
Abstract
We examine the utility of multiple channels of communication in wireless networks under the SINR model of interference. The central question is whether the use of multiple channels can result in linear speedup, up to some fundamental limit. We answer this question affirmatively for the data aggregation problem, perhaps the most fundamental problem in sensor networks. To achieve this, we form a hierarchical structure of independent interest, and illustrate its versatility by obtaining a new algorithm with linear speedup for the node coloring problem.
Similar content being viewed by others


Notes
A metric space is said to be fading if the path loss exponent \(\alpha \) is strictly greater than the doubling dimension of the metric. This is a generalization of the standard requirement of \(\alpha >2\) in the two-dimensional Euclidean space, as the two-dimensional Euclidean space has a doubling dimension of 2. For more details on fading metric, see [12].
References
An, M.K., Lam, N.X., Huynh, D.T., Nguyen, T.N.: Minimum latency data aggregation in the physical interference model. Comput. Commun. 35(18), 2175–2186 (2012)
Bodlaender, M.H., Halldórsson, M.M., Mitra, P.: Connectivity and aggregation in multihop wireless networks. In: PODC. ACM, pp. 355–364 (2013)
Cole, R., Vishkin, U.: Deterministic coin tossing with applications to optimal parallel list ranking. Inf. Control 70(1), 32–53 (1986)
Daum, S., Ghaffari, M., Gilbert, S., Kuhn, F., Newport, C.: Maximal independent sets in multichannel radio networks. In: PODC, pp. 335–344 (2013)
Daum, S., Gilbert, S., Kuhn, F., Newport, C.: Leader election in shared spectrum radio networks. In: PODC, pp. 215–224 (2012)
Daum, S., Gilbert, S., Kuhn, F., Newport, C.: Broadcast in the ad hoc SINR model. In: DISC, pp. 358–372 (2013)
Daum, S., Kuhn, F., Newport, C.: Efficient symmetry breaking in multi-channel radio networks. In: DISC, pp. 238–252 (2012)
Derbel, B., Talbi, E.: Distributed node coloring in the SINR model. In: ICDCS, pp. 708–717 (2010)
Dolev, S., Gilbert, S., Khabbazian, M., Newport, C.: Leveraging channel diversity to gain efficiency and robustness for wireless broadcast. In: DISC, pp. 252–267 (2011)
Du, H., Zhang, Z., Wu, W., Wu, L., Xing, K.: Constant-approximation for optimal data aggregation with physical interference. J. Global Optim. 56(4), 1653–1666 (2013)
Goussevskaia, O., Moscibroda, T., Wattenhofer, R.: Local broadcasting in the physical interference model. In: DIALM-POMC’08, pp. 35–44 (2008)
Halldórsson, M.M.: Wireless scheduling with power control. ACM Trans. Algorithms 9(1), 7:1–7:20 (2012)
Halldórsson, M.M., Mitra, P.: Distributed connectivity of wireless networks. In: PODC (2012)
Halldórsson, M.M., Mitra, P.: Wireless connectivity and capacity. In: SODA. SIAM, pp. 516–526 (2012)
Hobbs, N., Wang, Y., Hua, Q.-S., Yu, D., Lau, F.: Deterministic distributed data aggregation under the SINR model. In: TAMC’12, pp. 385–399 (2012)
Jurdzinski, T., Kowalski, D., Rozanski, M., Stachowiak, G.: Distributed randomized broadcasting in wireless networks under the SINR model. In: DISC, pp. 373–387 (2013)
Jurdzinski, T., Kowalski, D., Rozanski, M., Stachowiak, G.: On the impact of geometry on ad hoc communication in wireless networks. In: PODC’14 (2014)
Jurdzinski, T., Kowalski, D.R.: Distributed backbone structure for algorithms in the SINR model of wireless networks. In: DISC, pp. 106–120 (2012)
Jurdzinski, T., Kowalski, D.R., Stachowiak, G.: Distributed deterministic broadcasting in uniform-power ad hoc wireless networks. In: FCT’13, pp. 195–209 (2013)
Li, H., Hua, Q.-S., Wu, C., Lau, F.: Minimum-latency aggregation scheduling in wireless sensor networks under physical interference model. In: MSWiM’10, pp. 360–367 (2010)
