Complex & Intelligent Systems ( IF 5.8 ) Pub Date : 2022-11-24 , DOI: 10.1007/s40747-022-00909-0 Rongyun Zhang , Yufeng Du , Peicheng Shi , Lifeng Zhao , Yaming Liu , Haoran Li
|
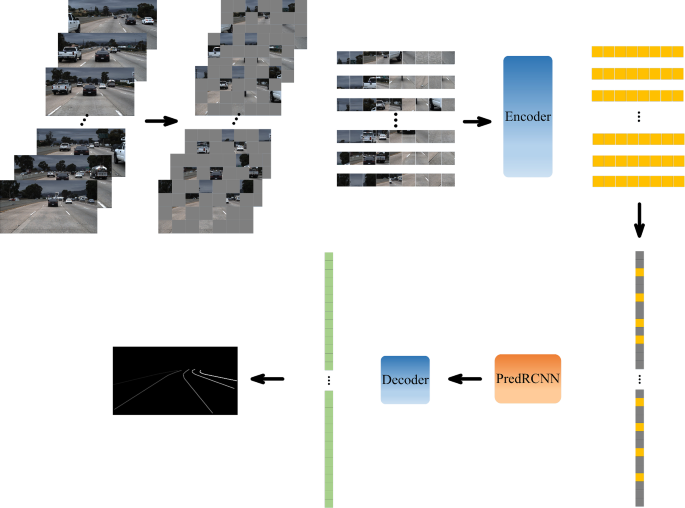
Lane detection is one of the key techniques to realize advanced driving assistance and automatic driving. However, lane detection networks based on deep learning have significant shortcomings. The detection results are often unsatisfactory when there are shadows, degraded lane markings, and vehicle occlusion lanes. Therefore, a continuous multi-frame image sequence lane detection network is proposed. Specifically, the continuous six-frame image sequence is input into the network, in which the scene information of each frame image is extracted by an encoder composed of Swin Transformer blocks and input into the PredRNN. Continuous multi-frame of the driving scene is modeled as time-series by ST-LSTM blocks, and then, the shape changes and motion trajectory in the spatiotemporal sequence are effectively modeled. Finally, through the decoder composed of Swin Transformer blocks, the features are obtained and reconstructed to complete the detection task. Extensive experiments on two large-scale datasets demonstrate that the proposed method outperforms the competing methods in lane detection, especially in handling difficult situations. Experiments are carried out based on the TuSimple dataset. The results show: for easy scenes, the validation accuracy is 97.46%, the test accuracy is 97.37%, and the precision is 0.865. For complex scenes, the validation accuracy is 97.38%, the test accuracy is 97.29%, and the precision is 0.859. The running time is 4.4 ms. Experiments are carried out based on the CULane dataset. The results show that, for easy scenes, the validation accuracy is 97.03%, the test accuracy is 96.84%, and the precision is 0.837. For complex scenes, the validation accuracy is 96.18%, the test accuracy is 95.92%, and the precision is 0.829. The running time is 6.5 ms.
中文翻译:
ST-MAE:基于深度混合网络的连续多帧驾驶场景中的鲁棒车道检测
车道检测是实现高级驾驶辅助和自动驾驶的关键技术之一。然而,基于深度学习的车道检测网络存在明显的缺点。当存在阴影、退化的车道标记和车辆遮挡车道时,检测结果往往不尽如人意。因此,提出了一种连续的多帧图像序列车道检测网络。具体来说,将连续的六帧图像序列输入到网络中,其中每帧图像的场景信息通过由Swin Transformer块组成的编码器提取并输入到PredRNN中。通过ST-LSTM块将驾驶场景的连续多帧建模为时间序列,然后有效地对时空序列中的形状变化和运动轨迹进行建模。最后,通过由Swin Transformer块组成的解码器,获取并重构特征,完成检测任务。在两个大型数据集上进行的大量实验表明,所提出的方法优于车道检测中的竞争方法,尤其是在处理困难情况时。基于TuSimple数据集进行实验。结果表明:对于简单场景,验证准确率为97.46%,测试准确率为97.37%,精度为0.865。对于复杂场景,验证准确率为97.38%,测试准确率为97.29%,精度为0.859。运行时间为 4.4 毫秒。基于CULane数据集进行实验。结果表明,对于简单场景,验证准确率为97.03%,测试准确率为96.84%,精度为0.837。对于复杂的场景,验证准确率为96.18%,测试准确率为95.92%,精度为0.829。运行时间为 6.5 毫秒。

























 京公网安备 11010802027423号
京公网安备 11010802027423号