Semantic Knowledge Representation for Strategic Interactions in Dynamic Situations
 Carlos Calvo Tapia1
Carlos Calvo Tapia1  José Antonio Villacorta-Atienza2
José Antonio Villacorta-Atienza2  Sergio Díez-Hermano2
Sergio Díez-Hermano2  Maxim Khoruzhko3
Maxim Khoruzhko3  Sergey Lobov3
Sergey Lobov3  Ivan Potapov3
Ivan Potapov3  Abel Sánchez-Jiménez2
Abel Sánchez-Jiménez2  Valeri A. Makarov1,3*
Valeri A. Makarov1,3*- 1Facultad de CC. Matemáticas, Instituto de Matemática Interdisciplinar, Universidad Complutense de Madrid, Madrid, Spain
- 2Biomathematics Unit, Faculty of Biology, Complutense University of Madrid, Madrid, Spain
- 3N. I. Lobachevsky State University, Nizhny Novgorod, Russia
Evolved living beings can anticipate the consequences of their actions in complex multilevel dynamic situations. This ability relies on abstracting the meaning of an action. The underlying brain mechanisms of such semantic processing of information are poorly understood. Here we show how our novel concept, known as time compaction, provides a natural way of representing semantic knowledge of actions in time-changing situations. As a testbed, we model a fencing scenario with a subject deciding between attack and defense strategies. The semantic content of each action in terms of lethality, versatility, and imminence is then structured as a spatial (static) map representing a particular fencing (dynamic) situation. The model allows deploying a variety of cognitive strategies in a fast and reliable way. We validate the approach in virtual reality and by using a real humanoid robot.
1. Introduction
Efficient object manipulation is simultaneously one of the most apparent features of humans' daily life and one of the most challenging skills that modern humanoid robots largely lack (see e.g., Calvo et al., 2018b; Billard and Kragicet, 2019 and references therein). The sensory-motor abilities ordinarily exhibited by humans may appear dull at first glance. However, children spent years to acquire adult-equivalent skills in manipulation (Thibaut and Toussaint, 2010). Therefore, such simple-but-difficult tasks possess vast intrinsic complexity, which impedes robots to mimic even basic human abilities in real-life scenarios.
Modern robots are capable of manipulating objects in repetitive and controlled conditions, e.g., in industrial assembly setups. In such tailor-made scenarios, a purely programmatic approach to the problem of limb movement works rather well (Choset et al., 2005; Patel and Shadpey, 2005). The development of adaptive techniques, the use of control theory, and learning in neural networks made it possible to adjust the robot's trajectories to comply with some degree of uncertainty. Nowadays, robots can retrieve objects at different locations, e.g., from a conveyer belt or even catch fast-moving objects (Kim et al., 2014; Nguyen et al., 2016; Bouyarmane et al., 2018; Mason, 2018). There is a growing body of approaches addressing the problems of a robust prediction of trajectories of objects, fast calculation of feasible postures and movements of limbs through, e.g., splines, etc. (Riley and Atkeson, 2002; Aleotti and Caselli, 2006; Xiao et al., 2016).
Although robots strive to dexterous object handling and gradually improve skills in orientation in space (Billard and Kragicet, 2019), they still undergo difficulties in handy and safe interactions with humans in time-evolving situations. Such cooperation requires the implementation of motor cognition at different levels of decision-making, including the abstract one (Villacorta-Atienza and Makarov, 2013). The latter, in particular, can be approached through studies of brain structures and functions involved in cognitive phenomena (Sporns, 2011; Calvo et al., 2020).
The remarkable human capacity to actuate in complex situations relies in part on semantic memory (for a review, see Binder and Desai, 2011). Models of semantic memory have seen an impressive improvement that has dramatically advanced our understanding of how humans create, represent, and use meanings from experiences (for a review, see Jones et al., 2015). The semantic organization of concepts and features is much more economical in terms of the memory capacity and ability of generalization. This advantage enables an efficient building of unexpected compound strategies and new knowledge.
Semantic memory uses the features and attributes of experiences that define concepts, and allow us to efficiently retrieve, act upon, and produce information in the service of thought and language. While the application of this methodology to simple concepts made of items (e.g., a lion, a tree, a table) and their features (e.g., wild, green, long) was hugely successful (Ralph et al., 2017), it has been used in studies of motor skills to a much lesser extent.
We will call a motor-motif a particular movement of a limb or a body in a specific time window. Then, a sequence of motor-motifs composes a behavior that can be arbitrarily complex (Calvo et al., 2018a). Each motor-motif is a function of space and time. The internal representation of such spatiotemporal objects in the brain is a challenging open problem (Livesey et al., 2007; Kraus et al., 2013; Bladon et al., 2019). How the brain generates concepts, and thus semantic memories from movement experiences, is largely unknown. To solve this puzzle, in our previous works, we proposed a theoretical hypothesis called time compaction (Villacorta-Atienza et al., 2010, 2015), which recently received experimental support (Villacorta-Atienza et al., 2019).
Time compaction states that when dealing with time-changing situations, the brain does not encode time explicitly but embeds it into space. Then, a dynamic situation (i.e., a spatio-temporal structure) is transformed into a purely static object, the so-called generalized cognitive map (GCM). A GCM, in particular, contains images of motor-motifs in the form of points in some configuration space. Such an enormous dimension reduction (compaction of time) significantly reduces brain resources required for the planning of trajectories in complex situations, including motor interactions of humans (Villacorta-Atienza et al., 2015). It also enables building concepts out of motor-motifs by using the principle of the high-dimensional brain (Calvo et al., 2019; Gorban et al., 2019, 2020; Tyukin et al., 2019).
Standard cognitive maps (CMs) are abstract internal representations of static situations in the brain (Tatler and Land, 2011; Schmidt and Redish, 2013; Noguchi et al., 2017). Such representations enable navigation in static environments, and, to some extent, can be compared to a modern GPS providing the ability to plan routes using a map with roads and obstacles (e.g., buildings) to be avoided (Schmidt and Redish, 2013). Similar to a standard CM, a GCM is also an abstract description of the environment, but it extends CMs into dynamic situations. Thus, the GCM approach allows selecting different strategies or motor-motifs to navigate in dynamic situations by using special maps.
Hypothetically, the GCM approach enables building semantic motor memory out of motor-motifs embedded as points into GCMs. However, no successful attempts have been made yet. In this work, we develop a novel approach to constructing behaviors based on the semantic description of motor-motifs emerging from GCMs. The method is illustrated in the simulation of the combat sport of fencing and further validated experimentally on a humanoid robot.
2. Materials and Methods
We begin with a practical example of the combat sport of fencing that will help us introduce the main idea of building cognitive strategies. Fencing is a highly demanding sport based on the perfect coordination of fast movements, where points are scored by hitting an opponent by the tip of a foil. Each dynamic, i.e., a time-evolving situation, gives rise to an internal brain model. Such a model includes relevant spatial and temporal aspects of the situation (Kraus et al., 2013). Our goal is to provide a semantic description of the strategic planning based on GCMs and motor-motifs. In the following subsections, we thus briefly summarize the GCM concept, introduce the configuration space of a manipulator, discuss how a GCM and motor-motifs can be constructed in the configuration space, and provide the robot design for validating the theory.