Li, X.-Y., Xu, X., Wang, S., Tang, S., Dai, G., Zhao, J., Qi, Y.: Efficient data aggregation in multi-hop wireless sensor networks under physical interference model. In: MASS’09, pp. 353–362 (2009)
Moscibroda, T., Wattenhofer, R.: The complexity of connectivity in wireless networks. In: INFOCOM, pp. 1–13 (2006)
Moscibroda, T., Wattenhofer, R.: Coloring unstructured radio networks. Distrib. Comput. 21(4), 271–284 (2008)
Pei, G., Vullikanti, A.K.S.: Distributed approximation algorithms for maximum link scheduling and local broadcasting in the physical interference model. In: INFOCOM (2013)
Scheideler, C., Richa, A., Santi, P.: An \(O(\log N)\) dominating set protocol for wireless ad-hoc networks under the physical interference model. In: MobiHoc’08, pp. 91–100 (2008)
Schneider, J., Wattenhofer, R.: Coloring unstructured wireless multi-hop networks. In: PODC, pp. 210–219 (2009)
Wan, P.-J., Huang, S. C.-H., Wang, L., Wan, Z., Jia, X.: Minimum-latency aggregation scheduling in multihop wireless networks. In: MobiHoc’09, pp. 185–194 (2009)
Xu, X., Li, M., Mao, X., Tang, S., Wang, S.: A delay-efficient algorithm for data aggregation in multihop wireless sensor networks. IEEE Trans. Parallel Distrib. Syst. 22(1), 163–175 (2011)
Yu, B., Li, J., Li, Y.: Distributed data aggregation scheduling in wireless sensor networks. In: INFOCOM’09, pp. 2159–2167 (2009)
Yu, D., Hua, Q.-S., Wang, Y., Tan, H., Lau, F.: Distributed multiple-message broadcast in wireless ad-hoc networks under the SINR model. In: SIROCCO’12, pp. 111–122 (2012)
Yu, D., Hua, Q.-S., Wang, Y., Yu, J., Lau, F.: Efficient distributed multiple-message broadcasting in unstructured wireless networks. In: INFOCOM’13, pp. 2427–2435 (2013)
Yu, D., Wang, Y., Hua, Q.-S., Lau, F.: Distributed (\(\Delta \)+1)-coloring in the physical model. In: ALGOSENSORS’11, pp. 145–160 (2011)
Yu, D., Wang, Y., Yan, Y., Yu, J., Lau, F.: Speedup of information exchange using multiple channels in wireless ad hoc networks. In: INFOCOM’15 (2015)
Acknowledgements
Partially supported by National Key Research and Development Program of China under Grant No. 2016QY02D0302, Iceland Research Foundation Grants 120032011, 152679-051, and 174484-051, National Natural Science Foundation of China Grants 61602195, Natural Science Foundation of Hubei Province 2017CFB301. Preliminary version appeared in PODC 2015.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix A: Proof of Lemma 3
Proof
(Proof of Lemma 3) We divide the proof into two parts: we first compute the interference experienced by every node \(u\in Q_F\cap E_v^{R}\) caused by nodes outside the region \(E_v^{\rho R}\), where \(\rho \ge 1\) is a constant that will be determined later; and we then consider the probability that there are no other transmitters in \(Q_F\cap E_v^{\rho R}\).
We first compute the interference experienced by u that is caused by nodes outside \(E_v^{\rho R}\). Let \(C_t\) be the ring with distance from v in the range \([t\rho R,(t+1)\rho R)\) for \(t\ge 1\). Without confusion, \(C_t\) is also used to denote the set of nodes in \(C_t\) that operate on F. Let \(M_t\) be maximal R-independent set in \(C_t\). Hence, any pair of nodes in \(M_t\) are separated by a distance at least R. Because disks \(E_w^{R/2}\) for \(w\in M_t\) are disjoint, an area argument implies that \(|M_t|\le 4(2t+1)\rho (\rho +1)\).
Denote by T the set of nodes outside \(E_v^{\rho R}\) that select the same channel and transmit simultaneously with v. Then, we bound the expected interference \(I_u\) experienced by u caused by nodes in T as follows.
The last inequality holds by setting \(\rho \ge \left( \frac{48\cdot 2^\alpha N\beta R_T^{\alpha }\psi }{R^\alpha }\cdot \frac{\alpha -1}{\alpha -2}\right) ^{\frac{1}{\alpha -2}}\cdot (\frac{P}{\beta R^{\alpha }}-N)^{-1/(\alpha -2)}\). Using Markov inequality, with probability at least \(\frac{1}{2}\), \(I_u\) is at most \(\frac{P}{\beta R^{\alpha }}-N\).
