sin ( \pi i 2^{-L} / H) \bigr )_{i=1,\ldots ,2^L} = X_1{{\,\mathrm{\bowtie }\,}}\cdots {{\,\mathrm{\bowtie }\,}}X_L\), where
with \(t_\ell =\pi 2^{-\ell } / H\),
Then, the representation \(\mathsf {A} \bullet \mathsf {X}\) of the matrix-vector product \(\varvec{A}^{\text {DD}}_L\varvec{x}_{\text {min},L}\) in exact arithmetic satisfies \(\tau (\mathsf {A} \bullet \mathsf {X}) = \varvec{A}^{\text {DD}}_L\varvec{x}_{\text {min},L} = \lambda _{\text {min},L} \varvec{x}_{\text {min},L} = \lambda _{\text {min},L} \tau (\mathsf {X})\).
We consider a similar numerical test as in Example 3, comparing the relative error in \({\text {orth}}^-(\mathsf {A} \bullet \mathsf {X})\) to that of \({\text {orth}}^-(\mathsf {X})\). The results are given in Table 2, where differences are computed in the TT format. Whereas the numerical manipulation of \(\mathsf {X}\) leads to errors close to the machine precision \(\varepsilon \), in \({\text {orth}}^-(\mathsf {A} \bullet \mathsf {X})\) we observe large relative errors of order \(2^{2L}\varepsilon \). Note that the representation (54) of \(A_L^{DD}\) has a similar structure as the redundant representation (52) in the previous example: the cores \(A_1,\ldots ,A_{L-1}\) have only positive entries, whereas \(A_L\) can introduce cancellations, in particular when the matrix is applied to low-frequency grid functions as above.
4.2 Representation Amplification Factors and Condition Numbers
We now introduce a quantitative measure for the stability of TT representations under numerical manipulations. To first order in the size of the perturbation, it is determined by the relative condition numbers of the multilinear mapping \(\tau \) with respect to the component tensors in its argument. Here, we use the appropriate metric on the components that corresponds to the above-considered perturbations arising in linear algebra operations.
Definition 3
We define the representation amplification factors of \(\mathsf {X} \in \mathrm {TT}_L\), for \(\ell =1,\ldots ,L\), by
and the representation condition numbers by
By the multilinearity of \(\tau \), if \(\mathsf {X}, {{\tilde{\mathsf {X}}}}\in \mathrm {TT}_L\) with \(\varvec{x} = \tau (\mathsf {X})\), \({{\tilde{\varvec{x}}}} = \tau ({{\tilde{\mathsf {X}}}})\) are such that \(\Vert {{\tilde{X}}}_\ell - X_\ell \Vert _{2} \le \varepsilon \Vert X_\ell \Vert _{2}\) for each \(\ell \), then for such relative perturbations of size \(\varepsilon \) of cores we have the bounds
In the following characterization, we use the notation \(\tau ^-_\ell \) and \(\tau ^+_\ell \) for left and right partial matricizations as introduced in (43c)–(43d).
Proposition 1
For any \(\mathsf {X} \in \mathrm {TT}_L\) and \(\ell = 1,\ldots , L\),
Proof
For fixed \(\ell \) in (56), let \(\mathsf {X}, {{\tilde{\mathsf {X}}}}\) satisfy the conditions in the supremum. Then,

The claim thus follows by taking the supremum over \({{\tilde{X}}}_\ell \) such that  , which is in fact attained. \(\square \)
, which is in fact attained. \(\square \)
Remark 3
The quantities in Definition 3 measuring the amplification of perturbations can be defined in an analogous way for more general tensor networks by considering perturbations in the respective components; see [7, 22, 42, 49] for an overview on such more general tensor formats.
We have the following general observations concerning possible representation condition numbers, where in certain special cases, we can also give bounds that depend only on the TT ranks. Here, we use the notion of TT-SVD forms introduced in Sect. 3.5.
Proposition 2
Let \(\mathsf {X}\in \mathrm {TT}_L\), then the following hold for \(\ell = 1, \ldots , L\).
-
(i)
One has \({{\,\mathrm{rcond}\,}}_\ell (\mathsf {X}) \ge 1\).
-
(ii)
If \({{\,\mathrm{rank}\,}}_{\ell -1}(\mathsf {X}) = {{\,\mathrm{rank}\,}}_\ell (\mathsf {X}) = 1\), then \({{\,\mathrm{rcond}\,}}_\ell (\mathsf {X}) = 1\).
-
(iii)
If \(\mathsf {X}\) is in right-orthogonal TT-SVD form, then \({{\,\mathrm{rcond}\,}}_\ell (\mathsf {X}) \le \sqrt{{{\,\mathrm{rank}\,}}_{\ell -1}(\mathsf {X})}\); if it is in left-orthogonal TT-SVD form, then \({{\,\mathrm{rcond}\,}}_\ell (\mathsf {X}) \le \sqrt{{{\,\mathrm{rank}\,}}_{\ell }(\mathsf {X})}\).
Proof
Statement (i) follows by estimating \(\Vert \tau (\mathsf {X})\Vert _{2}\) as in the proof of Proposition 1; (ii) follows directly from properties of the Kronecker product. To show (iii), it suffices to consider the right-orthogonal case. With \(\varvec{x} = \tau (\mathsf {X})\) and \(r_\ell = {{\,\mathrm{rank}\,}}_\ell (\mathsf {X})\) for each \(\ell \), we need to show that \({{\,\mathrm{ramp}\,}}_\ell (\mathsf {X}) \le \sqrt{r_{\ell -1}} \Vert \varvec{x}\Vert _{2}\) for each \(\ell \). Since \(\tau ^+_\ell (\mathsf {X})\) has orthonormal rows, \(\Vert \tau ^+_\ell (\mathsf {X})\Vert _{2\rightarrow 2} =1\) for each \(\ell \). For \(\ell =1\), we also have \(\Vert \tau ^-_\ell (\mathsf {X})\Vert _{2\rightarrow 2} = 1\) by definition and \(\Vert X_\ell \Vert _{2}=\Vert \varvec{x}\Vert _{2}\). For \(\ell >1\), by right-orthogonality of \(X_\ell \) we have \(\Vert X_\ell \Vert _{2} = \sqrt{r_{\ell -1}}\). In this case, since the representation is in TT-SVD form, \(\tau ^-_\ell (\mathsf {X})\) has orthogonal columns whose \(\ell ^2\)-norms are the singular values of \(\mathrm {U}_{\ell }(\varvec{x})\), and thus \(\Vert \tau ^-_\ell (\mathsf {X})\Vert _{2\rightarrow 2} \le \Vert \varvec{x}\Vert _{2}\). \(\square \)
Modifications to the components of a TT representation that leave the represented tensor unchanged can still lead to a change in the representation condition numbers. This change can be bounded from above as follows.
Proposition 3
For given \(\mathsf {X} \in \mathrm {TT}_L\), \(1 \le \ell < L\), and invertible \(R \in {{\mathbb {R}}}^{r_\ell \times r_{\ell }}\), where \(r_\ell = {{\,\mathrm{rank}\,}}_\ell (\mathsf {X})\), let \({{\tilde{\mathsf {X}}}}\) be identical to \(\mathsf {X}\) except for  ,
,  for \(i\in {\mathscr {I}}\). Then, \(\tau (\mathsf {X}) = \tau ({{\tilde{\mathsf {X}}}})\) and
for \(i\in {\mathscr {I}}\). Then, \(\tau (\mathsf {X}) = \tau ({{\tilde{\mathsf {X}}}})\) and
In the particular case when the matrix \( \tau ^+_\ell ({{\tilde{\mathsf {X}}}})\) has orthonormal rows, one has the stronger bound
If \( {{\tilde{X}}}_{\ell +1}\) is right-orthogonal, then
Proof
The estimates (58) follow from
for the first, and analogous estimates for the second inequality. To see (59), observe that \(R \tau ^+_\ell ({{\tilde{\mathsf {X}}}}) = \tau ^+_\ell (\mathsf {X})\) and that under the given additional assumption, \(\Vert \tau ^+_\ell ({{\tilde{\mathsf {X}}}})\Vert _{2\rightarrow 2} = 1\) and \(\Vert \tau ^+_\ell (\mathsf {X})\Vert _{2\rightarrow 2} = \Vert R\Vert _{2\rightarrow 2}\). Under the further assumption for (60), we have \(\Vert X_{\ell +1}\Vert _2 = \Vert R\Vert _F\), and thus
\(\square \)
Note that the improved bounds (59) and (60), which do not depend on the particular transformation R, correspond to the transformations made in algorithms for right-orthogonalizing \(\mathsf {X} \in \mathrm {TT}_L\). When the roles of \({{\tilde{X}}}_{\ell }\), \(\tilde{X}_{\ell +1}\) and the corresponding orthogonality requirements are reversed, (59) and (60) are replaced by \({{\,\mathrm{ramp}\,}}_{\ell +1} ({{\tilde{\mathsf {X}}}}) \le {{\,\mathrm{ramp}\,}}_{\ell +1} (\mathsf {X})\) and \({{\,\mathrm{ramp}\,}}_{\ell } ({{\tilde{\mathsf {X}}}}) \le \sqrt{ r_{\ell +1}} \, {{\,\mathrm{ramp}\,}}_{\ell } (\mathsf {X})\).
4.3 Orthogonalization as an Example of a Numerical Operation
Orthogonalization of tensor train representations is usually done via QR decompositions of matricized cores. When performed at machine precision \(\varepsilon \), these decompositions are affected by round-off errors: applied to \(M \in {{\mathbb {R}}}^{m\times n}\), where \(mn \varepsilon \) is sufficiently small, as shown in [27, §19] the standard Householder algorithm yields \({{\tilde{Q}}}, {{\tilde{R}}}\) such that
As a consequence of Proposition 3, we obtain a statement on the numerical errors incurred by orthogonalization of TT representations. As a simplifying assumption, let us suppose that the QR factorizations in \({\text {orth}}^-(\mathsf {X})\), \({\text {orth}}^+(\mathsf {X})\) of \(\mathsf {X}\in \mathrm {TT}_L\) are computed with machine precision \(\varepsilon \) up to the error bound (61), but that matrix–matrix multiplications are performed exactly (and hence the computed Householder reflectors act as exactly orthogonal matrices). Then, recursively using (59), (60), we obtain
where \(r_{\ell } = {{\,\mathrm{rank}\,}}_\ell (\mathsf {X})\) for \(\ell =1,\ldots ,L\). The analogous statements for the relative errors \(\Vert \tau ({\text {orth}}^+(\mathsf {X})) - \tau (\mathsf {X})\Vert _2/{\Vert \tau (\mathsf {X})\Vert _2}\) and \(\Vert \tau ({\text {orth}}^-(\mathsf {X})) - \tau (\mathsf {X})\Vert _2/{\Vert \tau (\mathsf {X})\Vert _2}\) hold with \({{\,\mathrm{ramp}\,}}\) replaced by \({{\,\mathrm{rcond}\,}}\).
Taking into account further numerical effects due to inexact matrix–matrix multiplications leads to substantially more complicated bounds involving additional prefactors depending more strongly on intermediate steps in the algorithms. As our numerical illustrations in Sect. 4.1 demonstrate, however, the order of magnitude of the resulting errors is typically already very well predicted by the bounds (62), (63).
4.4 Representations of Operators
Definition 4
For \(\ell =1,\ldots ,L\), we define the representation amplification factor and representation condition number of the matrix representation \(\mathsf {A} \in \mathrm {TT}^2_L\) by
In other words, these are the largest factors by which the action of the matrix representation \(\mathsf {A}\) can possibly change the representation amplification factors and the condition numbers of a vector representation. By definition, these functions are submultiplicative:
We do not have an explicit representation of these quantities as in Proposition 1, but we obtain the following upper bound in terms of the components of representations.
Proposition 4
For \(\mathsf {A}\in \mathrm {TT}^2_L\), we define the matrices
Then, \({{\,\mathrm{mramp}\,}}_\ell (\mathsf {A}) \le \beta _\ell (\mathsf {A})\) for \(\ell = 1,\ldots ,L\), where we define

and if \(\tau (\mathsf {A})\) is invertible,
Proof
By Proposition 1, with \(\mathsf {Y} = \mathsf {A} \bullet \mathsf {X}\),
The first statement follows with the estimates

