
Abstract
Single image super resolution aims to enhance image quality with respect to spatial content, which is a fundamental task in computer vision. In this work, we address the task of single frame super resolution with the presence of image degradation, e.g., blur, haze, or rain streaks. Due to the limitations of frame capturing and formation processes, image degradation is inevitable, and the artifacts would be exacerbated by super resolution methods. To address this problem, we propose a dual-branch convolutional neural network to extract base features and recovered features separately. The base features contain local and global information of the input image. On the other hand, the recovered features focus on the degraded regions and are used to remove the degradation. Those features are then fused through a recursive gate module to obtain sharp features for super resolution. By decomposing the feature extraction step into two task-independent streams, the dual-branch model can facilitate the training process by avoiding learning the mixed degradation all-in-one and thus enhance the final high-resolution prediction results. We evaluate the proposed method in three degradation scenarios. Experiments on these scenarios demonstrate that the proposed method performs more efficiently and favorably against the state-of-the-art approaches on benchmark datasets.











Similar content being viewed by others
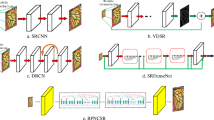


Notes
Since the pre-trained model of the PFFNet is not available, we train the network directly on the RESIDE dataset and achieve quantitative results on the RESIDE dataset better than the reported results. We use this model in the following experiments.
References
Agustsson, E., & Timofte, R. (2017). Ntire 2017 challenge on single image super-resolution: Dataset and study. In CVPR workshops
Bai, Y., Zhang, Y., Ding, M., & Ghanem, B. (2018). Finding tiny faces in the wild with generative adversarial network. In IEEE conference on computer vision and pattern recognition.
Bao, W., Zhang, X., Yan, S., & Gao, Z. (2017). Iterative convolutional neural network for noisy image super-resolution. In IEEE international conference on image processing.
Bascle, B., Blake, A., & Zisserman, A. (1996). Motion deblurring and super-resolution from an image sequence. In European conference on computer vision.
Berman, D., Avidan, S., et al. (2016). Non-local image dehazing. IEEE conference on computer vision and pattern recognition (pp. 1674–1682).
Chen, D., He, M., Fan, Q., Liao, J., Zhang, L., Hou, D., Yuan, L., Hua, G. (2019). Gated context aggregation network for image dehazing and deraining. In IEEE winter conference on applications of computer vision (pp. 1375–1383). IEEE.
Cho, S., & Lee, S. (2009). Fast motion deblurring. ACM Transactions on Graphics, 28(5), 145.
Dong, C., Loy, C. C., He, K., & Tang, X. (2016). Image super-resolution using deep convolutional networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(2), 295–307.
Fan, Z., Wu, H., Fu, X., Huang, Y., & Ding, X. (2017). Residual-guide network for single image deraining. In ACM international conference on multimedia.
Fattal, R. (2008). Single image dehazing. ACM Transactions on Graphics, 27(3), 72.
Geiger, A., Lenz, P., & Urtasun, R. (2012). Are we ready for autonomous driving? The kitti vision benchmark suite. In IEEE conference on computer vision and pattern recognition.
Godard, C., Mac Aodha, O., Firman, M., & Brostow, G. J. (2019). Digging into self-supervised monocular depth prediction. In IEEE international conference on computer vision.
Gong, D., Yang, J., Liu, L., Zhang, Y., Reid, I. D., Shen, C., Van Den Hengel, A., & Shi, Q. (2017). From motion blur to motion flow: A deep learning solution for removing heterogeneous motion blur. In IEEE conference on computer vision and pattern recognition.
Haris, M., Shakhnarovich, G., & Ukita, N. (2018). Deep backprojection networks for super-resolution. In IEEE conference on computer vision and pattern recognition.
He, K., Sun, J., & Tang, X. (2011). Single image haze removal using dark channel prior. IEEE Transactions on Pattern Analysis and Machine Intelligence, 33(12), 2341–2353.
He, K., Zhang, X., Ren, S., & Sun, J. (2015). Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In IEEE conference on computer vision and pattern recognition.
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735–1780.
Hradiš, M., Kotera, J., Zemcík, P., & Šroubek, F. (2015). Convolutional neural networks for direct text deblurring. In British machine vision conference.
Huang, J. B., Singh, A., & Ahuja, N. (2015). Single image super-resolution from transformed self-exemplars. In IEEE conference on computer vision and pattern recognition.
