当前位置:
X-MOL 学术
›
J. Chem. Inf. Model.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Few-Shot Learning for Low-Data Drug Discovery
Journal of Chemical Information and Modeling ( IF 5.6 ) Pub Date : 2022-11-21 , DOI: 10.1021/acs.jcim.2c00779 Daniel Vella 1 , Jean-Paul Ebejer 1, 2
Journal of Chemical Information and Modeling ( IF 5.6 ) Pub Date : 2022-11-21 , DOI: 10.1021/acs.jcim.2c00779 Daniel Vella 1 , Jean-Paul Ebejer 1, 2
Affiliation
|
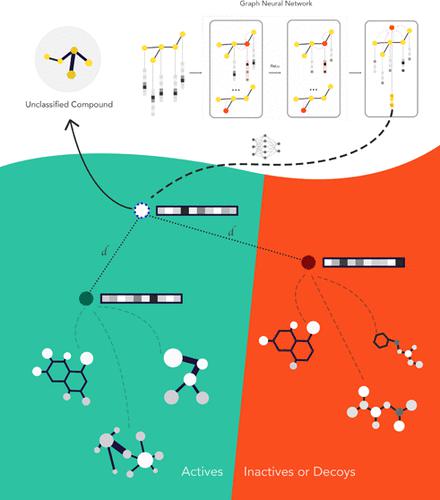
The discovery of new hits through ligand-based virtual screening in drug discovery is essentially a low-data problem, as data acquisition is both difficult and expensive. The requirement for large amounts of training data hinders the application of conventional machine learning techniques to this problem domain. This work explores few-shot machine learning for hit discovery and lead optimization. We build on the state-of-the-art and introduce two new metric-based meta-learning techniques, Prototypical and Relation Networks, to this problem domain. We also explore using different embeddings, namely, extended-connectivity fingerprints (ECFP) and embeddings generated through graph convolutional networks (GCN), as inputs to neural networks for classification. This study shows that learned embeddings through GCNs consistently perform better than extended-connectivity fingerprints for toxicity and LBVS experiments. We conclude that the effectiveness of few-shot learning is highly dependent on the nature of the data. Few-shot learning models struggle to perform consistently on MUV and DUD-E data, in which the active compounds are structurally distinct. However, on Tox21 data, the few-shot models perform well, and we find that Prototypical Networks outperform the state-of-the-art, which is based on the Matching Networks architecture. Additionally, training these networks is substantially faster (up to 190%) and therefore takes a fraction of the time to train for comparable, or better, results.
中文翻译:

低数据药物发现的小样本学习
在药物发现中通过基于配体的虚拟筛选发现新命中本质上是一个低数据问题,因为数据获取既困难又昂贵。对大量训练数据的要求阻碍了传统机器学习技术在这个问题领域的应用。这项工作探索了用于命中发现和先导优化的少样本机器学习。我们以最先进的技术为基础,向这个问题领域引入了两种新的基于度量的元学习技术,原型和关系网络。我们还探索使用不同的嵌入,即扩展连接指纹 (ECFP) 和通过图卷积网络 (GCN) 生成的嵌入,作为神经网络的输入进行分类。这项研究表明,通过 GCN 学习的嵌入在毒性和 LBVS 实验中始终比扩展连接指纹表现更好。我们得出结论,小样本学习的有效性在很大程度上取决于数据的性质。Few-shot 学习模型难以在 MUV 和 DUD-E 数据上始终如一地执行,其中活性化合物在结构上是不同的。然而,在 Tox21 数据上,小样本模型表现良好,我们发现原型网络优于基于匹配网络架构的最新技术。此外,训练这些网络的速度要快得多(高达 190%),因此只需花费一小部分时间来训练可比或更好的结果。我们得出结论,小样本学习的有效性在很大程度上取决于数据的性质。Few-shot 学习模型难以在 MUV 和 DUD-E 数据上始终如一地执行,其中活性化合物在结构上是不同的。然而,在 Tox21 数据上,小样本模型表现良好,我们发现原型网络优于基于匹配网络架构的最新技术。此外,训练这些网络的速度要快得多(高达 190%),因此只需花费一小部分时间来训练可比或更好的结果。我们得出结论,小样本学习的有效性在很大程度上取决于数据的性质。Few-shot 学习模型难以在 MUV 和 DUD-E 数据上始终如一地执行,其中活性化合物在结构上是不同的。然而,在 Tox21 数据上,小样本模型表现良好,我们发现原型网络优于基于匹配网络架构的最新技术。此外,训练这些网络的速度要快得多(高达 190%),因此只需花费一小部分时间来训练可比或更好的结果。我们发现原型网络优于基于匹配网络架构的最先进技术。此外,训练这些网络的速度要快得多(高达 190%),因此只需花费一小部分时间来训练可比或更好的结果。我们发现原型网络优于基于匹配网络架构的最先进技术。此外,训练这些网络的速度要快得多(高达 190%),因此只需花费一小部分时间来训练可比或更好的结果。
更新日期:2022-11-21
中文翻译:
低数据药物发现的小样本学习
在药物发现中通过基于配体的虚拟筛选发现新命中本质上是一个低数据问题,因为数据获取既困难又昂贵。对大量训练数据的要求阻碍了传统机器学习技术在这个问题领域的应用。这项工作探索了用于命中发现和先导优化的少样本机器学习。我们以最先进的技术为基础,向这个问题领域引入了两种新的基于度量的元学习技术,原型和关系网络。我们还探索使用不同的嵌入,即扩展连接指纹 (ECFP) 和通过图卷积网络 (GCN) 生成的嵌入,作为神经网络的输入进行分类。这项研究表明,通过 GCN 学习的嵌入在毒性和 LBVS 实验中始终比扩展连接指纹表现更好。我们得出结论,小样本学习的有效性在很大程度上取决于数据的性质。Few-shot 学习模型难以在 MUV 和 DUD-E 数据上始终如一地执行,其中活性化合物在结构上是不同的。然而,在 Tox21 数据上,小样本模型表现良好,我们发现原型网络优于基于匹配网络架构的最新技术。此外,训练这些网络的速度要快得多(高达 190%),因此只需花费一小部分时间来训练可比或更好的结果。我们得出结论,小样本学习的有效性在很大程度上取决于数据的性质。Few-shot 学习模型难以在 MUV 和 DUD-E 数据上始终如一地执行,其中活性化合物在结构上是不同的。然而,在 Tox21 数据上,小样本模型表现良好,我们发现原型网络优于基于匹配网络架构的最新技术。此外,训练这些网络的速度要快得多(高达 190%),因此只需花费一小部分时间来训练可比或更好的结果。我们得出结论,小样本学习的有效性在很大程度上取决于数据的性质。Few-shot 学习模型难以在 MUV 和 DUD-E 数据上始终如一地执行,其中活性化合物在结构上是不同的。然而,在 Tox21 数据上,小样本模型表现良好,我们发现原型网络优于基于匹配网络架构的最新技术。此外,训练这些网络的速度要快得多(高达 190%),因此只需花费一小部分时间来训练可比或更好的结果。我们发现原型网络优于基于匹配网络架构的最先进技术。此外,训练这些网络的速度要快得多(高达 190%),因此只需花费一小部分时间来训练可比或更好的结果。我们发现原型网络优于基于匹配网络架构的最先进技术。此外,训练这些网络的速度要快得多(高达 190%),因此只需花费一小部分时间来训练可比或更好的结果。

























 京公网安备 11010802027423号
京公网安备 11010802027423号