and
as well as the analogous bound for \(\tau ^+_\ell (\mathsf {Y})\). For (66), note that if \(\tau (\mathsf {A})\) is invertible, then
\(\square \)
In certain situations, Proposition 4 provides qualitatively sharp bounds. We now demonstrate this in the simple example of the stiffness matrix for the Dirichlet Laplacian on (0, 1). Similar results are observed numerically for direct representations of more general stiffness matrices of second-order elliptic problems.
Proposition 5
Let \(\varvec{A}^{\mathrm {DD}}_L\) be as in Example 4, and let \(\mathsf {A}\) with \(\tau (\mathsf {A}) = \varvec{A}^{\mathrm {DD}}_L\) be as in (54). Then, for \(\ell = 1, \ldots , L\), one has \( {{\,\mathrm{mramp}\,}}_\ell (\mathsf {A}) \sim 2^{2L} \) and \( 2^{(3L + \ell )/2} \lesssim {{\,\mathrm{mrcond}\,}}_\ell (\mathsf {A}) \lesssim 2^{2L}. \)
Proof
The upper bounds follow by direct computation from Proposition 4 via evaluation of the auxiliary matrices in (65). For the lower bound on \({{\,\mathrm{mramp}\,}}_\ell (\mathsf {A})\), we estimate the supremum from below using the representation \(\mathsf {X}_{{\mathrm {max}}}\) analogous to (55) of the eigenvector \(\varvec{x}_{\text {max},L} = \bigl ( \sin ( \pi i / H) \bigr )_{i=1,\ldots ,2^L}\) corresponding to the largest eigenvalue \(\lambda _{\text {max},L} \sim 2^{2L}\). To this end, it suffices to evaluate \({{\,\mathrm{ramp}\,}}_\ell (\mathsf {A}\bullet \mathsf {X}_{{\mathrm {max}}})/{{\,\mathrm{ramp}\,}}_\ell (\mathsf {X}_{{\mathrm {max}}})\) via Proposition 1 in a direct but tedious calculation. For the lower bound on \({{\,\mathrm{mrcond}\,}}_\ell (\mathsf {A})\), we instead use \(\varvec{x}_{{\mathrm {min}},L} = \bigl (\sin ( \pi i 2^{-L} / H) \bigr )_{i=1,\ldots ,2^L}\) in the representation (55). \(\square \)
Thus, applying the matrix representation \(\mathsf {A}\) to the tensor decomposition \(\mathsf {X}\) of a vector may in general increase its representation condition number by a factor proportional to \(2^{2L}\). For instance, if \(\mathsf {X}\) is given in TT-SVD form with representation condition number close to one, the further numerical manipulation of \(\mathsf {A}\bullet \mathsf {X}\) can cause errors of order \({\mathscr {O}}( 2^{2L} \varepsilon \Vert \tau (\mathsf {X})\Vert _2)\). This effect is observed also in the numerical tests in Sect. 7.1.
5 Multilevel Low-Rank Tensor Structure of the Operator
In this section, we analyze the low-rank structure of the preconditioner \(\varvec{C}_{L}\), given by (30), and of the preconditioned discrete differential operator \(\varvec{B}_{L}\) in the form of (33b). The resulting low-rank representations are designed specifically to have small representation condition numbers in the sense of Definition 4, which is not generally the case for low-rank decompositions of \(\varvec{B}_{L}\).
The central idea for obtaining well-conditioned representations is to directly combine the representations of differential operators \(\hat{\varvec{M}}_{L ,{\,}\!\alpha }\) as in (12d) with those of the averaging matrices \(\hat{\varvec{P}}_{\ell ,L}\) in the preconditioner. This leads to a natural rank-reduced representation of the products \(\hat{\varvec{M}}_{L ,{\,}\!\alpha } \hat{\varvec{P}}_{\ell ,L}\), where the cancellations causing representation ill-conditioning that are present in the tensor decomposition of \(\hat{\varvec{M}}_{L ,{\,}\!\alpha }\) are explicitly absorbed by the preconditioner and thus removed from the final representation.
5.1 Auxiliary Results
In this section, for \(\ell \in {{\mathbb {N}}}\), we present explicit joint representations of the identity matrix \(\hat{\varvec{I}}_{\ell }\) and of the shift matrix \(\hat{\varvec{S}}_{\ell }\), given by (12e), and of the linear vectors \(\hat{\varvec{\xi }}_{\ell }\) and \(\hat{\varvec{\eta }}_{\ell }\), defined in (15). These representations will be presented here in terms of the following cores:
Our derivations will also involve the square Kronecker product matrices
with \(\ell \in {{\mathbb {N}}}\) and iterated strong Kronecker products, such as \(\hat{U}^{{{\,\mathrm{\bowtie }\,}}\ell } = U {{\,\mathrm{\bowtie }\,}}\cdots {{\,\mathrm{\bowtie }\,}}U\) with \(\ell \in {{\mathbb {N}}}\) factors.
We start with the following auxiliary result, which appeared in slightly different forms in [30, 35]. The brief derivation, in the form given here, provides an illustration and simplifies further proofs given below.
Lemma 1
For every \(\ell \in {{\mathbb {N}}}\), the matrices \(\hat{\varvec{I}}_{\ell }\), \(\hat{\varvec{S}}_{\ell }\) and \(\hat{\varvec{J}}_{\ell }\), given by (12e) and (68), satisfy
where the blocks I and J are given by (37) and the core \(\hat{U}\) is as defined in (67).
Proof
For \(\ell =1\), the claim is trivial. Let us assume that \(\ell > 1\). Then, splitting each of the matrices \(\hat{\varvec{S}}_{\ell }\), \(\hat{\varvec{I}}_{\ell }\) and \(\hat{\varvec{J}}_{\ell }\) into four blocks, we obtain the following recurrence relations:
Using the core product, these relations can be recast as
Applying (71) recursively, we obtain (69). \(\square \)
As the following auxiliary result shows, a similar technique applies to cores whose blocks are vectors.
Lemma 2
For every \(\ell \in {{\mathbb {N}}}_0\), the vectors \(\hat{\varvec{\xi }}_{\ell }\) and \(\hat{\varvec{\eta }}_{\ell }\), given by (15), satisfy
where \({\hat{X}}\) is given by (67).
Proof
For \(\ell =0,1\), the claim is trivial. Let us assume that \(\ell > 1\). Splitting each of the vectors \(\hat{\varvec{\xi }}_{\ell }\) and \(\hat{\varvec{\eta }}_{\ell }\) into two blocks, we arrive at the recursion
from which it is easy to see that

Using the core product, relations (73a) and (73b) can be recast as
Applying (74) recursively and comparing \(\hat{\varvec{\xi }}_1\) and \(\hat{\varvec{\eta }}_1\) with the first column of the core \(\hat{X}\), which is given by \(\hat{X} {{\,\mathrm{\bowtie }\,}}\hat{P}\), we obtain (72). \(\square \)
5.2 Explicit Analysis of Univariate Factors
In this section, we show how the auxiliary results of Sect. 5.1 translate into low-rank decompositions of the univariate factors \(\hat{\varvec{M}}_{L ,{\,}\!\alpha }\) with  and \(\hat{\varvec{P}}_{\ell ,L}\) with \(\ell =0,\ldots ,L\), where \(L\in {{\mathbb {N}}}\). These matrices are introduced in (12d) and (14). Let
and \(\hat{\varvec{P}}_{\ell ,L}\) with \(\ell =0,\ldots ,L\), where \(L\in {{\mathbb {N}}}\). These matrices are introduced in (12d) and (14). Let
Lemma 3
For every \(L\in {{\mathbb {N}}}\) and for \(\alpha =0,1\), the matrix \(\hat{\varvec{M}}_{L ,{\,}\!\alpha }\), given by (12d), satisfies

for every \(\ell =0,\ldots ,L\), where the cores \(\hat{A}\), \(\hat{U}\), \(\hat{V}\), \(\hat{T}_{0}\) and \(\hat{M}_\alpha \) with \(\alpha =0,1\) are given by (67) and (75).
Proof
Consider \(L\in {{\mathbb {N}}}\) and  . Immediately from (12d), we obtain the representation
. Immediately from (12d), we obtain the representation

Applying Lemma 1, we arrive at the claimed decomposition in the case of \(\ell =L\),

Using that \(\hat{T}_{0} {{\,\mathrm{\bowtie }\,}}\hat{T}_{0} = 2 {\,}\!\hat{I}\), we obtain

for every \(\ell =0,\ldots ,L-1\), which completes the proof due to (75). \(\square \)
Lemma 4
For all \(L\in {{\mathbb {N}}}_0\) and \(\ell =0,\ldots ,L\), the matrix \(\hat{\varvec{P}}_{\ell ,L}\), given by (14), has the representation

where \(\hat{A}\), \(\hat{U}\), \(\hat{X}\) and \(\hat{P}\) are the cores given by (67) and (75).
Proof
We start with rewriting (14) in terms of the core product as

where the middle core should be omitted when \(\ell =0\). Applying Lemma 1 (for \(\ell > 0\)) and Lemma 2 to expand the middle and the last cores, we prove the claim. \(\square \)
5.3 Explicit Analysis of Univariate Factors Under Preconditioning
Here, obtain an optimal-rank representation of the product \(\varvec{M}_{L ,{\,}\!\alpha } \, \varvec{P}_{\ell ,L}\) and note how the products \( \hat{\varvec{M}}_{L ,{\,}\!\alpha } \, \hat{\varvec{P}}_{\ell ,L} \, \hat{\varvec{P}}_{\ell ,L}^{\mathsf {T}}\!\) and \(\hat{\varvec{P}}_{\ell ,L} \, \hat{\varvec{P}}_{\ell ,L}^{\mathsf {T}}\!\) can be represented, all for \(L\in {{\mathbb {N}}}\),  and \(\ell =0,\ldots ,L\).
and \(\ell =0,\ldots ,L\).
The optimal-rank representation of the product \(\varvec{M}_{L ,{\,}\!\alpha } \, \varvec{P}_{\ell ,L}\) is obtained in terms of the following cores:
The proof of the following lemma is rather technical and is therefore given in “Appendix B.”
Lemma 5
For all \(L,\ell \in {{\mathbb {N}}}_0\) such that \(\ell \le L\), the matrices \( \hat{\varvec{M}}_{L ,{\,}\!\alpha } \, \hat{\varvec{P}}_{\ell ,L} \) with \(\alpha =0,1\), where the factors are given by (12d) and (14), admit the representation

where the cores \(\hat{A}\), \(\hat{U}\) and \(\hat{T}_{\alpha }\), \(\hat{Y}_{\alpha }\), \(\hat{N}_{\alpha }\) with \(\alpha =0,1\) are as in (67) and (75).
Combining decomposition (77) and its transpose, we can rewrite the product \( \hat{\varvec{P}}_{\ell ,L} {\,}\!\hat{\varvec{P}}_{\ell ,L}^{\mathsf {T}}\!\) core-wise:

where the factors are
We remark that the ranks of the decomposition (80) are \(4,\ldots ,4\).
Applying the same argument to the product  , the factors \(\hat{\varvec{M}}_{L ,{\,}\!\alpha }\) and \(\hat{\varvec{P}}_{\ell ,L} \, \hat{\varvec{P}}_{\ell ,L}^{\mathsf {T}}\!\) being taken in the form of (76) and (80), we could obtain its explicit decomposition with ranks \(2^3,\ldots ,2^3\). Instead, we multiply \(\hat{\varvec{M}}_{L ,{\,}\!\alpha } \, \hat{\varvec{P}}_{\ell ,L}\) and \(\hat{\varvec{P}}_{\ell ,L}^{\mathsf {T}}\!\) using the representations (79) and (77) to form a representation of the same product \( \hat{\varvec{M}}_{L ,{\,}\!\alpha } \, \hat{\varvec{P}}_{\ell ,L} \, \hat{\varvec{P}}_{\ell ,L}^{\mathsf {T}}\!\). This representation has the ranks \(2^2,\ldots ,2^2,2^{2-\alpha },\ldots ,2^{2-\alpha }\), which means that the ranks of unfolding matrices \(1,\ldots ,\ell -1\) and \(\ell ,\ldots ,L-\alpha \) are bounded by 4 and \(2^{2-\alpha }\), respectively. As we discuss in Sect. 5.4, this reduction is substantial in the case of multiple dimensions, when the exponents (2 or \(2-\alpha \) instead of 3) that correspond to the dimensions are summed.
, the factors \(\hat{\varvec{M}}_{L ,{\,}\!\alpha }\) and \(\hat{\varvec{P}}_{\ell ,L} \, \hat{\varvec{P}}_{\ell ,L}^{\mathsf {T}}\!\) being taken in the form of (76) and (80), we could obtain its explicit decomposition with ranks \(2^3,\ldots ,2^3\). Instead, we multiply \(\hat{\varvec{M}}_{L ,{\,}\!\alpha } \, \hat{\varvec{P}}_{\ell ,L}\) and \(\hat{\varvec{P}}_{\ell ,L}^{\mathsf {T}}\!\) using the representations (79) and (77) to form a representation of the same product \( \hat{\varvec{M}}_{L ,{\,}\!\alpha } \, \hat{\varvec{P}}_{\ell ,L} \, \hat{\varvec{P}}_{\ell ,L}^{\mathsf {T}}\!\). This representation has the ranks \(2^2,\ldots ,2^2,2^{2-\alpha },\ldots ,2^{2-\alpha }\), which means that the ranks of unfolding matrices \(1,\ldots ,\ell -1\) and \(\ell ,\ldots ,L-\alpha \) are bounded by 4 and \(2^{2-\alpha }\), respectively. As we discuss in Sect. 5.4, this reduction is substantial in the case of multiple dimensions, when the exponents (2 or \(2-\alpha \) instead of 3) that correspond to the dimensions are summed.
Specifically, combining (79) and (77), we arrive at