2.1. Generalized Cognitive Maps
The concept of GCMs stems from standard cognitive maps. In time-changing situations, e.g., while navigating in a crowd, standard CMs are not suitable since the maps continuously change in time. The neural and functional mechanisms behind human decision making in time-changing situations are mostly unknown. Recently, a hypothesis that the brain entangles spatial and temporal dimensions in a single entity has been proposed (Villacorta-Atienza et al., 2010; Buzsaki and Llinas, 2017), which in the end gave rise to the GCM concept.
According to the hypothesis, the brain transforms “time into space” (Villacorta-Atienza et al., 2010; Villacorta-Atienza and Makarov, 2013). Such a functional mechanism, called time compaction, allows representing a dynamic situation as a static map, similar to a standard CM. The resulting generalized cognitive map also has steady obstacles and can be used to trace routs for navigation. A standard CM and a GCM of a static scene are equivalent, i.e., the static obstacles appear in both maps at the same places.
The advantage of GCMs is the projection of objects moving in the environment into a map as virtual obstacles. Such projection or time compaction occurs by identifying places of the potential collisions of the subject with moving objects. It is achieved by predicting and matching all trajectories of the moving elements and the subject. The latter is accomplished by a wave process simulating all possible movements simultaneously (Villacorta-Atienza et al., 2010). The places of potential collisions become virtual obstacles that subject should stay away to avoid crashes while navigating.
Time compaction is useful for navigation in different dynamic situations (Villacorta-Atienza et al., 2015). However, its power goes far beyond effective or “applied” cognition. The static representation of the subject's actions as mere points in a configuration space enables building memories of static images of motor-motifs, instead of memorizing the whole spatiotemporal situations (Villacorta-Atienza and Makarov, 2013). Then, the subject can establish causal relationships among such images and build high-level cognitive strategies in complex dynamic situations. Below we develop a model for semantic knowledge representation by means of linking images of motor-motifs as pieces in the Tetris-like game on the abstract cognitive level.
2.2. Model of Fencing in Hand-Space
Figure 1A sketches a typical situation of combat of two fencers. During training, one of the fencers (a learner, Figure 1A in blue) responds to the pre-designed movements of the other (a teacher, in pink). In what follows, we will model the actions of the learning subject.
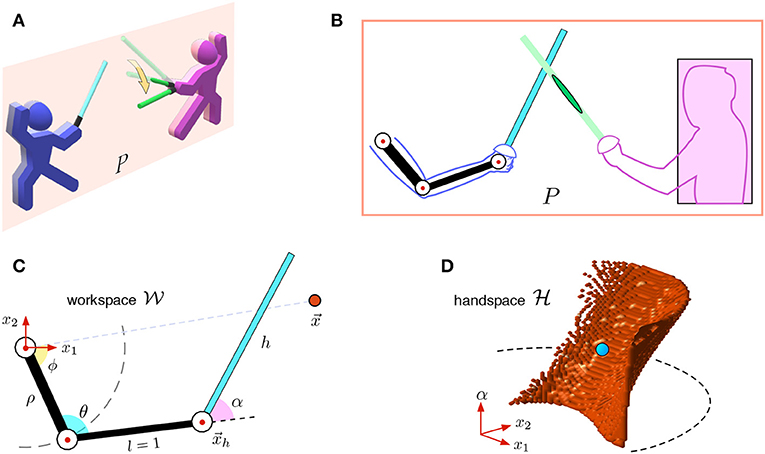
Figure 1. Model of fencing: from workspace to hand-space. (A) Sketch of combat of two fencers. The cognitive fencer (the subject colored in blue) is aligned within plane P. The opponent (in pink) moves the foil along the yellow arrow crossing the plane. (B) In plane P, the subject's upper limb has three joints (3 DoF), while the opponent is reduced to a rectangle. (C) Kinematic model of the subject's limb and foil in the workspace . Red dot at is a object point. (D) The model in the hand-space . The subject's limb and the foil are reduced to a single point (in blue), while the object point is extended to a surface (in red).
2.2.1. Kinematic Model in Workspace
We consider the fencer colored in blue in Figure 1A as a cognitive subject. Let P be the main plane aligned with the subject's upper limb and the foil. For simplicity, we assume that foils' tips can contact with the fencers' bodies within this plane only. The subject's limb and the foil can be described as a three-segment mechanical system with tree joints rotating within certain physiological limits (Figure 1B). The opponent's body in plane P can be represented by the minimal rectangle (colored in pink).
Figure 1C shows the kinematic model of the subject. Without loss of generality, we assume that the length of the subject's forearm is l = 1 a.u. The subject's shoulder is fixed at the origin of the (x1, x2)-plane, and it is joined to an articulated elbow by a rigid segment of length ρ. The forearm joins the elbow with the hand at . The wrist can flex, thus changing the angle of the last segment of length h, representing the foil. Besides, we consider a single-point object , which can have different semantic meanings, either a target or an obstacle. In numerical simulations and experimental validation, we use ρ = 1 a.u. and h = 3 a.u., which is close to the real anthropometry, the robot sizes, and the foil length used in fencing.
All movements of the subject's limb and foil are restricted to a disk of radius (ρ+1+h) centered at the origin. We then introduce the workspace (reachable space):
where denotes a closed disk of radius r centered at the origin. The shoulder, elbow, and wrist joints can rotate within specific limits posed onto the angles ϕ, θ, and α (Figure 1C). Thus, we have defined a redundant three degree of freedom (DoF) mechanical system working in a 2D workspace . For convenience, we also denote by the union of the three segments corresponding to the subject's upper arm, forearm, and foil.
2.2.2. Hand-Space Representation
The original procedure of building GCMs (Villacorta-Atienza et al., 2010) assumes that the subject has a rigid body and can be shrunken into a point. The spatial extension and the changing geometry of the subject's limb and foil bring an additional degree of complexity. To resolve this problem, recently, we have proposed a transformation from the workspace to a configuration space that allows extending the GCM-theory into manipulators (Spong et al., 2006; Calvo et al., 2017, 2018b; Villacorta-Atienza et al., 2017). The transformation eliminates the spatial dimensions and rotational degrees of freedom. Then, the equivalent collision space, called the hand-space, is given by:
where J = [αmin, αmax] is the feasible interval of the wrist angle α. Without loss of generality, we assume ρ ≥ 1. Then is a cylinder (or torus) without the central line.
2.2.3. Mapping From Workspace to Hand-Space
The technique of mapping from to has been described elsewhere (Calvo et al., 2017, 2018b; Villacorta-Atienza et al., 2017). Here we briefly summarize our earlier results.
2.2.3.1. Shrinkage of limb and foil
The shrinkage of the arm with the foil, i.e., the set , is given by the following mapping
which reduces the three-segment mechanical system in the workspace (black and cyan segments in Figure 1C) to the single point in the hand-space (blue dot in Figure 1D), corresponding to the hand position and the wrist angle in .
