
Abstract
Stochastic models are of fundamental importance in many scientific and engineering applications. For example, stochastic models provide valuable insights into the causes and consequences of intra-cellular fluctuations and inter-cellular heterogeneity in molecular biology. The chemical master equation can be used to model intra-cellular stochasticity in living cells, but analytical solutions are rare and numerical simulations are computationally expensive. Inference of system trajectories and estimation of model parameters from observed data are important tasks and are even more challenging. Here, we consider the case where the observed data are aggregated over time. Aggregation of data over time is required in studies of single cell gene expression using a luciferase reporter, where the emitted light can be very faint and is therefore collected for several minutes for each observation. We show how an existing approach to inference based on the linear noise approximation (LNA) can be generalised to the case of temporally aggregated data. We provide a Kalman filter (KF) algorithm which can be combined with the LNA to carry out inference of system variable trajectories and estimation of model parameters. We apply and evaluate our method on both synthetic and real data scenarios and show that it is able to accurately infer the posterior distribution of model parameters in these examples. We demonstrate how applying standard KF inference to aggregated data without accounting for aggregation will tend to underestimate the process noise and can lead to biased parameter estimates.
Similar content being viewed by others


1 Introduction
Stochastic differential equations (SDEs) are used to model the dynamics of processes that evolve randomly over time. SDEs have found a range of applications in finance (e.g. stock markets, Hull 2009), physics (e.g. statistical physics, Gardiner 2004) and biology (e.g. biochemical processes, Wilkinson 2011). Usually, the coefficients (model parameters) of SDEs are unknown and have to be inferred using observations from the systems of interest. Observations are typically partial (e.g. collected at discrete times for a subset of variables), corrupted by measurement noise, and may also be aggregated over time and/or space. Given these observed data, our task is to infer the process trajectory and estimate the model parameters.
A motivating example of stochastic aggregated data comes from biology and more specifically from luminescence bioimaging, where a luciferase reporter gene is used for studying gene expression inside a cell (Spiller et al. 2010). The luminescence intensity emitted from the luciferase experiments is collected from single cells and is integrated over a time period (in certain cases up to 30 min, Harper et al. 2011) and then recorded as a single data point. In this paper, we consider the problem of inferring SDE model parameters given temporally aggregated data of this kind.
Imaging data from single cells are highly stochastic due to the low number of reactant molecules and the inherent stochasticity of cellular processes such as gene transcription or protein translation. The chemical master equation (CME) is widely used to describe the evolution of biochemical reactions inside cells stochastically (Gillespie 1992). Exact inference with the CME is rare and, even when possible, computationally prohibitive. In Golightly and Wilkinson (2005), the authors perform inference using a diffusion approximation of the CME, resulting in a nonlinear SDE. The linear noise approximation (LNA) (Kampen 2007) has been used as an alternative approximation of the CME which is valid for a sufficiently large system (Komorowski et al. 2009; Fearnhead et al. 2014). According to the LNA, the system is decomposed into a deterministic and a stochastic part. The latter is described by a linear SDE of the following form:
where \(X_t\) is a d-dimensional process, \(a_t\) is a \((d\times d)\)-matrix-valued function, \(W_t\) is an m-dimensional Wiener process, and \(b_t\) a \((d\times m)\) matrix-valued function.
Given an initial condition \(X_0 = c\), Eq. (1) has the following known solution (Arnold 1974):
where \(\varPhi _t\) is the fundamental matrix of the homogeneous equation \(\mathrm{d}X_t = a_tX_t\mathrm{d}t\). Note that the right integral in Eq. (2) is a Gaussian process, as it is an integral of a non-random function with respect to \(W_t\) (Arnold 1974). If we further assume that the initial condition c is normally distributed or constant, Eq. (2) gives rise to a Gaussian process. Additionally, the solution of a (linear) SDE is a Markov process (Arnold 1974). These properties of linear SDEs (of the form of Eq. (1)) are highly desirable when carrying out inference.
The approaches above do not treat the aggregated nature of luciferase data in a principled way but instead assume that the data are proportional to the quantity of interest at the measurement time (Harper et al. 2011; Komorowski et al. 2009). Here, we build on the work of Komorowski et al. (2009) and Fearnhead et al. (2014) and extend it to the case of aggregated data. Since we are using the LNA, the problem is equivalent to a parameter inference problem for the time integral of a linear SDE as in Eq. (1): \(\int _{t_0}^t X(u)\mathrm{d}u\). We follow a Bayesian approach, where the likelihood of our model is computed using a continuous-discrete Kalman filter (Särkkä 2006) and parameter inference is achieved using an MCMC algorithm. The paper is structured as follows: we first provide a description of the LNA as an approximation of the CME and introduce the integral of the LNA for treating temporally aggregated observations. We then describe a Kalman filter framework for performing inference with the LNA and its integral. Finally, we apply our method in three different examples. The Ornstein–Uhlenbeck process has been picked as a system where we can study its exact solutions. The Lotka–Volterra model was selected as an example of a nonlinear system with partial observations. The translation inhibition model was used to demonstrate our method with real data.
2 The linear noise approximation and its integral
The CME can be used to model biochemical reactions inside a cell. It is essentially a forward Kolmogorov equation for a Markov process that describes the evolution of a spatially homogeneous biochemical system over time.
Assume a biochemical reaction network consisting of N chemical species \({\mathcal {X}_1}, \ldots ,{\mathcal {X}_N}\) in a volume \({\varOmega }\) and v reactions \({R_1}, \ldots ,{R_v}\). The usual notation for such a network is given below:
\({R_1}\) : \({p_{11}\mathcal {X}_1}\) + \({p_{12}\mathcal {X}_2} + \cdots + {p_{1N}\mathcal {X}_N}\) \({\rightarrow }\) \({q_{11}\mathcal {X}_1}\) + \({q_{12}\mathcal {X}_2} +\cdots + {q_{1N}\mathcal {X}_N}\) \({R_2}\) : \({p_{21}\mathcal {X}_1}\) + \({p_{22}\mathcal {X}_2} + \cdots + {p_{2N}\mathcal {X}_N}\) \({\rightarrow }\) \({q_{21}\mathcal {X}_1}\) + \({q_{22}\mathcal {X}_2} + \cdots + {q_{2N}\mathcal {X}_N}\) ... \({R_v}\) : \({p_{v1}\mathcal {X}_1}\) + \({p_{v2}\mathcal {X}_2} +\cdots + {p_{vN}\mathcal {X}_N}\) \({\rightarrow }\) \({q_{v1}\mathcal {X}_1}\) + \({q_{v2}\mathcal {X}_2} + \cdots + {q_{vN}\mathcal {X}_N}\)
where \({\varvec{X}}\) = \({(\mathcal {X}_1,\ldots ,\mathcal {X}_N)^T}\) represents the number of chemical species (we assume molecules) and \({\varvec{x}}\) = \({\frac{\varvec{X}}{\varOmega }}\) is the concentration of molecules. We denote with P the \({v\times u}\) matrix whose elements are given by \({p_{ij}}\) and Q the \({v\times u}\) matrix with elements \({q_{ij}}\). We define the stoichiometry matrix S as \({S = (Q - P)^T}\). The probability of a reaction taking place in \({[t, t+\mathrm{d}t)}\) is given by the vector of reaction rates \({h_j(x,\varOmega , t)\varOmega \mathrm{d}t}\).