where
Decomposition (82) is exact and explicit, the latter meaning that all the cores involved are provided in closed form. Since \(\hat{U}_\flat \) and \(\hat{Y}_{\alpha }\) are of ranks \(2^2 \times 2^2\) and \(2^{2-\alpha } \times 2^{2-\alpha }\), respectively, the ranks of decomposition (82) are \(2^2,\ldots ,2^2,2^{2-\alpha },\ldots ,2^{2-\alpha }\).
Direct calculation with expressions given in (67)–(75) leads to \( \hat{A}_\flat = \begin{bmatrix} 1 &{} 0 &{} 0 &{} 0 \\ \end{bmatrix} \),
Explicit expression for \(\hat{U}_\flat \), \(\hat{X}_\flat \) and \(\hat{Z}_\alpha \), \(\hat{K}_\alpha \) with \(\alpha =0,1\) can be likewise calculated based on (67) and (75), from which we refrain to keep exposition concise.
5.4 Analysis in D Dimensions by Tensorization
In this section, we generalize the results of Sect. 5.3 to the case of multiple dimensions and analyze the low-rank tensor structure of the preconditioner \(\varvec{C}_{L}\), given by (30), and of the preconditioned discrete differential operator \(\varvec{B}_{L}\) in the form of (33b). For the latter, we first derive a representation of the matrices \(\varvec{Q}_{L ,{\,}\!\alpha }\) with \(L\in {{\mathbb {N}}}\) and  , which are defined in (33c).
, which are defined in (33c).
The representations derived below are composed from the following cores:
for all  , where the factors are given by (81) and (83).
, where the factors are given by (81) and (83).
Tensorizing (80) core-wise and distributing the scaling factor over the cores, we obtain the decompositions

of ranks \(2^{2D},\ldots ,2^{2D}\), where the cores are given by (85) and the permutation matrix \(\varvec{\varPi }_{L}\) is as defined in (49). Applying [35, Lemma 5.5] to the sum of such matrices with \(\ell =1,\ldots ,L\) and adding the term corresponding to \(\ell =0\), we obtain the following result.
Theorem 3
For any \(L\in {{\mathbb {N}}}\), the matrix \(\varvec{C}_{L}\), defined by (30), admits the decomposition
of ranks \(2^{2D}+2^{2D},\ldots ,2^{2D}+2^{2D}\), all equal to \(2^{2D+1}\), where the middle cores are
the subcores being as in (85).
For any \(L\in {{\mathbb {N}}}\), \(\ell =0,1\ldots ,L\) and  , tensorizing (82) core-wise and distributing the scaling factor over the cores result in the decompositions
, tensorizing (82) core-wise and distributing the scaling factor over the cores result in the decompositions

of ranks  , where \(\varvec{M}_{L ,{\,}\!\alpha }\) and \(\varvec{P}_{\ell ,{\,}\!L}\) are given by (20c) and (22), the cores are given by (85) and the permutation matrices \(\varvec{\varPi }_{L}\) and \(\varvec{{\widetilde{\varPi }}}_{L ,{\,}\!\alpha }\) are as defined in (49) and (51).
, where \(\varvec{M}_{L ,{\,}\!\alpha }\) and \(\varvec{P}_{\ell ,{\,}\!L}\) are given by (20c) and (22), the cores are given by (85) and the permutation matrices \(\varvec{\varPi }_{L}\) and \(\varvec{{\widetilde{\varPi }}}_{L ,{\,}\!\alpha }\) are as defined in (49) and (51).
Similarly as for \(\varvec{C}_{L}\) above, we can apply [35, Lemma 5.5] to the sum of the matrices given by (88) with \(\ell =1,\ldots ,L\) and add the term corresponding to \(\ell =0\). This leads to the following result, which is analogous to Theorem 3.
Theorem 4
For any \(L\in {{\mathbb {N}}}\) and  , the matrix \(\varvec{Q}_{L ,{\,}\!\alpha }\), given by (33c), admits the decomposition
, the matrix \(\varvec{Q}_{L ,{\,}\!\alpha }\), given by (33c), admits the decomposition
of ranks  , all bounded from above by \(2^{2D+1}\), where the middle cores are
, all bounded from above by \(2^{2D+1}\), where the middle cores are

the subcores being defined by (85).
In Example 1, the case of the Laplace operator was considered and the factors \(\varvec{\varLambda }_{L ,{\,}\!\alpha \alpha '}\) with  for the suitable \({\mathscr {D}}\) were explicitly given in the Kronecker product form (27a). That form immediately leads to a multilevel TT decomposition of ranks \(1,\ldots ,1\) for each \(\varvec{\varLambda }_{L ,{\,}\!\alpha \alpha '}\). Here, we analyze the structure of \(\varvec{\varLambda }_{L ,{\,}\!\alpha \alpha '}\) with
for the suitable \({\mathscr {D}}\) were explicitly given in the Kronecker product form (27a). That form immediately leads to a multilevel TT decomposition of ranks \(1,\ldots ,1\) for each \(\varvec{\varLambda }_{L ,{\,}\!\alpha \alpha '}\). Here, we analyze the structure of \(\varvec{\varLambda }_{L ,{\,}\!\alpha \alpha '}\) with  in the general setting of Sect. 2.3, for an arbitrary
in the general setting of Sect. 2.3, for an arbitrary  of differential indices, under the additional assumption that the coefficient functions (24b) exhibit low-rank structure.
of differential indices, under the additional assumption that the coefficient functions (24b) exhibit low-rank structure.
Specifically, for each  , we assume that the coefficient vector \( \varvec{c}_{L ,{\,}\!\alpha \alpha '} \in {{\mathbb {R}}}^{{\mathscr {J}}_L \times \varGamma _{\! \alpha \alpha '}} \simeq {{\mathbb {R}}}^{2^{DL} R_{\alpha \alpha '}} \) parametrizing the coefficient function \(c_{\alpha \alpha '}\) through (24b) is given in a multilevel TT representation of ranks \(r_{0 ,{\,}\!\alpha \alpha '},\ldots ,r_{L ,{\,}\!\alpha \alpha '}\):
, we assume that the coefficient vector \( \varvec{c}_{L ,{\,}\!\alpha \alpha '} \in {{\mathbb {R}}}^{{\mathscr {J}}_L \times \varGamma _{\! \alpha \alpha '}} \simeq {{\mathbb {R}}}^{2^{DL} R_{\alpha \alpha '}} \) parametrizing the coefficient function \(c_{\alpha \alpha '}\) through (24b) is given in a multilevel TT representation of ranks \(r_{0 ,{\,}\!\alpha \alpha '},\ldots ,r_{L ,{\,}\!\alpha \alpha '}\):
where each of \(C_{L ,{\,}\!1 ,{\,}\!\alpha ,{\,}\!\alpha '},\ldots ,C_{L ,{\,}\!L ,{\,}\!\alpha ,{\,}\!\alpha '}\) is of mode size \(2^D\), whereas \(C_{L ,{\,}\!0 ,{\,}\!\alpha ,{\,}\!\alpha '}\) is of mode size 1 and \(C_{L ,{\,}\!L+1 ,{\,}\!\alpha ,{\,}\!\alpha '}\) is of mode size  . Then, the corresponding factor \(\varvec{\varLambda }_{L ,{\,}\!\alpha \alpha '}\), given by (26a), can as well be represented with ranks \(r_{0 ,{\,}\!\alpha \alpha '},\ldots ,r_{L ,{\,}\!\alpha \alpha '}\):
. Then, the corresponding factor \(\varvec{\varLambda }_{L ,{\,}\!\alpha \alpha '}\), given by (26a), can as well be represented with ranks \(r_{0 ,{\,}\!\alpha \alpha '},\ldots ,r_{L ,{\,}\!\alpha \alpha '}\):
where the cores are defined in terms of those appearing in (90a) as follows. First, one sets \( \varLambda _{L ,{\,}\!0 ,{\,}\!\alpha ,{\,}\!\alpha '} = C_{L ,{\,}\!0 ,{\,}\!\alpha ,{\,}\!\alpha '} \) and defines each core \(\varLambda _{L ,{\,}\!\ell ,{\,}\!\alpha ,{\,}\!\alpha '}\) with \(\ell =1,\ldots ,L\) by

for all \(\gamma _{\ell -1}=1,\ldots ,r_{\ell -1 ,{\,}\!\alpha \alpha '}\), \(\gamma _\ell =1,\ldots ,r_{\ell ,{\,}\!\alpha \alpha '}\) and \(i_\ell ,i'_\ell =1,2\). Then, the last core should be defined by

for all \(\gamma _L = 1,\ldots ,r_{L ,{\,}\!\alpha \alpha '}\),  and
and  , cf. (26a).
, cf. (26a).
Using the fact that the ranks add under addition and multiply under multiplication [45], we obtain the following result.
Theorem 5
For  and \(L\in {{\mathbb {N}}}\), consider a bilinear form of the type (24a)–(24b), where each coefficient vector \(\varvec{c}_{L ,{\,}\!\alpha \alpha '}\) with
and \(L\in {{\mathbb {N}}}\), consider a bilinear form of the type (24a)–(24b), where each coefficient vector \(\varvec{c}_{L ,{\,}\!\alpha \alpha '}\) with  admits a multilevel TT decomposition of the form (90a) with ranks \(r_{0 ,{\,}\!\alpha \alpha '},\ldots ,r_{L ,{\,}\!\alpha \alpha '}\) not exceeding \(r \in {{\mathbb {N}}}\). Then, the preconditioned matrix \(\varvec{B}_L\) of a, defined by (25a), (30) and (33a), admits a multilevel TT decomposition
admits a multilevel TT decomposition of the form (90a) with ranks \(r_{0 ,{\,}\!\alpha \alpha '},\ldots ,r_{L ,{\,}\!\alpha \alpha '}\) not exceeding \(r \in {{\mathbb {N}}}\). Then, the preconditioned matrix \(\varvec{B}_L\) of a, defined by (25a), (30) and (33a), admits a multilevel TT decomposition
of ranks \(R_0,\ldots ,R_L\), where