We next compute the probability that there are no other transmitters in \(E_v^{\rho R}\). By standard argument, \(E_v^{\rho R}\) can be covered with at most \((2\rho +1)^2\) disks of radius R. Since by assumption, the sum of the transmission probabilities in each disk is at most \(\psi \), the sum of transmission probabilities in \(E_v^{\rho R}\) is at most \((2\rho +1)^2 \psi \). The probability of the event A that there are no other transmitters in \(Q_F\cap E_v^{\rho R}\) can then be bounded below by:
Setting \(\kappa =\frac{1}{2}\cdot (1/4)^{(2\rho +1)^2\psi }\in \varOmega (1)\), we get that with probability \(\kappa \), the interference at every node \(u\in Q_F\cap E_v^{\rho R}\) is at most \(\frac{P}{\beta R^{\alpha }}-N\). By the SINR condition, u will then receive the message of v. \(\square \)
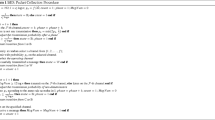
Appendix B: Dominating set algorithm
For completeness, we introduce the dominating set algorithm, the TWIN protocol, given by Scheideler et al. [25].
In the TWIN protocol, a node can either be inactive or active, and active nodes are either singles or twins, as will be explained later. The active nodes eventually converge to a dominating set. Each round of the TWIN protocol consists of three stages. In Stage 1, the active twins send out an ACTIVE signal with a certain probability so that inactive nodes or active singles can learn about active twins in their vicinity. In Stage 2, those nodes v that have not yet found an active twin in their vicinity probe the wireless medium and adjust their probabilities \(p_v\) so that in most rounds the contention within the transmission range of any node is constant bounded. In Stage 3, the non-twin nodes that were able to receive each other’s signal in Stage 2 acknowledge this to each other to be sure to form active twins. In order to become an active single, each node v maintains a counter \(acc(v)\ge 0\). Each time \(p_v=\hat{p}\), the maximum transmission probability a node can have, it sets \(acc(v) :=acc(v) + 4\), and each time \(p_v <\hat{p}\), it sets \(acc(v) := \max \{acc(v)-1,0\}\). A node is an active single as long as \(acc(v) > 0\). The details of each stage is given as follows. Initially, all nodes are inactive and \(acc(v) = 0\) for every node v. The probability \(p_v\) may be set to any value x with \(0 < x\le \hat{p}\). Let \(T'_s=(P/\rho ' R_T^\alpha )\), where P is the transmission power of nodes, \(\rho '\) is a small constant in (0,1), and \(R_T\) is the transmission range of nodes.
-
Stage 1: Announcing active twins
This stage consists of one time slot. In that time slot, each active twin v decides with probability 1/D to send out an ACTIVE signal, where the constant D is an upper bound on the maximum density of twins determined in the analysis. Each inactive node or active single v that receives an ACTIVE signal from a r-neighbor stops executing the protocol (since it is covered) and sets \(acc(v) := 0\) (i.e., becomes inactive).
-
Stage 2: Guessing the right density
This stage consists of two time slots. Each inactive node or active single v still participating in the protocol chooses one of the two time slots of this stage uniformly at random, say, slot s. For slot s, v decides with probability \(p_v\) to send a PING signal. If v sends a PING signal, it senses the wireless channel with threshold \(T'_s\) in the alternative slot, \(\bar{s}\). Otherwise, it senses the wireless channel with threshold \(T'_s\) in both slots. If it does not sense anything in either case, it sets \(p_v := \min \{(1 + \gamma )p_v, \hat{p}\}\), and otherwise it sets \(p_v := (1 + \gamma )^{-1}p_v\) for some constants \(\hat{p}<1\) and \(0< \gamma <1\). Whereas \(\gamma \) may be set to any constant value, the analysis requires that \(\hat{p}\) to be a small enough constant. If \(p_v =\hat{p}\), then \(acc(v) :=acc(v)+4\), (i.e., v becomes or remains an active single) and otherwise \(acc(v) := \max \{acc(v)-1,0\}\).
-
Stage 3: Forming new twins
This stage consists of two time slots. Every inactive node or active single v that sent a PING signal in some slot s and received a PING signal in the alternative slot \(\bar{s}\) does the following. It sends an ACK signal in slot s of this stage and listens to the wireless channel in slot \(\bar{s}\) of this stage. If it receives an ACK signal in slot \(\bar{s}\), it becomes an active twin.
With the above algorithm, it is shown that in any interval of \(\varTheta (\log n)\) rounds, for each node v, the contention in the vicinity and the interference from faraway nodes are bounded in most rounds. In this case, there will be a constant probability ensuring that an active twin appears in its vicinity in each of these rounds. Hence, at the end of the interval, either v joins an active twin or an active twin makes it inactive, with a high probability guarantee. Because each active twin can make all nodes within the transmission range stop executing the algorithm, the conclusion of constant density then follows. Formally, the following result was obtained in [25].
Theorem 4
The TWIN protocol can compute a dominating set of constant density in \(O(\log n)\) rounds with high probability.
