Food Chemistry ( IF 8.8 ) Pub Date : 2023-01-27 , DOI: 10.1016/j.foodchem.2023.135548 Rachel Ferraz de Camargo 1 , Tiago Rodrigues Tavares 1 , Nicolas Gustavo da Cruz da Silva 1 , Eduardo de Almeida 1 , Hudson Wallace Pereira de Carvalho 1
|
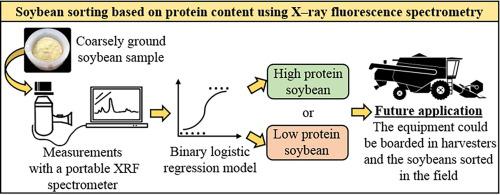
The purpose of this research was to evaluate performance of an energy-dispersive X-ray fluorescence (XRF) sensor to classify soybean based on protein content. The hypothesis was that sulfur signals and other XRF spectral features can be used as proxies to infer soybean protein content. Sample preparation and equipment settings to optimize detection of S and other specific emission lines were tested for this application. A logistic regression model for classifying soybean as high- or low-protein was developed based on XRF spectra and protein contents. Additionally, the model was validated with an independent set of samples. Global accuracy of the method was 0.83 (training set) and 0.81 (test set) and the corresponding kappa indices were 0.66 and 0.61, respectively. These numbers indicated satisfactory performance of the sensor, suggesting that XRF spectral features can be applied for screening protein content in soybean.
中文翻译:
使用 X 射线荧光光谱法根据蛋白质含量对大豆进行分类
本研究的目的是评估能量色散 X 射线荧光 (XRF) 传感器根据蛋白质含量对大豆进行分类的性能。假设是硫信号和其他 XRF 光谱特征可以用作推断大豆蛋白质含量的代理。针对此应用测试了样品制备和设备设置,以优化 S 和其他特定发射线的检测。基于 XRF 光谱和蛋白质含量开发了将大豆分类为高蛋白质或低蛋白质的逻辑回归模型。此外,该模型还使用一组独立的样本进行了验证。该方法的全局准确度为 0.83(训练集)和 0.81(测试集),相应的 kappa 指数分别为 0.66 和 0.61。这些数字表明传感器的性能令人满意,


























 京公网安备 11010802027423号
京公网安备 11010802027423号