for \(\ell =0,\ldots ,L\).
Remark 4
(Sharper bounds in specific cases) The last inequality of (91) is given for a general case with \(D^2\) second-order terms (no symmetry is assumed), D first-order terms and a zero-order term. However, for the Laplacian in the case \(D=2\), the first equality given in (91) results in \(R_\ell = 1152\), which is a marked reduction from the bound \(R_\ell \le 12288\) obtained for a general second-order bilinear form with constant coefficients.
Remark 5
(Inexact application) In computations, algorithms using products of \(\varvec{B}_L\) with vectors rather than explicit representations of \(\varvec{B}_L\) may be expected to be more efficient. Indeed, such products can be formed by adding the products of the terms in the sum (33b), and for each term the product can be computed by three multiplications. On the intermediate results obtained between these multiplications and additions, low-rank re-approximation can be performed, as explained further in the example of the discretized Laplacian in Sect. 5.5. The given bounds for TT ranks appear to be highly pessimistic for such inexact schemes.
Remark 6
The analysis in D dimensions is given here for the most generic discretization obtained by tensorization. The approach can be applied to discretizations that are not of tensor product form in order to mitigate the growth of the rank bounds with respect to D.
5.5 Numerical Illustrations
In summary, we obtain a combined tensor representation \(\mathsf {B}_L\) with  . Similarly, from Theorem 3, we also have \(\mathsf {C}_L\) with \(\tau (\mathsf {C}_L) = \varvec{\varPi }_{L} {\,}\!\varvec{C}_L {\,}\!\varvec{\varPi }_{L}^{\mathsf {T}}\!\). With a representation \(\mathsf {A}_L\) of the stiffness matrix \(\varvec{A}_L\), such that \(\tau (\mathsf {A}_L) = \varvec{\varPi }_{L} {\,}\!\varvec{A}_L {\,}\!\varvec{\varPi }_{L}^{\mathsf {T}}\!\), one can alternatively consider the simple product representation \(\mathsf {C}_L \bullet \mathsf {A}_L \bullet \mathsf {C}_L\), which corresponds to performing the action of the preconditioner \(\varvec{C}_L\) separately from that of \(\varvec{A}_L\).
. Similarly, from Theorem 3, we also have \(\mathsf {C}_L\) with \(\tau (\mathsf {C}_L) = \varvec{\varPi }_{L} {\,}\!\varvec{C}_L {\,}\!\varvec{\varPi }_{L}^{\mathsf {T}}\!\). With a representation \(\mathsf {A}_L\) of the stiffness matrix \(\varvec{A}_L\), such that \(\tau (\mathsf {A}_L) = \varvec{\varPi }_{L} {\,}\!\varvec{A}_L {\,}\!\varvec{\varPi }_{L}^{\mathsf {T}}\!\), one can alternatively consider the simple product representation \(\mathsf {C}_L \bullet \mathsf {A}_L \bullet \mathsf {C}_L\), which corresponds to performing the action of the preconditioner \(\varvec{C}_L\) separately from that of \(\varvec{A}_L\).
Note that, in Sect. 4.4, we have assumed decompositions consisting of L cores. The decompositions in Theorems 3, 4 and 5 comprise \(L+2\) cores, with first and last playing special roles since they can be merged with the respective adjacent cores. The cores in these extended decompositions are thus indexed by \(\ell =0,\ldots ,L+1\) in what follows, so that again the bounds for \(\ell =1,\ldots ,L\) are relevant.
One benefit of the combined representation \(\mathsf {B}_L\) is the rank reduction compared to \(\mathsf {C}_L \bullet \mathsf {A}_L \bullet \mathsf {C}_L\). More importantly, however, the decomposition \(\mathsf {B}_L\) is constructed so that the representation condition numbers \({{\,\mathrm{mrcond}\,}}_\ell (\mathsf {B}_L)\), \(\ell =1,\ldots ,L\), remain moderate even for large L. In contrast, the representation condition numbers of \(\mathsf {C}_L \bullet \mathsf {A}_L \bullet \mathsf {C}_L\) are in general of the same order of magnitude as those of \(\mathsf {A}_L\) – in other words, whereas the matrix condition number of \(\varvec{C}_L \varvec{A}_L \varvec{C}_L\) is uniformly bounded, for improving also the representation condition number, applying the preconditioner \(\varvec{C}_L\) separately is insufficient and one instead needs a carefully constructed combined representation \(\mathsf {B}_L\).
We now present numerical observations that illustrate how different the decompositions \(\mathsf {A}_L\), \(\mathsf {C}_L \bullet \mathsf {A}_L \bullet \mathsf {C}_L\) and \(\mathsf {B}_L\) are in terms of representation conditioning and demonstrate the improvement afforded by our findings presented in Sects. 4, 5.2 and 5.4. As in Example 1, we consider the case of the Laplacian: \(\varvec{A}_L= \varvec{D}_L\) with \(\varvec{D}_L\) as in (103). Using (37), for \(D=1\) we have \(\varvec{A}_L = A_1 {{\,\mathrm{\bowtie }\,}}\cdots {{\,\mathrm{\bowtie }\,}}A_L\) with  ,
,
as derived in [35]; similar representations can be obtained for \(D>1\) by tensorization.
We first consider the upper bounds \(\beta _\ell \), defined in (65), for \({{\,\mathrm{mramp}\,}}_\ell \) from Proposition 4. Since both \(\Vert \varvec{A}_L^{-1}\Vert \) and \(\Vert \varvec{B}_L^{-1}\Vert \) are bounded independently of L, by (66), up to fixed constants the respective \(\beta _\ell \) are also upper bounds of the corresponding representation condition numbers \({{\,\mathrm{mrcond}\,}}_\ell \).
For \(\mathsf {B}_L\), instead of directly computing the estimates for \({{\,\mathrm{mramp}\,}}_\ell (\mathsf {B}_L)\) with \(\ell =1,\ldots ,L\) given by Proposition 4, we will do this for the factors of a decomposition that is equivalent to \(\mathsf {B}_L\) and is also based on (33b). Let us note that the equality
of decompositions holds in terms of the factors \({\Theta }_{L ,{\,}\!k}\) with \(k=1,\ldots ,D\) given as follows: for every k, we set \( {\Theta }_{L ,{\,}\!k} = {\Lambda }_{L ,{\,}\!k}^{1/2} \bullet \mathsf {Q}_{L ,{\,}\!\alpha } \) with  , where \({\Lambda }_{L ,{\,}\!\alpha ,{\,}\!\alpha }^{1/2}\) is the decomposition of \(\varvec{\Lambda }_{L ,{\,}\!\alpha ,{\,}\!\alpha }^{1/2}\), which is diagonal and of Kronecker product form (27a); thus, its decomposition with ranks \(1,\ldots ,1\) is obtained by element-wise application of the square root to each core. Equality (92) results in the second of the following inequalities:
, where \({\Lambda }_{L ,{\,}\!\alpha ,{\,}\!\alpha }^{1/2}\) is the decomposition of \(\varvec{\Lambda }_{L ,{\,}\!\alpha ,{\,}\!\alpha }^{1/2}\), which is diagonal and of Kronecker product form (27a); thus, its decomposition with ranks \(1,\ldots ,1\) is obtained by element-wise application of the square root to each core. Equality (92) results in the second of the following inequalities:
where the equivalence is uniform with respect to \(L\in {{\mathbb {N}}}\) and, for each \(L\in {{\mathbb {N}}}\), \(\beta _\ell \) with \(\ell =1,\ldots ,L\) are as defined in (65). As well as in (93), the alternate form (92) of \(\mathsf {B}_L\) is used to improve the efficiency of residual approximation in the numerical tests of Sect. 7.
Figure 1a shows the computed values of \(\max _\ell \beta _\ell ( {\Theta }_{L,{\,}\!1} )\) for different values of L and \(D=1,2\), where we observe \(\max _\ell \beta _\ell ( {\Theta }_{L,{\,}\!1} ) = {\mathscr {O}}(L)\) in both cases, corresponding to
In contrast, as shown in Fig. 1b, both \(\max _\ell \beta _\ell (\mathsf {A}_L)\) and \(\max _\ell \beta _\ell (\mathsf {C}_L \bullet \mathsf {A}_L \bullet \mathsf {C}_L)\) increase exponentially with respect to L.
Although Proposition 5 shows that they can lead to useful qualitative statements, the upper bounds provided by \(\beta _\ell \) cannot be expected to be quantitatively sharp. The direct evaluation of the suprema in the definitions (64) is in general infeasible, but testing with concrete \(\mathsf {V} \in \mathrm {TT}_L\) can provide some further insight. For \(D=1\), we use TT-SVD representations \(\mathsf {V}_1\), \(\mathsf {V}_{\mathrm {min}}\), \(\mathsf {V}_{\mathrm {max}}\) (of maximum ranks 1, 2, and 2, respectively) of the vectors
with \(x_i = 2^{-L}i\) and with constants \(c_1\), \(c_{\mathrm {min}}\), \(c_{\mathrm {max}}\) chosen so that \(\Vert \varvec{v}_1\Vert _2 = \Vert \varvec{v}_{{\mathrm {min}}}\Vert _2 = \Vert \varvec{v}_{{\mathrm {max}}}\Vert _2 = 1\). By Proposition 2(iii), \({{\,\mathrm{rcond}\,}}_\ell (\mathsf {V}_1) = 1\) and \(1\le {{\,\mathrm{rcond}\,}}_\ell (\mathsf {V}_{\mathrm {min}}) \le \sqrt{2}\), \(1\le {{\,\mathrm{rcond}\,}}_\ell (\mathsf {V}_{\mathrm {max}})\le \sqrt{2}\). Consequently, as in the examples of Sect. 4.1, for each such a choice of \(\mathsf {V}\) and any representation of a matrix \(\mathsf {M}\), the absolute and relative errors incurred by the orthogonalization of \(\mathsf {M} \bullet \mathsf {V}\) give an indication of the order of magnitude of \({{\,\mathrm{ramp}\,}}_\ell (\mathsf {M} \bullet \mathsf {V})\) and \({{\,\mathrm{rcond}\,}}_\ell (\mathsf {M} \bullet \mathsf {V})\).
The results are summarized in Tables 3 and 4. We see that in all cases, the absolute and relative errors for \(\mathsf {B}_L\) are close to machine precision \(\varepsilon \approx 2.2\times 10^{-16}\), which is quantitatively better than indicated by the upper bounds in Fig. 1. For \(\mathsf {A}_L\) and \(\mathsf {C}_L \bullet \mathsf {A}_L \bullet \mathsf {C}_L\), we observe an amplification of relative errors that is exponential in L (and in fact slightly worse for \(\mathsf {C}_L \bullet \mathsf {A}_L \bullet \mathsf {C}_L\)). The absolute errors for \(\mathsf {C}_L\) are close to \(\varepsilon \), which is important for the evaluation of preconditioned right-hand sides; the corresponding relative errors increase with L in the case of \(\mathsf {V}_{\mathrm {max}}\), which is to be expected since \(\varvec{C}_L\) damps high-frequency oscillations.

