当前位置:
X-MOL 学术
›
J. Chem. Theory Comput.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Machine Learning Force Field Aided Cluster Expansion Approach to Configurationally Disordered Materials: Critical Assessment of Training Set Selection and Size Convergence
Journal of Chemical Theory and Computation ( IF 5.5 ) Pub Date : 2022-06-03 , DOI: 10.1021/acs.jctc.2c00017 Jun-Zhong Xie 1 , Xu-Yuan Zhou 1 , Dong Luan 1 , Hong Jiang 1
Journal of Chemical Theory and Computation ( IF 5.5 ) Pub Date : 2022-06-03 , DOI: 10.1021/acs.jctc.2c00017 Jun-Zhong Xie 1 , Xu-Yuan Zhou 1 , Dong Luan 1 , Hong Jiang 1
Affiliation
|
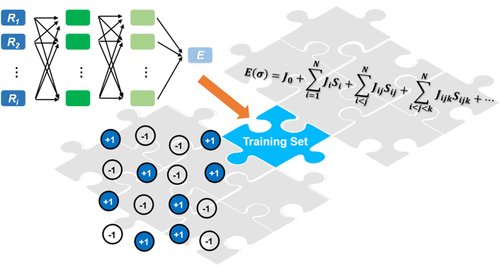
Cluster expansion (CE) is a powerful theoretical tool to study the configuration-dependent properties of substitutionally disordered systems. Typically, a CE model is built by fitting a few tens or hundreds of target quantities calculated by first-principles approaches. To validate the reliability of the model, a convergence test of the cross-validation (CV) score to the training set size is commonly conducted to verify the sufficiency of the training data. However, such a test only confirms the convergence of the predictive capability of the CE model within the training set, and it is unknown whether the convergence of the CV score would lead to robust thermodynamic simulation results such as order–disorder phase transition temperature Tc. In this work, using carbon defective MoC1–x as a model system and aided by the machine-learning force field technique, a training data pool with about 13000 configurations has been efficiently obtained and used to generate different training sets of the same size randomly. By conducting parallel Monte Carlo simulations with the CE models trained with different randomly selected training sets, the uncertainty in calculated Tc can be evaluated at different training set sizes. It is found that the training set size that is sufficient for the CV score to converge still leads to a significant uncertainty in the predicted Tc and that the latter can be considerably reduced by enlarging the training set to that of a few thousand configurations. This work highlights the importance of using a large training set to build the optimal CE model that can achieve robust statistical modeling results and the facility provided by the machine-learning force field approach to efficiently produce adequate training data.
中文翻译:

机器学习力场辅助集群扩展方法配置无序材料:训练集选择和大小收敛的关键评估
簇扩展(CE)是研究替代无序系统的配置相关属性的强大理论工具。通常,通过拟合通过第一性原理方法计算的几十或几百个目标量来构建 CE 模型。为了验证模型的可靠性,通常会进行交叉验证(CV)分数与训练集大小的收敛性测试,以验证训练数据的充分性。然而,这样的测试仅证实了 CE 模型在训练集中的预测能力的收敛性,尚不清楚 CV 分数的收敛是否会导致稳健的热力学模拟结果,例如有序 - 无序相变温度T c . 在这项工作中,使用碳缺陷 MoC 1–x作为模型系统,借助机器学习力场技术,高效地获得了大约 13000 种配置的训练数据池,用于随机生成相同大小的不同训练集。通过使用使用不同随机选择的训练集训练的 CE 模型进行并行蒙特卡罗模拟,可以在不同的训练集大小下评估计算出的T c的不确定性。发现足以使 CV 分数收敛的训练集大小仍然导致预测的T c存在显着的不确定性并且后者可以通过将训练集扩大到几千个配置来大大减少。这项工作强调了使用大型训练集来构建可以实现稳健统计建模结果的最佳 CE 模型的重要性,以及机器学习力场方法提供的设施以有效地产生足够的训练数据。
更新日期:2022-06-03
中文翻译:
机器学习力场辅助集群扩展方法配置无序材料:训练集选择和大小收敛的关键评估
簇扩展(CE)是研究替代无序系统的配置相关属性的强大理论工具。通常,通过拟合通过第一性原理方法计算的几十或几百个目标量来构建 CE 模型。为了验证模型的可靠性,通常会进行交叉验证(CV)分数与训练集大小的收敛性测试,以验证训练数据的充分性。然而,这样的测试仅证实了 CE 模型在训练集中的预测能力的收敛性,尚不清楚 CV 分数的收敛是否会导致稳健的热力学模拟结果,例如有序 - 无序相变温度T c . 在这项工作中,使用碳缺陷 MoC 1–x作为模型系统,借助机器学习力场技术,高效地获得了大约 13000 种配置的训练数据池,用于随机生成相同大小的不同训练集。通过使用使用不同随机选择的训练集训练的 CE 模型进行并行蒙特卡罗模拟,可以在不同的训练集大小下评估计算出的T c的不确定性。发现足以使 CV 分数收敛的训练集大小仍然导致预测的T c存在显着的不确定性并且后者可以通过将训练集扩大到几千个配置来大大减少。这项工作强调了使用大型训练集来构建可以实现稳健统计建模结果的最佳 CE 模型的重要性,以及机器学习力场方法提供的设施以有效地产生足够的训练数据。


























 京公网安备 11010802027423号
京公网安备 11010802027423号