2.2.3.2. Extension of objects
The price to pay by applying the shrinkage (3) is the augmentation of other objects in the hand-space. Let us first consider a single-point object (red dot in Figure 1C). This point is extended to a set of surfaces (red area in Figure 1D) corresponding to coincidences of the point object with the three segments of in the workspace. Thus,
where E1,2,3 represent the extensions due to collisions of the object with the upper arm, forearm, and foil, respectively. Note that depending on , some of Ej can be empty. For example, if is located outside the region accessible by the upper arm (i.e., , as in Figure 1C), then .
When dealing with objects of arbitrary shape, the extension E is applied to each over the object's boundary. This generates extended objects wrapping volumes in . If the object moves in , then its extension in changes with time.
Extension due to collision with upper arm, E1. If a point object at is reachable by the upper arm, then the upper arm segment contacts the object whenever ϕ = 0. Therefore, we get:
where
Note that the constraint on θ in (5) is imposed by assuming that the elbow joint can rotate within the limits [0, π]. Otherwise it can be relaxed.
Extension due to collision with forearm, E2. If the object is reachable by the forearm, then we have:
where
and . The lower bound for ϕ in (7) is given by
Extension due to collision with foil, E3. Assuming that the foil is in contact with the object at a distance from the wrist, we get:
where
and Rα is the standard clockwise rotational matrix. In Equation (11)
The lower bound for d in (10) is given by .
2.3. Neural Network Generating Generalized Cognitive Maps in Hand-Space
To generate a GCM, we simultaneously (i) predict the objects' movements and (ii) simulate all possible subject's actions matched with the objects' movements. Both calculations must be done by the subject faster than the time scale of the dynamic situation (for more detail see Calvo et al., 2016). To account for this internal processing, besides the “real” time t in the workspace , we introduce the “mental” time τ used for calculations in the hand-space . For convenience, we also introduce the discrete time n ∈ ℕ0 related to the continuous time by τ = δn, where δ is the time step.
There are several ways to solve problem (i) (see, e.g., Hong and Slotine, 1997; Riley and Atkeson, 2002; Villacorta-Atienza et al., 2010; Villacorta-Atienza and Makarov, 2013). For simplicity, we assume that the trajectories of all objects (except the subject, ) are given. Using these trajectories, we can evaluate images of the objects (e.g., the opponent's foil) in the hand-space (section 2.2.2). Then, we simulate all possible movements of the subject by means of a wave process initiated at the initial configuration .
In earlier works, we considered 2D internal representations of workspaces and postulated a constant velocity c for the wave of excitation spreading in the hand-space (Villacorta-Atienza et al., 2010, 2017; Calvo et al., 2017). The propagating wavefront simulates all possible movements of the hand (see below). In the 3D hand-space, the wrist joint can rotate with an angular velocity ω = dα/dt ∈ ℝ independent of the hand velocity in the (x1, x2)-plane. Then, we impose the following constraint on the compound subject velocity in :
where γ0 ∈ [0, 1] is the velocity bias. The value γ0 = 0 corresponds to a rigid wrist joint. The other limit γ0 = 1 describes the situation where the wrist flexion is the only available movement, i.e., the subject's upper limb is fixed. We note that formulation (13) is equivalent to fixing the kinetic energy of .
To describe the wave dynamics, we design a neural network on the cylindrical lattice:
where r ∈ ℕ defines the spatial resolution in the plane (x1, x2), and K ∈ ℕ defines the resolution for the wrist flexion angle α. Thus, Λ is the discrete version of the hand-space . On the lattice Λ, we define the neural network:
where uλ is the state variable describing the neuronal dynamics, f(u) = u(u − 0.1)(1 − u) is the nonlinear function providing the excitable dynamics of individual neurons, Δx, Δα are the discrete Laplacians in the corresponding variables, Γ(n) is the set of neurons occupied by the extended objects at time instant n, and L is a small spheroid centered at λ0 (the discrete version of ).
The dynamics of the neural network (15) admits propagation of spherical waves starting from the spheroid L (Calvo et al., 2018b). The initial spheroid sets the eccentricity of the wavefront defined by the bias parameter . Then, the wave propagates outwards, excites cells not occupied by obstacles, and creates effective objects when colliding with extended objects in the hand-space. The dynamically growing set Ω(n) describes effective objects at step n.
The dynamical system (15) is considered with Neumann boundary conditions on the cylinder border and extended objects. At τ = 0 (and hence n = 0), the neurons are set to uλ(0) = 0, ∀λ ∈ Λ \ L, uλ(0) = 1 ∀λ ∈ L, and Ω(0) = ∅. The diffusion coefficient d0 is adjusted to account for the compound subject velocity c (Calvo et al., 2018b).
2.4. Robot and Avatar Design
For testing and validating the theoretical results, we built a humanoid robot consisting of a robot Poppy Torso (upper part) attached to a wheeled platform Pioneer 3DX (Figure 2A). The wheeled platform provides the robot with the possibility to freely move in space, while the Torso enables manipulation of a foil.

Figure 2. Experimental design. (A) Robotic fencer. A humanoid robot Torso (in white) is attached to a wheeled platform Pioneer 3DX (in red). (B) Avatar in virtual reality.
To build the upper part of the robot, we used the open-source project Poppy Torso (Lapeyre et al., 2014; Duminy et al., 2016). The robot is based on Dynamixel smart servomotors and 3D printed plastic elements. The geometric dimension of the upper arms 15.5 cm (from the shoulder to the elbow), the forearms are 15 cm long (from the elbow to the foil hilt), and a toy foil is of 45 cm. To move the robot's body, we used a wheeled platform Pioneer 3DX (Adept Mobilerobotics, linear sizes l × w × h: 45.5 × 38.1 × 23.7 cm). An onboard computer (NUC, Intel) drives the robot through appropriate interfaces (USB and USB-COM).
To control the robot, we developed software called Avatar, which runs in a standalone PC. The Avatar serves as a bidirectional interface between the robot's body and its artificial “brain.” Thus, it provides the embodiment of the cognitive skills developed in simulations. The Avatar can work in two modes: (1) Driving the robot, and (2) Emulating the robot in virtual reality (Figure 2B).
In the first mode, the Avatar controls the servomotors of the robot. Thus, we can change the configuration of the robot's upper limbs and move it in space. At the initialization, the Avatar takes settings (main parameters such as e.g., the length of segments) from a text file, which allows flexible changes without reprogramming. The Avatar can also read in real-time the telemetric information of all servomotors. The software uses a client-server architecture based on TCP/IP for interacting with user programs simulating cognitive behaviors (artificial brain). The application programming interface allows controlling the robot movements at low and high levels. The low level allows selecting a motor and performing the desired rotation. At the high level, the user can send a trajectory for moving, e.g., the robot's arm . Then, the Avatar solves the inverse kinematics problem.
and applies the corresponding rotations to the servomotors in an automatic mode.
In the emulation mode, the Avatar builds a 3D model of the robot in a virtual environment (Figure 2B). Then, all the requested movements can be implemented by the virtual robot in the same way as would be done with the real robot. The Choregraphe program by the Aldebaran implements a similar functionality for the NAO robot (Pot et al., 2009; Shamsuddin et al., 2011). However, NAO is not suited for tasks considered in this work, in part, due to a significant deviation from anthropomorphic measures.