Upper bounds \(\max _{\ell =1,\ldots ,L} \beta _\ell \) as in (65) for \(\max _{\ell =1,\ldots ,L} {{\,\mathrm{mramp}\,}}_\ell \) from Proposition 4, in dependence of L: a \(\max _\ell \beta _\ell ( {\Theta }_{L,1} )\) for \(D=1\) (circles) and \(D=2\) (squares), with dashed lines representing \(10 (L+1)\) and \(120 (L-1)\), respectively; b \(\max _\ell [\beta _\ell ( {\Theta }_{L,1} )]^2\) (circles), \(\max _\ell \beta _\ell ( \mathsf {A}_L )\) (crosses), and \(\max _\ell \beta _\ell ( \mathsf {C}_L \bullet \mathsf {A}_L \bullet \mathsf {C}_L )\) (plusses), for \(D=1\), with dashed lines representing \((11 L)^2\) and \(25\times 2^{2L}\), respectively. The quantities \(\max _\ell [\beta _\ell ( {\Theta }_{L,1} )]^2\) bound \(\max _\ell [\beta _\ell ( \mathsf {B}_{L} )]\) up to a constant independent of L, see (93)
6 Complexity of Solvers
We now consider the numerical computation of \(\varvec{u}_{L}\) solving \(\varvec{B}_{L} \varvec{u}_{L} = \varvec{f}_{L}\) with \(\varvec{B}_{L} = \varvec{C}_{L} \varvec{A}_{L} \varvec{C}_{L}\) and \(\varvec{g}_L = \varvec{C}_{L} \varvec{f}_{L}\) as in (33a). Here, the objective is to find \(u_\varepsilon \in V_{L(\varepsilon )}\) such that \(\Vert u - u_\varepsilon \Vert _{\mathrm {H}^{1}_{}}\lesssim \varepsilon \), and we obtain an estimate for the computational complexity of achieving this goal. Assuming that \(L(\varepsilon ) \sim |\log \varepsilon |\) is suitably chosen a priori and that the TT singular values of \(\varvec{u}_{L}\) satisfy a natural decay estimate, we show that the number of arithmetic operations for computing a tensor train representation of \(u_\varepsilon \) is of order \({\mathscr {O}}(|\log \varepsilon |^\theta )\), where \(\theta >0\) depends only on the low-rank approximability of the \(\varvec{u}_{L}\).
Remark 7
The methods we consider rely on the accurate evaluation of residuals \(\varvec{B}_L \varvec{v} - \varvec{C}_{L} \varvec{f}_{L}\). As we have seen in Sect. 5.5, for the representations \(\mathsf {B}_L\) and \(\mathsf {C}_L\) of \(\varvec{B}_L\) and \(\varvec{C}_L\) that we have constructed, the quantities \({{\,\mathrm{mramp}\,}}_\ell (\mathsf {B}_L)\) and \({{\,\mathrm{mramp}\,}}_\ell (\mathsf {C}_L)\) grow only moderately with respect to L. Indeed, the results of Table 3 indicate that provided that \(\varvec{v}\) and \(\varvec{f}_{L}\) are given in well-conditioned representations, the corresponding residuals can be evaluated with an absolute error close to machine precision, which is corroborated also by our further numerical tests in Sect. 7. For the convergence analysis of this section, we assume exact arithmetic.
6.1 Estimates of Ranks and Computational Costs
To estimate the computational complexity of finding approximate solutions, we use the quasi-optimality properties of an iterative method using soft thresholding of hierarchical tensors introduced in [6]. This construction directly carries over to the special case of the TT format, leading to a soft thresholding operation \({\mathscr {S}}_\alpha \) that is non-expansive with respect to the \(\ell ^2\)-norm. It can be realized numerically for TT representations, described in [6, Sec. 3], at essentially the same cost as the TT-SVD.
Note that since \(\varvec{B}_{L}\) is well-conditioned uniformly with respect to L, as a consequence of Theorem 1 we can choose \(\omega >0\) such that \(\xi =\sup _{L>0}\Vert I - \omega \varvec{B}_{L}\Vert \) satisfies \(\xi < 1\). The basic iterative method applied to the present problem has the form
with \(\varvec{u}^0_L=0\) and \(\alpha _n \rightarrow 0\) determined (according to [6, Alg. 2]) as follows: set \(\alpha _0 = \omega \Vert \varvec{g}_L\Vert _2/(d-1)\), and for a fixed \({{\bar{B}}} > \Vert \varvec{B}_{L}\Vert _{2\rightarrow 2}\), take
In what follows, we refer to the algorithm given by (94), (95) as STSolve.
Recall that \(u_L = \sum _{j\in {\mathscr {J}}_L} (\varvec{C}_{L} \varvec{u}_{L})_j \varphi _{L ,{\,}\!j}\), with analogous notation for the iterates, where \(\Vert u_L\Vert _V \sim \Vert \varvec{u}_L\Vert _{2}\). Our convergence analysis is based on the following assumption on uniform decay of singular values, which is discussed further in Sect. 6.2.
Assumption 1
For all \(L\in {{\mathbb {N}}}\) and \(\ell =1,\ldots ,L\), let the singular values \(\sigma _{\ell ,j}(\varvec{u}_L)\) with \(j=1,\ldots ,2^{D {\,}\!\max (\ell ,L-\ell )}\) of the \(\ell \)th unfolding matrix \(\mathrm {U}_{\ell }(\varvec{u}_L)\), defined as in (44a), satisfy the bound
with \(C,c,\beta >0\) independent of \(\ell \) and L.
Theorem 6
Let \(\varepsilon >0\). Then, STSolve stops with \(\varvec{u}_{L,\varepsilon }\) such that
after finitely many steps. In addition, let Assumption 1 hold. Then, there exist \(c_1,c_2>0\) and \(\rho \in (0,1)\) independent of L and n such that with \(\varepsilon _n = \rho ^{n/\log L}\),
Proof
This is the statement of [6, Thm. 5.1(ii)] applied to our setting, combined with [6, Rem. 5.6] concerning the dependence of \(\varepsilon _n\) on L. \(\square \)
The above statement makes assumptions on the low-rank approximability of the approximations \(u_L\). We next relate this, by an appropriate choice of L, to the approximability of the exact solution \(u \in V\) of (4).
Corollary 1
Assume that there exist \(C_1>0\) and \(s >0\) such that \( \Vert u - u_L\Vert _{\mathrm {H}^{1}_{}} \le C_1 2^{-s L} \). Then, for given \(\varepsilon \in (0,1)\), taking \(L= \frac{1}{s} ( 1 + |\log \varepsilon |)\), with \(c_1,c_2>0\) and \(\varepsilon _n = \rho ^{n/\log L}\) as in Theorem 6, for \(n>0\) we have
and for \(N= (|\log \varepsilon | + \log L) \log L \lesssim (1 + |\log \varepsilon |) \log ( 1 + |\log \varepsilon |)\), we obtain
where \(C_2,C_3>0\) depend on \(c_1\), \(c_2\), \(\rho \), \(C_1\), and s.
Remark 8
(Complexity bounds) If \(\varvec{B}_{L}\) has fixed representation ranks, as in the case of the Laplacian, the costs of each step are dominated by those of applying \({\mathscr {S}}_{\alpha _n}\), which are of order \({\mathscr {O}}(L (\max _\ell {{\,\mathrm{rank}\,}}_\ell (\varvec{u}^n_L))^3)\). By Corollary 1, the total number of operations for N steps to guarantee an \(H^1\)-error of order \(\varepsilon \) is thus bounded by
with a uniform constant \(C>0\).
In cases with variable coefficients such that \(\varvec{B}_{L}\) does not have an exact low-rank form, but needs to be applied approximately, the iteration given in (94) and (95) can be adapted to residual approximations with prescribed tolerance as given in [6, Alg. 3], which preserves the statement of Theorem 6 as shown in [6, Prop. 5.9]. Depending on the L- and \(\varepsilon \)-dependent rank bounds for \(\varvec{B}_{L}\), one may then obtain additional factors in estimate (97).
Remark 9
Complexity estimates are also given in [4] for a similar iterative method based on hierarchical SVD truncation (which in the present setting translates to a direct TT-SVD truncation). A simplified version of this method operating on fixed discretizations is given in [6, Alg. 4]. Based on the theory for this method, one can also derive rank and complexity bounds similar to (97), but with a less favorable exponent: for this method, one arrives at a number of operations bounded by \( C (1 + |\log \varepsilon |)^{t + \frac{3}{\beta }} \) for some \(C>0\), where \(t>0\) now depends on the representation ranks and condition number of \(\varvec{B}_L\), and the bound can be substantially worse than (97). The practical performance of the scheme from [4], however, tends to be comparable to the one of STSolve considered above.
Remark 10
Alternatively, the linear systems \(\varvec{B}_L \varvec{u}_L = \varvec{g}_L\) can be solved by the AMEn methods introduced in [17]. The basic version analyzed in [17, Sec. 5] relies on residual approximations of a certain quality and increases approximation ranks in each iteration. However, the available convergence results only lead to a complexity bound that increases faster than exponentially in L. In the practical implementation that we also consider for comparison in Sect. 7, the basic method is combined with a faster heuristic residual approximation scheme based on the alternating least squares (ALS) method and with additional rank reduction steps. Although no convergence analysis is available for this version, the method performs well in our tests with well-conditioned \(\varvec{B}_L\).
6.2 Low-Rank Approximability Assumptions
For the case of one or two dimensions, a low-rank approximation analysis for the solution of problem (4) under certain analyticity assumptions on the coefficients and right-hand side, following from the regularity analysis developed in [2, 3], is available in [28, 33, 34]. The following result can be obtained as an immediate consequence of [34, Theorem 5.16].
Theorem 7
Consider problem (4) with \(D=2\) dimensions under the ellipticity and regularity assumptions made in Sect. 2. Assume additionally that the data (the diffusion coefficient and the right-hand side) are analytic on \({\overline{\varOmega }}\). Then, the following holds with positive constants \(C,C',b,b'\). For all \(L,R\in {{\mathbb {N}}}\), the exact solution u admits an approximation \(u_{L,R}\in V_L\) that can be exactly represented in the multilevel TT decomposition in the sense of (50a)–(50b), with ranks not exceeding R and such that

Theorem 7 and analogous results for highly oscillatory solutions [31] cover the tensor approximation of exact solutions in the nodal basis, described in Sect. 2.2. The requirements of Assumption 1 are somewhat different: they refer to the solution of the Galerkin discretization (uniformly in the discretization level L), and the application of \(\varvec{C}_{L}^{-1}\) to the corresponding coefficient \({\bar{\varvec{u}}}_L\) (which is with respect to the nodal basis) yields the coefficient \(\varvec{u}_L = \varvec{C}_{L}^{-1} {\bar{\varvec{u}}}_L\) with respect to the preconditioned basis. Nevertheless, the \(\mathrm {H}^{1}_{}\)-errors bounded implicitly by the decay of singular values in Assumption 1 and explicitly by the second term in the right-hand side of (98) both correspond to low-rank tensor approximation within the underlying finite element space \(V_L\).
The verification of the low-rank approximability of \(\varvec{u}_L\), \(L\in {{\mathbb {N}}}\), stipulated in Assumption 1 requires the result of Theorem 7 to be complemented by two further ingredients: bounds on the ranks of Galerkin discretizations (as opposed to interpolants of the exact solution); and suitable low-rank approximations of \(\varvec{C}_{L}^{-1}\), (which, unlike \(\varvec{C}_L\), does not have an explicit low-rank form).
In the present work, we restrict ourselves to studying the resulting approximability of \(\varvec{u}_L\) numerically. We are not aware of existing analysis that would allow to arrive at conclusions on Galerkin solution ranks, covering also the convergence behavior for accuracies below the size of the Galerkin discretization error; this appears to be a question of independent interest. In certain special cases, such as Poisson problems in \(D=1\), the Galerkin solution can in fact be shown to be the nodal interpolant of the exact solution. For more general problems and for \(D>1\), however, this is in general not the case.
The numerically observed decay of matricization singular values of the preconditioned solution coefficients \(\varvec{u}_L\) (with \(\Vert \varvec{u}_L\Vert _2 \sim \Vert u_L\Vert _{\mathrm {H}^{1}_{}}\)) and of the vector of scaled nodal values \({\bar{\varvec{u}}}_L = \varvec{C}_L \varvec{u}_L\) (with \(\Vert {\bar{\varvec{u}}}_L\Vert _2 \sim \Vert u_L\Vert _{\mathrm {L}^{2}_{}}\)) for a Poisson problem in spatial dimension \(D=2\) is illustrated in Fig. 2. We find that the action of \(\varvec{C}_L^{-1}\) on the vector of nodal values preserves the exponential decay of singular values, but at a slightly modified rate. This is consistent with the further numerical tests for this problem in Sect. 7.4. Similar results are also observed in further experiments presented in Sect. 7.

7 Numerical Experiments
In our numerical tests, we apply the preconditioned discretization matrices in well-conditioned tensor representations obtained in Sect. 5 to different problems of type (4), both with constant and with highly oscillatory diffusion coefficients A in (5).
For solving the resulting systems of equations, on the one hand we use STSolve analyzed in Sect. 6, implemented in the Julia programming language; on the other hand, we compare to results obtained using a Fortran implementation of the AMEn solver [17] wrapped by the Python version of the TT Toolbox by I. Oseledets.
These two solvers have quite distinct characteristics. The parameters for STSolve are chosen such that the convergence and complexity estimates of Theorem 6 are guaranteed, which leads to a very conservative control of the iteration. Since residuals are approximated with guaranteed accuracy, this method yields rigorous error bounds. In contrast, the considered version of AMEn uses several heuristic extensions, as described in [17, Sec. 6]. In particular, it uses a simplified ALS-type residual approximation that has strongly reduced complexity, but does not give any error guarantees.
Moreover, in the given results, iteration numbers for AMEn need to be interpreted differently, where each iteration in the convergence plots comprises several substeps with local residual evaluations for each core.
7.1 Results Without Preconditioning
We first illustrate the results obtained by a direct application of multilevel tensor representations of stiffness matrices \(\varvec{A}_L\) without preconditioning. Such representations have been derived, for instance, in [35]. In the present case of mixed Dirichlet and Neumann boundary conditions, this leads to representations similar to the pure Dirichlet case in (54). Here, we consider the case \(D=1\), where for simplicity we take reaction coefficient \(c = 0\) and right-hand side \(f=1\), that is, we solve the weak formulation of
Using AMEn directly with system matrix \(\varvec{A}_L\) and right-hand side \(\varvec{f}_L\), we observe that the resulting residual indicators stagnate at values above \(2^{2L} \varepsilon \), where \(\varepsilon \approx 2.2 \times 10^{-16}\) is the relative machine precision. This is to be expected in view of the matrix and representation ill-conditioning of \(\varvec{A}_L\).
If we instead implement the preconditioned matrix \(\varvec{C}_L\varvec{A}_L \varvec{C}_L\) by pre- and post-multiplying with a separate tensor representation \(\varvec{C}_L\) of the preconditioner, we still obtain essentially the same type of stagnation at approximately \(2^{2L} \varepsilon \). Since the represented matrix \(\varvec{C}_L\varvec{A}_L \varvec{C}_L\) is now well-conditioned, these remaining catastrophic round-off errors and the resulting stagnation are entirely due to representation ill-conditioning, which is not removed by simply multiplying by the preconditioner. This effect is observed both with AMEn and with STSolve. The results are shown in Fig. 3, with the residual values with respect to the system matrices \(\varvec{A}_L\) and \(\varvec{C}_L\varvec{A}_L \varvec{C}_L\), respectively.