Hu, Z., Xu, L., & Yang M. H. (2014). Joint depth estimation and camera shake removal from single blurry image. In IEEE conference on computer vision and pattern recognition.
Jiang, T. X., Huang, T. Z., Zhao, X. L., Deng, L. J., & Wang, Y. (2017). A novel tensor-based video rain streaks removal approach via utilizing discriminatively intrinsic priors. In IEEE conference on computer vision and pattern recognition.
Johnson, J., Alahi, A., & Li, F. F. (2016). Perceptual losses for real-time style transfer and super-resolution. In European conference on computer vision.
Kim, J., Lee, J. K., & Lee, K. M. (2016a). Accurate image super-resolution using very deep convolutional networks. In IEEE conference on computer vision and pattern recognition.
Kim, J., Lee, J. K., & Lee, K. M. (2016b). Deeply-recursive convolutional network for image super-resolution. In IEEE conference on computer vision and pattern recognition.
Kim, T. H., Ahn, B., & Lee, K. M. (2013). Dynamic scene deblurring. In IEEE international conference on computer vision.
Kingma, D. P., & Ba, J. (2015). Adam: A method for stochastic optimization. In International conference on learning representations.
Köhler, R., Hirsch, M., Mohler, B., Schölkopf, B., & Harmeling, S. (2012). Recording and playback of camera shake: Benchmarking blind deconvolution with a real-world database. In European conference on computer vision.
Kupyn, O., Budzan, V., Mykhailych, M., Mishkin, D., & Matas, J. (2018). DeblurGAN: Blind motion deblurring using conditional adversarial networks. In IEEE conference on computer vision and pattern recognition.
Lai, W. S., Huang, J. B., Ahuja, N., & Yang, M. H. (2019). Fast and accurate image super-resolution with deep laplacian pyramid networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 41(11), 2599–2613.
Lai, W. S., Huang, J. B., Hu, Z., Ahuja, N., & Yang, M. H. (2016). A comparative study for single image blind deblurring. In IEEE conference on computer vision and pattern recognition.
Ledig, C., Theis, L., Huszár, F., Caballero, J., Cunningham, A., Acosta, A., Aitken, A. P., Tejani, A., Totz, J., Wang, Z., & Shi, W. (2017). Photo-realistic single image super-resolution using a generative adversarial network. In IEEE conference on computer vision and pattern recognition.
Li, B., Peng, X., Wang, Z., Xu, J., & Feng, D. (2017). Aod-net: All-in-one dehazing network. In IEEE international conference on computer vision.
Li, B., Ren, W., Fu, D., Tao, D., Feng, D., Zeng, W., et al. (2018a). Reside: A benchmark for single image dehazing. IEEE Transactions on Image Processing, 28(1), 492–505.
Li, G., He, X., Zhang, W., Chang, H., Dong, L., & Lin, L. (2018b). Non-locally enhanced encoder-decoder network for single image de-raining. arXiv:1808.01491.
Li, M., Xie, Q., Zhao, Q., Wei, W., Gu, S., Tao, J., & Meng, D. (2018c). Video rain streak removal by multiscale convolutional sparse coding. In IEEE conference on computer vision and pattern recognition.
Li, X., Wu, J., Lin, Z., Liu, H., & Zha, H. (2018d). Recurrent squeeze-and-excitation context aggregation net for single image deraining. In European conference on computer vision.
Lim, B., Son, S., Kim, H., Nah, S., & Lee, K. M. (2017). Enhanced deep residual networks for single image super-resolution. In CVPR workshops.
Liu, G., Lin, Z., Yan, S., Sun, J., Yu, Y., & Ma, Y. (2013). Robust recovery of subspace structures by low-rank representation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(1), 171–184.
Liu, J., Yang, W., Yang, S., & Guo, Z. (2018). Erase or fill? deep joint recurrent rain removal and reconstruction in videos. In IEEE conference on computer vision and pattern recognition.
Mairal, J., Bach, F., Ponce, J., Sapiro, G. (2009). Online dictionary learning for sparse coding. In International conference on machine learning.
Mei, K., Jiang, A., Li, J., & Wang, M. (2018). Progressive feature fusion network for realistic image dehazing. In Asian conference on computer vision.
