
Abstract
Programming screencasts are growing in popularity and are often used by developers as a learning source. The source code shown in these screencasts is often not available for download or copy-pasting. Without having the code readily available, developers have to frequently pause a video to transcribe the code. This is time-consuming and reduces the effectiveness of learning from videos. Recent approaches have applied Optical Character Recognition (OCR) techniques to automatically extract source code from programming screencasts. One of their major limitations, however, is the extraction of noise such as the text information in the menu, package hierarchy, etc. due to the imprecise approximation of the code location on the screen. This leads to incorrect, unusable code. We aim to address this limitation and propose an approach to significantly improve the accuracy of code localization in programming screencasts, leading to a more precise code extraction. Our approach uses a Convolutional Neural Network to automatically predict the exact location of code in an image. We evaluated our approach on a set of frames extracted from 450 screencasts covering Java, C#, and Python programming topics. The results show that our approach is able to detect the area containing the code with 94% accuracy and that our approach significantly outperforms previous work. We also show that applying OCR on the code area identified by our approach leads to a 97% match with the ground truth on average, compared to only 31% when OCR is applied to the entire frame.











Similar content being viewed by others



Notes
“Objectness” indicates if a box contains an object.
Fig. 7 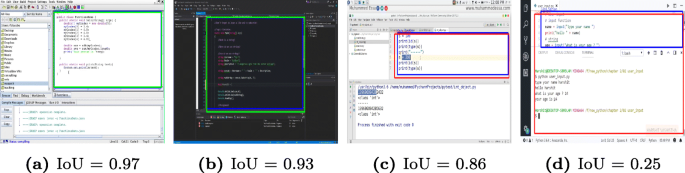
Ground truth bounding box (in blue) compared to predicted bounding box (in green) for correct prediction or (in red) for incorrect prediction

References
Alahmadi M, Hassel J, Parajuli B, Haiduc S, Kumar P (2018) Accurately predicting the location of code fragments in programming video tutorials using deep learning. In: Proceedings of the 14th International Conference on Predictive Models and Data Analytics in Software Engineering - PROMISE’18. https://doi.org/10.1145/3273934.3273935. http://dl.acm.org/citation.cfm?doid=3273934.3273935. ACM Press, Oulu, pp 2–11
Bao L, Li J, Xing Z, Wang X, Xia X, Zhou B (2017) Extracting and analyzing time-series hci data from screen-captured task videos. Empir Softw Eng 22 (1):134–174
Bao L, Xing Z, Xia X, Lo D (2018) VT-Revolution: Interactive programming video tutorial authoring and watching system. IEEE Transactions on Software Engineering, https://doi.org/10.1109/TSE.2018.2802916. http://ieeexplore.ieee.org/document/8283605/
Brandt J, Guo PJ, Lewenstein J, Dontcheva M, Klemmer SR (2009) Two studies of opportunistic programming: Interleaving web foraging, learning, and writing code. In: Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, CHI ’09. https://doi.org/10.1145/1518701.1518944. ACM, New York, pp 1589–1598
Canny J (1986) A computational approach to edge detection. Ieee Transactions on Pattern Analysis and Machine Inteligence, pp 679–698
Dai J, Li Y, He K, Sun J (2016) R-FCN: Object detection via region-based fully convolutional networks. arXiv:160506409 [cs]
Ellmann M, Oeser A, Fucci D, Maalej W (2017) Find, understand, and extend development screencasts on youtube. In: Proceedings of the 3rd ACM SIGSOFT International Workshop on Software Analytics, ACM, pp 1–7
Escobar-Avila J, Parra E, Haiduc S (2017) Text retrieval-based tagging of software engineering video tutorials. In: Proceedings of the 39th IEEE/ACM International Conference on Software Engineering (ICSE’17). IEEE, Buenos Aires, pp 341–343
Everingham M, Van Gool L, Williams CK, Winn J, Zisserman A (2010) The pascal visual object classes (voc) challenge. Int J Comput Vis 88(2):303–338
Felzenszwalb PF, Huttenlocher DP (2004) Efficient graph-based image segmentation. Int J Comput Vis 59(2):167–181
Girshick R (2015) Fast R-CNN. arXiv:150408083 [cs]
Girshick R, Donahue J, Darrell T, Malik J (2013) Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv:13112524 [cs]
Grzywaczewski A, Iqbal R (2012) Task-specific information retrieval systems for software engineers. J Comput Syst Sci 78(4):1204–1218
He K, Zhang X, Ren S, Sun J (2015) Deep residual learning for image recognition. arXiv:151203385 [cs]
