Nature Machine Intelligence ( IF 23.8 ) Pub Date : 2019-12-02 , DOI: 10.1038/s42256-019-0112-6 Martin Gerlach , Hanyu Shi , Luís A. Nunes Amaral
|
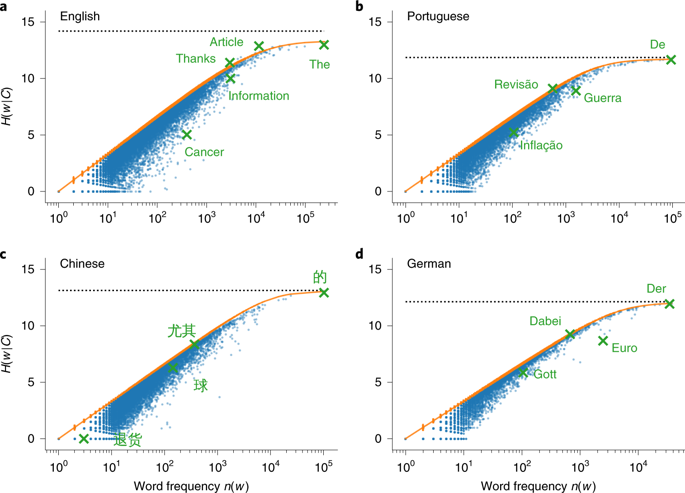
One of the most widely used approaches in natural language processing and information retrieval is the so-called bag-of-words model. A common component of such methods is the removal of uninformative words, commonly referred to as stopwords. Currently, most practitioners use manually curated stopword lists. This approach is problematic because it cannot be readily generalized across knowledge domains or languages. As a result of the difficulty in rigorously defining stopwords, there have been few systematic studies on the effect of stopword removal on algorithm performance, which is reflected in the ongoing debate on whether to keep or remove stopwords. Here we address this challenge by formulating an information theoretic framework that automatically identifies uninformative words in a corpus. We show that our framework not only outperforms other stopword heuristics, but also allows for a substantial reduction of document size in applications of topic modelling. Our findings can be readily generalized to other bag-of-words-type approaches beyond language such as in the statistical analysis of transcriptomics, audio or image corpora.
中文翻译:
识别停用词的通用信息理论方法
在自然语言处理和信息检索中使用最广泛的方法之一是所谓的词袋模型。这种方法的一个常见组成部分是删除非信息性单词,通常称为停用词。当前,大多数从业者使用手动策划的停用词列表。这种方法是有问题的,因为它不能轻易地跨知识领域或语言进行概括。由于很难严格定义停用词,因此很少有关于停用词对算法性能的影响的系统研究,这反映在有关是否保留或删除停用词的争论中。在这里,我们通过制定一种信息理论框架来应对这一挑战,该框架可以自动识别语料库中的非信息性单词。我们表明,我们的框架不仅优于其他停用词启发式算法,而且还可以在主题建模应用程序中大幅减少文档的大小。我们的发现可以很容易地推广到语言以外的其他词袋式方法,例如在转录组学,音频或图像语料库的统计分析中。


























 京公网安备 11010802027423号
京公网安备 11010802027423号