Journal of International Business Studies ( IF 11.6 ) Pub Date : 2022-06-02 , DOI: 10.1057/s41267-022-00531-9 Arturs Kalnins
|
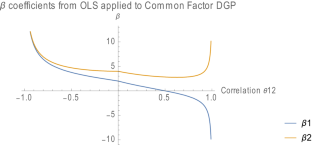
Lindner et al. (J Int Bus Stud 51:283–298, 2020; hereafter “LPV”) and Kalnins (Strateg Manag J 39(8):2362–2385, 2018) have published recent original analyses on multicollinearity, but the conclusions appear contradictory. LPV argue that multicollinearity does not affect the validity of regression coefficients, but only their reliability. In other words, multicollinearity does not bias coefficients, but only inflates standard errors. In Kalnins (2018), I conclude that multicollinearity may bias coefficients and cause type 1 errors (false positives). My goal here is to reconcile these two perspectives. I consider two data generating processes (DGPs) that create dependent variables (DVs) and apply them to specifications simulated by LPV. If the DV is generated by the Canonical DGP, that is, one which fully satisfies the Gauss–Markov assumptions, I show that previously derived econometric results generalize the conclusions of LPV. But if there are deviations from these conditions, such as in the case of a Common Factor DGP, multicollinearity acts as an amplifier of bias. I extend Kalnins’ (2018) conclusions by analyzing LPV’s specifications within the common factor context: in this case, incorporating all seemingly relevant, observable variables into a regression does not yield unbiased estimates. Coefficient estimates for variables of theoretical interest may be more accurate when correlated variables are omitted. While researchers may prefer estimates with or without a correlated variable included in a regression, both specifications should always be presented.
中文翻译:
多重共线性偏差系数何时会导致类型 1 错误?Lindner、Puck 和 Verbeke (2020) 与 Kalnins (2018) 的和解
林德纳等人。(J Int Bus Stud 51:283–298, 2020; 以下简称“LPV”) 和 Kalnins (Strateg Manag J 39(8):2362–2385, 2018) 发表了最近关于多重共线性的原始分析,但结论似乎相互矛盾。LPV 认为多重共线性不会影响回归系数的有效性,而只会影响它们的可靠性。换句话说,多重共线性不会使系数产生偏差,而只会扩大标准误。在 Kalnins (2018) 中,我得出结论,多重共线性可能会使系数产生偏差并导致 1 类错误(误报)。我的目标是调和这两种观点。我考虑了两个数据生成过程 (DGP),它们创建因变量 (DV) 并将它们应用于 LPV 模拟的规范。如果 DV 是由 Canonical DGP 生成的,即完全满足 Gauss-Markov 假设的,我表明,先前得出的计量经济学结果概括了 LPV 的结论。但是,如果与这些条件存在偏差,例如在公因数 DGP 的情况下,多重共线性会充当偏差的放大器。我通过在公因子背景下分析 LPV 的规范来扩展 Kalnins (2018) 的结论:在这种情况下,将所有看似相关的、可观察的变量合并到回归中不会产生无偏估计。当省略相关变量时,理论上感兴趣的变量的系数估计可能更准确。虽然研究人员可能更喜欢回归中包含或不包含相关变量的估计,但应始终提供两种规范。但是,如果与这些条件存在偏差,例如在公因数 DGP 的情况下,多重共线性会充当偏差的放大器。我通过在公因子背景下分析 LPV 的规范来扩展 Kalnins (2018) 的结论:在这种情况下,将所有看似相关的、可观察的变量合并到回归中不会产生无偏估计。当省略相关变量时,理论上感兴趣的变量的系数估计可能更准确。虽然研究人员可能更喜欢回归中包含或不包含相关变量的估计,但应始终提供两种规范。但是,如果与这些条件存在偏差,例如在公因数 DGP 的情况下,多重共线性会充当偏差的放大器。我通过在公因子背景下分析 LPV 的规范来扩展 Kalnins (2018) 的结论:在这种情况下,将所有看似相关的、可观察的变量合并到回归中不会产生无偏估计。当省略相关变量时,理论上感兴趣的变量的系数估计可能更准确。虽然研究人员可能更喜欢回归中包含或不包含相关变量的估计,但应始终提供两种规范。将所有看似相关的可观察变量合并到回归中不会产生无偏估计。当省略相关变量时,理论上感兴趣的变量的系数估计可能更准确。虽然研究人员可能更喜欢回归中包含或不包含相关变量的估计,但应始终提供两种规范。将所有看似相关的可观察变量合并到回归中不会产生无偏估计。当省略相关变量时,理论上感兴趣的变量的系数估计可能更准确。虽然研究人员可能更喜欢回归中包含或不包含相关变量的估计,但应始终提供两种规范。


























 京公网安备 11010802027423号
京公网安备 11010802027423号