Hu W, Huang Y, Li W, Zhang F, Li H (2015) Deep convolutional neural networks for hyperspectral image classification. J Sensors 2015:258,619–258,619. https://doi.org/10.1155/2015/258619
Huang J, Rathod V, Sun C, Zhu M, Korattikara A, Fathi A, Fischer I, Wojna Z, Song Y, Guadarrama S, et al. (2017) Speed/accuracy trade-offs for modern convolutional object detectors. In: IEEE CVPR, vol 4
Ioffe S, Szegedy C (2015) Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv:150203167 [cs]
Jaccard P (1912) The distribution of the flora in the alpine zone. 1. New Phytologist 11(2):37–50
Juan L, Gwun O (2009) A comparison of sift, pca-sift and surf. International Journal of Image Processing (IJIP) 3(4):143–152
Khandwala K, Guo PJ (2018) codemotion: expanding the design space of learner interactions with computer programming tutorial videos. In: Proceedings of the Fifth Annual ACM Conference on Learning at Scale - L@S ’18. https://doi.org/10.1145/3231644.3231652. http://dl.acm.org/citation.cfm?doid=3231644.3231652. ACM Press, London, pp 1–10
Kim KH, Hong S, Roh B, Cheon Y, Park M (2016) PVANET: Deep but lightweight neural networks for real-time object detection. arXiv:160808021
LeCun Y, Haffner P, Bottou L, Bengio Y (1999) Object recognition with gradient-based learning. In: Shape, Contour and Grouping in Computer Vision. Springer, London, pp 319–345. http://dl.acm.org/citation.cfm?id=646469.691875
Lin TY, Maire M, Belongie S, Bourdev L, Girshick R, Hays J, Perona P, Ramanan D, Zitnick CL, Dollár P (2014) Microsoft coco: Common objects in context. arXiv:14050312 [cs]
Lin TY, Dollár P, Girshick R, He K, Hariharan B, Belongie S (2017) Feature pyramid networks for object detection. In: CVPR, vol 2
Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu CY, Berg AC (2016) SSD: Single shot multibox detector. 9905:21–37, arXiv:151202325 [cs], https://doi.org/10.1007/978-3-319-46448-0_2
Lowe DG (1999) Object recognition from local scale-invariant features. In: Proceedings of the Seventh IEEE International Conference on Computer Vision, vol 2, IEEE, pp 1150–1157. https://doi.org/10.1109/ICCV.1999.790410. http://ieeexplore.ieee.org/document/790410/
Lowe DG (2004) Distinctive image features from Scale-Invariant keypoints. Int J Comput Vis 60(2):91–110
MacLeod L, Storey MA, Bergen A (2015) Code, camera, action: How software developers document and share program knowledge using youtube. In: Proceedings of the 23rd IEEE International Conference on Program Comprehension (ICPC’15), Florence, pp 104–114
MacLeod L, Bergen A, Storey MA (2017) Documenting and sharing software knowledge using screencasts. Empir Softw Eng 22(3):1478–1507. https://doi.org/10.1007/s10664-017-9501-9. https://link.springer.com/article/10.1007/s10664-017-9501-9
Mikolajczyk K, Schmid C (2005) A performance evaluation of local descriptors. IEEE Transactions on Pattern Analysis and Machine Intelligence 27(10):1615–1630
Moslehi P, Adams B, Rilling J (2018) Feature location using crowd-based screencasts. In: Proceedings of the 15th International Conference on Mining Software Repositories - MSR ’18. https://doi.org/10.1145/3196398.3196439. http://dl.acm.org/citation.cfm?doid=3196398.3196439. ACM Press, Gothenburg, pp 192–202
Ott J, Atchison A, Harnack P, Bergh A, Linstead E (2018a) A deep learning approach to identifying source code in images and video. In: Proceedings of the 15th IEEE/ACM Working Conference on Mining Software Repositories, pp 376–386
Ott J, Atchison A, Harnack P, Best N, Anderson H, Firmani C, Linstead E (2018b) Learning lexical features of programming languages from imagery using convolutional neural networks
Parra E, Escobar-Avila J, Haiduc S (2018) Automatic tag recommendation for software development video tutorials. In: Proceedings of the 26th Conference on Program Comprehension, ACM, pp 222–232
Poché E, Jha N, Williams G, Staten J, Vesper M, Mahmoud A (2017) Analyzing user comments on youtube coding tutorial videos. In: Proceedings of the 25th International Conference on Program Comprehension, IEEE Press, pp 196–206
Ponzanelli L, Bavota G, Mocci A, Di Penta M, Oliveto R, Hasan M, Russo B, Haiduc S, Lanza M (2016a) Too long; didn’t watch!: Extracting relevant fragments from software development video tutorials. ACM Press, pp 261–272, https://doi.org/10.1145/2884781.2884824. http://dl.acm.org/citation.cfm?doid=2884781.2884824