Nah, S., Kim, T. H., & Lee, K. M. (2017). Deep multi-scale convolutional neural network for dynamic scene deblurring. In IEEE conference on computer vision and pattern recognition.
Nimisha, T. M., Singh, A. K., & Rajagopalan, A. N. (2017). Blur-invariant deep learning for blind-deblurring. In IEEE international conference on computer vision.
Noroozi, M., Chandramouli, P., & Favaro, P. (2017). Motion deblurring in the wild. In German conference on pattern recognition.
Pan, J., Sun, D., Pfister, H., & Yang, M. H. (2016). Blind image deblurring using dark channel prior. In IEEE conference on computer vision and pattern recognition.
Paramanand, C., & Rajagopalan, A. N. (2013). Non-uniform motion deblurring for bilayer scenes. In IEEE conference on computer vision and pattern recognition.
Park, H., & Lee, K. M. (2017). Joint estimation of camera pose, depth, deblurring, and super-resolution from a blurred image sequence. In IEEE international conference on computer vision.
Redmon, J., & Farhadi, A. (2018). Yolov3: An incremental improvement. arXiv:1804.02767.
Ren, W., Liu, S., Zhang, H., Pan, J., Cao, X., & Yang, M. H. (2016). Single image dehazing via multi-scale convolutional neural networks. In European conference on computer vision.
Ren, W., Ma, L., Zhang, J., Pan, J., Cao, X., Liu, W., & Yang, M. H. (2018). Gated fusion network for single image dehazing. In IEEE conference on computer vision and pattern recognition.
Reynolds, D. A., Quatieri, T. F., & Dunn, R. B. (2000). Speaker verification using adapted gaussian mixture models. Digital Signal Processing, 10(1–3), 19–41.
Sajjadi, M. S., Schölkopf, B., & Hirsch, M. (2017). Enhancenet: Single image super-resolution through automated texture synthesis. In IEEE international conference on computer vision.
Schmidt, U., Rother, C., Nowozin, S., Jancsary, J., & Roth, S. (2013). Discriminative non-blind deblurring. In IEEE conference on computer vision and pattern recognition.
Schmidt, U., Schelten, K., & Roth, S. (2011). Bayesian deblurring with integrated noise estimation. In IEEE conference on computer vision and pattern recognition.
Schulter, S., Leistner, C., & Bischof, H. (2015). Fast and accurate image upscaling with super-resolution forests. In IEEE conference on computer vision and pattern recognition.
Shan, Q., Jia, J., & Agarwala, A. (2008). High-quality motion deblurring from a single image. ACM Transactions on Graphics, 27(3), 73.
Shi, W., Caballero, J., Huszár, F., Totz, J., Aitken, A. P., Bishop, R., Rueckert, D., & Wang, Z. (2016). Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In IEEE conference on computer vision and pattern recognition.
Su, S., Delbracio, M., Wang, J., Sapiro, G., Heidrich, W., & Wang, O. (2017). Deep video deblurring for hand-held cameras. In IEEE conference on computer vision and pattern recognition.
Tai, Y., Yang, J., & Liu, X. (2017). Image super-resolution via deep recursive residual network. In IEEE conference on computer vision and pattern recognition.
Tan, R. T. (2008). Visibility in bad weather from a single image. In IEEE conference on computer vision and pattern recognition.
Tao, X., Gao, H., Wang, Y., Shen, X., Wang, J., & Jia, J. (2018). Scale-recurrent network for deep image deblurring. In IEEE conference on computer vision and pattern recognition.
Timofte, R., De Smet, V., & Van Gool, L. (2014). A+: Adjusted anchored neighborhood regression for fast super-resolution. In Asian conference on computer vision.
Xu, L., Zheng, S., & Jia, J. (2013). Unnatural l0 sparse representation for natural image deblurring. In IEEE conference on computer vision and pattern recognition.
Xu, X., Sun, D., Pan, J., Zhang, Y., Pfister, H., & Yang, M. H. (2017). Learning to super-resolve blurry face and text images. In IEEE international conference on computer vision.
Yamaguchi, T., Fukuda, H., Furukawa, R., Kawasaki, H., & Sturm. P. (2010). Video deblurring and super-resolution technique for multiple moving objects. In Asian conference on computer vision.
Yang, W., Tan, R. T., Feng, J., Liu, J., Guo, Z., & Yan, S. (2017). Deep joint rain detection and removal from a single image. In IEEE conference on computer vision and pattern recognition.