The probability \({p(\varvec{X},t)}\) that the system is in state \({\varvec{X}}\) at time t is given by the CME:
However, as mentioned before, exact inference with the CME, even when possible, is computationally prohibitive. We use the LNA as an approximation of the CME due to its successful application in Komorowski et al. (2009) and Fearnhead et al. (2014). The state of the system \({\varvec{X}}\) is expected to have a peak around the macroscopic value of order \(\varOmega \) and fluctuations of order \(\varOmega ^{1/2}\) such that \(X_t = \varOmega \phi _t + \varOmega ^{1/2}\xi _t\). This way the system is decomposed to the deterministic part \(\phi _t\) and the stochastic part \(\xi _t\). The LNA arises as a Taylor expansion of the CME in powers of the volume \(\varOmega \); for a detailed derivation the reader is referred to Kampen (2007) and Elf and Ehrenberg (2003). By collecting terms of order \(\varOmega ^{1/2}\), we obtain the deterministic part of the system, namely the macroscopic rate equations \(\phi _i\), where i stands for the ith species:
Terms of order \(\varOmega ^0\) give us the stochastic part of the system:
where, \(A_t = SF_t\) and \(F_{ij} = \frac{\partial h_j(\phi _t,\varOmega , t)}{\partial \phi _i(t) }\), while \({EE_t}^{T} = Sdiag(h(\phi _t,\varOmega , t))S^T\). Equation (5) is a linear SDE of the form of Eq. (1). Its solution is a Gaussian Markov process, provided that we have an initial condition that is a constant or a Gaussian random variable. The ordinary differential equations (ODEs) that describe the mean and variance of this Gaussian process are given by Arnold (1974):
Note that if we set the initial condition of \(m_0=0\), then Eq. (6) will lead to \(m_t = 0\) at all times. We will make the assumption that, at each observation point, \(m_t\) is reset to zero since it can be beneficial for inference as discussed in Fearnhead et al. (2014) and Giagos (2010).
In what follows we will assume, without loss of generality, that the volume \({\varOmega }=1\), i.e. the number of molecules equals the concentration of molecules and thus,
Equation (8) is the sum of a deterministic and a Gaussian term; consequently, it will also be normally distributed. By taking its expectation and variance, we have that \(X_t|X_0 \sim N(\phi _t + m_t,V_t)\) which, according to the initial condition \(m_0=0\), leads to \(X_t|X_0 \sim N(\phi _t,V_t)\).
We are now interested in the integral of Eq. (8), as this will allow us to model the aggregated data,
The deterministic part of this aggregated process is given by I(t), and the stochastic part is given by Q(t). Subsequently, we have the following ODEs:
Here, \(Q_t\) will also follow a Gaussian process (as it is the integral of a Gaussian process) so we need to compute its mean and variance. The ODEs for the mean, variance and \(\mathbb {E}[Q_t\xi _t^T]\) are given below; their proofs can be found in “Appendix A.1”:
Note that \(Q_t\) is not Markovian since knowledge of its history is not sufficient to determine its current state. However, jointly with \(\xi _t\) it forms a bivariate Gaussian Markov process, that is characterised by the following linear SDE:
From Eq. (15) we have that \(\xi _t, Q_t\) are jointly Gaussian and, consequently, their marginals are also normally distributed. Thus, according to (9) \(H_t|H_0,X_0 \sim N(\mu _t, \varSigma _t)\) with \(\mu _t = I_t\) and \(\varSigma _t = V[Q_t]\).
3 Kalman filter for the LNA and its integral
The classical filtering problem is concerned with the problem of estimating the state of a linear system given noisy, indirect or partial observations (Kalman 1960). In our case, the state is continuous and is described by Eq. (8) while the observations are collected at discrete time points with or without Gaussian noise. For this reason, we refer to it as the continuous-discrete filtering problem (Jazwinski 1970; Särkkä 2006).
First, we consider the case where observations are taken from the process \(X_t\) and not from its integral \(H_t\). In that case, the observation process is given by \(y_t = P_tX_t + \epsilon _t\) where \(\epsilon _t \sim N(0,R)\) and accounts for technical noise. The observability matrix \(P_t\) is used to deal with the partial observability of the system, for example, if we have two species \(X_1\), \(X_2\) and we observe only \(X_1\), \(P = [1,0]^\mathrm{T}\).
Following the Kalman filter (KF) methodology, we need to define the following quantities:
-
Prior: \(p(X_0)\).
-
Predictive distribution: \(p(X_t|y_{1:t-1})\), where \(y_{1:t-1}\) refers to the observations at discrete points up to time \(t-1\).
-
Posterior or Update distribution: \(p(X_t|y_{1:t})\).
The predictive distribution is given by \(X_t|y_{1:t-1} \sim N(\mu _{1t}^-,V_{t}^-)\), where \(\mu _{1t}^-\) and \(V_{t}^-\) are found by integrating forward for \([t,t-1]\) Eqs. (4) and (7) initialised at the posterior mean \(\mu _{1t-1}\) and variance \(V_{t-1}\). In our case, the mean of the stochastic part is initialised at 0, so \(\mu _{1t}\) corresponds to the deterministic part \(\phi _t\). By updating the deterministic solution at each observation point, we achieve a better estimate, as the ODE solution can become a poor approximation over long periods of time. The posterior distribution \(p(X_t|y_{1:t}) = N(\mu _{1t}, V_t)\) corresponds to the standard posterior distribution of a discrete KF and the updated \(\mu _{1t}\) and \(V_t\) are given in “Appendix A.3”. This case has been thoroughly studied in Fearnhead et al. (2014).
We consider now the case where the state \(X_t\) is being observed through the integrated process \(H_t\), such that the observation process is given by \(y_t = P_tH_t + \epsilon _t\) and \(\epsilon _t \sim N(0,R)\). Again, we need to define a prior distribution as well as calculate the predictive and posterior distributions for the system that we are studying.
The predictive distribution of our system is given by \(p\Big (\begin{bmatrix}X_t\\H_t\end{bmatrix}|y_{1:t-1}\Big ) = N\Big (\begin{bmatrix} \mu _{1t}^-\\\mu _{2t}^-\end{bmatrix}, \begin{bmatrix} V_{t}^-&{C_{t}^-}^T\\C_{t}^-&\varSigma _{t}^-\end{bmatrix} \Big )\), where \(C_t = \mathbb {E}[Q_tM_t^T]\). For this step, we need to integrate forward the ODEs (4), (10), (7), (13) and (14) with the appropriate initial conditions as seen in Algorithm 1. Note that the integrated process \(H_t\) needs to be reset to 0 at each observation point in order to capture correctly the ‘area under graph’ of the underlying process \(X_t\).
To compute the posterior distribution \(p(X_t|y_{1:t})\), we look at the joint distribution of \((H_t,X_t,y_t)\) conditioned on \(y_{1:t-1}\):
By using the lemma in “Appendix A.2” and using the corresponding blocks of the joint distribution (16), we can calculate the posterior mean and variance of \(p(X_t|y_{1:t})\):
Since we are interested in parameter inference, we will need to compute the likelihood \(L(\theta )\) of the system, where \(\theta \) represents the parameter vector of the system:
The individual terms of the likelihood are given by \(p(y_t|y_{1:t-1}) = N(P_t\mu _{2t}^-,P_t\varSigma _{t}^-P^T_t+R_t)\). Parameter inference is then straightforward either by using a numerical technique such as the Nelder–Mead algorithm to obtain the maximum likelihood (ML) parameters or using a Bayesian method such as a Metropolis-Hastings (MH) algorithm. The general procedure for performing inference using aggregated data is summarised in Algorithm 1.

