Foundations of Computational Mathematics ( IF 3 ) Pub Date : 2022-06-14 , DOI: 10.1007/s10208-022-09568-6 Charles Bordenave , Simon Coste , Raj Rao Nadakuditi
|
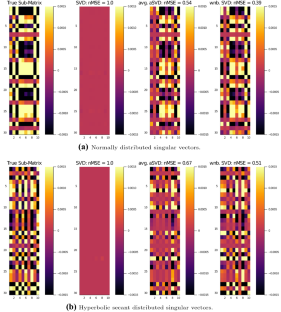
We study the matrix completion problem: an underlying \(m \times n\) matrix P is low rank, with incoherent singular vectors, and a random \(m \times n\) matrix A is equal to P on a (uniformly) random subset of entries of size dn. All other entries of A are equal to zero. The goal is to retrieve information on P from the observation of A. Let \(A_1\) be the random matrix where each entry of A is multiplied by an independent \(\{0,1\}\)-Bernoulli random variable with parameter 1/2. This paper is about when, how and why the non-Hermitian eigen-spectra of the matrices \(A_1 (A - A_1)^*\) and \((A-A_1)^*A_1\) captures more of the relevant information about the principal component structure of A than the eigen-spectra of \(A A^*\) and \(A^* A\). We show that the eigenvalues of the asymmetric matrices \(A_{1} (A - A_{1})^{*}\) and \((A-A_{1})^{*} A_{1}\) with modulus greater than a detection threshold are asymptotically equal to the eigenvalues of \(PP^*\) and \(P^*P\) and that the associated eigenvectors are aligned as well. The central surprise is that by intentionally inducing asymmetry and additional randomness via the \(A_1\) matrix, we can extract more information than if we had worked with the singular value decomposition (SVD) of A. The associated detection threshold is asymptotically exact and is non-universal since it explicitly depends on the element-wise distribution of the underlying matrix P. We show that reliable, statistically optimal but not perfect matrix recovery, via a universal data-driven algorithm, is possible above this detection threshold using the information extracted from the asymmetric eigen-decompositions. Averaging the left and right eigenvectors provably improves estimation accuracy but not the detection threshold. Our results encompass the very sparse regime where d is of order 1 where matrix completion via the SVD of A fails or produces unreliable recovery. We define another variant of this asymmetric principal component analysis procedure that bypasses the randomization step and has a detection threshold that is smaller by a constant factor but with a computational cost that is larger by a polynomial factor of the number of observed entries. Both detection thresholds allow to go beyond the barrier due to the well-known information theoretical limit \(d \asymp \log n\) for exact matrix completion found in the literature.
中文翻译:
非常稀疏矩阵完成中的检测阈值
我们研究矩阵补全问题:一个底层\(m\times n\)矩阵P是低秩的,具有不连贯的奇异向量,并且随机\(m\times n\)矩阵A等于P在 a 上(一致)大小为dn的条目的随机子集。A的所有其他条目都等于零。目标是从A的观察中检索P的信息。令\(A_1\)为随机矩阵,其中A的每个条目都乘以独立的\(\{0,1\}\)-Bernoulli 随机变量,参数为 1/2。本文是关于矩阵\(A_1 (A - A_1)^*\)和\((A-A_1)^*A_1\)的非厄米特特征谱何时、如何以及为何捕获更多相关信息关于A的主成分结构,而不是\(AA^*\)和\(A^* A\)的特征谱。我们证明了非对称矩阵\(A_{1} (A - A_{1})^{*}\)和\((A-A_{1})^{*} A_{1}\)的特征值模大于检测阈值的渐近等于\(PP^*\)和\(P^*P\)的特征值并且相关的特征向量也对齐。令人惊讶的是,通过\(A_1\)矩阵有意引入不对称性和额外的随机性,我们可以提取比使用 A 的奇异值分解 (SVD) 更多的信息。相关的检测阈值是渐近精确的并且是非通用的,因为它显式依赖于基础矩阵P的元素分布. 我们表明,使用从非对称特征分解中提取的信息,通过通用数据驱动算法,可靠、统计上最优但不完美的矩阵恢复可能高于该检测阈值。对左右特征向量进行平均可以证明可以提高估计精度,但不能提高检测阈值。我们的结果包括非常稀疏的区域,其中d为 1 阶,其中矩阵通过A的 SVD 完成失败或产生不可靠的恢复。我们定义了这种不对称主成分分析过程的另一个变体,它绕过了随机化步骤,并且检测阈值小了一个常数因子,但计算成本大了观察条目数的多项式因子。由于众所周知的信息理论限制\(d \asymp \log n\) ,这两个检测阈值都允许超出障碍,以便在文献中找到精确的矩阵完成。

























 京公网安备 11010802027423号
京公网安备 11010802027423号