Yu, X., Fernando, B., Hartley, R., & Porikli, F. (2018). Super-resolving very low-resolution face images with supplementary attributes. In IEEE conference on computer vision and pattern recognition.
Zhang, H., & Patel, V. M. (2018a). Densely connected pyramid dehazing network. In IEEE conference on computer vision and pattern recognition.
Zhang, H., & Patel V. M. (2018b). Density-aware single image de-raining using a multi-stream dense network. In IEEE conference on computer vision and pattern recognition.
Zhang, H., Yang, J., Zhang, Y., Nasrabadi, N. M., & Huang, T. S. (2011). Close the loop: Joint blind image restoration and recognition with sparse representation prior. In IEEE international conference on computer vision.
Zhang, H., Sindagi, V., & Patel, V. M. (2017). Joint transmission map estimation and dehazing using deep networks. arXiv:1708.00581.
Zhang, H., Sindagi, V., & Patel, V. M. (2019). Image de-raining using a conditional generative adversarial network. In Transactions on circuits and systems for video technology. IEEE. https://doi.org/10.1109/TCSVT.2019.2920407.
Zhang, L., Zhang, H., Shen, H., & Li, P. (2010). A super-resolution reconstruction algorithm for surveillance images. Signal Processing, 90(3), 848–859.
Zhang, X., Wang, F., Dong, H., & Guo, Y. (2018a). A deep encoder-decoder networks for joint deblurring and super-resolution. In IEEE international conference on acoustics, speech, and signal processing.
Zhang, Y., Li, K., Li, K., Wang, L., Zhong, B., & Fu, Y. (2018b). Image super-resolution using very deep residual channel attention networks. In European conference on computer vision.
Zhang, Y., Tian, Y., Kong, Y., Zhong, B., & Fu, Y. (2018c). Residual dense network for image super-resolution. In IEEE conference on computer vision and pattern recognition (pp. 2472–2481).
Zou, W. W., & Yuen, P. C. (2012). Very low resolution face recognition problem. IEEE Transactions on Image Processing, 21(1), 327–340.
Acknowledgements
X. Zhang, H. Dong, and F. Wang are supported in part by National Major Science and Technology Projects of China Grant under No. 2019ZX01008103, National Natural Science Foundation of China (61603291), Natural Science Basic Research Plan in Shaanxi Province of China (Program No. 2018JM6057), and the Fundamental Research Funds for the Central Universities. W.-S. Lai and M.-H. Yang are supported in part by NSF CAREER Grant #1149783 and Gifts from Verisk, Adobe and Google.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Yasuyuki Matsushita.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
1.1 Network Configuration
We present the detailed configuration of the proposed network in Table 6, with respect to the four modules in the network: the deblurring module, SR feature extraction module, recursive gate module, and reconstruction module.
1.2 List of the Evaluated Methods
All the the evaluated methods in Sect. 4 are listed in Table 7.
1.3 Additional Visual Results
In this section, we present more qualitative comparisons on the LR-RESIDE in Fig. 12, which includes the combinations of the SR algorithm (Lim et al. 2017) and dehazing algorithms (He et al. 2011; Berman et al. 2016; Ren et al. 2018).

1.4 Additional Ablation Study and Analysis
To further demonstrate the importance of the dual-branch architecture and gate module, more ablation study and visual results are presented in this section. We first compare the restoration module with the state-of-the-art restoration methods to evaluate the performance contribution brought by the image restoration module. Then, the qualitative results of the ablation study are presented to demonstrate how other modules help to improve the performance.
1.4.1 Performance of Restoration Module
We provide the quantitative results from the state-of-the-art restoration methods and the proposed restoration module in Table 8. The restoration methods include deblurring algorithms [DeepDeblur Nah et al. (2017), DeblurGAN Kupyn et al. (2018), and SRN Tao et al. (2018)], dehazing algorithms [DGFN Ren et al. (2018), GCANet Chen et al. (2019), and PFFNet Mei et al. (2018)), and deraining algorithms (IDGAN Zhang et al. (2019), RESN Li et al. (2018d), and DID-MDN Zhang and Patel (2018b)]. Since these restoration methods are trained on the high-resolution images (GOPRO, RESIDE, Rain1200 datasets), we re-train the restoration module on the same high-resolution datasets for fair comparisons. As shown in Table 8, in none of these three datasets does our restoration module acquire the best results, while the proposed GFN still performs favorably on all the three datasets as shown in Tables 1, 2, 3 of the manuscript. Therefore, the favorable performance of the proposed method comes from the architecture designs, such as the dual-branch architecture and the gate module.