4 The Ornstein–Uhlenbeck process
We first investigate the effect of integration in a one-dimensional, zero-mean OU process of the following form:
where \(\alpha \) is the drift or decay rate of the process and \(\sigma \) is the diffusion constant. Both of these parameters are assumed to be unknown, and we will try to infer them using the KF scheme that we have developed.
The OU process is a special case of a linear SDE (Eq. (1)), since its coefficients are time invariant, resulting in a stationary Gaussian–Markov process. Analytical solutions for both the OU and its integral exist (Gillespie 1996) and are presented in “Appendix A.4”. The results for the mean \(m_t\) and variance \(V_t\) of the OU, where \(\Delta = t-t_0\), are given below:
The integral of Eq. (19) is given by \(\mathrm{d}Y_t = X_t\mathrm{d}t \), and the mean, variance and covariance are given below,
We are interested in inferring the parameters \(\alpha \) and \(\sigma \) given observations from \(Y_t\) at discrete times, where the interval \(\Delta \) between two observations is constant. We will compare two approaches. First, we will assume that the data come directly from \(X_t\) ignoring their aggregated nature and use the standard discrete–continuous KF, referred to as KF1. To make the comparison of this scenario fairer, we will normalise the observations by dividing with \(\Delta \), which brings the observation close to an average value of the process, in an attempt to match the observations to data generated from the process \(X_t\). In the second case, we will use the KF on the integrated process in analogy with Algorithm 1, which we will refer to as KF2. The case of inferring the parameters of an OU process using non-aggregated data with an MCMC algorithm has already been studied in Mbalawata et al. (2013).
\(X_t\) will reach its stationary distribution after a time of order \(\frac{1}{\alpha }\), which is given by \(N(0,\frac{\sigma ^2}{2\alpha })\) (Gillespie 1992). However, the integrated process \(Y_t\) is non-stationary since \(\mathrm {Var}[y_t] \rightarrow \infty \) as \(\Delta \rightarrow \infty \) . This already shows us that the two processes behave differently.
Since we are going to use the normalised observations from \(Y_t\) with KF1, we will take a look at the normalised process \(Z_t = \frac{1}{\Delta }Y_t\):
By taking the limit as \(\Delta \rightarrow \infty \) in Eq. (22) and using L’Hospital’s rule we can show that \(\mathbb {E}[z_t]\rightarrow 0\) and \(\mathrm {Var}[z_t]\rightarrow 0\). So, the normalised process is again not approaching the stationary distribution of \(X_t\).
We have generated aggregated data from the integral of an OU process with \(\alpha = 4\) and \(\sigma = 2\). To simulate data from \(Y_t\), we need to first simulate data from \(X_t\). This can be done in general by discretising the process and using the Euler–Maruyama algorithm. However, in the case of the OU process, we can also use an exact updating formula (see “Appendix A.6”). The aggregated data can then be collected using the discretised form \(Y_{t+dt} = Y_t + X_tdt\) or a numerical integration method such as the trapezoidal rule over the indicated integration period. In “Appendix A.12” we have included plots of the OU process and the corresponding aggregated process.
We tested inference using KF1 with normalised data and KF2 with aggregated data. Results of parameter estimation using a standard random walk MH algorithm are presented in Table 1. Improper uniform priors over infinite range have been used on the log parameters, while different time intervals \(\Delta \) have been considered. For each interval \(\Delta \), we have sampled 100 observations from a single trajectory of an OU process with \(\alpha =4\) and \(\sigma = 2\) aggregated over the specified \(\Delta \). For this example, we have assumed no observation noise. MCMC traceplots of \(\alpha \) and \(\sigma \) can be found in “Appendix A.13” (Figs. 6, 7) which indicate a good mixing of the chain and fast convergence. All chains were run for 50K iterations and 30K were discarded as burn-in. To verify the validity of the results, we have run nine more datasets, separately each time. An average over the ten datasets can be found in “Appendix A.7” (Table 5). As we can see, the estimates for KF1 deteriorate for larger \(\Delta \). This is expected since the aggregated process diverges further from the OU process as \(\Delta \) increases. Estimates remain good for KF2 even when \(\Delta \) is large, although they become more uncertain, as can be witnessed by the increased standard deviations. Filtering results for KF1 and KF2 with aggregated data using the estimated parameter results for \(\Delta = 1\) are given in “Appendix A.14”.
It is of interest to investigate the inferred stationary variance of the OU process using KF1 and KF2. We have plotted the inferred stationary variances obtained by the MH for both KF1 and KF2 in Fig. 1. The boxplots are obtained using the average of 10 different datasets and correspond again to an OU process with \(\alpha = 4\) and \(\sigma = 2\), thus giving rise to a stationary variance of \(\frac{\sigma ^2}{2\alpha } = 0.5\). When using the normalised aggregated data directly with KF1, we infer the wrong stationary variance of the underlying OU process which tends to zero as \(\Delta \) becomes larger, consistent with the theoretical results from Eq. (22). Intuitively, we can attribute this behaviour to the fact that aggregated data have relatively smaller fluctuations, so that KF1 will tend to underestimate the process variance.

