当前位置:
X-MOL 学术
›
J. Expo. Sci. Environ. Epid.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Latent classes for chemical mixtures analyses in epidemiology: an example using phthalate and phenol exposure biomarkers in pregnant women.
Journal of Exposure Science and Environmental Epidemiology ( IF 4.5 ) Pub Date : 2019-10-21 , DOI: 10.1038/s41370-019-0181-y Rachel Carroll 1, 2 , Alexandra J White 3 , Alexander P Keil 3, 4 , John D Meeker 5 , Thomas F McElrath 6 , Shanshan Zhao 1 , Kelly K Ferguson 3
Journal of Exposure Science and Environmental Epidemiology ( IF 4.5 ) Pub Date : 2019-10-21 , DOI: 10.1038/s41370-019-0181-y Rachel Carroll 1, 2 , Alexandra J White 3 , Alexander P Keil 3, 4 , John D Meeker 5 , Thomas F McElrath 6 , Shanshan Zhao 1 , Kelly K Ferguson 3
Affiliation
|
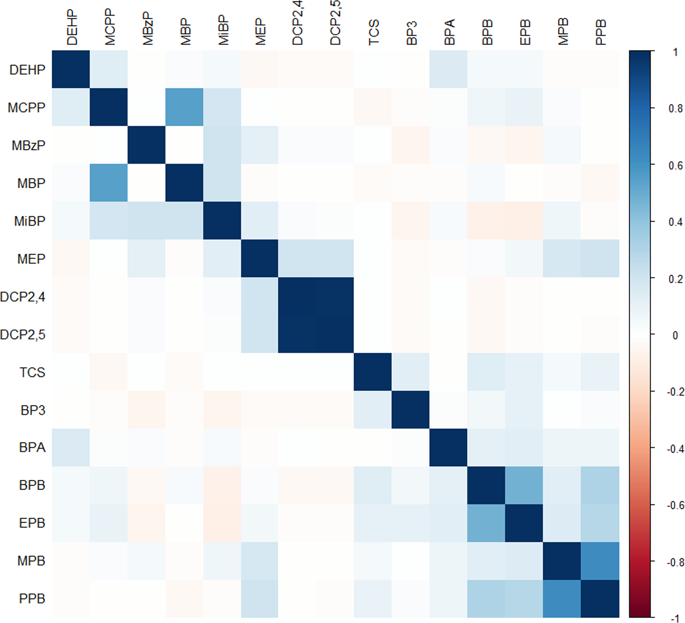
Latent class analysis (LCA), although minimally applied to the statistical analysis of mixtures, may serve as a useful tool for identifying individuals with shared real-life profiles of chemical exposures. Knowledge of these groupings and their risk of adverse outcomes has the potential to inform targeted public health prevention strategies. This example applies LCA to identify clusters of pregnant women from a case-control study within the LIFECODES birth cohort with shared exposure patterns across a panel of urinary phthalate metabolites and parabens, and to evaluate the association between cluster membership and urinary oxidative stress biomarkers. LCA identified individuals with: "low exposure," "low phthalates, high parabens," "high phthalates, low parabens," and "high exposure." Class membership was associated with several demographic characteristics. Compared with "low exposure," women classified as having "high exposure" had elevated urinary concentrations of the oxidative stress biomarkers 8-hydroxydeoxyguanosine (19% higher, 95% confidence interval [CI] = 7, 32%) and 8-isoprostane (31% higher, 95% CI = -5, 64%). However, contrast examinations indicated that associations between oxidative stress biomarkers and "high exposure" were not statistically different from those with "high phthalates, low parabens" suggesting a minimal effect of higher paraben exposure in the presence of high phthalates. The presented example offers verification of latent class assignments through application to an additional data set as well as a comparison to another unsupervised clustering approach, k-means clustering. LCA may be more easily implemented, more consistent, and more able to provide interpretable output.
中文翻译:

流行病学中化学混合物分析的潜在类别:以孕妇使用邻苯二甲酸盐和苯酚暴露生物标志物为例。
潜在类别分析(LCA)尽管很少用于混合物的统计分析,但它可能是一种有用的工具,可用来识别具有共享的真实生活中化学暴露特征的个人。了解这些类别及其不良后果的风险有可能为有针对性的公共卫生预防策略提供信息。本示例应用LCA从LIFECODES出生队列中的病例对照研究中识别出孕妇集群,并通过一组尿邻苯二甲酸酯代谢产物和对羟基苯甲酸酯的共有暴露模式进行评估,并评估集群成员与尿液氧化应激生物标志物之间的关联。LCA将个体识别为:“低暴露”,“低邻苯二甲酸盐,高对羟基苯甲酸酯”,“高邻苯二甲酸盐,低对羟基苯甲酸酯”和“高暴露”。班级成员资格与几个人口统计学特征有关。与“低暴露”相比,被归类为“高暴露”的女性尿液中氧化应激生物标记物8-羟基脱氧鸟苷的浓度较高(高19%,95%置信区间[CI] = 7、32%)和8-异前列腺素(高31%,95%CI = -5,64%)。然而,对比检查表明,氧化应激生物标志物与“高暴露”之间的关联与“高邻苯二甲酸酯,低对羟基苯甲酸酯”的相关性在统计学上没有差异,这表明在高邻苯二甲酸酯存在下高对羟基苯甲酸酯暴露的影响最小。呈现的示例通过应用到其他数据集以及与另一种无监督聚类方法的比较,提供了对潜在类分配的验证,k均值聚类。LCA可能更容易实现,更一致,并且更能够提供可解释的输出。
更新日期:2019-10-21
中文翻译:
流行病学中化学混合物分析的潜在类别:以孕妇使用邻苯二甲酸盐和苯酚暴露生物标志物为例。
潜在类别分析(LCA)尽管很少用于混合物的统计分析,但它可能是一种有用的工具,可用来识别具有共享的真实生活中化学暴露特征的个人。了解这些类别及其不良后果的风险有可能为有针对性的公共卫生预防策略提供信息。本示例应用LCA从LIFECODES出生队列中的病例对照研究中识别出孕妇集群,并通过一组尿邻苯二甲酸酯代谢产物和对羟基苯甲酸酯的共有暴露模式进行评估,并评估集群成员与尿液氧化应激生物标志物之间的关联。LCA将个体识别为:“低暴露”,“低邻苯二甲酸盐,高对羟基苯甲酸酯”,“高邻苯二甲酸盐,低对羟基苯甲酸酯”和“高暴露”。班级成员资格与几个人口统计学特征有关。与“低暴露”相比,被归类为“高暴露”的女性尿液中氧化应激生物标记物8-羟基脱氧鸟苷的浓度较高(高19%,95%置信区间[CI] = 7、32%)和8-异前列腺素(高31%,95%CI = -5,64%)。然而,对比检查表明,氧化应激生物标志物与“高暴露”之间的关联与“高邻苯二甲酸酯,低对羟基苯甲酸酯”的相关性在统计学上没有差异,这表明在高邻苯二甲酸酯存在下高对羟基苯甲酸酯暴露的影响最小。呈现的示例通过应用到其他数据集以及与另一种无监督聚类方法的比较,提供了对潜在类分配的验证,k均值聚类。LCA可能更容易实现,更一致,并且更能够提供可解释的输出。

























 京公网安备 11010802027423号
京公网安备 11010802027423号