3. Results
3.1. Emergence of Generalized Cognitive Maps and Single Motor Actions
Let us first consider how a GCM can be constructed for a novel dynamic situation. Figure 3A illustrates a simple combat scene similar to that shown in Figure 1A. The upper limb and the foil of the cognitive fencer (on the left) are aligned within the main plane. Its opponent (on the right) moves its foil with a constant angular velocity by a circular displacement of the hand, from right to left. The goal of the subject is to either defend (i.e., to stop the opponent's foil) or attack (i.e., to hit the opponent's body by the foil tip). Such decision-making goes through the construction of a generalized cognitive map.
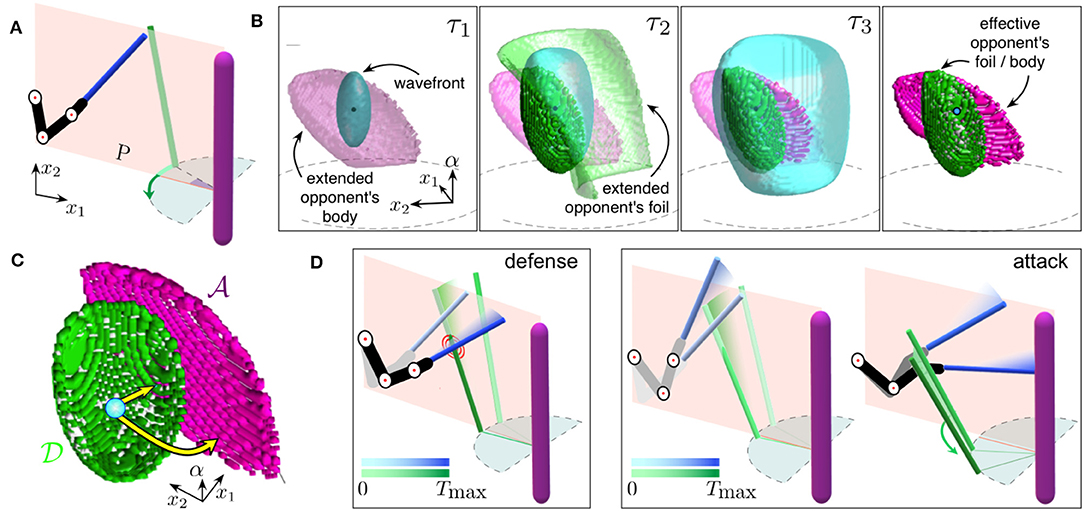
Figure 3. Emergence of cognitive map driving subject's actions. (A) Sketch of a combat situation. The subject's upper limb (in black) and the foil (in blue) are shown. The pink vertical bar represents the opponent with a foil (in green). (B) Generation of the GCM in the discretized hand-space Λ. Three successive snapshots (τ1, τ2, and τ3) and the final GCM (right subplot) are shown. (C) Two typical trajectories (yellow curves) of the subject movement in the discrete hand-space. Arrows starting at blue point and ending at the pink/green area correspond to an attack/defense movement (sets and ). (D) Implementation of the trajectories shown in (C) in the workspace. Left: Execution of the defensive trajectory. Right: Execution of the attack trajectory (the color darkness corresponds to the time course).
Figure 3B shows three successive snapshots at time instants τ1 < τ2 < τ3 illustrating the process of building the GCM in the discrete hand-space Λ (see section 2.3). The traveling wavefront (light-blue) explores the environment containing the extended opponent's body (snapshot τ1). Note that the opponent's body does not move and the corresponding extended object has a fixed shape in all snapshots. In contrast, the opponent's foil crosses plane P in a certain time interval and hence its representation in Λ changes in time (it is present in snapshot τ2 only).
Let λ0 ∈ Λ be the point representing the limb configuration at τ = 0, i.e., the discrete version of (see Equation 3). We then can express the process of generation of a GCM given by Equation (15) as the map:
Gλ0(λ) stores the time taken by the subject to modify the configuration of its limb from λ0 to λ, following the course of the wave propagation.
While propagating, the wavefront hits the extended opponent's body and foil, which produces static effective objects Ω(1) ⊆ ⋯ ⊆ Ω(nmax) = Ω that can be reached by the subject's foil. The process (see Equation 15) creates the GCM when the wave propagation ends:
Note that for each λ ∈ Ω, Gλ0(λ) ∈ ℕ represents the time instant when the subject's foil either stops the opponent's foil or hits the opponent's body at location λ. We thus can divide this set into sets for a defense and for an attack (dark green and dark pink sets in Figure 3B, respectively):
Figure 3C shows two representative examples of the subject movements in the hand-space. One of them (yellow arrow ending in the green area) corresponds to a defense action , i.e., the subject stops the opponent's foil, whereas the other (yellow arrow ending in the pink area) describes an attack , i.e., the foil tip hits the opponent's body.
We can now unfold the trajectories from the hand-space to the workspace (i.e., solve the inverse kinematic problem). Figure 3D shows two combat actions corresponding to a defense and an attack. In the first case (Figure 3D, left), the subject lowers his foil and stops the opponent's attack. In the second case (Figure 3D, right), the subject performs a “two-step” action. First, he lifts the foil and then moves it down, simultaneously rotating his wrist. Thus, the subject circumvents the opponent's foil and then hits the opponent's body.
3.2. Cognitive Substrate for Building Strategies in Dynamic Situations
To master different skills of defense and attack, a fencer learns to actuate in different situations S1, …, Sm simulating parts of real combat (Figure 4A). Such learning shapes generalized cognitive maps M1, …, Mn describing the internal representation of each situation (Figure 3). Thus, the time dimension of the perceived situations is compacted into the fourth dimension of M while the combat-relevant spatiotemporal events are mapped into a virtual collision space (Figure 4B).
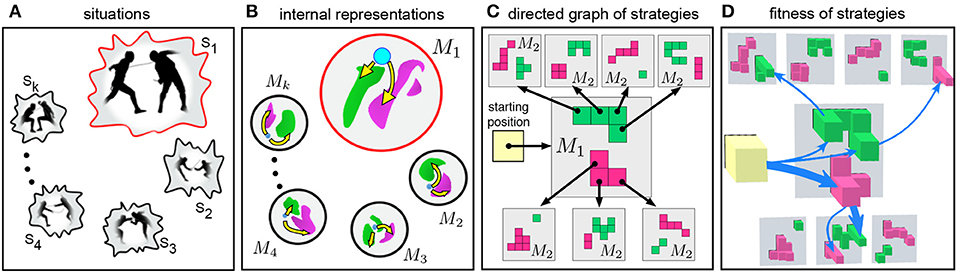
Figure 4. Building optimal strategies in dynamic situations. (A) A fencer learns to actuate in different dynamic situations while training. (B) Sketches of generalized cognitive maps of the learned situations. Blue dot represents the subject's upper limb and the foil. Yellow paths to pink and green regions correspond to attack and defense actions, respectively. (C) Sketch of two-step strategies. The subject invokes a first order map M1 from the starting position and gets several options for the first movement. Then, each movement leads to a second order map M2 with new possible movements. The strategy is built by selecting one of the pathways in the directed graph. (D) Each action has a fitness (imminence, lethality, and versatility) denoted by the height of colored squares. This allows selecting the most suitable strategies (blue arrows).
