
Abstract
In communication networks resilience or structural coherency, namely the ability to maintain total connectivity even after some data links are lost for an indefinite time, is a major design consideration. Evaluating resilience is a computationally challenging task since it often requires examining a prohibitively high number of connections or of node combinations, depending on the structural coherency definition. In order to study resilience, communication systems are treated in an abstract level as graphs where the existence of an edge depends heavily on the local connectivity properties between the two nodes. Once the graph is derived, its resilience is evaluated by a tensor stack network (TSN). TSN is an emerging deep learning classification methodology for big data which can be expressed either as stacked vectors or as matrices, such as images or oversampled data from multiple-input and multiple-output digital communication systems. As their collective name suggests, the architecture of TSNs is based on tensors, namely higher-dimensional vectors, which simulate the simultaneous training of a cluster of ordinary multilayer feedforward neural networks (FFNNs). In the TSN structure the FFNNs are also interconnected and, thus, at certain steps of the training process they learn from the errors of each other. An additional advantage of the TSN training process is that it is regularized, resulting in parsimonious classifiers. The TSNs are trained to evaluate how resilient a graph is, where the real structural strength is assessed through three established resiliency metrics, namely the Estrada index, the odd Estrada index, and the clustering coefficient. Although the approach of modelling the communication system exclusively in structural terms is function oblivious, it can be applied to virtually any type of communication network independently of the underlying technology. The classification achieved by four configurations of TSNs is evaluated through six metrics, including the F1 metric as well as the type I and type II errors, derived from the corresponding contingency tables. Moreover, the effects of sparsifying the synaptic weights resulting from the training process are explored for various thresholds. Results indicate that the proposed method achieves a very high accuracy, while it is considerably faster than the computation of each of the three resilience metrics. Concerning sparsification, after a threshold the accuracy drops, meaning that the TSNs cannot be further sparsified. Thus, their training is very efficient in that respect.










Similar content being viewed by others

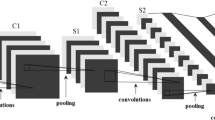
References
Abadi M (2016a) TensorFlow: learning functions at scale. ACM SIGPLAN Not. 51(9):1–1
Mea A (2016b) TensorFlow: a system for large-scale machine learning. OSDI 16:265–283
Alenazi MJ, Sterbenz JP (2015) Comprehensive comparison and accuracy of graph metrics in predicting network resilience. In: DRCN, IEEE, pp 157–164
Bengua JA, Phien HN, Tuan HD (2015) Optimal feature extraction and classification of tensors via matrix product state decomposition. In: ICBD, IEEE, pp 669–672
Benson AR, Gleich DF, Leskovec J (2015) Tensor spectral clustering for partitioning higher-order network structures. In: ICDM, SIAM, pp 118–126
Bergstra J et al (2011) Theano: Deep learning on GPUs with Python. In: NIPS BigLearning workshop vol 3, pp 1–48
Biguesh M, Gershman AB (2006) Training-based MIMO channel estimation: a study of estimator tradeoffs and optimal training signals. IEEE Trans Signal Process 54(3):884–893
Bishop CM (1995) Training with noise is equivalent to Tikhonov regularization. Neural Comput 7(1):108–116
Blackmore S (2000) The meme machine. Oxford Universtiy Press, Oxford
Chandrasekhar AG, Jackson MO (2014) Tractable and consistent random graph models. Technical report, National Bureau of Economic Research
Collobert R, Kavukcuoglu K, Farabet C (2011) torch7: A MATLAB-like environment for machine learning. In: BigLearn, NIPS workshop
Deng L (2014) A tutorial survey of architectures, algorithms, and applications for deep learning. APSIPA Trans Signal Inf Process 3:2 3https://doi.org/10.1017/atsip.2013.9
Deng L, Yu D (2011) Deep convex net: A scalable architecture for speech pattern classification. In: Twelfth annual conference of the International Speech Communication Association