Boxplots of inferred stationary variance of the OU process for different \(\Delta \). The simulated OU process has \(\alpha = 4\) and \(\sigma = 2\) corresponding to a stationary variance of 0.5, as indicated by the dotted horizontal line. The inferred stationary variance using KF1 tends to zero as \(\Delta \) grows, but the stationary variance from KF2 is inferred correctly at all \(\Delta \). a Boxplots of inferred stationary variance for different \(\Delta \) using KF1. b Boxplots of inferred stationary variance for different \(\Delta \) using KF2
In this section, we have looked at an example of inferring the parameters of an SDE using aggregated data, and we have found that to obtain accurate results we need to explicitly model the aggregated process. As the observation intervals become larger, there is a greater mismatch between KF1 and KF2. In the next two sections, we will look at examples of more complex stochastic systems that must be approximated by the LNA and compare again inference results using KF1 and KF2.
5 Lotka–Volterra model
We are now going to look at a system of two species that interact with each other according to three reactions
The model represented by the biochemical reaction network (23) is known as the Lotka–Volterra model, with \(X_1\) representing prey species and \(X_2\) predator species. Although a simple model, it has been used as a reference model (Boys et al. 2008; Fearnhead et al. 2014) since it consists of two species, making it possible to observe it partially through one of the species and also provides a simple example of a nonlinear system.
The LNA can be used to approximate the dynamics and the resulting ODEs can be found in “Appendix A.8”. We want to compare parameter estimation results using KF1 and KF2. We collected aggregated data from a Lotka–Volterra model using the Gillespie algorithm. We assumed a known initial population of 10 prey species and 100 predator species. The parameters of the system for producing the synthetic data were set to \((\theta _1,\theta _2,\theta _3) = (0.5,0.0025,0.3)\), following (Boys et al. 2008). We have added Gaussian noise with standard deviation set to 3.0, and we assumed that the noise level was known for inference. Our goal was to infer the three parameters \((\theta _1,\theta _2,\theta _3)\) of the system using aggregated observations solely from the predator population.
The Gillespie algorithm was run for 20 min. Data were aggregated and collected every 2 min resulting in 10 observations per sample. To infer the parameters, we assumed that we had 40 independent samples available. Since we assumed independence between the samples, we worked with the product of their likelihoods. In the ideal case of having complete data of a stochastic kinetic model the likelihood is conjugate to an independent gamma prior for the rate constants (Wilkinson 2011). The choice of Ga(2,10) with shape \(= 2\) and rate \(= 10\) gives a reasonable range for all three parameters and has also been used by Fearnhead et al. (2014). However, in this case the choice of prior is not important as the data dominate the posterior. We have run the same experiment using uninformative exponential priors Exp(\(10^{-4}\)) that resulted in equivalent posterior distributions. Since we know that we want all parameters to be positive, we worked with a log transformation. MCMC convergence in this example is relatively slow and adaptive MCMC (Sherlock et al. 2010) was found to speed up convergence (see “Appendix A.9” for details). The adaptive MCMC was run for 30K iterations with 10K regarded as burn-in. The MCMC was initialised at random values sampled from uniform distributions. Parameter estimation results for all three parameters using adaptive MCMC are shown in Table 2, while Fig. 2 shows histograms of their posterior densities. The ground truth value for each parameter is indicated by a vertical blue line. We can see that only the posterior histograms corresponding to KF2 include the correct estimate for all three parameters in their support. In “Appendix A.15”, we have included traceplots of the MCMC runs for all three parameters, where we can see that the adaptive MCMC leads to a fast convergence for both KF1 and KF2. In order to verify the validity of our results, we have run an extra 100 datasets, each consisting of 40 independent samples and obtained point estimates from KF1 and KF2 using the Nelder–Mead algorithm. The results can be found in “Appendix A.10” and agree with our previous conclusion that inference with KF1 gives inaccurate estimates.