3.2.1. From Single Movements to Series of Actions
As we discussed above, the collision space is configurational. The whole subject's limb and the foil are represented by a single point in and hence in Λ (blue dot in Figures 3C, 4B), while the opponent's body and the foil are augmented and mapped by the wave-process into static effective objects (green and pink areas in Figures 3C, 4B). Such virtual objects represent collisions with the subject's foil. Thus, depending on the fighting skills, the fencer gets potential options to attack or to defend by following a trajectory from the blue dot to either red () or green area () (yellow arrows in Figures 3C, 4B).
From the mathematical viewpoint, a GCM, M1(λ0), can be defined by the mapping Gλ0 (see Equation 18). Now, once the agent is able to move from λ0 to λ1 ∈ Ω1 in time Gλ0(λ1), a second GCM can be generated by using λ1 as the initial limb configuration: M2(λ0, λ1) = {(λ,Gλ1(λ))}λ∈Λ. Such a process can be continued, and we get the chain
where nk = Gλk−1(λk) is the time taken to move the subject's limb from λk−1 to λk, and Mk = {(λ,Gλk−1(λ))}λ∈Λ is the k-th order GCM. Thus, the fencer can design a route consisting of a chain of (k + 1) points in the hand-space λ0 → λ1 → ⋯ → λk. Such a route allows reproducing a series of concatenated actions according to a certain strategy. Since each GCM enables several different movements with the foil (e.g., two yellow curves in each GCM shown in Figure 4B), each movement, λi−1 → λi, can be followed by a series of next movements. This leads to the emergence of a strategy graph and a reach variety of combat repertoires.
3.2.2. Semantic Description of Strategies Over Cognitive Substrate
Let us now consider the process of building strategies in detail. Figure 4C shows the sketch of planning a two-step action. When the opponent initiates the first movement from a specific starting position, the subject predicts the evolution of the situation (yellow square) and invokes the first GCM (Figure 4C, gray square M1). Green and pink Tetris-like pieces in map M1 illustrate the sets and , respectively. We remind that moving to one of the pieces in or in the hand-space corresponds to a defense or attack action in the workspace.
Each specific square in the first order map (Figure 4C) m1: = (λ1, n1) ∈ M1 can be considered as a motor-motif, i.e., an essential motor actions of the subject (Colome and Torras, 2014; Makarov et al., 2016; Calvo et al., 2018a). We now can take one motor-motif m1 and use it as a new situation for generating the second motor-motif through a second order GCMs (Figure 4C, black arrows pointing to gray squares marked as M2). Each of these GCMs provides several options for the second motif (Figure 4C, Tetris-like pieces in maps M2). Such an iteration can be repeated and thus we get a sequence of motor-motifs:
Sequences of the form (21) define diverse semantic contents of the possible chained actions of the subject. For example, the simplest defense-attack chain is given by (λ1, n1) → (λ2, n2), where and . Note that there are many such chains even for a single given situation (Figure 4C). Now the subject can learn different semantic chains and perform series of motor-motifs.
3.2.3. Strategy Fitness
Each piece in a Tetris-like map (Figure 4C) represents an action with some particular features such as imminence, lethality, and versatility. We then can assign the corresponding fitness values to all pieces in the maps (Figure 4D). Now taking a particular chain of motor-motifs m1 → … → mk, the subject can evaluate its compound fitness and thus select the most suitable strategy according to his motivation by maximizing, e.g., the safety (thick blue arrow in Figure 4D).
Let us now introduce definitions for a two-step strategy d1 = (λ1, n1) → a2 = (λ2, n2), with and .
• Imminence: It is the relative time taken by a chain of motor-motifs:
• Lethality: It is the mean injury to the opponent's body made by a chain of motor-motifs:
where L : Λ → [0, 1] is the operator defining the opponent's resistance to injury. Here, we use a piecewise linear function increasing from 0 (null lethality) in the opponent's feet to 1 (highest lethality) in the opponent's neck, and decreasing again to 0.4 in the opponent's head.
• Versatility: It is the relative size (i.e., the relative cardinality) of the set of available attacks:
We note that all strategy features are defined over the point λ1 in the first order map M1. Finally, the compound fitness of a strategy is given by:
where the factors α define the bias between the strategy features. Such a bias depends on the subject's motivation. For example, if the combat comes to its end, the weights of imminence and lethality can be raised, whereas at the combat beginning one can maximize imminence and versatility.
3.3. Two-Step Parry-Riposte Strategies
Let us now illustrate how a complex combat strategy known as parry-riposte can be built by using the approach shown in Figure 4. In this case, the subject uses the strength of his foil to block the opponent's attack (parry), and then he begins a counter-attack (riposte) with the aim of winning the combat.
3.3.1. Optimization Over Two-Symbol Semantic Chains
We consider the initial situation shown in Figure 3A. The opponent takes a step forward and makes an offensive circular movement by his foil. As a response, the subject invokes the cognitive map corresponding to this situation (Figure 3C). In this case, however, we are interested in the defense movements only and hence select one of the points from the set (Figure 5A, green surface in the first map highlighted in red). This defines the parry step d1 = (λ1, n1) ∈ M1, with , similar to the defense movement shown in Figure 3D. However, now we consider different options for blocking the opponent's foil, i.e., trajectories ending at different green points of the map .
