Journal of Real-Time Image Processing ( IF 3 ) Pub Date : 2022-09-21 , DOI: 10.1007/s11554-022-01253-9 Jiyuan Hu , Tao Wang , Shiqiang Zhu
|
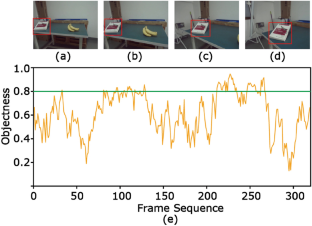
Object detection plays an important role on various mobile robot tasks. However, directly applying existing detectors on videos from a mobile robot will cause a sharp accuracy decline, because such videos introduce some extra difficulties on accurate detection. This paper proposes a viewpoint-based memory mechanism to handle detection performance deterioration and improve detection accuracy of the videos in real time. The mechanism positively organizes previous results from multiple viewpoints of target objects as prior knowledge to enhance detection accuracy for succeeding frames, and it is designed as an extension module of an existing image detector. In experiments, we collect testing dataset from an indoor mobile robot, and compare performance of several sole image detectors and the same detectors extended by the extension module. The result shows the mechanism module achieves 20.7% object localization rate margin in average at a cost of 18.1 ms, and the mechanism can give positive impact on various existing detectors. The result indicates the proposed method achieves good accuracy margin, has acceptable time cost, and gets a degree of universal applicability.
中文翻译:
多视图聚合,用于移动相机的实时准确对象检测
目标检测在各种移动机器人任务中发挥着重要作用。然而,直接将现有的检测器应用于移动机器人的视频会导致准确率急剧下降,因为这样的视频会给准确检测带来一些额外的困难。本文提出了一种基于视点的记忆机制来实时处理检测性能恶化并提高视频的检测精度。该机制积极地将目标对象多个视点的先前结果组织为先验知识,以提高后续帧的检测精度,并将其设计为现有图像检测器的扩展模块。在实验中,我们从一个室内移动机器人收集测试数据集,并比较了几个唯一图像检测器和扩展模块扩展的相同检测器的性能。结果表明,该机制模块以 18.1 ms 的成本平均实现了 20.7% 的目标定位率余量,该机制可以对现有的各种检测器产生积极影响。结果表明,该方法取得了良好的准确率,具有可接受的时间成本,并具有一定的普遍适用性。


























 京公网安备 11010802027423号
京公网安备 11010802027423号