Journal of Signal Processing Systems ( IF 1.8 ) Pub Date : 2022-07-20 , DOI: 10.1007/s11265-022-01782-3 Seokhyeon Choi , Kyuhong Shim , Jungwook Choi , Wonyong Sung , Byonghyo Shim
|
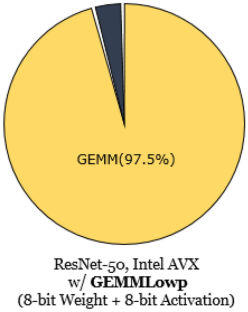
Efficient implementation of deep neural networks (DNNs) on CPU-based systems is critical owing to the proliferation of applications in embedded and Internet of Things systems. Nowdays, most CPUs are equipped with single instruction multiple data (SIMD) instructions, which are used to implement an efficient general matrix multiply (GEMM) library for accelerating DNN inference. Quantized neural networks are actively investigated to simplify DNN computation and memory requirements; however, the current CPU libraries do not efficiently support arithmetic operations below eight bits. Hence, we developed TernGEMM, a GEMM library composed of SIMD instructions for DNNs with ternary weights and sub-8-bit activations. TernGEMM is implemented using simple logical operations that replace the long-latency multiply–add operation. Instead of fixing the accumulation bit precision as 32-bit, TernGEMM accumulates the partial sums in a bit-incremental manner to exploit parallelism in 8-bit and 16-bit SIMD instructions. Furthermore, we propose different tile sizes for TernGEMM to better support the diverse dimensions of DNNs. Compared with a state-of–the-art reduced precision DNN GEMM library, i.e., GEMMLowp, TernGEMM achieve \(\times\)1.785 to \(\times\)4.147 speedup for ResNet50, MobileNet-V2, and EfficientNet-B0, as evaluated on both Intel and ARM CPUs.
中文翻译:
用于快速 DNN 推理的三元权重通用矩阵乘库优化
由于嵌入式和物联网系统中应用程序的激增,在基于 CPU 的系统上有效实施深度神经网络 (DNN) 至关重要。如今,大多数 CPU 都配备了单指令多数据 (SIMD) 指令,用于实现高效的通用矩阵乘法 (GEMM) 库以加速 DNN 推理。积极研究量化神经网络以简化 DNN 计算和内存要求;但是,当前的 CPU 库不能有效地支持 8 位以下的算术运算。因此,我们开发了 TernGEMM,这是一个由 SIMD 指令组成的 GEMM 库,用于具有三元权重和亚 8 位激活的 DNN。TernGEMM 是使用简单的逻辑操作来实现的,该操作取代了长延迟乘加操作。TernGEMM 没有将累加位精度固定为 32 位,而是以位增量方式累加部分和,以利用 8 位和 16 位 SIMD 指令中的并行性。此外,我们为 TernGEMM 提出了不同的图块大小,以更好地支持 DNN 的不同维度。与最先进的降低精度 DNN GEMM 库相比,即 GEMMLowp、TernGEMM 实现在 Intel 和 ARM CPU 上评估,ResNet50、MobileNet-V2 和 EfficientNet-B0 的\(\times\) 1.785 到\(\times\) 4.147 加速。


























 京公网安备 11010802027423号
京公网安备 11010802027423号