Posterior densities of \(\theta _1,\theta _2,\theta _3\) from aggregated data using KF1 (red histogram) and KF2 (green histogram). a Posterior density of \(\theta _1\). b Posterior density of \(\theta _2\). c Posterior density of \(\theta _3\)
Assuming knowledge of the parameter values, we can also use the KF for trajectory inference. In Fig. 3, we demonstrate filtering results for the prey population assuming that we have aggregated data. We simulated a trajectory using \(\theta _1 = 0.5 ,\theta _2 = 0.0025,\theta _3 =0.3\) and sampled aggregated data every 2 min. Black lines represent the true trajectory of the populations. We see that the inferred credible region with KF1 does not contain the true underlying trajectory in many places. Note that red dots correspond to normalised (aggregated) observations for KF1 and aggregated observations for KF2, so they do not have the same values. In “Appendix A.16”, we include filtering results for the unobserved predator population.

Filtering results for the prey population. Red dots correspond to aggregated observations for KF2 and normalised observations for KF1. The black line represents the actual process. Purple lines represent the mean estimate and green 1 s.d. . a Filtering results for the prey population using KF1. b Filtering results for the prey population using KF2
6 Translation inhibition model
In this example, we are interested in inferring the degradation rate of a protein from a translation inhibition experiment. We model the translation inhibition experiment by the following set of reactions where R stands for mRNA and P for protein:
The LNA is used, again, as an approximation of the dynamics and the resulting system of ODEs can be found in “Appendix A.11”. Before applying our method to real data from this system, we test the performance on synthetic data simulated using the Gillespie algorithm. We simulated 30 time series (corresponding to 30 different cells), assuming the following values as the ground truth for the kinetic parameters: \(c_P = 200\) and \(d_P = 0.97\). We further set the initial protein abundance of \(m_0\) to 400 molecules. We have scaled the data by a factor \(k = 0.03\), so that they are proportional to the original synthetic data and added Gaussian noise with a variance of \(s = 0.1\). For this study, we have assumed that data were integrated over 30 min.
Again we use an adaptive MCMC algorithm (Sherlock et al. 2010). Non-informative exponential priors with mean \(10^4\) were placed on all parameters. We have adopted the parametarisation used in Komorowski et al. (2009) and Finkenstädt et al. (2013) such as \(\widetilde{c}_P = k\cdot c_p\) and \(\widetilde{m}_0 = k\cdot m_0\) and worked in the log parameter space. Parameter estimation results for the vector \((c_p,d_p,s,k,m_0)\) using KF1 and KF2 are summarised in Table 3. As we can see, the degradation rates are successfully inferred by both approaches. However, using KF1 leads to an overestimation of \(m_0\) and an underestimation of the noise level s, which corresponds to a smoother process than the underlying one. MCMC traces from both KF1 and KF2 are presented in Fig. 11.
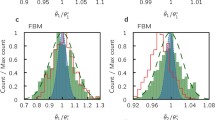
We then applied our model to single cell luciferase data from a subset of 11 pituitary cells (Harper et al. 2011). Parameter estimation results using the same adaptive MCMC are summarised in Table 4. The MCMC was run for 100K iterations out of which 60K were discarded as burn-in. Again, we observe that, using KF1, we get a higher \(m_0\) and a slightly lower noise level s. Posterior histograms of the degradation rates are shown in Fig. 4. A deterministic approach for fitting the data would give a degradation rate of around 1.02 and, as we can see, this value is included in both histograms of Fig. 4. To check convergence using the Gelman–Rubin statistic, we have run 3 different chains with different initialisations. MCMC traces for both KF1 and KF2 are shown in “Appendix A.18” (Fig. 12 and 13) where we can see that the three chains are very close to each other, corresponding to a Gelman–Rubin statistic close to 1.