Results for Sect. 7.1, computed residual bounds in dependence on iteration count: a AMEn applied directly to \(\varvec{A}_L\), b AMEn with directly multiplied \(\varvec{C}_L\varvec{A}_L \varvec{C}_L\), (c) STSolve with directly multiplied \(\varvec{C}_L\varvec{A}_L \varvec{C}_L\); each for \(L=10,15,20,25,30\) (by increasing line thickness)
7.2 Constant Coefficient Diffusion, \(D=1\)
We now consider the same basic test case (99), but with \(\varvec{B}_L =\varvec{C}_L\varvec{A}_L \varvec{C}_L\) in the combined tensor representation constructed in Sect. 5. In this and the following tests, residual values always refer to the preconditioned residuals \(\Vert \varvec{B}_L \cdot - \varvec{g}_L \Vert _2\), which is proportional to the \(\mathrm {H}^{1}_{}\)-errors in the corresponding grid functions. With a target residual of \(10^{-12}\), both AMEn and STSolve converge unaffected by any round-off errors for very large values of L (Fig. 4). Indeed, this remains true for values L that are substantially larger than in the case \(L=50\) shown here, but since the corresponding mesh widths are then smaller than machine precision, the results are more difficult to interpret.
For the AMEn solver, we assemble the complete representation of \(\varvec{B}_L\). In exact arithmetic, this would in fact be equivalent to applying representations \(\mathsf {A}_L\) and \(\mathsf {C}_L\) separately, and differences are entirely due to the different tensor decomposition in the previous case. With STSolve, we have the additional option of using error-controlled inexact residual evaluations as in [6, Alg. 3] to reduce the arising ranks of intermediate results; as shown in [6, Prop. 5.9], the statement of Theorem 6 still applies to this modification. To this end, we use that the tensor representation can be directly rewritten in the form \(\varvec{B}_L = \varvec{\varTheta }_{L,{\,}\!1}^{\mathsf {T}}\!\, \varvec{\varTheta }_{L,{\,}\!1}\) as in (92), where \(\Vert \varvec{\varTheta }_{L,{\,}\!1}\Vert \) is uniformly bounded with respect to L, and apply an additional recompression by TT-SVD after applying \(\varvec{\varTheta }_{L,{\,}\!1}\).

Results for Sect. 7.2: residual bounds (black) and maximum approximation ranks (gray), with well-conditioned combined representation of \(\varvec{B}_L = \varvec{C}_L\varvec{A}_L \varvec{C}_L\) for \(L=10,15,20,25,30,35,40,45,50\) (by increasing line thickness)
7.3 Highly Oscillatory Diffusion Coefficients, \(D=1\)
We next consider the family of problems with oscillatory diffusion coefficients on \(\varOmega =(0,1)\) given by
for large values of K. The exact solution reads
For \(K\in 4{{\mathbb {N}}}\), we represent the vectors \(\varvec{u}_{\mathrm {ex}}\) and \(\varvec{v}_{\mathrm {ex}}\) of nodal values of u and \(u'\) in the multiscale TT format with ranks bounded by seven and six, respectively.
The coefficient \(a_K\) does not have an explicit low-rank form, and we compute approximations as follows: using the explicit rank-three representation of \(c(x) = 2 + \cos (K\pi x)\), using STSolve we solve the equation \(c(x_i) \,a_K(x_i) = 1\) in the points \(x_i = 2^{-L}(i-\frac{1}{2})\), \(i=1,\ldots ,2^L\), as an elliptic problem on \(\ell ^2(\{1,\ldots ,2^L\})\) for \(a_K\); the tolerance is chosen to ensure a sufficient uniform error bound.
We compare the results for the values \(K=2^{10}, 2^{20}, 2^{30}, 2^{40}\) with \(L = 50\) in Fig. 5. The observed convergence patterns of both methods show hardly any influence of the value of K. Note that the computed preconditioned coefficients \(\varvec{u}_L\) do not satisfy the same rank bound as (101) (which holds for \(\varvec{C}_L \varvec{u}_L\), the corresponding vector of scaled nodal values). In each case, comparison with the explicit low-rank form of \(\varvec{u}_{\mathrm {ex}}\), \(\varvec{v}_{\mathrm {ex}}\) shows that the expected total error bounds are achieved.
More specifically, approximations of the \(\mathrm {H}^{1}_{}\)-error in the solutions can be obtained in a numerically stable way by evaluating \(\Vert \varvec{u}_{\mathrm {ex}} - \varvec{C}_L \varvec{u}_L\Vert _2\) and \(\Vert \varvec{v}_{\mathrm {ex}} -\varvec{\varTheta }_{L,{\,}\!1} \varvec{u}_L\Vert _2\), where \(\varvec{\varTheta }_{L,{\,}\!1}\) is the factor of the preconditioned Laplacian stiffness matrix as in Sect. 7.2. In Table 5, we summarize the obtained approximations of \(\mathrm {H}^{1}_{}\)-errors for different solver tolerances and parameters L. We observe an effect that is particular to the present one-dimensional setting, where the accuracy in the nodal values is limited only by the solver tolerance as soon as L is sufficiently large for resolving the oscillations in the solution.

Results for Sect. 7.3: residual bounds (black) and maximum approximation ranks (gray), with well-conditioned representation of \(\varvec{B}_L\) for oscillatory coefficient \(a_K\) with \(K= 2^{10},2^{20},2^{30},2^{40}\) (by increasing line thickness) and \(L=50\)
7.4 Constant Coefficient Diffusion, \(D=2\)
On \(\varOmega = (0,1)^2\), we consider (4) with \(A=1\), \(c=0\) and \(f=1\), that is, the weak form of
with \(\varGamma \) as in (3). Both STSolve and AMEn show the expected convergence for \(L=50\) (Fig. 6), with ranks that are consistent with the singular value decay of discretized solutions of Fig. 2b.
Similarly to Sect. 7.2, STSolve is used with inexact residual evaluation, now using that the tensor representation of \(\varvec{B}_L\) can be written in the form \(\varvec{B}_L = \varvec{\varTheta }_{L,{\,}\!1}^{\mathsf {T}}\!\; \varvec{\varTheta }_{L,{\,}\!1} + \varvec{\varTheta }_{L,{\,}\!2}^{\mathsf {T}}\!\; \varvec{\varTheta }_{L,{\,}\!2}\) as in (92). Here, \(\varvec{\varTheta }_{L,{\,}\!1}\) and \(\varvec{\varTheta }_{L,{\,}\!2}\) are uniformly bounded, and each has maximum representation rank 24. Although these ranks remain independent of L, additional rank reductions in this decomposition are important from a quantitative point of view: since \(\varvec{B}_L\) has maximum representation rank 1152, applying it directly would lead to very large ranks. In the available version of AMEn, the decomposition of \(\varvec{B}_L\) needs to be used directly, but the impact of large residual ranks is limited due to the ALS-type residual approximation. In this case, the main downside of the direct assembly of \(\varvec{B}_L\) is in the higher memory requirements for large L.