Appendix C: Cluster size approximation with small \({{\hat{\varvec{\varDelta }}}}\)
When the contention is known to be small relative to the number of channels, we can reduce the time complexity for computing the cluster size. Here we consider the case that \({{\hat{\varDelta }}}\le \mathcal {F}\log ^{c}n\) for some constant \(c\ge 1\).
Algorithm For each cluster \(C_v\), the algorithm consists of four procedures:
1. Initially, each dominatee in \(C_v\) selects a channel from \(\mathcal {F}\) uniformly at random. On each channel, the nodes selecting the channel elect a leader by executing the ruling-set algorithm given in Sect. 4. This procedure consists of \(\gamma _3\ln n\) rounds, where \(\gamma _3\) is set to be a sufficiently large constant such that there are enough rounds for the execution of the algorithm in Sect. 4.
2. On each channel, nodes execute the CSA Algorithm with \({{\hat{\varDelta }}} = \gamma _3\ln ^cn\), where the leader functions as the dominator on the channel.
3. The leaders aggregate the number of nodes that selected the channels they dominate. This procedure consists of \(O(\log \mathcal {F})\) rounds. In particular, denote by \(U_v=\{x_1,\ldots ,x_\mathcal {F}\}\) the set of leaders in cluster \(C_v\). Note that there may be some channels without nodes selecting it and thus without leaders elected on them. Hence, there may be some nodes \(x_i\) missing. For each channel that does not have nodes, we add an auxiliary node, and it will be introduced how to deal with these auxiliary nodes in the aggregation process.
We first construct a binary tree on these \(\mathcal {F}\) nodes rooted at the dominator using the same manner as the reporter tree construction in Sect. 5.2. Then we use the data aggregation algorithm on the reporter tree given in Sect. 6 to aggregate the number of nodes to the dominator. Specifically, we need to handle here the auxiliary nodes. The solution is to divide each slot in each round into two sub-slots (recall that there are two slots in each round for the data aggregation on reporter trees), and make a parent send the ack message when it receives a message from its children. For each node \(x_j\) transmits, if it does not receive the ack message from its parent, which means that its parent is an auxiliary node, \(x_j\) will function as its parent in the subsequent aggregation process.
4. Finally, in a single round, v broadcasts the estimate of the cluster size to its dominatees on the first channel.
Analysis
Proof of Lemma 11 Consider a cluster \(C_v\). We analyze the four procedures one by one. We first bound the number of nodes operating on each channel in the first procedure.
Claim
For a cluster \(C_v\), in the first procedure, there are at most \(2\ln ^c n\) nodes on each channel with probability \(1-n^{-2}\).
Proof
Because dominatees select channels uniformly at random, the expected number of dominatees selecting each channel is at most \(\ln ^cn\). Consider a channel F. Using Chernoff bound (3), we get that the number of dominatees selecting F is at most twice the expectation, with probability \(1-n^{-3}\). By the union bound on all channels, the result follows. \(\square \)
A channel F is nonempty with respect to a cluster \(C_v\) if there are dominatees in \(C_v\) selecting it in the first procedure. Using a similar argument for proving Lemma 13, we have the following result for the first procedure.
Claim
For each cluster and each nonempty channel F, exactly one leader is elected on F in \(O(\log n)\) rounds, with probability \(1-n^{-2}\).
Using a similar argument for proving Lemma 10, we have the following result for the second procedure.
Claim
Each leader in each cluster can get an absolute constant approximation of the number of dominatees selecting its channel in \(O(\log n\log \log n)\) rounds, with probability \(1-n^{-2}\).
By Lemma 8, a node will receive an ack message after it sends a message to its parent if its parent is not an auxiliary node. Hence, the auxiliary nodes will not affect the aggregation process in the third procedure. Hence, we have the following result.
Claim
For a cluster \(C_v\), the estimates of leaders will be aggregated to the dominator v in \(O(\log \mathcal {F})\) rounds.
After the estimates of leaders are aggregated to the dominator, the dominator v will get a constant approximation of the cluster size by Claim 1. Then in the fourth procedure, v can send the estimate of the cluster size to all dominatees by Lemma 8. Adding the time used in each procedure, each node in cluster \(C_v\) will get a constant approximation of the cluster size in \(O(\log n\log \log n)\) rounds with probability \(1-O(n^{-2})\). The result is then proved by the union bound. \(\square \)
Rights and permissions
About this article

Cite this article
Halldórsson, M.M., Wang, Y. & Yu, D. Leveraging multiple channels in ad hoc networks. Distrib. Comput. 32, 159–172 (2019). https://doi.org/10.1007/s00446-018-0329-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00446-018-0329-3