Posterior histograms of degradation rate using KF1 and KF2
7 Discussion
We have presented a Bayesian framework for doing inference using aggregated observations from a stochastic process. Motivated by a systems biology example, we chose to use the LNA to approximate the dynamics of the stochastic system, leading to a linear SDE. We then developed a Kalman filter that can deal with integrated, partial and noisy data. We have compared our new inference procedure to the standard Kalman filter which has previously been applied in systems biology applications approximated using the LNA. Overall, we conclude that the aggregated nature of data should be considered when modelling data, as aggregation will tend to reduce fluctuations and therefore the stochastic contribution of the process may be underestimated.
In Sect. 4, we described the different properties of a stochastic process and its integral in the case of the Ornstein–Uhlenbeck process. We showed that one cannot simply treat the integrated observations as proportional to observations coming from the underlying unintegrated process when carrying out inference. As the aggregation time window increases, parameter estimates using this approach become less accurate and the inferred stationary variance of the process is underestimated. In contrast, our modified KF is able to accurately estimate the model parameters and stationary variance of the process.
In Sect. 5, we have demonstrated the ability of our method to give more accurate results in a Lotka–Volterra model given synthetic aggregated data. In Sect. 6, we looked at a real-world application with data from a translation inhibition experiment carried out in single cells. As the LNA depends on its deterministic part, and in a deterministic system integration is dealt with reasonably well using the simple proportionality constant approach, some of the system parameters, such as the degradation rate, can be inferred reasonably well by the standard non-aggregated data approach. However, neglecting the aggregated nature of the data does lead to a significantly larger estimate of the initial population of molecules even in this simple application. This is consistent with our observation that neglecting aggregation will tend to underestimate the scale of fluctuations as it is the number of molecules that determines the size of fluctuations in this example. In models where noise plays a more critical role, e.g. systems with noise-induced oscillations, the effect of parameter misspecification could have more serious consequences on model-based inferences.
Our proposed inference method can deal with the intrinsic noise inside a cell, measurement noise and temporal aggregation. However, cell populations are highly heterogeneous, and cell-to-cell variability has not been considered in our current inference scheme. It would be possible to deal with cell-to-cell variability using a hierarchical model (Finkenstädt et al. 2013) which could be combined with the integrated data Kalman Filter developed here.
All experiments were carried out on a cluster of 64bit Ubuntu machines with an i5-3470 CPU @ 3.20 GHz x 4 processor and 8 GB RAM. All scripts were run in Spyder (Anaconda 2.5.0, Python 2.7.11, Numpy 1.10.4). Code reproducing the results of the experiments can be found on GitHub https://github.com/maria-myrto/inference-aggregated.
References
Arnold, L.: Stochastic Differential Equations Theory and Applications. [S.l.]. Wiley, Hoboken (1974)
Bishop, C.: Pattern Recognition and Machine Learning (Information Science and Statistics). Springer, New York (2007)
Boys, R., Wilkinson, D., Kirkwood, T.: Bayesian inference for a discretely observed stochastic kinetic model. Stat. Comput. 18(2), 125–135 (2008)
Elf, J., Ehrenberg, M.: Fast evaluation of fluctuations in biochemical networks with the linear noise approximation. Genome Res. 13(11), 2475–2484 (2003)
Fearnhead, P., Giagos, V., Sherlock, C.: Inference for reaction networks using the linear noise approximation. Biometrics 70(2), 457–466 (2014)
Finkenstädt, B., Woodcock, D.J., Komorowski, M., Harper, C.V., Davis, J.R.E., White, M.R.H., Rand, D.A.: Quantifying intrinsic and extrinsic noise in gene transcription using the linear noise approximation: an application to single cell data. Ann. Appl. Stat. 7(4), 1960–1982 (2013)
Gardiner, C.: Handbook of Stochastic Methods: for Physics, Chemistry and the Natural Sciences (Springer Series in Synergetics), 3rd edn. Springer, Berlin (2004)
Giagos, V.: Inference for auto-regulatory genetic networks using diffusion process approximations. Ph.D. Thesis, Lancaster University (2010)
Gillespie, D.T.: Markov Processes : An Introduction for Physical Scientists. Academic Press, Boston (1992)
Gillespie, D.T.: A rigorous derivation of the chemical master equation. Phys. A Stat. Mech. Appl. 188, 404–425 (1992)
Gillespie, D.T.: Exact numerical simulation of the Ornstein-Uhlenbeck process and its integral. Phys. Rev. E 54, 2084–2091 (1996). doi:10.1103/physreve.54.2084
Golightly, A., Wilkinson, D.J.: Bayesian inference for stochastic kinetic models using a diffusion approximation. Biometrics 61(3), 781–788 (2005)