Deng L, Hutchinson B, Yu D (2012) Parallel training for deep stacking networks. In: Thirteenth annual conference of the International Speech Communication Association
Deng L, He X, Gao J (2013) Deep stacking networks for information retrieval. In: ICASSP, IEEE
Deng L (2013) Recent advances in deep learning for speech research at Microsoft. In: ICASSP, IEEE
Drakopoulos G, Gourgaris P, Kanavos A, Makris C (2016a) A fuzzy graph framework for initializing k-means. IJAIT 25(6):1–21
Drakopoulos G, Kontopoulos S, Makris C (2016) Eventually consistent cardinality estimation with applications in biodata mining. In: SAC, ACM
Drakopoulos G, Kanavos A, Karydis I, Sioutas S, Vrahatis AG (2017) Tensor-based semantically-aware topic clustering of biomedical documents. Computation 5(3):34
Drakopoulos G, Kanavos A, Mylonas P, Sioutas S (2017) Defining and evaluating Twitter influence metrics: a higher order approach in Neo4j. SNAM 71(1):52
Drakopoulos G, Kanavos A, Tsolis D, Mylonas P, Sioutas S (2017) Towards a framework for tensor ontologies over Neo4j: representations and operations. In: IISA
Drakopoulos G, Liapakis X, Tzimas G, Mylonas P (2018) A graph resilience metric based on paths: higher order analytics with GPU. In: ICTAI, IEEE
Drakopoulos G, Stathopoulou F, Kanavos A, Paraskevas M, Tzimas G, Mylonas P, Iliadis L (2019) A genetic algorithm for spatiosocial tensor clustering: exploiting TensorFlow potential. Evol Syst
Dunlavy DM, Kolda TG, Acar E (2010) Poblano v1. 0: A MATLAB toolbox for gradient-based optimization
Estrada E, Higham DJ (2010) Network properties revealed through matrix functions. SIAM Rev 52(4):696–714
Fisher DH (1987) Knowledge acquisition via incremental conceptual clustering. Mach Learn 2(2):139–172
Golub GH, Hansen PC, O’Leary DP (1999) Tikhonov regularization and total least squares. J Matrix Anal Appl 21(1):185–194
Goodman DF, Brette R (2009) The brian simulator. Front Neurosci 3(2):192
Grubb A, Bagnell JA (2013) Stacked training for overfitting avoidance in deep networks. In: ICML workshops, p 1
Gulli A, Pal S (2017) Deep learning with keras. PACKT Publishing Ltd, Birmingham
Ho TY, Lam PM, Leung CS (2008) Parallelization of cellular neural networks on GPU. Pattern Recognit 41(8):2684–2692
Hutchinson B, Deng L, Yu D (2013) Tensor deep stacking networks. TPAMI 35(8):1944–1957
Ip WH, Wang D (2011) Resilience and friability of transportation networks: evaluation, analysis and optimization. IEEE Syst J 5(2):189–198
Jang H, Park A, Jung K (2008) Neural network implementation using CUDA and OpenMP. In: DICTA’08, IEEE, pp 155–161
Jia Y (2014) Caffe: convolutional architecture for fast feature embedding. In: International conference on multimedia. ACM, pp 675–678
Kanavos A, Drakopoulos G, Tsakalidis A (2017) Graph community discovery algorithms in Neo4j with a regularization-based evaluation metric. In: WEBIST
Kohonen T (1998) The self-organizing map. Neurocomputing 21(1):1–6
Kolda T (2009) Tensor decompositions and applications. SIAM Rev 51(3):455–500
Kontopoulos S, Drakopoulos G (2014) A space efficient scheme for graph representation. In: ICTAI, IEEE
Kumar R, Sahni A, Marwah D (2015) Real time big data analytics dependence on network monitoring solutions using tensor networks and its decompositions. Netw Complex Syst 5(2)
Larsson EG et al (2014) Massive MIMO for next generation wireless systems. IEEE Commun Mag 52(2):186–195
Jea L (2010) Kronecker graphs: an approach to modeling networks. JMLR 11:985–1042
Li J, Chang H, Yang J (2015) Sparse deep stacking network for image classification. In: AAAI, pp 3804–3810
Li L, Boulware D (2015) High-order tensor decomposition for large-scale data analysis. In: ICBD, IEEE, pp 665–668
Liberti JC, Rappaport TS (1996) A geometrically based model for line-of-sight multipath radio channels. Veh Technol Conf 2:844–848
Lin S et al (2016) ATPC: adaptive transmission power control for wireless sensor networks. TOSN 12(1):6
Loguinov D, Casas J, Wang X (2005) Graph-theoretic analysis of structured peer-to-peer systems: routing distances and fault resilience. IEEE/ACM TON 13(5):1107–1120
Loyka SL (2001) Channel capacity of MIMO architecture using the exponential correlation matrix. IEEE Commun Lett 5(9):369–371
Lusher D, Koskinen J, Robins G (2013) Exponential random graph models for social networks: theory, methods, and applications. Cambridge University Press, Cambridge