Results for Sect. 7.4: residual bounds (black) and maximum approximation ranks (gray), for well-conditioned representation of \(\varvec{B}_L\), \(L=50\)
In terms of computational costs, the error-controlled full residual approximation used by STSolve is substantially more expensive in all considered tests than the heuristic ALS-based residual approximation used by AMEn. The precise CPU timings are of limited significance due to the different implementations, but we observe running times on the order of several minutes with STSolve and of seconds with AMEn in the tests with \(D=1\), and of several hours with STSolve and several minutes with AMEn in the case of \(D=2\). Although no convergence analysis is available for this AMEn implementation, especially for the present well-conditioned representations it is thus an interesting practical choice.
8 Conclusion and Outlook
We have identified notions of condition numbers of tensor representations that determine the propagation of errors in numerical algorithms. In the application to multilevel tensor-structured discretizations of second-order elliptic PDEs, the careful construction of tensor representations of preconditioned system matrices guided by these notions leads to solvers that remain numerically stable also for very large discretization levels. For one such method based on soft thresholding of tensors, we have shown that the total number of arithmetic operations scales like a fixed power of the logarithm of the prescribed bound on the total solution error.
The new variant of BPX preconditioning that we have analyzed leads to a very natural low-rank structure of the symmetrically preconditioned stiffness matrix. Remarkably, unlike the rank increase with discretization levels observed in the case of separation of spatial coordinates [5], in the present case of tensor separation of scales, we obtain preconditioner representation ranks that remain uniformly bounded with respect to the discretization level. Similar results can be obtained for related preconditioners based on wavelet transforms, which are the subject of ongoing work.
For the preconditioned solvers, the relevant approximability properties of solutions we have identified are slightly different from the ones for nodal basis coefficients studied, e.g., in [34]. The numerically observed favorable decay of TT singular values of preconditioned quantities thus requires further investigation; it also depends on the particular choice of preconditioner.
The practical application to more general problems was not considered here to avoid further technicalities, but one can similarly treat different boundary conditions, more general coefficients (such as highly oscillatory diffusion coefficients in \(D>1\)) or more general domains by techniques developed in [28]. We also expect that our basic considerations concerning the combined low-rank representations of preconditioners and discretization matrices of differential operators can be applied, with potentially more technical effort, to other types of basis expansions and to different classes of PDE problems.
Although the representation ranks of preconditioned matrices that we obtain are bounded independently of the discretization level, they are fairly large for \(D>1\). This suggests the further investigation of solvers with improved quantitative performance, in particular the combination of AMEn-type methods with efficient residual approximation strategies for preconditioned operator representations.
We expect that the framework we have proposed here for studying the conditioning of tensor representations can be developed further to provide more detailed information, as well as sharper computable bounds for representations of matrices.
References
Andreev, R., Tobler, C.: Multilevel preconditioning and low-rank tensor iteration for space–time simultaneous discretizations of parabolic PDEs. Numerical Linear Algebra with Applications 22(2), 317–337 (2015)
Babuška, I., Guo, B.: The \(h\)-\(p\) version of the finite element method for domains with curved boundaries. SIAM Journal on Numerical Analysis 25(4), 837–861 (1988)
Babuška, I., Guo, B.: Regularity of the solution of elliptic problems with piecewise analytic data. Part I. boundary value problems for linear elliptic equation of second order. SIAM Journal on Mathematical Analysis 19(1), 172–203 (1988)
Bachmayr, M., Dahmen, W.: Adaptive near-optimal rank tensor approximation for high-dimensional operator equations. Found. Comput. Math. 15(4), 839–898 (2015)
Bachmayr, M., Dahmen, W.: Adaptive low-rank methods: problems on Sobolev spaces. SIAM J. Numer. Anal. 54(2), 744–796 (2016)
Bachmayr, M., Schneider, R.: Iterative methods based on soft thresholding of hierarchical tensors. Found. Comput. Math. 17, 1037–1083 (2017)
Bachmayr, M., Schneider, R., Uschmajew, A.: Tensor networks and hierarchical tensors for the solution of high-dimensional partial differential equations. Found. Comput. Math. 16(6), 1423–1472 (2016)
Ballani, J., Grasedyck, L.: A projection method to solve linear systems in tensor format. Numerical Linear Algebra with Applications 20(1), 27–43 (2013)
Bornemann, F., Yserentant, H.: A basic norm equivalence for the theory of multilevel methods. Numer. Math. 64(4), 455–476 (1993)
Bramble, J.H., Pasciak, J.E., Xu, J.: Parallel multilevel preconditioners. Math. Comp. 55(191), 1–22 (1990)
Chertkov, A.V., Oseledets, I.V., Rakhuba, M.V.: Robust discretization in quantized tensor train format for elliptic problems in two dimensions. arXiv:1612.01166 (2016)
Dahmen, W., Kunoth, A.: Multilevel preconditioning. Numer. Math. 63(3), 315–344 (1992)
De Launey, W., Seberry, J.: The strong Kronecker product. Journal of Combinatorial Theory, Series A 66(2), 192–213 (1994)
de Silva, V., Lim, L.H.: Tensor rank and the ill-posedness of the best low-rank approximation problem. SIAM Journal on Matrix Analysis and Applications 30(3), 1084–1127 (2008)
Dolgov, S.V., Kazeev, V.A., Khoromskij, B.N.: Direct tensor-product solution of one-dimensional elliptic equations with parameter-dependent coefficients. Mathematics and Computers in Simulation 145(Supplement C), 136–155 (2018)
Dolgov, S.V., Khoromskij, B.N., Oseledets, I.V., Tyrtyshnikov, E.E.: Tensor structured iterative solution of elliptic problems with jumping coefficients. Preprint 55, Max Planck Institute for Mathematics in the Sciences (2010)
Dolgov, S.V., Savostyanov, D.V.: Alternating minimal energy methods for linear systems in higher dimensions. SIAM J. Sci. Comput. 36(5), A2248–A2271 (2014)
Grasedyck, L.: Hierarchical singular value decomposition of tensors. SIAM Journal on Matrix Analysis and Applications 31(4), 2029–2054 (2010)
Grasedyck, L.: Polynomial approximation in hierarchical Tucker format by vector-tensorization. Preprint 308, Institut für Geometrie und Praktische Mathematik, RWTH Aachen (2010)
Grasedyck, L., Kressner, D., Tobler, C.: A literature survey of low-rank tensor approximation techniques. GAMM-Mitteilungen 36(1), 53–78 (2013)
Hackbusch, W.: Tensorisation of vectors and their efficient convolution. Numerische Mathematik 119(3), 465 (2011)
Hackbusch, W.: Tensor Spaces and Numerical Tensor Calculus, Springer Series in Computational Mathematics, vol. 42. Springer (2012)
Hackbusch, W.: Solution of linear systems in high spatial dimensions. Computing and Visualization in Science 17(3), 111–118 (2015)
Hackbusch, W.: Elliptic Differential Equations: Theory and Numerical Treatment, Springer Series in Computational Mathematics, vol. 18, second edn. Springer (2017)
Hackbusch, W., Kühn, S.: A new scheme for the tensor representation. J. Fourier Anal. Appl. 15(5), 706–722 (2009)
Harbrecht, H., Schneider, R., Schwab, C.: Multilevel frames for sparse tensor product spaces. Numer. Math. 110(2), 199–220 (2008)
Higham, N.J.: Accuracy and stability of numerical algorithms, second edn. Society for Industrial and Applied Mathematics (SIAM), Philadelphia, PA (2002)
Kazeev, V.: Quantized tensor-structured finite elements for second-order elliptic PDEs in two dimensions. Ph.D. thesis, ETH Zürich (2015). https://doi.org/10.3929/ethz-a-010554062
Kazeev, V., Khammash, M., Nip, M., Schwab, C.: Direct solution of the chemical master equation using quantized tensor trains. PLOS Computational Biology 10(3), 742–758 (2014)
Kazeev, V., Khoromskij, B., Tyrtyshnikov, E.: Multilevel Toeplitz matrices generated by tensor-structured vectors and convolution with logarithmic complexity. SIAM Journal on Scientific Computing 35(3), A1511–A1536 (2013)
Kazeev, V., Oseledets, I., Rakhuba, M., Schwab, C.: QTT-finite-element approximation for multiscale problems I: model problems in one dimension. Adv. Comput. Math. 43(2), 411–442 (2017)
Kazeev, V., Reichmann, O., Schwab, C.: Low-rank tensor structure of linear diffusion operators in the TT and QTT formats. Linear Algebra and its Applications 438(11), 4204–4221 (2013)
Kazeev, V., Schwab, C.: Approximation of singularities by quantized-tensor FEM. Proceedings in Applied Mathematics and Mechanics 15(1), 743–746 (2015)
Kazeev, V., Schwab, C.: Quantized tensor-structured finite elements for second-order elliptic PDEs in two dimensions. Numerische Mathematik 138, 133–190 (2018)
Kazeev, V.A., Khoromskij, B.N.: Low-rank explicit QTT representation of the Laplace operator and its inverse. SIAM Journal on Matrix Analysis and Applications 33(3), 742–758 (2012)
Khoromskaia, V., Khoromskij, B.N.: Grid-based lattice summation of electrostatic potentials by assembled rank-structured tensor approximation. Comp. Phys. Communications 185(12), 3162–3174 (2014)
Khoromskij, B.N.: \({\mathscr {O}}(d \log n)\)-quantics approximation of \(n\)-\(d\) tensors in high-dimensional numerical modeling. Constructive Approximation 34(2), 257–280 (2011)
Khoromskij, B.N.: Tensor Numerical Methods in Scientific Computing. De Gruyter Verlag (2018)
Khoromskij, B.N., Oseledets, I.V.: QTT approximation of elliptic solution operators in higher dimensions. Russ. J. Numer. Anal. Math. Modelling 26(3), 303–322 (2011)
Kolda, T.G., Bader, B.W.: Tensor decompositions and applications. SIAM Review 51(3), 455–500 (2009)
Kressner, D., Tobler, C.: Algorithm 941: Htucker—a matlab toolbox for tensors in hierarchical Tucker format. ACM Transactions on Mathematical Software 40(3), 22:1–22:22 (2014)
Orús, R.: A practical introduction to tensor networks: Matrix product states and projected entangled pair states. Annals of Physics 349(Supplement C), 117–158 (2014)
Oseledets, I.: Approximation of matrices with logarithmic number of parameters. Doklady Mathematics 80(2), 653–654 (2009)
Oseledets, I.V.: Approximation of \(2^{d} \times 2^{d}\) matrices using tensor decomposition. SIAM Journal on Matrix Analysis and Applications 31(4), 2130–2145 (2010)
Oseledets, I.V.: Tensor Train decomposition. SIAM Journal on Scientific Computing 33(5), 2295–2317 (2011)
Oseledets, I.V., Rakhuba, M.V., Chertkov, A.V.: Black-box solver for multiscale modelling using the QTT format. In: Proc. ECCOMAS. Crete Island, Greece (2016)
Oseledets, I.V., Tyrtyshnikov, E.E.: Breaking the curse of dimensionality, or how to use SVD in many dimensions. SIAM Journal on Scientific Computing 31(5), 3744–3759 (2009)
Oswald, P.: On discrete norm estimates related to multilevel preconditioners in the finite element method. In: Constructive Theory of Functions, Proc. Int. Conf. Varna, 1991, pp. 203–214. Bulg. Acad. Sci., Sofia (1992)
Schollwöck, U.: The density-matrix renormalization group in the age of matrix product states. Annals of Physics 326(1), 96–192 (2011). January 2011 Special Issue
Uschmajew, A., Vandereycken, B.: The geometry of algorithms using hierarchical tensors. Linear Algebra and its Applications 439(1), 133–166 (2013)
Vassilevski, P.S., Wang, J.: Stabilizing the hierarchical basis by approximate wavelets. I. Theory. Numer. Linear Algebra Appl. 4(2), 103–126 (1997)
Yserentant, H.: On the multilevel splitting of finite element spaces. Numer. Math. 49(4), 379–412 (1986)
Yserentant, H.: Two preconditioners based on the multi-level splitting of finite element spaces. Numer. Math. 58(2), 163–184 (1990)
Zhang, X.: Multilevel Schwarz methods. Numer. Math. 63(4), 521–539 (1992)
Acknowledgements
Open Access funding provided by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Endre Süli.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
M.B. acknowledges support by the Hausdorff Center of Mathematics, University of Bonn. M.B. was partially supported by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) - Projektnummer 211504053 - SFB 1060.
Appendices
Preconditioner Optimality
In preparation of the proof of Theorem 2, we define the square matrix \(\varvec{D}_L\) of order \(2^{DL}\) by

Since the bilinear form a is elliptic on V with  , we obtain
, we obtain
and it thus suffices to show (31) for \(\varvec{D}_L\) in place of \(\varvec{A}_L\).
For \(\ell =0,\ldots ,L\), we introduce the nested subspaces \( {\mathscr {V}}_\ell = {{\,\mathrm{ran}\,}}\varvec{P}_{\ell ,L} \subseteq {{\mathbb {R}}}^{{\mathscr {J}}_L} \); that is, the spaces \({\mathscr {V}}_\ell \) are spanned by vectors of finest-grid nodal values of the functions \(\varphi _{\ell ,{\,}\!j}\), \(j\in {\mathscr {J}}_\ell \). In particular, \({\mathscr {V}}_L = {{\mathbb {R}}}^{{\mathscr {J}}_L}\).
Lemma 6
For \(\ell , \ell ' \in \{0,\ldots ,L\}\), let
Then, for \(0\le k\le \ell \), \(0\le k'\le \ell '\),

for all \(\varvec{w}_k \in {\mathscr {V}}_k\) and \(\varvec{w}_{k'} \in {\mathscr {V}}_{k'}\).
Proof
The matrices defined in 104 can also be expressed in terms of
as
The matrices \(\hat{\varvec{L}}_{\ell , \ell '}\) for \(\ell > \ell '\) can be written in terms of \(\hat{\varvec{L}}_{\ell ',\ell '}\) as follows: since \({\hat{\varphi }}_{\ell ,{\,}\!j}'\) for \(j\in {\hat{{\mathscr {J}}}}_\ell \) with \(j < 2^\ell \) are \(\mathrm {L}^{2}_{}\)-orthogonal to constants, the inner products of these functions with \({\hat{\varphi }}_{\ell ' ,{\,}\!j'}'\), \(j'\in {\hat{{\mathscr {J}}}}_{\ell '}\), can be nonzero only when \(j = 2^{\ell - \ell '} j'\). For \(\ell \ge \ell '\), we thus define \(\hat{\varvec{\varXi }} \in {{\mathbb {R}}}^{ {\hat{{\mathscr {J}}}}_\ell \times {\hat{{\mathscr {J}}}}_{\ell '} }\) by

Additionally taking into account the difference in \(\mathrm {L}^{2}_{}\)-normalization factors between levels \(\ell \) and \(\ell '\), we obtain
Let \({{\hat{{\mathscr {V}}}}}_{k,\ell } = {{\,\mathrm{ran}\,}}\hat{\varvec{P}}_{k,\ell } \subseteq {{\mathbb {R}}}^{{\hat{{\mathscr {J}}}}_\ell }\) and \({\hat{{\mathscr {V}}}}_k = {{\,\mathrm{ran}\,}}\hat{\varvec{ P}}_{k,L}\). For \(k\le \ell \) and \(\varvec{w}\in {{\hat{{\mathscr {V}}}}}_{k,\ell }\), let \(w \in V_k\) be the function represented by \(\varvec{w}\). Then, by (106) and the standard inverse estimate for \(V_k\) (see, e.g., [24, Sec. 8.8.3]), we have \(\langle \hat{\varvec{L}}_{\ell ,\ell } \varvec{w}, \varvec{w}\rangle = 2^{-2\ell } |w|_{\mathrm {H}^{1}_{0}}^2 \lesssim 2^{2(k-\ell )} \Vert w\Vert _{\mathrm {L}^{2}_{}}^2\), and thus
in particular, we also have \(\Vert \hat{\varvec{L}}_{\ell ,\ell }\Vert _{2\rightarrow 2} \lesssim 1\). Moreover, one has
To see this, denote again by \(w \in V_k\) the function represented by \(\varvec{w}\), and consider first \(\ell ' \le k \le \ell \). Then, \({\tilde{\varvec{w}}} := \hat{\varvec{\varXi }}_{\ell ,\ell '}^{\mathsf {T}}\!\, \varvec{w}\) corresponds to evaluations of w on the grid of level \(\ell '\), which is coarser than the one on which it is piecewise linear, and consequently \(2^{\ell - k} \sum _{j' \in {\hat{{\mathscr {J}}}}_{\ell '}} |{\tilde{\varvec{w}}}_{j'}|^2 \lesssim \sum _{j \in {\hat{{\mathscr {J}}}}_{\ell } } |\varvec{w}_j|^2\). Thus, \(\Vert {\tilde{\varvec{w}}}\Vert _2 =\Vert \hat{\varvec{\varXi }}_{\ell ,\ell '}^{\mathsf {T}}\!\, \varvec{w}\Vert _2 \lesssim 2^{\frac{1}{2}(k-\ell )} \Vert \varvec{w}\Vert _2\), and (109) follows in this case. If \(k < \ell ' \le \ell \), \({\tilde{\varvec{w}}} \in {{\hat{{\mathscr {V}}}}}_{k,\ell '}\) corresponds to a reinterpolation of w that is still on a finer level than k, and thus \(\Vert {\tilde{\varvec{w}}}\Vert _2 \le 2^{\frac{1}{2}(\ell '-\ell )} \Vert \varvec{w}\Vert _2\). Using (108), we thus obtain \(\langle \hat{\varvec{L}}_{\ell ',\ell '} {\tilde{\varvec{w}}},{\tilde{\varvec{w}}} \rangle \lesssim 2^{2(k-\ell ')} \Vert {\tilde{\varvec{w}}}\Vert _2^2 \lesssim 2^{2k - 2\ell ' + \ell ' - \ell } \Vert \varvec{w}\Vert _2^2\), which gives (109).
We next show that
Let \(s_{j\,i} := (\hat{\varvec{P}}_{\ell ,L}^{\mathsf {T}}\!\hat{\varvec{P}}_{k,L})_{j\,i}\), \(v_{j\,i} := (\hat{\varvec{P}}_{k,\ell })_{j\,i}\), \(j \in {\hat{{\mathscr {J}}}}_{\ell }\), \(i \in {\hat{{\mathscr {J}}}}_{k}\). Recalling (10), and taking into account that \({{\,\mathrm{supp}\,}}{\hat{\varphi }}_{\ell ,{\,}\!j} = [2^{-\ell } (j-1), 2^{-\ell } (j+1)]\cap [0,1]\),
Whenever \({\hat{\varphi }}_{k ,{\,}\!i}\) is linear on \({{\,\mathrm{supp}\,}}{\hat{\varphi }}_{\ell ,{\,}\!j}\), one has \(s_{j\,i}=v_{j\,i}\) by the symmetries in the summation in \(s_{j\,i}\). This fails to hold only when \(j = 2^{\ell - k} i\). In these cases, one easily verifies that \(| s_{j\,i} - v_{j\,i} | \lesssim 2^{\frac{3}{2} (k-\ell )}\) when \(j < 2^\ell \) and \(| s_{j\,i} - v_{j\,i} | \lesssim 2^{\frac{1}{2} (k-\ell )}\) for \(i=2^k\), \(j = 2^\ell \), with L-independent constants. Using interpolation to bound \(\Vert \hat{\varvec{P}}_{\ell ,L}^{\mathsf {T}}\!\hat{\varvec{P}}_{k,L} - \hat{\varvec{P}}_{k,\ell } \Vert _{2\rightarrow 2}\) by the corresponding row- and column-sum norms, where the number of nonzero entries in each row and column is uniformly bounded, we obtain (110).
Note that for any \(\varvec{w}\in {{\hat{{\mathscr {V}}}}}_{k}\) there exists a unique \(\varvec{z}\in {{\mathbb {R}}}^{{\hat{{\mathscr {J}}}}_{k}}\) such that \(\varvec{w}= \hat{\varvec{P}}_{k,L} \varvec{z}\), where \(\Vert \varvec{w}\Vert _2 \sim \Vert \varvec{z}\Vert _2\) with constants independent of k, L. As a consequence, using this with (110), we obtain \( \Vert \hat{\varvec{P}}_{\ell ,L}^{\mathsf {T}}\!\varvec{w}- \hat{\varvec{P}}_{k,\ell } \varvec{z} \Vert _2 \lesssim 2^{\frac{1}{2} (k - \ell )} \Vert \varvec{w}\Vert _2 \) for such \(\varvec{w}\) and \(\varvec{z}\). Since
using (108) for \(\hat{\varvec{P}}_{k,\ell } \varvec{z} \in {{\hat{{\mathscr {V}}}}}_{k,\ell }\), \(\Vert \hat{\varvec{L}}_{\ell ,\ell } \Vert _{2\rightarrow 2}\lesssim 1\), and the Cauchy–Schwarz inequality for the middle term on the right, we obtain
and similarly, using (109) in the same manner,
for any \(\varvec{w}\in {{\hat{{\mathscr {V}}}}}_k\), \(k\le \ell \).
Consequently, with \(0\le k\le \ell \), \(0\le k'\le \ell '\), \(\ell \le \ell '\), for all \(\varvec{w}_k \in {\hat{{\mathscr {V}}}}_k\) and \(\varvec{w}_{k'} \in {\hat{{\mathscr {V}}}}_{k'}\),