Ponzanelli L, Bavota G, Mocci A, Di Penta M, Oliveto R, Russo B, Haiduc S, Lanza M (2016b) codetube: Extracting relevant fragments from software development video tutorials. In: Proceedings of the 38th ACM/IEEE International Conference on Software Engineering (ICSE’16). ACM, Austin, pp 645–648
Ponzanelli L, Bavota G, Mocci A, Oliveto R, Di Penta M, Haiduc SC, Russo B, Lanza M (2017) Automatic identification and classification of software development video tutorial fragments. IEEE Transactions on Software Engineering. https://doi.org/10.1109/TSE.2017.2779479. http://ieeexplore.ieee.org/document/8128506/
Qian N (1999) On the momentum term in gradient descent learning algorithms. Neural Netw 12(1):145–151
Redmon J, Divvala S, Girshick R, Farhadi A (2015) You only look once: Unified, real-time object detection. arXiv:150602640 [cs]
Ren S, He K, Girshick R, Sun J (2015) Faster R-CNN: Towards real-time object detection with region proposal networks. arXiv:150601497 [cs]
Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S, Huang Z, Karpathy A, Khosla A, Bernstein M et al (2015) Imagenet large scale visual recognition challenge. Int J Comput Vis 115(3):211–252
Shrivastava A, Gupta A (2016) Contextual priming and feedback for faster R-CNN. In: Leibe B, Matas J, Sebe N, Welling M (eds) Computer Vision – ECCV 2016. https://doi.org/10.1007/978-3-319-46448-0_20. http://link.springer.com/10.1007/978-3-319-46448-0_20, vol 9905. Springer International Publishing, Cham, pp 330–348
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. arXiv:14091556 [cs]
Storey MA, Singer L, Cleary B, Figueira Filho F, Zagalsky A (2014) The (R) Evolution of social media in software engineering. In: Proceedings of the on Future of Software Engineering, FOSE 2014. https://doi.org/10.1145/2593882.2593887. ACM, New York, pp 100–116
Sun Y (2015) A comparative evaluation of string similarity metrics for ontology alignment. Journal of Information and Computational Science 12(3):957–964. https://doi.org/10.12733/jics20105420. http://www.joics.com/publishedpapers/2015_12_3_957_964.pdf
Szegedy C, Ioffe S, Vanhoucke V, Alemi A (2016) Inception-v4, inception-resnet and the impact of residual connections on learning. arXiv:160207261 [cs]
Thummalapenta S, Cerulo L, Aversano L, Di Penta M (2010) An empirical study on the maintenance of source code clones. Empir Softw Eng 15(1):1–34. https://doi.org/10.1007/s10664-009-9108-x. http://link.springer.com/10.1007/s10664-009-9108-x
Uijlings JR, Van De Sande KE, Gevers T, Smeulders AW (2013) Selective search for object recognition. Int J Comput Vis 104(2):154–171
Wang Z, Bovik AC, Sheikh HR, Simoncelli EP et al (2004) Image quality assessment: from error visibility to structural similarity. IEEE Trans Image Process 13 (4):600–612
Yadid S, Yahav E (2016) Extracting code from programming tutorial videos. In: Proceedings of the 6th ACM International Symposium on New Ideas, New Paradigms, and Reflections on Programming and Software (Onward!’16). ACM, Amsterdam, pp 98–111
Zhao D, Xing Z, Chen C, Xia X, Li G, Tong SJ (2019) Actionnet: Vision-based workflow action recognition from programming screencasts. In: Proceedings of the 41st ACM/IEEE International Conference on Software Engineering (ICSE’19)
Zimmermann T, Premraj R, Zeller A (2007) Predicting defects for eclipse. In: Proceedings of the 3rd IEEE International Workshop on Predictor Models in Software Engineering (PROMISE’07), Washington, pp 9–15
Acknowledgements
Mohammad Alahmadi was sponsored in part by the University of Jeddah. Abdulkarim Khormi was sponsored in part by Jazan University. Sonia Haiduc was supported in part by the National Science Foundation under Grant No. 1846142.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by: Shane McIntosh, Leandro L. Minku, Ayşe Tosun, Burak Turhan
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article belongs to the Topical Collection: Predictive Models and Data Analytics in Software Engineering (PROMISE)
Rights and permissions
About this article

Cite this article
Alahmadi, M., Khormi, A., Parajuli, B. et al. Code Localization in Programming Screencasts. Empir Software Eng 25, 1536–1572 (2020). https://doi.org/10.1007/s10664-019-09759-w
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10664-019-09759-w