Malewicz G (2010) Pregel: a system for large-scale graph processing. In: CIKM, ACM, pp 135–146
Matthews DG (2017) GPflow: a Gaussian process library using tensorflow. JMLR 18(1):1299–1304
Xea M (2016) MLlib: machine learning in Apache spark. JMLR 17(1):1235–1241
Nageswaran JM (2009) A configurable simulation environment for the efficient simulation of large-scale spiking neural networks on graphics processors. Neural Netw 22(5):791–800
Najjar W, Gaudiot JL (1990) Network resilience: a measure of network fault tolerance. ToC 2(1):174–181
Ngo HQ, Larsson EG, Marzetta TL (2013) Energy and spectral efficiency of very large multiuser MIMO systems. ToC 61(4):1436–1449
Oh KS, Jung K (2004) GPU implementation of neural networks. Pattern Recognit 37(6):1311–1314
Palangi H, Ward RK, Deng L (2013) Using deep stacking network to improve structured compressed sensing with multiple measurement vectors. In: ICASSP, pp 3337–3341
Papalexakis EE, Faloutsos C (2015) Fast efficient and scalable core consistency diagnostic for the PARAFAC decomposition for big sparse tensors. In: ICASSP, pp 5441–5445
Papalexakis EE, Pelechrinis K, Faloutsos C (2014) Spotting misbehaviors in location-based social networks using tensors. In: WWW, pp 551–552
Pellionisz A, Llinás R (1979) Brain modeling by tensor network theory and computer simulation. The cerebellum: Distributed processor for predictive coordination. Neuroscience 4(3):323–348
Priest DM (1991) Algorithms for arbitrary precision floating point arithmetic. In: Tenth symposium on computer arithmetic. IEEE, pp 132–143
Hea R (1992) Neural computation and self-organizing maps: an introduction. Addison-Wesley Reading, Boston
Schmidhuber J (2015) Deep learning in neural networks: an overview. Neural Netw 61:85–117
Seshadhri C, Pinar A, Kolda TG (2011) An in-depth study of stochastic Kronecker graphs. In: ICDM, SIAM, pp 587–596
Seshadhri C, Pinar A, Kolda TG (2013) An in-depth analysis of stochastic Kronecker graphs. JACM 60(2):13
Shi Y, Niranjan U, Anandkumar A, Cecka C (2016) Tensor contractions with extended BLAS kernels on CPU and GPU. In: HiPC, IEEE, pp 193–202
Sutskever I, Vinyals O, Le QV (2014) Sequence to sequence learning with neural networks. In: NIPS, pp 3104–3112
Vasilescu MAO, Terzopoulos D (2002) Multilinear analysis of image ensembles: Tensorfaces. In: European conference on computer vision. Springer, pp 447–460
Vázquez A, Moreno Y (2003) Resilience to damage of graphs with degree correlations. Phys Rev E 67(1):15–101
Vedaldi A, Lenc K (2015) Matconvnet: Convolutional neural networks for MATLAB. In: International conference on multimedia. ACM, pp 689–692
Vervliet N, Debals O, De Lathauwer L (2016) TensorLab 3.0—numerical optimization strategies for large-scale constrained and coupled matrix-tensor factorization. In: Asilomar conference on signals, systems and computers. IEEE, pp 1733–1738
Wang M et al (2018) Disentangling the modes of variation in unlabelled data. TPAMI 40(11):2682–2695
Wolpert DH (1992) Stacked generalization. Neural Netw 5(2):241–259
Wong D, Cox DC (1999) Estimating local mean signal power level in a Rayleigh fading environment. TVT 48(3):956–959
Wongsuphasawat K (2018) Visualizing dataflow graphs of deep learning models in TensorFlow. Trans Vis Comput Graph 24(1):1–12
Yu D, Deng L, Seide F (2013) The deep tensor neural network with applications to large vocabulary speech recognition. Trans Audio Speech Language Process 21(2):388–396
Zeng R, Wu J, Senhadji L, Shu H (2015) Tensor object classification via multilinear discriminant analysis network. In: ICASSP, IEEE, pp 1971–1975
Acknowledgements
The authors acknowledge the support of NVIDIA Corporation with the donation of the Titan Xp GPU used for this research.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Drakopoulos, G., Mylonas, P. Evaluating graph resilience with tensor stack networks: a Keras implementation. Neural Comput & Applic 32, 4161–4176 (2020). https://doi.org/10.1007/s00521-020-04790-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-020-04790-1
Keywords
- Tensor stack network
- Tensor algebra
- Deep learning
- Big data
- Higher-order data
- Graph mining
- Graph resilience
- Estrada index
- Clustering coefficient
- Multilinear classification
- Sparsification
- Regularization
- TensorFlow
- Keras