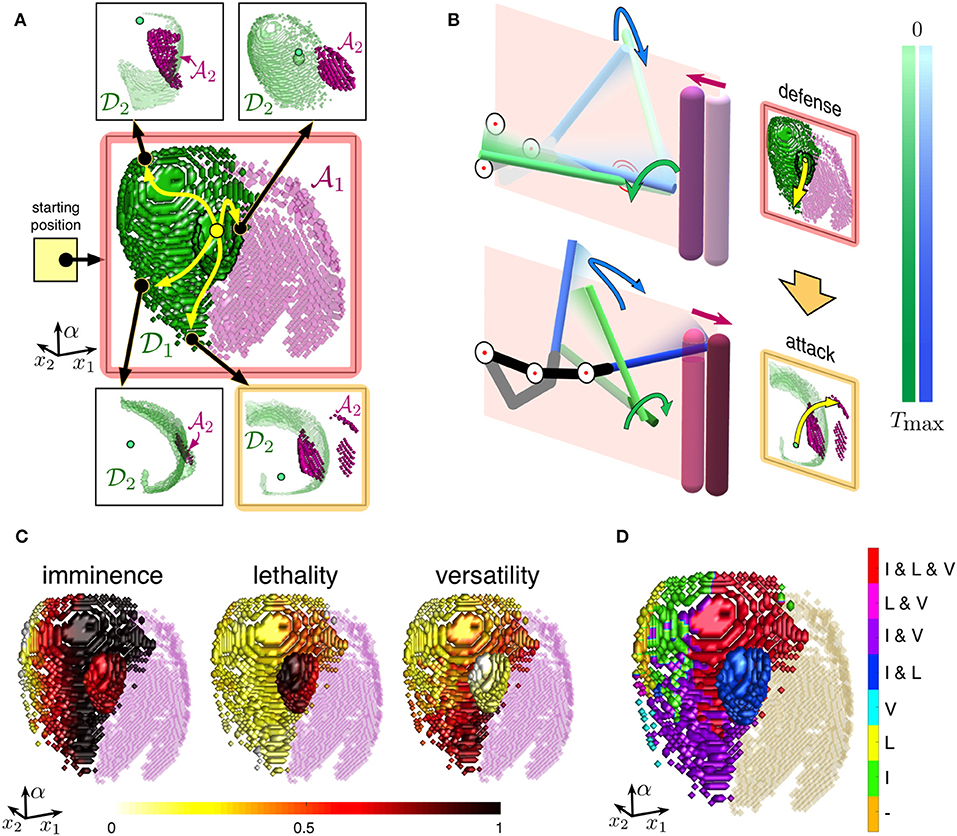
Figure 5. Semantic of parry-riposte strategies. (A) Strategies in the hand-space following Figure 4C (initial situation as in Figure 3). In the parry step, the subject uses a defensive movement d1 reaching some point λ1 in the set (green region). In the riposte step, the subject invokes one of the secondary maps and initiates an attack (pink points in ). (B) Implementation in the workspace of a strategy from the map highlighted in yellow in (A). First, the subject's foil deflects the opponent's foil (parry). Then, the attack action is executed (riposte). (C) Fitness of semantic strategies presented over the set . The color represents features of the defensive actions leading to: short/long attack trajectories (imminence), more/less dangerous attacks (lethality), and different/similar offensive actions (versatility). (D) Semantic meaning of different motor-motifs represented over the set . Color represents different combinations of the attributes (I, imminence; L, lethality; V, versatility).
Each of the defense movements gives rise to a new situation after the parry step (see Equation 21) and a secondary cognitive map (Figure 5A, see also Figure 4C). Then, the subject can select an attack movement, i.e., draw a path in the hand-space Λ to a pink point in one of the maps M2. Such a path defines a riposte step a2 = (λ2, n2), which ends with hitting the opponent's body by the subject's foil. Figure 5B illustrates the sequence of the subject's and opponent's actions in the workspace . First, the opponent takes a step forward and attacks. The subject deflects the opponent's attack, and the opponent takes a step back while the subject makes an offensive action and hits the opponent.
As above-discussed, the subject has a variety of two-symbol chains . We now can evaluate the fitness of each semantic chain for a given defensive movement d1 = (λ1, n1). Figure 5C shows the imminence, lethality, and versatility of different strategies. It is worth noting that the strategy features achieve their maxima at different parts of the set . Thus, as it frequently occurs in real combat, there is no global optimum, and the fencer should resort to a complex optimization, depending on his motivation. For illustration purpose, in Figure 5B, we have chosen the strategy maximizing the imminence and versatility with low lethality (Figure 5A, highlighted in yellow).
3.3.2. Linking Motor-Motifs to Semantic Meaning
The measures of the strategy fitness now can be used to define the semantic description of the strategies. We continue working with two-step actions as above and use the definition of motor-motifs. Then, each motor-motif is a single strategy, which generates certain fitness measures (Figure 5C).
Now, each point in the defensive set defines some motor-motif. If a particular fitness measure exceeds a threshold (set to 0.3 in simulations), then we link the motor-motif to the corresponding attribute. In our case, each motor-motif can have up to three attributes: I for imminence, L for lethality, and V for versatility. Figure 5D shows combinations of the attributes for different motor-motifs. Thus, the fencer can now get access to the semantic meaning of each action. Due to significant dimension reduction, such a meaning can be easily stored and retrieved on purpose.
3.4. Validation of Approach in Humanoid Robot
Let us illustrate the above-described theoretical approach in the developed humanoid robot (see section 2). We use again the parry-riposte combat situation shown in Figure 5. However, now we select another, more aggressive riposte strategy than shown in Figure 5B. This is achieved by checking the semantic meaning shown in Figure 5D and then by choosing the corresponding motor-motifs in Figure 5A.
As has been mentioned, the Avatar software allows emulating a combat situation in virtual reality. Figure 6A shows a series of snapshots of the Avatar. The Avatar first deflects the opponent's foil, and then conducts an effective attack and hits the opponent.
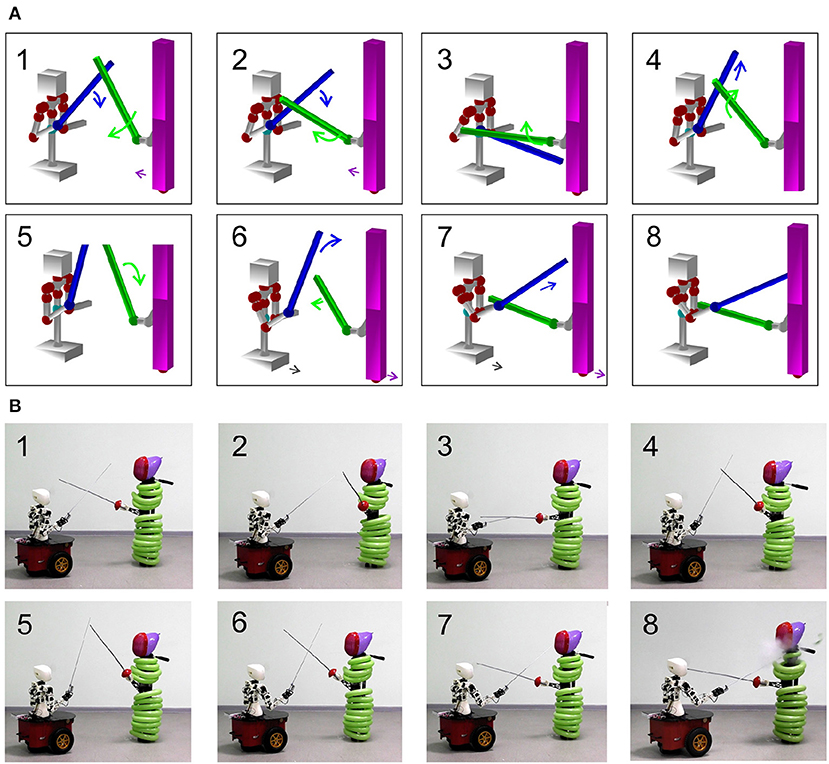
Figure 6. Experimental validation of a parry-riposte strategy. (A) Implementation of the strategy in virtual environment. (B) Same as in (A) but executed by the robot.
Finally, we implemented the same dynamics in the humanoid robot. Figure 6B illustrates the sequence of snapshots. The robot first makes a defense movement and then attacks the opponent. To get a simple marker of hitting the opponents by the subject's foil, we used balloons. In the last snapshots, one can see how one balloon explodes, which confirms a point scored by the robot in this combat situation.