Harper, C.V., Finkenstädt, B., Woodcock, D.J., Friedrichsen, S., Semprini, S., Ashall, L., Spiller, D.G., Mullins, J.J., Rand, D.A., Davis, J.R.E., White, M.R.H.: Dynamic analysis of stochastic transcription cycles. PLoS Biol 9(4), e1000607 (2011)
Hull, J.: Futures and Other Derivatives. Options, Options, Futures and Other Derivatives. Pearson/Prentice Hall, Upper Saddle River (2009)
Jazwinski, A.H.: Stochastic Processes and Filtering Theory. Academic Press, Cambridge (1970)
Kalman, R.E.: A new approach to linear filtering and prediction problems. J. Basic Eng. 82(1), 35–45 (1960)
Komorowski, M., Finkenstädt, B., Harper, C.V., Rand, D.A.: Bayesian inference of biochemical kinetic parameters using the linear noise approximation. BMC Bioinform. 10(1), 1–10 (2009)
Mbalawata, I.S., Särkkä, S., Haario, H.: Parameter estimation in stochastic differential equations with Markov chain Monte Carlo and non-linear Kalman filtering. Comput. Stat. 28(3), 1195–1223 (2013)
Roberts, G.O., Rosenthal, J.S.: Examples of adaptive MCMC. J. Comput. Graph. Stat. 18(2), 349–367 (2009)
Särkkä, S.: Recursive Bayesian inference on stochastic differential equations. Ph.D. Thesis, Helsinki University of Technology (2006)
Sherlock, C., Fearnhead, P., Roberts, G.O.: The random walk metropolis: linking theory and practice through a case study. Stat. Sci. 25(2), 172–190 (2010)
Spiller, D.G., Wood, C.D., Rand, D.A., White, M.R.H.: Measurement of single-cell dynamics. Nature 465(7299), 736–745 (2010)
van Kampen, N.: Stochastic Processes in Physics and Chemistry, 3rd edn. Elsevier, Amsterdam (2007)
Wilkinson, D.J.: Stochastic modelling for systems biology. In: Chapman & Hall/CRC Mathematical and Computational Biology, 2nd edn. Taylor & Francis (2011)
Acknowledgements
MR was funded by the UK’s Medical Research Council (award MR/M008908/1).
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
1.1 Mean and variance of the integrated process
We start by computing \(\mathbb {E}[Q_t]\), i.e. the mean of \(Q_t\). We know that:
Averaging Eq. (26), dividing by \(\mathrm{d}t\) and letting \(\mathrm{d}t\rightarrow 0\), gives us:
The mean of \(Q_t\) is set to zero, as we have chosen to use the Restarting LNA.
We now need to compute the covariance between \(Q_t\) and \(\xi _t\). Again \(\mathbb {E}[Q_t] = 0\) and \(\mathbb {E}[\xi _t] = 0\) since we are using the Restarting LNA and thus, the covariance is given by \(\mathbb {E}[Q_t\xi _t^T]\). For our derivation, we need to use:
By multiplying Eqs. (26) and (28) we get:
Averaging the result (29), retaining terms up to first order in \(\mathrm{d}t\), dividing by \(\mathrm{d}t\) and letting \(\mathrm{d}t\rightarrow 0\), we get:
The variance of \(Q_t\) is given by \(\mathrm {Var}[Q_t]=\mathbb {E}[Q_tQ_t^T]\) since \(\mathbb {E}[Q_t] = 0\). We have that,
By averaging (31), retaining terms up to first order in \(\mathrm{d}t\), dividing by \(\mathrm{d}t\) and letting \(\mathrm{d}t\rightarrow 0\), we get:
1.2 Useful Gaussian identities
Let x and y be jointly Gaussian random vectors:
Then, the marginal and conditional distributions of x (equivalently for y) are, respectively (Bishop 2007):
1.3 Update equations of a discrete Kalman Filter
Using the Gaussian Identities in A.2 we have
Since we are working with Gaussians, we know that \(X_i|y_{1:i}\sim N(m_i^*,S_i^*)\), and the updated \(m_i^*\) and \(S_i^*\) are given by:
1.4 Analytical solutions for the OU process and its integral
Given an OU process of the following form:
we can derive its solution according to the general theory for linear SDEs. Since the solution is a Gaussian process, we will only need to define its mean and variance which are given by Eqs. (6, 7). All the ODEs in this case are first-order linear ODEs with constant coefficients, so using for example an integrating factor, we can derive the following solution for an ODE of the form \(\frac{\mathrm{d}x}{\mathrm{d}t}+ax=g(t), \quad x(t=0)=x_0\):
For the mean we get from Eq. (6):
For the variance we have the following:
For the solution of the integrated OU process \(\mathrm{d}Y_t/\mathrm{d}t = X_t \), we need to calculate its mean, covariance and variance given by Eqs. (12), (13) and (14). The initial conditions for these ODEs will be set to 0, since at each observation point the integrated process starts from 0. For clarity, we will use the results A, B, C from “Appendix A.5”.
First we find the mean:
For the covariance, we first calculate from Eq. (13):
Now the covariance can be calculated from:
For the variance, we need to calculate:
Now we can derive the variance:
1.5 Frequently used integrals for part (A.4)
1.6 Exact updating formula of OU process
The OU process \(\mathrm{d}X_t = -\alpha X_t\mathrm{d}t + \sigma \mathrm{d}W_t\) admits an exact update formula given by Gillespie (1992):
1.7 Average over 10 datasets—OU example
See Table 5.
1.8 LNA for Lotka–Volterra model
The Lotka–Volterra model (23) gives rise to the stoichiometry matrix,
with transition rates,
The following matrices need to be computed:
The macroscopic rate equations are now given by:

Simulated trajectories from an OU process with \(\alpha =4\) and \(\sigma =2\), along with the corresponding aggregated process with an integration period of 2 min. For the aggregated process, we assumed observations every 2 min, which are indicated by red crosses. a OU process. b Aggregated process

MCMC traces of the posterior of \(\alpha \) using a random walk MH for both KF1 and KF2. Ground truth for \(\alpha = 4\)

MCMC traces of the posterior of \(\sigma \) using a random walk MH for both KF1 and KF2. Ground truth for \(\sigma = 2\)
For the diffusion terms, we only need to compute the variance of the resulting Gaussian process since we restart the stochastic part at each observation point in accordance with (Fearnhead et al. 2014).
V is a symmetric matrix so \(V_{12} = V_{21}\). So:
The integrated process \(\mathrm{d}Y_t = X_t\mathrm{d}t\) follows Eqs. (10),(13),(14). The deterministic part is given by:
The ODEs for its integrated variance and covariance with the underline process \(X_t\) are given below, where \(\mathrm {Cov}(YX^T) = C_t= \begin{bmatrix} C_{11}&C_{12}\\ C_{21}&C_{22} \end{bmatrix} \) and \(\mathrm {Var}(Y) = G_t\):
such as,

Filtering results from KF1 and KF2 for an OU process with \(\alpha = 4.0\) and \(\sigma = 2.0\) (blue trace) using aggregated data over an integration period of \(\Delta = 1.0\). Black lines correspond to the posterior mean estimate and green lines to 1 s.d.. For inference, we used the estimated parameters from A.7. a KF1 (\(\Delta =1.0\)). b KF2 (\(\Delta =1.0\)). (Color figure online)
1.9 Adaptive MCMC
According to the specific adaptive MH (Sherlock et al. 2010), the new state \(\theta ^*\) is sampled from a mixture of Gaussians:
\(\varSigma _t\) corresponds to the sampled variance up to iteration t and is estimated after enough samples have been accepted. The parameter \(\delta \in (0,1)\) and is defined by the user, we have chosen a value of 0.05. The scaling factor \(\lambda \) can either be fixed (Roberts and Rosenthal 2009) or be tuned (Sherlock et al. 2010). This algorithm targets an acceptance rate of \(\approx 0.3\).

MCMC traceplots for the LV experiment using an adaptive MCMC algorithm. a MCMC traceplots for \(\theta _1\). b MCMC traceplots for \(\theta _2\). c MCMC traceplots for \(\theta _3\)

Filtering results for the predator population. Red dots correspond to aggregated observations, and the black line represents the actual process. Purple lines represent the mean estimate and green 1 s.d. . a Filtering results for the predator population using KF1. b Filtering results for the predator population using KF2
1.10 Nelder Mead results for LV model
See Table 6.
1.11 LNA for translation inhibition model
The following model is being assumed where R and P stand for the (numbers of) gene mRNA and protein, respectively:
The above equations result in the following stoichiometry matrix:
and the transition rates are :
The required matrices are calculated below:

Adaptive MCMC traces of the posterior vector \((c_p,d_p,s,k,m_0)\) using synthetic data with KF1 and KF2

Three MCMC chains of the posterior vector \((c_p,d_p,s,k,m_0)\) using single cell data with KF1
The deterministic part is now given by:
The stochastic part is given by the (restarting) LNA where we have dropped the dependency of \(M_t,V_t\) from time:
resulting in the following ODE for the stochastic variance:
For the integrated process, we get the following according to Eqs. (10),(13) and (14) (Fig. 5). First the deterministic part is given by:
The stochastic part is given by:
resulting in the following ODEs for its integrated variance and covariance with the unintegrated process:
1.12 OU and aggregated OU process
See Fig. 5.
1.13 OU traceplots
Figures 6 and 7 show samples of the OU parameters during the MCMC runs.

Three MCMC chains of the posterior vector \((c_p,d_p,s,k,m_0)\) using single cell data with KF2
1.14 Filtering results for OU process using aggregated data
See Fig. 8.
1.15 MCMC traces from LV experiment
See Fig. 9.
1.16 Filtering results for the predator population
See Fig. 10.
1.17 MCMC traces for Translation inhibition example with synthetic data
See Fig. 11.
1.18 MCMC traces for translation inhibition example with single cell data
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Folia, M.M., Rattray, M. Trajectory inference and parameter estimation in stochastic models with temporally aggregated data. Stat Comput 28, 1053–1072 (2018). https://doi.org/10.1007/s11222-017-9779-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11222-017-9779-x