By (107), since \(\Vert \hat{\varvec{E}}_{\ell ,\ell '}\Vert _{2\rightarrow 2} \le 1\), this implies (105). \(\square \)
Proof (Theorem 2)
Theorem 1 implies in particular that \(\langle \varvec{C}_{2,L} \varvec{v},\varvec{v}\rangle \sim \langle \varvec{D}_L^{-1} \varvec{v},\varvec{v}\rangle \) for all \(\varvec{v}\), that is,
We use this in the following proof of the lower bound in (31), which is inspired by arguments using frame theory from [26]. Let  . We consider the mappings \(\varvec{F}:{\mathscr {V}}_L \rightarrow {{\bar{{\mathscr {V}}}}}_L\) and \(\varvec{F}^{\mathsf {T}}\!:{{\bar{{\mathscr {V}}}}}_L \rightarrow {\mathscr {V}}_L\) given by
. We consider the mappings \(\varvec{F}:{\mathscr {V}}_L \rightarrow {{\bar{{\mathscr {V}}}}}_L\) and \(\varvec{F}^{\mathsf {T}}\!:{{\bar{{\mathscr {V}}}}}_L \rightarrow {\mathscr {V}}_L\) given by
For any \(\varvec{w}= (\varvec{w}_\ell )_{\ell =0,\ldots ,L} \in {{\,\mathrm{ran}\,}}\varvec{F}\), where \(\varvec{w}= \varvec{F}\varvec{v}\) for \(\varvec{v}\in {\mathscr {V}}_L\), we obtain
by (112). Now let \(\varvec{G} :{\mathscr {V}}_L \rightarrow {{\bar{{\mathscr {V}}}}}_L, \, \varvec{v} \mapsto \bigl ( \varvec{ P}_{\ell ,L}^{\mathsf {T}}\!\varvec{v}\bigr )_{\ell =0,\ldots ,L}\). Then, \({{\,\mathrm{ran}\,}}\varvec{G} \subset {{\,\mathrm{ran}\,}}\varvec{F}\), and thus
which shows the lower bound in (31).
Arguing along similar lines to obtain the upper bound in (31) would lead to a constant depending linearly on L, and we thus now turn to a different approach using Lemma 6. Let \(\varvec{R}_\ell = \varvec{ P}_{\ell ,L} (\varvec{ P}_{\ell ,L}^{\mathsf {T}}\!\, \varvec{ P}_{\ell ,L})^{-1}\varvec{ P}_{\ell ,L}^{\mathsf {T}}\!\) be the discrete orthogonal projector onto \({\mathscr {V}}_\ell \). For any \(\varvec{w} \in {\mathscr {V}}_L\), setting \(\varvec{w}_0 = \varvec{R}_0 {\,}\!\varvec{w}\) and \(\varvec{w}_\ell = (\varvec{R}_\ell - \varvec{R}_{\ell -1}) \, \varvec{w}\) for \(\ell = 1,\ldots ,L\), we obtain the decomposition
which yields
For \(n = 0,1,\ldots ,L\), by Lemma 6,

We thus arrive at
completing the proof of the upper bound in (31) and hence of Theorem 2. \(\square \)
Remark 11
Although we have used some simplifications due to the tensor structure in our particular setting, the proof of Theorem 2 carries over to more general hierarchies of finite element spaces, provided that one can establish a corresponding strengthened Cauchy–Schwarz inequality as in (105), see, e.g., [9, 52, 54].
Rank-Reduced Decomposition
The following proof of Lemma 5 relies on properties of the strong Kronecker product inherited from the matrix and Kronecker products: linearity, associativity and distributivity. In particular, products of cores can be transformed into products of smaller cores by eliminating linear dependence from the decomposition, as the following example illustrates.
For any scalar coefficients \(\alpha \), \(\beta \) and blocks or subcores \(V_{11}\), \(V_{12}\), \(V_{21}\), \(V_{22}\), \(W_{11}\), \(W_{12}\) of suitable rank and mode size, we have
When the partitioning shown in (114a)–(114c) is in terms of blocks (which, by our identification convention, are subcores of rank \(1 \times 1\)), the rank of the product is \(2 \times 2\). The left-hand side of (114a) and the right-hand side of (114c) represent this core “in the TT format,” which has only one rank parameter and happens to be nothing else than low-rank matrix factorization in these two cases. The “ranks” of the first decomposition, equal to 2, are larger than the “ranks” of the last decomposition, equal to 1.
The TT representation (114b) consists of three cores and has ranks 2, 1. However, all mode indices of its middle core are dummy indices (the mode size of the middle core is \(1 \times 1\)), so the middle core can be merged with either of the neighboring cores without changing the decomposition scheme (by the latter we mean the set and the ordering of the variables separated by the TT format).
Proof (Lemma 5)
Let \(\hat{\varvec{N}}_{\ell ,{\,}\!L ,{\,}\!\alpha } = \hat{\varvec{M}}_{L ,{\,}\!\alpha } \, \hat{\varvec{P}}_{\ell ,L} \) and  . Applying Lemma 3 with the same \(\ell \) as fixed here, we obtain
. Applying Lemma 3 with the same \(\ell \) as fixed here, we obtain

where \(\hat{I}\) is as defined in (78). On the other hand, Lemma 4 gives the decomposition

Rewriting matrix multiplication core-wise, we combine the rank 2 decompositions given by (115a)–(115b) into a rank 4 decomposition for the product:

where \(\hat{A}_\flat \) and \(\hat{W}_\alpha \) with \(\alpha =0,1\) are as in (81) and (83) and \( E = \hat{I} \bullet \hat{P} \), \( \hat{U}_\sharp = \hat{U} \bullet \hat{U} \) and \( \hat{Y}_\sharp = \hat{V} \bullet \hat{X} \) are newly introduced cores. Direct calculation with expressions given in (67), (75) and (78) yields
in terms of the blocks I, \(I_1\), \(I_2\) and J defined in (37).
Sweeping from level L to level 1. Let us define the following cores:
First, we note that the second and fourth rows in each of the cores \(E\) and \(\hat{Y}_\sharp {{\,\mathrm{\bowtie }\,}}C\) are equal. This implies that \( E = C {{\,\mathrm{\bowtie }\,}}E \) and \( \hat{Y}_\sharp {{\,\mathrm{\bowtie }\,}}C = C {{\,\mathrm{\bowtie }\,}}\hat{Y}_\sharp {{\,\mathrm{\bowtie }\,}}C \). Further, in each of the cores \(\hat{W}_0 {{\,\mathrm{\bowtie }\,}}C\) and \(\hat{U}_\sharp \), the last row is zero, so that \( \hat{W}_0 {{\,\mathrm{\bowtie }\,}}C = G {{\,\mathrm{\bowtie }\,}}\hat{W}_0 {{\,\mathrm{\bowtie }\,}}C \) and \( \hat{U}_\sharp = G {{\,\mathrm{\bowtie }\,}}\hat{U}_\sharp \). These equalities allow to sweep the cores \(C\) and \(G\) through the last \(L-\ell \) and first \(\ell \) levels, respectively: starting from (115c), we obtain

Sweeping from level 1 to level L. Further, we notice that the cores
satisfy the relations \( \hat{A}_\flat = \hat{A} {{\,\mathrm{\bowtie }\,}}F \), \( F {{\,\mathrm{\bowtie }\,}}\hat{U}_\sharp {{\,\mathrm{\bowtie }\,}}G = \hat{U} {{\,\mathrm{\bowtie }\,}}F \), \( F {{\,\mathrm{\bowtie }\,}}\hat{W}_0 {{\,\mathrm{\bowtie }\,}}C = \hat{T}_{0} {{\,\mathrm{\bowtie }\,}}H \), \( H {{\,\mathrm{\bowtie }\,}}\hat{Y}_\sharp {{\,\mathrm{\bowtie }\,}}C = \hat{Y}_{0} {{\,\mathrm{\bowtie }\,}}H \) and \( H {{\,\mathrm{\bowtie }\,}}E = \hat{I} \). These relations allow to sweep the cores \(F\) and \(H\) through the first \(\ell \) and last \(L-\ell \) levels respectively: continuing (115c), we derive

This proves the claim in the case of \(\alpha =0\) since \(\hat{M}_0 = \hat{N}_0\) by (75) and (78).
Sweeping from level L to level \(\ell \). In the decomposition (115e), the ranks involved in the core products to the right of \(\hat{T}_{0}\) (in particular, those bounding the ranks of unfolding matrices \(\ell ,\ldots ,L-1+\alpha \)) are all equal to two. To prove the claim, it remains to consider the case of \(\alpha =1\) and obtain a reduced decomposition in which those ranks are all equal to one instead of two. To this end, we note that \( \hat{Y}_{0} {{\,\mathrm{\bowtie }\,}}\hat{M}_1 = \hat{M}_1 {{\,\mathrm{\bowtie }\,}}\hat{Y}_{1} = \hat{M}_1 {{\,\mathrm{\bowtie }\,}}\hat{Y}_{1} {{\,\mathrm{\bowtie }\,}}\hat{N}_1 \) and \( \hat{T}_{0} {{\,\mathrm{\bowtie }\,}}\hat{M}_1 = {\hat{T}}_1 \). Applying these relations to (115e), we obtain the claim in the case of \(\alpha =1\). \(\square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bachmayr, M., Kazeev, V. Stability of Low-Rank Tensor Representations and Structured Multilevel Preconditioning for Elliptic PDEs. Found Comput Math 20, 1175–1236 (2020). https://doi.org/10.1007/s10208-020-09446-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10208-020-09446-z
Keywords
- Elliptic boundary value problems
- Multilevel preconditioning
- Tensor decompositions
- Representation condition number
- Solver complexity