4. Conclusions
The cognitive-motor skills exhibited by humans in fast dynamic situations are far beyond the abilities of modern humanoid robots. Object manipulation is one of the prominent examples widely observed in different sports. In this work, we have considered the combat game of fencing, which, besides fast manipulation, includes precise strategic planning. We have provided and experimentally validated a novel approach to building strategies on an abstract cognitive level. The procedure uses the theory of generalized cognitive maps generated in a configuration space, the so-called hand-space. We have shown how GCMs can be constructed in a discrete 3D lattice representing three degrees of freedom of an upper limb handling a foil. A neural network simulates the process of the parallel exploration of different movements of the fencer. It thus transforms the dynamic combat situation into a static 4D map encapsulating all relevant events.
The resulting 4D cognitive map can be readily used for planning actions. However, what is more important, it enables a possibility to construct multi-action strategies in an abstract semantic way. Different GCMs can be chained, aiming at human-like multilevel decision-making. Starting from an initial position of combat, the fencer can select one of the motor-motifs (a point in the corresponding GCM) for the next movement. In turn, this leads to a new situation, which is also described by a GCM. Such a secondary GCM provides a variety of subsequent actions. This way, the fencer generates a chain of symbols, e.g., (d1, a2, a3, d4, …) describing the sequence of defense and attack movements.
We then have introduced the fitness depicting each strategy (symbolic chain) in terms of the imminence (velocity of actions), lethality (effect over the opponent), and versatility (variety of available movements). Note that the fencer can use the strategy fitness to optimize his actions depending on the motivation (a higher level of cognition). For example, at the beginning of combat, the fencer can use imminence and versatility as main attributes, whereas, at the end, the lethality may be the goal. We then confirmed our theoretical modeling by using the robot Torso, which has 3DoF in its upper limbs. To gain versatility, we have developed an avatar of the robot, which enables close to real simulations of different fencing situations. The experimental results validated the approach.
Concluding, the GCM theory and its generalization to the semantic abstraction provide a functional bridge between straightforward cognition, dealing with direct interaction in the workspace, and abstract cognition, whose impact over the subject's behavior is less immediate but much more profound. The semantic level of strategy description presented here takes a step forward to the latter ambitious goal.
Data Availability Statement
The datasets generated for this study are available on request to the corresponding author.
Author Contributions
CC, JV-A, and VM contributed conception, design of the study, and the mathematical analysis. CC, JV-A, and SD-H performed numerical simulations. MK designed and developed the Avatar software. SL and IP developed the robot and performed experiments. AS-J performed the statistical analysis. VM wrote the manuscript. All authors contributed to the manuscript revision, read, and approved the submitted version.
Funding
This work was supported by the Russian Science Foundation (project 19-12-00394) and by the Spanish Ministry of Science, Innovation and Universities (grant FIS2017-82900-P).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The authors thank M. Shamshin and A. Zharinov for the help with building the Torso robot.
References
Aleotti, J., and Caselli, S. (2006). Robust trajectory learning and approximation for robot programming by demonstration. Robot. Auton. Syst. 54, 409–413. doi: 10.1016/j.robot.2006.01.003
Billard, A., and Kragicet, D. (2019). Trends and challenges in robot manipulation. Science 364:1149. doi: 10.1126/science.aat8414
Binder, J. R., and Desai, R. H. (2011). The neurobiology of semantic memory. Tren. Cogn. Sci. 15, 527–536. doi: 10.1016/j.tics.2011.10.001
Bladon, J. H., Sheehan, D. J., De Freitas, C. S., and Howard, M. W. (2019). In a temporally segmented experience hippocampal neurons represent temporally drifting context but not discrete segments J. Neurosci. 39, 6936–6952. doi: 10.1523/JNEUROSCI.1420-18.2019
Bouyarmane, K., Chappellet, K., Vaillant, J., and Kheddar, A. (2018). Quadratic programming for multirobot and task-space force control. IEEE Trans. Robot. 35, 64–77. doi: 10.1109/TRO.2018.2876782
Buzsaki, G., and Llinas, R. (2017). Space and time in the brain. Science 358, 482–485. doi: 10.1126/science.aan8869
Calvo Tapia, C., Makarov, V. A., and van Leeuwen, C. (2020). Basic principles drive self-organization of brain-like connectivity structure. Commun. Nonlin. Sci. Numer. Simulat. 82:105065. doi: 10.1016/j.cnsns.2019.105065
Calvo Tapia, C., Tyukin, I. Y., and Makarov, V. A. (2018a). Fast social-like learning of complex behaviors based on motor motifs. Phys. Rev. E 97:052308. doi: 10.1103/PhysRevE.97.052308
Calvo, C., Kastalskiy, I., Villacorta-Atienza, J. A., Khoruzhko, M., and Makarov, V. A. (2017). “Holistic model of cognitive limbs for dynamic situations,” in Proceedings of the International Congress of Neurotechnix (Funchal), 60–67. doi: 10.5220/0006586900600067
Calvo, C., Tyukin, I., and Makarov, V. A. (2019). Universal principles justify the existence of concept cells. arXiv:1912.02040.
Calvo, C., Villacorta-Atienza, J. A., Mironov, V., Gallego, V., and Makarov, V. A. (2016). Waves in isotropic totalistic cellular automata: Application to real-time robot navigation. Adv. Compl. Syst. 19, 1650012–1650018. doi: 10.1142/S0219525916500120
Calvo-Tapia, C., Villacorta-Atienza, J. A., Kastalskiy, I., Diez-Hermano, S., Sanchez-Jimenez, A., and Makarov, V. A. (2018b). “Cognitive neural network driving DoF-scalable limbs in time-evolving situations,” in International Joint Conference on Neural Networks (IJCNN) (Rio de Janeiro), 1–7. doi: 10.1109/IJCNN.2018.8489562
Choset, H., Hutchinson, S., Lynch, K., Kantor, G., Burgard, W., Kavraki, L., et al. (2005). Principles of Robot Motion: Theory, Algorithms, and Implementation. Cambridge, MA: The MIT Press.
Colome, A., and Torras, C. (2014). “Dimensionality reduction and motion coordination in learning trajectories with dynamic movement primitives,” in Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (Chicago, IL), 1414–1420.