1.5 Effect of Dual-Branch Architecture and Gate Module
To further demonstrate the benefits of the dual-branch architecture and gate module, we present an example in Fig. 13. Figure 13b, c show the outputs of the restoration module \(G_{res}\) and Model-1 (\(G_{res}\) + \(G_{base}\) + \(G_{recon}\)) in Fig. 11a. Since the artifacts in the \(G_{res}\) are propagated to the \(G_{base}\) and \(G_{recon}\), the Model-1 generates less satisfactory results as shown in Fig. 13c. Figure 13d shows the output of the Model-4 in Fig. 11d, which adopts the dual-branch architecture without the gate module \(G_{gate}\). Figure 13d contains fewer artifacts than Fig. 13c, especially on the regions that are relatively sharper in the input image. This is because the dual-branch architecture combines features from both input images and recovered images and, therefore, avoids error propagation from only the recovered images. Fig. 13e shows the output of the proposed GFN introducing the gate module to adaptively fuse the features. By exploiting the confidence of the features from two branches (\(\phi _{RF}\) into \(\phi _{BF}\)), the gate module manages to suppress the artifacts and blurry features via local and channel-wise feature fusion. Figure 13f–j shows that our model progressively fuses features and suppresses artifacts through the gate module.

Qualitative results of the ablation study. \(\phi _{BF}\) denotes the base features from the base module \(G_{base}\) and \(\phi _{RF}\) denotes the features from the restoration module \(G_{res}\). All the models are trained on the LR-GOPRO dataset with the same training settings as the proposed GFN
1.6 Applications on Detection Task
To demonstrate that the proposed method can help the following high-level tasks, we compare the proposed GFN with state-of-the-art methods on the object detection task. We first generate two datasets from the KITTI dataset (Geiger et al. 2012), one blurry low-resolution dataset and a hazy low-resolution dataset. For the blurry dataset, we apply the single image non-uniform blurry synthesis method in Lai et al. (2016) to generate the blurry HR images and use the bicubic downsampling to generate the blurry LR images as the inputs. We then generate recovered HR images with the following methods: the bicubic upsampling, deblurring method SRN (Tao et al. 2018 with super resolution method RCAN (Zhang et al. 2018b), joint restoration and super-resolution method ED-DSRN (Zhang et al. 2018a), and the proposed GFN. For the hazy dataset, we first apply the single image depth estimation method, the Monodepth2 (Godard et al. 2019), to predict a depth map for each image and then synthesize the hazy image following the instruction of the RESIDE dataset (Li et al. 2018a). We compare the proposed GFN with the following approaches: the bicubic upsampling, dehazing method PFFNet (Mei et al. 2018) with super resolution method RCAN (Zhang et al. 2018b), and joint restoration and super-resolution method ED-DSRN (Zhang et al. 2018a). We use the above methods to recover HR images and then use the YOLOv3 (Redmon and Farhadi 2018) to evaluate the detection accuracy.
We show the detection accuracy in Tables 9 and 10. The HR images restored from the proposed GFN obtain the best detection accuracy in both applications. The qualitative results in Figs. 14 and 15 demonstrate that our GFN not only generates clean HR outputs but also improves the detection algorithm to recognize the cars and pedestrians.

Detection results using the recovered images from different methods. We compare the following methods: bicubic upsampling, deblurring method SRN (Tao et al. 2018) + super resolution method RCAN (Zhang et al. 2018b), joint restoration and super-resolution method ED-DSRN (Zhang et al. 2018a), and the proposed GFN

Detection results using the recovered images from different methods. We compare the following methods: bicubic upsampling, dehazing method PFFNet (Mei et al. 2018) + super resolution method RCAN (Zhang et al. 2018b), joint restoration and super-resolution method ED-DSRN (Zhang et al. 2018a), and the proposed GFN
Rights and permissions
About this article

Cite this article
Zhang, X., Dong, H., Hu, Z. et al. Gated Fusion Network for Degraded Image Super Resolution. Int J Comput Vis 128, 1699–1721 (2020). https://doi.org/10.1007/s11263-019-01285-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11263-019-01285-y