Duminy, N., Nguyen, S. M., and Duhaut, D. (2016). “Strategic and interactive learning of a hierarchical set of tasks by the Poppy humanoid robot,” in IEEE International Conference on Development and Learning Epigenetic Robotics (Cergy-Pontoise), 204–209. doi: 10.1109/DEVLRN.2016.7846820
Gorban, A. N., Makarov, V. A., and Tyukin, I. Y. (2019). The unreasonable effectiveness of small neural ensembles in high-dimensional brain. Phys. Life Rev. 29, 55–88. doi: 10.1016/j.plrev.2018.09.005
Gorban, A. N., Makarov, V. A., and Tyukin, I. Y. (2020). High dimensional brain in high-dimensional world: blessing of dimensionality. Entropy. 22:82. doi: 10.3390/e22010082
Hong, W., and Slotine, J.-J. E. (1997). “Experiments in hand-eye coordination using active vision,” in Proceedings of the International Symposium on Exp. Robotics IV (Berlin; Heidelberg), 130–139. doi: 10.1007/BFb0035204
Jones, M. N., Willits, J., and Dennis, S. (2015). “Models of semantic memory,” in The Oxford Handbook of Computational and Mathematical Psychology, eds J. R. Busemeyer, Z. Wang, J. T. Townsend, and A. Eidels (New York, NY: Oxford University Press), 232–254. doi: 10.1093/oxfordhb/9780199957996.013.11
Kim, S., Shukla, A., and Billard, A. (2014). Catching objects in flight. IEEE Trans. Robot. 30, 1049–1065. doi: 10.1109/TRO.2014.2316022
Kraus, B. J., Robinson, R. J., White, J. A., Eichenbaum, H., and Hasselmo, M. E. (2013). Hippocampal “time cells”: time versus path integration. Neuron 78, 1090–101. doi: 10.1016/j.neuron.2013.04.015
Lapeyre, M., Rouanet, P., Grizou, J., Nguyen, S., Depraetre, F., Le Falher, A., et al. (2014). Poppy Project: Open-Source Fabrication of 3D Printed Humanoid Robot for Science, Education and Art. Nantes, 6. Available online at: https://hal.inria.fr/hal-01096338
Livesey, A. C., Wall, M. B., and Smith, A. T. (2007). Time perception: manipulation of task difficulty dissociates clock functions from other cognitive demands. Neuropsychologia 45, 321–331. doi: 10.1016/j.neuropsychologia.2006.06.033
Makarov, V. A., Calvo, C., Gallego, V., and Selskii, A. (2016). Synchronization of heteroclinic circuits through learning in chains of neural motifs. IFAC-PapersOnLine 49, 80–83. doi: 10.1016/j.ifacol.2016.07.986
Mason, M. T. (2018). Toward robotic manipulation. Annu. Rev. Control Rob. Auton. Syst. 1, 1–28. doi: 10.1146/annurev-control-060117-104848
Nguyen, A., Kanoulas, D., Caldwell, D. G., and Tsagarakis, N. G. (2016). “Detecting object affordances with convolutional neural networks,” in Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (Daejeon), 2765–2770. doi: 10.1109/IROS.2016.7759429
Noguchi, W., Iizuka, H., and Yamamoto, M. (2017). Cognitive map self-organization from subjective visuomotor experiences in a hierarchical recurrent neural network. Adapt. Behav. 25, 129–146. doi: 10.1177/1059712317711487
Patel, R. V., and Shadpey, F. (2005). Control of Redundant Manipulators: Theory and Experiments. Berlin; Heidelberg: Springer-Verlag.
Pot, E., Monceaux, J., Gelin, R., and Maisonnier, B. (2009). “Choregraphe: a graphical tool for humanoid robot programming,” in IEEE International Symposium on Robot and Human Interactive Communication (Toyama), 46–51. doi: 10.1109/ROMAN.2009.5326209
Ralph, M. A. L., Jefferies, E., Patterson, K., and Rogers, T. T. (2017). The neural and computational bases of semantic cognition. Nat. Rev. Neurosci. 18, 42–55. doi: 10.1038/nrn.2016.150
Riley, M., and Atkeson, C. G. (2002). Robot catching: towards engaging human-humanoid interaction. Auton. Robots 12, 119–128. doi: 10.1023/A:1013223328496
Schmidt, B., and Redish, A. (2013). Navigation with a cognitive map. Nature 497, 42–43. doi: 10.1038/nature12095
Shamsuddin, S., Ismail, L. I., Yussof, H., Ismarrubie Zahari, N., Bahari, S., Hashim, H., et al. (2011). “Humanoid robot NAO: review of control and motion exploration,” in IEEE International Conference on Control System, Computing and Engineering (Penang), 511–516. doi: 10.1109/ICCSCE.2011.6190579
Spong, M., Hutchinson, S., and Vidyasagar, M. (2006). Robot Modeling and Control. New York, NY: Wiley.
Sporns, O. (2011). The nonrandom brain: efficiency, economy, and complex dynamics. Front. Comput. Neurosci. 5:5. doi: 10.3389/fncom.2011.00005
Tatler, B., and Land, M. (2011). Vision and the representation of the surroundings in spatial memory. Philos. Trans. R. Soc. B 366, 596–610. doi: 10.1098/rstb.2010.0188
Thibaut, J. P., and Toussaint, L. (2010). Developing motor planning over ages. J. Exp. Child Psychol. 105, 116–129. doi: 10.1016/j.jecp.2009.10.003
Tyukin, I., Gorban, A., Calvo, C., Makarova, J., and Makarov, V. A. (2019). High-dimensional brain: a tool for encoding and rapid learning of memories by single neurons. Bull. Math. Biol. 81, 4856–4888. doi: 10.1007/s11538-018-0415-5
Villacorta-Atienza, J., Velarde, M. G., and Makarov, V. A. (2010). Compact internal representation of dynamic situations: neural network implementing the causality principle. Biol. Cybern. 103, 285–297. doi: 10.1007/s00422-010-0398-2
Villacorta-Atienza, J. A., Calvo Tapia, C., Diez-Hermano, S., Sanchez-Jimenez, A., Lobov, S., Krilova, N., et al. (2019). Static internal representation of dynamic situations evidences time compaction in human cognition. arXiv:1806.10428.
Villacorta-Atienza, J. A., Calvo, C., Lobov, S., and Makarov, V. A. (2017). Limb movement in dynamic situations based on generalized cognitive maps. Math. Modell. Nat. Phen. 12, 15–29. doi: 10.1051/mmnp/201712403
Villacorta-Atienza, J. A., Calvo, C., and Makarov, V. A. (2015). Prediction-for-compaction: navigation in social environments using generalized cognitive maps. Biol. Cybern. 109, 307–320. doi: 10.1007/s00422-015-0644-8
Villacorta-Atienza, J. A., and Makarov, V. A. (2013). Neural network architecture for cognitive navigation in dynamic environments. IEEE Trans. Neur. Net. Learn. Syst. 24, 2075–2087. doi: 10.1109/TNNLS.2013.2271645
Keywords: cognitive maps, manipulation of objects, dynamical systems, semantic description, neural networks
Citation: Calvo Tapia C, Villacorta-Atienza JA, Díez-Hermano S, Khoruzhko M, Lobov S, Potapov I, Sánchez-Jiménez A and Makarov VA (2020) Semantic Knowledge Representation for Strategic Interactions in Dynamic Situations. Front. Neurorobot. 14:4. doi: 10.3389/fnbot.2020.00004
Received: 31 October 2019; Accepted: 14 January 2020;
Published: 13 February 2020.
Edited by:
Witali L. Dunin-Barkowski, Scientific Research Institute of System Analysis (RAS), RussiaReviewed by:
Boris Gutkin, École Normale Supérieure, FranceAlexander N. Pisarchik, Polytechnic University of Madrid, Spain
Copyright © 2020 Calvo Tapia, Villacorta-Atienza, Díez-Hermano, Khoruzhko, Lobov, Potapov, Sánchez-Jiménez and Makarov. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Valeri A. Makarov, vmakarov@ucm.es